【半监督医学图像分割 2021 IEEE】DU-GAN
论文题目:DU-GAN: Generative Adversarial Networks with Dual-Domain U-Net Based Discriminators for Low-Dose CT Denoising
中文题目:基于双域U-Net鉴别器的生成对抗网络用于低剂量CT去噪
论文链接:[2108.10772] DU-GAN: Generative Adversarial Networks with Dual-Domain U-Net Based Discriminators for Low-Dose CT Denoising (arxiv.org)
论文代码:https://github.com/hzzone/du-gan
论文团队:
发表时间:
DOI:
引用:
引用数:
摘要
低剂量计算机断层扫描(LDCT)由于其相关的x射线辐射对患者的潜在健康风险而引起了医学成像领域的广泛关注。然而,降低辐射剂量会降低重建图像的质量,从而影响诊断性能。在过去的几年里,各种深度学习技术,特别是生成对抗网络(gan),已经被引入到通过去噪来提高LDCT图像的图像质量,比传统方法取得了令人印象深刻的结果。基于高斯的去噪方法通常利用一个额外的分类网络,即鉴别器,来学习去噪图像与正常剂量图像之间最大的区别,从而相应地正则化去噪模型;它通常关注全局结构或局部细节。为了更好地正则化LDCT去噪模型,本文提出了一种称为DUGAN的新方法,该方法利用gan框架中基于U-Net的鉴别器来学习去噪图像和正常剂量图像在图像和梯度域的全局和局部差异。这种基于U-Net的鉴别器的优点在于它不仅可以通过U-Net的输出向去噪网络提供逐像素反馈,而且可以通过U-Net的中间层在语义层面关注全局结构。除了在图像域进行对抗性训练外,我们还在图像梯度域应用了另一种基于U-Net的鉴别器,以减轻光子饥饿引起的伪像,增强去噪后CT图像的边缘。此外,CutMix技术使基于U-Net鉴别器的逐像素输出能够为放射科医生提供置信度图,以可视化去噪结果的不确定性,从而促进基于ldct的筛查和诊断。
1. 介绍
计算机断层扫描(CT)可以通过x射线辐射提供人体内部的横切面图像,是临床诊断中最重要的成像方式之一。尽管CT在疾病诊断中发挥着至关重要的作用,但由于CT相关的x射线辐射可能对人类健康造成不可避免的损害并诱发癌症,因此CT的广泛使用引起了越来越多的公众对其安全性的关注。因此,将CT的辐射剂量降低到合理可行的最低水平。
ALARA)是过去几十年在ct相关研究中被广泛接受的原则[1]。然而,辐射剂量的降低不可避免地将噪声和伪影带入重建图像,严重影响后续诊断和其他任务,如基于ldct的肺结节分类[2]。
解决这个问题的一个直接方法是降低LDCT图像中的噪声[3],[4]。然而,由于其病态性质,它仍然是一个具有挑战性的问题。近年来,人们提出了各种基于深度学习的LDCT去噪方法[5]、[6]、[7]、[8]、[9]、[10]、[11],并取得了令人印象深刻的效果。设计去噪模型有两个关键组成部分:网络结构和损失函数;前者可以决定去噪模型的容量,后者可以控制去噪后的图像在视觉上的样子[7]。尽管人们已经探索了2D卷积神经网络(cnn)[5]、3D cnn[7]、[10]和残差编解码器cnn (REDCNN)[12]等不同的网络架构用于LDCT去噪,但文献表明,损失函数相对于网络架构更为重要,因为它直接影响图像质量[7]、[13]。
最流行的损失函数之一是均方误差(MSE),它计算去噪和正常剂量图像之间的每像素误差的平方的平均值。尽管在峰值信噪比(PSNR)方面获得了令人印象深刻的性能,但MSE通常会导致图像过度平滑,这已被证明与人类对图像质量的感知相关性较差[14],[15]。鉴于这一观察结果,已经研究了LDCT去噪的替代损失函数,如感知损失,’ 1损失和对抗损失。在训练过程中,Loss对抗性可以动态度量去噪图像与正剂量图像之间的相似性,从而使去噪图像能够保留比正剂量图像更多的纹理信息。对抗损失的计算是基于鉴别器的,鉴别器是一种分类网络,用来学习区分去噪图像和正常剂量图像的表示;根据判别器输出的一个单元对应于整个图像或局部区域,它可以在全局或局部级别测量最具判别性的差异。这种判别器容易忘记之前的差异,因为合成样本的分布随着生成器在训练过程中的不断变化而发生变化,无法保持强大的数据表示来表征全局和局部图像差异[16]。因此,往往会导致生成的图像局部结构断续、斑驳[17],或者图像的几何和结构模式不连贯[18]。除了噪声外,LDCT图像还可能包含由光子饥饿引起的严重条纹伪影,仅通过图像域的损失函数可能无法有效去除。
为了学习一种强大的数据表示来正则化对抗训练中的去噪模型,我们在gan框架中提出了一种基于U-Net[19]的LDCT去噪判别器,称为DU-GAN,它可以同时学习去噪图像和正常剂量图像在图像和梯度域中的全局和局部差异。更具体地说,我们提出的鉴别器遵循U-Net架构,包括一个编码器和一个解码器网络,其中编码器将输入编码为关注全局结构的标量值,而解码器重建一个高像素置信度图,捕捉去噪和正常剂量图像之间局部细节的变化。这样,它不仅可以提供逐像素反馈,还可以为去噪网络提供全局结构差异。除了在图像域进行对抗性训练外,我们还在图像梯度域应用了另一种基于U-Net的鉴别器,以减轻光子饥饿引起的伪像,增强去噪图像的边缘。此外,为了正则化基于U-Net的鉴别器,我们引入了CutMix数据增强来混合去噪和正常剂量的图像。因此,基于U-Net的鉴别器可以为放射科医生提供逐像素输出作为置信度图,以可视化去噪结果的不确定性,从而方便放射科医生在使用去噪后的LDCT图像时进行筛查和诊断。
所提出的DU-GAN的优点如下。
- 与现有基于gan的去噪方法使用分类作为判别器不同,本文提出的DUGAN采用基于U-Net的判别器进行LDCT去噪,可以同时学习去噪后图像与正常剂量图像的全局和局部差异。因此,它不仅可以为去噪模型提供超像素反馈,还可以提供全局结构差异。
- 除了在图像域进行对抗性训练外,本文提出的DU-GAN还在图像梯度域进行对抗性训练,可以减轻由于光子饥饿引起的条纹伪像,增强去噪图像的边缘。
- 本文提出的DU-GAN可以通过CutMix技术为放射科医生提供一个可视化去噪结果不确定性的置信度图,方便放射科医生在使用去噪后的LDCT图像时进行筛查和诊断。
在模拟和真实数据集上的大量实验通过定性和定量比较证明了所提出方法的有效性。
本文的其余部分组织如下。在第二节中,我们简要地概述了LDCT去噪方法和生成对抗网络的发展。我们介绍了基于双域U-Net鉴别器的LDCT去噪框架DU-GAN,然后在第三节中介绍了我们框架中的CutMix正则化技术以及网络架构和损失函数,随后在第四节中对模拟和现实数据集上的最新方法进行了定性和定量比较。最后,我们在第五节中总结本文。
2. 相关工作
本节简要概述了LDCT去噪和生成对抗网络的发展。
2.1 LDCT去噪
LDCT的降噪算法可以概括为三类:1)正弦图滤波;2)迭代重建;3)图像后处理。与常规CT不同的是,LDCT从扫描仪中获取有噪声的正弦图数据。一种简单的解决方案是在图像重建之前对正弦图数据进行去噪处理,即基于正弦图滤波的方法[20],[21],[22]。迭代重建方法将原始数据在正弦图域[23]、[24]的统计与图像域的总变分[25]、字典学习[26]等先验信息相结合;这些通用信息片段可以有效地集成到最大似然和压缩感知框架中。然而,这两种类型都需要访问原始数据,而商用CT扫描仪通常无法访问原始数据。
与前两类不同的是,图像后处理方法直接对去除患者隐私后公开的重构图像进行操作。然而,非局部均值[27]和块匹配3D[28]等传统方法会导致一些关键结构细节的丢失,导致LDCT图像过度平滑去噪。深度学习技术的快速发展推动了许多医学应用的发展。在LDCT去噪方面,基于深度学习的模型已经取得了令人印象深刻的效果[5]、[7]、[9]、[10]、[12]、[29]。设计基于深度学习的去噪模型有两个关键组成部分:网络结构和损失函数;前者决定了去噪模型的能力,而后者决定了去噪模型的能力然后控制去噪图像的视觉效果。
虽然文献提出了几种不同的LDCT去噪网络架构,如2D CNN[5]、3D CNN[7]、[10]、RED-CNN[5]、级联CNN[12],但文献表明损失函数的作用相对于网络架构更为重要,因为损失函数对图像质量有直接影响[7]、[13]。最简单的损失函数是MSE,但它与人类对图像质量的感知相关性很差[14],[15]。鉴于这一观察结果,已经研究了LDCT去噪的替代损失函数,如感知损失、1损失、对抗损失或混合损失函数。
其中,对抗损失被证明是一种强大的损失,它可以在训练过程中动态度量去噪图像与正常剂量图像之间的相似性,使去噪图像比正常剂量图像保留更多的纹理信息。对抗损失反映全局或局部相似度,取决于鉴别器的设计。
与传统的对抗损失不同,本研究中使用的对抗损失是基于基于U-Net的鉴别器,它可以同时表征去噪和正常剂量图像之间的全局和局部差异,更好地正则化去噪模型。也就是说,DU-GAN既具有逐像素鉴别器捕获像素级变化的优点,又具有传统分类鉴别器关注全局结构的优点。除了图像域的对抗损失外,本文提出的图像梯度域的对抗损失可以减轻光子饥饿引起的条纹伪影,增强去噪图像的边缘。
2.2 GANs
作为近年来最热门的研究课题之一,gan[14]及其变体已成功应用于各种任务中[30],[31],[32]。它们通常由两个网络组成:1)生成器学习捕获训练数据的数据分布并产生与真实样本无法区分的新样本,以及2)鉴别器试图区分真实样本和生成器产生的假样本。这两个网络交替训练,一旦达到平衡就结束。在LDCT去噪中,发生器的目的是产生逼真的去噪结果来欺骗鉴别器,而鉴别器则试图区分真实的正常剂量CT (NDCT)图像和去噪后的图像。为了提高训练GAN的稳定性,人们提出了各种GAN的变体,如Wasserstein GAN (WGAN)[33]、带梯度惩罚的WGAN (WGAN- gp)[34]和最小二乘GAN[35]。
本文采用最小二乘gan[35]、谱归一化gan[36]和基于U-Net的鉴别器[16]组成了LDCT去噪的gan框架。作为显著的区别,我们的DU-GAN在图像和梯度域都进行对抗训练,这可以同时减少噪声和条纹伪像。我们注意到,提出的DU-GAN也适用于其他GAN变体,如WGAN和WGAN- gp。
3. 方法
图1给出了提出的用于LDCT去噪的DU-GAN,它包含一个去噪模型作为生成器,以及两个基于UNet的图像和梯度域鉴别器。我们强调基于U-Net的鉴别器能够学习去噪和正常剂量图像之间的全局和局部差异。接下来,我们详细介绍了所有组件,网络架构和损失函数,其次是其复杂性
3.1 去噪过程
去噪过程是学习生成模型G,该模型将大小为
w
×
h
w\times h
w×h的LDCT图像
I
L
D
∈
R
w
×
h
I_{\mathrm{LD}}\in\mathbb{R}^{w\times h}
ILD∈Rw×h映射到其正常剂量CT (NDCT)对应的IND
I
N
D
∈
R
w
×
h
I_{\mathrm{ND}}\in\mathbb{R}^{w\times h}
IND∈Rw×h消除LDCT图像中的噪声。正式地,它可以写成:
I
d
e
n
=
G
(
I
L
D
)
≈
I
N
D
,
I_{\mathrm{den}}=G(I_{\mathrm{LD}})\approx I_{\mathrm{ND}},
Iden=G(ILD)≈IND,
其中
I
d
e
n
I_{\mathrm{den}}
Iden为去噪后的LDCT图像。通常,LDCT去噪可以看作是一个特定的图像翻译问题。因此,基于gan的方法[7]、[8]、[9]、[37]利用gan生成高质量图像的强大能力,提高去噪后LDCT图像的视觉质量。与传统gan采用噪声向量生成图像不同,我们的去噪模型作为生成器,只以LDCT图像作为输入。在本研究中,我们使用RED-CNN[6]作为去噪模型来证明基于双域U-Net的鉴别器在对抗训练中的有效性。
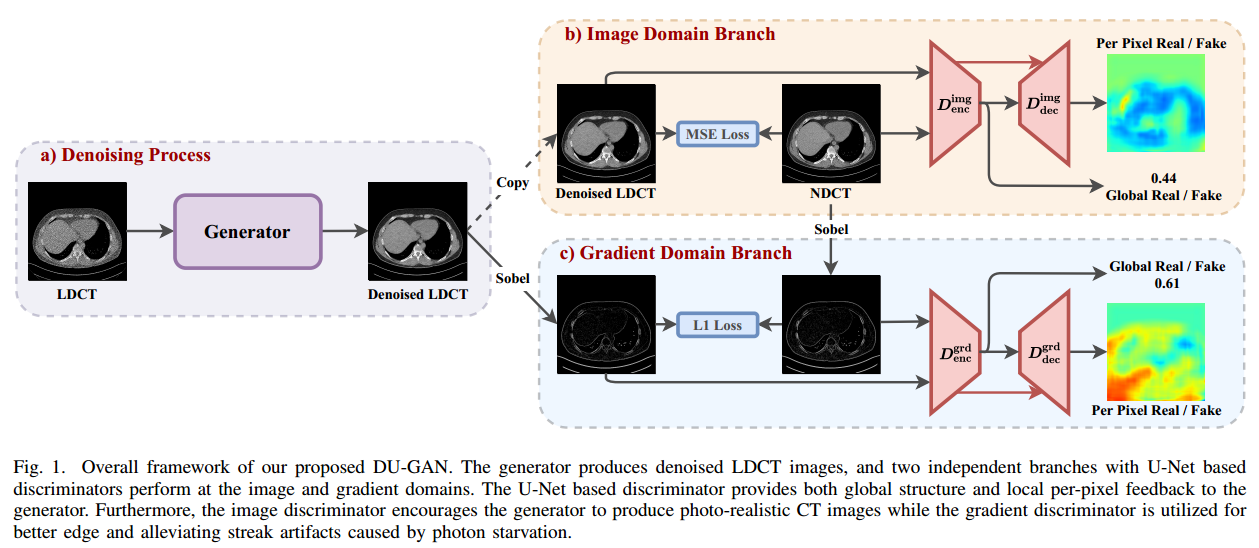
3.2 基于双域u网的鉴别器
基于gan的LDCT去噪方法[7]、[8]、[9]、[37]通常保持gan在结构层次下的竞争,其判别器将输入逐步下采样为标量值,并使用Wasserstein gan[33]、[34]进行训练,如图2(a)所示。然而,鉴别器容易忘记之前的样本,因为在训练过程中合成样本的分布会随着生成器的不断变化而发生变化,无法保持强大的数据表示来表征全局和局部图像差异[16],[38]。
为了解决上述问题,我们在图像和梯度域引入了基于U-Net的鉴别器。
基于U-Net的图像域鉴别器:为了学习一种能够同时表征全局和局部差异的强大数据表示,我们设计了一个基于gan的LDCT去噪框架来处理LDCT去噪。
传统上,U-Net包含一个编码器、一个解码器和几个跳过连接,将特征映射从编码器复制到解码器,以保持高分辨率特征,这在许多语义分割任务[39]、[40]和图像翻译任务[16]、[31]中展示了其最先进的性能。在LDCT去噪的背景下,我们强调U-Net及其变体仅被用作去噪模型,而未被用作鉴别器。我们采用U-Net来代替标准。
gan中的分类鉴别器具有U-Net风格的鉴别器,允许鉴别器同时维护全局和局部数据表示。图2(b)详细描述了基于U-Net的鉴别器的体系结构
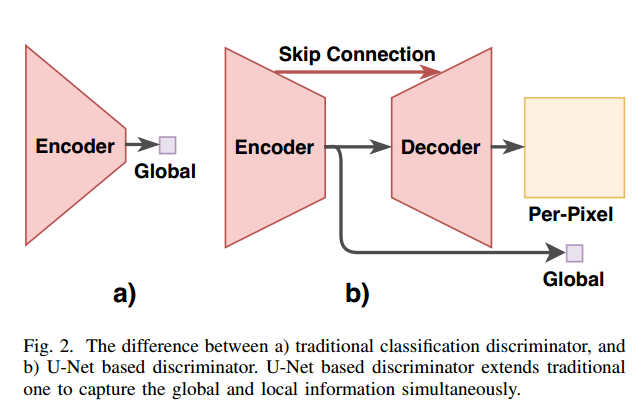
在这里,我们使用 D i m g D^{\mathrm{img}} Dimg来表示图像域中基于U-Net的鉴别器。 D i m g D^{\mathrm{img}} Dimg的编码器, D e n c i m g D^{\mathrm{img}}_{enc} Dencimg,遵循传统的鉴别器,使用几个卷积层逐步下采样输入,捕获全局结构上下文。另一方面,解码器 D i m g D^{\mathrm{img}} Dimg解码器通过与编码器 D i m g D^{\mathrm{img}} Dimg解码器以相反顺序的跳过连接进行累进上采样,进一步增强了鉴别器绘制真实和虚假样本的局部细节的能力。此外,鉴别器损失从 D e n c i m g D^{\mathrm{img}}_{enc} Dencimg和 D d e c i m g D^{\mathrm{img}}_{dec} Ddecimg的输出中计算,而以前的作品[7],[8],[37]中使用的传统鉴别器仅将编码器的输入分为真假。这样,基于U-Net的鉴别器可以为生成器提供更多的信息反馈,包括局部逐像素和全局结构信息。在本文中,我们采用最小二乘gan[35]而不是传统的gan[14]作为鉴别器,以稳定训练过程并提高去噪后LDCT的视觉质量。
正式地,Dimg的鉴别器损失从
D
e
n
c
i
m
g
D^{\mathrm{img}}_{enc}
Dencimg和
D
d
e
c
i
m
g
D^{\mathrm{img}}_{dec}
Ddecimg都可以写成:
L
D
i
m
g
=
E
I
N
D
[
D
e
n
c
i
m
g
(
I
N
D
)
−
1
]
2
+
E
I
L
D
[
D
e
n
c
i
m
g
(
I
d
e
n
)
]
2
+
⏟
global adversarial
E
I
N
D
[
D
d
e
c
i
m
g
(
I
N
D
)
−
1
]
2
+
E
I
L
D
[
D
d
e
c
i
m
g
(
I
d
e
n
)
]
2
⏟
l
o
c
a
l
a
d
v
e
r
s
a
r
i
a
l
\begin{gathered} \mathcal{L}_{D^{\mathrm{img}}} =\underbrace{\mathbb{E}_{\boldsymbol{I}_{\mathrm{ND}}}\left[D_{\mathrm{enc}}^{\mathrm{img}}\left(\boldsymbol{I}_{\mathrm{ND}}\right)-1\right]^{2}+\mathbb{E}_{\boldsymbol{I}_{\mathrm{LD}}}\left[D_{\mathrm{enc}}^{\mathrm{img}}\left(\boldsymbol{I}_{\mathrm{den}}\right)\right]^{2}+}_{\text{global adversarial}} \\ \underbrace{\mathbb{E}_{\boldsymbol{I_{\mathrm{ND}}}}\left[D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I_{\mathrm{ND}}})-1\right]^{2}+\mathbb{E}_{\boldsymbol{I_{\mathrm{LD}}}}\left[D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I_{\mathrm{den}}})\right]^{2}}_{\mathrm{local~adversarial}} \end{gathered}
LDimg=global adversarial
EIND[Dencimg(IND)−1]2+EILD[Dencimg(Iden)]2+local adversarial
EIND[Ddecimg(IND)−1]2+EILD[Ddecimg(Iden)]2
梯度域基于U-Net的鉴别器:
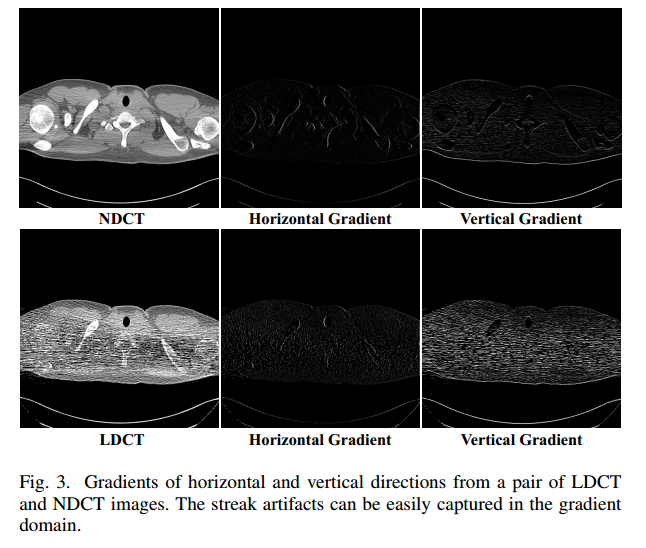
然而,单独在图像域的竞争只能迫使生成器生成逼真的去噪LDCT图像;保留原始NDCT的病理变化不足以鼓励更好的边缘消除了LDCT中光子饥饿引起的条纹伪影。先前的方法如[9]测量梯度域中不同的MSE,由于MSE容易使图像模糊,可能不足以增强边缘。为此,我们建议在梯度域进行额外的gan竞争,我们的动机如图3所示。具体来说,CT图像中的条纹和边缘在其水平和垂直梯度大小上突出显示。因此,在图像分支之外执行由Sobel算子[41]估计的梯度的另一个分支,从而获得更好的边缘信息并减轻条纹伪影。与(2)类似,我们可以定义梯度域中的鉴别器损失LDgrd,其中Dgrd表示梯度域中的鉴别器。
基于双域U-Net的判别器:结合图像域和梯度域的U-Net判别器,在训练过程中保持两个独立的gan竞争。我们提出的LDCT去噪模型的总体框架如图1所示。具体来说,该生成器是对LDCT图像进行降噪,然后将其馈送到两个独立的判别器中,分别在图像和梯度域中工作。图像域分支中的鉴别器
D
i
m
g
D^{\mathrm{img}}
Dimg惩罚生成逼真的去噪LDCT的生成器,而梯度域分支中的鉴别器
D
g
r
d
D^{\mathrm{grd}}
Dgrd鼓励更好的边缘,同时减轻由光子饥饿引起的条纹伪影。此外,每个分支的鉴别器采用了基于U-Net的架构,以鼓励生成器同时关注全局结构和局部细节,这也可以提高对
D
d
e
c
i
m
g
D^{\mathrm{img}}_{dec}
Ddecimg和
D
d
e
c
g
r
d
D^{\mathrm{grd}}_{dec}
Ddecgrd输出的逐像素置信图的去噪过程的可解释性。最后,基于U-Net的双域鉴别器损失可以定义为:
L
D
d
u
d
=
L
D
i
m
g
+
L
D
g
r
d
.
\mathcal{L}_{D^{\mathrm{dud}}}=\mathcal{L}_{D^{\mathrm{img}}}+\mathcal{L}_{D^{\mathrm{grd}}}.
LDdud=LDimg+LDgrd.
3.3 CutMix正规化
随着训练的进行,鉴别器
D
i
m
g
D^{\mathrm{img}}
Dimg识别真假样本局部差异的能力逐渐下降,这可能会对去噪性能产生意想不到的影响。此外,鉴别器应该关注全局级的结构变化和逐像素级的局部细节。为了解决这些问题,我们采用CutMix增强技术对受到[16],[42]启发的鉴别器进行正则化,使鉴别器能够学习真假样本之间的内在差异。具体来说,CutMix技术通过从一个图像中剪切补丁并将其粘贴到另一个图像中,从两个图像中生成新的训练图像。我们在LDCT去噪的背景下定义这种增强技术如下:
I
m
i
x
=
mix
(
I
N
D
,
I
d
e
n
,
M
)
=
M
⊙
I
N
D
+
(
1
−
M
)
⊙
I
d
e
n
,
\begin{aligned} I_{\mathrm{mix}}=& \operatorname*{mix}(\boldsymbol{I_{\mathrm{ND}}},\boldsymbol{I_{\mathrm{den}}},\boldsymbol{M}) \\ =& \boldsymbol{M\odot I_{\mathrm{ND}}+(1-M)\odot I_{\mathrm{den}},} \end{aligned}
Imix==mix(IND,Iden,M)M⊙IND+(1−M)⊙Iden,
其中
M
∈
{
0
,
1
}
w
×
h
M\in\{0,1\}^{w\times h}
M∈{0,1}w×h是一个二进制掩码,控制如何混合NDCT和去噪图像,并表示逐元素乘法。
由于 CutMix 操作破坏了 NDCT 图像的全局上下文,因此编码器 D e n c i m g D_{\mathrm{enc}}^{\mathrm{img}} Dencimg应将混合样本视为全局的假样本;否则,在 GAN 的训练过程中,CutMix 可能会被引入到去噪的 LDCT 图像中,造成不良的去噪效果。同样, D d e c i m g D_{\mathrm{dec}}^{\mathrm{img}} Ddecimg应该能够识别混合区域,从而为生成器提供准确的每像素反馈。
因此,CutMix 的正则化损失可以表述为:
L
r
e
g
=
E
I
m
i
x
[
[
D
e
n
c
i
m
g
(
I
m
i
x
)
]
2
+
[
D
d
e
c
i
m
g
(
I
m
i
x
)
−
M
]
2
]
,
\mathcal{L}_{\mathrm{reg}}=\mathbb{E}_{\boldsymbol{I}_{\mathrm{mix}}}\Big[[D_{\mathrm{enc}}^{\mathrm{img}}(\boldsymbol{I}_{\mathrm{mix}})]^2+[D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I}_{\mathrm{mix}})-\boldsymbol{M}]^2\Big],
Lreg=EImix[[Dencimg(Imix)]2+[Ddecimg(Imix)−M]2],
其中,在CutMix中使用的M也可以作为
D
d
e
c
i
m
g
D_{\mathrm{dec}}^{\mathrm{img}}
Ddecimg的基本真理
此外,为了惩罚鉴别器的输出与CutMix操作后的逐像素预测一致,我们进一步引入如下[16]的另一种一致性损失,用CutMix操作正则化鉴别器,可以写为:
L
c
o
n
=
∥
D
d
e
c
i
m
g
(
I
m
i
x
)
−
m
i
x
(
D
d
e
c
i
m
g
(
I
N
D
)
,
D
d
e
c
i
m
g
(
I
d
e
n
)
,
M
)
∥
F
2
,
\mathcal{L}_{\mathrm{con}}=\|D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I}_{\mathrm{mix}})-\mathrm{mix}(D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I}_{\mathrm{ND}}),D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I}_{\mathrm{den}}),\boldsymbol{M})\|_F^2,
Lcon=∥Ddecimg(Imix)−mix(Ddecimg(IND),Ddecimg(Iden),M)∥F2,
其中
∥
⋅
∥
F
\|\cdot\|_{F}
∥⋅∥F表示弗罗本纽斯范数。
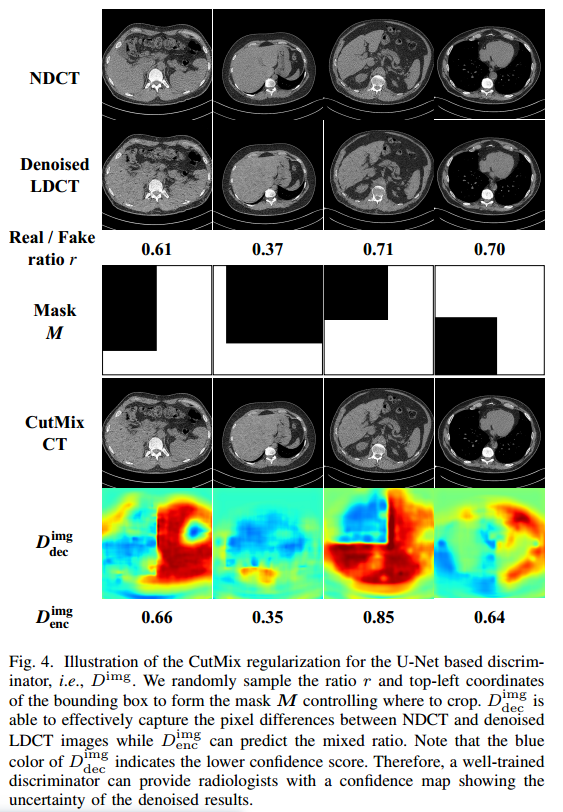
在训练过程中,按照与[42],[43]相同的管道生成二进制掩码M。具体来说,我们首先从beta分布beta (1;1),然后对边界的左上角坐标进行均匀采样box表示从 I N D I_{\mathrm{ND}} IND到 I d e n I_{\mathrm{den}} Iden的裁剪区域,同时保持r比。与[42],[43]类似,我们使用概率 p m i x p_{\mathrm{mix}} pmix来控制是否对每个小批量样本应用CutMix正则化技术,经验设置为0:5。图4为采用CutMix正则化技术的 D i m g D^{\mathrm{img}} Dimg可视化结果。可以看出, D d e c i m g D_{\mathrm{dec}}^{\mathrm{img}} Ddecimg的输出是真实patch和生成patch相对于真实/虚假分类分数的空间组合。因此,结果证明了基于U-Net的鉴别器在准确学习真实样本和生成样本之间的逐像素差异方面具有很强的判别能力,即使它们被切割和混合在一起以欺骗鉴别器。除了学习每像素的局部细节外, D e n c i m g D_{\mathrm{enc}}^{\mathrm{img}} Dencimg还可以准确地预测真实斑块的比例,即混合比例,因为它关注的是全局结构。
3.4 网络架构
如上所述,我们提出的方法遵循gan框架来有效地优化LDCT去噪的生成器,基于U-Net的鉴别器同时关注全局结构和局部细节,以及一个额外的梯度分支来鼓励更好的边界和细节。在本小节中,我们描述了生成器和基于U-Net的鉴别器的网络架构。
1)基于RED-CNN的生成器:在本文中,我们使用RED-CNN[6]作为我们的LDCT去噪框架的生成器,因为本文主要关注基于双域U-Net的鉴别器的对抗损失。与[6]的主要区别在于,我们的框架是以gan的方式进行优化的,而普通的RED-CNN存在LDCT图像被MSE过度平滑的问题。
具体来说,RED-CNN采用U-Net架构,但去掉了下采样/上采样操作,以防止信息丢失。我们在编码器和解码器上堆叠了10个(解)卷积层,出于计算成本的考虑,每个层都有32个滤波器,然后是一个ReLU激活函数。总共有10个剩余的跳过连接。值得注意的是,虽然在我们的框架中采用RED-CNN作为生成器,但所提出的方法也可以适用于其他基于gan的方法,如CPCE[7]和WGAN-VGG[8],只需改变鉴别器。
2)基于U-Net的鉴别器:如第III-B节所述,在图像和梯度域中都有两个独立的鉴别器,每个鉴别器都遵循U-Net架构。
具体来说,Denc有6个downsampling ResBlocks[44],随着滤波器数量的增加;即64、128、256、512、512、512。在Denc的底部,一个全连接层用于输出全局置信度得分。类似地,Ddec以相反的顺序使用相同数量的ResBlocks来处理相同分辨率的双线性上采样特征和跳过残差,然后使用1 × 1的卷积层来输出逐像素置信图。最重要的是,除最后一层外,每个D的卷积层后面都有一个谱归一化层[36]和一个斜率为0.2的Leaky ReLU激活。
我们注意到文献中提出了生成器和鉴别器的网络架构;我们没有提出新的网络架构来实现性能提升。我们的主要贡献之一是使用U-net作为双域中的鉴别器来捕获LDCT去噪的局部细节和全局结构。
3.5 损失函数
对抗损失:这里我们使用这两个分支的和作为对抗损失,它在最小二乘gan的背景下定义如下:
L
a
d
v
=
E
[
[
D
e
n
c
i
m
g
(
I
d
e
n
)
−
1
]
2
+
[
D
d
e
c
i
m
g
(
I
d
e
n
)
−
1
]
2
⏟
image domain
+
[
D
e
n
c
g
r
d
(
∇
(
I
d
e
n
)
)
−
1
]
2
+
[
D
d
e
c
g
r
d
(
∇
(
I
d
e
n
)
)
−
1
]
2
⏟
gradient domain
\begin{aligned}\mathcal{L}_{\mathrm{adv}}&=\mathbb{E}\Big[\underbrace{[D_{\mathrm{enc}}^{\mathrm{img}}(\boldsymbol{I_{den}})-1]^2+[D_{\mathrm{dec}}^{\mathrm{img}}(\boldsymbol{I_{den}})-1]^2}_{\text{image domain}}+\\ &\underbrace{[D_{\mathrm{enc}}^{\mathrm{grd}}(\nabla(\boldsymbol{I_{den}}))-1]^2+[D_{\mathrm{dec}}^{\mathrm{grd}}(\nabla(\boldsymbol{I_{den}}))-1]^2}_{\text{gradient domain}}\end{aligned}
Ladv=E[image domain
[Dencimg(Iden)−1]2+[Ddecimg(Iden)−1]2+gradient domain
[Dencgrd(∇(Iden))−1]2+[Ddecgrd(∇(Iden))−1]2
式中,$\nabla $为获得图像梯度的Sobel算子。
(2) 像素级损失:为了促使生成器输出具有像素级和梯度级匹配的去噪LDCT图像,我们在NDCT图像和去噪LDCT图像之间采用像素级损失,其中包括每个分支的像素级损失和梯度损失,如图1所示。额外的梯度损失有助于在像素级上更好地保留边缘信息。这两个损失可以写成:
L
i
m
g
=
E
(
I
L
D
,
I
N
D
)
∥
I
d
e
n
−
I
N
D
∥
F
2
,
L
g
r
d
=
E
(
I
L
D
,
I
N
D
)
∣
∇
(
I
d
e
n
)
−
∇
(
I
N
D
)
∣
.
\begin{aligned}\mathcal{L}_{\mathrm{img}}&=\mathbb{E}_{(\boldsymbol{I}_{\mathrm{LD}},\boldsymbol{I}_{\mathrm{ND}})}\Big\|\boldsymbol{I}_{\mathrm{den}}-\boldsymbol{I}_{\mathrm{ND}}\Big\|_{F}^{2},\\\mathcal{L}_{\mathrm{grd}}&=\mathbb{E}_{(\boldsymbol{I}_{\mathrm{LD}},\boldsymbol{I}_{\mathrm{ND}})}\Big|\nabla(\boldsymbol{I}_{\mathrm{den}})-\nabla(\boldsymbol{I}_{\mathrm{ND}})\Big|.\end{aligned}
LimgLgrd=E(ILD,IND)
Iden−IND
F2,=E(ILD,IND)
∇(Iden)−∇(IND)
.
需要注意的是,在预训练模型中,我们采用的是像素级的均方误差,而不是特征级的均方误差[7]、[8],这是考虑到计算成本的原因,而且梯度级的绝对平均误差作为梯度比像素稀疏得多。
(3)最终损失:为了促使生成器生成具有更好边缘信息的逼真去噪LDCT图像,减轻条纹伪影,优化生成器G的最终损失函数表示为:
L
G
=
λ
a
d
v
L
a
d
v
+
λ
i
m
g
L
i
m
g
+
λ
g
r
d
L
g
r
d
,
\mathcal{L}_{G}=\lambda_{\mathrm{adv}}\mathcal{L}_{\mathrm{adv}}+\lambda_{\mathrm{img}}\mathcal{L}_{\mathrm{img}}+\lambda_{\mathrm{grd}}\mathcal{L}_{\mathrm{grd}},
LG=λadvLadv+λimgLimg+λgrdLgrd,
其中,
λ
a
d
v
,
λ
i
m
g
\lambda_{\mathrm{adv}},\lambda_{\mathrm{img}}
λadv,λimg和
λ
g
r
d
\lambda_{\mathrm{grd}}
λgrd分别为Ladv、Limg和Lgrd的权值。在这里,我们以顺序的方式经验地确定超参数。首先,只有像素损失,我们提出的DU-GAN减少到RED-CNN,因为在训练过程中不包括鉴别器。虽然快速收敛,但只优化MSE损失会导致结果过平滑和模糊,导致结构细节丢失。设
λ
i
m
g
=
1
\lambda_{\mathrm{img}}=1
λimg=1。其次,我们调整
λ
a
d
v
\lambda_{\mathrm{adv}}
λadv来控制对抗损失对纹理细节捕获的重要性。我们从
λ
a
d
v
\lambda_{\mathrm{adv}}
λadv的一个小值开始,然后逐渐增加对抗损失的重要性,并将去噪结果可视化。最后,由于梯度比像素稀疏得多,我们调整λ网格以捕获具有大值的边缘信息。
鉴别器
D
i
m
g
D^{img}
Dimg和
D
g
r
d
D^{grd}
Dgrd通过最小化以下混合损失来优化:
L
D
=
L
D
d
u
d
+
L
r
e
g
+
L
c
o
n
.
\mathcal{L}_D=\mathcal{L}_{D^{\mathrm{dud}}}+\mathcal{L}_{\mathrm{reg}}+\mathcal{L}_{\mathrm{con}}.
LD=LDdud+Lreg+Lcon.
请注意,我们在(11)中使用相同的损失函数来优化Dimg和Dgrd,但它们彼此独立,Dgrd有一个额外的Sobel算子来计算梯度。
3.6 DU-GAN 的复杂性
接下来,我们从超参数和计算成本的角度讨论了DU-GAN的复杂性。首先,与直接优化均方损失的基于mse的方法相比,DU-GAN是一种基于高斯的方法,在训练过程中引入了额外的对抗损失。与传统的基于gaas的分类鉴别器方法相比,DU-GAN提出使用基于U-Net的鉴别器来关注局部细节和全局结构。此外,DU-GAN还沿着原始像素分支引入了另一个梯度分支,以鼓励清晰的边界。因此,只有一个额外的超参数来控制梯度分支的重要性。
其次,DU-GAN的主要计算开销来自于基于U-Net的鉴别器和梯度分支。
然而,考虑到我们的DUGAN具有更好的去噪质量和性能,这样的计算成本是可以承受的,并且只发生在训练阶段。也就是说,推理效率仍然与传统推理效率相同。