什么是迁移学习
迁移学习是一种机器学习方法,就是把任务为A的开发模型作为其的初始点,重新使用在任务为B的开发模型的过程中。迁移学习是通过从已学习的相关任务中转移知识来改进学习的新任务。虽然大多数机器学习的新 算法都是为了解决单个任务而设计的,但是促进迁移学习的算法开发是机器学习持续关注的话题,迁移学习对人类来说很常见,例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴
- 可以理解为模型套模型
找到目标问题的相似性,迁移学习的任务都是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。
为什么需要迁移学习?
- 大数据与少标注的矛盾,虽然有大量的数据,但往往都是没有标注的,无法训练机器学习模型,人工进行数据标注太耗时。
- 大数据与弱计算的矛盾:普通人无法拥有庞大的数据量与计算资源,因此需要借助模型的迁移。
- 普适化模型和个性化需求的矛盾:即使在同一个任务上,一个模型也往往难以满足每个人的个性化需求,比如说特定的隐私设置,这就需要在不同人之间做模型适配。
- 特定应用(如冷启动)的需求。
迁移学习的基本问题有哪些?
- 如何进行迁移学习?
- 给定一个目标领域,如何找到相对应的源领域,然后进行迁移?
- 什么时候可以进行迁移,什么时候不可以。
迁移学习有那些常用概念?
- 基本定义
- 域(Domain): 数据特征和特定分布组成,是学习的主体。
- 源域: Source domain: 已有的知识域。
- 目标域(Target domain): 要进行学习的域。
- 域(Domain): 数据特征和特定分布组成,是学习的主体。
- 任务(Task): 由目标函数和学习结果组成,是学习的结果。
- 按特征空间分类
- 同构迁移学习: 源域和目标域的特征空间相同
- 异构迁移学习:源域和目标域的特征空间不同》
- 按迁移情景分类:
- 归纳式迁移学习:源域和目标域学习任务不同。
- 直推式迁移学习:源域和目标域不同,学习任务相同
- 无监督迁移学习:源域和目标域均没有标签。
- 按迁移方法分类
- 基于样本的迁移:通过权重重用源域和目标域的样例进行迁移
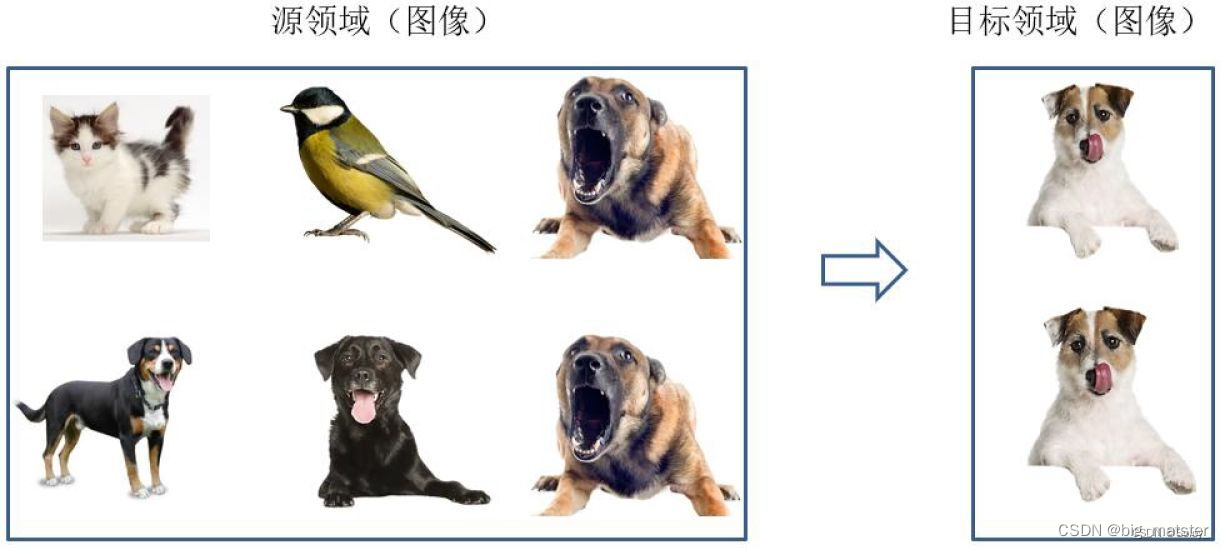
- 基于样本的迁移方法根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习,下图形象的表示了基于样本的迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等。目标域只有狗这一类别,在迁移时,为了最大限度的跟目标域相似,我们可以人为的提高源域中属于狗这个类别样本的权重。
- 基于特征的迁移:将源域和目标域的特征变换到相同空间
- 基于特征的迁移方式,是指通过特征变换的方式互相迁移,来减少源域和目标域之间的差距。或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别,根据特征的同构性和异构性,又可以分为同构和异构迁移学习,
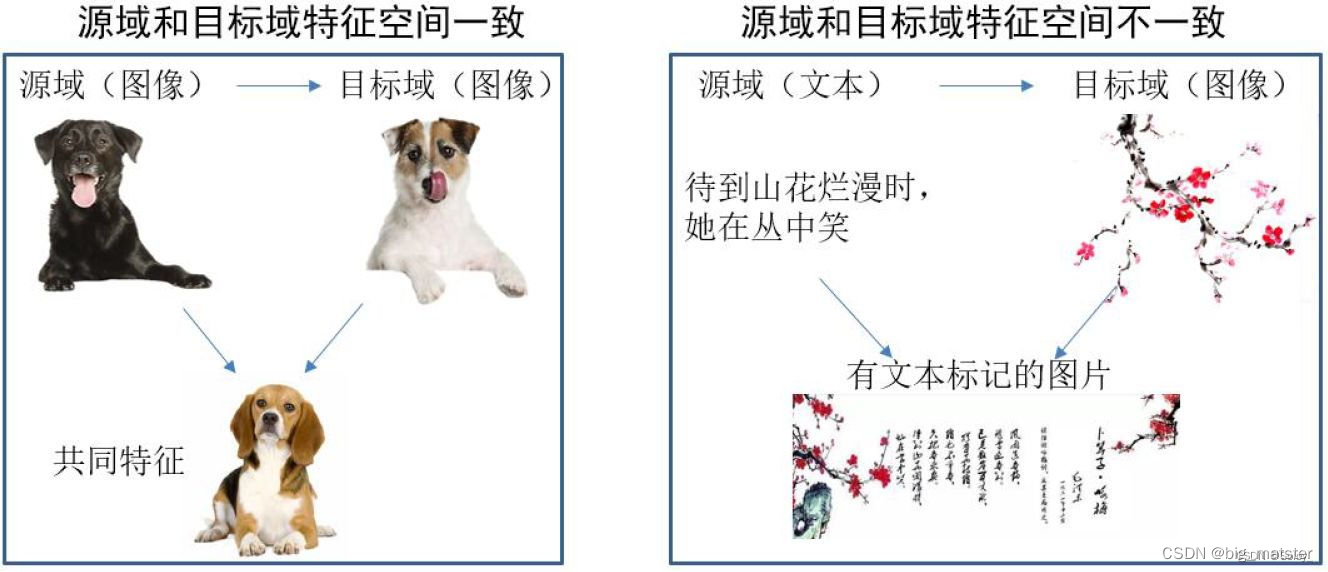
- 基于特征的迁移方式,是指通过特征变换的方式互相迁移,来减少源域和目标域之间的差距。或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别,根据特征的同构性和异构性,又可以分为同构和异构迁移学习,
- 基于模型的迁移:利用源域和目标域的参数共享模型
- 基于模型的迁移方法,是指从源域和目标域中找到它们之间共享参数的信息,以实现迁移的方法。这种迁移方式要求假设条件是:源域中的数据和目标域中的数据可以共享一些模型参数,下图形象的表示了基于模型迁移的基本思路:

- 基于模型的迁移方法,是指从源域和目标域中找到它们之间共享参数的信息,以实现迁移的方法。这种迁移方式要求假设条件是:源域中的数据和目标域中的数据可以共享一些模型参数,下图形象的表示了基于模型迁移的基本思路:
- 基于关系的迁移: 利用源域中的逻辑网络关系进行迁移。
- 基于关系的迁移方法与上述三种方法具有截然不同的思路,这种方法比较关注源域和目标域的样本之间的关系,下图形象的表示了不同领域间的相似关系。


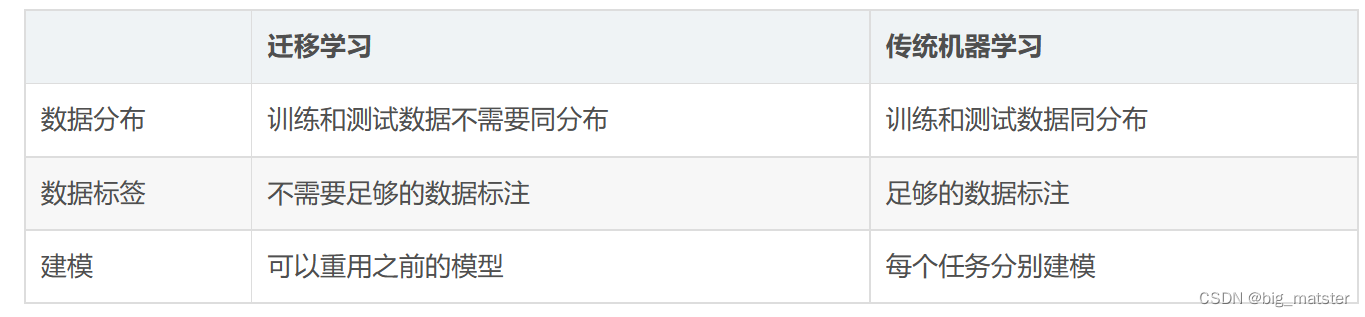
- 迁移学习与传统机器学习有什么区别?
迁移学习的核心及度量准则
迁移学习的总体思路可以概括为: 开发算法来最大限度地利用有标注的领域的知识,来辅助目标领域的知识获取和学习。- 迁移学习的核心是: 找到源领域和目标领域之间的相似性,并加以合理利用,这种相似性非常普遍,比如,不同人的身体构造是相似的,自行车和摩托车的骑行方式是相似的;国际象棋和中国象棋是相似的;羽毛球和网球的打球方式是相似的。这种相似性也可以理解为不变量。以不变应万变,才能立于不败之地。
- 有了这种相似性后,下一步工作就是:如何度量和利用这种相似性,度量工作的目标有两点:
-
- 一是很好的度量两个领域的相似性。不仅定性的告诉我们它们是否相似,而且定量的给出相似程度
-
- 以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
迁移学习与其他概念的区别
- 多任务学习: 多个相关任务一起协同学习。
- 迁移学习:强调信息的复用,从一个领域迁移到另一个领域。
- 迁移学习与领域自适应: 领域自适应:使两个特征分布不一致的domain一致
- 协方差漂移: 数据的条件概率分布发生变化。
什么是finetune?
度网络的finetune也许是最简单的深度网络迁移方法。Finetune,也叫微调、fine-tuning, 是深度学习中的一个重要概念。简而言之,finetune就是利用别人己经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
为什么需要已经训练好的网络?
在实际任务中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络,这样操作显然是非常耗时的,尤其是,我们的训练数据不可能像imageNet那么大,可以训练出泛化能力足够强的深度神经网络,即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
为什么需要finetune?
因为别人训练好的模型,可能并不是完全适用于我们自己的任务。可能别人的训练数据和我们的数据之间不服从同一个分布;可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
什么是深度网络自适应
深度网络的 finetune 可以帮助我们节省训练时间,提高学习精度。但是 finetune 有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为 finetune 的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法都开发出了自适应层(AdaptationLayer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
GAN在迁移学习中的应用
生成对抗网络, G A N GAN GAN,受到自博弈论二人零和博弈的思想启发而提出,一共包含两个部分:
- 一部分生成网络( G e n e r a t i v e N e t w o r k Generative Network GenerativeNetwork)此部分负责生成尽可能以假乱真的样本,这部分被称为生成器。
- 另一部分判别网络(
D
i
s
c
r
i
m
i
n
a
t
i
v
e
N
e
t
w
o
r
k
Discriminative Network
DiscriminativeNetwork):此部分负责判别样本是真实的,还是由生成器生成的,这部分被称为判别器(
D
i
s
c
r
i
m
i
n
a
t
o
r
Discriminator
Discriminator),生成器和判别器互相博弈,就完成了对抗训练。
GAN的目标很明确:生成训练样本,这似乎与迁移学习的大目标有的许出入,然而,由于在迁移学习中,天然存在着一个源领域,一个目标领域。因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。
总结
慢慢的根据其他将其全部都学习与研究完整都行啦的回事与打算。




![[ AWS - SAA ] 解决方案架构师之设计弹性架构 - 选择可靠的弹性存储(如何选择 SSD vs. HDD)](https://img-blog.csdnimg.cn/b7d116aa30614ab280ba8eadefd1d8f4.png)


![学习open62541 --- [73] 数据源造成无法监测变量的问题解决](https://img-blog.csdnimg.cn/883790485f584428b5c1ee8d923b54ba.png)