在本章中,我们将和您分享大型语言模型(LLM)的工作原理、训练方式以及分词器(tokenizer)等细节对 LLM 输出的影响。
我们还将介绍 LLM 的提问范式(chat format),这是一种指定系统消息(system message)和用户消息(user message)的方式,让您了解如何利用这种能力。
一、语言模型
大大语言模型(LLM)是通过预测下一个词的监督学习方式进行训练的。目标是预测下一个词的概率分布。
训练方式
- 准备大规模文本数据集,并从中提取句子或句子片段作为模型输入。
- 模型根据当前输入的上下文预测下一个词的概率分布。
- 通过比较模型预测和实际下一个词,并不断更新模型参数以最小化两者之间的差异,使模型预测能力不断提高。
基础语言模型 vs. 指令调优语言模型
- 基础语言模型(Base LLM):
- 通过反复预测下一个词进行训练,没有明确的目标导向。
- 在开放式的prompt下可能生成戏剧化的内容,给出与问题无关的回答。
- 指令调优语言模型(Instruction Tuned LLM):
- 进行了专门的训练,以更好地理解问题并给出符合指令的回答。
- 在任务导向的对话应用中表现更好,生成遵循指令的语义准确的回复。
训练过程
- 基础语言模型转变为指令调优语言模型的过程:
- 在大规模文本数据集上进行无监督预训练,获得基础语言模型。
- 使用包含指令及对应回复示例的小数据集对基础模型进行有监督的fine-tune,使其逐步学会遵循指令生成输出。
- 通过人类对输出进行评级,使用强化学习技术进一步调整模型,增加生成高质量输出的概率。这通常使用基于人类反馈的强化学习(RLHF)技术来实现
相较于训练基础语言模型可能需要数月的时间,从基础语言模型到指令微调语言模型的转变过程可能只需要数天时间,使用较小规模的数据集和计算资源。
通过训练过程,可以将基础语言模型转变为指令调优语言模型,提高其在特定任务下的表现,并节约训练时间和资源。
二、Tokens
在描述LLM时,需要考虑到一项重要的技术细节,即LLM实际上不是重复预测下一个单词,而是重复预测下一个token。Token是指文本中的最小单位,可以是单词、词组或字符。
分词器(Tokenizer)的作用
- LLM使用分词器将输入文本拆分为一系列token,而不是原始的单词。
- 分词器可以将生僻词或复杂词组拆分为更小的token,从而降低字典规模,提高模型训练和推断的效率。
示例
- 对于句子"Learning new things is fun!",每个单词被转换为一个token。
- 对于较少使用的单词,如"Prompting as powerful developer tool",单词"prompting"会被拆分为三个token,即"prom"、“pt"和"ing”。
通过Token化技术,LLM能够更高效地处理各种类型的文本输入,并提高模型的训练和推断效率。
# 为了更好展示效果,这里就没有翻译成中文的 Prompt
# 注意这里的字母翻转出现了错误,吴恩达老师正是通过这个例子来解释 token 的计算方式
response = get_completion("Take the letters in lollipop \
and reverse them")
print(response)
The reversed letters of "lollipop" are "pillipol".
但是,“lollipop” 反过来应该是 “popillol”。
但分词方式也会对语言模型的理解能力产生影响。当您要求 ChatGPT 颠倒 “lollipop” 的字母时,由于分词器(tokenizer) 将 “lollipop” 分解为三个 token,即 “l”、“oll”、“ipop”,因此 ChatGPT 难以正确输出字母的顺序。这时可以通过在字母间添加分隔,让每个字母成为一个token,以帮助模型准确理解词中的字母顺序。
因此,语言模型以 token 而非原词为单位进行建模,这一关键细节对分词器的选择及处理会产生重大影响。开发者需要注意分词方式对语言理解的影响,以发挥语言模型最大潜力。
❗❗❗ 对于英文输入,一个 token 一般对应 4 个字符或者四分之三个单词;对于中文输入,一个 token 一般对应一个或半个词。不同模型有不同的 token 限制,需要注意的是,这里的 token 限制是输入的 Prompt 和输出的 completion 的 token 数之和,因此输入的 Prompt 越长,能输出的 completion 的上限就越低。 ChatGPT3.5-turbo 的 token 上限是 4096。

三、Helper function 辅助函数 (提问范式)
语言模型提供了专门的“提问格式”,可以更好地发挥其理解和回答问题的能力。本章将详细介绍这种格式的使用方法。
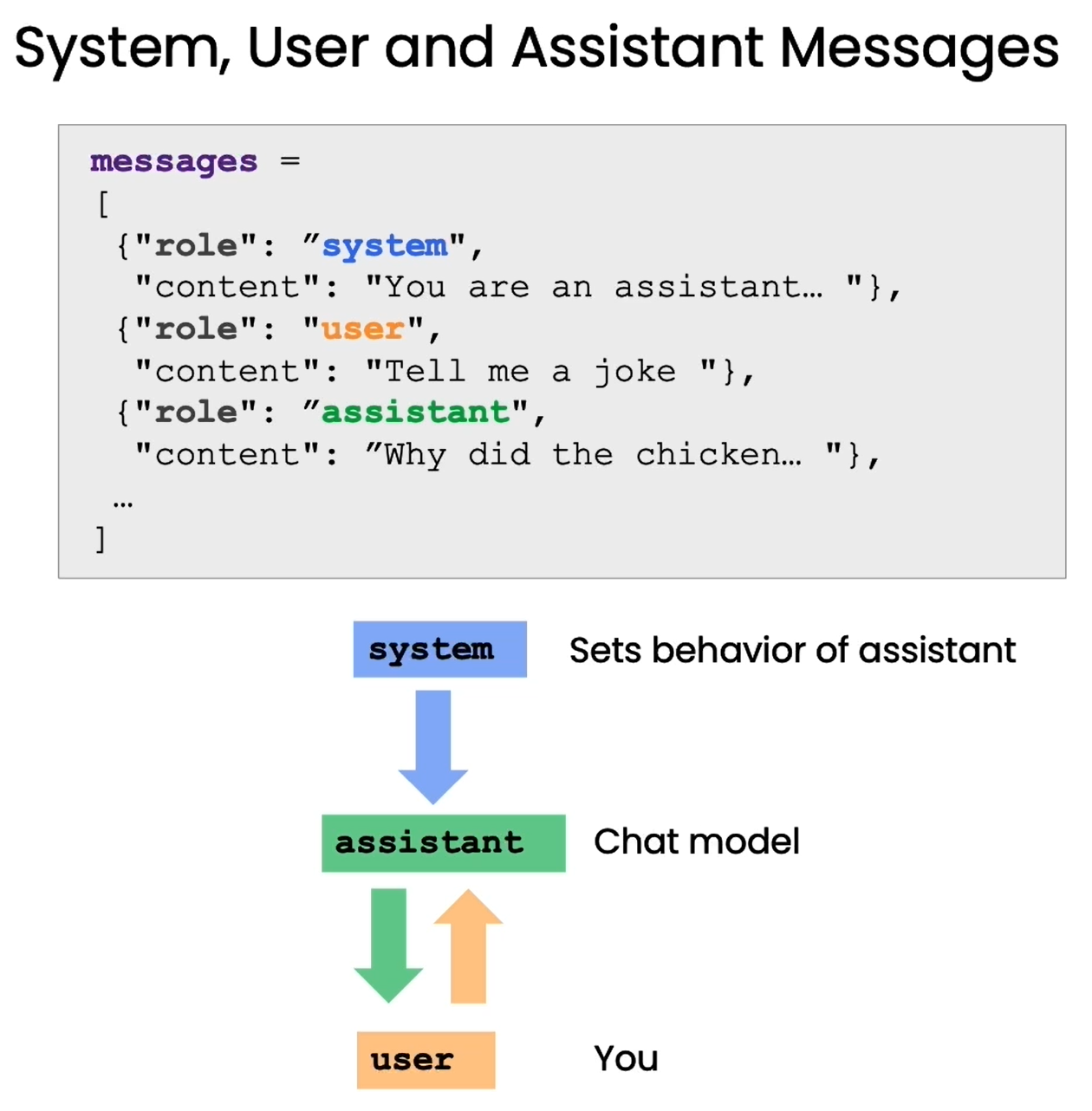
这种提问格式区分了“系统消息”和“用户消息”两个部分。系统消息是我们向语言模型传达讯息的语句,用户消息则是模拟用户的问题。例如:
系统消息:你是一个能够回答各类问题的助手。
用户消息:太阳系有哪些行星?
通过这种提问格式,我们可以明确地角色扮演,让语言模型理解自己就是助手这个角色,需要回答问题。这可以减少无效输出,帮助其生成针对性强的回复。本章将通过OpenAI提供的辅助函数,来演示如何正确使用这种提问格式与语言模型交互。掌握这一技巧可以大幅提升我们与语言模型对话的效果,构建更好的问答系统。
import openai
def get_completion_from_messages(messages,
model="gpt-3.5-turbo",
temperature=0,
max_tokens=500):
'''
封装一个支持更多参数的自定义访问 OpenAI GPT3.5 的函数
参数:
messages: 这是一个消息列表,每个消息都是一个字典,包含 role(角色)和 content(内容)。角色可以是'system'、'user' 或 'assistant’,内容是角色的消息。
model: 调用的模型,默认为 gpt-3.5-turbo(ChatGPT),有内测资格的用户可以选择 gpt-4
temperature: 这决定模型输出的随机程度,默认为0,表示输出将非常确定。增加温度会使输出更随机。
max_tokens: 这决定模型输出的最大的 token 数。
'''
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # 这决定模型输出的随机程度
max_tokens=max_tokens, # 这决定模型输出的最大的 token 数
)
return response.choices[0].message["content"]
在上面,我们封装一个支持更多参数的自定义访问 OpenAI GPT3.5 的函数 get_completion_from_messages 。在以后的章节中,我们将把这个函数封装在 tool 包中。
messages = [
{'role':'system',
'content':'你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。'},
{'role':'user',
'content':'就快乐的小鲸鱼为主题给我写一首短诗'},
]
response = get_completion_from_messages(messages, temperature=1)
print(response)
在大海的广漠深处,
有一只小鲸鱼欢乐自由;
它的身上披着光彩斑斓的袍,
跳跃飞舞在波涛的傍。
它不知烦恼,只知欢快起舞,
阳光下闪亮,活力无边疆;
它的微笑如同璀璨的星辰,
为大海增添一片美丽的光芒。
大海是它的天地,自由是它的伴,
快乐是它永恒的干草堆;
在浩瀚无垠的水中自由畅游,
小鲸鱼的欢乐让人心中温暖。
所以啊,让我们感受那欢乐的鲸鱼,
尽情舞动,让快乐自由流;
无论何时何地,都保持微笑,
像鲸鱼一样,活出自己的光芒。
在上面,我们使用了提问范式与语言模型进行对话:
系统消息:你是一个助理, 并以 Seuss 苏斯博士的风格作出回答。
用户消息:就快乐的小鲸鱼为主题给我写一首短诗
下面让我们再看一个例子:
# 长度控制
messages = [
{'role':'system',
'content':'你的所有答复只能是一句话'},
{'role':'user',
'content':'写一个关于快乐的小鲸鱼的故事'},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)Copy to clipboardErrorCopied
从小鲸鱼的快乐笑声中,我们学到了无论遇到什么困难,快乐始终是最好的解药。Copy to clipboardErrorCopied
将以上两个例子结合起来:
# 以上结合
messages = [
{'role':'system',
'content':'你是一个助理, 并以 Seuss 苏斯博士的风格作出回答,只回答一句话'},
{'role':'user',
'content':'写一个关于快乐的小鲸鱼的故事'},
]
response = get_completion_from_messages(messages, temperature =1)
print(response)Copy to clipboardErrorCopied
在海洋的深处住着一只小鲸鱼,它总是展开笑容在水中翱翔,快乐无边的时
Prompt 技术在 AI 应用开发中的革命性变革
在 AI 应用开发领域,Prompt 技术的出现带来了革命性的变革,但其重要性并未得到广泛认知。
传统机器学习工作流程的挑战
- 传统监督机器学习需要大量标记数据,耗时耗力。
- 选择、调整、评估模型需要数周甚至数月。
- 模型部署及运行需要额外时间和资源,通常需要团队数月完成。
基于 Prompt 的机器学习方法的优势
- 使用简单的 Prompt 即可构建应用,大大简化了流程。
- 构建过程通常仅需数分钟到数小时,与传统方法相比节省大量时间。
- 快速迭代、调用模型进行推理,极大提高了开发效率。
适用范围与局限性
- 适用于非结构化数据应用,特别是文本和视觉应用。
- 不适用于结构化数据应用,如处理大量数值的机器学习应用。
- 虽然整个系统构建仍需时间,但使用 Prompt 技术可加速组件构建过程。
总结
Prompt 技术改变了 AI 应用开发的范式,使开发者能更快速、高效地构建和部署应用。然而,应认识到其局限性,以更好地推动 AI 应用的发展。
在下一章中,我们将展示如何利用 Prompt 技术评估客户服务助手的输入,作为构建在线零售商客户服务助手示例的一部分。