智能咖啡厅助手:人形机器人 +融合大模型,行为驱动的智能咖啡厅机器人(机器人大模型与具身智能挑战赛)
“机器人大模型与具身智能挑战赛”的参赛作品。的目标是结合前沿的大模型技术和具身智能技术,开发能在模拟的咖啡厅场景中承担服务员角色并自主完成各种具身任务的智能机器人。这里是的参赛作品《基于大模型和行为树和生成式具身智能体》的机器人控制端代码。
1.大赛简介:
官网:https://chinasoft.ccf.org.cn/
-
机器人应用是人工智能时代最具有挑战性的前沿科学技术难题之一,它汇集了人工智能和机器人核心技术,包括人工智能学的智能感知、认知和决策的各种算法能力,以及机器人学在传感器、控制器和执行器的高可靠、高精确的运动和控制能力。
-
预训练大模型GPT技术的突破,可以为机器人提供智慧的大脑。同时,具身智能机器人是一个具有物理实体、可与真实世界进行多模态交互,像人类一样感知和理解环境,并通过自主学习完成任务的智能体。二者的结合将使机器人做到“心灵手巧”。
-
达闼云端机器人国家新一代人工智能开放创新平台与中国计算机学会、AITISA联盟、OpenI启智、CCF开源发展委员会、北京大学、复旦大学、北京航空航天大学、中山大学、北京邮电大学、北京智谱联合,共同举办达闼杯“机器人大模型与具身智能挑战赛”,旨在鼓励开发者能够利用大模型技术和具身智能技术,实现跨模态人机交互、并能自主完成各种复杂任务的机器人应用。
1.1 赛题设计:
大赛包含规定任务和开放任务两个赛道,有关各赛道的详细赛题、仿真环境与技术支持的说明,请通过“阅读原文”链接到大会网站,或参见文末“比赛指南”链接。
-
总体目标任务
-
在仿真环境中,参赛者通过大模型训练机器人在咖啡厅场景成为合格的咖啡厅服务员。这项比赛的考核要点是将大语言模型(LLMs)整合到机器人系统中,开发能够理解自然语言并以友好和有效的方式与人类互动,并能在咖啡店仿真场景中自主完成各种服务任务的智能机器人。
-
选手可以按照一般常识性理解,进行机器人任务设定和训练。在仿真场景中,机器人可以与可交互的物品和NPC进行互动操作的训练,比如:咖啡店服务员与顾客(NPC)互动、接受和执行订单以及回答有关菜单的问题、导航、操作咖啡机、清理桌子/地面、开空调/开灯、递送咖啡/饮料/食物等。
-
-
考核要点
▪主动探索和记忆(Active Exploration and Memorization):机器人在环境中通过主动探索获得各种环境信息,实现对位置环境的感知,形成以环境感知信息以及运动轨迹等历史信息维护一个机器人自身的记忆库。
▪场景多轮对话(Grouded Question Answering):多轮对话要求机器人智能体具有与人进行流畅的交流能力,具身对话是机器人利用视觉等传感器获得的场景信息基础上,完成于场景相关的对话。
▪视觉语言导航(Vision Language Navigation):导航是构建智能机器人的一个基本要素。在现实场景中,一个机器人要在不同的场景下承担多种复杂的导航任务。的模拟器支持多任务的现实世界导航和物体互动。对于这个任务中的导航,尽管有传统的ObjectNav和PointNav,你可以利用的环境完成简单到复杂的视觉语言导航,并有不同难度的指示,以及交流导航,机器人智能体可以在导航中寻求帮助。
▪视觉语言操作(Vision Language Manipulation):抓取是指机器人使用机械臂抓取物体并将其从一个原始位置移动到目标位置的动作。尽管机器人学习算法在现有的挑战上取得了很大的突破和改进,但仍有许多问题亟待解决。这项任务要求机器人按照视觉和语言的场景描述来抓取一个物体。虽然Saycan和RT-1在以前的研究中被用来实现使用Deep-RL算法的抓取,但这项任务更侧重于在现实环境中抓取薄、大、平、软的物体,避免碰撞,以及多任务抓取。参赛者需要根据大语言模型提供的指令,解决在不同场景下抓取不同物体的问题。具体抓取物品的技能需要参赛者基于提供的环境和工具接口,通过强化学习等方式进行训练。
1.2 评估
参赛队必须将LLMs纳入其机器人系统,以促进自然语言的理解和互动。比赛将根据以下标准来评估机器人系统的性能:
-
任务完成的准确性和效率:参赛者将被评估任务完成的准确性和效率,包括物体操作、导航到准确位置的精度,执行推理速度,订单执行和人机互动。机器人必须准确、高效地完成任务,才能获得分数。
-
人与机器人的互动:参赛者将被评估其机器人与顾客和工作人员互动的自然度和友好度。机器人必须以自然和友好的方式进行交流,以获得积分。
-
时间限制:参赛者将有规定的时间来完成任务,在规定时间内得分最高的团队将被宣布为获胜者。
1.3 更多细节
需要这些团队在仿真咖啡厅场景中展开一场竞技,参赛者们**不仅要 “教” 服务机器人学会如何充当咖啡厅服务员的角色,还要应对顾客、老板等角色的多轮对话“考验”,**最终自主去执行完成一系列复杂任务。
人类充当服务员在咖啡店制作一杯咖啡,并将咖啡端到指定客户的桌上或许并非难事。但是如果换成机器人,其复杂度不言而喻。这不仅仅面对硬件和环境的考验,还对于软件和算法提出了更大的挑战。
显著的技术融合性
为了实现高还原度,达闼首先在**仿真环境中构建了一个机器人元宇宙的数字孪生场景,**该虚拟场景是基于实际咖啡厅一致的各类数据产生,通过采集融合了几百个咖啡厅模型的各种常见物品,不仅仅还原了例如咖啡机、桌椅、饮品、蛋糕等环境中的各类物品、商品,同时还原了咖啡厅的实际布置灯光、清洁卫生用的工具等。一般团队很难有这个资金和精力。

值得注意的是,发现,该模拟环境中,甚至还考虑到了实际环境中物品的纹理和物理属性等问题,**杯子重量不同、落地会打碎,物品接触有摩擦力,**可以说基本做到了最终 100% 的还原。
通过提供庞大且还原度较高的数据集,基于这个数字孪生的场景,机器人开发平台可以仅通过算力,就轻易且低成本在虚拟仿真中像在真实场景一样进行各种各样的训练这也使得国内人工智能和智能大模型科研团队,能很快尝试在人形机器人上实现各类技术的结合落地。除了数字孪生环境,为了让机器人与环境进行交互的能力进一步提升,机器人硬件作为软件和算法的执行层,其设计和能力也至关重要。 由于该机器人智能体需要与外界实现实时交互,这首先需要机器人对于环境实现感知,包括了听觉、视觉和触觉等方面。
例如人到了咖啡厅,机器人不仅需要领位,由于环境的还原度非常高,机器人制作咖啡的任务中,还需要再次细分,例如如何找到咖啡机的按钮,确定咖啡机的按钮和用途等。同时,在该任务中,选择咖啡、制作咖啡、运送咖啡等也都是难点。这意味着**如何通过大模型,实现对于实际环境任务的理解和分析并执行。**例如顾客对机器人说想要喝 XX 咖啡,这种任务可能就有所区别,首先需要依靠交流中大模型的分析,准确定义需求,并实现环境中的运动和操作能力。

多任务本质上就升级到了更高层的认知层面,需要机器人语言和视觉为主的大模型,**能在环境中实现感知、认知,并根据各种请求进行处理,**这就还涉及人工智能的算法,从而才能让机器人精准实现各种各样的操作。
大模型带来的变革
大模型对于实际场景的价值仍然处于发掘期,本次大赛中,大模型对于机器人技术的实际提升无疑是一个很大的亮点。本次比赛着重体现了大模型技术应用思维链(CoT)能力的价值该能力主要体现在机器人接到任务后,对于任务的分解,从而基于思维推理形成思路链,该方式相较原先的固定化编程和深度学习,机器人可以借助大语言模型,实现自然语言到机器语言的理解、转化,最终完成两者的对齐,从而自主化执行任务。这也意味着,机器人和大模型深度结合后,在未来如果进一步实现了零样本学习 (zero-shot), 依托这两项技术,机器人也可以借助大模型实现关节运动控制,从而无需对机器人身体部位、动作的轨迹进行编程,真正做到零代码编程。
在这个比赛流程中,就看到了**智能服务机器人在语音、视觉、导航、操作等方面的落地可能性。**机器人进入陌生场景,首先会进行环境的主动探索与记忆,感知、判断不同物体和属性,实现记忆数据记录和调取。在此基础上,随后机器人开始在咖啡厅场景里与人进行交流对话,拆解任务信息。在执行层面,机器人需要借助视觉语言模型,拆分指令并实现具体动作,例如人说想喝水,机器人就需要拿取水杯、用水壶去倒水,并把水送给客人。
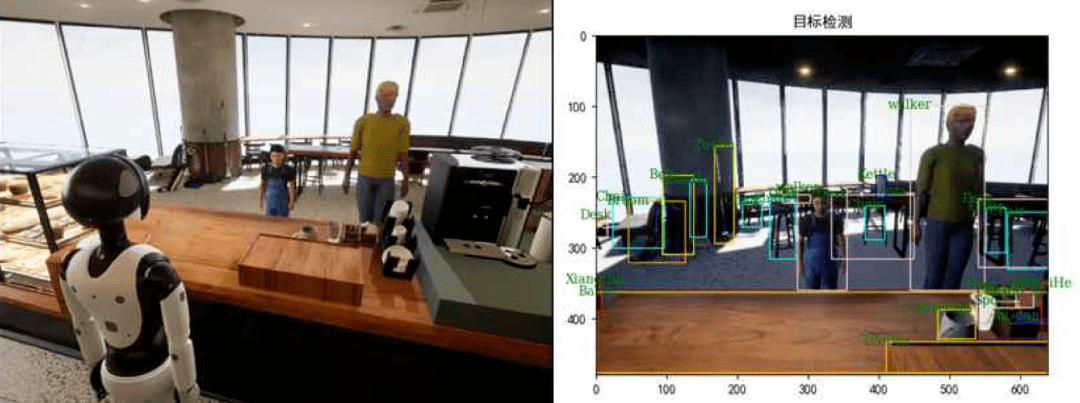
新任务新挑战
在该研究中,非常有意思的是达闼机器人还设计了两个具有挑战性的赛题,在对话人员中加入了 “店长” 这一角色。 机器人除了需要作为服务员响应相关顾客的消费需求,还需要与店长 “对接” 工作,实现人机协同。
在店长与机器人的交互中,又衍生出了更加复杂的任务,机器人需要完成 “领导交办的其他任务”。
“例如店长说好像地面不干净了,机器人就要理解这话什么意思,判断意思是我可能还要去再清洁一下卫生。” 类似的机器人触发式任务,非常考验机器人环境职责定义和自主动作选择, 需要最终机器人能够像是真正的咖啡厅服务人员,具备各种各样的附加能力,做到类似 “阴天开灯”、“水洒擦桌子” 等随机性事件的自主化观察和处理,为真正落地应用部署打下基础。

2. 项目安装(必看)
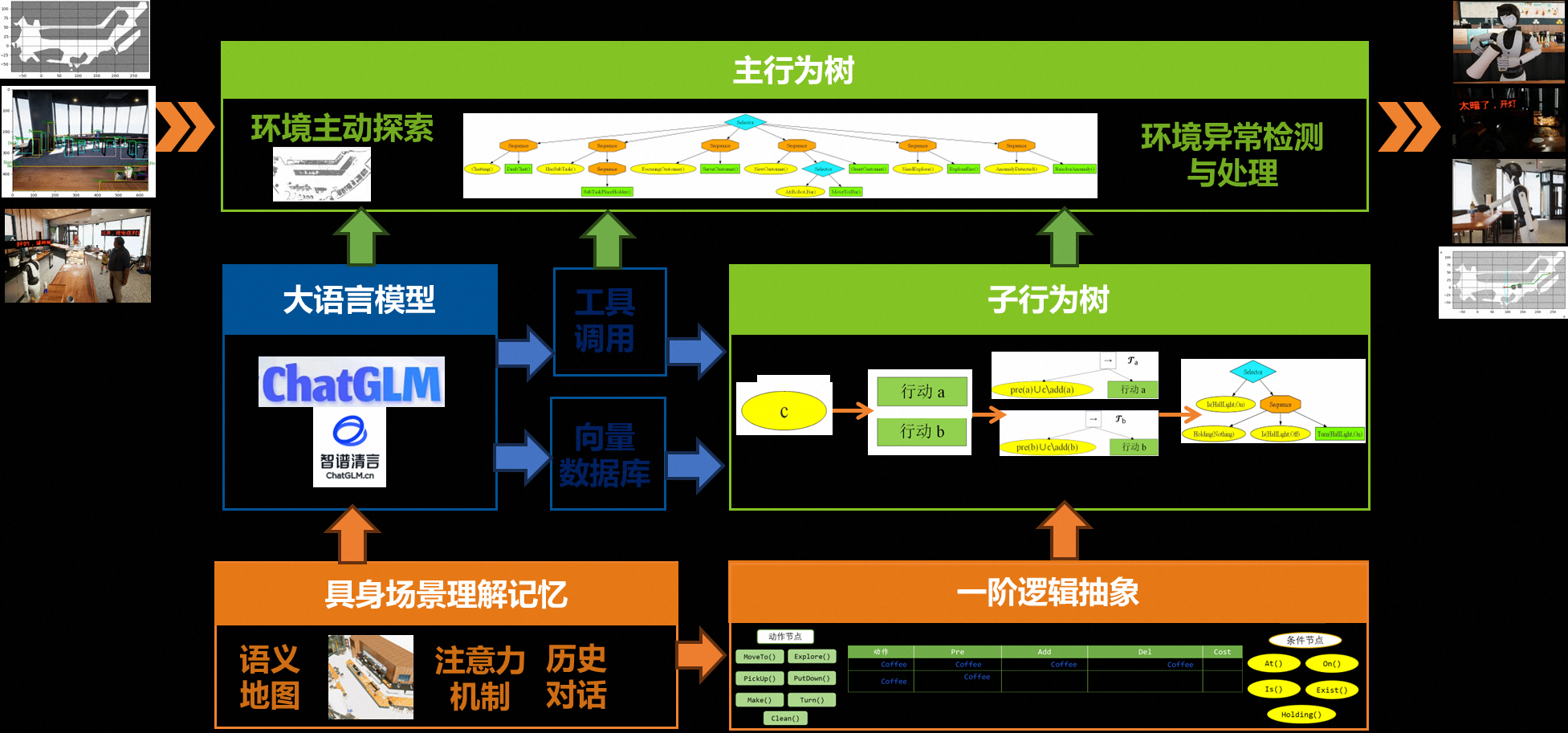
- 技术简介:提出基于大模型和行为树的生成式具身智能体系统框架
-
行为树是系统的中枢,作为大模型和具身智能之间的桥梁,解决两者结合的挑战
-
大语言模型是系统的大脑。一方面,设计了向量数据库和工具调用,另一方面,在实现智能体规划上,不再需要大语言模型输出完整的动作序列,而仅仅给出一个任务目标,这大大缓解了大模型的具身幻觉现象。
-
而具身机器人是系统的躯体,在条件节点感知和动作节点控制的函数中,优化了接口调用和算法设计,提高感知高效性和控制准确性
-
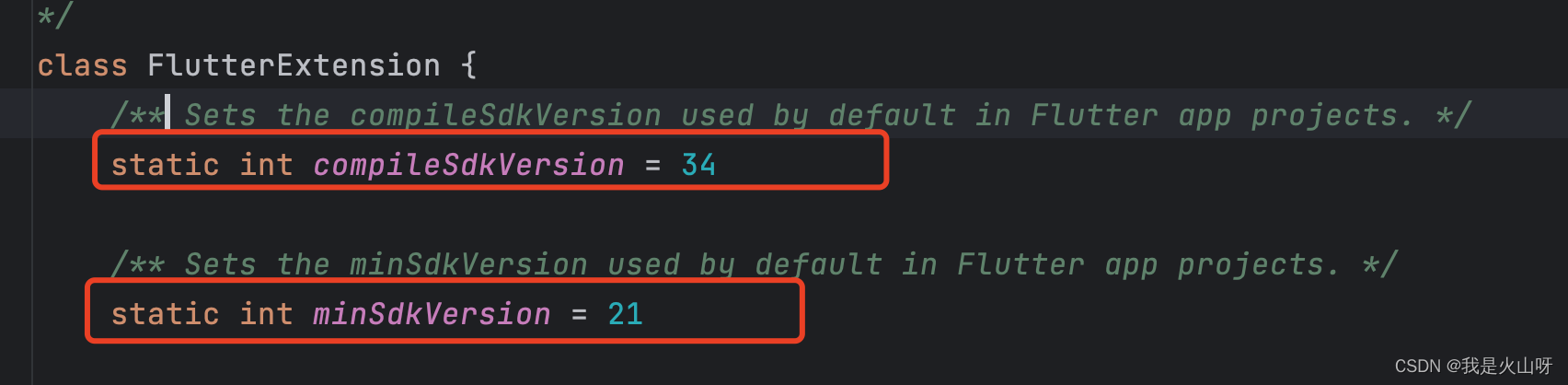
2.1 环境要求
Python=3.10
2.2 安装步骤
git clone https://github.com/HPCL-EI/RoboWaiter.git
cd RoboWaiter
pip install -e .
以上步骤将完成robowaiter项目以及相关依赖库的安装
2.3 安装UI
-
安装 graphviz-9.0.0 (详见官网)
-
将软件安装目录的bin文件添加到系统环境中。如电脑是 Windows 系统,Graphviz 安装在 D:\Program Files (x86)\Graphviz2.38,该目录下有bin文件,将该路径添加到电脑系统环境变量 path 中,即 D:\Program Files (x86)\Graphviz2.38\bin。如果不行,则需要重启。
-
安装向量数据库
conda install -c conda-forge faiss -
安装自然语言处理和翻译工具,用于计算相似性
pip install translate pip install spacy python -m spacy download zh_core_web_lgzh_core_web_lg如果下载较慢,可以直接通过分享的网盘链接下载链接:https://pan.baidu.com/s/1vr7dqHsgnh6UChymQc26VA
提取码:1201
–来自百度网盘超级会员V7的分享pip install zh_core_web_lg-3.7.0-py3-none-any.whl
2.4 快速入门
-
安装 UE 及 Harix 插件,打开默认项目并运行
-
不使用 UI 界面 :运行 tasks_no_ui 文件夹下的任意场景即可实现机器人控制端与仿真器的交互
-
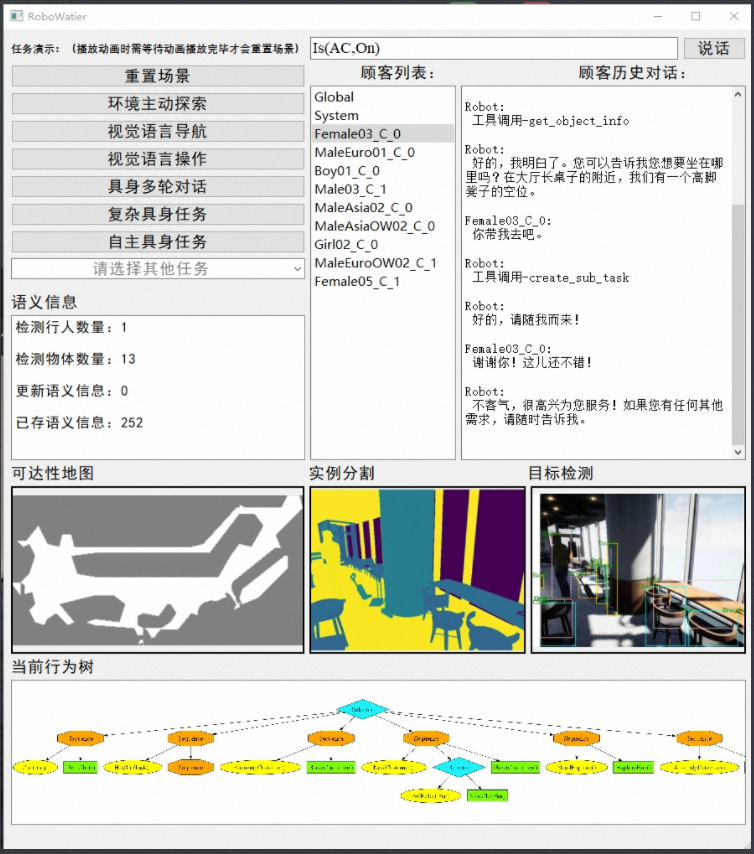
使用 UI 界面:运行
run_ui.py,显示下面的界面。点击左侧的按钮,机器人就会执行相应的任务。也可以在右上方直接输出目标状态或者对话和机器人直接交互。
3. 代码框架介绍
代码库被组织成几个模块,每个模块负责系统功能的一部分:
- behavior_lib:
behavior_lib是行为树节点库类,包括行为树的动作节点和条件节点。它们分别存放在act和cond文件夹下。 - behavior_tree:
behavior_tree是行为树算法类,包括ptml编译器、最优行为树逆向扩展算法等。 - robot:
robot是机器人类,包括从ptml加载行为树的方法,以及执行行为树的方法等。 - llm_client:
llm_client是大模型类,主要实现了大模型的数据集构建、数据处理工具、大模型调用接口、大模型评测、工具调用、工具注册、向量数据库、单论对话、对轮对话等方法或接口。
调用大模型接口。运行llm_client.py文件调用大模型进行多轮对话。输入字符即可等待回答/
cd robowaiter/llm_client
python multi_rounds.py
- scene:
scene是场景基类,该类实现了一些通用的场景操作接口,实现了与 UE 和咖啡厅仿真场景的通信。其中,包括了官方已经封装好的各种接口,如场景初始化、行人控制、操作动画设置、物品设置、机器人 IK 接口等。task_map返回的任务场景都继承于Scene。此外,在scene/ui中,实现了 UI 的界面设计和接口封装。 - utils:
utils为其它工具类,比如绘制行为树并输出为图片文件。 - algos:
algos是其它算法类,包括MemGPT、导航算法 (navigator)、边界探索 (explore)、视觉算法 (vision)、向量数据库 (retrieval) 等。 - tasks:
tasks文件夹中存放的场景定义及运行代码。
| 缩写 | 任务 |
|---|---|
| AEM | 主动探索和记忆 |
| GQA | 具身多轮对话 |
| VLN | 视觉语言导航 |
| VLM | 视觉语言操作 |
| OT | 复杂开放任务 |
| AT | 自主任务 |
| CafeDailyOperations | 整体展示:咖啡厅的一天 |
| Interact | 命令行自由交互 |
4. 效果展示
机器人根据顾客的点单,完成订单并送餐

顾客询问物品位置,并要求机器人送回

下载资料
https://download.csdn.net/download/sinat_39620217/88860251
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。