Flink-CDC版本:2.3.0
问题描述
之前通过Flink-CDC捕获Mysql数据库的数据变更情况,代码大致如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(flinkEnvConf);
MySqlSource<String> mysql = MySqlSource.<String>builder()
.hostname(host)
.port(port)
.serverId(serverId)
.username(username)
.password(password)
.databaseList(database)
.tableList(tableList)
.startupOptions(startupOptions)
.debeziumProperties(debeziumProp)
.jdbcProperties(jdbcProp)
.deserializer(new JsonDebeziumDeserializationSchema())
.build();
DataStreamSource<String> mySQLSource = env.fromSource(mysql, WatermarkStrategy.noWatermarks(), "MySQL Source");
mySQLSource.print();
debezium.database.history=com.ververica.cdc.connectors.mysql.debezium.EmbeddedFlinkDatabaseHistory
并且我是开启的checkpoint,并且重启程序后是从checkpoint进行恢复的
一开始同步一张表table_a的增量数据,发现没问题,后续新增表table_b,在捕获table_b的数据时,发现异常:
Encountered change event 'Event{header=EventHeaderV4{timestamp=170917 7391000, eventType=TABLE_MAP, serverId=1, headerLength=19, dataLength=117, nextPosition=769436194, flags=0}, data=TableMapEventData{tableId=5303, database='test', table='table_b', columnTypes=8, 15, 18, 18, 18, 18, 18, 18, 18, 18, 18, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 1, 15, columnMetadata=0, 192, 0, 0, 0, 0, 0, 0, 0, 0, 0, 192, 96, 96, 96, 96, 96, 384, 96, 96, 384, 30, 30, 30, 30, 0, 96, columnNullability={5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 1 9, 20, 21, 22, 23, 24, 25, 26}, eventMetadata=TableMapEventMetadata{signedness={1}, defaultCharset=33, charsetCollations=null, columnCharsets=null, columnNames=null, setStrValues=null, enumStrValues=null, geometryTypes=null, simplePrimaryKeys=null, primaryKeysWithPrefix=null, enumAndSetDefaultCharset=null, enumAndSetColumnCharse ts=null,visibility=null}}}' at offset {transaction_id=null, ts_sec=1709177391, file=binlog.000476, pos=769435520, server_id=1, event=3} for table test.table_b whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.
101065 Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position=769436058 --stop-position=769436194 --verbose binlog.000476
问题解决
结合debezium的源码,并且在网上找了一下相关方案如下:
链接:https://help.aliyun.com/zh/flink/support/faq-about-cdc#section-nbg-sb4-ebe
主要是两个点
1、不建议使用配置'debezium.snapshot.mode'='never'
2、通过'debezium.inconsistent.schema.handling.mode' = 'warn'参数避免报错
针对1:不使用'debezium.snapshot.mode'='never'意味着每次重启CDC进程的时候,就要重新消费一遍同步表的所有数据,无法满足业务需求
针对2:修改配置'debezium.inconsistent.schema.handling.mode' = 'warn',其实这种办法是治标不治本,修改配置只是让程序打印warn日志,代码可以继续运行,还是无法解决无法捕获增量的问题;
没办法,只能debug源码来发现问题了。先从报错位置开始看起
MySqlStreamingChangeEventSource
private void informAboutUnknownTableIfRequired(
MySqlOffsetContext offsetContext, Event event, TableId tableId, String typeToLog) {
if (tableId != null
&& connectorConfig.getTableFilters().dataCollectionFilter().isIncluded(tableId)) {
metrics.onErroneousEvent("source = " + tableId + ", event " + event);
EventHeaderV4 eventHeader = event.getHeader();
if (inconsistentSchemaHandlingMode == EventProcessingFailureHandlingMode.FAIL) {
LOGGER.error(
"Encountered change event '{}' at offset {} for table {} whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.{}"
+ "Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position={} --stop-position={} --verbose {}",
event,
offsetContext.getOffset(),
tableId,
System.lineSeparator(),
eventHeader.getPosition(),
eventHeader.getNextPosition(),
offsetContext.getSource().binlogFilename());
throw new DebeziumException(
"Encountered change event for table "
+ tableId
+ " whose schema isn't known to this connector");
} else if (inconsistentSchemaHandlingMode == EventProcessingFailureHandlingMode.WARN) {
LOGGER.warn(
"Encountered change event '{}' at offset {} for table {} whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.{}"
+ "The event will be ignored.{}"
+ "Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position={} --stop-position={} --verbose {}",
event,
offsetContext.getOffset(),
tableId,
System.lineSeparator(),
System.lineSeparator(),
eventHeader.getPosition(),
eventHeader.getNextPosition(),
offsetContext.getSource().binlogFilename());
} else {
LOGGER.debug(
"Encountered change event '{}' at offset {} for table {} whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.{}"
+ "The event will be ignored.{}"
+ "Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position={} --stop-position={} --verbose {}",
event,
offsetContext.getOffset(),
tableId,
System.lineSeparator(),
System.lineSeparator(),
eventHeader.getPosition(),
eventHeader.getNextPosition(),
offsetContext.getSource().binlogFilename());
}
} else {
LOGGER.debug(
"Filtering {} event: {} for non-monitored table {}", typeToLog, event, tableId);
metrics.onFilteredEvent("source = " + tableId);
}
}
protected void handleUpdateTableMetadata(MySqlOffsetContext offsetContext, Event event) {
TableMapEventData metadata = unwrapData(event);
long tableNumber = metadata.getTableId();
String databaseName = metadata.getDatabase();
String tableName = metadata.getTable();
TableId tableId = new TableId(databaseName, null, tableName);
// 获取了日志变更信息,根据tableId(表名)在判断缓存中是否存在
// 如果是新增表,在taskContext.getSchema() 对象中是不存在的
if (taskContext.getSchema().assignTableNumber(tableNumber, tableId)) {
LOGGER.debug("Received update table metadata event: {}", event);
} else {
informAboutUnknownTableIfRequired(
offsetContext, event, tableId, "update table metadata");
}
}
MySqlDatabaseSchema
public boolean assignTableNumber(long tableNumber, TableId id) {
// 通过schemaFor
final TableSchema tableSchema = schemaFor(id);
if (tableSchema == null) {
return false;
}
tableIdsByTableNumber.put(tableNumber, id);
return true;
}
RelationalDatabaseSchema
@Override
public TableSchema schemaFor(TableId id) {
// 最终是从schemasByTableId对象中取值
// schemasByTableId 对象通过ConcurrentMap存储
// 现在我们需要知道,ConcurrentMap 是什么时候将数据添加进去的
return schemasByTableId.get(id);
}
// 通过debug发现,调用下面这个方法,我们需要知道是谁在调用此方法
protected void buildAndRegisterSchema(Table table) {
if (tableFilter.isIncluded(table.id())) {
TableSchema schema = schemaBuilder.create(schemaPrefix, getEnvelopeSchemaName(table), table, columnFilter, columnMappers, customKeysMapper);
schemasByTableId.put(table.id(), schema);
}
}
HistorizedRelationalDatabaseSchema
// 在前面,我设置的配置是:debezium.database.history=com.ververica.cdc.connectors.mysql.debezium.EmbeddedFlinkDatabaseHistory
@Override
public void recover(OffsetContext offset) {
if (!databaseHistory.exists()) {
String msg = "The db history topic or its content is fully or partially missing. Please check database history topic configuration and re-execute the snapshot.";
throw new DebeziumException(msg);
}
// 当我们断点在这里的时候,发现tables(), tableIds()是没有数据的
databaseHistory.recover(offset.getPartition(), offset.getOffset(), tables(), getDdlParser());
// 当我们断点在这里的时候,发现tables(), tableIds()是有数据的
// recover() 这个方法时完成了赋值
// tables(), tableIds() 里面的数据,就是我们要的schema信息
recoveredTables = !tableIds().isEmpty();
for (TableId tableId : tableIds()) {
buildAndRegisterSchema(tableFor(tableId));
}
}
EmbeddedFlinkDatabaseHistory
@Override
public void recover(
Map<String, ?> source, Map<String, ?> position, Tables schema, DdlParser ddlParser) {
listener.recoveryStarted();
// schema 里面的值其实就是从tableSchemas里面遍历得到的
for (TableChange tableChange : tableSchemas.values()) {
schema.overwriteTable(tableChange.getTable());
}
listener.recoveryStopped();
}
@Override
public void configure(
Configuration config,
HistoryRecordComparator comparator,
DatabaseHistoryListener listener,
boolean useCatalogBeforeSchema) {
this.listener = listener;
this.storeOnlyMonitoredTablesDdl = config.getBoolean(STORE_ONLY_MONITORED_TABLES_DDL);
this.skipUnparseableDDL = config.getBoolean(SKIP_UNPARSEABLE_DDL_STATEMENTS);
// recover
String instanceName = config.getString(DATABASE_HISTORY_INSTANCE_NAME);
this.tableSchemas = new HashMap<>();
// tableSchemas 里面的值是通过removeHistory(instanceName)获取的
for (TableChange tableChange : removeHistory(instanceName)) {
tableSchemas.put(tableChange.getId(), tableChange);
}
}
// 这个方法的返回值是TABLE_SCHEMAS 返回的,所以要搞清楚
// TABLE_SCHEMAS在何时赋值的
public static Collection<TableChange> removeHistory(String engineName) {
if (engineName == null) {
return Collections.emptyList();
}
//
Collection<TableChange> tableChanges = TABLE_SCHEMAS.remove(engineName);
return tableChanges != null ? tableChanges : Collections.emptyList();
}
// 在此方法下,TABLE_SCHEMAS 完成赋值
// 是谁在调用此方法
public static void registerHistory(String engineName, Collection<TableChange> engineHistory) {
TABLE_SCHEMAS.put(engineName, engineHistory);
}
StatefulTaskContext
// configure()内部调用registerHistory完成schema的赋值
// 其实就是调用:mySqlSplit.getTableSchemas().values() 完成对schema的赋值
public void configure(MySqlSplit mySqlSplit) {
// initial stateful objects
final boolean tableIdCaseInsensitive = connection.isTableIdCaseSensitive();
this.topicSelector = MySqlTopicSelector.defaultSelector(connectorConfig);
EmbeddedFlinkDatabaseHistory.registerHistory(
sourceConfig
.getDbzConfiguration()
.getString(EmbeddedFlinkDatabaseHistory.DATABASE_HISTORY_INSTANCE_NAME),
mySqlSplit.getTableSchemas().values());
...
...
}
总结:
- 为什么新增实时表时,新增表的增量数据无法捕获?
因为RelationalDatabaseSchema对象内部,有一个对象Tables,Tables内部并没有保存新增表的schema信息,在解析到新增表的增量数据时会判断Tables内是否存在这个表,如果不存在会直接将这张表的增量数据过滤
- Tables对象内的schema信息是怎么获取到的?
通过上面源码从下到上的解析可以发现,Tables对象内的schema信息是通过MySqlSplit 这个对象传进来的,我们现在需要搞明白,MySqlSplit是怎么获取到的。
下面这段代码流程比较简单,直接写出来
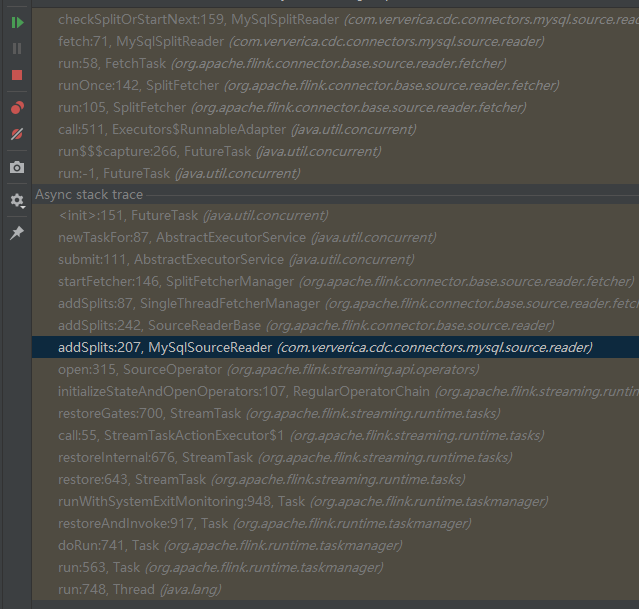
1、com.ververica.cdc.connectors.mysql.source.reader.MySqlSourceReader#addSplits
2、org.apache.flink.connector.base.source.reader.SourceReaderBase#addSplits
3、org.apache.flink.connector.base.source.reader.fetcher.SingleThreadFetcherManager#addSplits
4、org.apache.flink.connector.base.source.reader.fetcher.SplitFetcherManager#startFetcher
5、java.util.concurrent.AbstractExecutorService#submit(java.lang.Runnable)
这边是多线程异常提交:org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher
6、org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher#run
7、org.apache.flink.connector.base.source.reader.fetcher.SplitFetcher#runOnce
8、org.apache.flink.connector.base.source.reader.fetcher.FetchTask#run
9、com.ververica.cdc.connectors.mysql.source.reader.MySqlSplitReader#fetch
10、com.ververica.cdc.connectors.mysql.source.reader.MySqlSplitReader#checkSplitOrStartNext
11、com.ververica.cdc.connectors.mysql.debezium.reader.BinlogSplitReader#submitSplit
12、com.ververica.cdc.connectors.mysql.debezium.task.context.StatefulTaskContext#configure
最终调用:configure()
主要看下面:
// 此方法的入参splits,是flink通过savepoint恢复,从state中获取的
// 如果之前只捕获table_A表的增量,那么splits对象内部只有table_A的schema信息
// 如果此程序是第一次启动,那么splits中是没有任何一张表的shcema信息,那么flink-cdc代码是肯定有去获取表的schema信息的实现
// 下面看discoverTableSchemasForBinlogSplit()
@Override
public void addSplits(List<MySqlSplit> splits) {
// restore for finishedUnackedSplits
List<MySqlSplit> unfinishedSplits = new ArrayList<>();
for (MySqlSplit split : splits) {
LOG.info("Add Split: " + split);
if (split.isSnapshotSplit()) {
MySqlSnapshotSplit snapshotSplit = split.asSnapshotSplit();
snapshotSplit = discoverTableSchemasForSnapshotSplit(snapshotSplit);
if (snapshotSplit.isSnapshotReadFinished()) {
finishedUnackedSplits.put(snapshotSplit.splitId(), snapshotSplit);
} else {
unfinishedSplits.add(split);
}
} else {
MySqlBinlogSplit binlogSplit = split.asBinlogSplit();
// the binlog split is suspended
if (binlogSplit.isSuspended()) {
suspendedBinlogSplit = binlogSplit;
} else if (!binlogSplit.isCompletedSplit()) {
uncompletedBinlogSplits.put(split.splitId(), split.asBinlogSplit());
requestBinlogSplitMetaIfNeeded(split.asBinlogSplit());
} else {
uncompletedBinlogSplits.remove(split.splitId());
MySqlBinlogSplit mySqlBinlogSplit =
discoverTableSchemasForBinlogSplit(split.asBinlogSplit());
unfinishedSplits.add(mySqlBinlogSplit);
}
}
}
// notify split enumerator again about the finished unacked snapshot splits
reportFinishedSnapshotSplitsIfNeed();
// add all un-finished splits (including binlog split) to SourceReaderBase
if (!unfinishedSplits.isEmpty()) {
super.addSplits(unfinishedSplits);
}
}
private MySqlBinlogSplit discoverTableSchemasForBinlogSplit(MySqlBinlogSplit split) {
final String splitId = split.splitId();
// 当split == null时,才会去获取所有cdc表的schema信息
// 如果我是从state恢复,split肯定 != null
// 真正需要改的地方就是这里,我比较暴力,直接改为if(true)
if (split.getTableSchemas().values().isEmpty()) {
try (MySqlConnection jdbc = DebeziumUtils.createMySqlConnection(sourceConfig)) {
Map<TableId, TableChanges.TableChange> tableSchemas =
TableDiscoveryUtils.discoverCapturedTableSchemas(sourceConfig, jdbc);
LOG.info("The table schema discovery for binlog split {} success", splitId);
return MySqlBinlogSplit.fillTableSchemas(split, tableSchemas);
} catch (SQLException e) {
LOG.error("Failed to obtains table schemas due to {}", e.getMessage());
throw new FlinkRuntimeException(e);
}
} else {
LOG.warn(
"The binlog split {} has table schemas yet, skip the table schema discovery",
split);
return split;
}
}
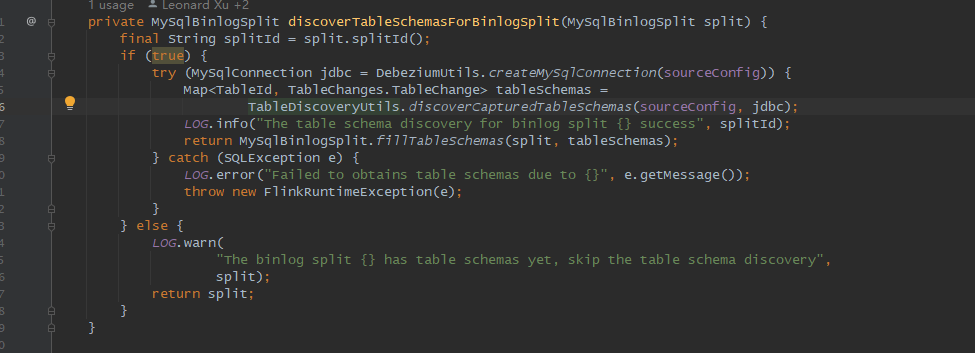
重新打包编译后测试,之前的问题已经解决。