作者:李一鸣 张兆 中科院计算所
会话式多文档问答旨在根据检索到的文档以及上下文对话来回答特定问题。 在本文中,我们介绍了 WSDM Cup 2024 中“对话式多文档 QA”挑战赛的获胜方法,该方法利用了大型语言模型 (LLM) 卓越的自然语言理解和生成能力。
在方案中,首先让大模型适应该任务,然后设计一种混合训练策略,以充分利用领域内的未标记数据。 此外,采用先进的文本嵌入模型来过滤掉潜在的不相关文档,并为模型集成设计和比较了几种方法。 凭借所有这些技术,我们的解决方案最终在 WSDM Cup 2024 中排名第一,超越在很大程度上是其竞争对手。
关键词:问答;大语言模型;文本嵌入模型;混合训练
Github开源地址:https://github.com/zhangzhao219/WSDM-Cup-2024
方案简介
对话式问答旨在根据对话中识别的用户意图生成正确且有意义的答案,在现代搜索引擎中发挥着至关重要的作用和对话系统。 然而,这仍然具有挑战性,特别是对于当前或趋势主题,因为在语言模型的训练阶段无法获得及时的知识。 尽管提供多个相关文档作为上下文信息似乎可行,但该模型仍然面临着被大量输入淹没或误导的风险。 基于来自小红书的真实文本数据,WSDM Cup 20241提出了“对话式多文档QA”的挑战,以鼓励对问题的进一步探索。
最近,ChatGPT 等大模型在多项自然语言处理任务上表现出了令人印象深刻的性能。 通过利用大模型的理解和推理能力,有望解决这一挑战。 然而,包括训练配置的设计和不相关文档的存在在内的许多因素仍然阻碍了生成质量的提高。
在这项工作中,为了激活 LLM 的能力,我们首先将任务表述为具有不同 LLM 的多轮条件生成问题。 然后,进行多阶段混合训练管道,将未标记的评估集合并为额外的训练语料库。为了删除潜在的不相关信息,我们实施了某些策略,包括最先进的嵌入模型,即 Nomic Embed 计算输入和文档之间的相似度得分。 最后,在选择最佳响应作为模型集成的最终答案之前,考虑了几种方法来近似评估各种大模型生成的答案的质量。 实验结果表明,我们的解决方案在每个评估指标上都取得了最高分,远远超出了我们背后的团队,而消融研究也表明了所提出技术的有效性。
对话式多文档问答挑战赛
「对话式多文档问答」挑战赛 Conversational Multi-Doc QA
赛题任务
每个月有数以亿计的用户在小红书上分享和发现生活的美好,并在小红书海量笔记中获取相关信息和实用的生活经验。小红书利用先进的 AI 技术,如深度学习及时下流行的大语言模型等,提升用户个性化的互动体验,更好地满足他们对高效、准确信息获取的需求。
在多轮对话场景中,为用户的查询提供准确且全面的回答是一项充满挑战的任务,在本次比赛中,我们将模拟真实的多轮对话场景,提供对话历史、当前查询 query、以及搜索系统检索到的相关笔记。参赛者的系统被要求依据这些输入信息,理解用户查询意图并输出面向查询 query 的文本回答。我们将评估回答的准确性与完善性。通过这个挑战,期待能探索和提高对话系统在面对多轮上下文和多样化搜索结果时,生成更准确,完善回答的能力,更好地理解和满足用户的需求,获取更加高效、准确的信息。
数据集
数据集包括训练/验证/测试数据,每个都将以“json”格式给出,每个样本包含以下字段:
- uuid:字符串,每个示例的唯一标识符
- history:字符串元组列表,顺序 QA 对
- documents:字符串列表,最多5个参考文档
- question:字符串,用户问题
- answer:字符串,参考答案(未在评估/测试数据中给出)
- keywords:字符串列表,最好在参考答案中提及的参考关键字(训练/评估/测试集中均未给出)
数据样例如下:
{
"uuid": "xxxxx",
"history": [
{"question": xxx, "history": xxx},
{"question": xxx, "history": xxx},
...
],
"documents":
[
"Jun 17th through Fri the 21st, 2024 at the Seattle Convention Center, Vancouver Convention Center.", "Workshops within a “track” will take place in the same room (or be co-located), and workshop organizers will be asked to work closely with others in their track ...",
...
],
"question": "Where will CVPR 2024 happen?",
"answer": "CVPR 2024 will happen at the Seattle Convention Center, Vancouver.",
"keywords": # Will not be given.
[
"Vancouver", "CVPR 2024", "Seattle Convention Center"
]
}
评估指标
指标:
- 关键词召回:答案是否包含事实以及精确匹配的特定关键词。
- 字符级 ROUGE-L :通过模糊字符级匹配,答案是否与参考答案相似。
- 单词级ROUGE-L :通过模糊单词级匹配,答案是否与参考答案相似。
排名规则:
- 整体表现将通过检查第二阶段(测试集)排行榜上上述指标的平均排名来确定。
- 如果团队平均排名相同,则优先考虑单词级 ROUGE-L分数较高的团队。
方案思路
基于LLMs实现多文档问答
为了使 LLM 适应这项任务,我们仔细设计了输入格式,并按以下顺序将每个文本部分连接在一起:
u
=
{
q
1
}
{
a
1
}
{
q
2
}
{
a
1
}
.
.
.
{
q
n
}
{
a
n
}
{
q
}
{
d
1
}
{
d
2
}
.
.
.
{
d
n
}
{
a
}
u=\{q_{1}\}\{a_{1}\}\{q_{2}\}\{a_{1}\}...\{q_{n}\}\{a_{n}\}\{q\}\{d_{1}\}\{d_{2}\}...\{d_{n}\}\{a\}
u={q1}{a1}{q2}{a1}...{qn}{an}{q}{d1}{d2}...{dn}{a}
请注意,我们在上面的拼接中排除了特殊字符(例如<s>、[INST])。
然后,可以通过最大化整个序列的对数似然来训练模型 θ \theta θ:
L g e n = − ∑ i = 1 u m i l o g p ( u i ∣ , u < i : θ ) L_{gen}=-\sum_{i=1}^{u}m_{i}log p(u_{i}|,u<i:\theta) Lgen=−i=1∑umilogp(ui∣,u<i:θ)
其中 p ( u i ∣ , u < i : θ ) p(u_{i}|,u<i:\theta) p(ui∣,u<i:θ) 代表在第i步选择来自于 u < i u<i u<i之前字符 u i u_{i} ui 的概率, m i m_{i} mi代表针对第i字符的loss mask。其中有两种训练模式
- 单轮模式:当 u i u_{i} ui属于 a {a} a, m i = 1 m_{i}=1 mi=1
- 多轮模式:当 u i u_{i} ui属于 a {a} a或者 a i {a}_{i} ai, m i = 1 m_{i}=1 mi=1。
我们基于Llama2-13B-base做了实验,发现多轮模式会带来更好的性能,可以使LLM更加关注上下文信息

在决定输入格式和掩码模式后,我们比较了许多现成的 LLM,它们要么仅经过预训练,要么经过指令调整。 如表 2 所示,SOLAR-10.7B-Instruct 模型在评估数据集上远远超过了同类模型,该模型使用深度放大来缩放 LLM,并针对指令跟踪功能进行了微调。 因此,在后续的实验中选择它作为我们的backbone。

混合训练
来自相似分布的适当标记文本可能对大模型生成性能的提高做出很大贡献。 在第二阶段,我们建议利用精调的模型为评估数据集生成(伪)答案,然后将它们添加到原始训练集以从头开始微调新模型。 上述混合训练策略的出发点有两个,一方面,它可以被视为对域内未标记数据的知识蒸馏过程,另一方面,因为我们只在a中生成最终目标${a} 伪标记方式, 伪标记方式, 伪标记方式,{ai}$仍然是官方注释的,这可能有利于多轮设置。 请注意,我们不会进一步涉及混合训练的测试数据集,因为它可能会过度拟合模型,从而削弱最终评估中的模型性能,这也通过我们的实验进行了验证。
噪音文档过滤
毫无疑问,高质量的参考文档不仅可以帮助减轻幻觉现象,还可以提高大模型的推理质量[6]。 仔细观察整个数据集后,我们发现主要有两种类型的噪声文档,如图1所示:
-
文档几乎重新表述了该问题,该问题与文档具有极高的相关分数。
-
文档包含了不相关的信息,因此它们与问题或历史记录的相关分数极低。
因此,在不存在真实答案的情况下量化相关性至关重要。 从语义和词汇的角度来看,我们得出以下两个指标:
- 嵌入级余弦相似度 我们采用高级文本嵌入模型Nomic Embed 来计算文档与相应问题(或与对话历史记录一起)之间的余弦相似度。
- 单词或字符级ROUGE-L 如前所述,ROUGE-L 分数可以被视为词汇相关性标准。
实际上,我们对每个指标分别设置较高的阈值 τ h \tau_{h} τh和较低的阈值 τ l \tau_{l} τl,然后筛选出参考文档,其对应分数≥ τ h \tau_{h} τh或≤ τ l \tau_{l} τl进行手动检查。结果,我们在第2阶段过滤掉了193个噪声文档。
此外,之前的工作表明,大模型可以更好地理解位于输入开头或结尾的重要段落。 然而,我们发现文档索引和官方注释答案中出现的相对顺序之间存在很强的相关性,这意味着对参考文档重新排序可能会导致严重的性能下降。
模型融合

模型集成已被证明在判别任务中是有效的,但是,很少在生成环境下进行探索。 在这项工作中,我们建议近似评估不同模型生成的答案的质量,然后选择最好的作为最终结果。 假设给定一个测试样本,我们有
M
M
M个候选响应进行聚合,对于每个候选
r
i
r_{i}
ri ,我们计算
r
i
r_{i}
ri 和
r
j
r_{j}
rj 之间的相关性分数
s
(
r
i
,
r
j
)
(
j
=
1
,
.
.
.
,
M
,
j
≠
i
)
s(r_{i} ,r_{j} )(j=1,...,M,j\neq i)
s(ri,rj)(j=1,...,M,j=i),将它们加在一起作为
r
i
(
q
i
=
∑
j
s
(
r
i
,
r
j
)
)
的质量分数
r_{i}(q_{i}=\sum_{j}s(r_{i},r_{j}))的质量分数
ri(qi=∑js(ri,rj))的质量分数q_{i}$。 类似地,相关性量化器可以是嵌入级余弦相似度(表示为 emb_a_s)、单词级 ROUGE-L(表示为 word_a_f)和字符级 ROUGE-L(表示为 char_a_f)。动机是最终答案应该是与最多候选模型达成一致性的代表。
实验
实验设置
训练代码使用modelscope的swift,超参数设置如下:

实验结果
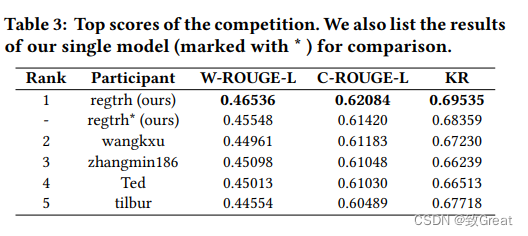
表3列出了本次比赛的最终结果。 如图所示,我们的解决方案汇总了 8 个不同模型的结果,与第二名相比,W-ROUGE-L、C-ROUGE-L 和 KR 的绝对性能分别提高了 1.6%、0.9% 和 2.3%。 此外,值得注意的是,我们的单模型也可以比其他模型产生更好的性能,这表明我们的模型是有效的策略。
消融实验
文档过滤的消融实验:表 4 显示了我们的单一模型在使用和不使用噪声文档过滤的情况下推断的实验结果。 我们发现它略微提高了最终分数,因为提供的文件是由杯赛组织者精心挑选的,大模型可以在一定程度上区分潜在的干扰因素。

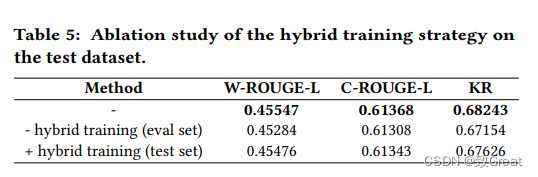
混合训练策略的消融实验:我们在表 5 中验证了所提出的混合训练策略的效果。如图所示,将评估集与相应的伪目标相结合可以很大程度上提高生成质量,特别是对于关键字召回分数。 但进一步加入测试集几乎没有什么效果,这验证了我们的设计选择。
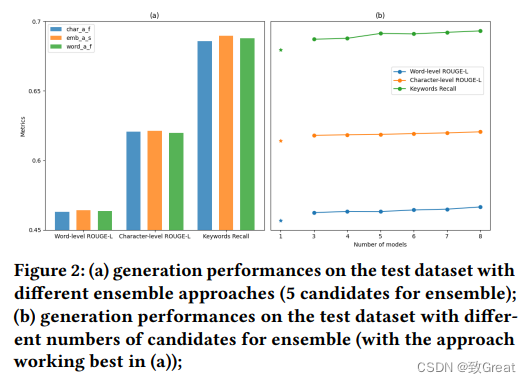
模型融合的消融实验:我们首先比较不同的集成方法,如图 2 (a) 所示。 尽管上述方法在 ROUGE 分数上都具有竞争力,但 emb_a_s 在关键字召回方面带来了更多改进,因此被选为我们最终的集成方法。 然后,对整体候选数量进行参数分析。 从图 2 (b) 中可以看出,更多的候选者通常会带来更好的性能。 由于时间和预算有限,我们最终将数量定为8。
在本文中,我们详细介绍了 WSDM Cup 2024 中“对话式多文档 QA”任务的获胜解决方案。利用法学硕士的能力,我们使用 SOLAR-10.7B-Instruct 模型作为骨干,结合混合模型 训练、噪声文档过滤器,并通过评估最终提交的 8 个结果的质量来选择最佳响应。 我们的解决方案在公共排行榜上获得了第一名。