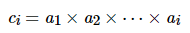课程视频链接:https://www.bilibili.com/video/BV19x411X7C6?p=1
本笔记参照该视频,笔记顺序做了些调整【个人感觉逻辑顺畅】,并删掉一些不重要的内容
系列笔记目录【持续更新】:https://blog.csdn.net/weixin_42214698/category_11393896.html
文章目录
- 1.矩阵
- (1)创建矩阵
- (2)给矩阵的行列命名
- (3)返回矩阵的行列数
- (4)矩阵的索引
- (5)矩阵的运算
- 2.数组【其实就是多维的矩阵】
- 3.列表 【就是一些对象的有序集合。每一个对象都是列表子集?】
- 4.数据框【是一种表格式的数据结构,数据框旨在模拟数据集】
1.矩阵
矩阵是二维的,需要有行和列。向量是一维的。
在R软件中,矩阵是有维数的向量,这里的矩阵元素可以是数值型、字符型或者逻辑型,但是每个元素必须拥有相同的模式,这个和向量一致。
(1)创建矩阵
m <- matrix(1:20,4,5)
行数和列数的分配必须满足分配条件。若分配的行列过大或过小,则报错。

m <- matrix(1:20,4,5,byrow=T)
byrow为TRUE为按行进行排列。默认按列进行排列。

(2)给矩阵的行列命名
rnames <- c(“R1”,“R2”,“R3”,“R4”)
cnames <- c(“C1”,“C2”,“C3”,“C4”,“C5”)
dimnames(m) <- list(rnames,cnames)

(3)返回矩阵的行列数
dim(m)

(4)矩阵的索引
m <- matrix(1:20,4,5,byrow=T) #按行优先
m[1,2]:访问第1行,第2列元素。
m[1,c(2,3,4)]:访问第1行,第234列元素。
m[c(2:4),c(2,3)]:输出矩阵的一个子集。
m[2,]:访问第2行。
m[-1,2]:去除第1行再取第2列。
注意:如果矩阵的行和列具有名称属性,也可以通过名称来访问矩阵。
(5)矩阵的运算
两矩阵的四则运算,需要两矩阵的行和列一致。
colSums(m):计算矩阵每列的和。
rowSums(m):计算矩阵每行的和。
colMeans(m):计算矩阵每列的平均值。
rowMeans(m):计算矩阵每行的平均值。
n <-matrix(1:9,3,3)
t <- matrix(2:10,3,3)
n * t:矩阵内积,两矩阵对应位置相乘。
n %*% t:矩阵外积,线性代数中的矩阵乘积。
diag(n):返回方阵对角线位置的值。
t(n):t函数能够对矩阵进行转置,将行和列进行互换。
2.数组【其实就是多维的矩阵】
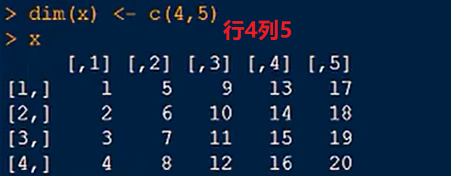
二维数组:
x <- 1:20
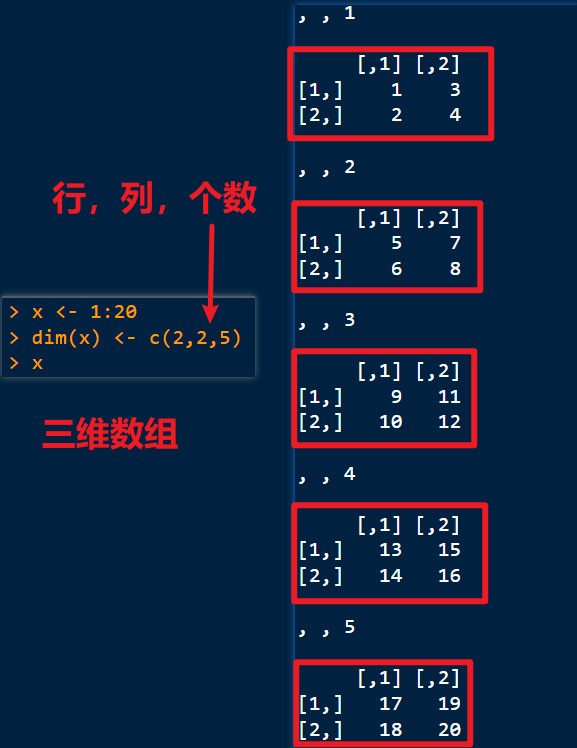
三维数组:
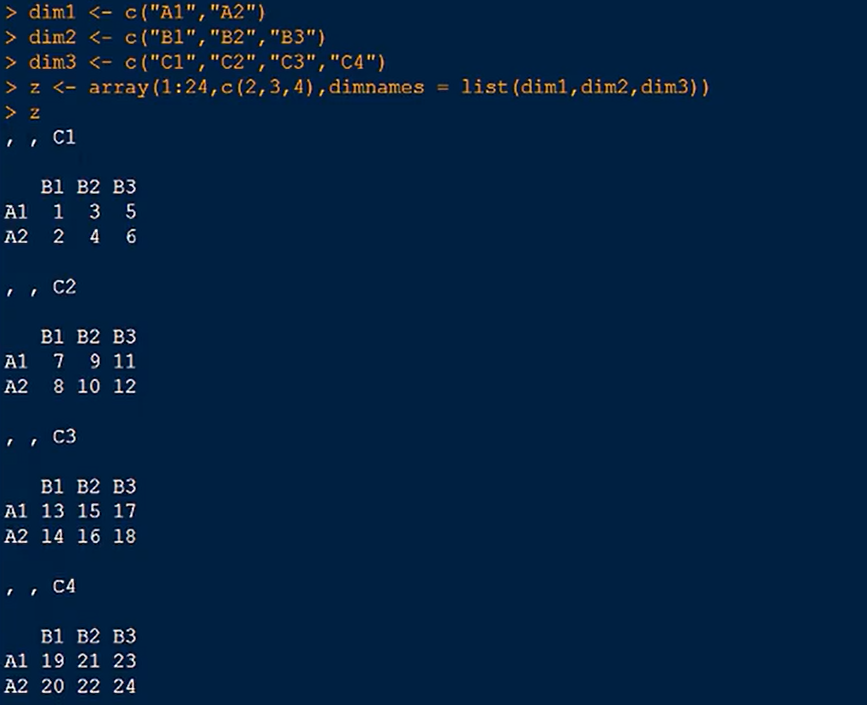
数组可以利用array函数进行创建:
3.列表 【就是一些对象的有序集合。每一个对象都是列表子集?】
在其他编程语言中,列表一般和数组等同,但在R语言中,列表却是R中最复杂的一种数据结构,也是非常重要的一种数据结构。
列表中可以存储若干向量、矩阵、数据框,甚至其他列表的组合。
与向量的区别:
- 在模式上和向量类似,都是一维数据集合。
- 向量只能存储一种数据类型,列表中的对象可以是R中的任何数据结构,甚至列表本身。
列表创建:mlist <- list(a,b,c,d)
创建列表时为列表中的每个对象命名:mlist <- list(first=a,second=b,third=c,forth=d)
访问列表:
mlist[1]:访问列表第1个元素。
mlist[c(1,4)]:访问列表第1和第4个元素。
mlist[c(“first”,“third”)]:通过列表中的对象名访问对象。
mlist$first:通过列表中的对象名访问对象。
注意:对于mlist[1]和mlist[[1]],两者返回的对象内容是一样的,
但是mlist[1]返回的对象类型是列表(列表子集),而mlist[[1]]返回的对象类型是其在mlist列表中本身的类型。
插入元素(对象):
mlist[[5]] = e # 双括号
删除元素(对象):
mlist[[5]] <- NULL 或 mlist <- mlist[-5]
4.数据框【是一种表格式的数据结构,数据框旨在模拟数据集】
数据集通常是由数据构成的一个矩形数组。行表示观测,列表示变量。就是说法不一样,观测指的就是行,变量指的是列。
数据框实际上是一个列表。列表中的元素是向量,这些向量构成数据框的列,
每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
补充个人理解:
⭐️⭐️每一个对象 都是列表子集,列表子集=【列名 + 向量(即元素)】* 1~n
与矩阵的区别:
- 数据框形状上很像矩阵;
- 数据框是比较规则的列表;
- 矩阵必须为同一数据类型;
- 数据框每一列必须同一类型 ,列与列的类型可以不同。
如:

数据框的创建:
state <- data.frame(state.name,state.abb,state.region,state.x77)
数据框的访问:
state[1]:输出数据框的第1列。
state[c(2,4)]:输出数据框的第2和第4列。
state[-c(2,4)]:输出除第2和第4列的其他列。
state[,“state.abb”]:利用列的名字 输出列的内容。
state$state.name:利用列的名字输出列的内容。
state[“Alabama”,]:利用行的名字 输出行的内容。
attach函数:加载数据框到R的搜索目录中。加载后,就可以在命令窗口中直接输入数据框列的名字就可以访问对应列。
detach函数:取消加载的数据框。
如:
attach(mtcars) #加载mtcars数据框
mpg #输入该数据框中列名为“mpg”的列
detach(mtcars) #取消加载mtcars数据框
with(数据框,{列名}):也可以访问数据框的某列。
注意:对于state[1]和state[[1]],两者返回的对象内容是一样的,但是返回的对象类型是不同的。
![C++课程成绩管理与分析系统[2023-01-07]](https://img-blog.csdnimg.cn/img_convert/68d3f788b5f1e061b7a3adcc6a872d0d.png)