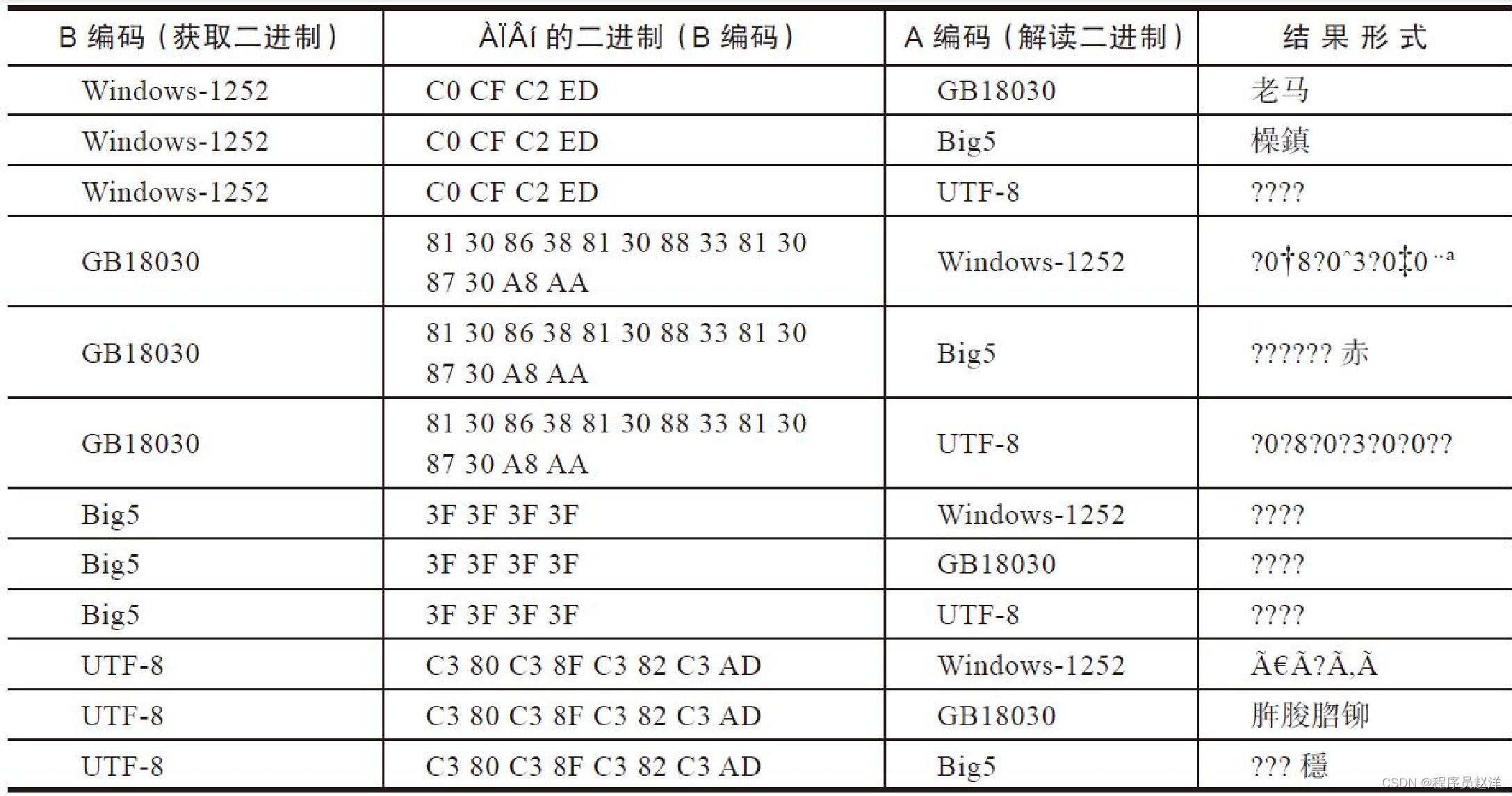
背景1
今天在看一个开源包,发现他的requirements.txt里面放着more_itertools包。
这个包的名字还是挺有意思的,在itertools包前面加上了一个more。难道是python自带的包itertools的加强版?
后来查了一下,这个包,果然是itertools的加强版,好家伙。心里有点害怕😨。
为什么会说,看到这个包,就感到害怕呢。主要是有下面几个方面:
- 多:
itertools包的函数太多了,实在是记不住,基本上算是我学习python的一大噩梦。 - 重要:
itertools包是python的函数式编程模块中,相当重要的包。 - 难:函数式编程?听起来都很高大上,更别说,用这个包了。
背景2
我其实很喜欢编程,写代码就不带困的。有时候,我会一直研究python的一些官方文档,仔细查看每一个细节。
但是我知道,我看itertools包的文档,真的很困,因为我觉得这个文档太无聊了。
https://docs.python.org/zh-cn/3/library/itertools.html
这里随手截几张itertools的函数列表:
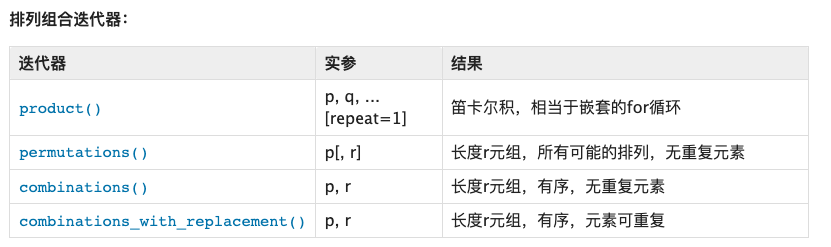
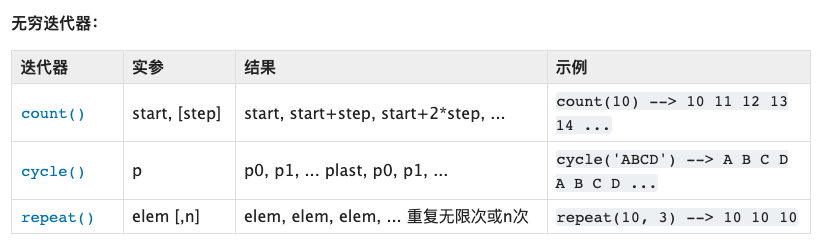
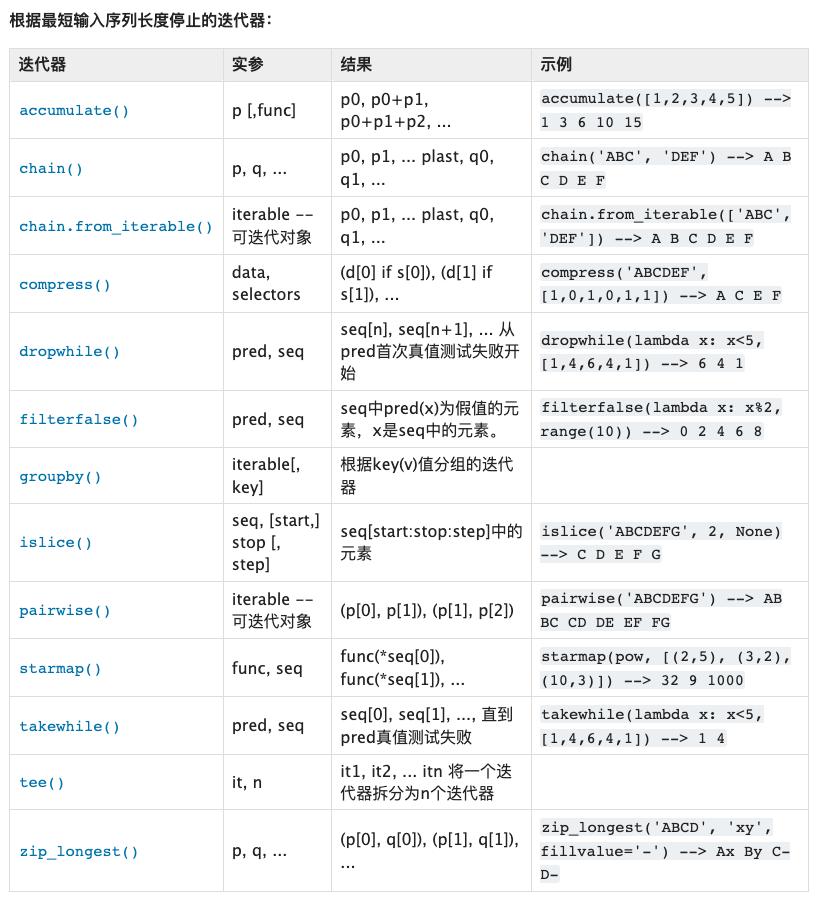
你看每一个函数对于的功能,其实都可以使用他的函数名称来表示。看起来好像不难,但是如果真的是要看懂,好像确实是挺难的。
背景3
既然这个包在python的函数式编程里面的角色这么重要,而且官方文档阅读起来也很费力。那我去网上找一找别人写的案例呗。
但是在网上找了一圈,好像也没找到什么有意思的文章,基本上都在照搬官网的文档,感觉好像没啥意思,感觉写的比python官网还无聊。
进入正题
- 想一想,自己学python真的是只是去学习几个牛逼的函数,然后拿出去炫耀,写在项目里面嘛?
- 想一想,自己学习编程中,学到的是那些包的优秀用法,还是说学习那些包所蕴含的优秀的编程思想?
- 想一想,自己在学习做项目的时候,所谓的成长,是只是把一个项目完成了,还是说掌握了解决一类问题的方法?
其实,我觉得,在有扎实的编程能力之后,我们更需要提升的是解决问题的能力,而思路,在其中发挥着一个相当大的作用。
在本文中,我将从一些现实中的问题出发,分享使用more_itertools包(或者itertools包)解决这些问题的思路。
希望这些思路,可以开阔你编程的思路;
希望这些智慧的结晶,可以抚慰你那被996压榨的灵魂。
案例
这里要说明一下:
itertools和more_itertools是两个包。itertools是python自带的,不需要安装了。more_itertools需要安装,安装方式为pip install more-itertools。但是在导入的时候,是这样的import more_itertools。希望不要搞混淆了。
1. 按条件分割
民间自古有句话,说的非常好:“什么客,什么菜;什么人,什么待”。
有一天,你的领导对你说:“良睦路程序员,马上要过春节了,给一些客户发点礼物吧,但是不是所有的客户都要发哦,在白名单里面的人,给我发,没在白名单里面的。就不要发了。”
这个时候,其实使用more_itertools包的partition函数就非常方便。
partition函数基本是这个样子的:
不满足条件的对象们, 满足条件的对象们 = partition(条件, 可迭代对象)。基本解释如下:
条件:是我们写的判断条件。可迭代对象:里面有很多元素。会用上面的条件对这里面的每一个元素做判断。- 如果元素不满足条件,就把这个元素放在
不满足条件的对象们里面。反之,放在满足条件的对象们里面。
举一个简单的例子:
from more_itertools import partition
res1, res2 = partition(lambda x: x >2, [1,4,3,2,6])
list(res1), list(res2)
# > ([1, 2], [4, 3, 6])
可以看出来:
- 不满足条件的,都跑到
res1里面了。 - 满足条件的,都跑到
res2里面了。
那么,我们回到上面领导提出的要求,说白了,就是把
- 不在白名单里面的人名字提取出来。
- 把白名单里面的人联系方式提取出来(比如邮箱)。
那么使用partition函数就可以这么写:
from typing import Dict, Iterable, Set, Tuple
from more_itertools import partition
def process(
names: Iterable[str], whitelisted_names: Set[str], name_to_email: Dict[str, str]
) -> Tuple[Iterable[str], Iterable[str]]:
refused_names, approved_names = partition(
lambda name: name in whitelisted_names, names
) # 1
approved_emails = {name_to_email[name] for name in approved_names} # 2
return refused_names, approved_emails # 3
def test_only_return_emails_for_approved_users():
name_to_email = {"John": "john.doe@gmail.com",
"Bob": "is.still.using@hotmail.com"}
names = {"Alice", "Bernard", "Bill"} | set(name_to_email.keys())
_, actual_emails = process(
names=names,
whitelisted_names=set(name_to_email.keys()),
name_to_email=name_to_email,
)
assert set(actual_emails) == set(name_to_email.values()) # 4
def test_filters_non_approved_users():
not_in_whitelist = {"Alice", "Bernard", "Bill"}
name_to_email = {"John": "john.doe@gmail.com",
"Bob": "is.still.using@hotmail.com"}
names = not_in_whitelist | set(name_to_email.keys())
refused_names, _ = process(
names=names,
whitelisted_names=set(name_to_email.keys()),
name_to_email=name_to_email,
)
assert set(refused_names) == not_in_whitelist # 5
在上面的代码中:
- 在
#1部分,我们设置了一个条件:判断这个人的名字,在不在白名单里面。如果在白名单里面,就把这些名字放在approved_names里面,如果不在白名单里面,就把名字放在refused_names里面。 - 在
#2部分,我们顺着这些满足条件的名字,提取他们对应的联系方式(这里为邮箱)。 - 在
#3部分,我们返回不在白名单里面的人的姓名和在白名单里面的人的邮箱。 - 在
#4部分,我们校验:提取的邮箱是不是真的和白名单的邮箱是一摸一样的。 - 在
#5部分,我们校验:那些不在白名单里面的人的姓名是不是确实是不在白名单里面的人。
注意上面代码里面加了type hints,就算是不运行代码,也都能了解代码的运行规则(就像是读一篇文章一样)。
实际上,上面的process函数,写法有很多,又不是非要使用partition函数。比如if-else和列表推导式。比如下面会提到的map_except函数都可以实现,选择你自己喜欢的即可。
2. 把多层嵌套展开
看我文章的人,大部分都还是20~30岁左右的年轻人吧。大家的人生可能都是这样的:
- 小学的时候:玩花片、玩玻璃珠、写作业、吃饭、睡觉。
- 初中的时候:去网吧、看小说、听歌、写作业、吃饭、睡觉。
- 高中的时候:去网吧、看视频、听歌、写作业、吃饭、睡觉。
- 大学的时候:谈恋爱、看视频、听歌、写作业、吃饭、睡觉。
- 工作的时候:结婚、买房、买车、逛街、吃饭、睡觉。
大概是这样的,一个图:
my_life = [
['小学',['玩花片','玩玻璃珠','写作业','吃饭','睡觉']],
['初中',['去网吧','看小说','听歌','写作业','吃饭','睡觉']],
['高中',['去网吧','看视频','听歌','写作业','吃饭','睡觉']],
]
# 高中、大学、工作就不列出来了,太麻烦了。
如果这个时候,我们想问自己,我们这一生,到底做了多少事情,经过多少阶段呢?只要把我们的人生,不断的展开,然后去重就行了。一行代码搞定:
from more_itertools import flatten, collapse
set(collapse(my_life))
#> {'写作业', '初中', '去网吧', '吃饭', '听歌', '小学', '玩玻璃珠', '玩花片', '看小说', '看视频', '睡觉', '高中'}
是的,我们要介绍collapse了。
collapse和flatten函数功能差不多的,都是相当于把可迭代对象当成洋葱。把他们一层一层剥开,展平。但是有个差异:
flatten函数只能展开一层。就是剥洋葱,剥一层他可以的,剥多了,她就说就辣眼睛了。collapse函数就很牛逼了。直接剥洋葱剥到内心,辣眼睛?那是不存在的,她就是这么强。
再来一个案例,如果我们希望把字典的每一个值都都提取出来,然后去重,那么常规的代码是这样的:
from typing import Dict, Set
def flatten_multivalues(key_to_values: Dict[str, Set[int]]) -> Set[int]:
all_values = set()
for values in key_to_values.values():
all_values.update(values)
return all_values
def test_flattens_multivalue_dicts():
# shamelessly taken from: https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
term_to_document_indices = {
"choice": {3},
"coming": {1},
"fury": {2},
"is": {1, 2, 3},
"the": {2, 3},
}
all_document_indices = flatten_multivalues(term_to_document_indices)
assert all_document_indices == {1, 2, 3}
但是,如果使用这个flatten函数,就简单多了,大概是这样的:
from typing import Dict, Set
from more_itertools import flatten
def flatten_multivalues(key_to_values: Dict[str, Set[int]]) -> Set[int]:
return set(flatten(key_to_values.values()))
def test_flattens_multivalue_dicts():
# shamelessly taken from: https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
term_to_document_indices = {
"choice": {3},
"coming": {1},
"fury": {2},
"is": {1, 2, 3},
"the": {2, 3},
}
all_document_indices = flatten_multivalues(term_to_document_indices)
assert all_document_indices == {1, 2, 3}
这里插一句,还有人记得numpy函数也有flatten函数吧。
import numpy as np
data = np.random.randint(0, 10, size=(3,4))
data.flatten()
#> array([3, 9, 9, 5, 5, 7, 7, 3, 9, 2, 6, 4])
3. 犯错误也别怕
在成长的过程中,谁没犯错误过。
- 考试的时候,涂错了答题卡。没事儿,只是小的模拟考试。
- 工作的时候,不小心造成了一个小错误,损失几个亿。没事儿,反正又不是你的钱。
- 恋爱的时候,惹女朋友生气了,没事儿,哄一哄就行了。
- …
就是这样,很多时候,在我们生活中,虽然犯错了,确实没什么大影响的。只要不是致命的错误即可。
就像是下面的代码一样。下面代码做了一个demo:将一串列表转换成int类型的列表。
虽然int('three') => ValueError会报错、虽然int(None) => TypeError会报错。
但是这两个错误,我们都对map_except说了:“如果犯了这两个错误,不要紧,请继续”
from more_itertools import map_except
iterable = ['1', '2', 'three', '4', None]
list(map_except(int, iterable, ValueError, TypeError))
#> [1, 2, 4]
在上面的代码中,可以使用try...except...来忽视一些错误,但是在有些情况下,这么做难免有些麻烦。而上面的map_except函数就可以做到很简单。
这里也把try...except...解决办法分享出来。大家可以对比一下。
from typing import List, Iterable
def process(x: Iterable) -> List[int]:
def small_func(x) -> int:
try:
return int(x)
except (TypeError, ValueError) as e:
return None
res = [small_func(i) for i in x]
res = [i for i in res if i is not None]
return res
process([1,2,'three', 4, None])
以前其实我还是很喜欢列表推导式的,可是这样一对比,确实使用map_except更简单。
还记得上面那个给白名单客户发邮箱的故事么?使用map_except同样是可以做到。具体方法就是直接找这个人是不是在白名单里面。如果在白名单里面,就返回邮箱,如果不在白名单里面。虽然会爆出keyError(因为白名单是一个dict数据结构,找不到key,就会爆出keyError错误),但是这个错误是在我们运行的情况下。因此没事。这里也分享出代码:
from typing import Dict, Iterable, Set, Tuple
from more_itertools import map_except
def process(
names: Iterable[str], whitelisted_names: Set[str], name_to_email: Dict[str, str]
) -> Iterable[str]:
whitelisted_name_to_email = {
name: email for name, email in name_to_email.items() if name in whitelisted_names
} # 1
return map_except(
lambda name: whitelisted_name_to_email[name], # 3
names, # 2
KeyError # 4
)
def test_only_return_emails_for_approved_users():
name_to_email = {"John": "john.doe@gmail.com", "Bob": "is.still.using@hotmail.com"}
names = {"Alice", "Bernard", "Bill"} | set(name_to_email.keys())
actual_emails = process(
names=names,
whitelisted_names=set(name_to_email.keys()),
name_to_email=name_to_email,
)
assert set(actual_emails) == set(name_to_email.values())
4. 分割
- 这个季节,很适合吃甘蔗。我觉得没人吃甘蔗,是拿着一整根吃吧。当然是要切开,分段吃。
- 还记得pandas在处理大数据的时候,他有一个
chunk_size,这样在处理的时候,就算是内存不够,也可以分批处理数据。 - 很多人可能也都是搞过pytorch、tensorflow训练nlp、cv模型。加载数据的时候,也都是一个batch进去,然后不断的迭代更新。
其实有的时候,我们也需要把列表切开,最常见的就是把一段长的list文本,按照指定的大小,分段,然后放到模型里面,进行encoding。在以前,可能就是会这么写:
liststr = [f'text_{i}' for i in range(11)]
batch_size = 3
[liststr[i:(i+batch_size)] for i in range(0,len(liststr),batch_size)] #1
#> [['text_0', 'text_1', 'text_2'],
#> ['text_3', 'text_4', 'text_5'],
#> ['text_6', 'text_7', 'text_8'],
#> ['text_9', 'text_10']]
#1这段代码其实是很巧妙的,我怀疑大部分人都不知道可以这么用。- 但是
#1这段代码,也太长了。不瞒你说,我刚开始也都不会写,写了几次之后,搞懂其中的原理之后,倒是很懂了。 - 但是就算是你很熟练,代码写的长,也有很大概率出错。
那么接下来分享一个非常简单的函数,使用这个函数,就可以达到相同的目的。
from more_itertools import chunked
liststr = [f'text_{i}' for i in range(11)]
list(chunked(liststr, 3))
#> [['text_0', 'text_1', 'text_2'],
#> ['text_3', 'text_4', 'text_5'],
#> ['text_6', 'text_7', 'text_8'],
#> ['text_9', 'text_10']]
注意,这里只是分享一下思路,我并不希望你以后都只是用chunked,而不再用上面那个比较长的写法。
更多
- 我在做排列组合的时候,我会使用
itertools包的product函数、permutations函数、combinations函数。相对于的,numpy里面有np.meshgrid。 - 我之前在做列表展开的时候,我会使用
itertools包的chain函数。
这些函数,我觉得都可以试一试,以至于more_itertools包的官网上的函数,也可以看看。
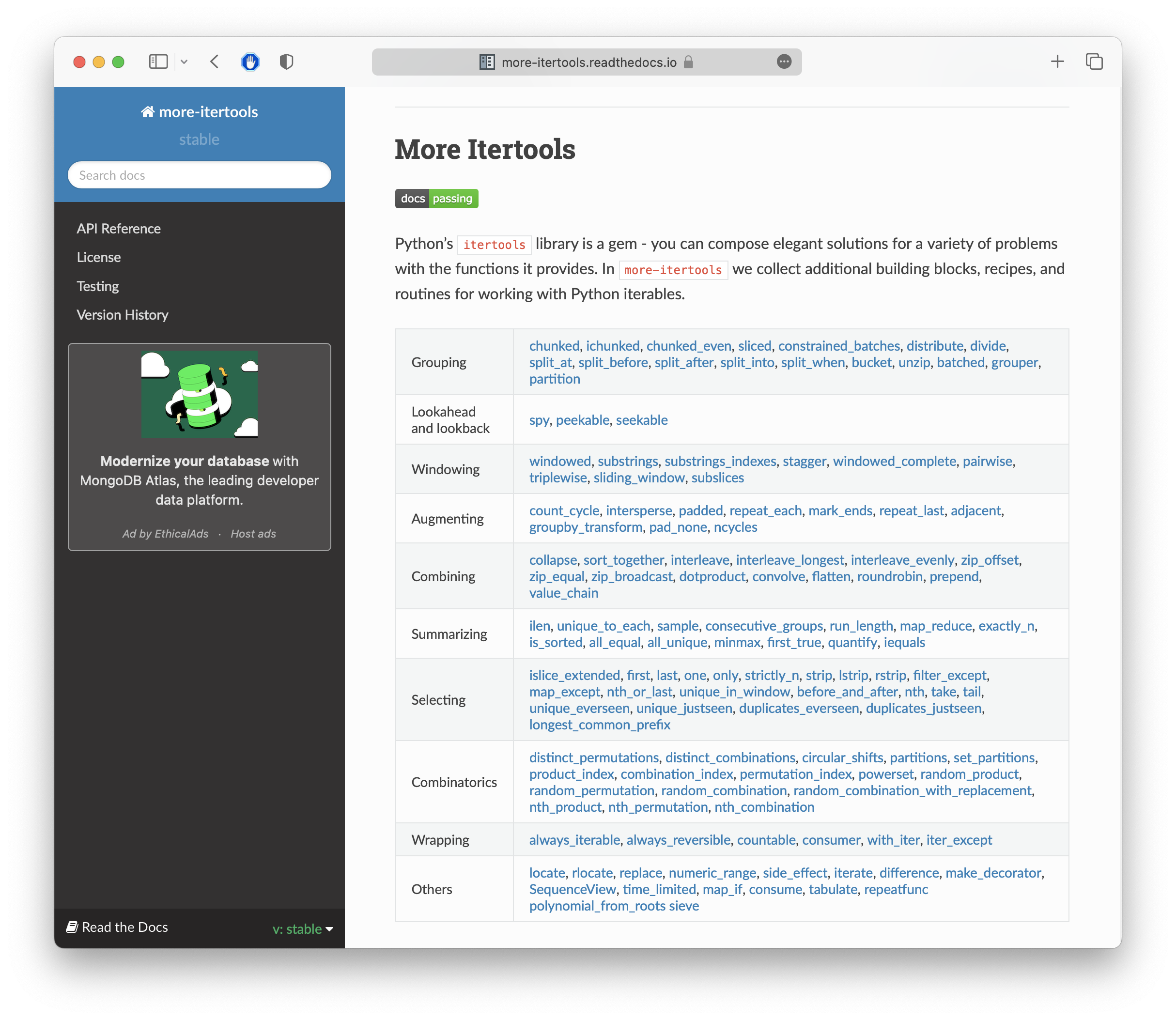
这里给出若干条我觉得比较好的参考链接。有兴趣完全可以探索一下:
- https://more-itertools.readthedocs.io/en/stable/
- https://www.gidware.com/real-world-more-itertools/#map_except
- https://docs.python.org/zh-cn/3/library/itertools.html
- https://martinheinz.dev/blog/16
- https://www.bbayles.com/index/decorator_factory
总结
itertools和more_itertolls在python编程里面,一直是扮演一个相当重要的角色。
但是很多人觉得里面的函数太多了,看不过来,也用不过来。以至于一直都是敬而远之。
本文介绍了几个小的知识点。面对同一个问题,有几种不同的解法。
我并不会觉得哪一种代码写法在任何情况下都非常的优雅。
优雅的不是那个代码,优雅的是那些代码蕴含的前人的智慧。
在我们未来写代码的道路上
可能也不会用这两个包
更有可能使用的编程语言也不一定会局限于python
但是从中我们学到的知识
我们掌握的智慧
都将伴随我们一生
在面对一些棘手的问题的时候
可能,就是一个想法就帮助了你,解决了问题
ok
以上就是本文的全部内容了
如果觉得有用
欢迎关注、转发公众号【统计学人】
下期再见