课程视频链接:https://www.bilibili.com/video/BV19x411X7C6?p=1
本笔记参照该视频,笔记顺序做了些调整【个人感觉逻辑顺畅】,并删掉一些不重要的内容
系列笔记目录【持续更新】:https://blog.csdn.net/weixin_42214698/category_11393896.html
文章目录
- 1.因子
- 2.缺失数据【NA代表缺失值,not available的简称,用来存储缺失信息】
- 3.字符串
- 4.时间序列数据(数据类型:ts— time sequence)
1.因子
👷变量分类
- 名义型变量:比如省份
- 有序型变量:如:good、better、best
- 连续型变量:如年龄
在R中名义型变量和有序型变量称为因子(factor)。
这些分类变量的可能值称为一个水平(level),例如good、better、best,都称为一个level。
有这些水平值构成的向量就称为因子。
举个例子,理解因子:
table函数进行频数统计

其中4、6、8就是因子

例子2:
f <- factor(c(“red”,“red”,“green”,“red”,“blue”,“green”,“blue”,“blue”))
week <- factor(c(“Mon”,“Fri”,“Thu”,“Wed”,“Mon”,“Fri”,“Sun”))
week <- factor(c(“Mon”,“Fri”,“Thu”,“Wed”,“Mon”,“Fri”,“Sun”),order = TRUE, levels = c(“Mon”,“Tue”,“Wed”,“Thu”,“Fri”,“Sat”,“Sun”))

cut()函数:划分区间?
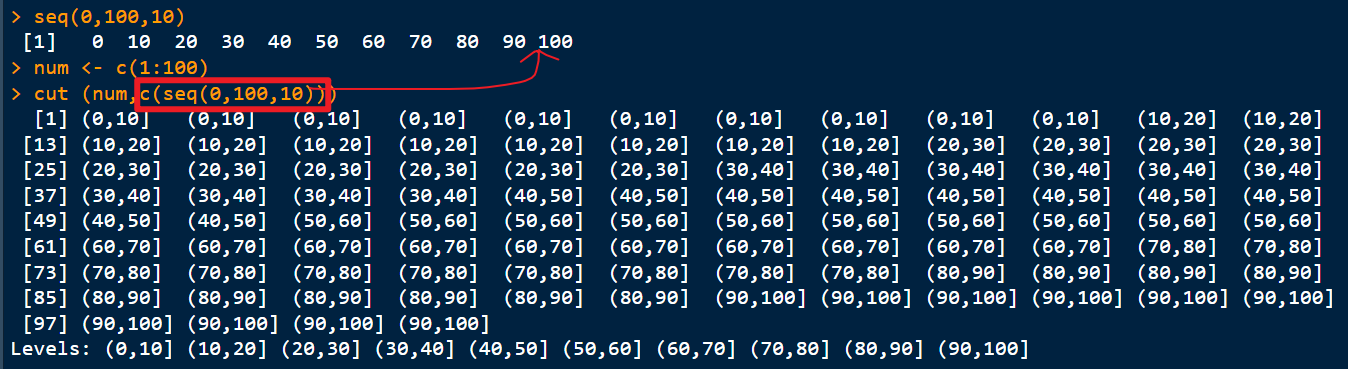
2.缺失数据【NA代表缺失值,not available的简称,用来存储缺失信息】
这里缺失值NA表示没有,但注意没有并不一定就是0,NA是不知道是多少,也能是0,也可能是任何值。
缺失值和值为零是完全不同的。
缺失值会被原封不动的保留和传送,如:
1+NA返回的还是NA
NA==0返回的还是NA
为何出现缺失数据?
- 机器断电,设备故障导致某个测量值发生了丢失;
- 测量根本没有发生,例如在做调查问卷时,有些问题没有回答,或者有些问题是无效的回答等。
跳过NA:
a <- c(NA ,1:49) #共50个数
sum(a , na.rm=TRUE)
mean(a , na.rm=TRUE) #除总数时也跳过计数NA
是否包含NA:
install.packages(“VIM”)
library(VIM)
is.na(sleep) #使用sleep数据集,执行后每一个元素都是TRUE or FALSE
colSums(is.na(sleep)) #统计每列的缺失总数
rowSums(is.na(sleep)) #统计每行的缺失总数
去掉数据集中的缺失值:
c <- c(NA,1:20,NA,NA) #共23个数
d <- na.omit( c )
如果将na.omit函数应用于一个数据框,则会将包含NA的每一整行删除掉。
处理缺失值包:

其他缺失数据:
- 缺失数据NaN,代表不可能的值;
- Inf表示无穷,分为 正无穷lnf 和 负无穷lnf,代表无穷大或者无穷小。
不同缺失值之间的差别:
- NA是存在的值,但是不知道是多少;
- NaN是不存在的;
- Inf存在,是无穷大或者无穷小,但是表示不可能的值。
如:
1/0返回Inf
-1/0返回-lnf
0/0返回NaN
是否是NaN或者无穷数:
is.nan(0/0)
is.infinite(1/0)
3.字符串
在R中字符串出现的地方一定加引号。
正则表达式:
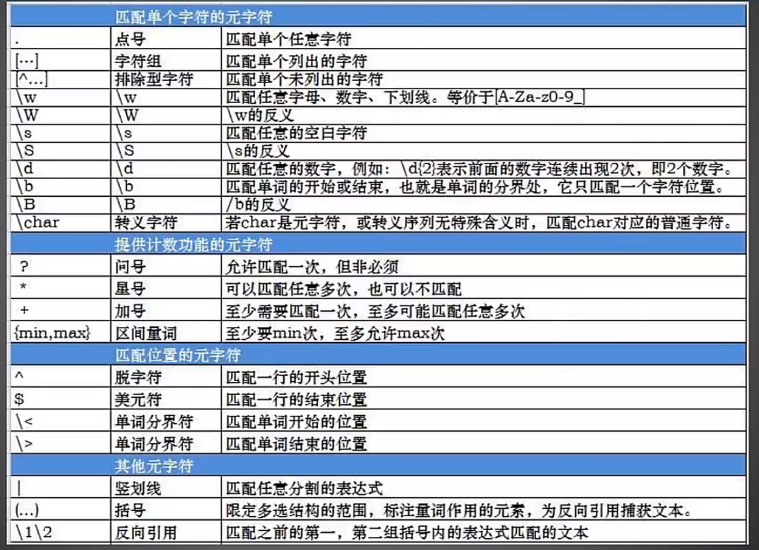
🏠处理字符串的函数:
nchar(“Hello World”):返回字符串长度。
nchar(month.name):返回向量中每个元素字符串的长度。
nchar(c(12,2,345)):测量数值型向量,会将数值型向量转换为字符型向量,返回每个字符串的长度。
length(month.name):返回向量中元素的个数。
paste(“Everybody”,“loves”,“stats”,sep=“-”):连接字符串,以sep进行分隔。
substr(x=month.name,start=1,stop=3):返回起始点和结束点之间的字符串。
toupper(month.name):将字符串转换为大写。
tolower(month.name):将字符串转换为小写。

gsub(“^(\w)”,“\U\1”,tolower(temp),perl=T):将字符串首字母大写。
gsub(“^(\w)”,“\L\1”,tolower(temp),perl=T):将字符串首字母小写。
grep(pattern,x,fixed)函数:对向量中的具有特定条件的元素进行查询,并返回下标。
fixed为FALSE,则搜索模式为正则表达式;为TRUE,则搜索模式为一个文本字符串。
如:
x <- c(“b”,“A+”,“AC”)
grep (“A+”,x,fixed=TRUE) 返回2,表示匹配的是x中的第2个元素。
grep (“A+”,x,fixed=FALSE) 返回2 3,这里的“A+”表示一个正则表达式,匹配的是x中的第2和3个元素。
match( )函数也可以进行字符串匹配,但是不支持正则表达式。
如:
match(“AC”,x):返回3。
strsplit( )函数:分割字符串。返回的是一个字符串列表。
如:
path <- “/user/local/bin/R”
strsplit(path,“/”)
outer( )函数:生成字符串成对组合。
如:
faces <- 1:13
suit <- c(“spades”,“clubs,“hearts”,“diamonds”)
outer(suit,face,FUN=paste,sep=”-")

4.时间序列数据(数据类型:ts— time sequence)
在R中,日期和时间被单独归为一个Date类,它与数字和字符串是不同的。
R中的时间序列数据集:sunspots , persidents

时间序列分析:
- 对时间序列的描述;
- 利用前面的结果进行预测。
Sys.Date():返回当前系统的时间。

字符串转换为Date,如:
a <- “2017-01-01”
as.Date(a) #还是字符串类型
as.Date(a,format=“%Y-%m-%d”)
注意:如果a <- “17-01-01”,则as.Date(a,format=“%y-%m-%d”)
seq( )函数:创建连续的时间点。
如: seq(as.Date(“2017-01-01”),as.Date(“2017-07-05”),by=5)

ts( )函数:生成时间序列。
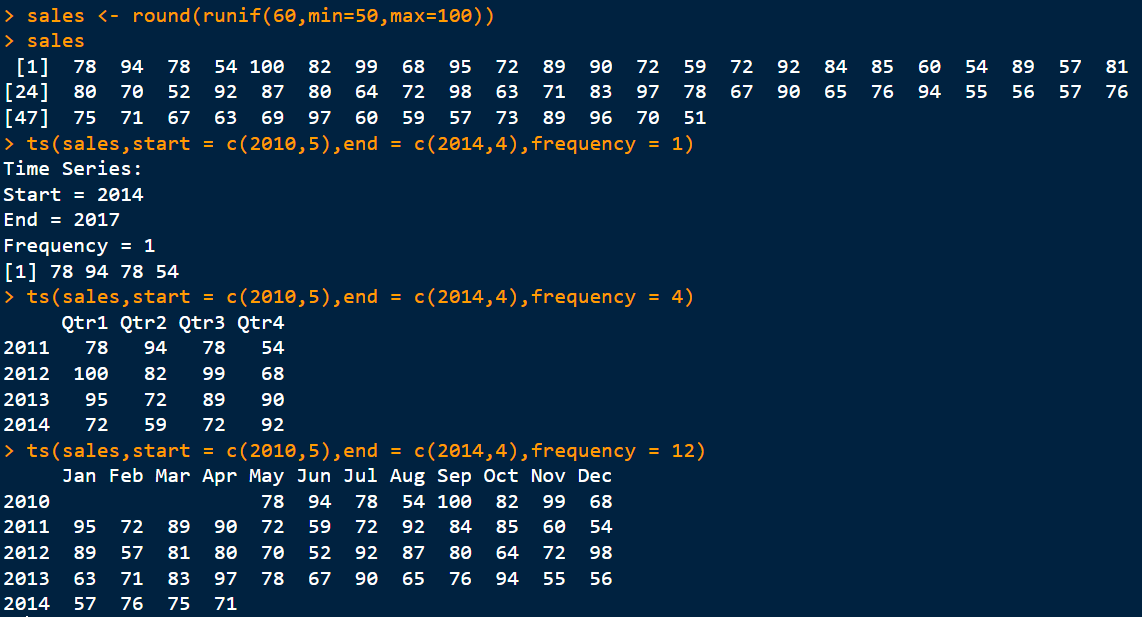
sales <- round(runif(60,min=50,max=100)) # runif( )函数:生成60个50到100之间的随机数 ;round() 函数:取整
ts(sales,start = c(2010,5),end = c(2014,4),frequency = 1)
ts(sales,start = c(2010,5),end = c(2014,4),frequency = 4)
ts(sales,start = c(2010,5),end = c(2014,4),frequency = 12)
#生成的序列数据从2010年5月开始,到2014年4月,frequency为1代表以年为单位、为12代表以月份为单位、为4代表以季度为单位的频率变化。