自注意力机制(常见的神经网络结构)
上节课我们已经讲述过 CNN 卷积神经网络 和 spatial transformer 网络。这次讲述一个其他的常用神经网络自注意力机制神经网络。
对于输入的变量长度不一的时候,采用frame的形式,进行裁剪设计。
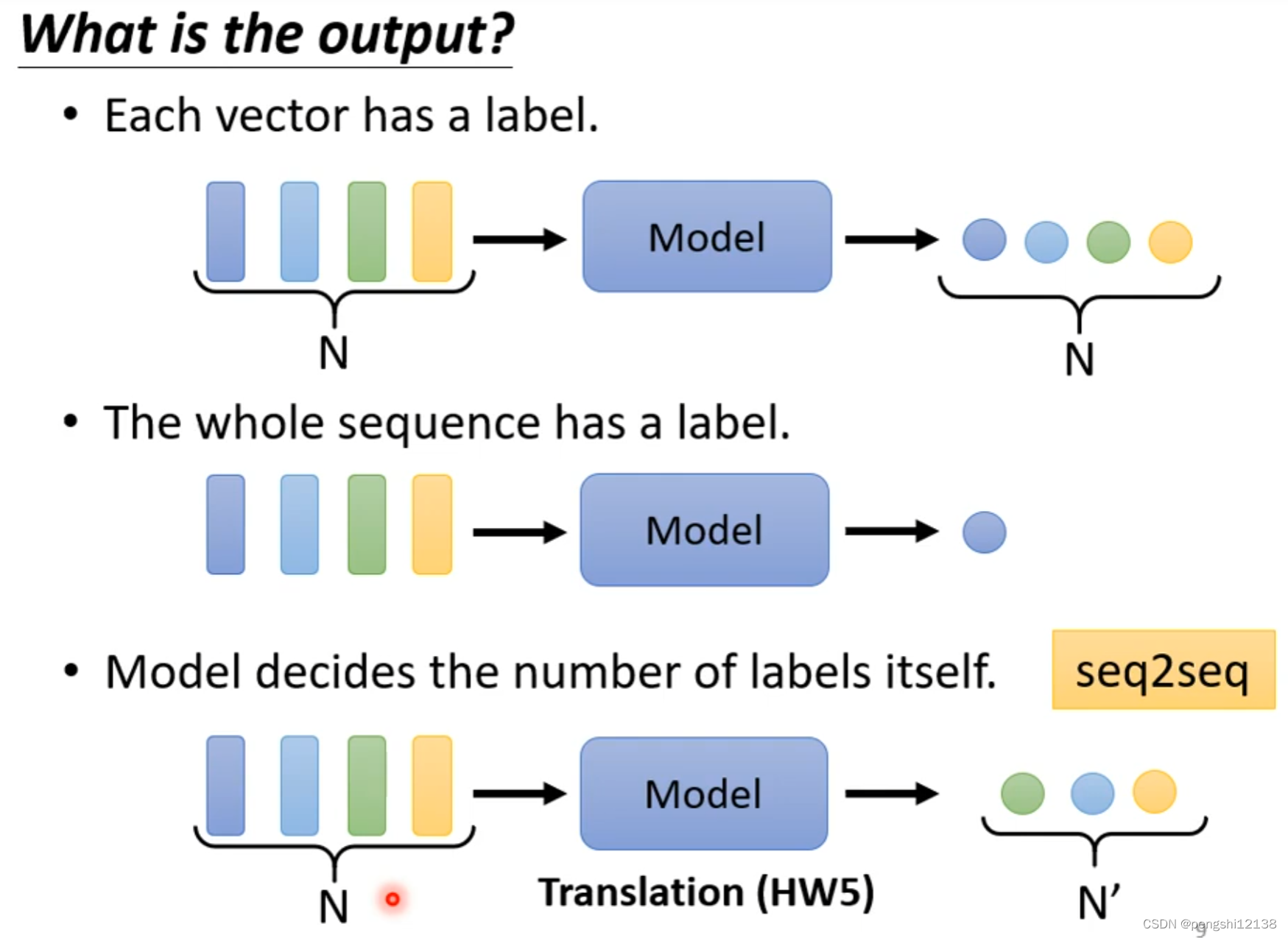
对于模型输入输出,存在几种情况:
(1) n个输入对应n个输出
(2) n个输入对应一个输出
(3) n个输入对应多个输出
对于不定长输入数据的时候,可以进行裁剪变帧进行输入,但是对于模型的训练就是需要查看前后frame的关系,进行结果的关联,如何实现的这个关联,就是使用self-attention机制进行设计。
self-attention作为一个层,进行前后输入数据的关联。其实本质上就是全部关联的过程。
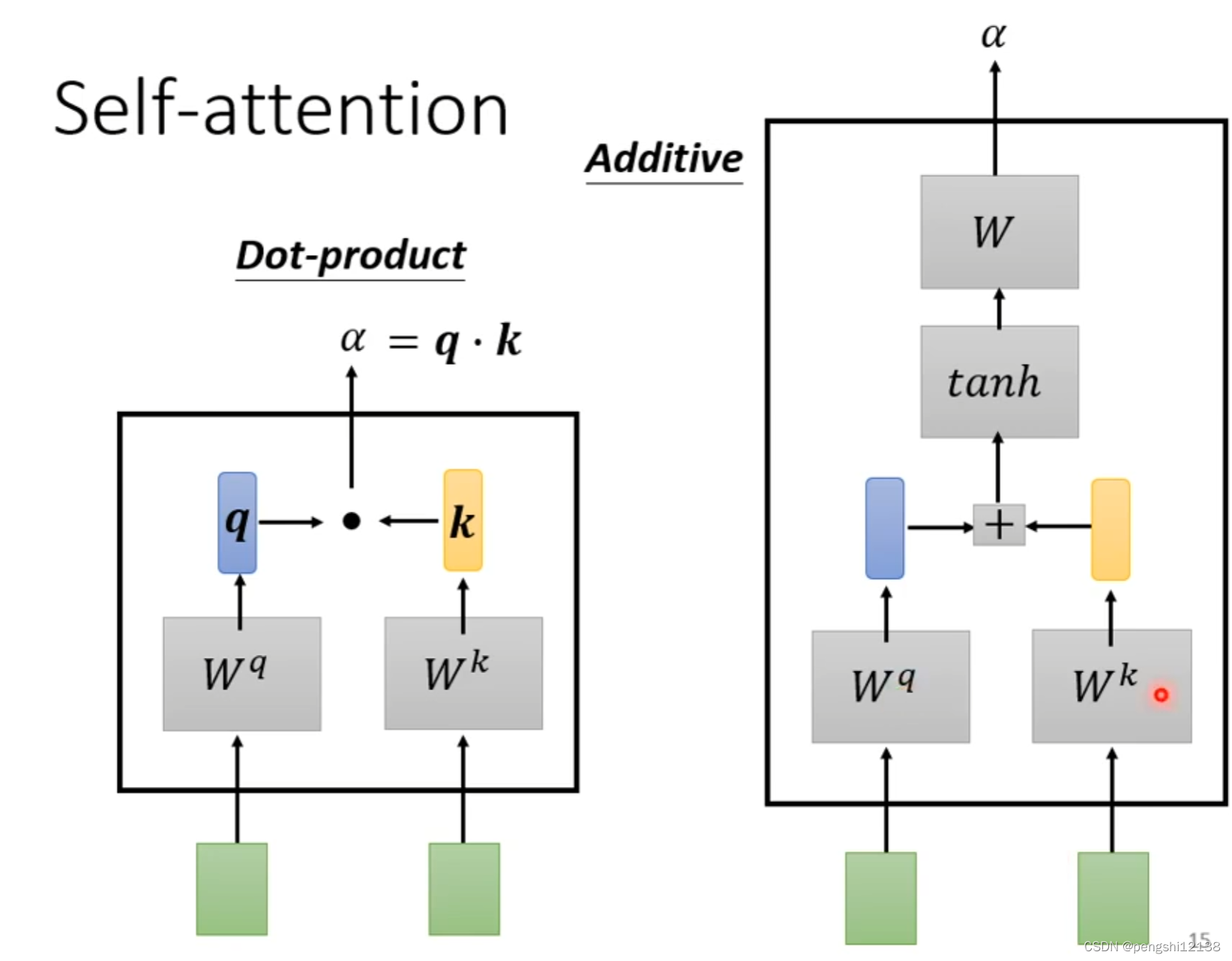
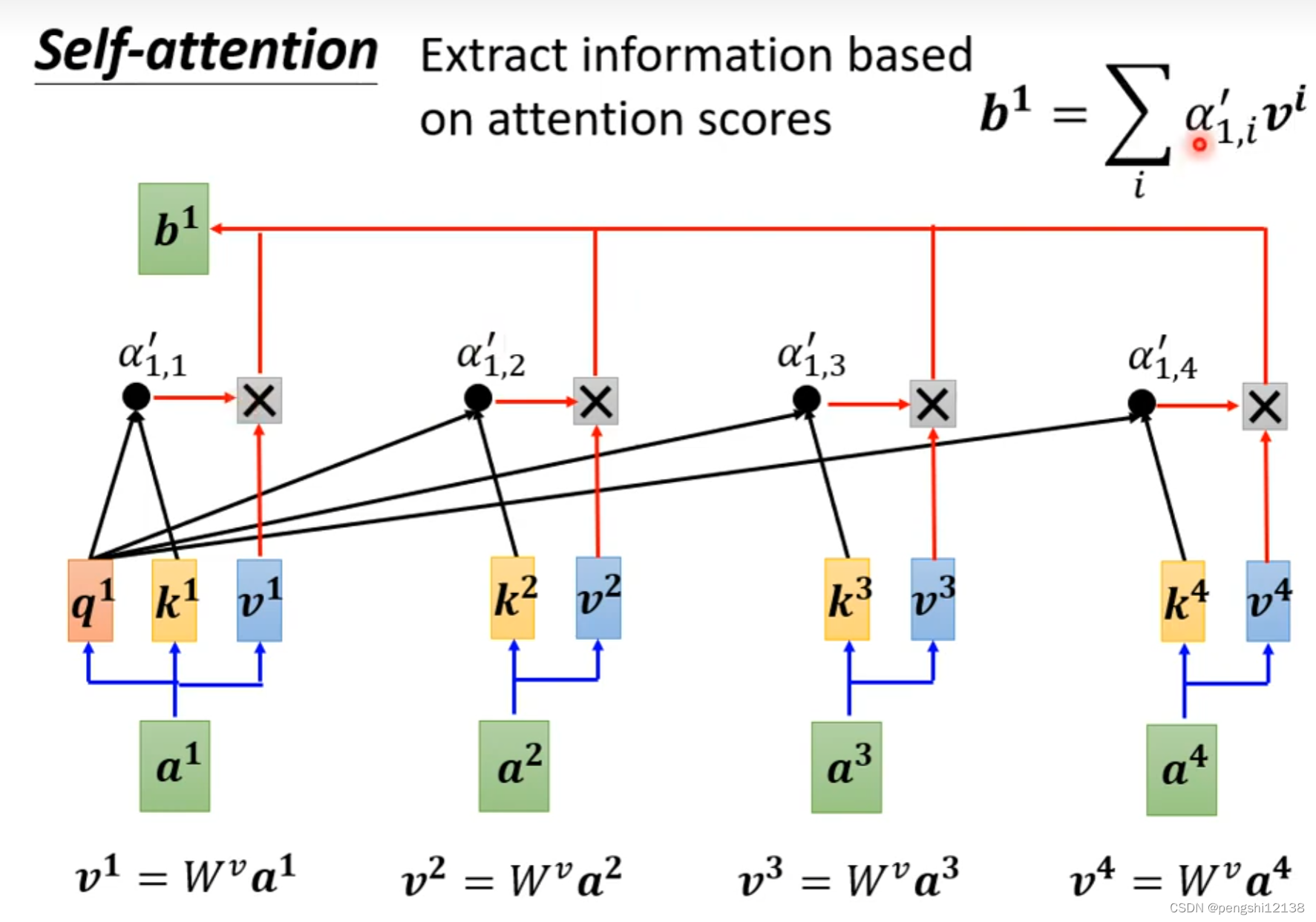
实现self-attention关联程度的两种方式,其中对于输入的每个变量与其它变量的关联程度使用阿法表示,如上图,计算这个程度的方式有两种。
左边的方法也是常用在transformer的方法。而左边的方式计算过程如下:
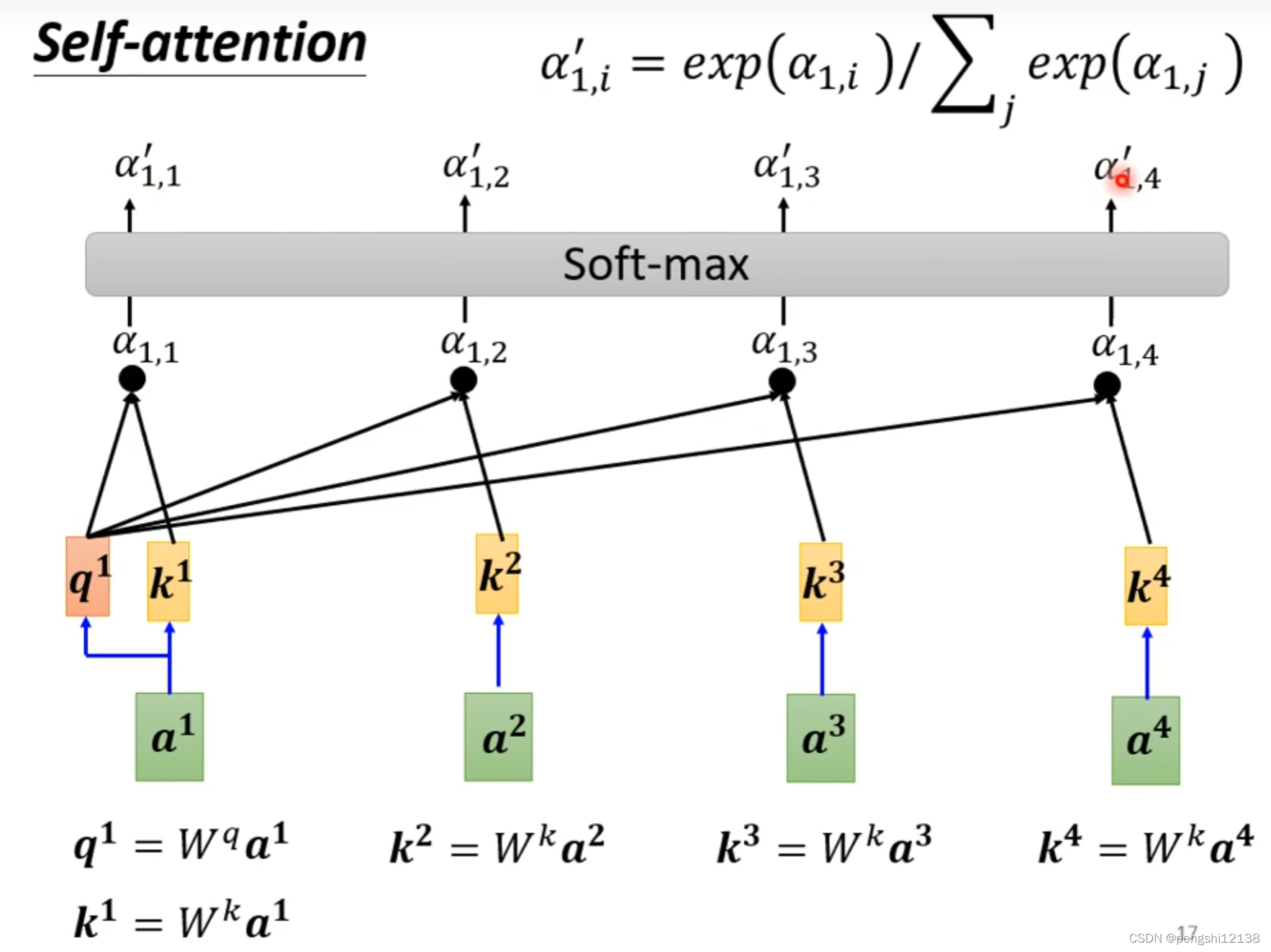
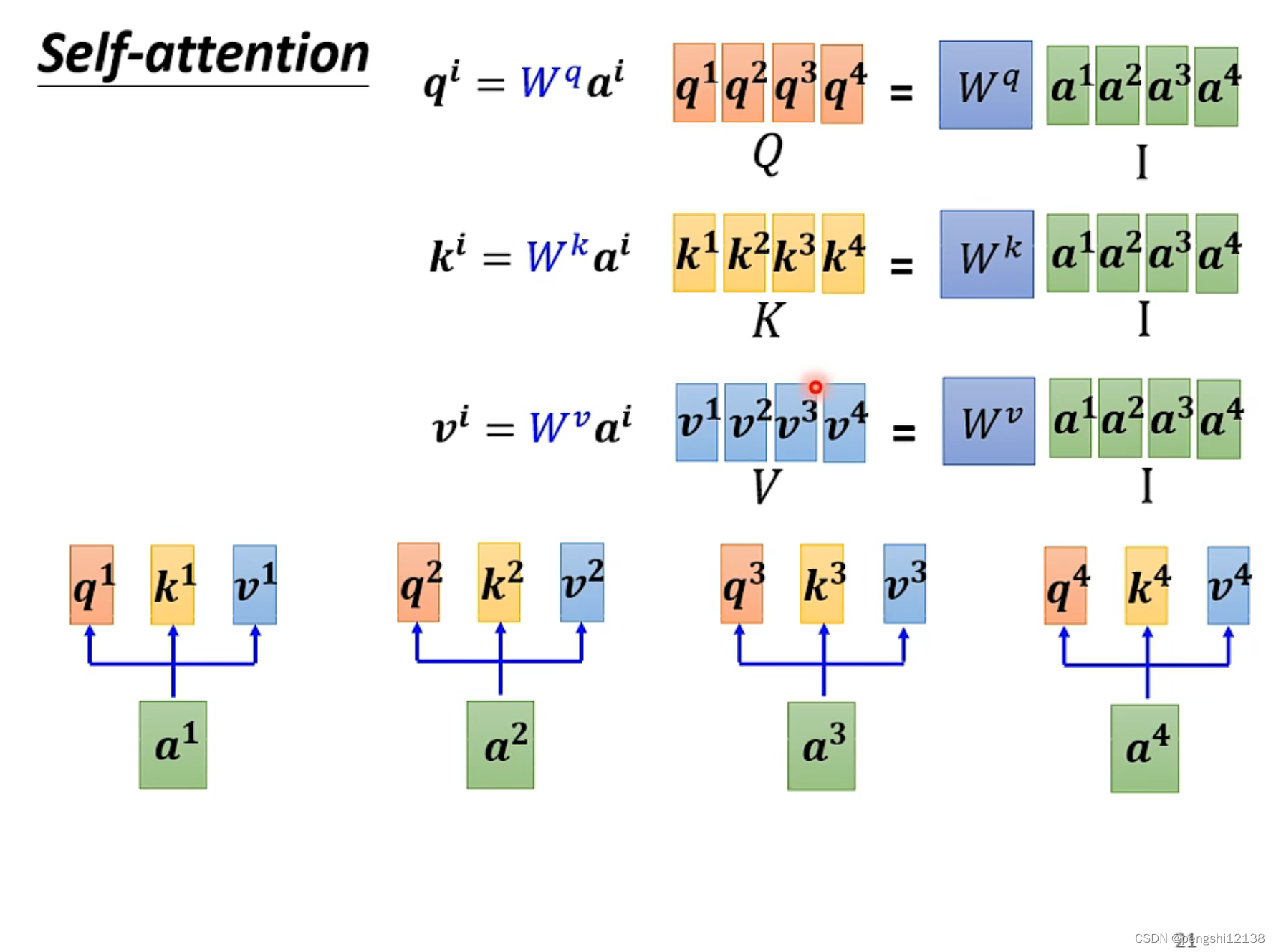
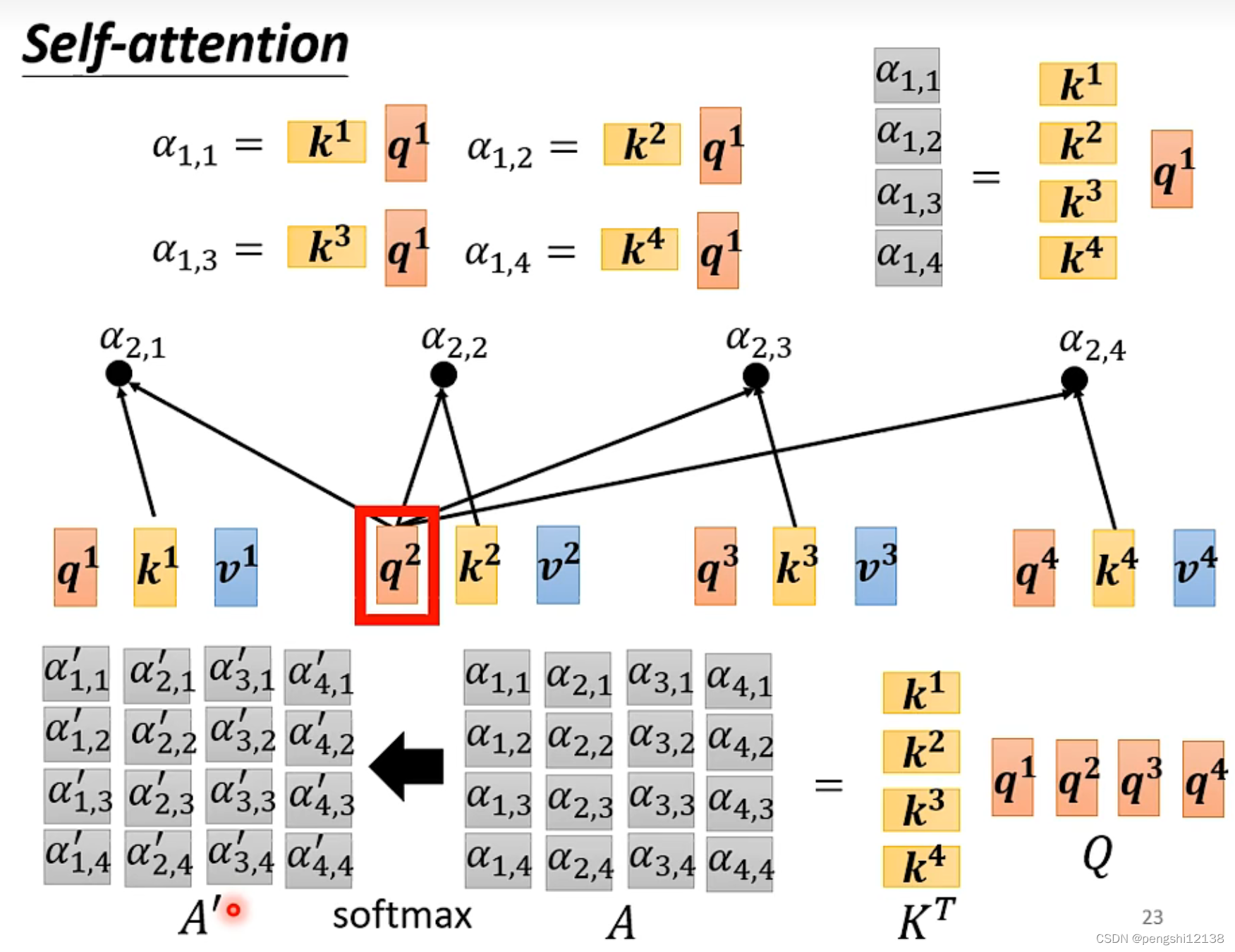
计算出变量的q 然后计算和其他变量的关联性,最后做一个softmax
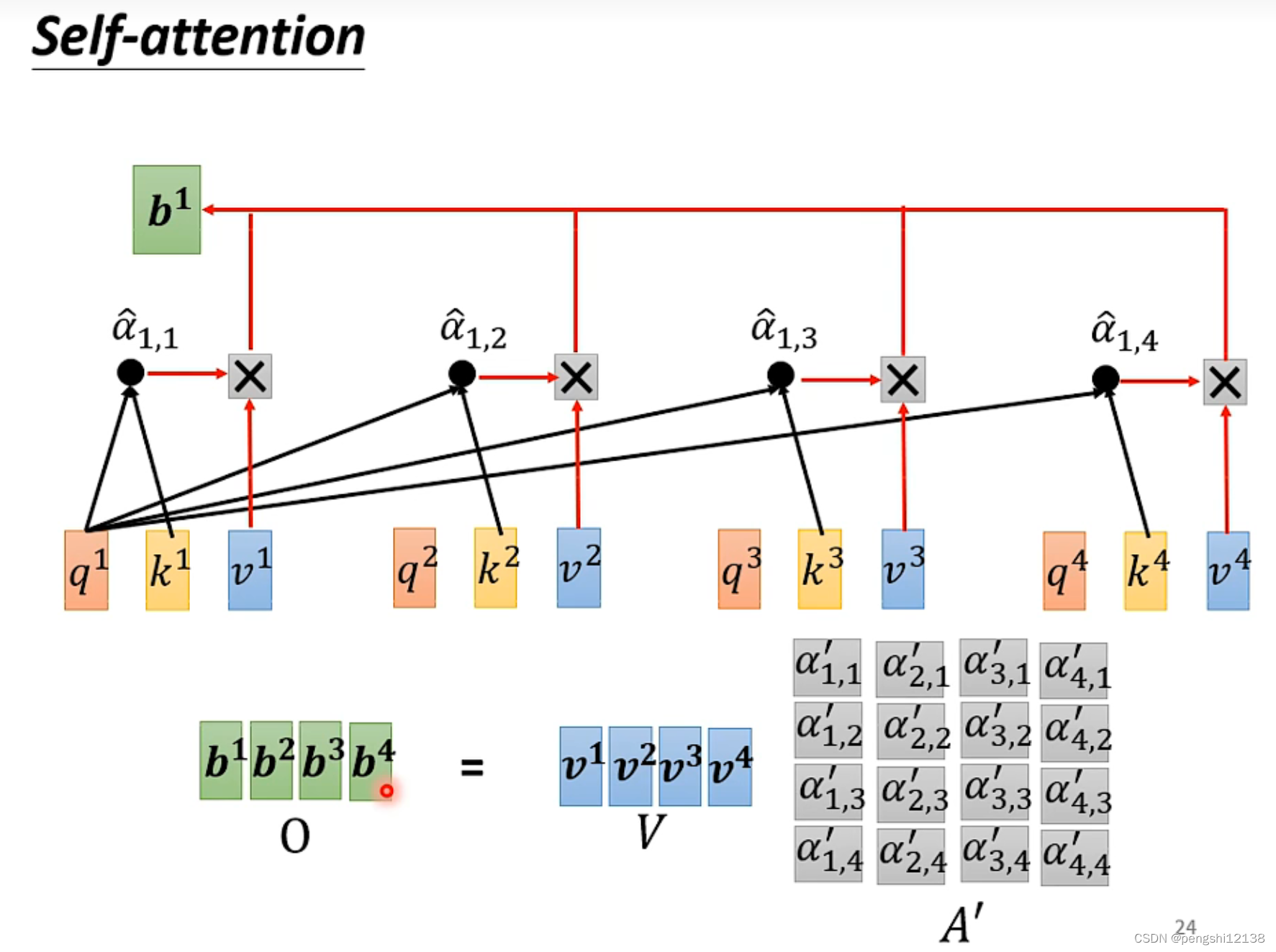
对于计算过程,使用矩阵计算能够更快速的计算
尝试使用多个head的超参数设定,来设计关联程度,计算过程就是多了对应的head参数矩阵计算。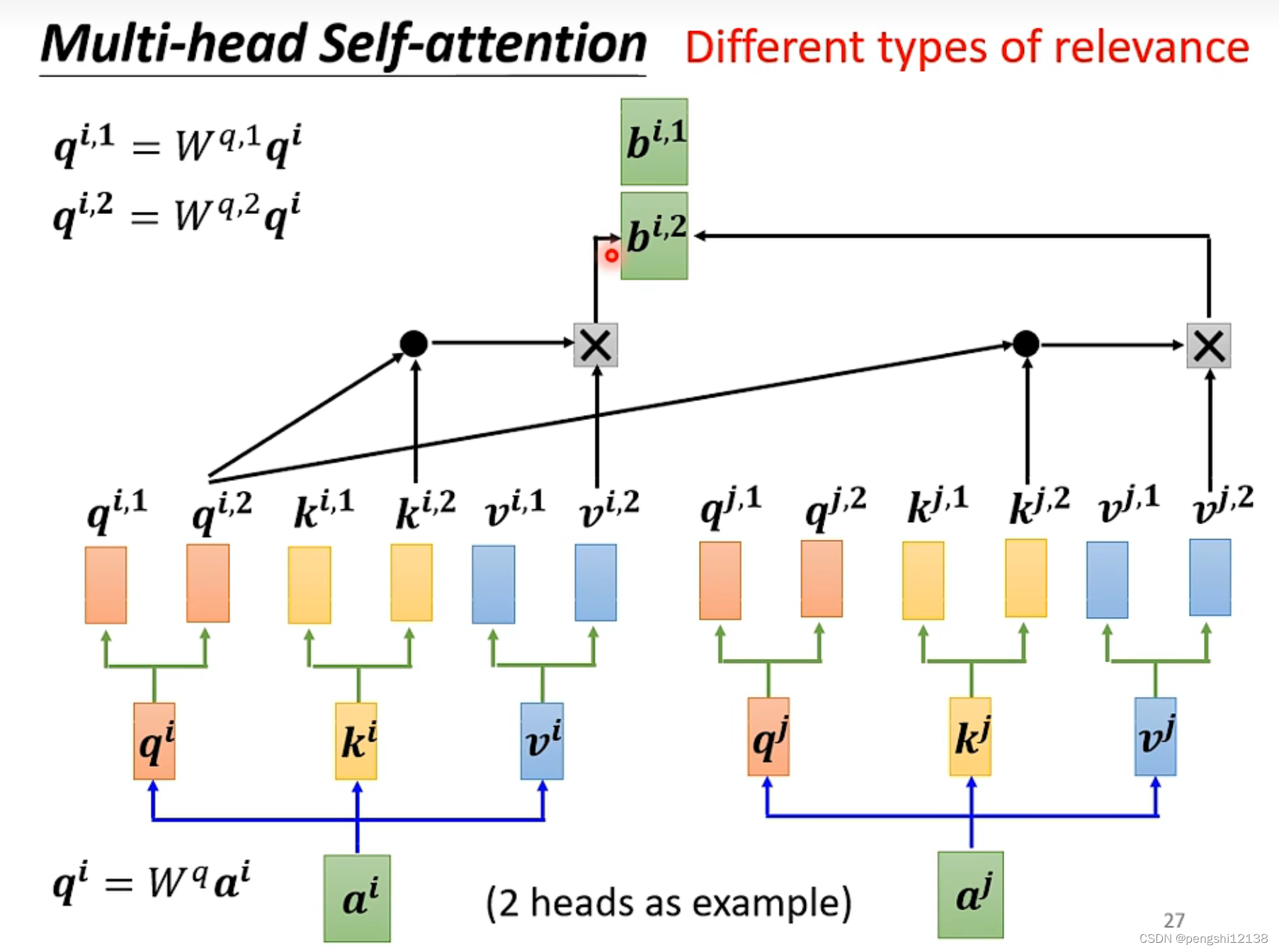
但是对于上面讲述的算法中,没有关于位置信息的加入,假如输入的变量前后是具有关联性的话,就需要使用位置信息编码:
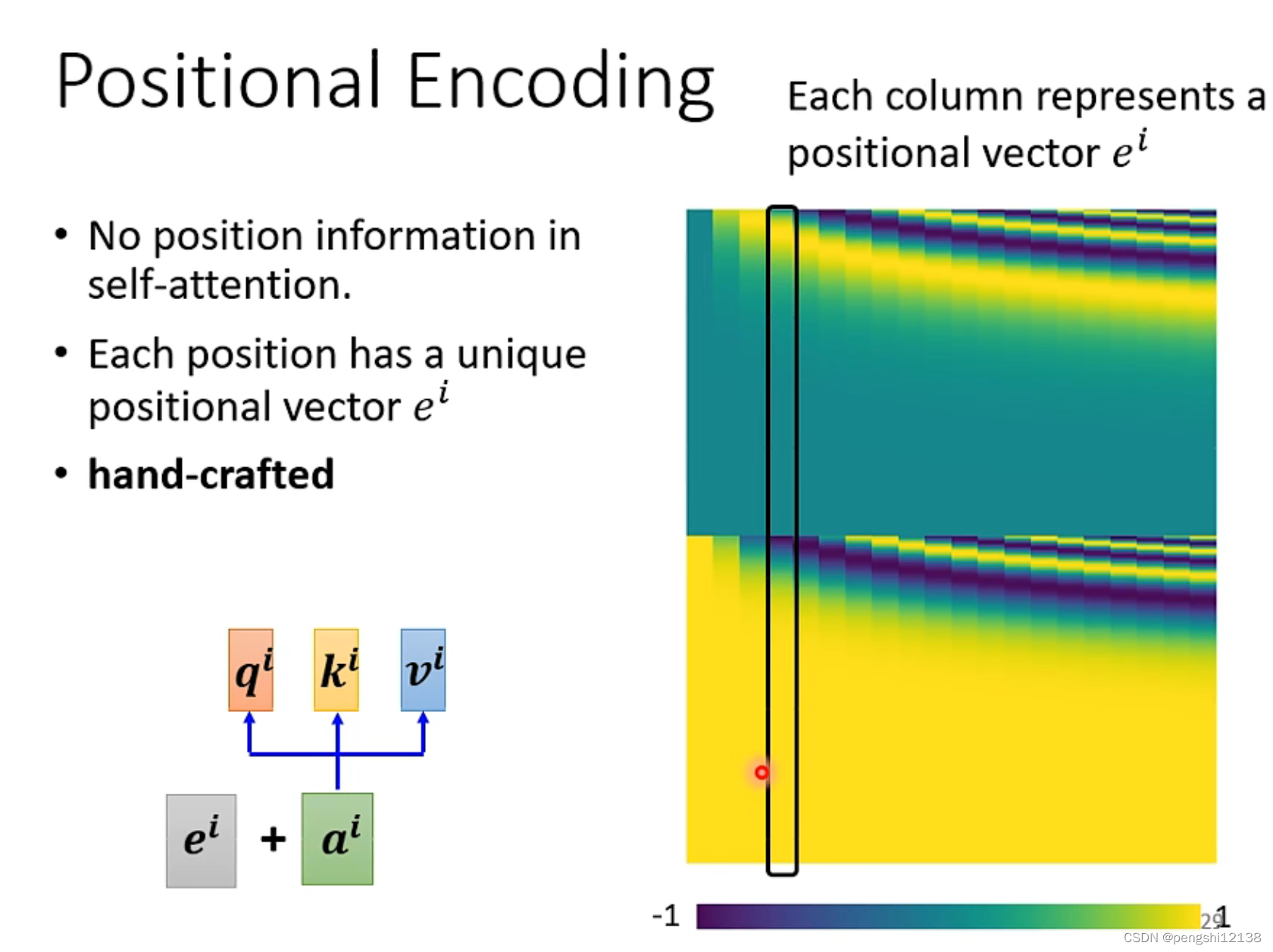
对不同位置都有不同的e,但是是通过人为设定的。
对于长段的输入的时候,可能存在导致attention matrix过大,所以使用小个范围进行设计。
self-attention可以用在语音输入、图片输入。
语音输入对于每个frame进行处理,而对于图片输入,可以进行多通道的关联进行特征提取。
self-attention 和 CNN
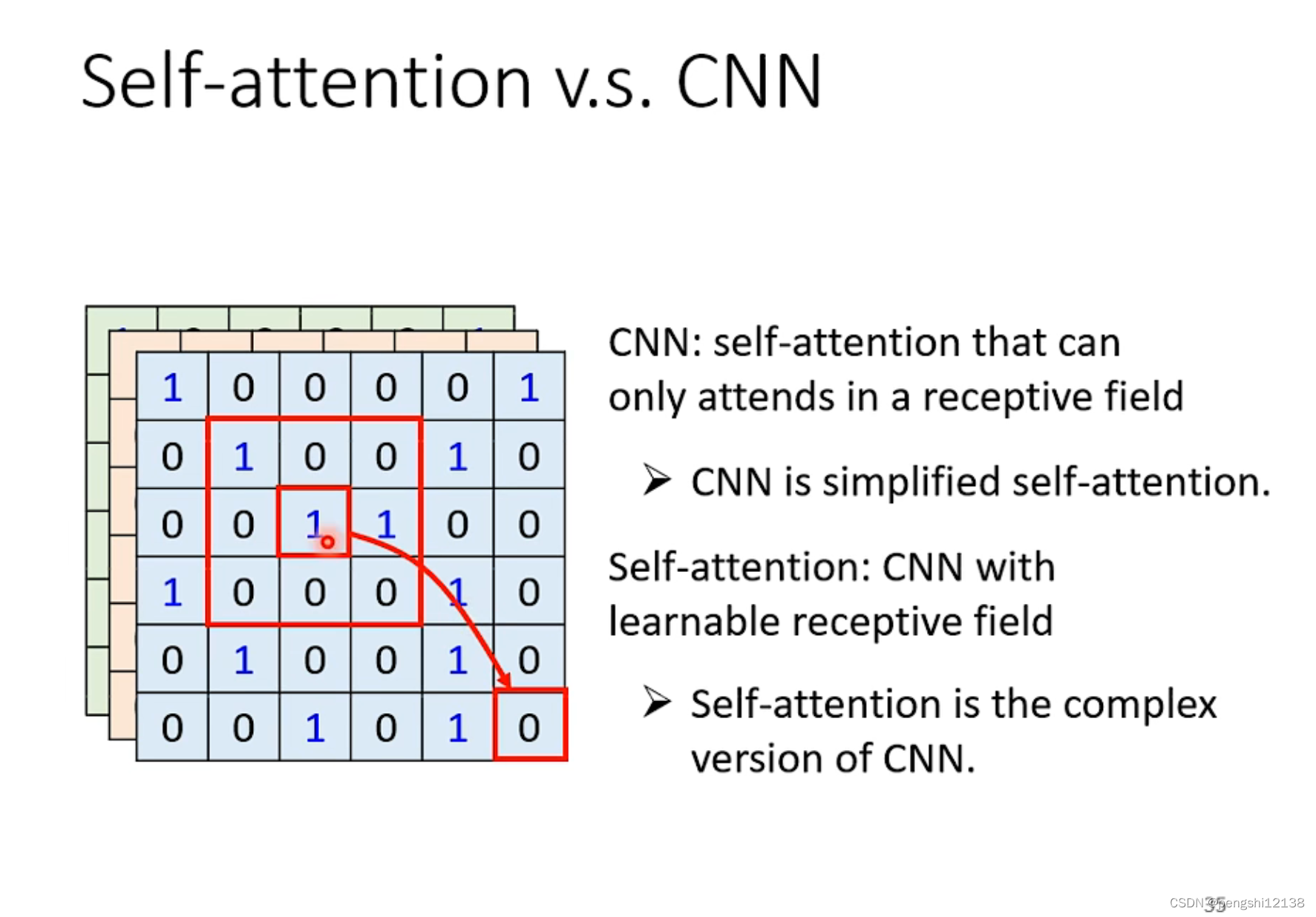
CNN是self-attention的特例,self-attention弹性比较大,对于数据量较大的时候训练效果会更好。
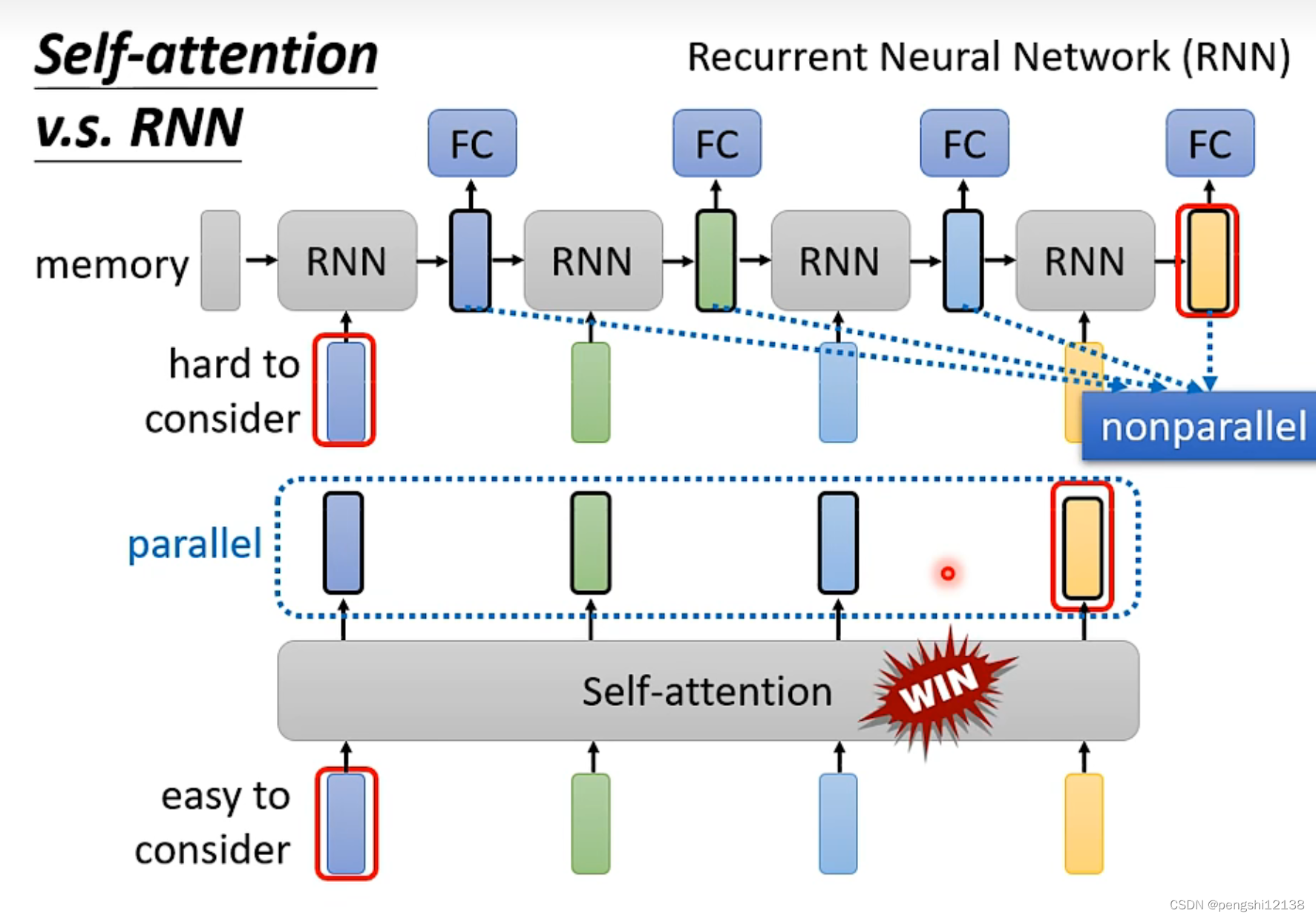
self-attention 和 RNN
对于RNN的缺点就是从左到右进行逐步分析,不想self-attention进行平行计算。
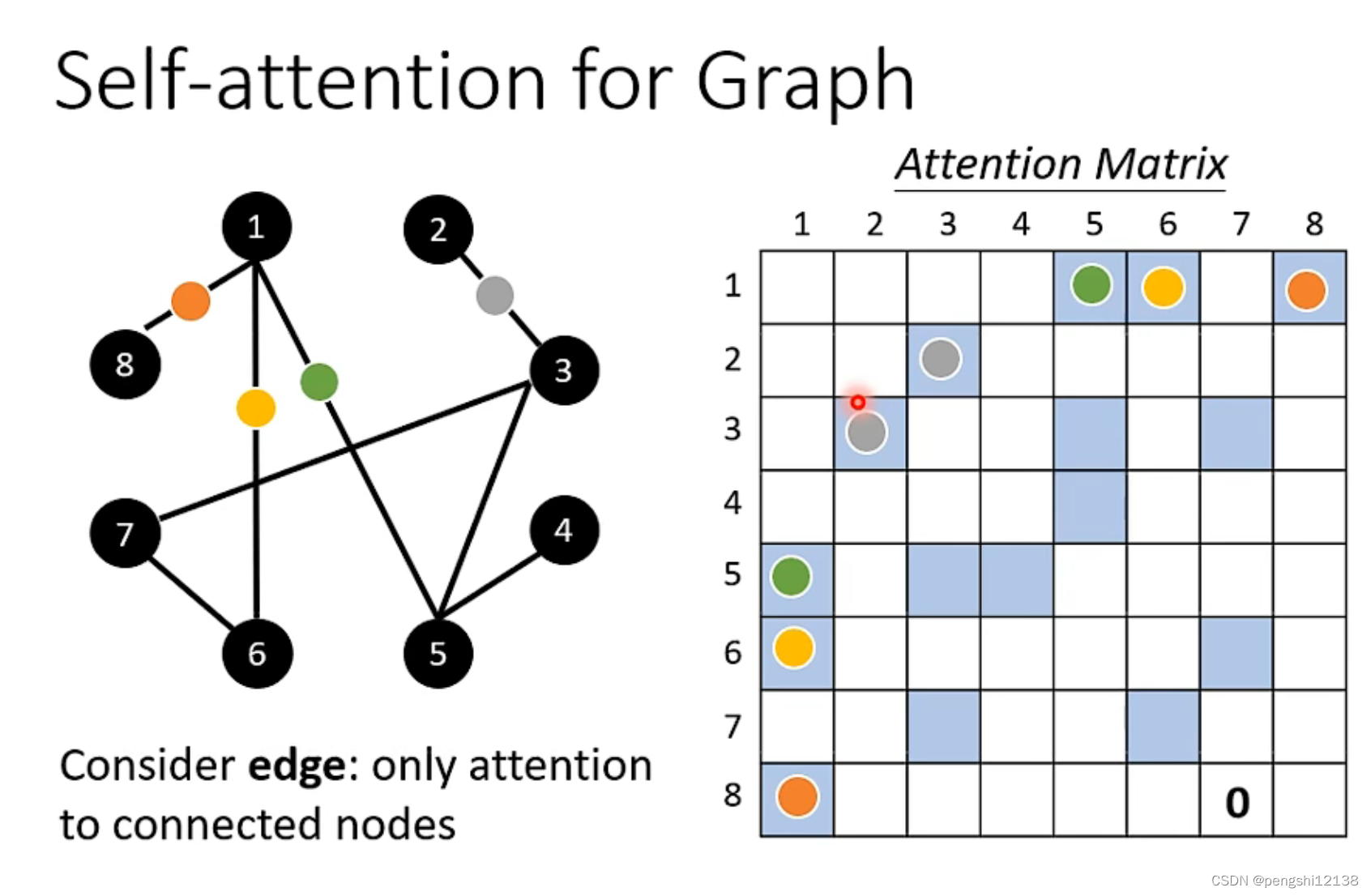
self-attention for graph
对于图的计算使用self-attention,就是一种的GNN,对于图中点与点的关系,类似于数据结构上的图的关系,进行矩阵表示,表示对应的权重。
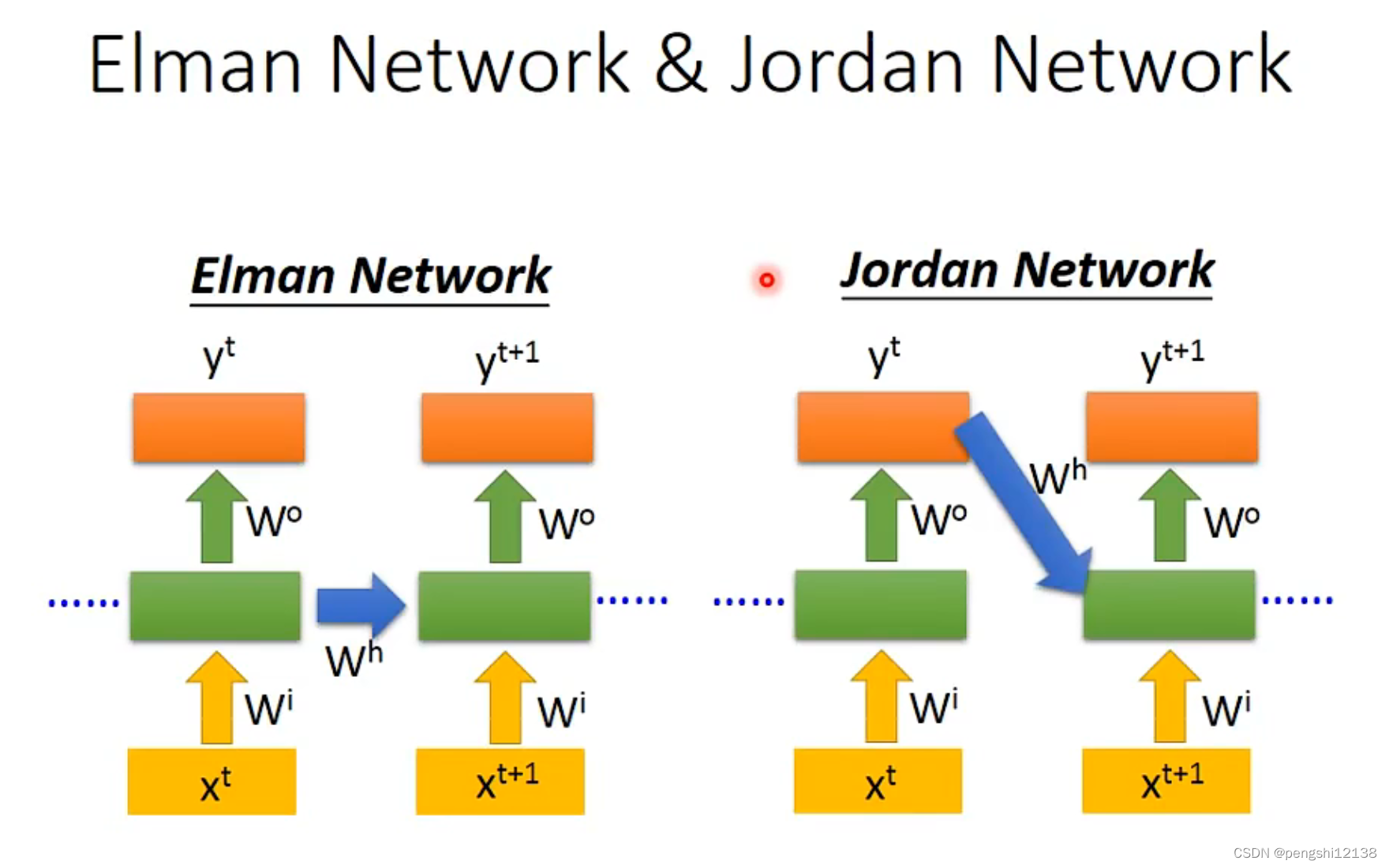
Recurrent Neural Network(RNN)
对于网络存在记忆能力,所以需要额外的空间记录信息,因为在使用过程中,我们遇到很多时候都有顺承关系的输入。
对于RNN的输入会考虑输入变量的顺序。
对于RNN存在两种方式,一种是下面左边的存储每一层的输出值,另一种是像右边存储整个网络的最终输出值。
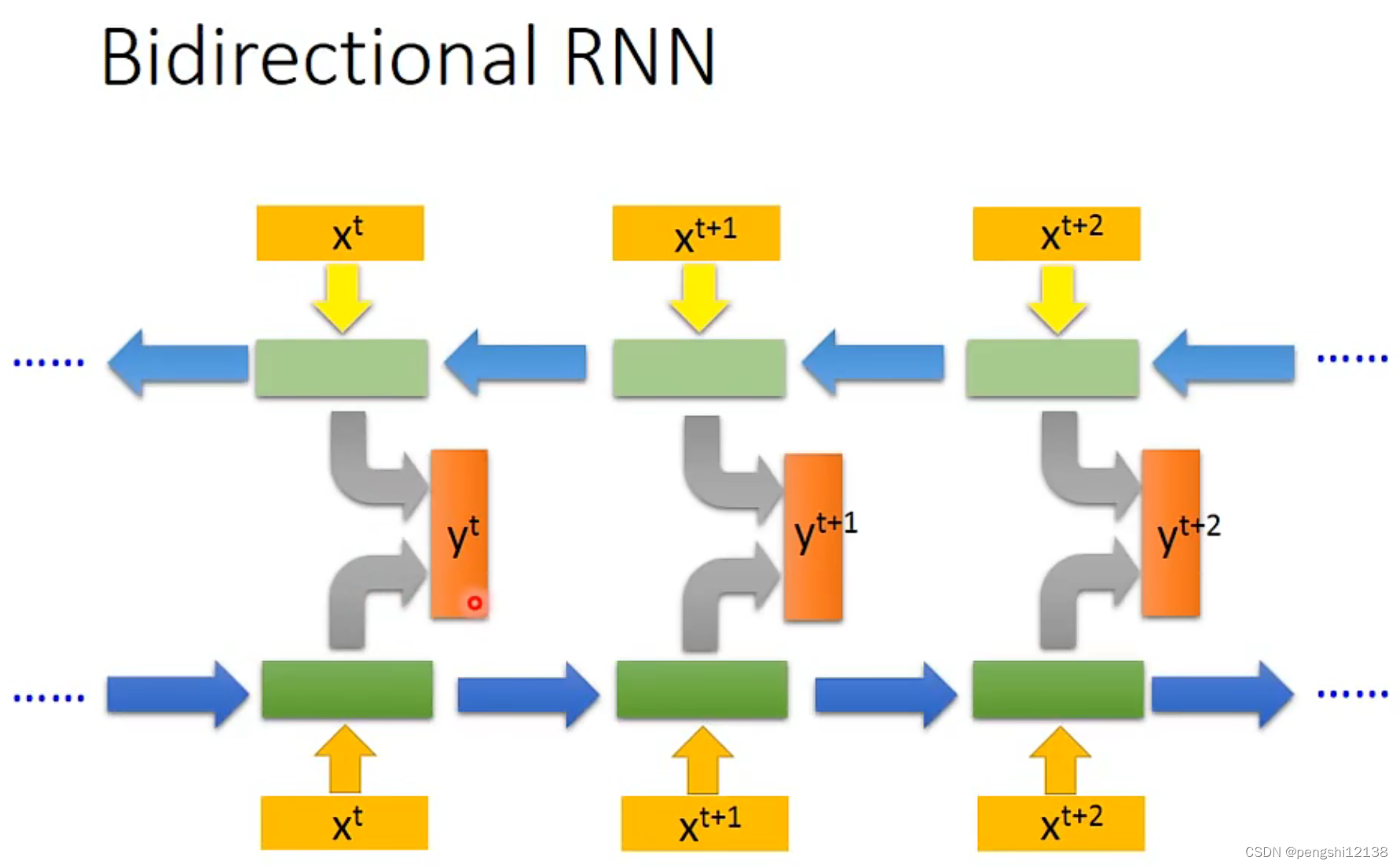
可以训练正向和反向的RNN。
Long Short-term Memory(LSTM)
存在三个gate。进行存储,全部都是自己训练得出判断gate。
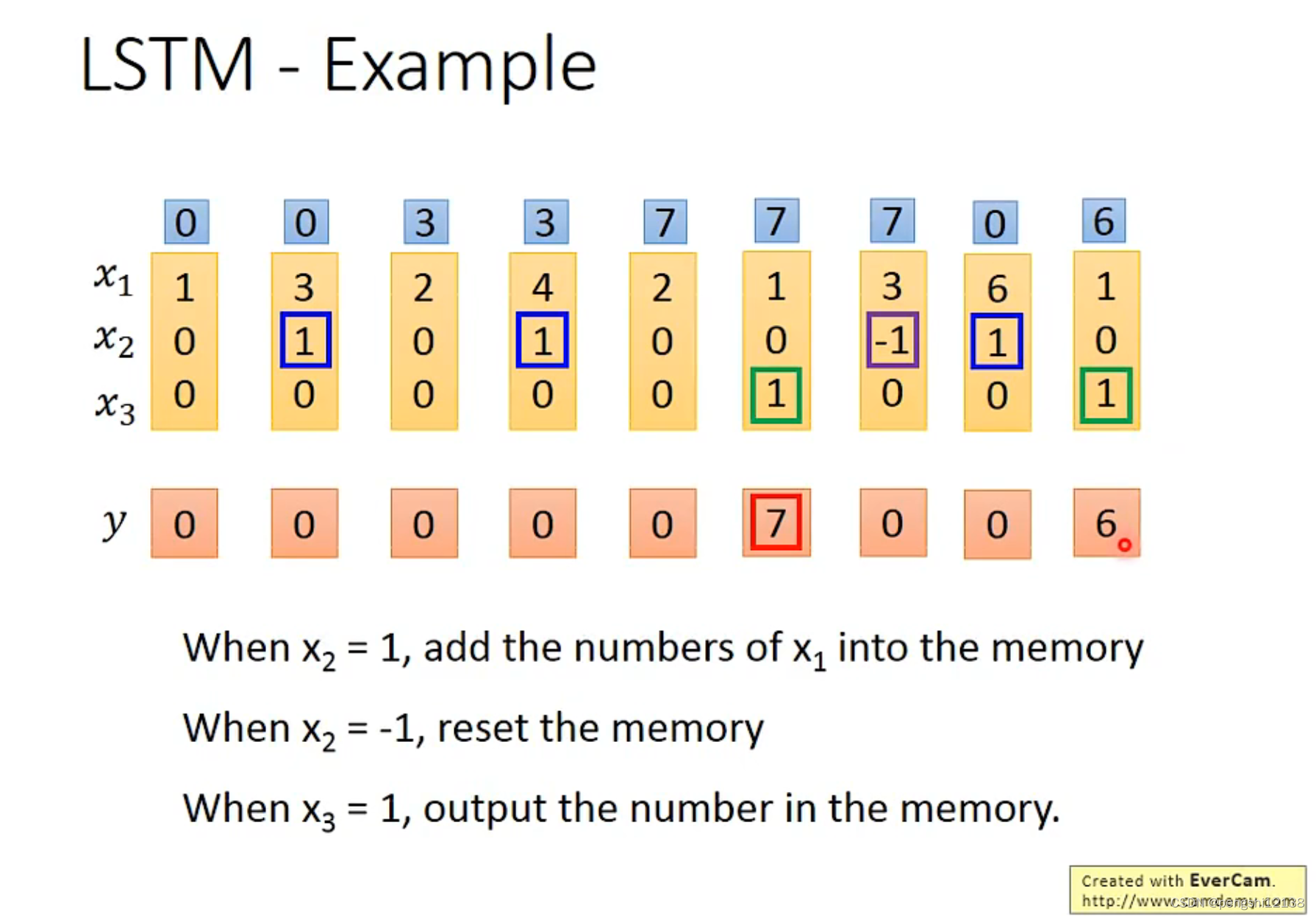
RNN因为每次新的input都会把memory洗掉,而下面的结构能够较长时间的保存短期的数据。
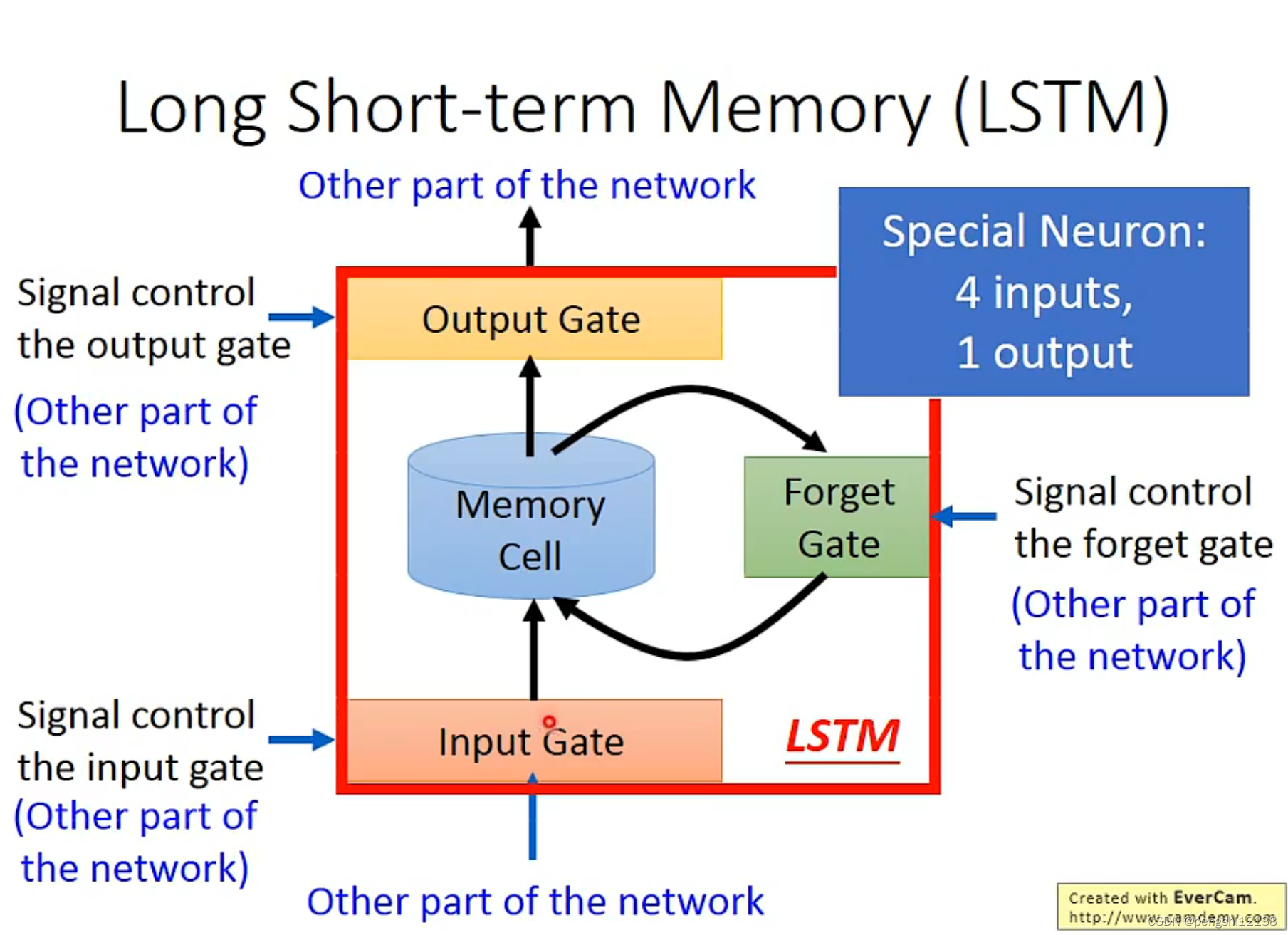
对于LSTM模型如下,就是通过sigmoid进行判断,是否要进行计算、输出等操作。
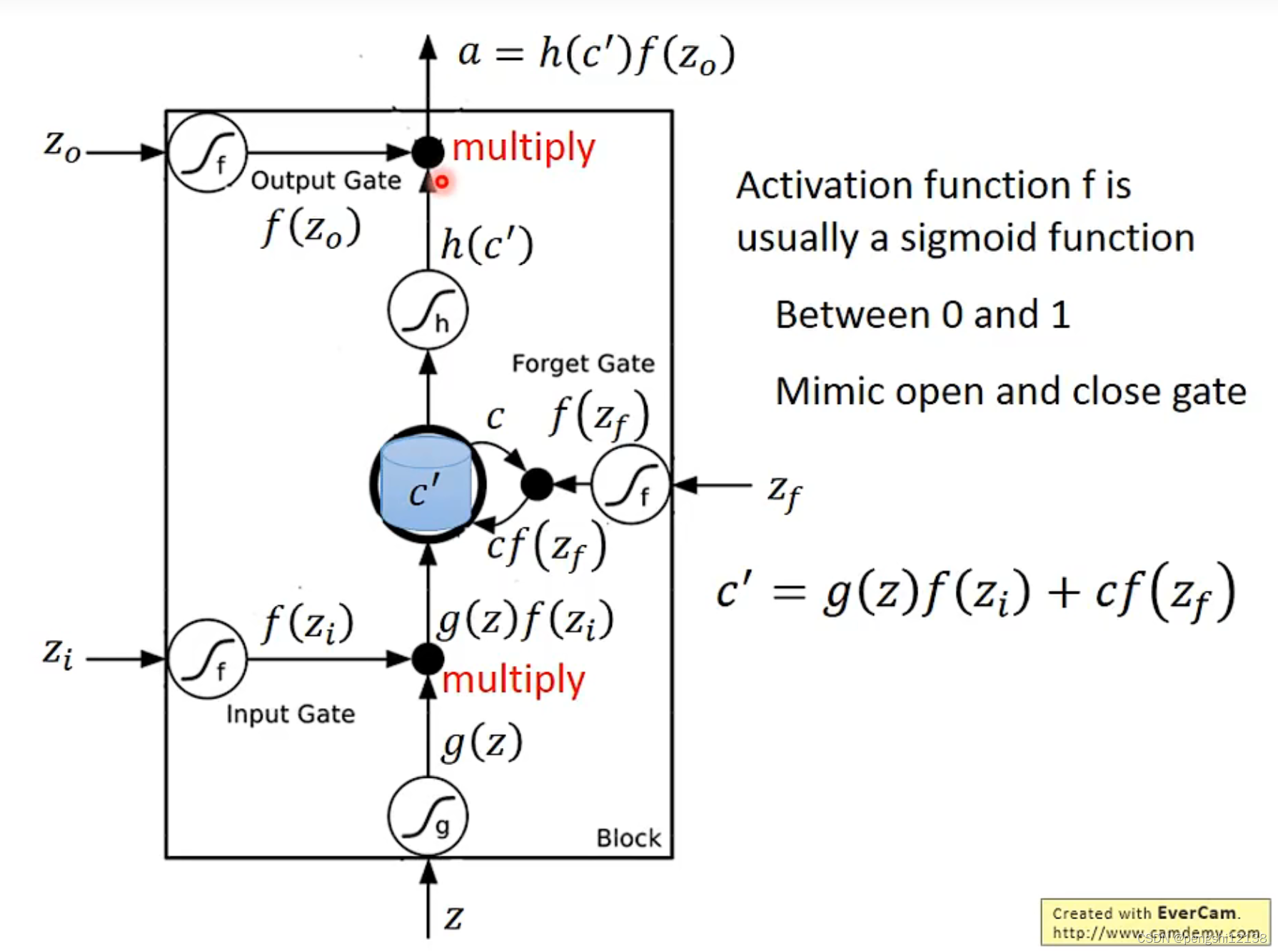
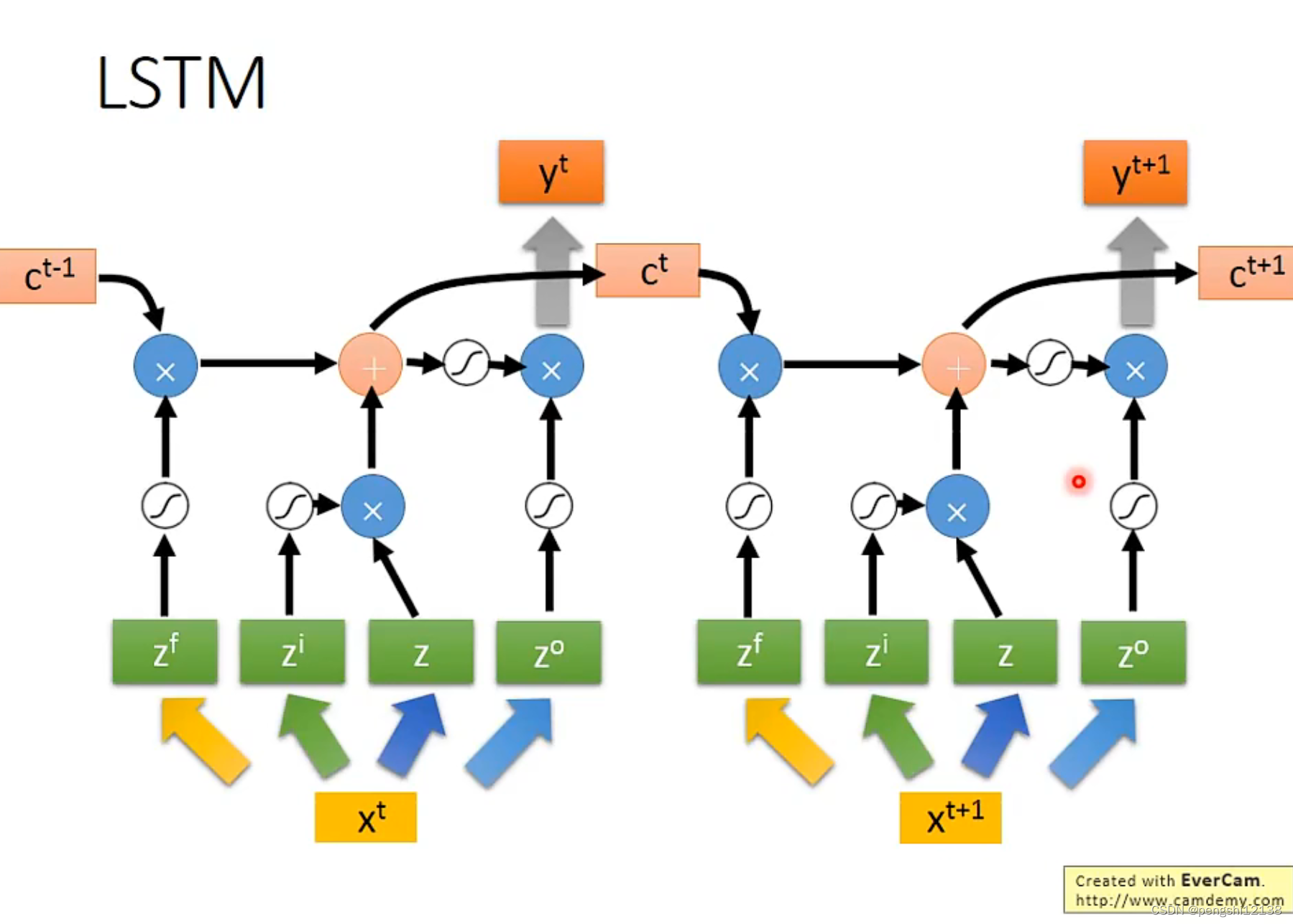
对于LSTM运行如下,将输入input形成对应的四个gate的输入的矩阵,再进行判断使用,同时c矩阵表示是记忆cell进行存储信息。
对于更加复杂的LSTM,也就是最终形态,使用的是需要查看上一个c矩阵进行判断,也就是peephole,同时还需要加上上一个输出的值综合考虑。
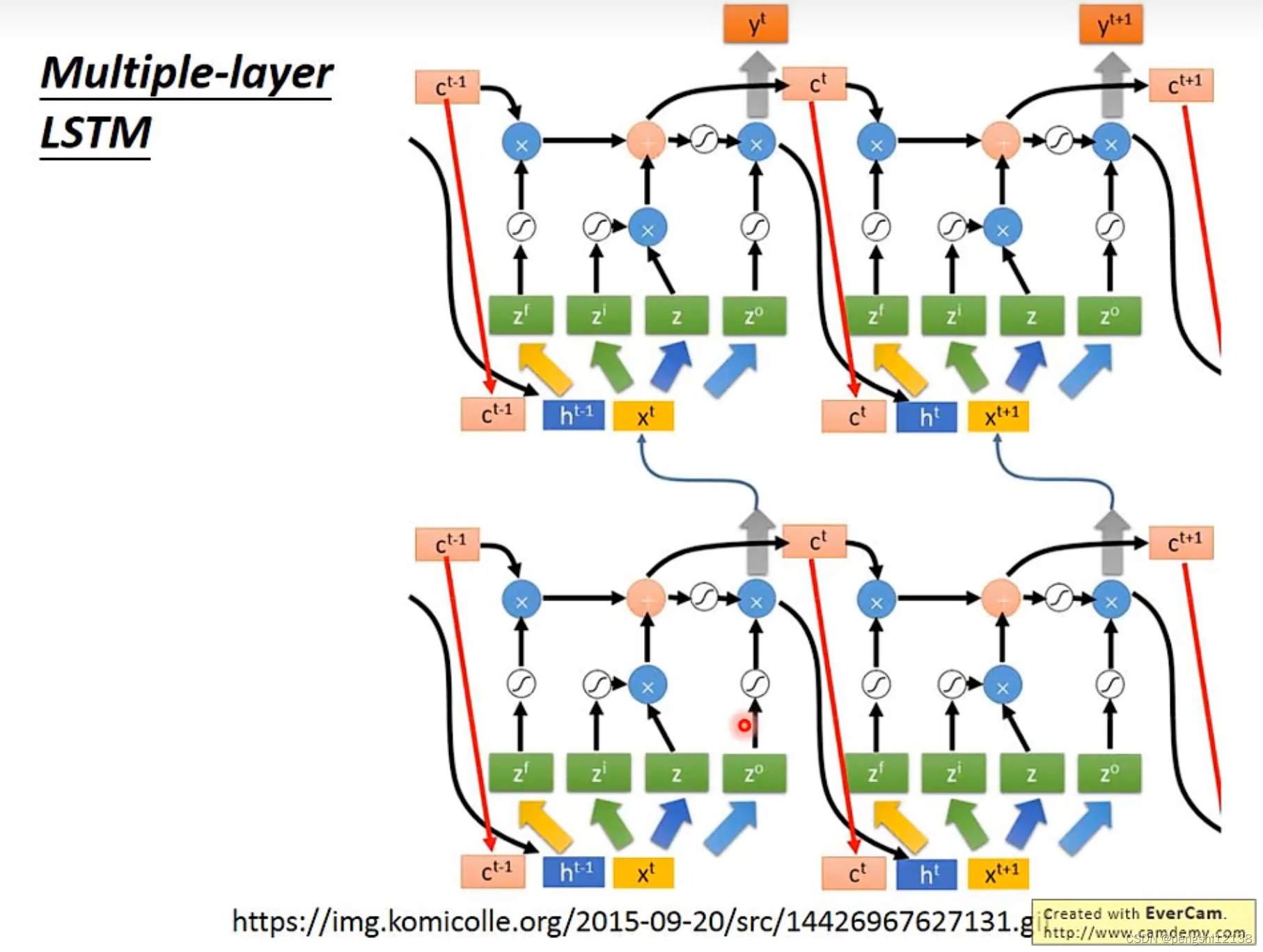
目前常用的RNN就是使用LSTM,而对于keras直接使用就可以了。
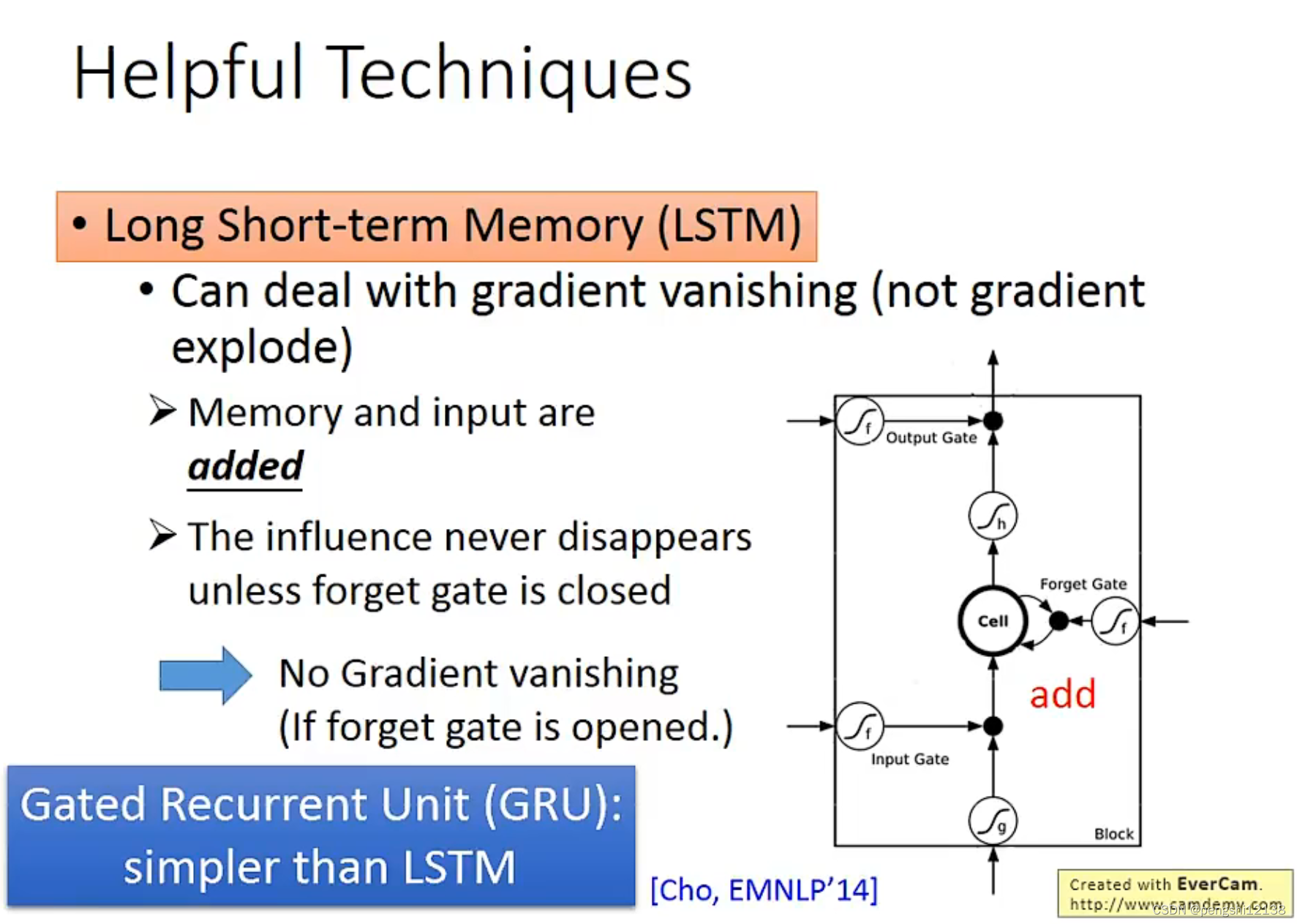
对于RNN的训练是比较困难的,可能会出现梯度爆炸的问题,但是解决这个问题的方式就是LSTM,解决梯度消失和梯度爆炸问题。主要是因为对于memory和输入的操作是相加操作,对于这个memory的影响不会消失直到forget gate打开,可以适当的消除memory。
语音辨识关于RNN
对于语音输入的过程,使用RNN进行关联前后关系进行整体识别。
对于语音辨识的输入输出使用的多对多的关系,使用了CTC进行判断,将输出进行压缩。
Attention-based Model (RNN的进阶)
除了RNN网络存在记忆单元以外,这个模型也可以实现
RNN对比structured learning

Graph Neural Network
主要就是突出图的关系,首先进行convolution卷积操作,提取特征。
将变量分为各种关系,将其关系录入到关系网中,其中运行逻辑有:
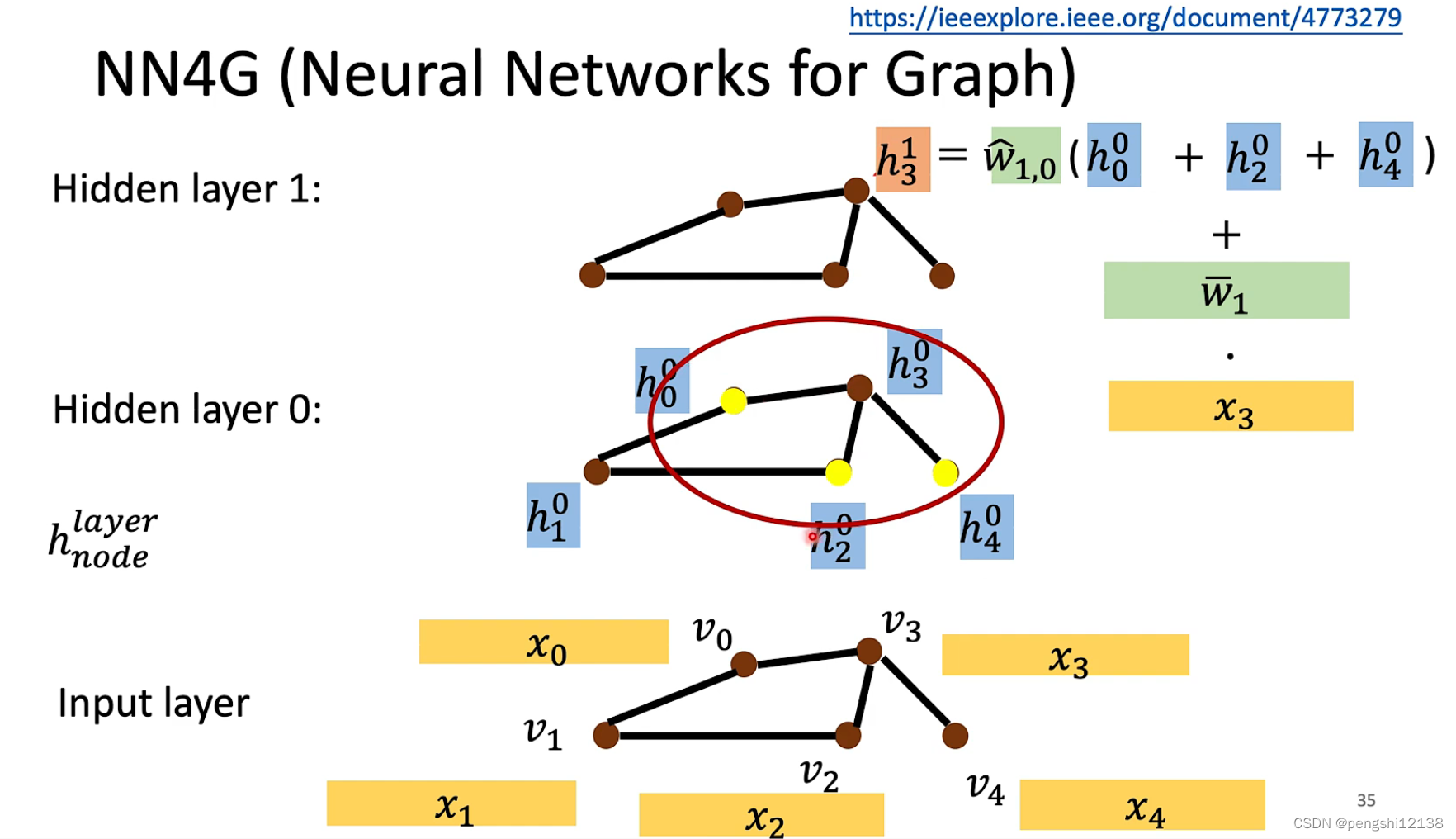
每个变量的相关节点进行相加
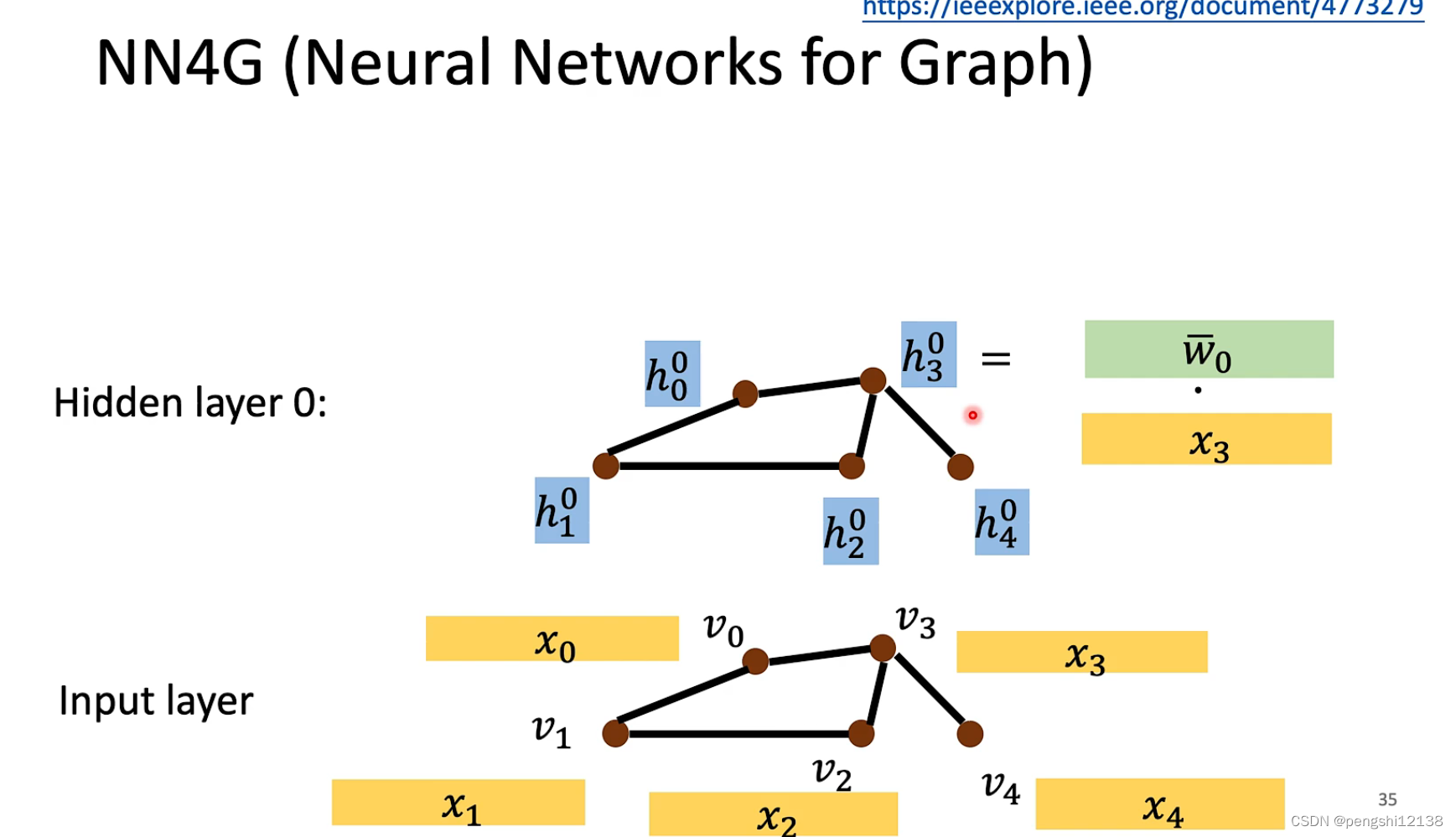
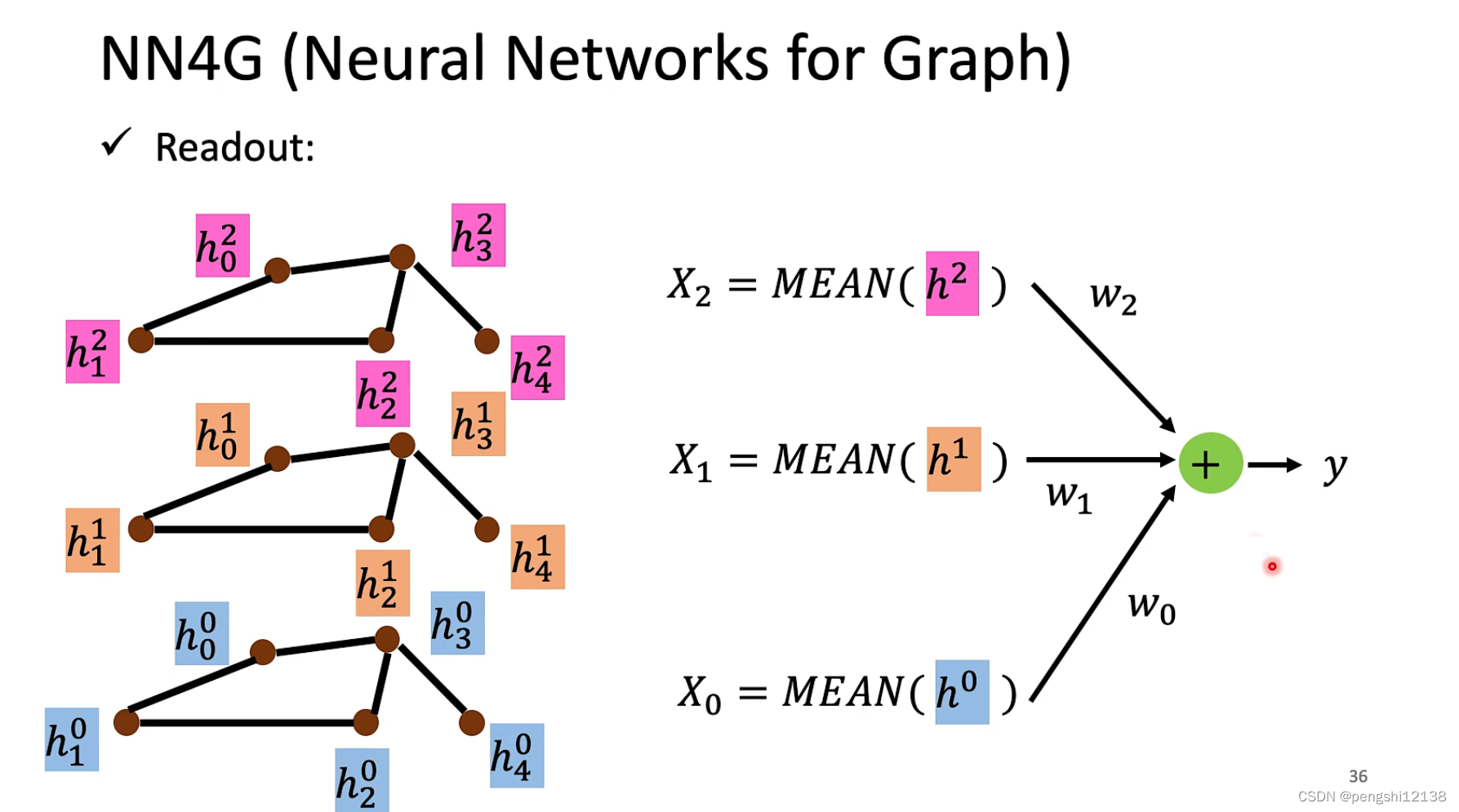
NN4G model
对于readout层使用
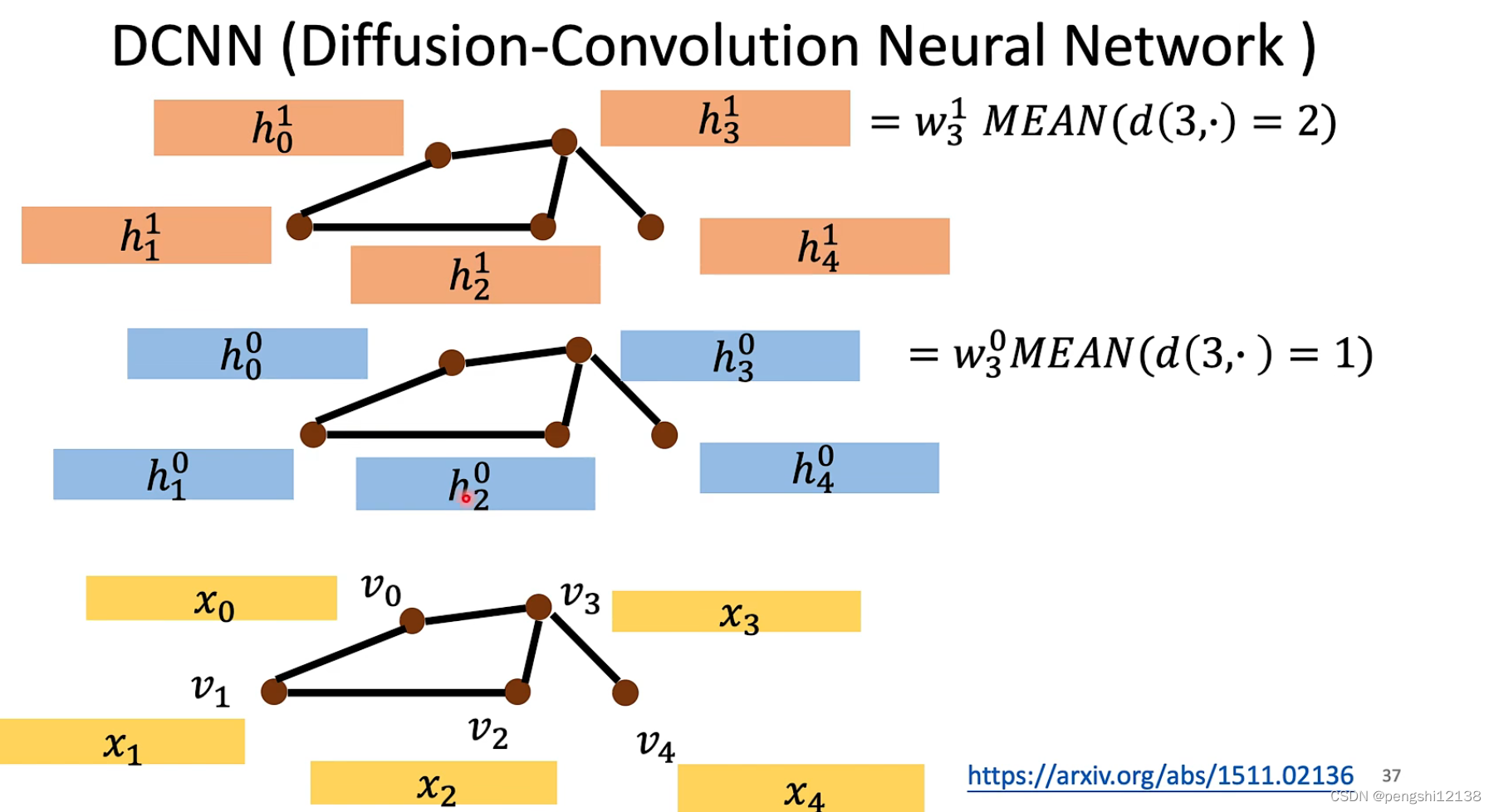
DCNN
将距离相等的权重相加平均进行计算。
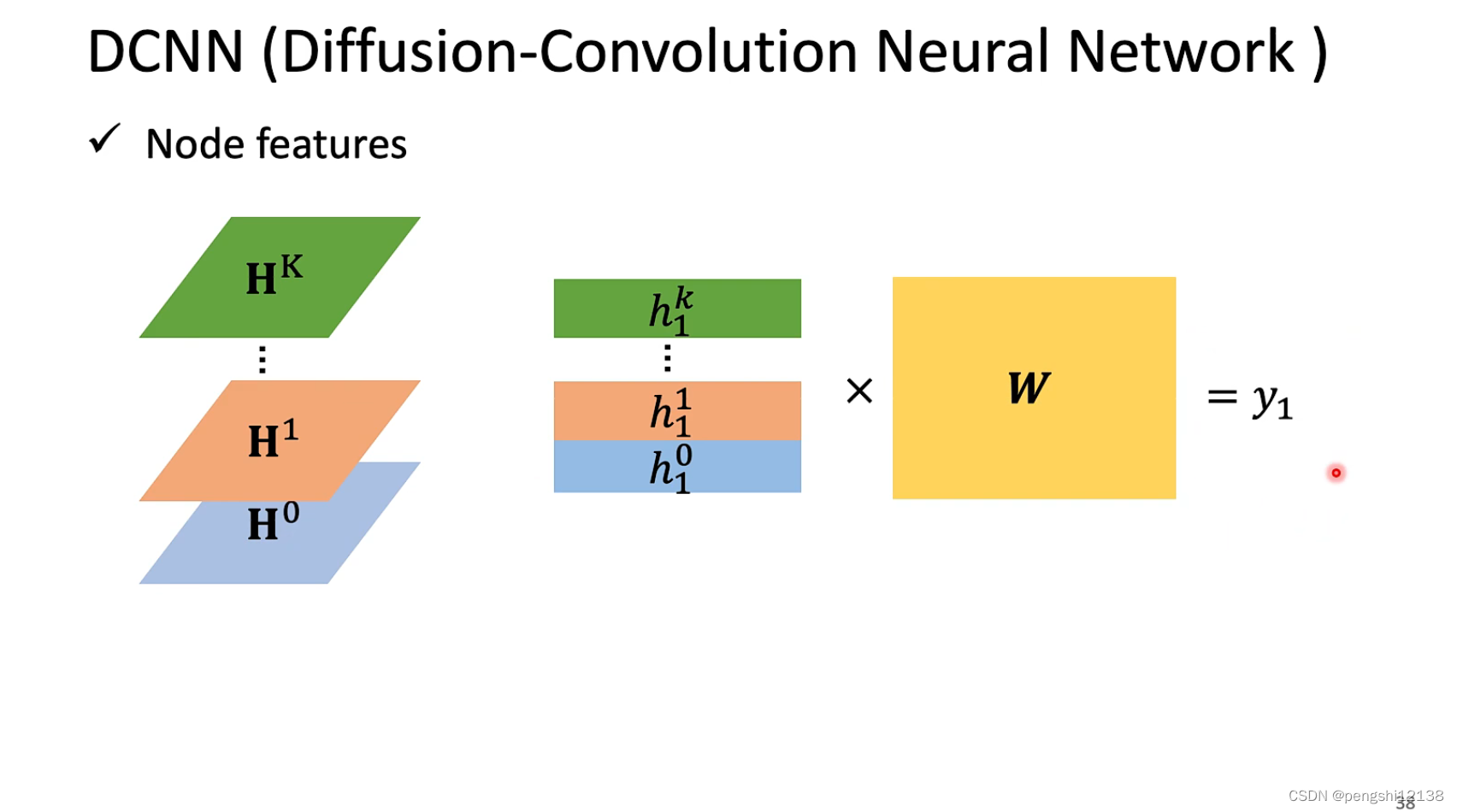
最后将对应每次的不同变量进行计算机得出最后的结果。
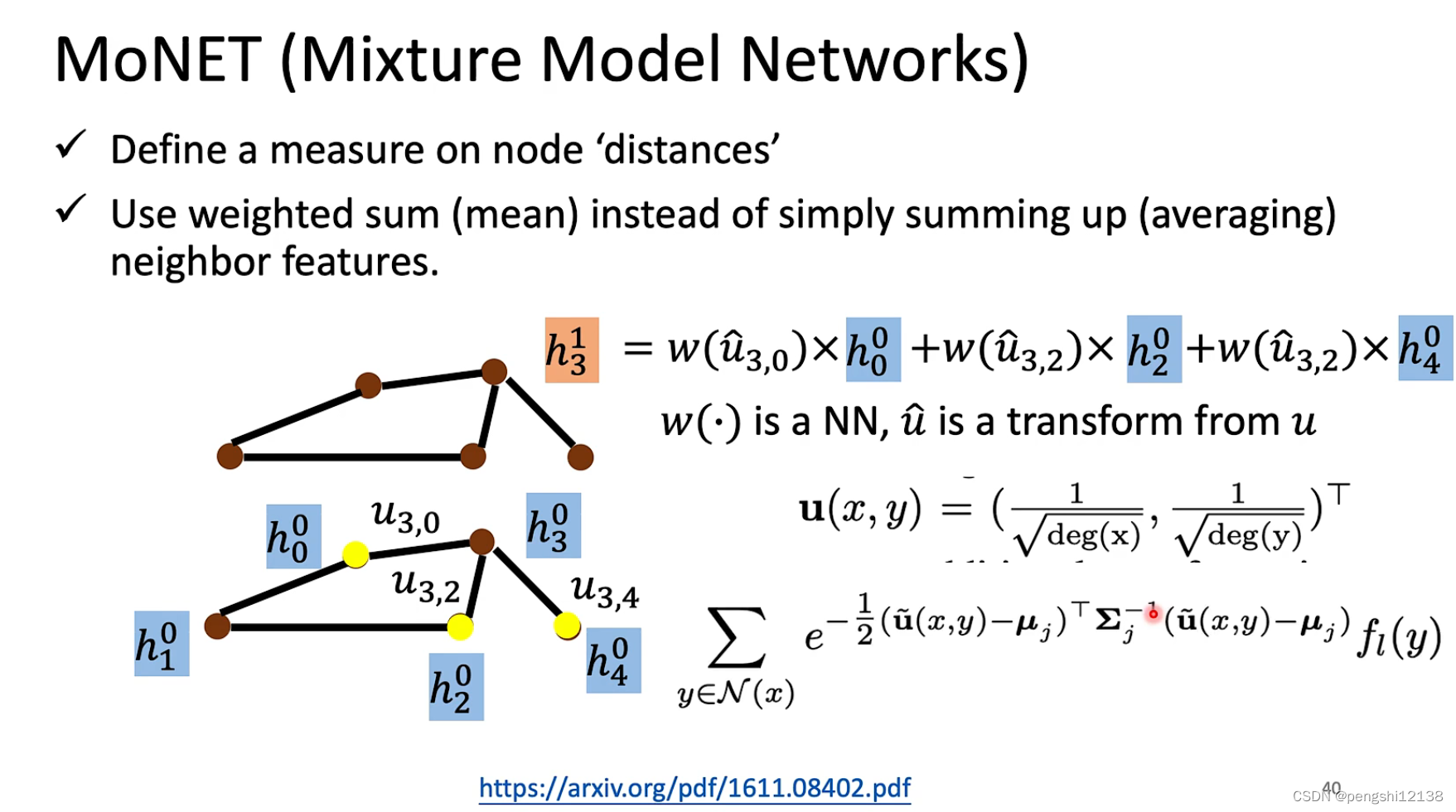
MoNet
对于距离进行重新计算机,更换不同的函数形式
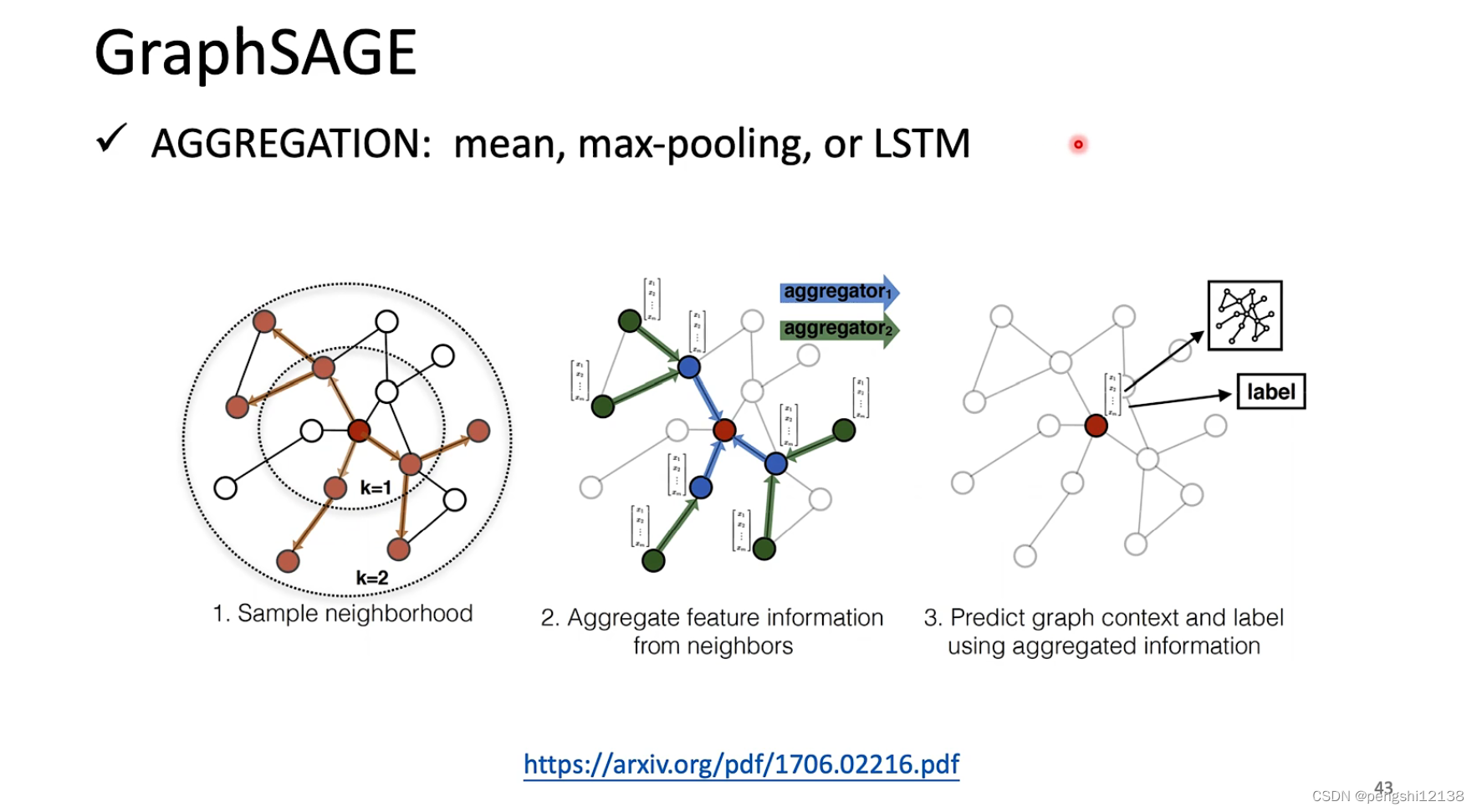
GraphSAGE
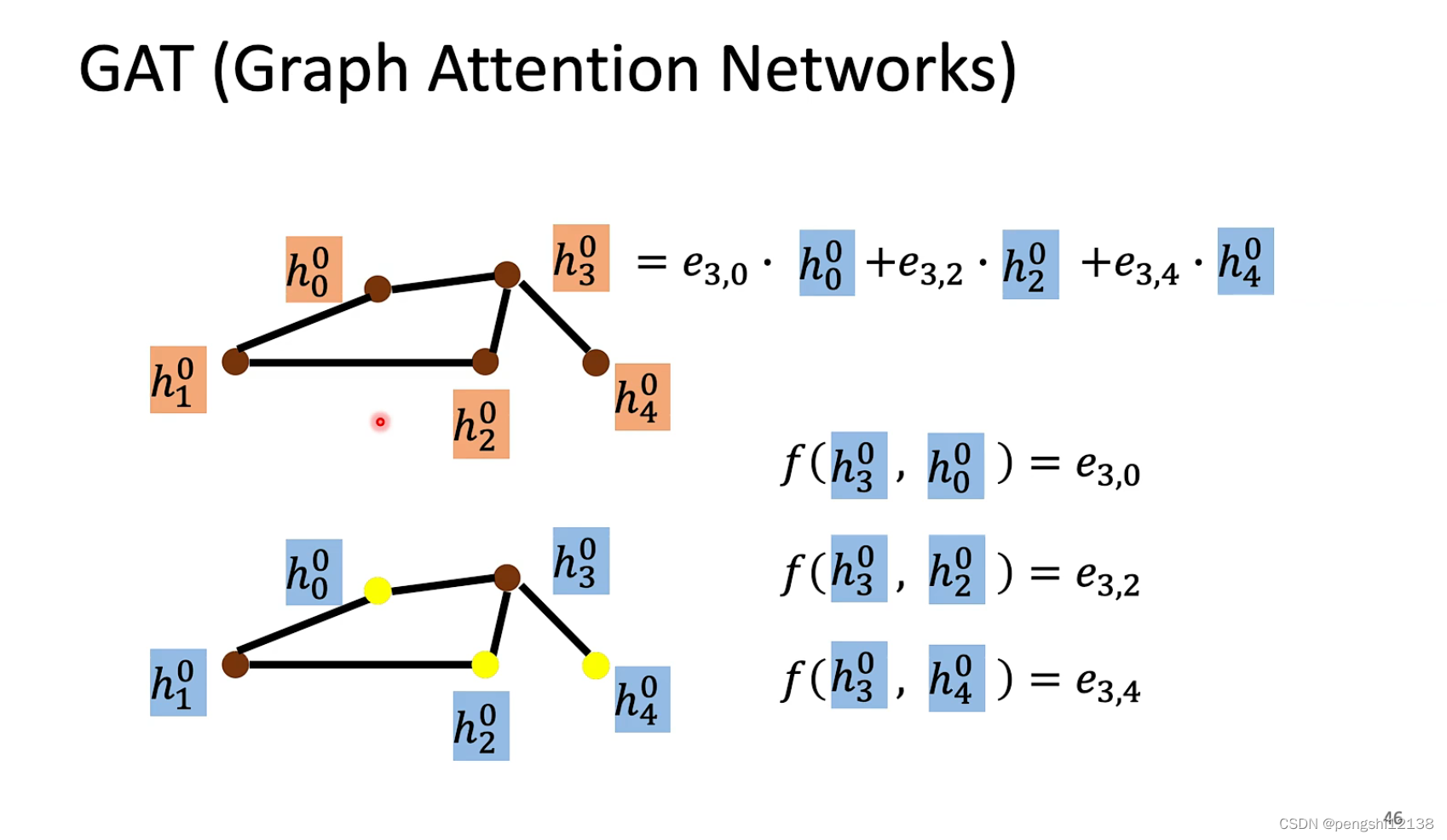
GAT

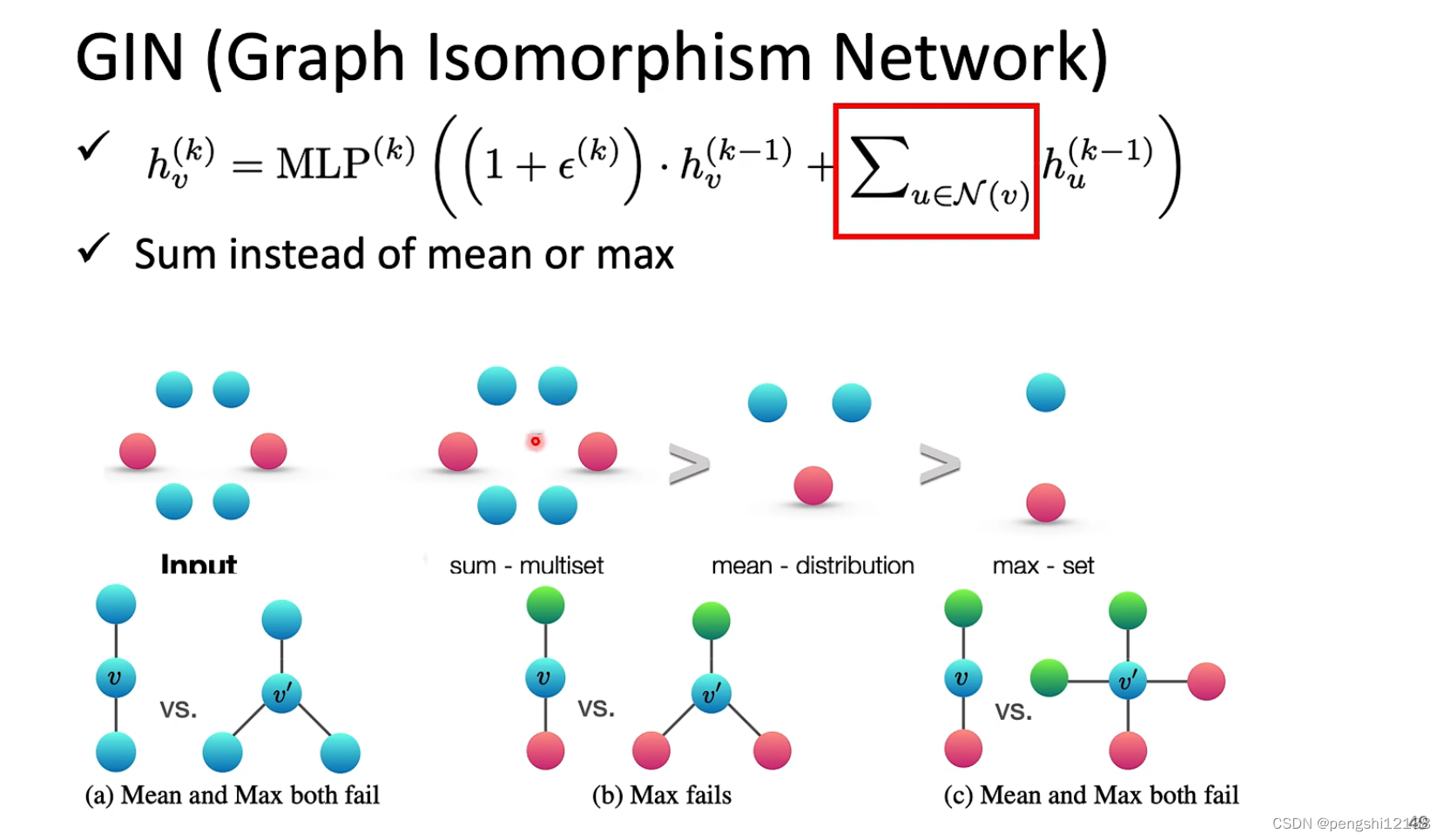
GIN
对于每层关系函数使用sum函数将关联的变量相加,主要是如果不用相加,使用mean或者maxpool 存在无法区分的情况。
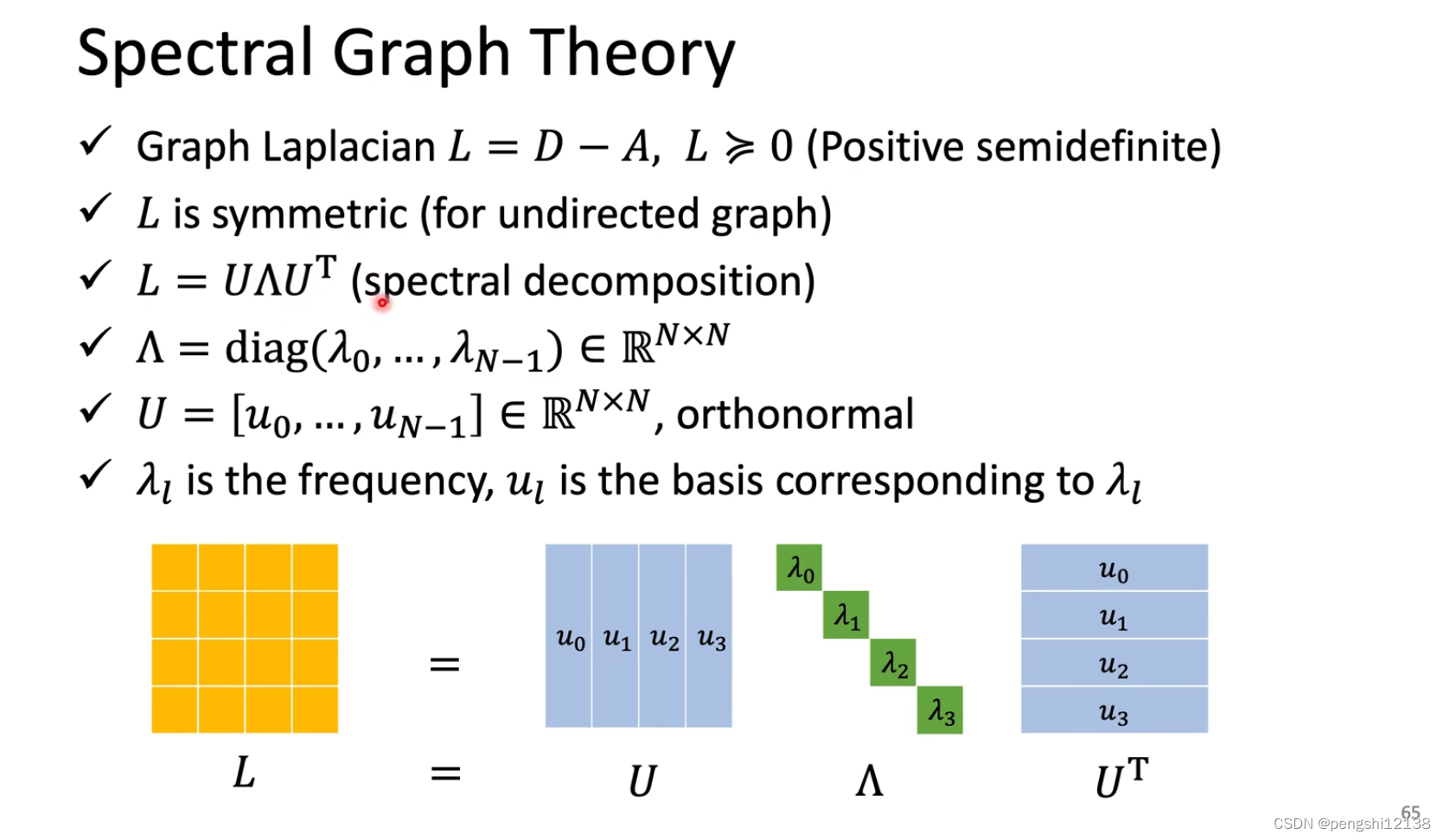
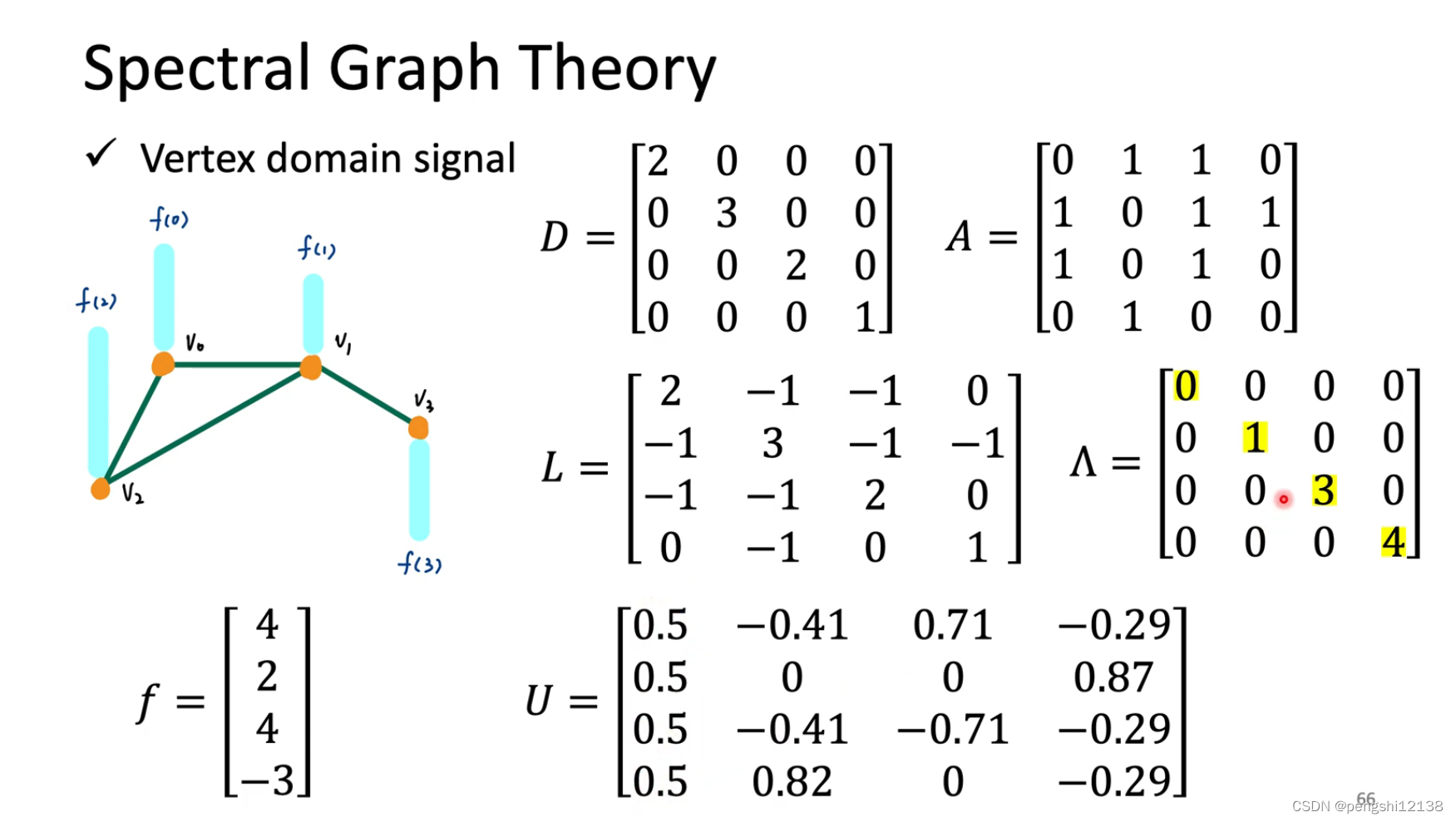
Graph Signal Pro




矩阵A表示对应的图各个节点相连的对称矩阵判断,而D表示A每行的和
下面举一个例子进行判断:
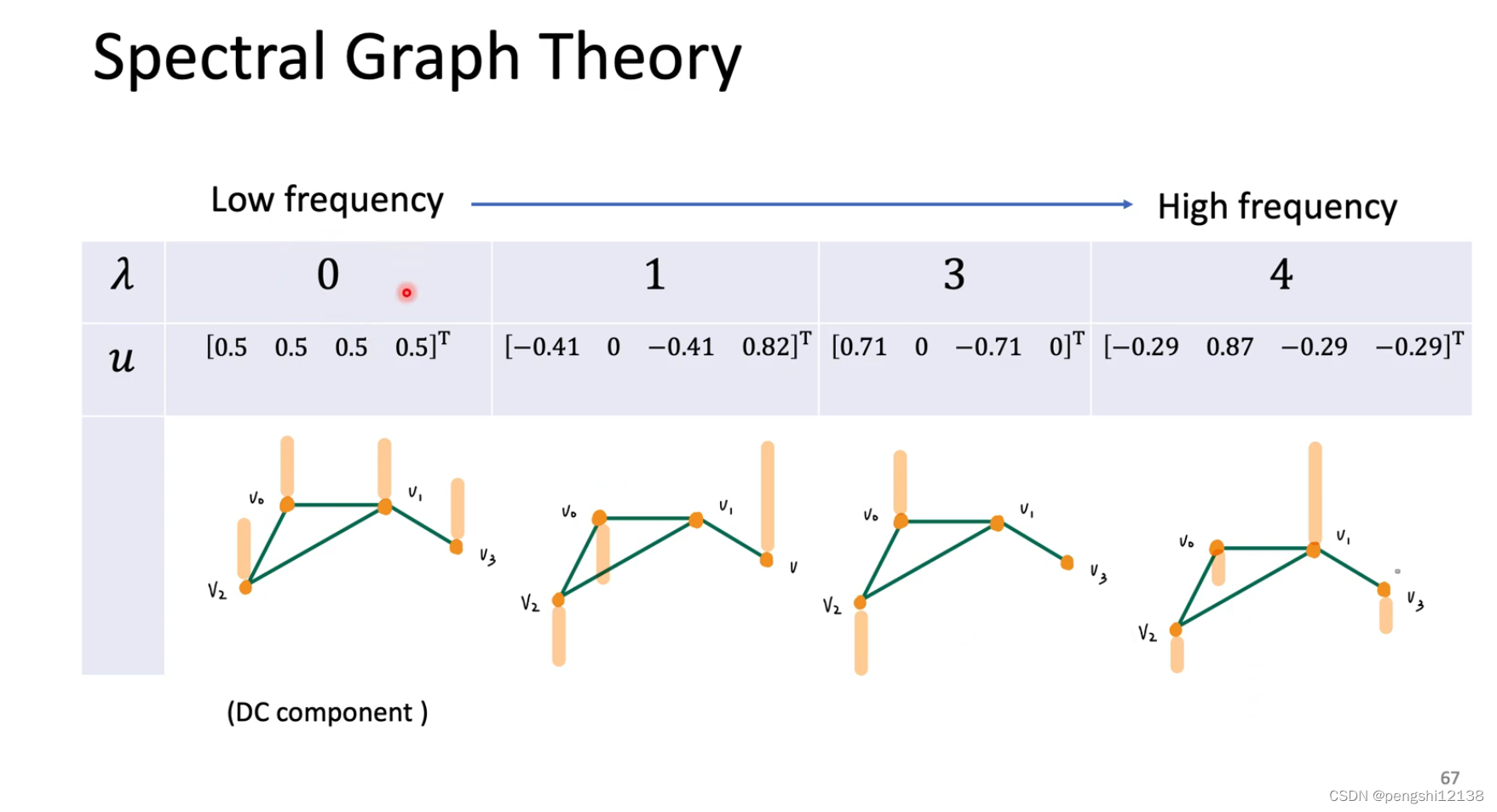
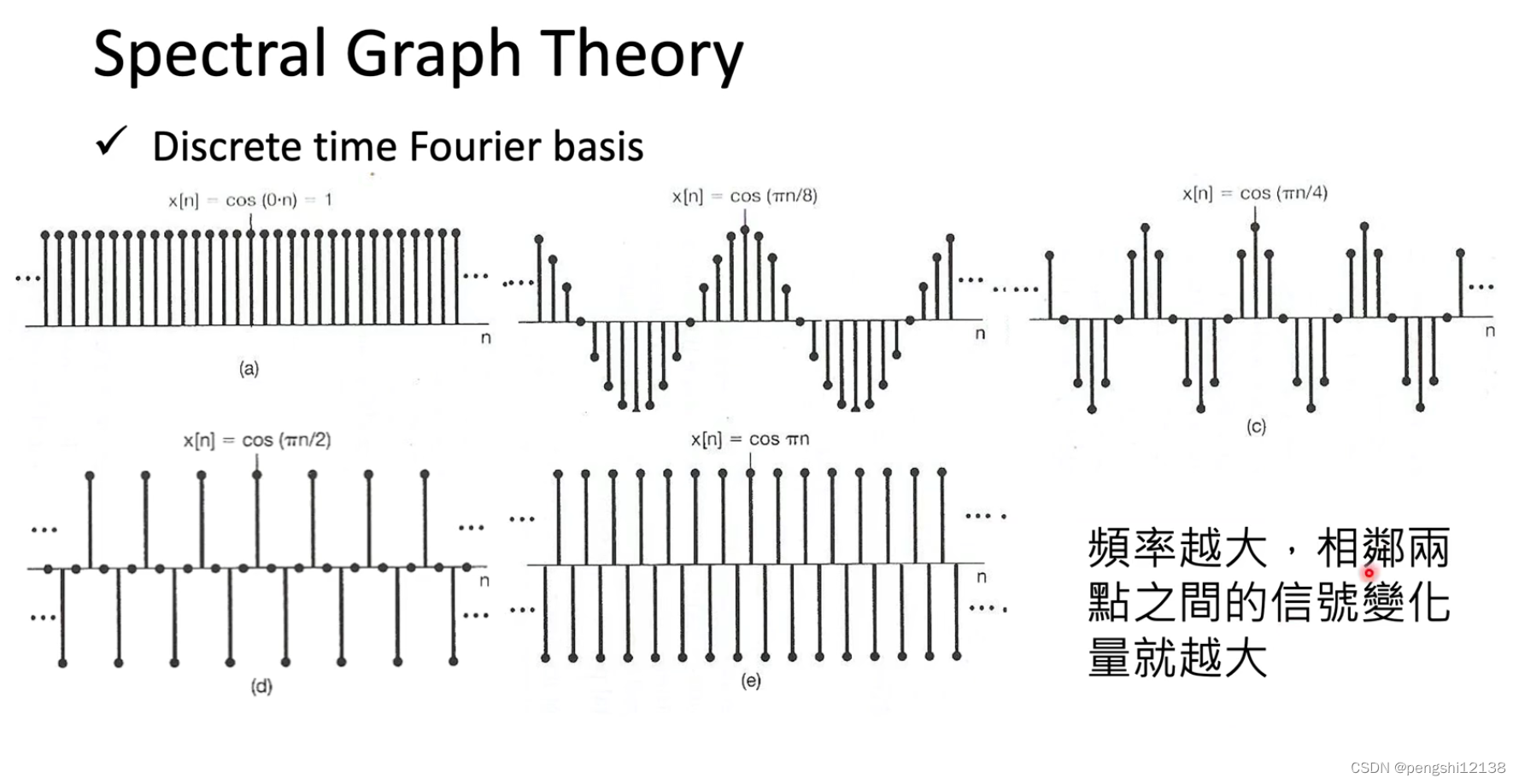
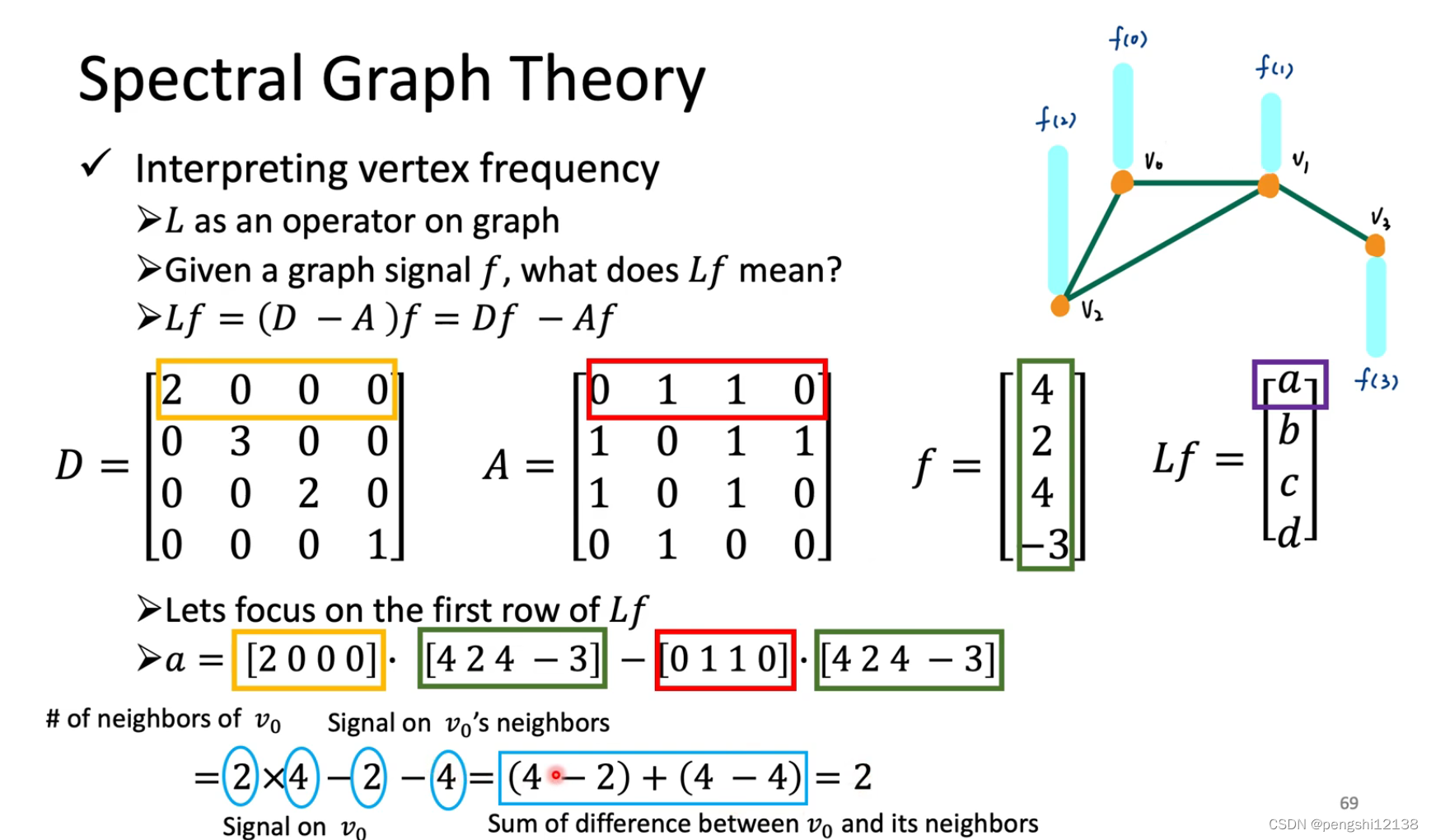

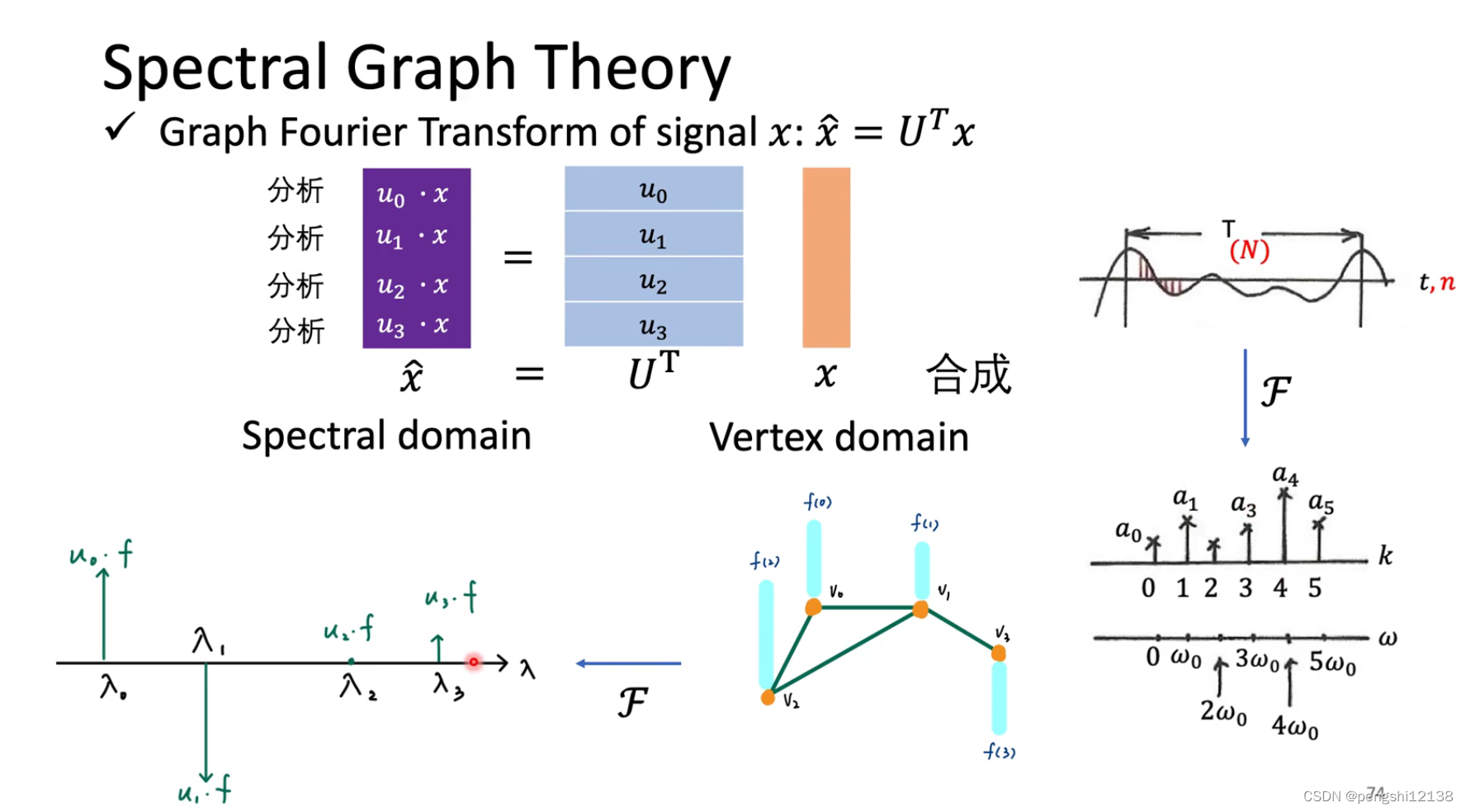
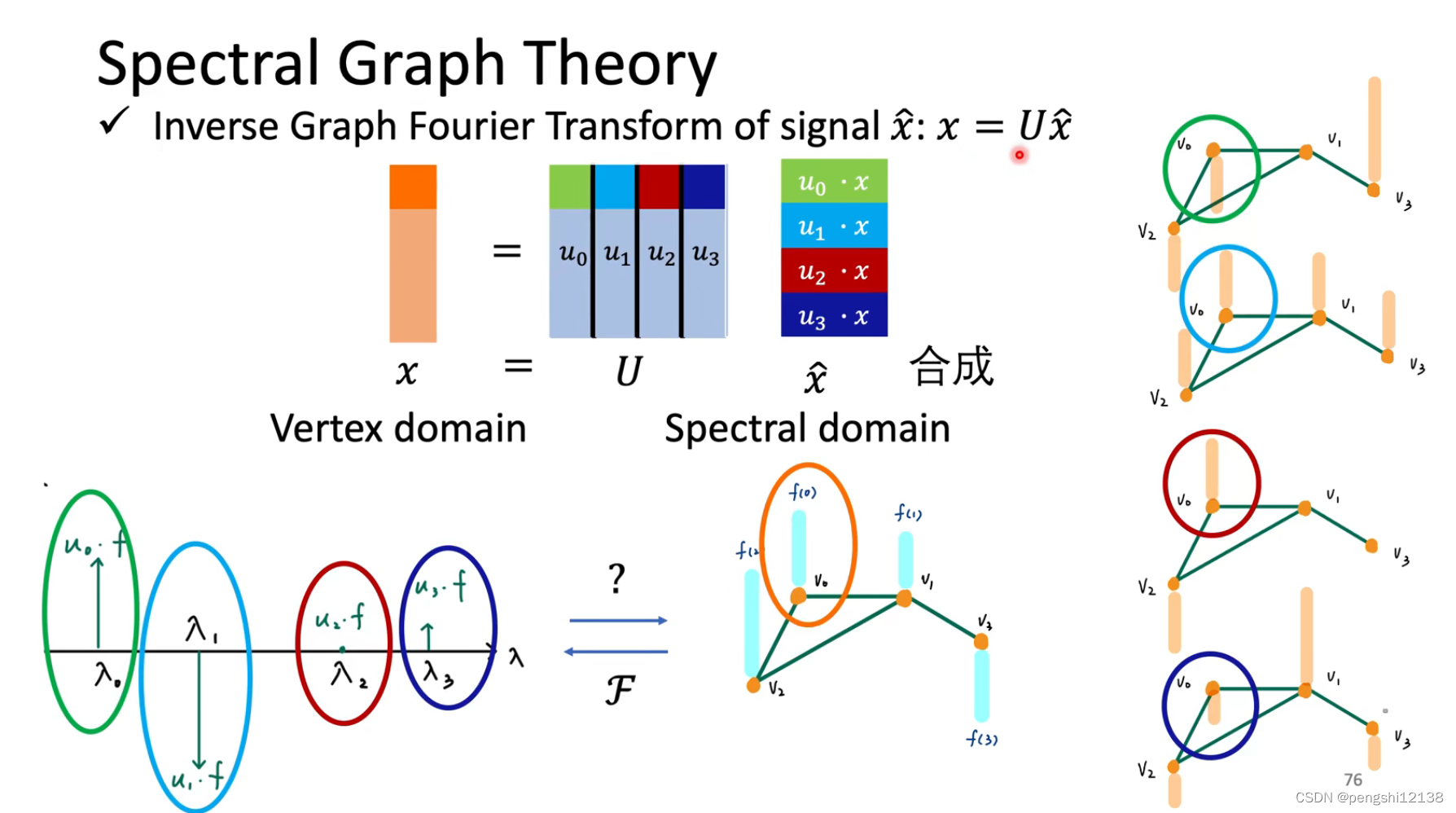
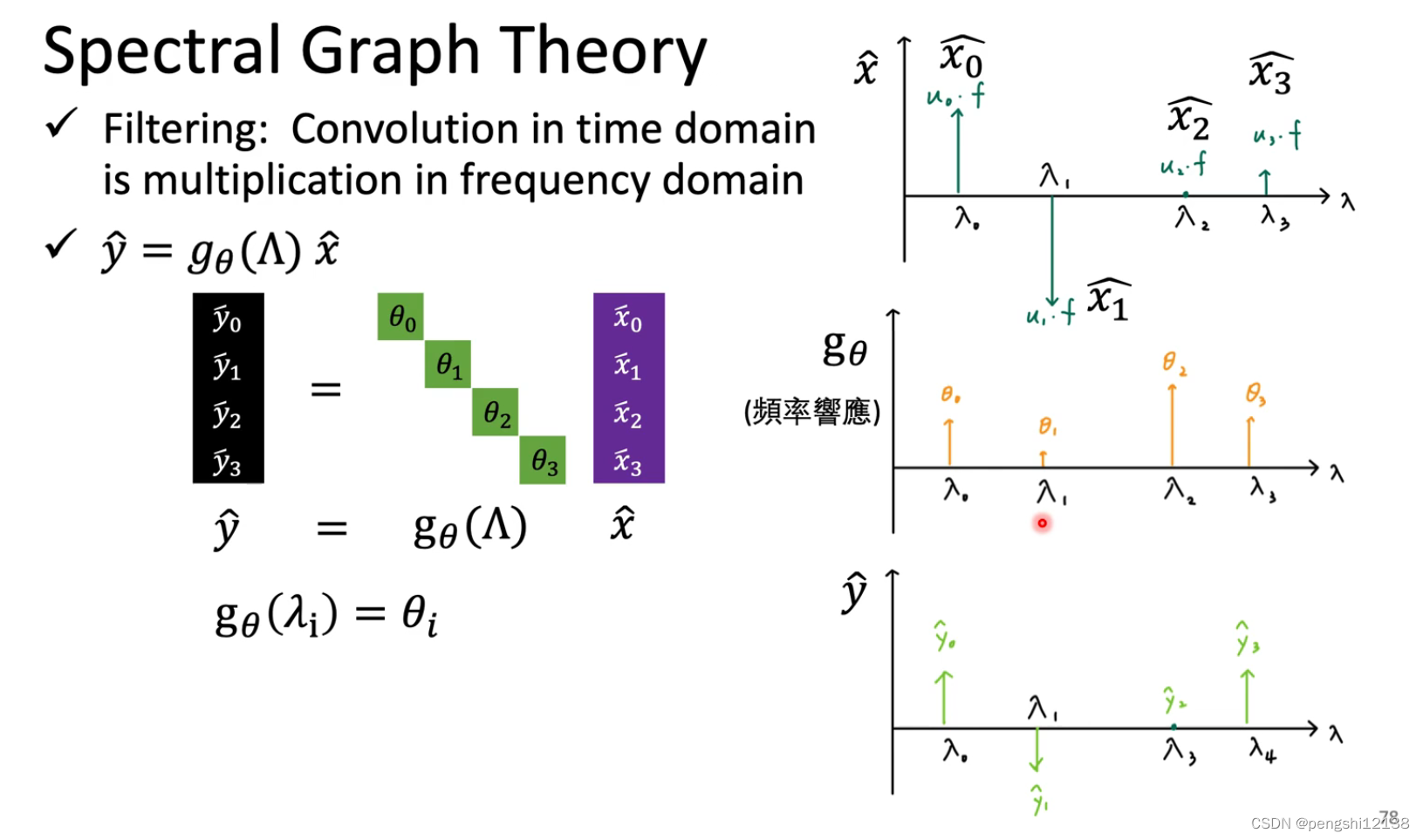

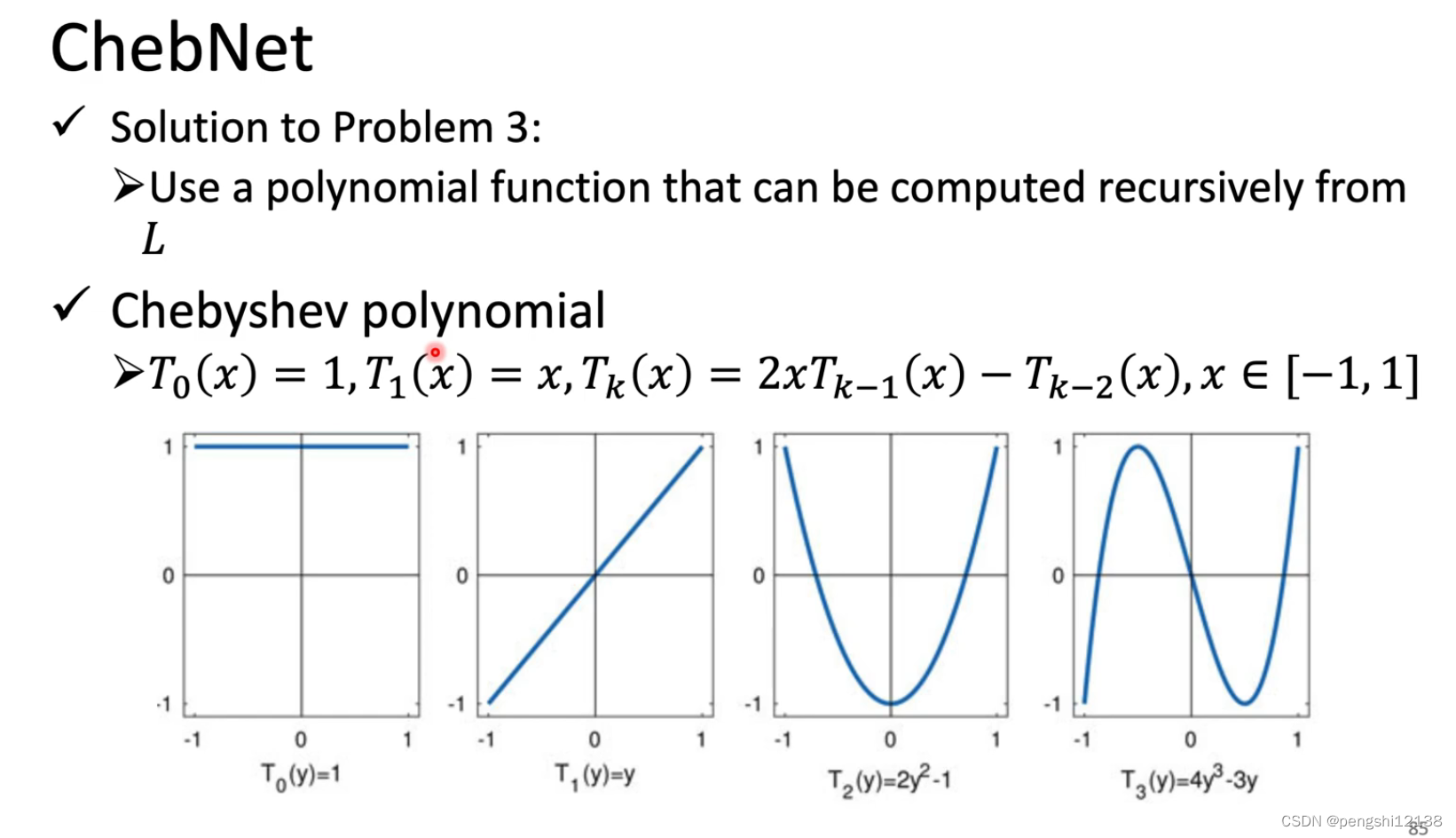
对于L函数可以知道,主要是因为L可能会影响到所有的点,但是我们希望影响是局部的。可以使用 ChebNet进行固定对应的范围。

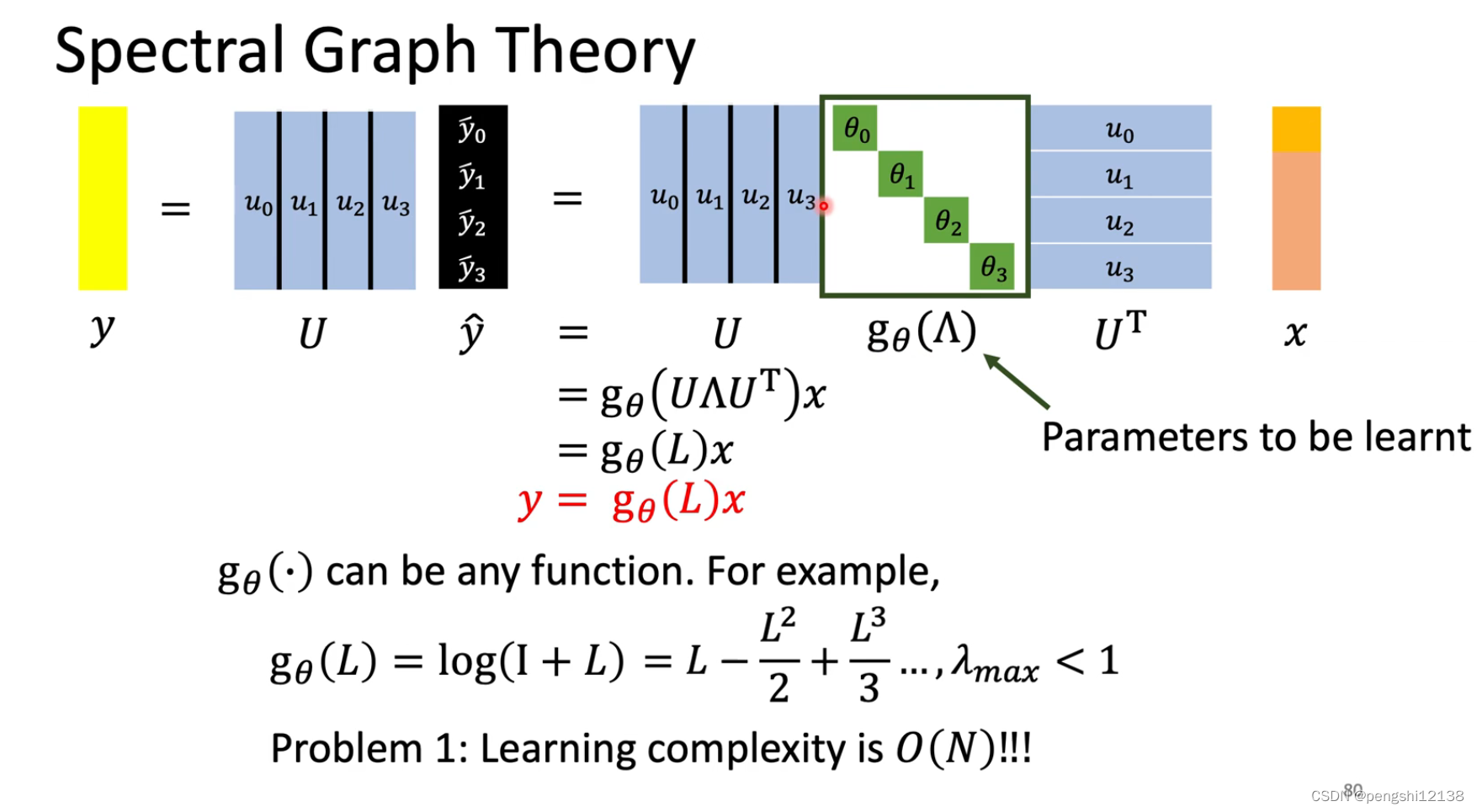
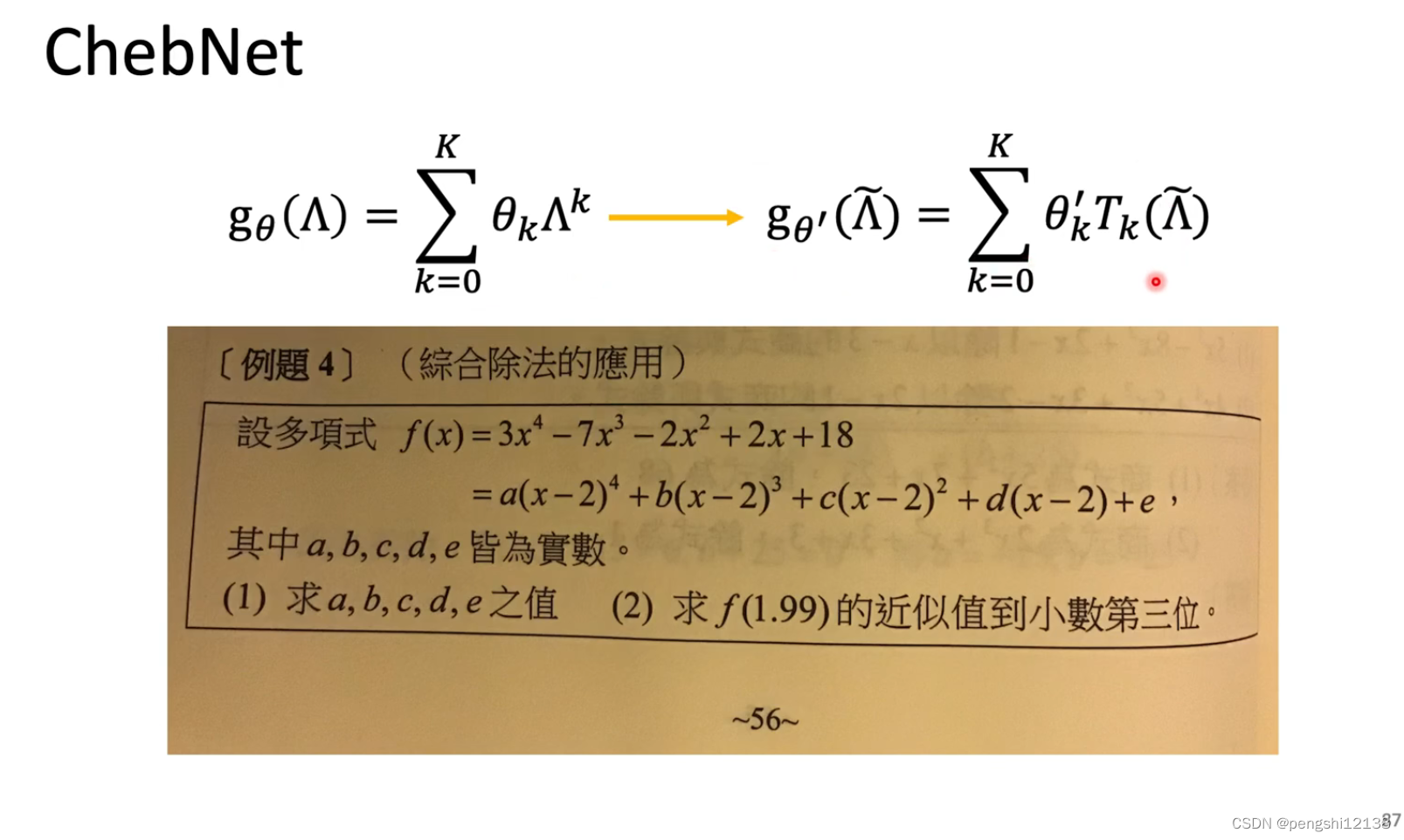
为了解决问题三计算量较大的问题,可以使用公式的转换,对应的就是一个filter,过滤数据,转换以下。
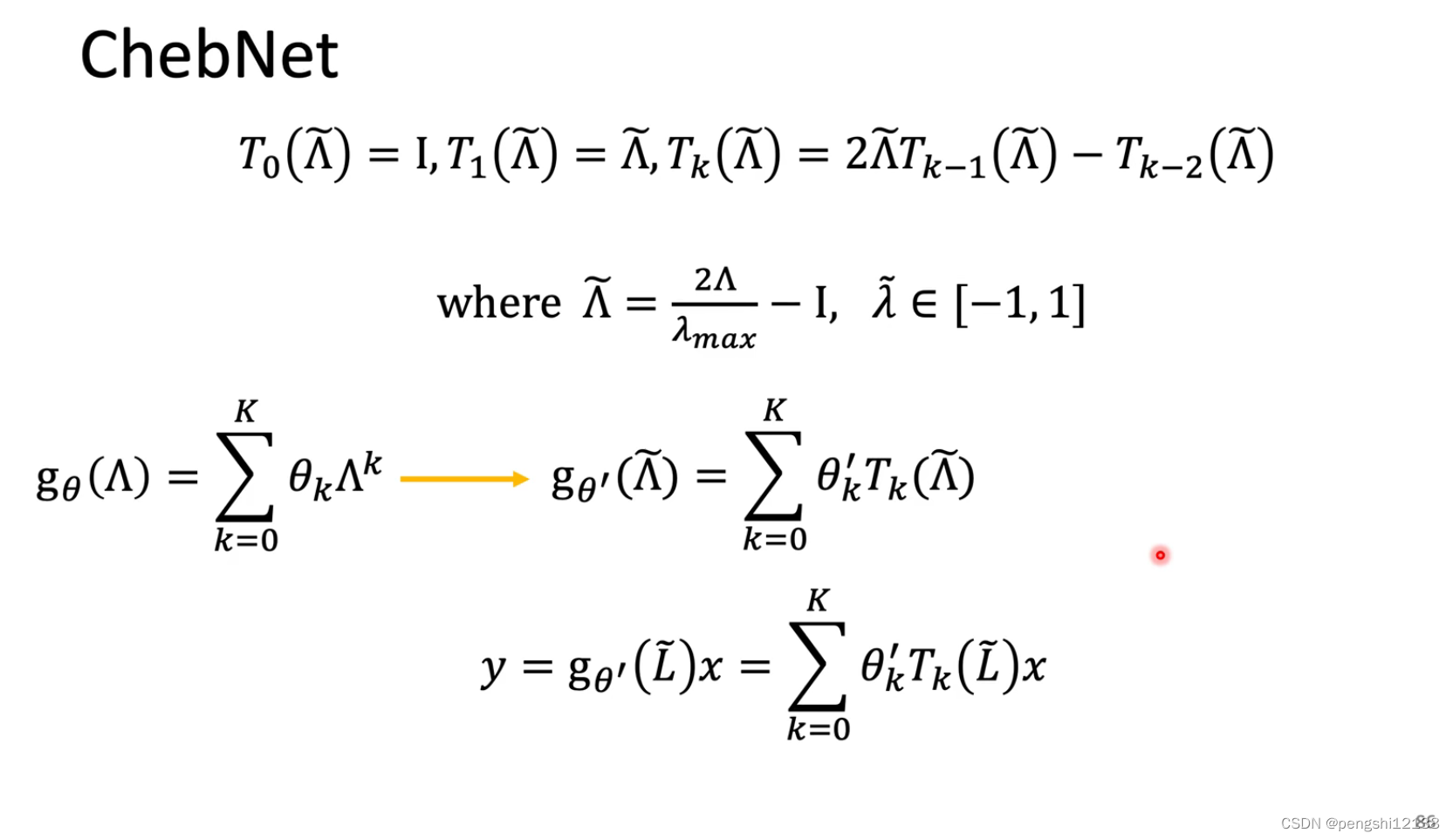
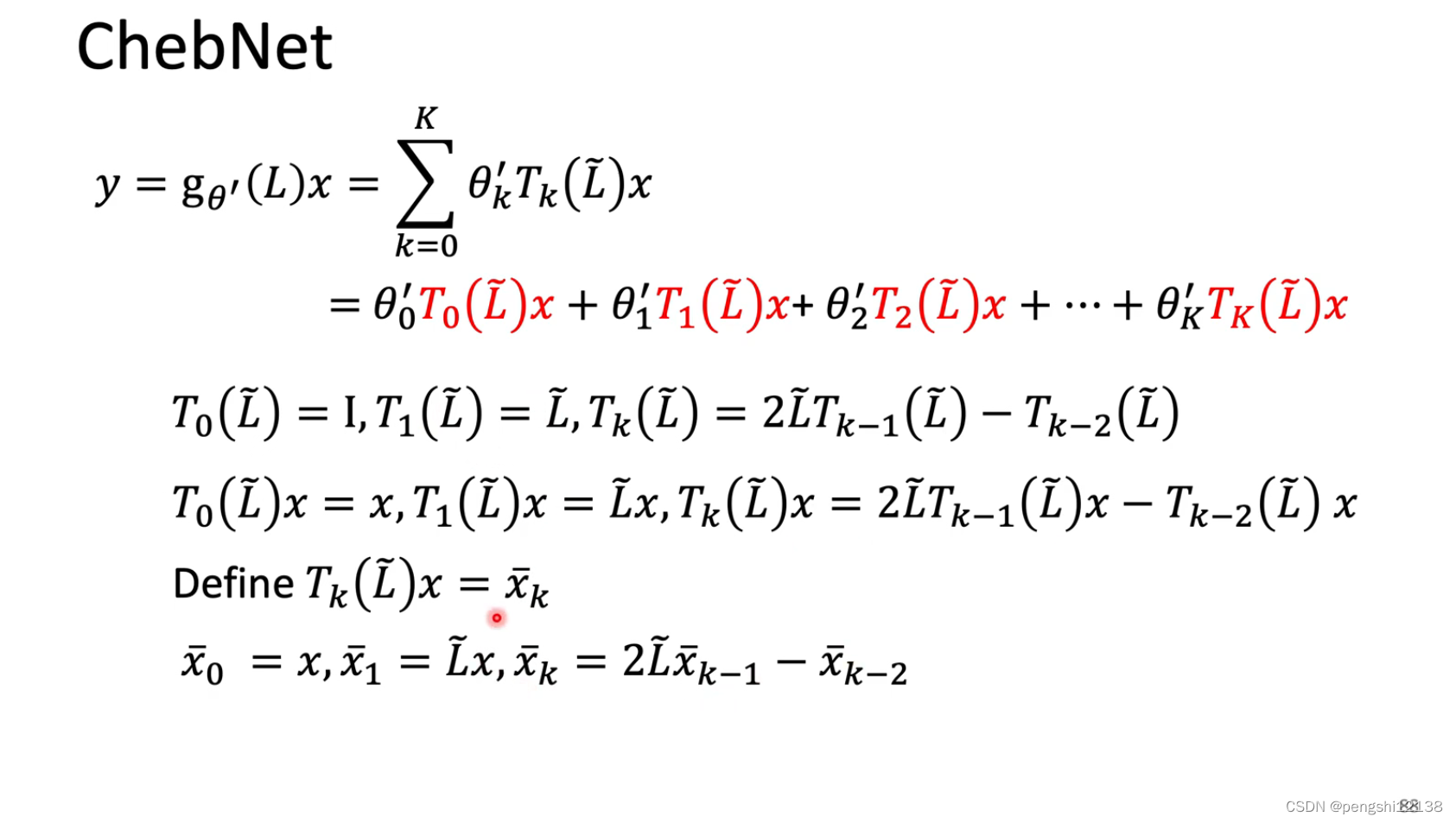

使用一个递推的公式转换原本的x变量,同时求解对应的filter会更加快速,复杂度会降低。
GCN
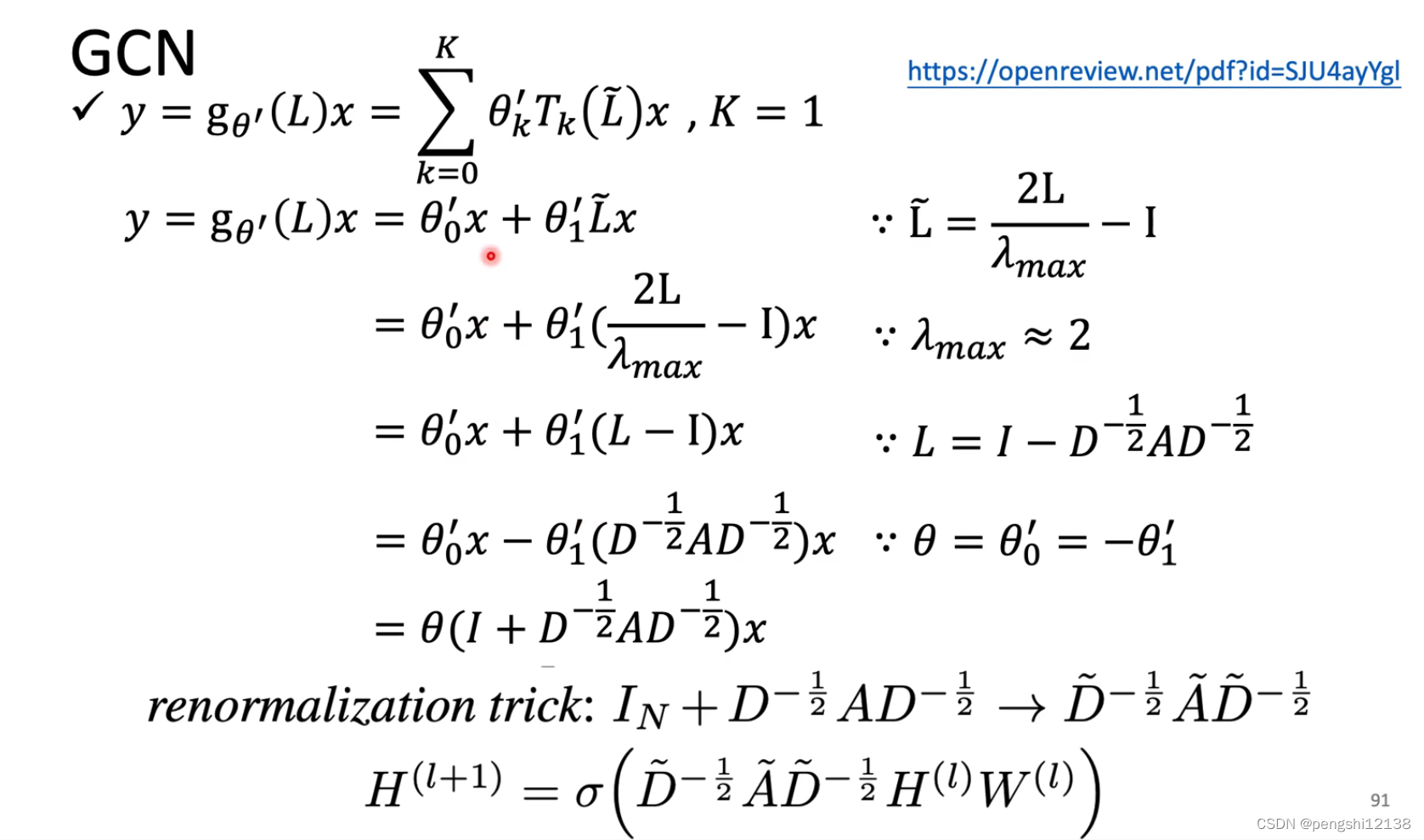

Graph Generation 图片生成

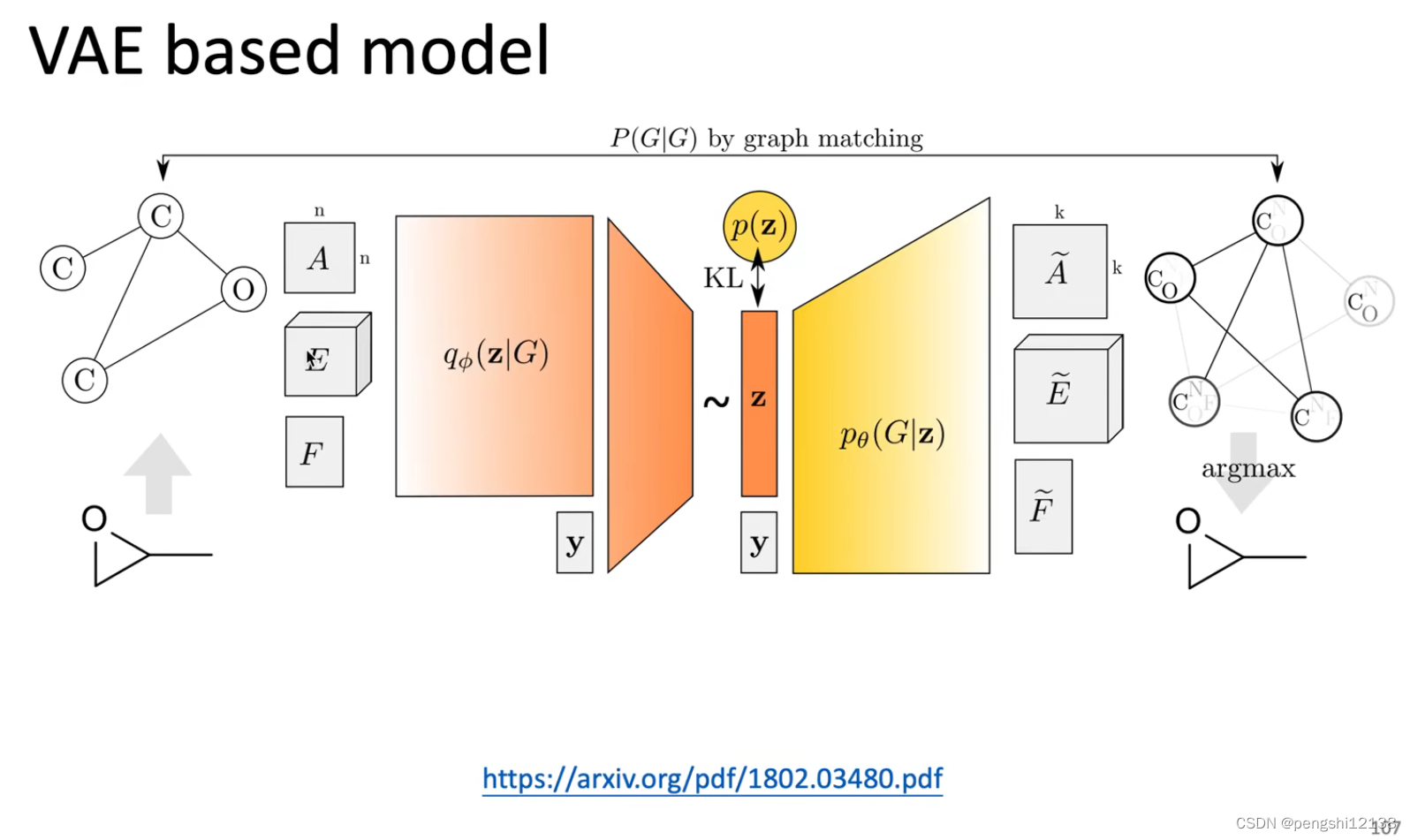
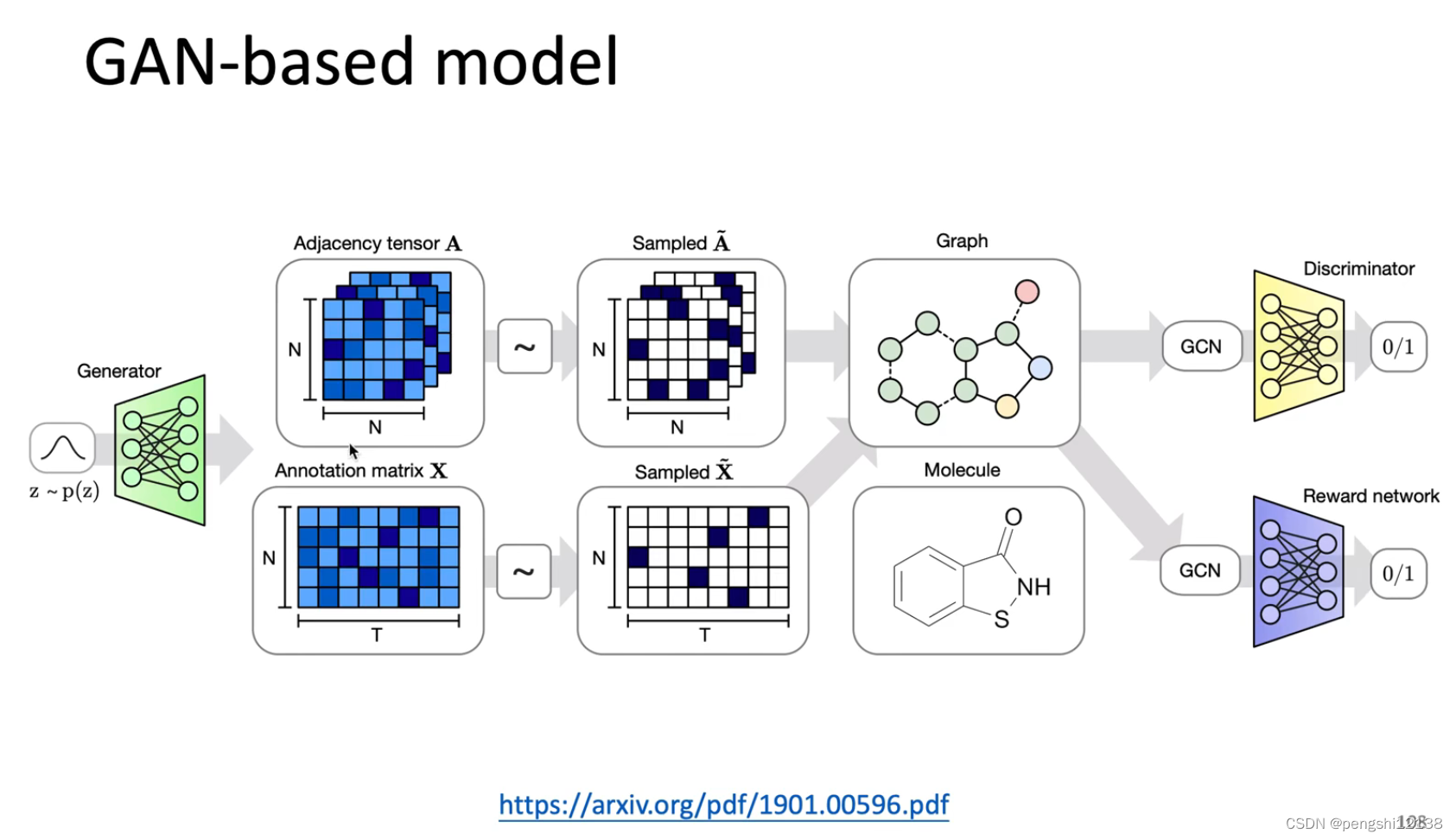
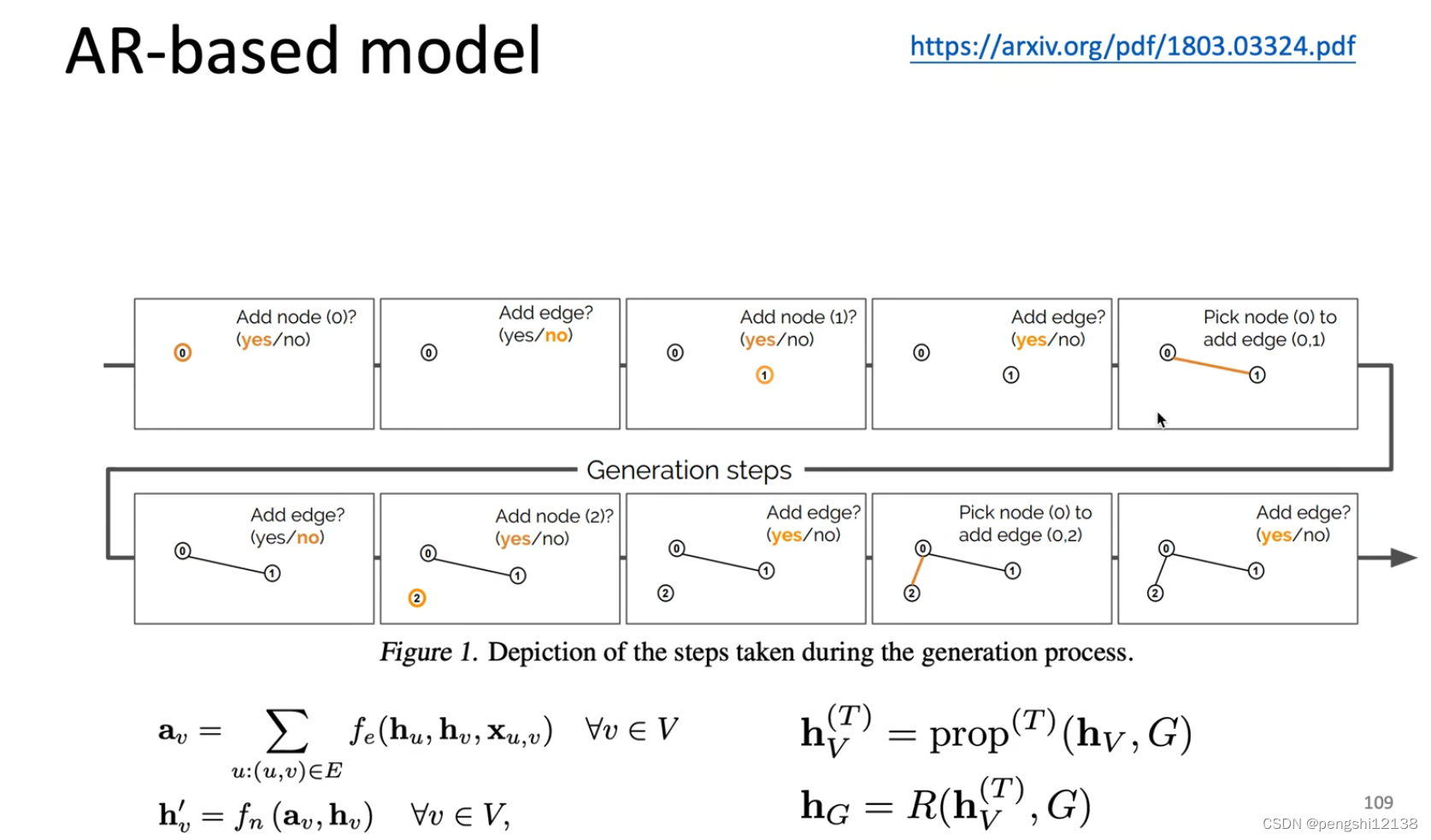
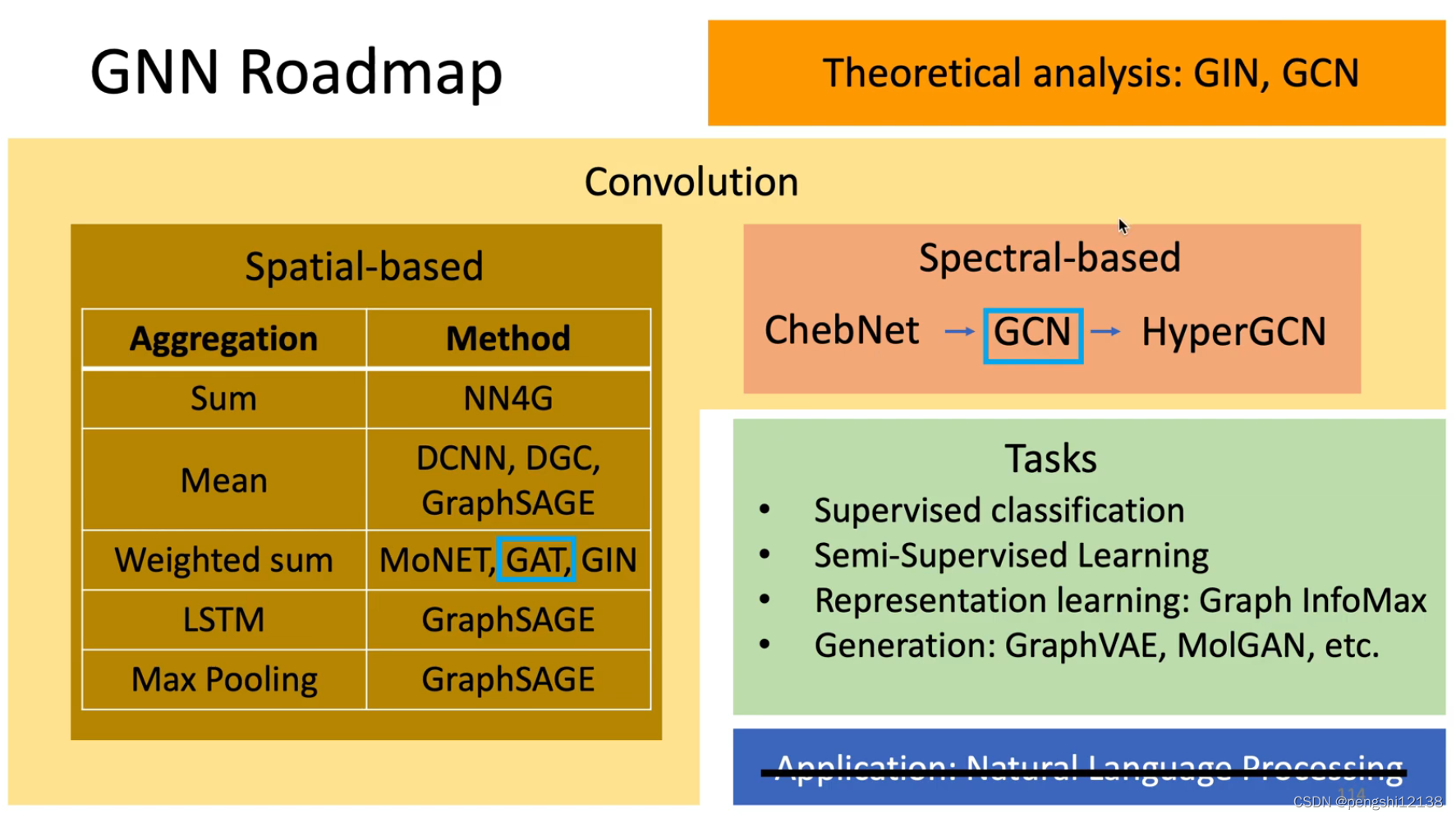

(上面这一块的 GNN不是很熟悉 需要进一步了解底层的原理)
Unsupervised Learning Word Embedding(无监督学习之词嵌入)
通过词汇的含义进行划分分类,不用特意的定制过多的词汇进行分类one-hot导致输出过大。
通过机器读取大量的文章,了解对应的词汇,生成单词变量的过程是无监督的,结果也是不知道的。
维数会比 1-N encoding的方式低
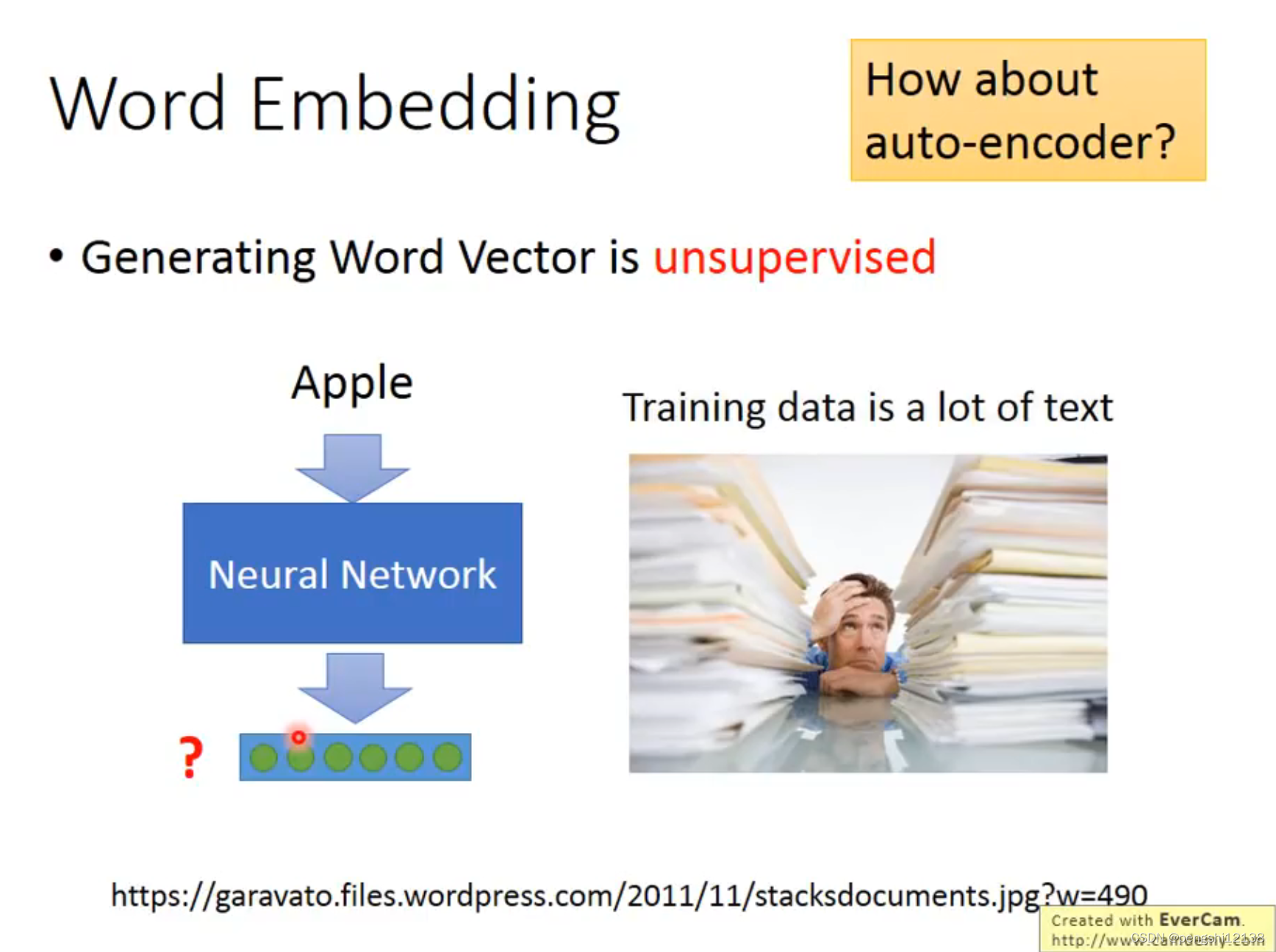
如何找出单词的含义
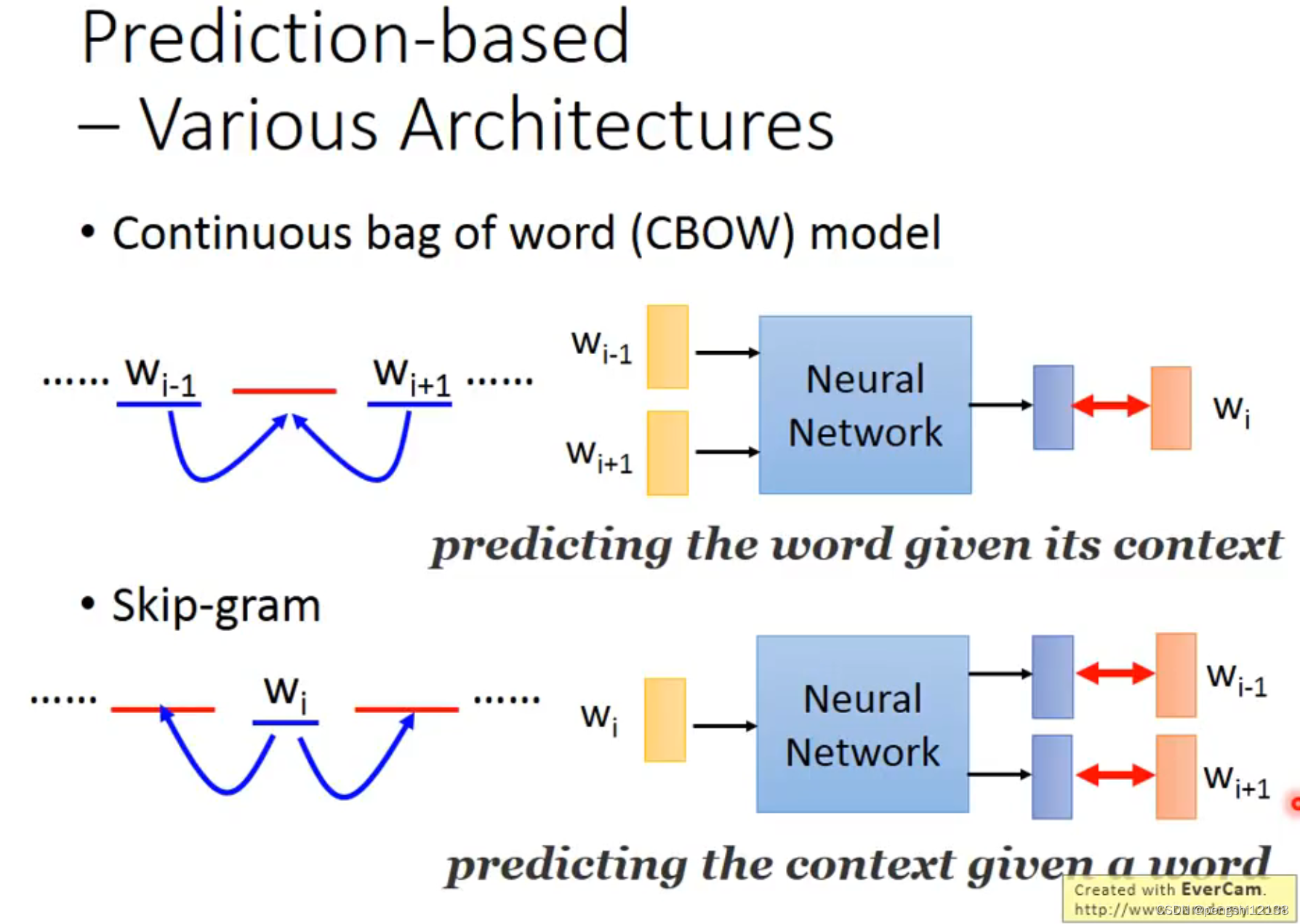
count based 和 prediction based 的两种方式,前者假如两个单词频繁的同时出现的次数,同时两者的word vector会比较接近,同时计算两个单词的内积,将这两者越接近越好。后者是预测的概念,预测下一个单词的几率,输入的是1-N encoding

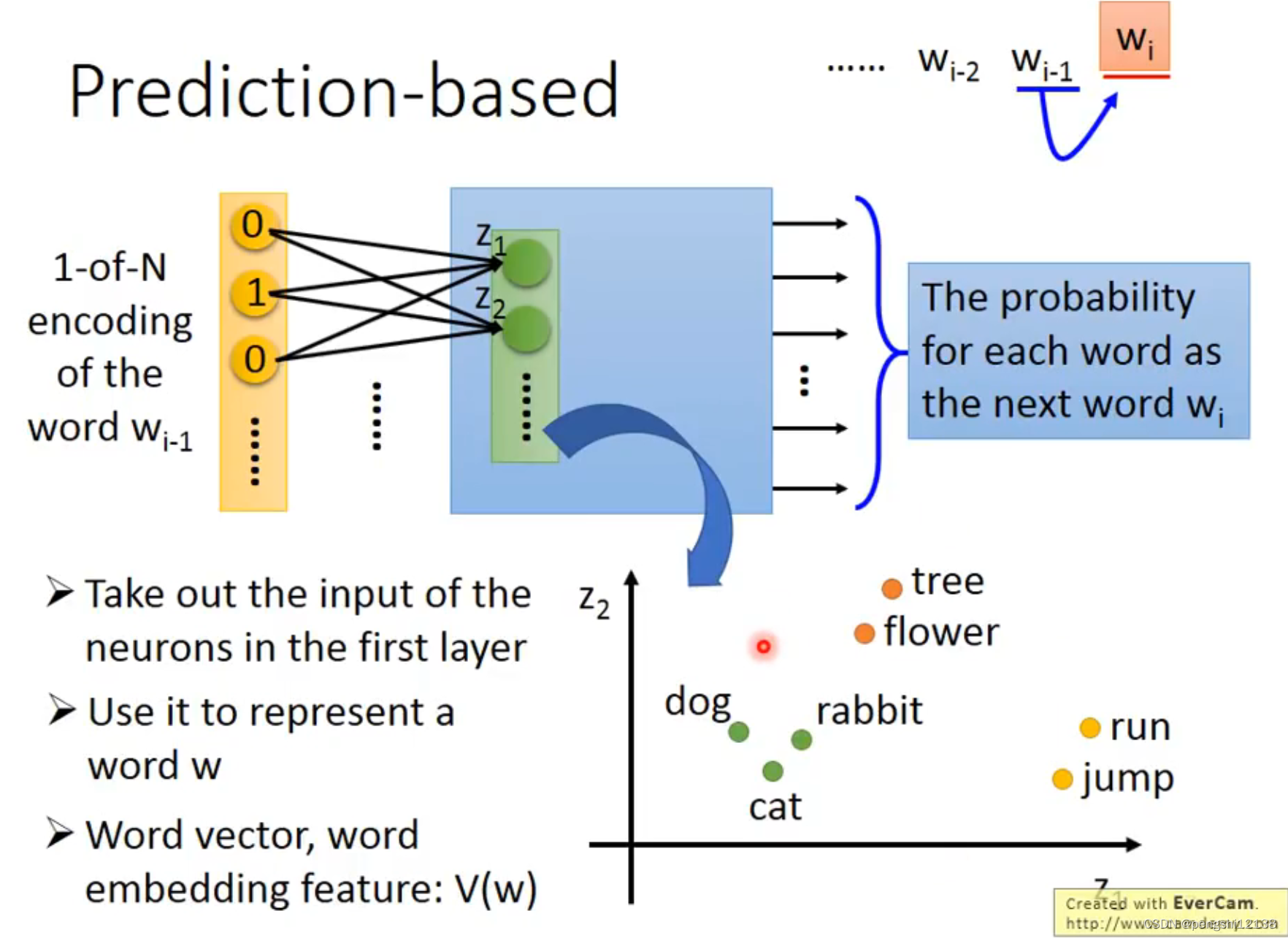
但是对于一个单词预测下一词汇,关联性很弱,所以需要进行共享变量,多个单词共同输入。
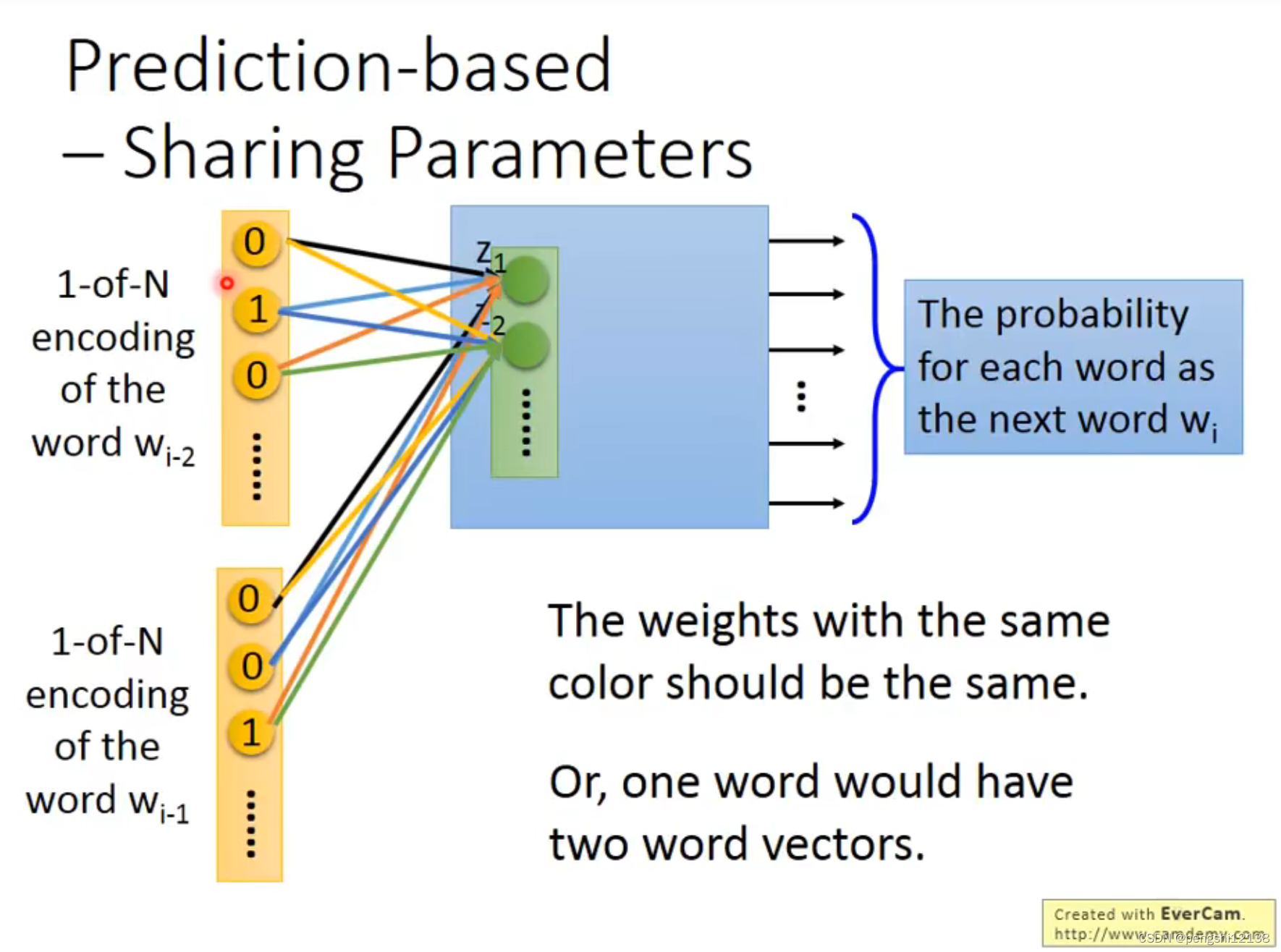
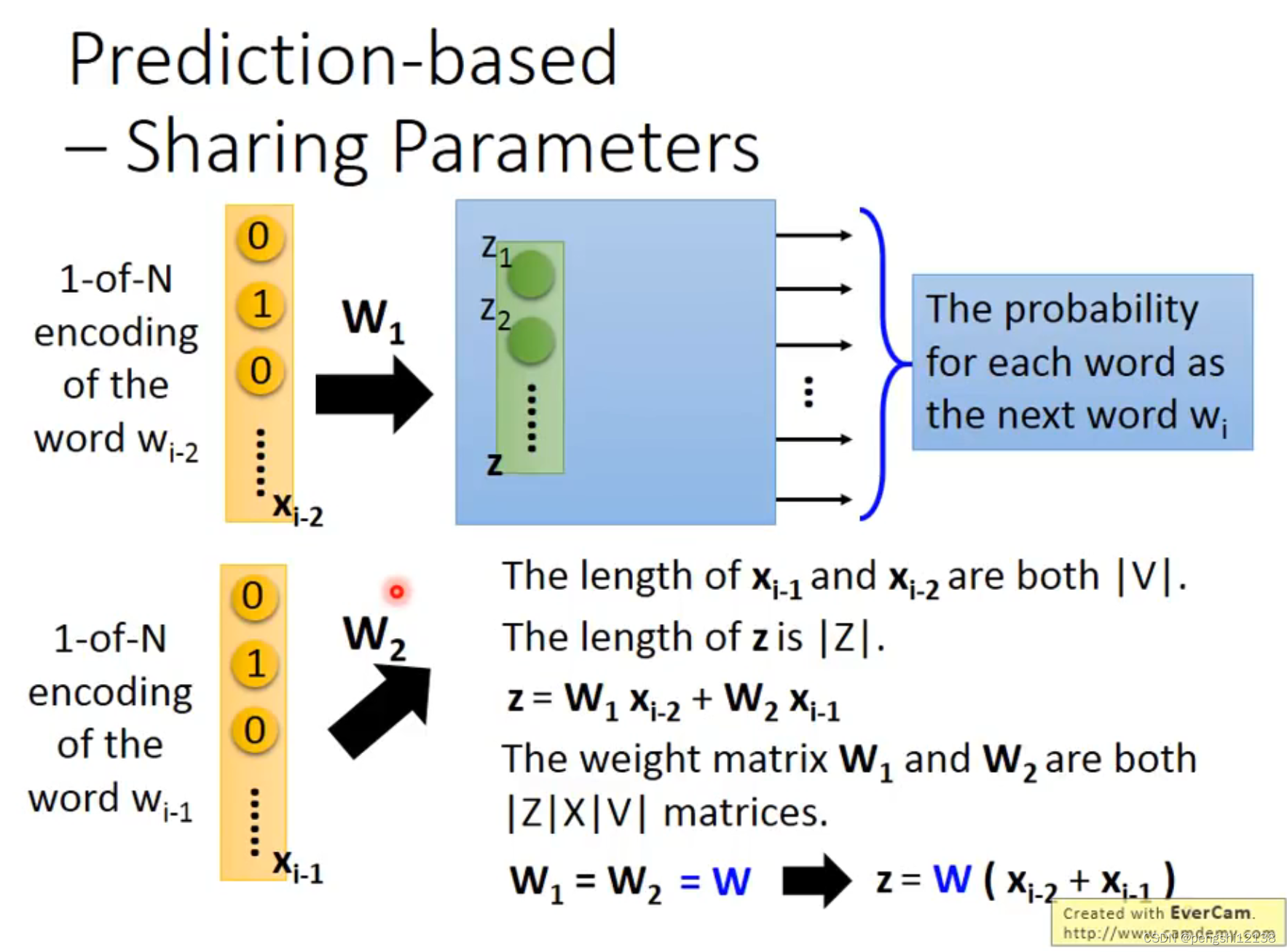
参数共享,对于不同输入变量的权重w初始值一样,同时能够将梯度下降的过程合并一起。
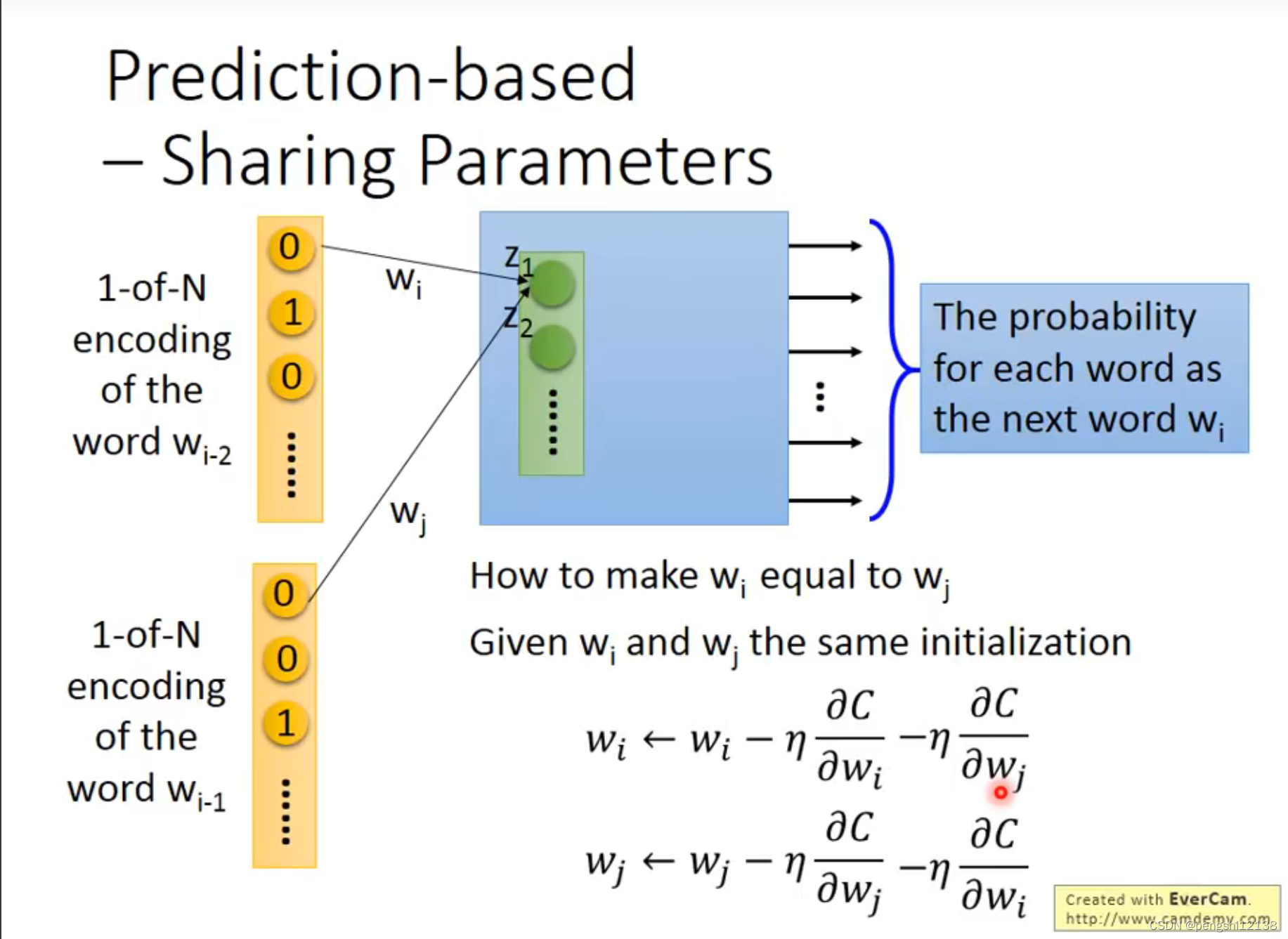
对于prediction based 有种种变形。
将两边的词汇推测中间的单词,
或者将中间词汇推测两边的单词。