内存虚拟化方案
最直观的方案,将QEMU进程的虚拟地址空间的一部分作为虚拟机的物理地址。但该方案有一个问题:
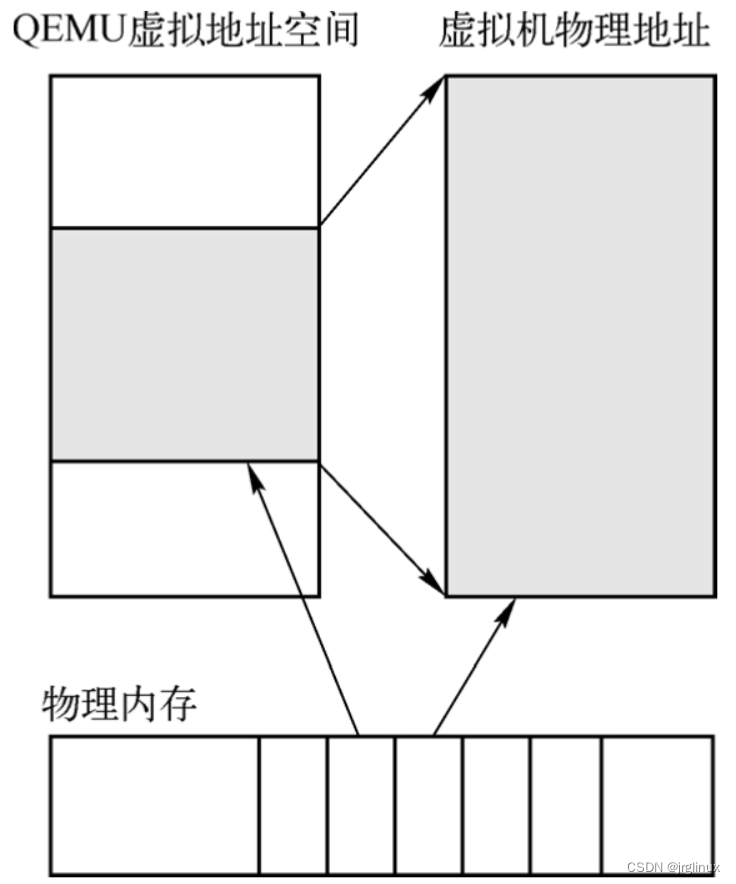
在物理机上,CPU对内存的访问在保护模式下是通过分段分页实现的,在该模式下,CPU访问时使用的是虚拟地址,必须通过硬件MMU进行转换,将虚拟地址转换成物理地址才能够访问到实际的物理内存:
显然,在虚拟机内部,其也是访问的虚拟地址,要想让其访问到实际的物理内存,必须先将这个地址转换成虚拟机的物理地址,然后将物理地址转换成QEMU的虚拟地址,最后将QEMU的虚拟地址转换成物理机上的物理地址,才能访问到数据。这就引出MMU的虚拟化。
EPT(Extended Page Table),VMX架构引入了EPT(Extended Page Table, 扩展页表)机制来实现VM物理地址空间的隔离, EPT机制实现原理与x86/x64的分页机制是一致的。当guest软件发出指令访问内存时, guest最终生成GPA(Guest-Physical Address)。EPT页表结构定义在host端, 处理器接受到guest传来的guest-physical address后, 通过EPT页表结构转换为HPA(Host-physical address), 从而访问平台上的物理地址。
纯软MMU
在CPU没有支持EPT之前,通过影子页表(Shadow Page Table)来实现虚拟机地址到host主机物理地址的转换。效率较低,KVM中维护影子页表。
支持EPT
EPT方案中,CPU的寻址模式在VM non-root operation下会发生变化,其会使用两个页表。
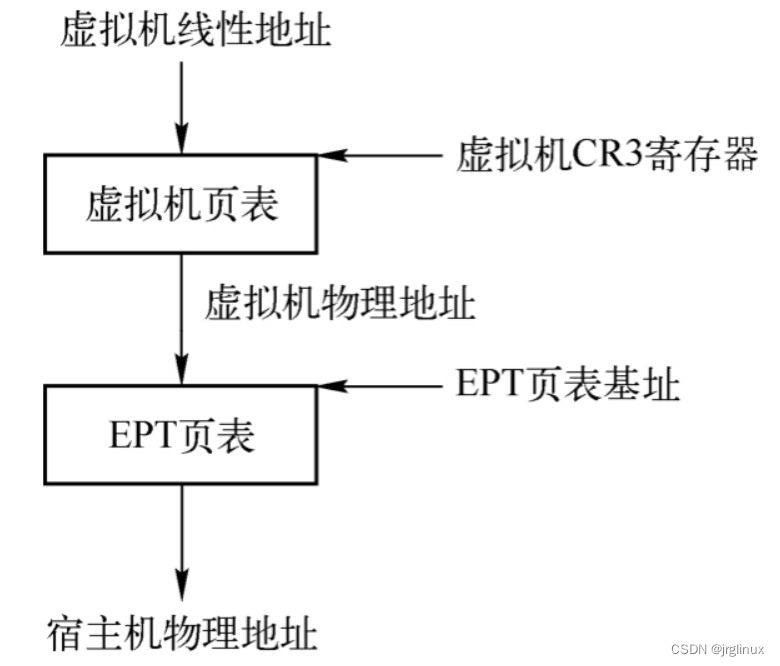
如果开启EPT,当CPU进行VM Entry时,会使用EPT功能,虚拟机对内部自身页表有着完全的控制,CPU先将虚拟机内部的虚拟地址转换为虚拟机物理地址,通过这个过程查找虚拟机内部页表,然后CPU会将这个地址转换为宿主机的物理地址,通过这个过程查找宿主机中的EPT页表。当CPU产生VM Exit时,EPT会关闭,这个时候CPU在宿主机上又会按照传统的单页表方式寻址。虚拟机中的页表就像物理机操作系统页表一样,页表里面保存的是虚拟机物理地址,由自己维护,EPT页表则由宿主机维护,里面记录着虚拟机物理地址到宿主机的物理地址的转换。
QEMU内存虚拟化初始化
基本数据结构
AddressSpace结构体,用来表示一个虚拟机或者虚拟CPU能够访问的所有物理地址。注意这里的访问和能够访问是两回事,与进程的地址空间一样,一个进程的虚拟地址空间为4GB(32位下),这并不是说操作系统需要为进程分配这么大的空间。同样,QEMU中的AddressSpace表示的是一段地址空间,整个系统可以有一个全局的地址空间,CPU可以有自己的地址空间视角,设备也可以有自己的地址空间视角。
/**
* struct AddressSpace: describes a mapping of addresses to #MemoryRegion objects
*/
struct AddressSpace {
/* private: */
struct rcu_head rcu;
char *name;
MemoryRegion *root;
/* Accessed via RCU. */
struct FlatView *current_map;
int ioeventfd_nb;
struct MemoryRegionIoeventfd *ioeventfds;
QTAILQ_HEAD(, MemoryListener) listeners;
QTAILQ_ENTRY(AddressSpace) address_spaces_link;
};
QEMU的其他子系统可以注册地址空间变更的事件,所有注册的信息都通过listeners连接起来。所有的AddressSpace通过address_spaces_link这个node连接起来,链表头是address_spaces。
内存管理中另一个结构是MemoryRegion,它表示的是虚拟机的一段内存区域。MemoryRegion是内存模拟中的核心结构,整个内存的模拟都是通过MemoryRegion构成的无环图完成的,图的叶子节点是实际分配给虚拟机的物理内存或者是MMIO,中间的节点则表示内存总线,内存控制器是其他MemoryRegion的别名。
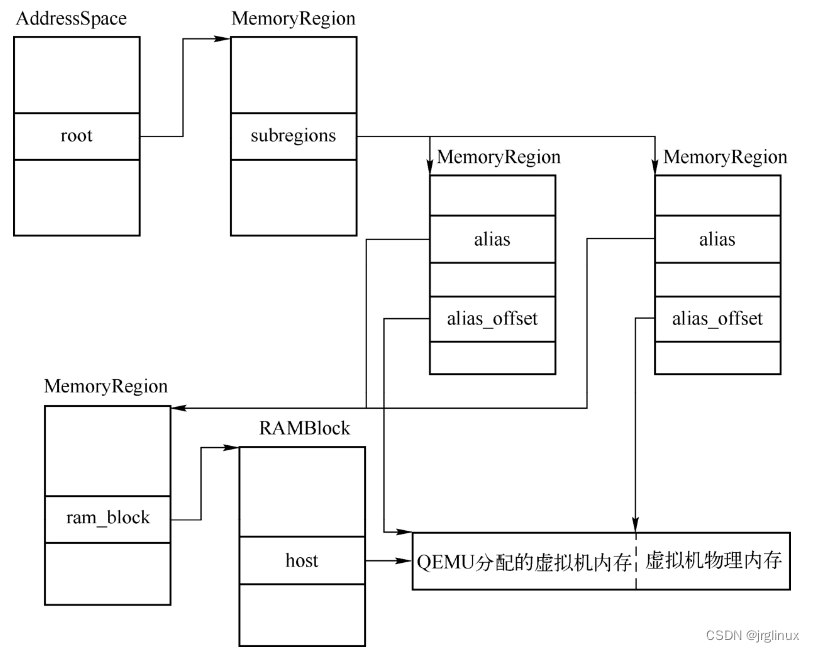
struct MemoryRegion {
Object parent_obj;
/* private: */
/* The following fields should fit in a cache line */
bool romd_mode;
bool ram;
bool subpage;
bool readonly; /* For RAM regions */
bool nonvolatile;
bool rom_device;
bool flush_coalesced_mmio;
uint8_t dirty_log_mask;
bool is_iommu;
RAMBlock *ram_block;
Object *owner;
const MemoryRegionOps *ops;
void *opaque;
MemoryRegion *container;
Int128 size;
hwaddr addr;
void (*destructor)(MemoryRegion *mr);
uint64_t align;
bool terminates;
bool ram_device;
bool enabled;
bool warning_printed; /* For reservations */
uint8_t vga_logging_count;
MemoryRegion *alias;
hwaddr alias_offset;
int32_t priority;
QTAILQ_HEAD(, MemoryRegion) subregions;
QTAILQ_ENTRY(MemoryRegion) subregions_link;
QTAILQ_HEAD(, CoalescedMemoryRange) coalesced;
const char *name;
unsigned ioeventfd_nb;
MemoryRegionIoeventfd *ioeventfds;
RamDiscardManager *rdm; /* Only for RAM */
};
QEMU虚拟内存初始化
虚拟机虚拟化内存是在/hw/i386/pc_piix.c中进行的,内存分为低端内存和高端内存,之所以会有这个区分是因为一些有传统设备的虚拟机,其设备必须使用一些地址空间在4GB以下的内存。
/* PC hardware initialisation */
static void pc_init1(MachineState *machine,
const char *host_type, const char *pci_type)
{
...
if (!pcms->max_ram_below_4g) {
pcms->max_ram_below_4g = 0xe0000000; /* default: 3.5G */
}
lowmem = pcms->max_ram_below_4g;
if (machine->ram_size >= pcms->max_ram_below_4g) {
if (pcmc->gigabyte_align) {
if (lowmem > 0xc0000000) {
lowmem = 0xc0000000;
}
if (lowmem & (1 * GiB - 1)) {
warn_report("Large machine and max_ram_below_4g "
"(%" PRIu64 ") not a multiple of 1G; "
"possible bad performance.",
pcms->max_ram_below_4g);
}
}
}
if (machine->ram_size >= lowmem) {
x86ms->above_4g_mem_size = machine->ram_size - lowmem;
x86ms->below_4g_mem_size = lowmem;
} else {
x86ms->above_4g_mem_size = 0;
x86ms->below_4g_mem_size = machine->ram_size;
}
...
}
KVM内存虚拟化
虚拟机MMU初始化
VMCS中VM execution区域里的secondary processor-based VM-execution control字段的第二位用来表示是是否开启EPT,在KVM初始化的时候会调用架构相关的hardware_setup函数,hardware_setup函数会调用setup_vmcs_config,在其中读取MSR_IA32_VMX_PROCBASED_CTLS2,将寄存器存放在vmcs_conf->cpu_based_2nd_exec_ctrl中。
KVM在创建VCPU的过程中会创建虚拟机MMU,具体是在函数kvm_arch_vcpu_init中调用kvm_mmu_create。
int kvm_mmu_create(struct kvm_vcpu *vcpu)
{
uint i;
int ret;
vcpu->arch.mmu_pte_list_desc_cache.kmem_cache = pte_list_desc_cache;
vcpu->arch.mmu_pte_list_desc_cache.gfp_zero = __GFP_ZERO;
vcpu->arch.mmu_page_header_cache.kmem_cache = mmu_page_header_cache;
vcpu->arch.mmu_page_header_cache.gfp_zero = __GFP_ZERO;
vcpu->arch.mmu_shadow_page_cache.gfp_zero = __GFP_ZERO;
vcpu->arch.mmu = &vcpu->arch.root_mmu;
vcpu->arch.walk_mmu = &vcpu->arch.root_mmu;
vcpu->arch.root_mmu.root_hpa = INVALID_PAGE;
vcpu->arch.root_mmu.root_pgd = 0;
vcpu->arch.root_mmu.translate_gpa = translate_gpa;
for (i = 0; i < KVM_MMU_NUM_PREV_ROOTS; i++)
vcpu->arch.root_mmu.prev_roots[i] = KVM_MMU_ROOT_INFO_INVALID;
vcpu->arch.guest_mmu.root_hpa = INVALID_PAGE;
vcpu->arch.guest_mmu.root_pgd = 0;
vcpu->arch.guest_mmu.translate_gpa = translate_gpa;
for (i = 0; i < KVM_MMU_NUM_PREV_ROOTS; i++)
vcpu->arch.guest_mmu.prev_roots[i] = KVM_MMU_ROOT_INFO_INVALID;
vcpu->arch.nested_mmu.translate_gpa = translate_nested_gpa;
ret = alloc_mmu_pages(vcpu, &vcpu->arch.guest_mmu);
if (ret)
return ret;
ret = alloc_mmu_pages(vcpu, &vcpu->arch.root_mmu);
if (ret)
goto fail_allocate_root;
return ret;
fail_allocate_root:
free_mmu_pages(&vcpu->arch.guest_mmu);
return ret;
}
EPT表的创建
EPT的缺页处理是由函数tdp_page_fault完成的。当虚拟机内部进行内存访问的时候,MMU首先会根据虚拟机操作系统的页表把GVA转换成GPA,然后根据EPT页表把GPA转换成HPA,这就是所谓的两级页表转换,也就是tdp(two dimission page)的来源。GVA转换为GPA的过程中,如果发生缺页异常,这个异常会由虚拟机操作系统内核处理;GPA转换成HPA的过程中,如果发生缺页异常,虚拟机会产生退出,并且退出原因为EXIT_REASON_EPT_VIOLATION,其对应的处理函数为handle_ept_violation,这个函数就会调用tdp_page_fault来完成缺页异常的处理。
vcpu_enter_guest函数会完成虚拟机的进入和退出,函数最后调用架构相关的handle_exit回调函数,Intel CPU对应的是vmx_handle_exit,该函数会根据退出原因调用kvm_vmx_exit_handlers函数表中的一个函数,EPT异常会调用handle_ept_violation。
static int (*kvm_vmx_exit_handlers[])(struct kvm_vcpu *vcpu) = {
...
[EXIT_REASON_GDTR_IDTR] = handle_desc,
[EXIT_REASON_LDTR_TR] = handle_desc,
[EXIT_REASON_EPT_VIOLATION] = handle_ept_violation,
[EXIT_REASON_EPT_MISCONFIG] = handle_ept_misconfig,
...
};
static int handle_ept_violation(struct kvm_vcpu *vcpu)
{
unsigned long exit_qualification;
gpa_t gpa;
u64 error_code;
exit_qualification = vmx_get_exit_qual(vcpu);
if (!(to_vmx(vcpu)->idt_vectoring_info & VECTORING_INFO_VALID_MASK) &&
enable_vnmi &&
(exit_qualification & INTR_INFO_UNBLOCK_NMI))
vmcs_set_bits(GUEST_INTERRUPTIBILITY_INFO, GUEST_INTR_STATE_NMI);
gpa = vmcs_read64(GUEST_PHYSICAL_ADDRESS);
trace_kvm_page_fault(gpa, exit_qualification);
...[省略]
vcpu->arch.exit_qualification = exit_qualification;
if (unlikely(allow_smaller_maxphyaddr && kvm_mmu_is_illegal_gpa(vcpu, gpa)))
return kvm_emulate_instruction(vcpu, 0);
return kvm_mmu_page_fault(vcpu, gpa, error_code, NULL, 0);
}
MMIO机制
在x86下访问设备的资源有两种方式:一种是通过Port I/O,即PIO;另一种是通过MemoryMapped I/O,即MMIO。虚拟机的VMCS中定义了两个IO bitmap,共2页,总共有4096×8×2=65536个位,每一个位如果进行了置位则表示虚拟机对该端口的读写操作会退出到KVM,KVM可以自己处理这些PIO的请求,但是更多时候KVM会将对PIO的请求分派到QEMU,这就是PIO的实现机制。那么MMIO应该怎么实现呢?答案是EPT。MMIO的机制简单介绍如下。
1)QEMU申明一段内存作为MMIO内存,这不会导致实际QEMU进程的内存分配。
2)SeaBIOS会分配好所有设备MMIO对应的基址。
3)当Guest第一次访问MMIO的地址时候,会发生EPT violation,产生VM Exit。
4)KVM创建一个EPT页表,并设置页表项特殊标志。
5)虚拟机之后再访问对应的MMIO地址的时候就会产生EPT misconfig,从而产生VM Exit,退出到KVM,然后KVM负责将该事件分发到QEMU。
虚拟机脏页跟踪
开启EPT并建立EPT的页表后,虚拟机中对内存的访问都是通过两级页表完成的,这是在硬件中自动完成的。但是有的时候需要知道虚拟的物理内存中有哪些内存被改变了,也就是记录虚拟机写过的内存,写过的内存叫作内存脏页,记录写过的脏页情况叫作内存脏页跟踪,脏页跟踪是热迁移的基础。热迁移能够将虚拟机从一台宿主机(源端)迁移到另一台宿主机(目的端)上,并且对客户机的影响极小,迁移过程主要就是将虚拟机的内存页迁移到目的端,在热迁移进行内存迁移的同时,虚拟机会不停地写内存,如果虚拟机在QEMU迁移了该页之后又对该页写入了新数据,那么QEMU就需要重新迁移该页,所以QEMU需要跟踪虚拟机的脏页情况。
脏页跟踪的实现
应用层软件QEMU在需要进行脏页跟踪时,会设置memslot的flags为KVM_MEM_LOG_DIRTY_PAGES,在__kvm_set_memory_region函数中,当检测到这个标识设置的时候,会调用kvm_create_dirty_bitmap创建一个脏页位图。
int __kvm_set_memory_region(struct kvm *kvm,
const struct kvm_userspace_memory_region *mem)
{
...
/* Allocate/free page dirty bitmap as needed */
if (!(new.flags & KVM_MEM_LOG_DIRTY_PAGES))
new.dirty_bitmap = NULL;
else if (!new.dirty_bitmap) {
r = kvm_alloc_dirty_bitmap(&new);
if (r)
return r;
...
}
EXPORT_SYMBOL_GPL(__kvm_set_memory_region);
static int kvm_alloc_dirty_bitmap(struct kvm_memory_slot *memslot)
{
unsigned long dirty_bytes = 2 * kvm_dirty_bitmap_bytes(memslot);
memslot->dirty_bitmap = kvzalloc(dirty_bytes, GFP_KERNEL_ACCOUNT);
if (!memslot->dirty_bitmap)
return -ENOMEM;
return 0;
}
kvm_alloc_dirty_bitmap()分配的空间是实际的2倍。
当应用层需要知道虚拟机的内存访问情况时,调用虚拟机所属ioctl(KVM_GET_DIRTY_LOG)可以得到脏页位图。KVM中对这个ioctl的处理函数是kvm_vm_ioctl_get_dirty_log,该函数调用kvm_get_dirty_log_protect来完成实际工作。QEMU每次调用ioctl(KVM_GET_DIRTY_LOG)都能够获得虚拟机上一次进行该调用之后到现在之间的脏页情况。