目录
1 选择排序
1.1 原理
1.2 具体步骤
1.3 代码实现
1.4 优化
2 冒泡排序
2.1 原理
2.2 具体步骤
2.3 代码实现
2.4 优化
3 插入排序
3.1 原理
3.2 具体步骤
3.3 代码实现
3.4 优化
4. 快速排序
4.1 原理
4.2 具体步骤
4.3 代码实现
4.4 优化
为了讲解方便,以下排完序后,统一为升序
1 选择排序
1.1 原理
核心思想是通过不断地选择未排序序列中的最小元素,然后将其放到已排序序列的末尾(或未排序列的起始位置)。
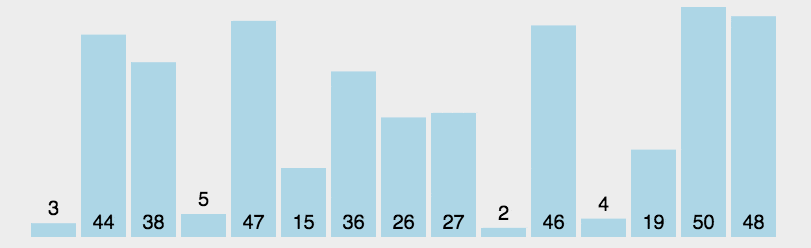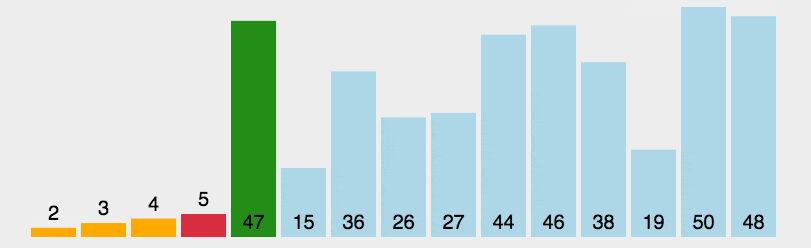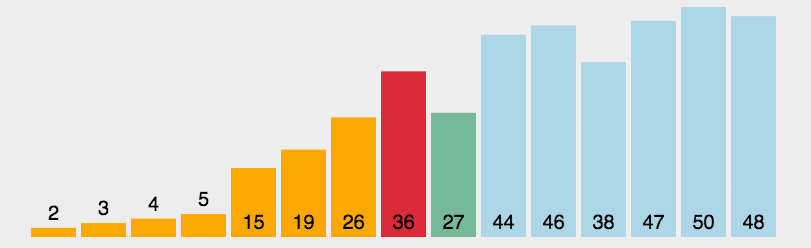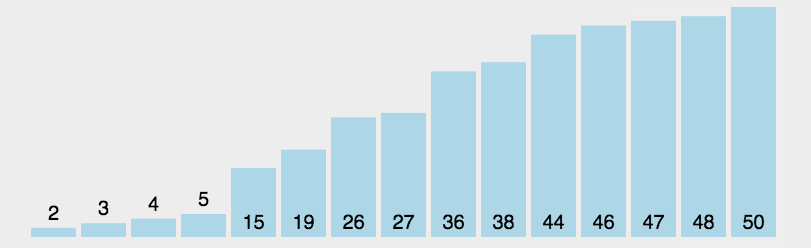
1.2 具体步骤
1. 初始状态:所有元素初始都为未排序状态
2 在未排序元素中,找到最小的那个元素的下标
3 与未排序的第一个元素(已排序的末尾元素)交换位置
4 循环 2 ~ 3,直到所有元素都变为已排了的元素
1.3 代码实现
代码实现的关键点:找下标,换位置,以及循环条件。同时也是容易出错的点。
#include<stdio.h>
void sort(int* p, int n)
{
for (int i = 0; i < n - 1; i++) // < n 也可以,只是无意义的重复,效率更低
{
int min = i; // 找出的最小值,最后要放的位置的下标
int j = i;
for (j = i + 1; j < n; j++) // 可以=i,只是=i,无意义。
{
if (p[min] > p[j])
min = j;
// for循环结束后,j会++
if (n - 1 == j)
break;
}
// 交换数据
int temp = p[i];
p[i] = p[min];
p[min] = temp;
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 选择排序
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
1.4 优化
原来一趟只找出最小值,现在一趟既找出最小值,也找出最大值,循环的次数就减半了。
#include<stdio.h>
void swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
}
void sort(int* p, int n)
{
// 循环趟数减半,可以了就要停止,不然就会继续换,反而无序
for (int i = 0; i <= n / 2 + 1; i++)
{
int min = i; // 找出的最小值的下标
int max = n -i - 1; // 找出的最大值的下标
int j = i;
for (j = i; j < n - i; j++)
{
if (p[min] > p[j])
min = j;
if (p[max] < p[j])
max = j;
if (n - 1 - i == j)
break;
}
// 交换数据
// 当最小值与最大值恰好位置相反,换两次=没换
if (!(p[min] == p[n - 1 - i] || p[i] == p[max]))
{
swap(&p[i], &p[min]);
swap(&p[n - 1 - i], &p[max]);
}
else
{
swap(&p[i], &p[n - 1 - i]);
}
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
int sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 选择排序优化
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}2 冒泡排序
2.1 原理
核心思想是通过重复交换相邻元素来实现排序。
类比选择排序,相当于从右往左开始排,每次在未排序中找出最大值,放在已排序的前一个位置。
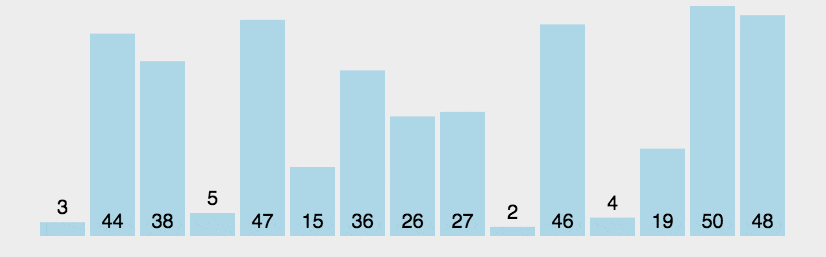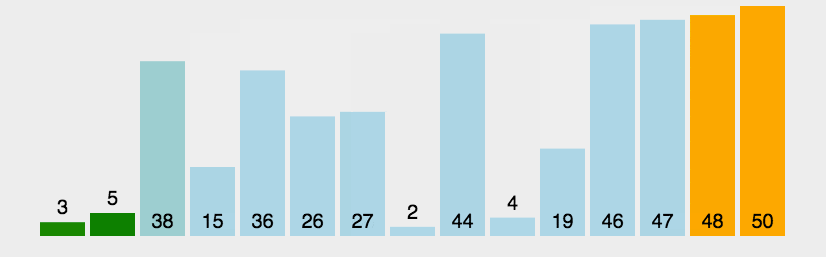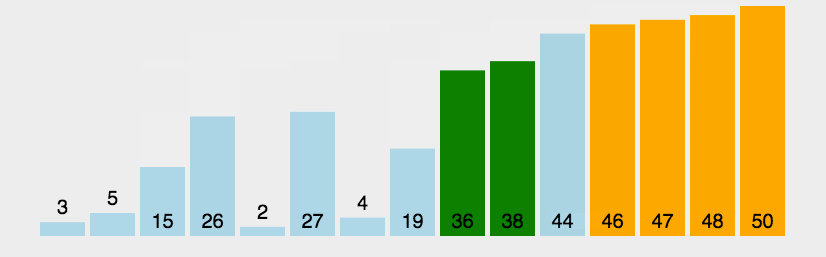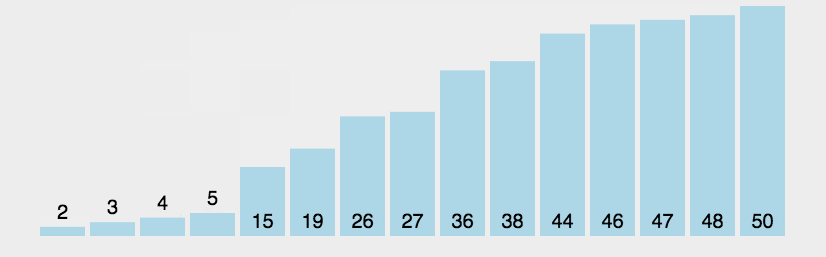
2.2 具体步骤
1. 从左往右相邻元素比较,让大的数不断右移
2. 循环1,直至每个已排序的元素 = 所有元素的个数
2.3 代码实现
关键点:循环条件的控制,以及交换(大的靠右)
#include<stdio.h>
void sort(int arr[], size_t sz)
{
for (int i = 0; i < sz - 1; i++)
{
// 在这里j可以 < sz - 1;
// 在本段代码中交换位置是有条件的
// < sz - 1;进去了也不会执行
// 选择排序从哪开始到哪结束就必须是那样
// 不可能在再在排了序中挑最大最小值
for (int j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 冒泡排序
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}2.4 优化
如果我们一开始拿到的数组就是有序的话,我们还是不得不执行那循环套循环,效率就很低。我们可以先假设已达到了有序状态,如果交换了,就通过修改flag的值来办,这样就可以提前跳出循环了。
#include<stdio.h>
void sort(int arr[], size_t sz)
{
for (int i = 0; i < sz - 1; i++)
{
// 假设已经到达了有序状态
int flag = 1;
for (int j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
// 交换了,说明无序
flag = 0;
}
}
if (flag)
{
break;
}
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 冒泡排序优化
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}3 插入排序
3.1 原理
核心思想是构建有序序列。将未排序的元素逐个插入到已排序的部分。
左边是已排序的,右边是未排序的。未排序的从左到右第一个,放到已排序列中开始交换,大的就右移,移到不能再移。
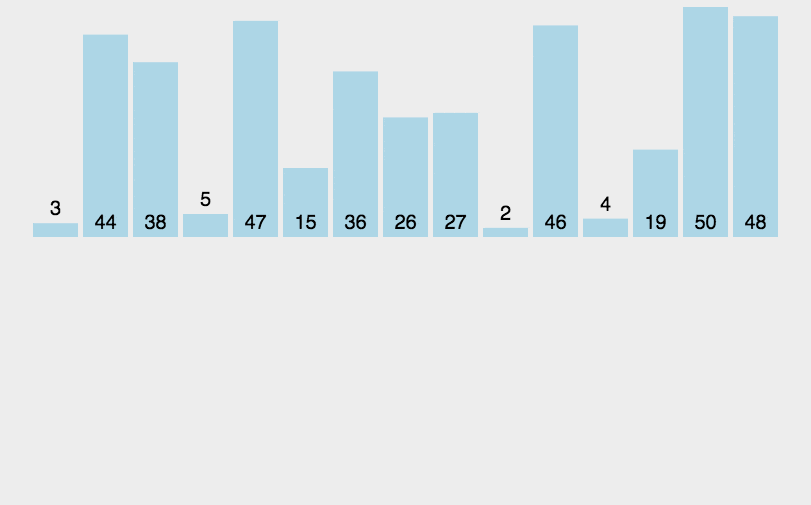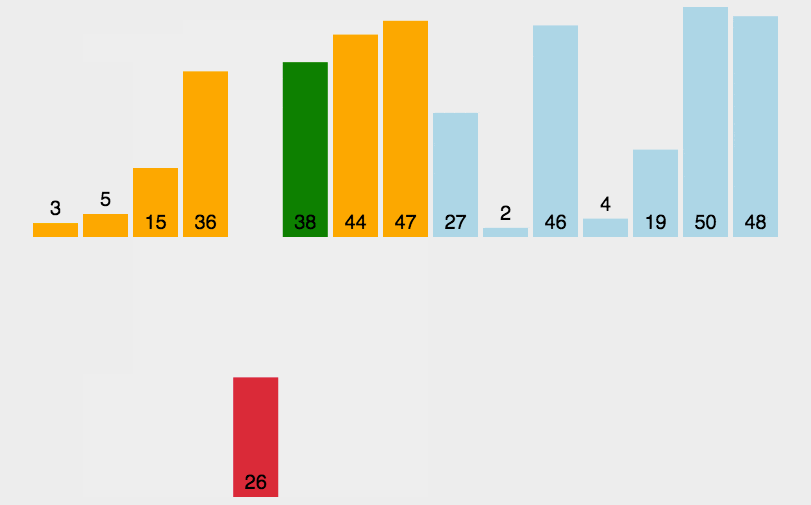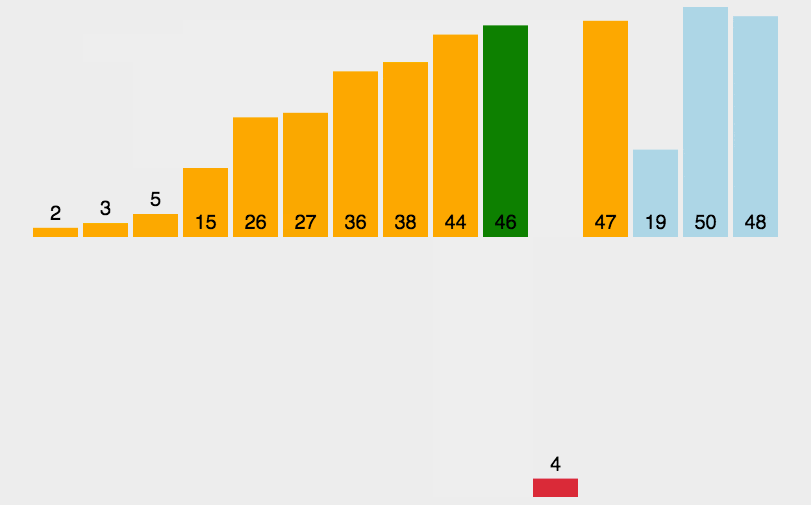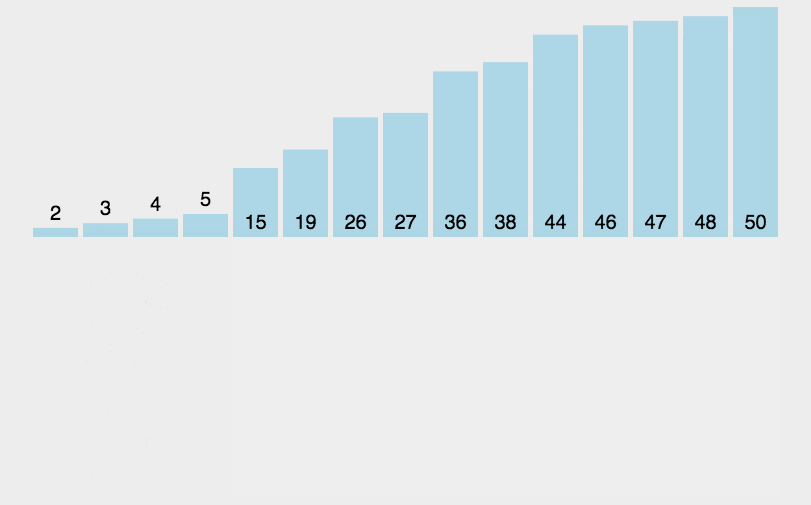
3.2 具体步骤
1. 初始化:左边第一个是已排序的,右边都是未排序的。
2 交换位置:未排序的第一个进入排序中,比较大小,大的右移,移到不能再移
3 循环 1 ~ 2,直到遍历数组中的所有元素
3.3 代码实现
关键点: 交换位置的意识,递推的意识
#include<stdio.h>
void sort(int arr[], size_t sz)
{
// 外层每一次循环都会让已排序的元素+1
for (int i = 1; i < sz; i++)
{
int j = i;
while (j >= 1 && arr[j] < arr[j - 1])
{
// 交换位置
arr[j - 1] = arr[j] ^ arr[j - 1];
arr[j] = arr[j] ^ arr[j - 1];
arr[j - 1] = arr[j] ^ arr[j - 1];
j--;
}
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 插入排序
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}3.4 优化
所谓优化算法就更接近于通俗意义上的插入,找到该插入的的地方,再进行插入。即对插入的位置实行二分查找。
#include<stdio.h>
// 返回值是该数插入进去后的下标
int find(int arr[], int sz)
{
// 1 2 4 5 7 8 9 6
int left = 0;
int right = sz - 1;
while (left < right)
{
// 防止陷入死循环
if (left == right)
break;
int mid = right + (left - right) / 2;
if (arr[mid] > arr[sz])
{
right = mid - 1;
}
else if (arr[mid] < arr[sz])
{
left = mid + 1;
}
else
{
right = left;
break;
}
}
if (arr[sz] < arr[right])
{
return right;
}
else
{
return right + 1;
}
}
void sort(int arr[], size_t sz)
{
for (int i = 1; i < sz; i++)
{
// 本质:二分查找 + 交换
int temp = arr[i]; // 将要排序的数暂时储存起来
// 二分查找找到应该插入的下标
int final_local = find(arr, i);
// 该右移的右移
for (int j = i - 1; j >= final_local; j--)
{
arr[j + 1] = arr[j];
}
arr[final_local] = temp;
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
sort(arr, sz); // 插入排序优化
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}4. 快速排序
4.1 原理
核心思想是分治法。一分为二,左边比某个基准数小,右边比某个基准数大,左边右边又一分为二,直至不可再分
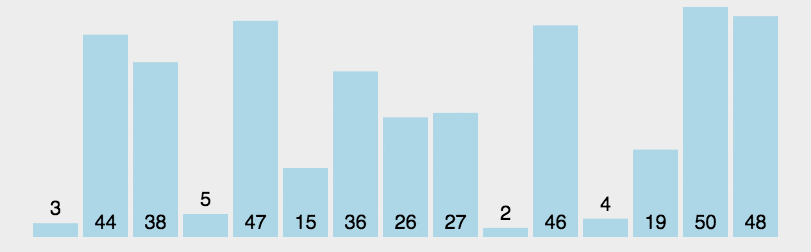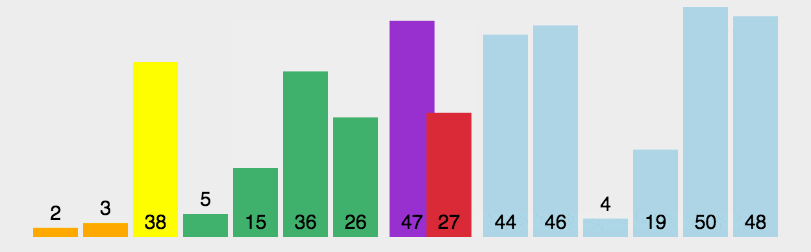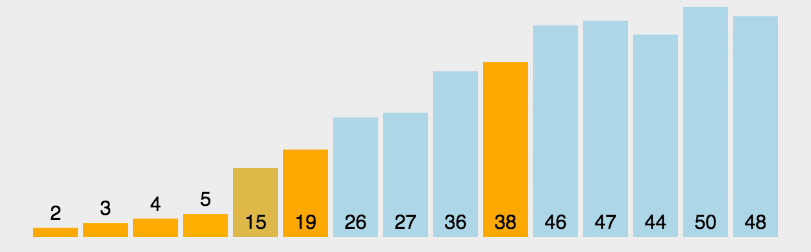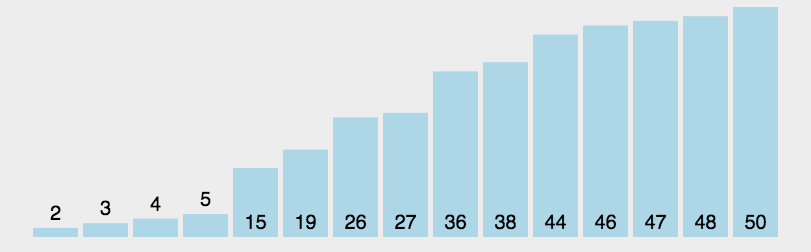
4.2 具体步骤
-
从数列中随便挑一个数作为基准数(我选的是最后一个数);
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。
-
递归地把小于基准值元素的子数列和大于基准值元素的子数列排序;
4.3 代码实现
关键点:递归的思想,函数要被调用,要写得一般一些
#include<stdio.h>
/*
函数功能:将最后一个元素作为基准数
小于它的放左边,大于它的放右边
返回值:基准数最后的位置
*/
int partition(int arr[], int start, int end)
{
// 遍历基准元素前的所有元素
for (int i = end - 1; i >= start; i--)
{
if (arr[i] > arr[end])
{
int temp = arr[i];
arr[i] = arr[end - 1];
arr[end - 1] = arr[end];
arr[end] = temp;
end -= 1;
}
}
return end;
// 2 1 3 2
}
void QuickSort(int arr[], int start, int end)
{
if (start < end)
{
// 函数最后返回的是排过后基准元素的位置
int pivot = partition(arr, start, end);
// 递推式的一分为二
QuickSort(arr, start, pivot - 1);
QuickSort(arr, pivot + 1, end);
}
}
int main()
{
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
// 以后还要调用,需写得一般一些
QuickSort(arr, 0, sz - 1); // 快速排序
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
4.4 优化
快速排序的效率在于其平均时间复杂度为O(nlogn),这使其成为实际应用中非常受欢迎的一种排序算法。然而,在最坏的情况下,其时间复杂度会退化到O(n^2),这通常发生在每次选择的基准都是最大或最小元素时。为了避免这种情况,可以采用随机选择基准或者三数取中等策略来优化快速排序的性能。下面演示随机选择的优化
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
/*
函数功能:将最后一个元素作为基准数
小于它的放左边,大于它的放右边
返回值:基准数最后的位置
*/
int partition(int arr[], int start, int end)
{
int end_temp = end;
end = rand() % (end - start) + start + 1;
// 把左边大的甩到右边
for (int i = end - 1; i >= start; i--)
{
if (arr[i] > arr[end])
{
int temp = arr[i];
arr[i] = arr[end - 1];
arr[end - 1] = arr[end];
arr[end] = temp;
end -= 1;
}
}
// 把右边小的甩到左边
for (int i = end + 1; i <= end_temp; i++)
{
if (arr[i] < arr[end])
{
int temp = arr[i];
arr[i] = arr[end + 1];
arr[end + 1] = arr[end];
arr[end] = temp;
end += 1;
}
}
return end;
// 2 1 3 2
}
void QuickSort(int arr[], int start, int end)
{
if (start < end)
{
// 函数最后返回的是排过后基准元素的位置
int pivot = partition(arr, start, end);
// 递推式的一分为二
QuickSort(arr, start, pivot - 1);
QuickSort(arr, pivot + 1, end);
}
}
int main()
{
srand((unsigned int)time(NULL));
int arr[] = { 9,6,8,-1,0,5,2,8 };
size_t sz = sizeof(arr) / sizeof(arr[0]);
// 以后还要调用,需写得一般一些
QuickSort(arr, 0, sz - 1); // 快速排序
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
感谢观看!!!









![[AIGC] JDK17中的Record类介绍](https://img-blog.csdnimg.cn/img_convert/b9a5b0ec992a0c4b0c17a97f4f805de4.jpeg)