1. IPv4数据报的结构
本结构遵循的是RFC 791规范,介绍了一个IPv4数据包头部的不同字段。
1.1 IPv4头部
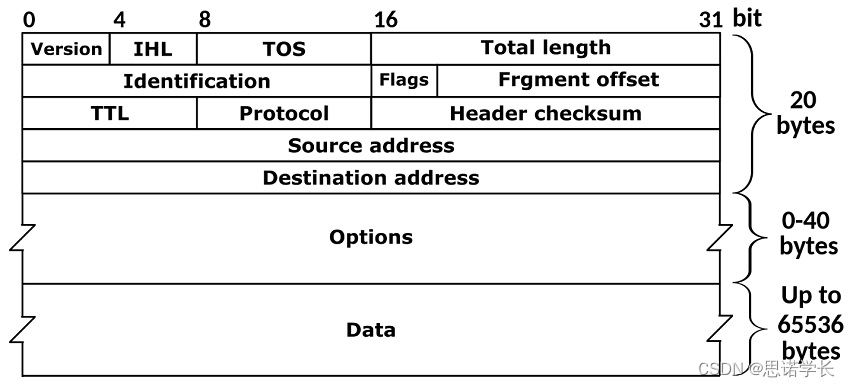
a. 版本(Version):指明了IP协议的版本,IPv4表示为4。
b. 头部长度(IHL, Internet Header Length):指明了头部的长度,以32位的字为单位。
c. 服务类型(Type of Service,简称ToS):指明了数据包的服务质量,它的设计目的是让发送者指明数据包的处理优先级和要求:
ToS的使用并不普遍,因为不是所有的网络设备都会利用这些信息。预置位可以被用于在网络中的路由器上标记流量,以便于流量管理和QoS(服务质量)。ToS位可以通过终端应用程序使用套接字API来设置,在Windows和Linux系统上都有相应的实现。在Linux系统上,还可以使用`iptables`命令根据不同的标准来设置这些位。ToS字段是RFC 1349中定义的,并且在后来的RFC 2474中被重新定义为“区分服务”(Differentiated Services,简称DiffServ)字段。在现代网络实践中,DiffServ已经变得更加常用,它为互联网流量提供了基于服务质量的分类。
e.服务类型字段的DiffServ(区分服务)版本:DiffServ通过使用DSCP(区分服务代码点)重定义了ToS字段,以提供网络流量的分类和优先级处理。DSCP占据了原始ToS字段的前六位,如下所示:
DSCP:这六位用来编码PHB(每跳行为),它是DiffServ架构的基础,定义了数据包在每个网络设备(如路由器)上的处理方式。
PHBs定义了不同的服务级别,例如:
Expedited Forwarding (EF):用于高优先级流量,如VoIP或实时视频会议,它保证低延迟、低丢包率和高可靠性。
Assured Forwarding (AF):提供一组PHBs,允许客户端获得保证的带宽。
Best Effort:是传统的互联网服务模型,数据包没有优先级,尽最大努力交付,但不保证。
Network Control:用于网络控制流量,如路由器之间的路由协议交换信息。
DSCP使得网络运营商可以实现复杂的QoS策略,以优化网络流量并保证服务质量。这些设置通常在网络设备上配置,并可以基于业务要求来优先处理或限制流量。这种服务质量的区分对于维护网络性能和处理高优先级的流量至关重要。
f.总长度(Total Length):整个数据包的长度,包括头部和数据。
g.标识(Identification)、标志(Flags)、片偏移(Fragment Offset):这些字段与IP分段有关,用于重组分段的数据包。
h.生存时间(TTL, Time to Live):数据包在网络中的生存时间,每经过一个路由器减一。
i.协议(Protocol):指明了数据包携带的上层协议类型,例如TCP或UDP。
j.头部校验和(Header Checksum):用于检测头部信息是否在传输过程中被篡改。
k.源地址(Source Address)和目的地址(Destination Address):发送方和接收方的IP地址。
l.选项(Options):可选字段,可用于各种控制和设置。
m. 数据(Data):实际传输的数据,也称为有效载荷。
IPv4头部为网络设备提供了必要的信息,以正确地传递数据包从源地址到目的地址。头部的每个字段都扮演特定的角色,例如,TTL防止数据包在网络中无限循环,而校验和则保证头部在传输中未被错误修改。
1.2 IPv4头部中的选项字段
这个字段用于提供额外的功能,例如进行路由选择和特殊处理。图中显示了选项字段的基本格式,包括类型(Type),长度(Longueur),和参数(Paramètres)。
选项类型:
LSR(Loose Source Routing):允许发送者指定数据包在到达目的地之前应该经过的一系列路由器。"松散"指的是数据包可以自由地在指定的路由器之间选择路径。
SSR(Strict Source Routing):与LSR类似,但路径更为严格,数据包必须严格按照发送者指定的路由器路径传递。
RR(Record Route):使数据包在通过每个路由器时记录其地址,允许发送者获取关于路径的信息。
时间戳:可以记录数据包到达每个路由器的时间。
IPv4的这些选项提供了灵活的路由和路径跟踪能力,虽然它们增加了头部的复杂性和处理时间,但在特定的网络诊断和路由优化场景中非常有用。
2. IPv4地址的类别
2.1 IPv4地址的传统类别
IPv4地址的传统类别系统,通过地址的前几位来识别不同的类别,从而定义了网络号和主机号的大小。这个系统包括了A、B、C三个主要类别,以及D类多播和E类未使用或实验性使用的特殊类别。
类别A:提供了128个网络,每个网络可以有约2^24个主机。
类别B:提供了2^14个网络,每个网络可以有2^16个主机。
类别C:提供了2^21个网络,每个网络可以有254个主机。
类别D:用于多播,支持一对多通信。
类别E:保留用于实验和测试。
这个系统由于其简单性在早期得到了广泛应用,但自1992年以来已经过时,并被无类别域间路由(CIDR)所取代。CIDR引入了更灵活的地址分配方法和子网掩码,使得网络管理员可以根据实际需要划分任意大小的地址块,从而更有效地利用IP地址空间。尽管如此,类别D的多播地址仍然被广泛用于特定的通信场景。
2.2 Pv4地址中的几种特殊地址及其用途
2.2.1 本地回环地址(Local Loopback Address)
127.0.0.1`是最著名的本地回环地址,用于网络软件测试以及系统自身通信。数据包发送到这个地址不会离开主机,而是直接由本地主机处理。
在Linux系统中,这个地址通常与`lo`(回环)接口关联。
2.2.2 私有地址(Private Addresses)
根据RFC 1918,有几个地址块被指定为私有地址,它们在私人网络内部使用,而不应该直接在互联网上路由。
私有地址范围包括:
10.0.0.0`到`10.255.255.255`(10/8前缀)
172.16.0.0`到`172.31.255.255`(172.16/12前缀)
192.168.0.0`到`192.168.255.255`(192.168/16前缀)
这些地址在互联网上不可路由,但可以在内部网络中自由使用。
2.2.3 网络地址转换(NAT)
即使是使用私有地址的设备也可以访问互联网,前提是它们通过执行NAT的网关或路由器进行连接。NAT可以将私有地址翻译成有效的公网地址,允许私有网络内的机器与互联网上的机器进行通信。
2.2.4 私有网络中的路由
私有地址在私有网络内部是可路由的,这意味着在同一私有网络内的设备可以相互通信,但这些地址不会被互联网路由器转发到外部网络。
私有地址和NAT技术的使用是因为IPv4地址数量的限制,这些技术可以有效地在没有足够公网地址的情况下扩展网络。
2.2.5 Pv4地址中用于广播的特殊地址及其使用方式
这段文字介绍了IPv4地址体系中用于广播的特殊地址类型。在计算机网络中,广播地址允许信息发送给网络上的所有设备。这里的内容包括:
局域网广播地址:`255.255.255.255`是一个特殊的地址,它被用来在本地网络上发送广播消息。当一个信息包发送到这个地址时,网络上的所有设备都会接收到这个信息包。
定向广播地址:这种类型的广播地址有一个特定的网络部分,而主机部分则全部设置为`255`。例如,在`192.168.100.0`网络中,`192.168.100.255`会被用作广播地址,用来发送给这个子网上的所有设备。
零主机部分的广播地址:在某些旧的系统中,广播地址可以是网络地址的零主机部分,例如`192.168.100.0`。这种做法在现代网络中很少使用,但在一些老旧的系统(如SUNOS-4操作系统)中可能还存在。
要点是,广播地址使得发送方能够发送单个数据包给同一网络上的多个接收方,但它可能会导致大量的网络流量。现代网络通常使用更有效的方法,如多播,来减少这种影响。
3. 如何定义一个网络的地址
具体包括两个部分:
3.1 标准网络掩码
网络掩码用来区分IP地址中的网络部分和主机部分。在IP地址中,网络部分的主机号设置为0。例如,在类C网络中,最后一个数字(八位组)为0,像`192.168.100.0`;在类B网络中,最后两个数字为0;而在类A网络中,最后三个数字为0。这种IP地址表示的是整个网络,而不是网络中的单个设备。
3.2 子网
子网是将一个较大的网络划分成更小的网络块。在子网地址中,网络地址部分可能包括原本属于主机号的一部分。比如,`192.168.100.32`可能是一个子网的网络地址。如果子网掩码是`255.255.255.224`,这意味着这个子网包括的地址从`192.168.100.32`到`192.168.100.63`。
子网掩码`255.255.255.224`告诉我们网络地址的哪些部分是网络部分,哪些是主机部分。这个子网掩码在二进制中表示如下:
11111111.11111111.11111111.11100000这里的`1`代表网络部分,`0`代表主机部分。最后8位中的前三位是网络部分,所以网络部分是`11100000`,这等于十进制中的224。
在IPv4地址中,主机部分是可变的,而网络部分是固定的。在`255.255.255.224`掩码中,最后8位有5位是可变的,因为它们是`0`:
00000 - 最小主机地址(这是子网地址)
...
11111 - 最大主机地址(这是广播地址)二进制的`00000`到`11111`等于十进制的0到31。但是,这些主机部分的数字加上子网的基础部分(在这个例子中是`192.168.100`),给出了可用的IP地址范围:
网络地址(通常不分配给设备)是`192.168.100.32`(`192.168.100` + `00000`的二进制即32的十进制)。
广播地址(也通常不分配给设备)是`192.168.100.63`(`192.168.100` + `11111`的二进制即31的十进制加上基础部分32)。
所以,可分配的主机地址从`192.168.100.33`(网络地址后的第一个地址)到`192.168.100.62`(广播地址前的最后一个地址)。
网络掩码帮助确定一个IP地址属于哪个子网,这对于路由器转发数据包到正确的目的地非常关键。简单来说,网络掩码是一个用于标识网络地址范围的系统,它定义了哪些IP地址属于同一个网络。
3.3 子网划分(subnetting)
用于将一个较大的网络划分为多个较小的子网络。下面是对您提到的子网划分21/53和C类地址示例的中文解释:
1. 扩展网络地址部分:在子网划分中,通过借用IP地址中主机部分的一些高位比特来扩展网络地址部分。这样做可以增加网络部分的长度,从而创建更多的子网络。
2. 举例说明:例如,在C类地址中,一个常见的子网掩码是255.255.255.224。这个子网掩码意味着IP地址的前27位被用作网络地址,剩下的5位用作主机地址。
3. 子网掩码的作用:子网掩码用于确定IP地址中哪些位属于网络地址,哪些位属于主机地址。在上述例子中,224(十进制)对应的二进制为1110 0000,表明IP地址的最后三位被用作网络地址的一部分。
4. 创建子网:这种方法允许将一个大网络划分成多个小网络,每个小网络被称为子网。每个子网都可以作为一个独立的网络来运行。
5. 子网间的连接:子网之间通常通过路由器相连,就像普通网络一样。路由器负责在不同子网之间转发数据。
6. 始终存在的子网掩码:在任何网络中,都会有一个子网掩码用来区分网络地址和主机地址。
7. 标准与非标准子网掩码:如果子网掩码没有扩展出原始地址类别的位数,则称为标准子网掩码。例如,对于C类地址,标准的子网掩码是255.255.255.0。
通过子网划分,网络管理员可以更有效地管理和分配IP地址,提高网络的安全性和效率。
3.4 现代IP地址管理
网络掩码(netmask)和无类别域间路由(CIDR,Classless Inter-Domain Routing)是现代IP地址管理的重要概念。以下是对这些概念的中文解释:
无类别地址:传统的IP地址系统按大小分为不同的类别(A、B、C等)。但在CIDR出现后,这种基于类别的划分方式已不再适用,CIDR允许更灵活、更有效的地址分配。
CIDR概念(RFC-1519):CIDR是一种用于创建更灵活、高效的IP地址分配方式的方法。它允许定义不同大小的网络,这比传统基于类别的方法更有效。
灵活的网络地址界限:使用CIDR时,IP地址中网络部分和主机部分之间的界限不再固定。这提供了对IP地址的更灵活、更优化的使用。
路由聚合:CIDR特别适合用于路由器的路由表中的路由聚合,从而减小路由表的大小并提高路由效率。
服务提供商的应用:CIDR允许服务提供商将地址子集分配给客户,这比分配基于类别的完整地址范围更高效。
指定网络掩码:使用CIDR时,必须明确指定网络掩码。网络掩码确定了IP地址中属于网络地址的部分。
传统表示法:网络掩码的传统表示方法可能类似于255.255.255.128,其中掩码代表25个比特(例如在此例中)。
CIDR表示法:CIDR表示法更简洁明了,使用“/[掩码比特数]”的格式。例如,“/25”表示IP地址的前25位用作网络地址。一个带有CIDR表示法的IP地址示例可能是192.168.100.128/25,表示前25位用于网络,剩余7位用于主机。
总之,CIDR是一种IP地址管理方法,提供了更大的灵活性和效率,特别是在IPv4地址日益稀缺的情况下显得尤为重要。








![[AIGC] JDK17中的Record类介绍](https://img-blog.csdnimg.cn/img_convert/b9a5b0ec992a0c4b0c17a97f4f805de4.jpeg)