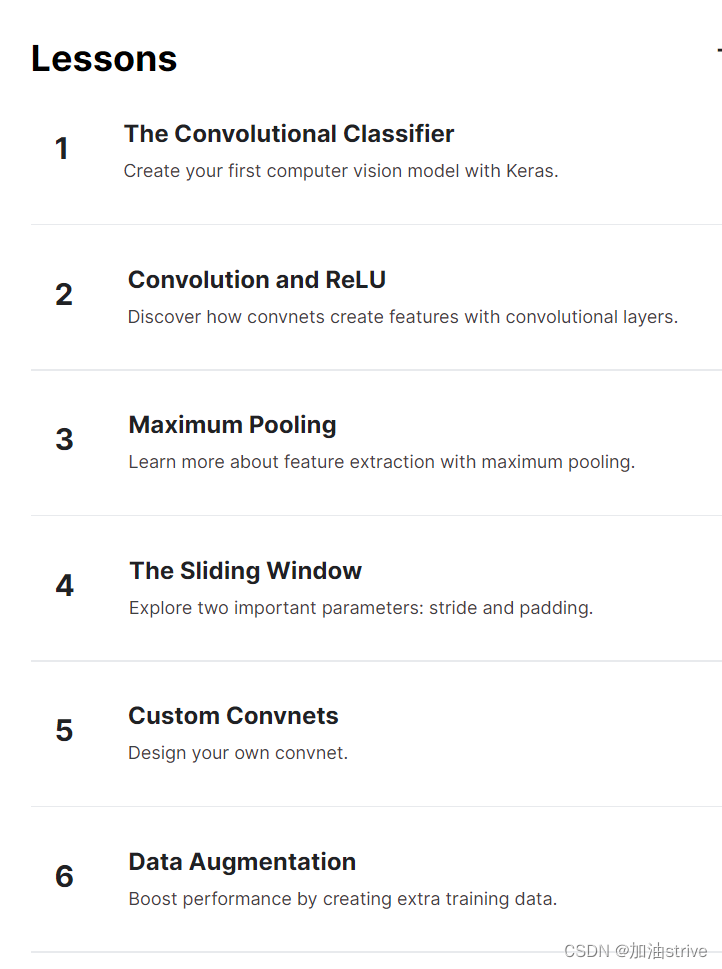
目录
- 1.The Convolutional Classifier
- 2.Convolution and ReLU
- 3.Maximum Pooling
- 4.The Sliding Window
- 5.Custom Convnets
- 6.Data Augmentation
1.The Convolutional Classifier
使用Keras创建第一个计算机视觉模型。
用于图像分类的网络由两部分组成:卷积层和密集层
卷积分类器
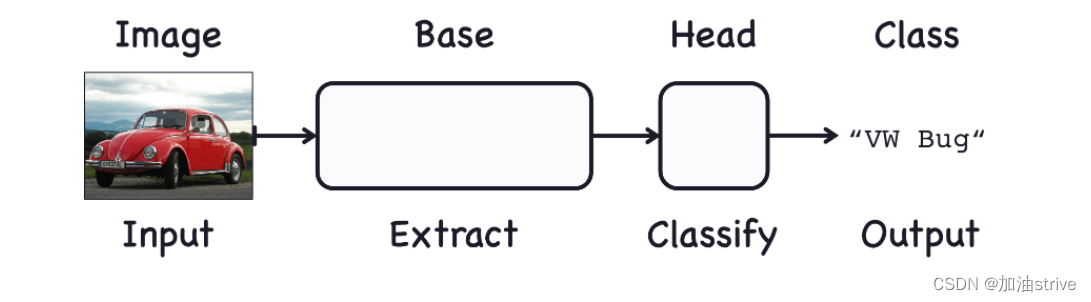
base使用的是卷积层,主要功能是提取特征
head使用的是密集层,主要功能是决定图片的分类
整个过程类似于下图:
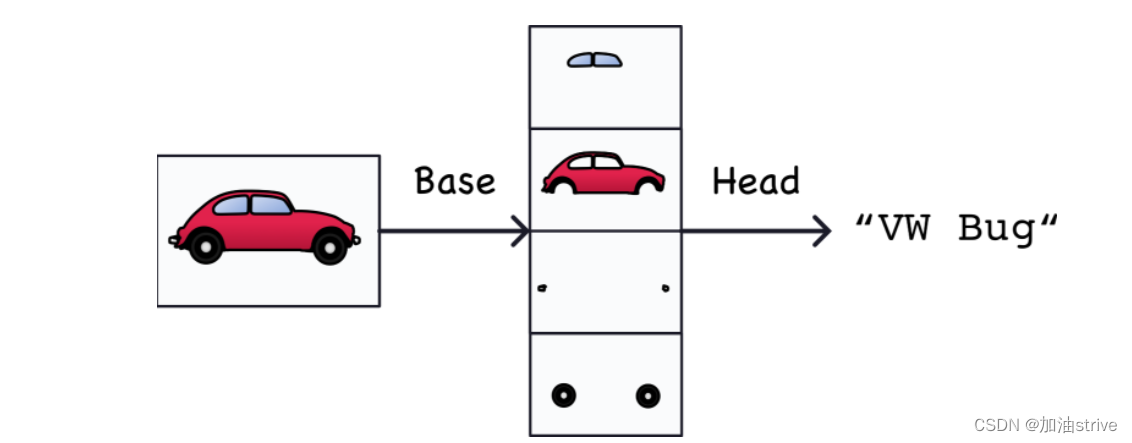
训练一个卷积分类器
Step 1 - Load Data
# Load training and validation sets
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# Data Pipeline
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
Step 2 - Define Pretrained Base
载入预训练的VGG16模型
pretrained_base = tf.keras.models.load_model(
'../input/cv-course-models/cv-course-models/vgg16-pretrained-base',
)
pretrained_base.trainable = False
Step 3 - Attach Head
pretrained_base所需要的是二维输入,
Dense层所需要的是一维输入
Flatten层将基底的二维输出转换为头部所需的一维输入。
如下所示:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
pretrained_base,
layers.Flatten(),
layers.Dense(6, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
Step 4 - Train
model.compile(
optimizer='adam', # 优化器
loss='binary_crossentropy', # 损失函数
metrics=['binary_accuracy'], # acc评价函数
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=30,
verbose=0,
)
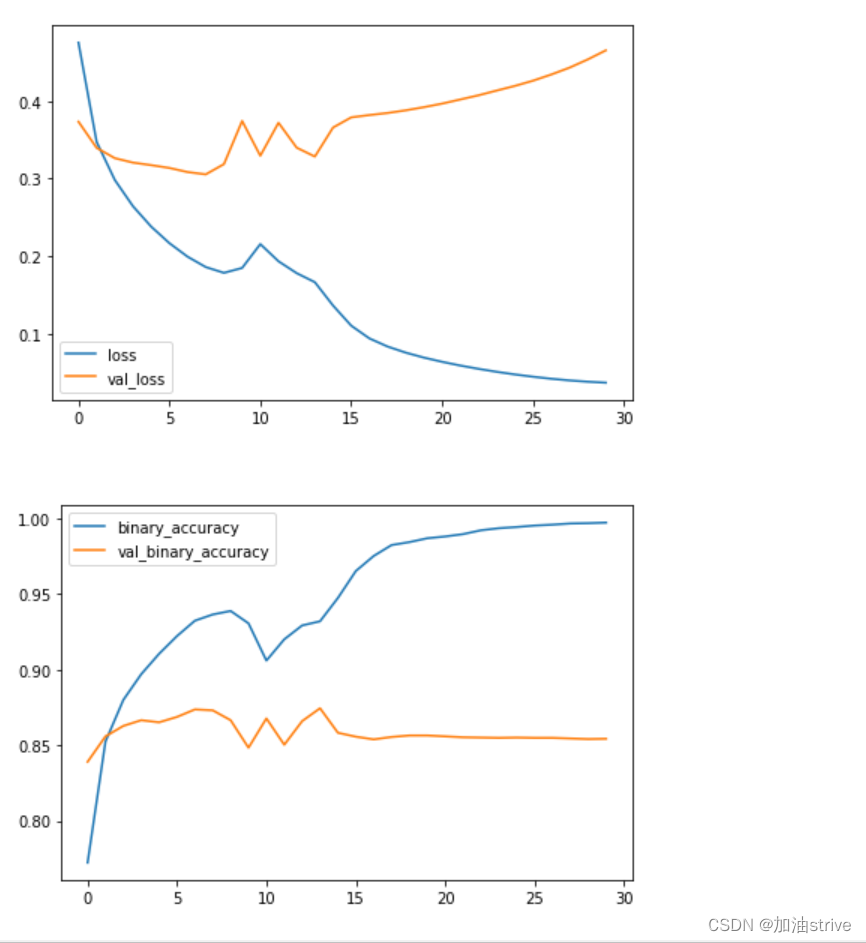
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();
2.Convolution and ReLU
在我们讨论卷积的细节之前,让我们讨论一下网络中这些层的用途。我们将了解如何使用这三个操作(卷积、ReLU和池化层)来实现特征提取过程。
卷积: Filter an image
Relu: Detect that feature
池化层:Condense the image (压缩)
类似于以下三个步骤:

Filter 卷积层:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
# More layers follow
])
我们可以通过查看这些参数与层的权重和激活函数关系来理解这些参数。
These weights we call kernels. We can represent them as small arrays:
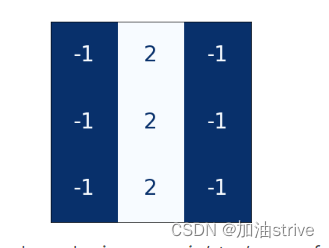
内核通过扫描图像并产生像素值的加权和来操作。通过这种方式,内核的作用有点像偏振透镜,强调或淡化某些信息模式。
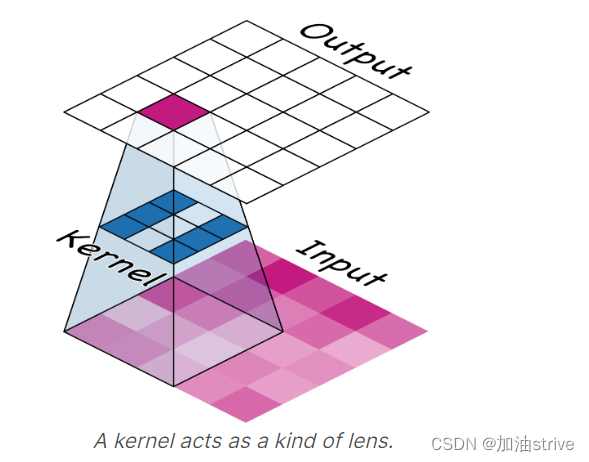
从内核中的数字模式,您可以知道它创建的特征图的类型。通常,卷积在其输入中强调的内容将与内核中正数的形状相匹配。
Detect ReLU层
ReLU特定的激活层中定义,但通常只将其作为Conv2D的激活函数。
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3, activation='relu')
# More layers follow
])
您可以将激活函数视为根据某种重要度量对像素值进行评分。ReLU激活表示负值不重要,因此将其设置为0。
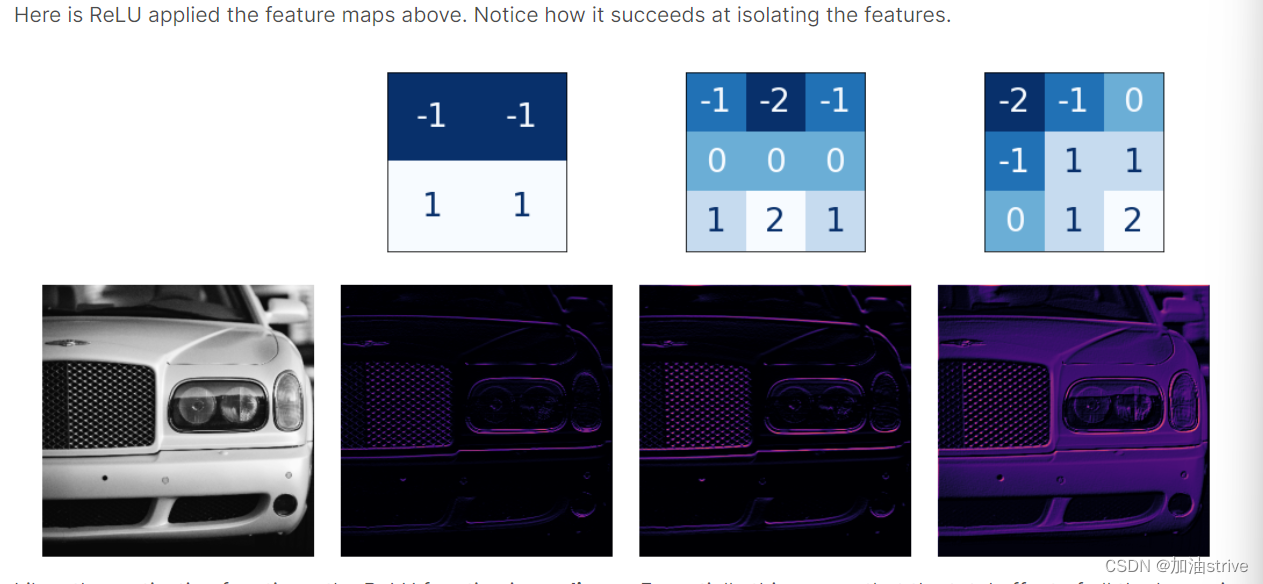
与其他激活函数一样,ReLU函数是非线性的。本质上,这意味着网络中所有层的总效果变得不同于仅将这些效果相加所获得的效果。非线性确保特征在深入网络时以有趣的方式组合。
Example - Apply Convolution and ReLU
import tensorflow as tf
import matplotlib.pyplot as plt
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
image_path = '../input/computer-vision-resources/car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.show();

你可以用tf.constant定义它,就像你用np.array定义Numpy中的数组一样。这会创建TensorFlow使用的张量。
import tensorflow as tf
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
])
plt.figure(figsize=(3, 3))
show_kernel(kernel)
TensorFlow在其tf.nn模块中包含许多由神经网络执行的常见操作。我们将使用的两个是conv2d和relu。这些只是Keras层的函数版本。
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
# we'll talk about these two in lesson 4!
strides=1,
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_filter))
# 并删除所有维度为1的维度
plt.axis('off')
plt.show();

image_detect = tf.nn.relu(image_filter)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.show();

现在我们已经创建了一个功能图!像这样的图像是头部用来解决分类问题的。我们可以想象,某些特征可能更具汽车的特征,而其他特征则更具卡车的特征。在训练期间,convnet的任务是创建能够找到这些特征的内核。
我们在本课中看到了convnet用于执行特征提取的前两个步骤:使用Conv2D层过滤和使用relu激活进行检测。
3.Maximum Pooling
Condense with Maximum Pooling
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
layers.MaxPool2D(pool_size=2),
# More layers follow
])
请注意,在应用ReLU激活函数后,特征图最终会出现大量“死空间”,即仅包含0的大区域(图像中的黑色区域)。在整个网络中携带这种"死空间"将增加模型的大小,而不会添加太多有用的信息。相反,我们希望精简特征图,只保留最有用的部分——特征本身。
池化层作用如下图所示:
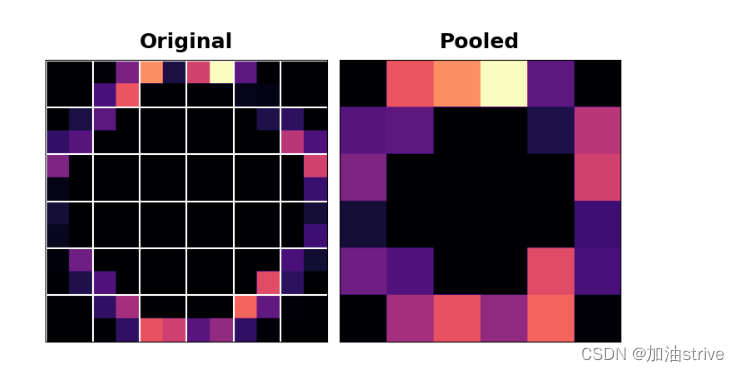
Example
import tensorflow as tf
image_condense = tf.nn.pool(
input=image_detect, # image in the Detect step above
window_shape=(2, 2),
pooling_type='MAX',
# we'll see what these do in the next lesson!
strides=(2, 2),
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.show();
应用卷积和ReLU激活函数是图片是这样的
(未应用池化层前)

应用池化层后是这样的

我们称零像素为“不重要”。这是否意味着它们根本不携带信息?事实上,零像素携带位置信息。空白区域仍将在图像中定位特征。当MaxPool2D删除其中一些像素时,它会删除要素地图中的一些位置信息。
具有最大池化的神经网络将倾向于 不通过其在图像中的位置 来区分特征。
观察当我们对以下功能图重复应用最大池时会发生什么。
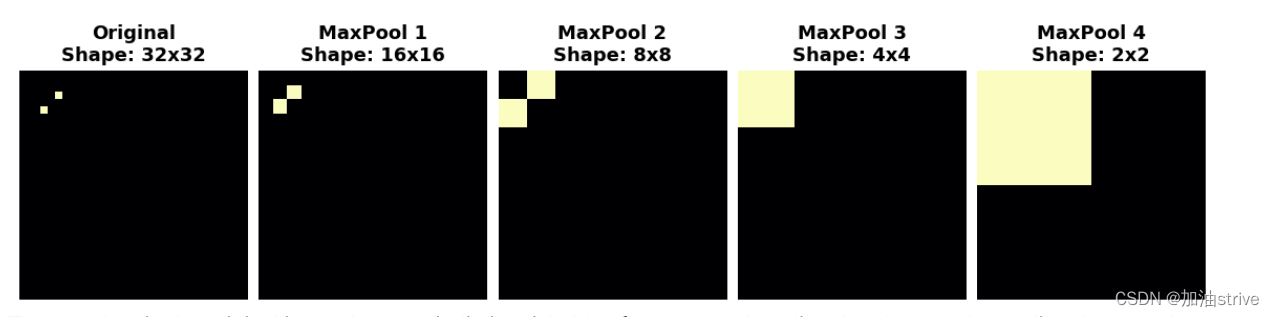
在重复池化之后,原始图像中的两个点变得无法区分。换句话说,池化效果破坏了他们的一些位置信息。由于网络不再能够在特征图中区分它们,因此它也无法在原始图像中区分它们:它已经对位置的差异不敏感。
事实上,池化效果就像图像中的两个点一样。开始时相距很远的特征在合并后将保持不同;只丢失了一些位置信息,但没有丢失全部位置信息。
这使得卷积网络比仅具有密集层的网络具有更大的效率优势。
4.The Sliding Window
卷积神经网络中两个重要的参数:stride and padding
stride
卷积和池运算有一个共同的特点:它们都是在滑动窗口上执行的。通过卷积,这个“窗口”由内核的维度,即参数kernel_size给出。对于池,它是池窗口,由pool_size给出。
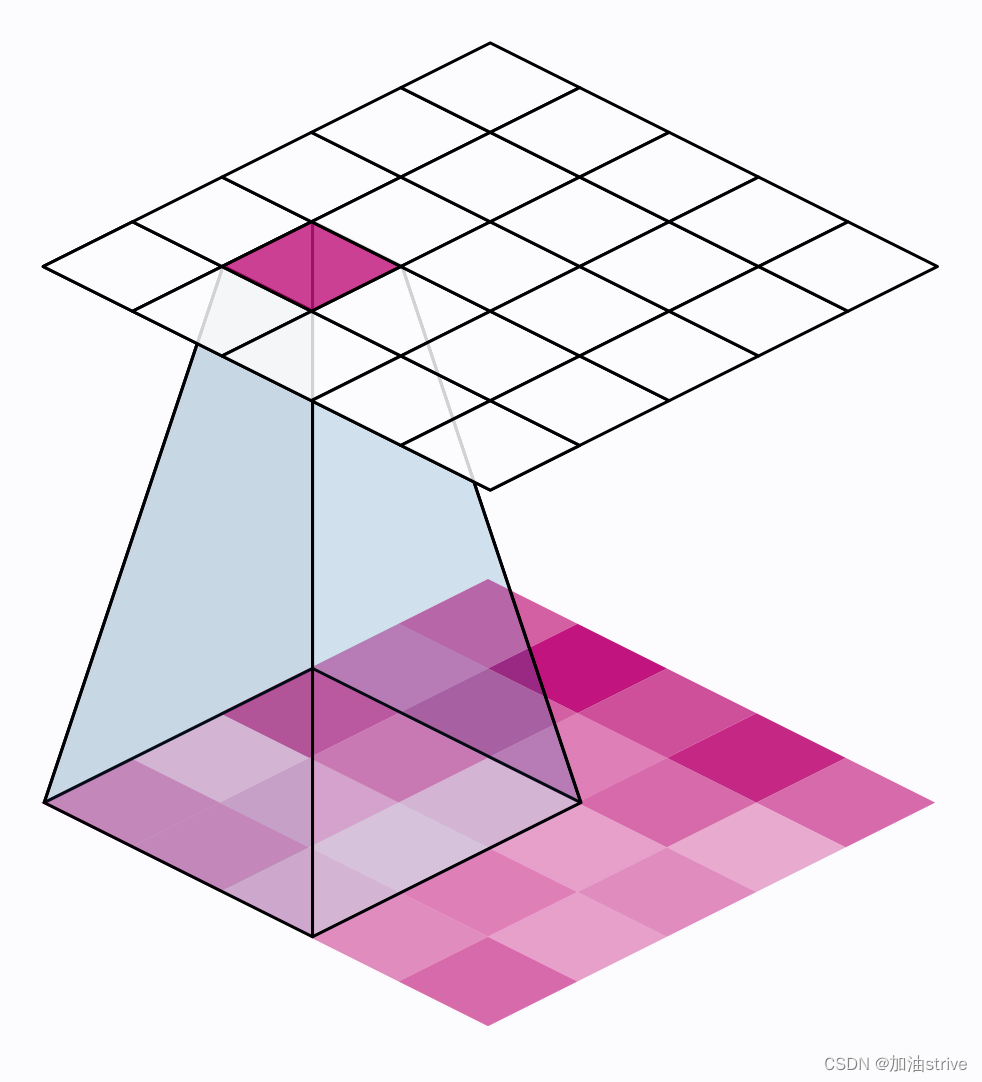
stride参数表示窗口在每一步应该移动多远,填充参数表示我们如何处理输入边缘的像素。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64,
kernel_size=3,
strides=1,
padding='same',
activation='relu'),
layers.MaxPool2D(pool_size=2,
strides=1,
padding='same')
# More layers follow
])
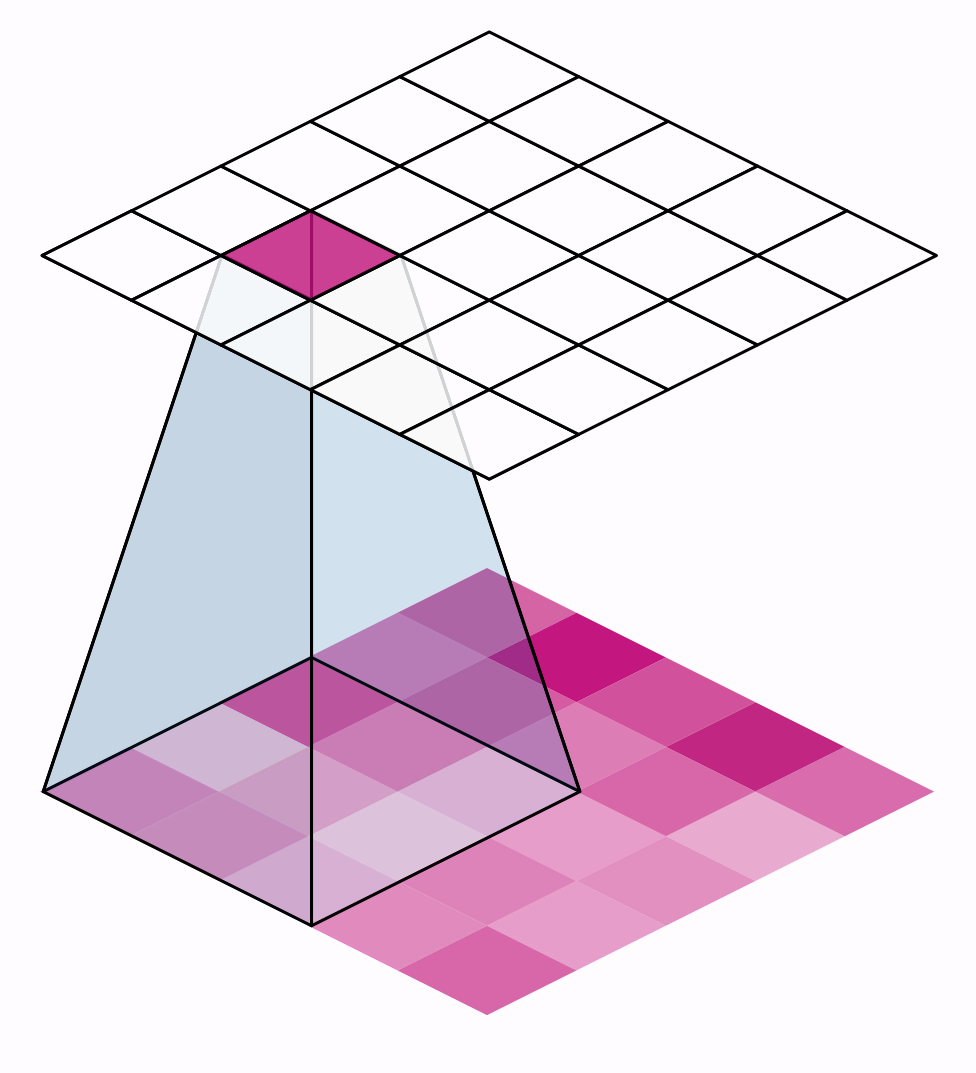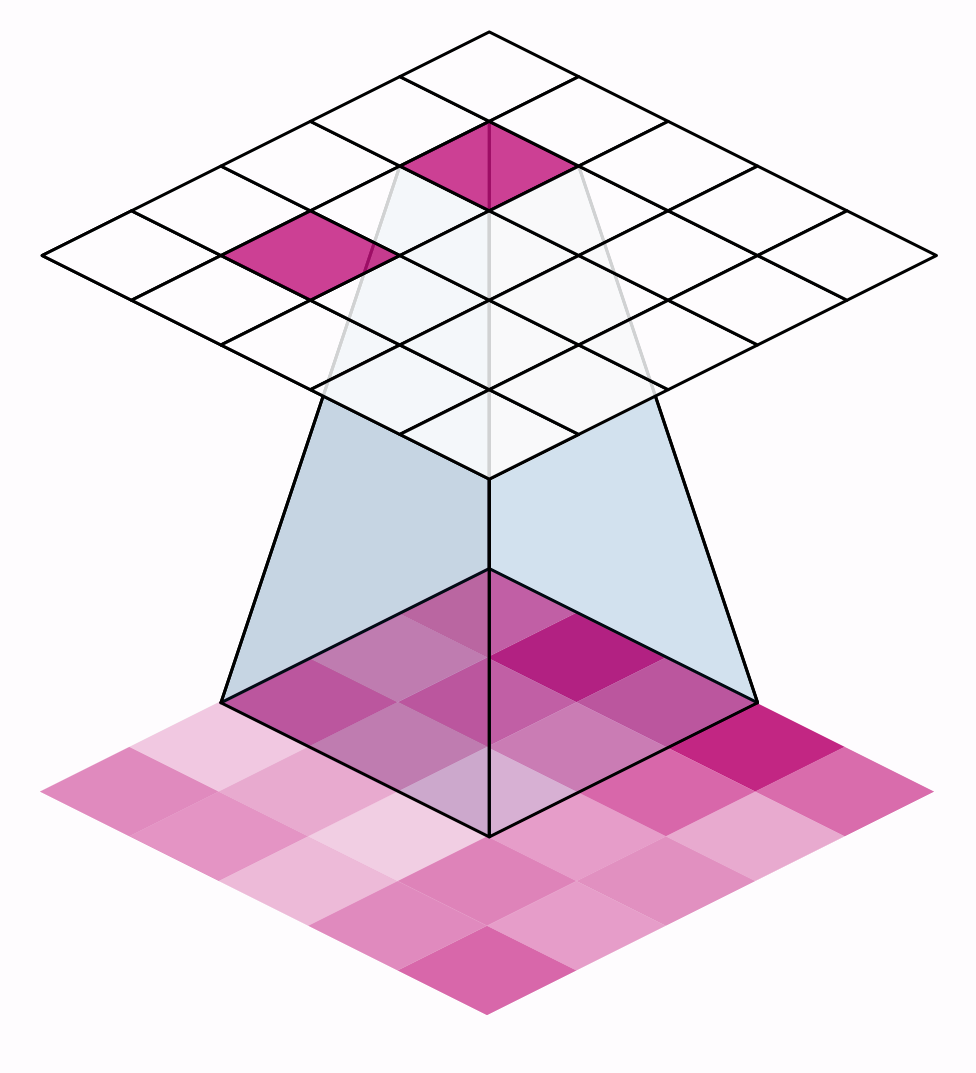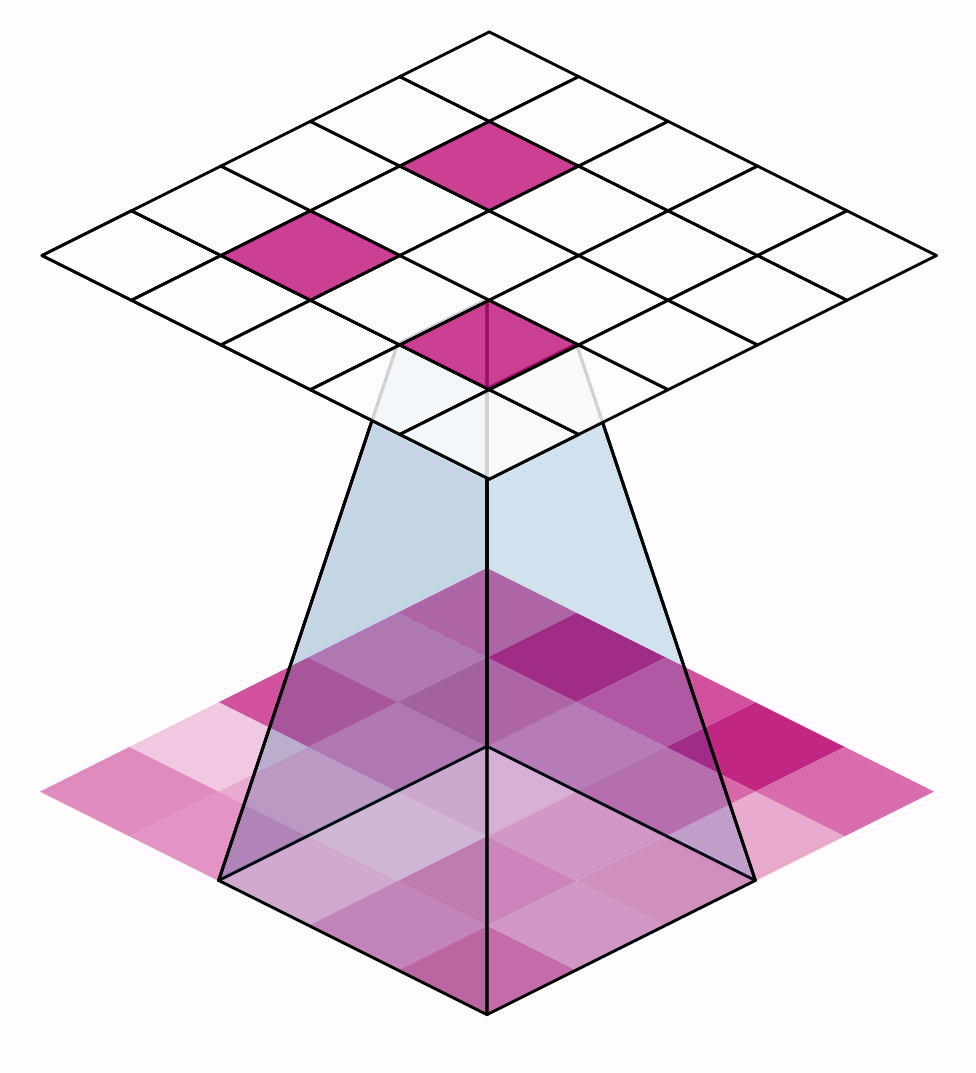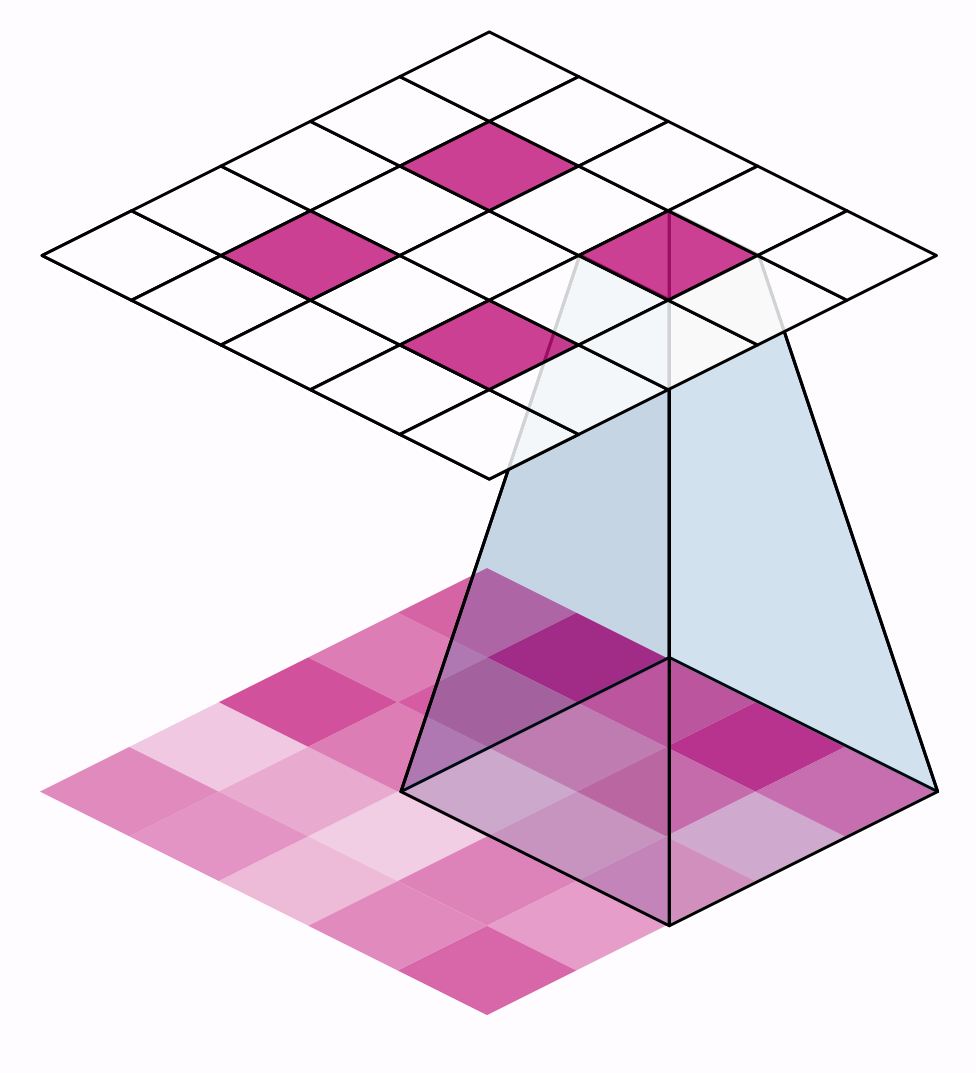
步幅有什么影响?每当任一方向的步幅大于1时,滑动窗口将在每个步骤跳过输入中的一些像素。
因为我们希望使用高质量的特征进行分类,卷积层通常具有stride=(1,1)。增加步幅意味着我们错过了可能有价值的信息。然而,最大池层的步长值几乎总是大于1,如(2,2)或(3,3),但不大于窗口本身。
最后,请注意,当两个方向上的步幅值都是相同的数字时,您只需要设置该数字;例如,您可以在参数设置中使用stride=2,而不是stride=(2,2)。
Padding
当执行滑动窗口计算时,存在一个问题,即在输入的边界处做什么。完全停留在输入图像内意味着窗口永远不会像对输入中的其他像素那样,位于这些边界像素之上。既然我们对所有像素的处理不完全相同,那么会有问题吗?
卷积如何处理这些边界值取决于其填充参数。在TensorFlow中,您有两个选择:padding='same’或padding=‘valid’。每种方法都有利弊得失。
当我们设置padding='valid’时,卷积窗口将完全位于输入内部。缺点是输出会缩小(丢失像素),对于较大的内核会缩小更多。
另一种方法是使用padding=‘same’。这里的技巧是在输入的边界周围填充0,使用足够的0使输出的大小与输入的大小相同。然而,这可能会削弱边界处像素的影响。
下面的动画显示了一个带有“SAME”填充的滑动窗口。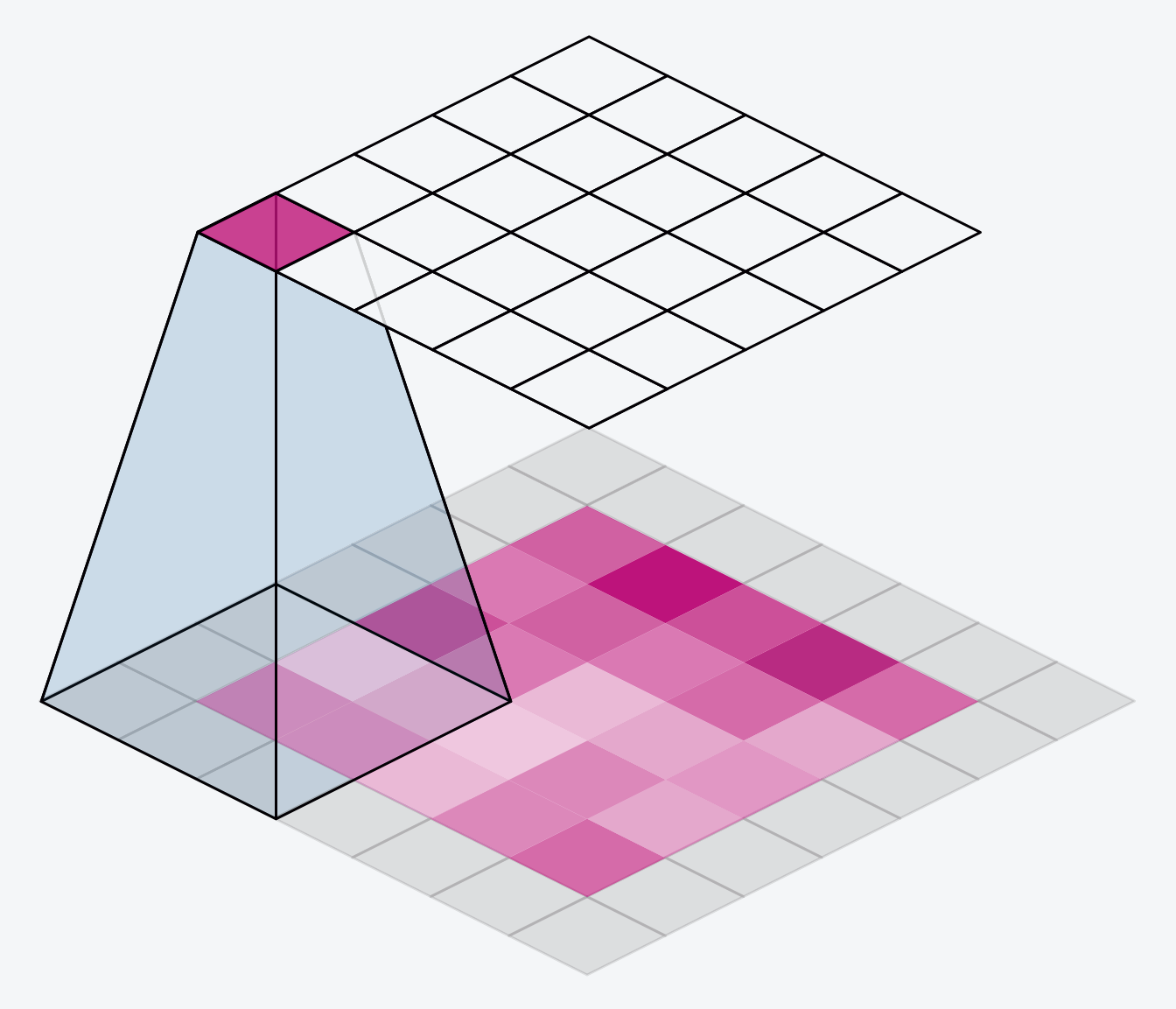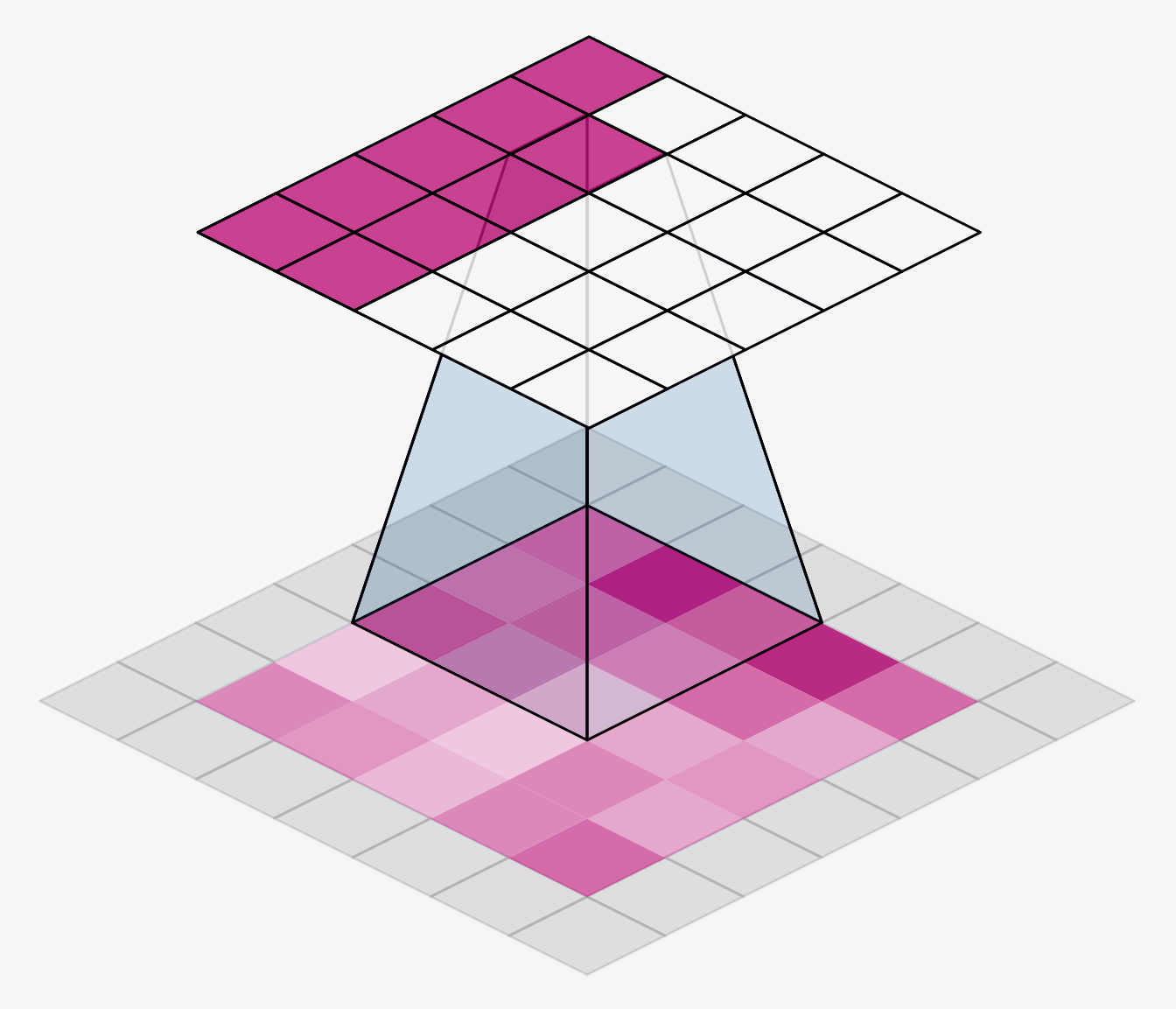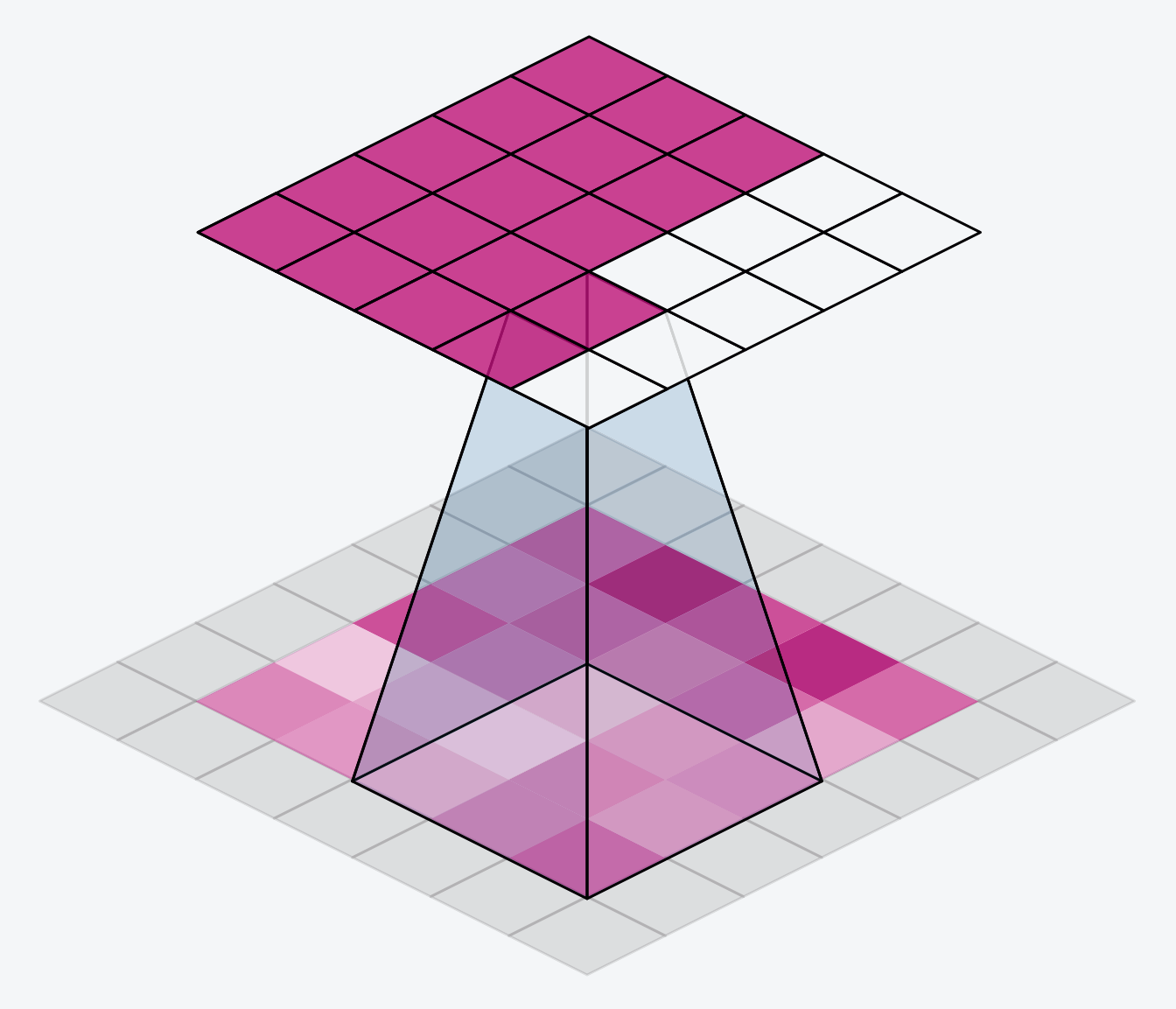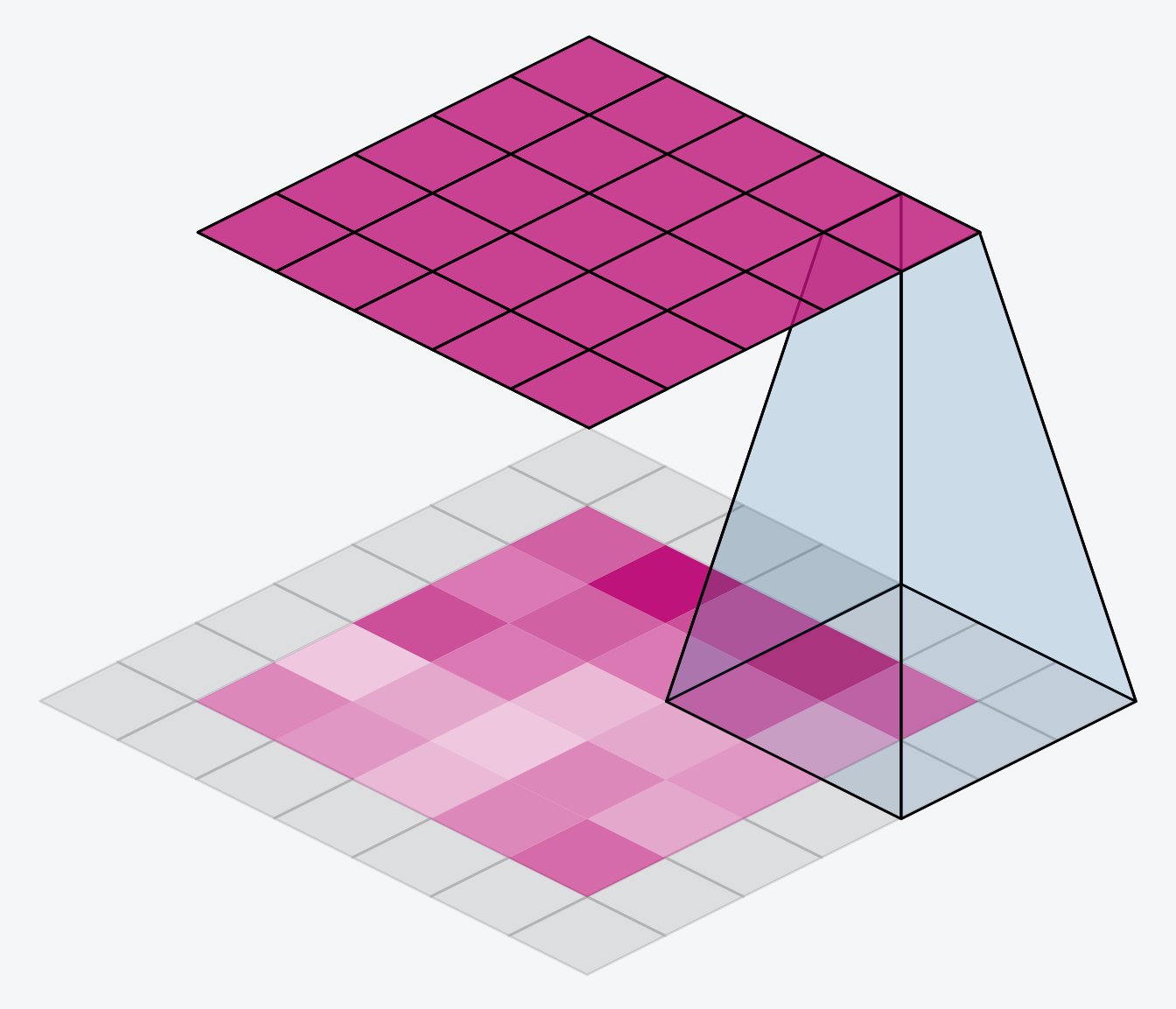
VGG架构相当简单。它使用步幅为1的卷积,2×2窗口和步幅为2的最大池。
VGG模型的展示;
show_extraction(
image, kernel,
# Window parameters
conv_stride=1,#步幅为1的卷积
pool_size=2, #2×2窗口
pool_stride=2,# 步幅为2
subplot_shape=(1, 4),
figsize=(14, 6),
)
效果:
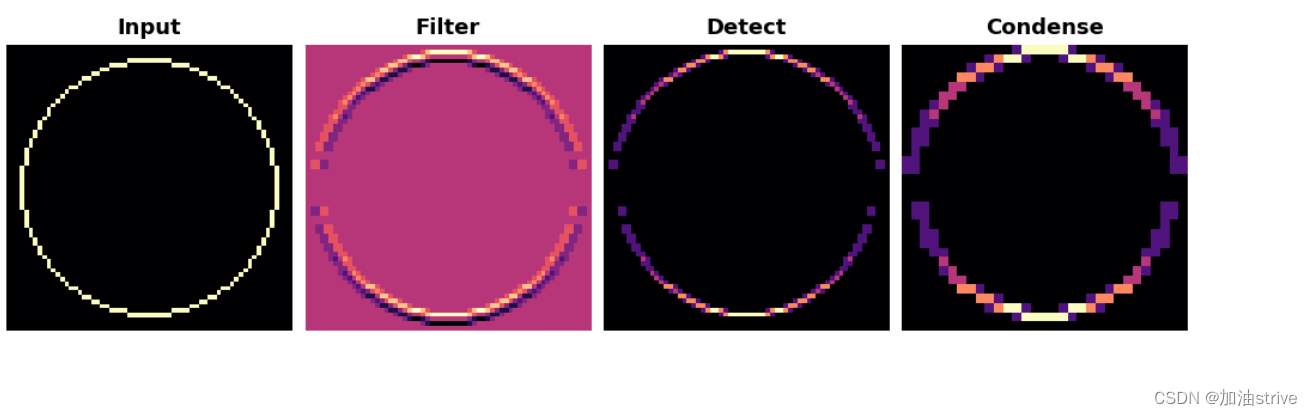
效果很好!内核被设计为检测水平线,我们可以看到,在生成的特征图中,输入的水平部分越多,激活程度越高。
如果我们将卷积的步长改为3,会发生什么?
show_extraction(
image, kernel,
# Window parameters
conv_stride=3,#步幅为3的卷积
pool_size=2,
pool_stride=2,
subplot_shape=(1, 4),
figsize=(14, 6),
)
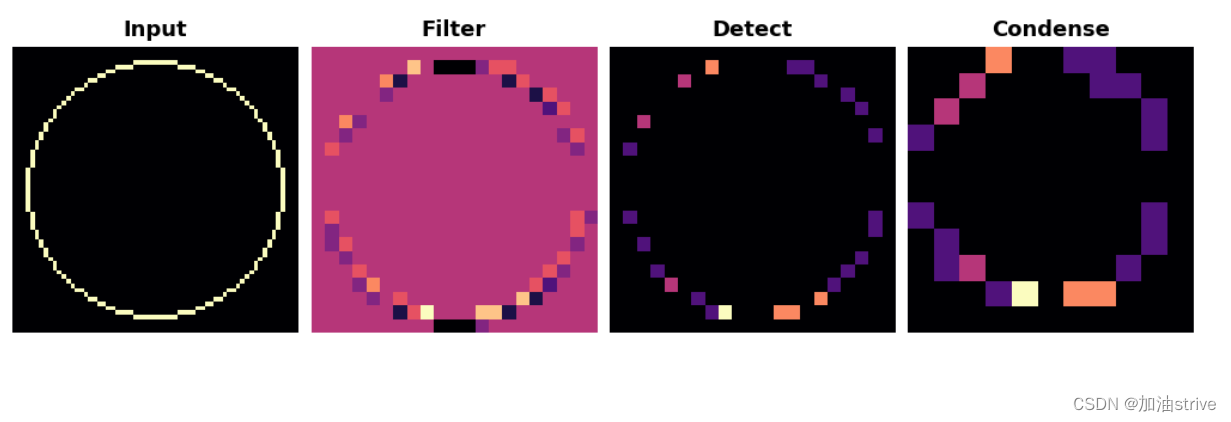
这似乎降低了提取的特征的质量。我们的输入圆相当“精细”,只有1个像素宽。步幅为3的卷积过于粗糙,无法从中生成良好的特征图。
有时,模型将在其初始层使用具有较大步长的卷积。这通常也会与更大的内核相结合。例如,ResNet50模型在其第一层使用7×7内核,步长为2。这似乎加快了大规模功能的生产,而不会牺牲输入中的太多信息。
5.Custom Convnets
设计你自己的卷积网络
既然您已经看到了convnet用于提取特征的层,那么是时候将它们放在一起并构建自己的网络了!
在最后三节课中,我们看到了卷积网络如何通过三个操作执行特征提取:过滤、检测和压缩。单轮特征提取只能从图像中提取相对简单的特征,例如简单的线条或对比度。这些太简单,无法解决大多数分类问题。相反,convnets将反复重复这种提取,从而使特征在深入网络时变得更加复杂和精细。
通过执行该提取的卷积块的长链来实现这一点。
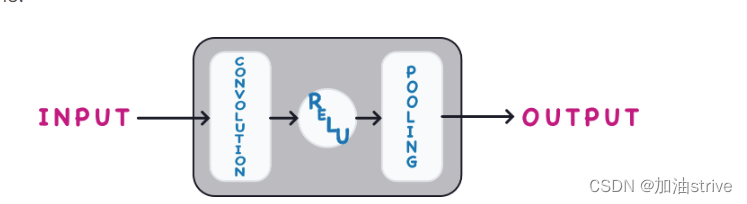

每个块代表一轮提取,通过组合这些块,convnet可以组合和重组生成的特征,使其生长和成形,以更好地解决当前的问题。现代对流的深层结构使得这种复杂的特征工程得以实现,并在很大程度上为其卓越的性能负责。
Example
Step 1 - Load Data
# Imports
import os, warnings
import matplotlib.pyplot as plt
from matplotlib import gridspec
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# Reproducability
def set_seed(seed=31415):
np.random.seed(seed)
tf.random.set_seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
os.environ['TF_DETERMINISTIC_OPS'] = '1'
set_seed()
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# Load training and validation sets
ds_train_ = image_dataset_from_directory(
'../input/car-or-truck/train',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=True,
)
ds_valid_ = image_dataset_from_directory(
'../input/car-or-truck/valid',
labels='inferred',
label_mode='binary',
image_size=[128, 128],
interpolation='nearest',
batch_size=64,
shuffle=False,
)
# Data Pipeline
def convert_to_float(image, label):
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
return image, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = (
ds_train_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
ds_valid = (
ds_valid_
.map(convert_to_float)
.cache()
.prefetch(buffer_size=AUTOTUNE)
)
Step 2 - Define Model
现在我们来定义模型。
看看我们的模型是如何由三个Conv2D和MaxPool2D层(基础)组成的,然后是一个密集层的头部。只需填写适当的参数,我们就可以将该图直接转换为Keras Sequential模型。
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
# First Convolutional Block
# filters are "过滤器"
layers.Conv2D(filters=32, kernel_size=5, activation="relu", padding='same',
# give the input dimensions in the first layer
# [height, width, color channels(RGB)]
input_shape=[128, 128, 3]),
layers.MaxPool2D(),
# Second Convolutional Block
layers.Conv2D(filters=64, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# Third Convolutional Block
layers.Conv2D(filters=128, kernel_size=3, activation="relu", padding='same'),
layers.MaxPool2D(),
# Classifier Head
layers.Flatten(),
layers.Dense(units=6, activation="relu"),
layers.Dense(units=1, activation="sigmoid"),
])
model.summary()
请注意,在这个定义中,过滤器的数量是如何逐块加倍的:32、64、128。这是一种常见的模式。由于MaxPool2D层减少了特征的大小,我们可以增加创建的数量。
Step 3 - Train
model.compile(
optimizer=tf.keras.optimizers.Adam(epsilon=0.01),
loss='binary_crossentropy',
metrics=['binary_accuracy']
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=40,
verbose=0,
)
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();
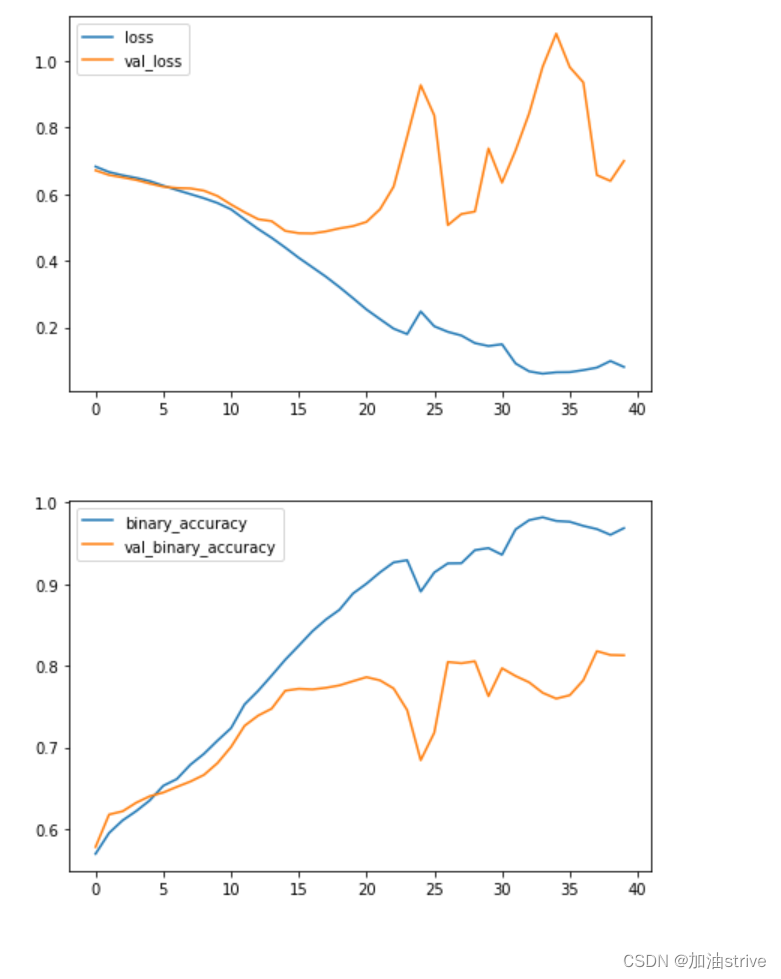
该模型比第1课中的VGG16模型小得多——只有3个卷积层,而VGG16只有16个。尽管如此,它仍然能够很好地拟合这个数据集。我们仍然可以通过添加更多卷积层来改进这个简单的模型,希望创建更适合数据集的特征。
6.Data Augmentation
通过创建额外的训练数据来提高性能。
提高机器学习模型性能的最佳方法是在更多数据上对其进行训练。模型需要学习的例子越多,它就能更好地识别哪些图像差异重要,哪些图像差异不重要。更多的数据有助于模型更好地概括。
获取更多数据的一种简单方法是使用现有数据。如果我们能够以保留类的方式转换数据集中的图像,我们就可以教分类器忽略这些类型的转换。例如,照片中的汽车是朝左还是朝右,并不能改变这是一辆汽车而不是卡车的事实。因此,如果我们用翻转图像来增强训练数据,我们的分类器将了解到“左或右”是一个应该忽略的差异。
这就是数据扩充背后的全部想法:添加一些看起来很像真实数据的额外伪数据,您的分类器将得到改进
通常,在扩充数据集时使用多种转换。这些可能包括旋转图像、调整颜色或对比度、扭曲图像或其他许多通常组合应用的事情。下面是一个可以转换单个图像的不同方式的示例。

每次在训练期间使用图像时,都会应用新的随机变换。通过这种方式,模型总是看到一些与以前不同的东西。训练数据中的这种额外差异有助于模型处理新数据。
但重要的是要记住,并不是每个转换都对给定的问题有用。最重要的是,无论使用什么转换,都不应混淆图片所属类。例如,如果你正在训练一个数字识别器,旋转图像会混淆9和6。
最后,找到好的扩充的最佳方法与大多数ML问题相同。
Step 1 - Load Model
略
Step 2 - Define Model
为了说明增强的效果,我们将向教程1中的模型添加几个简单的转换。
from tensorflow import keras
from tensorflow.keras import layers
# these are a new feature in TF 2.2
# 预处理库
from tensorflow.keras.layers.experimental import preprocessing
pretrained_base = tf.keras.models.load_model(
'../input/cv-course-models/cv-course-models/vgg16-pretrained-base',
)
pretrained_base.trainable = False
model = keras.Sequential([
# Preprocessing
preprocessing.RandomFlip('horizontal'),
# 从左向右翻转
preprocessing.RandomContrast(0.5),
# 对比度变化高达50%
# Base VGG模型
pretrained_base,
# Head
layers.Flatten(),
layers.Dense(6, activation='relu'),
layers.Dense(1, activation='sigmoid'),
])
Step 3 - Train and Evaluate
model.compile(
optimizer='adam', # adam优化器
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
history = model.fit(
ds_train,
validation_data=ds_valid,
epochs=30,
verbose=0,
)
import pandas as pd
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot()
history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();

该模型的学习曲线能够保持在一起,我们在验证损失和准确性方面取得了一些适度的改进。这表明数据集确实从增强中得到改进。