目录
往期精彩内容:
前言
1 多特征变量数据集制作与预处理
1.1 导入数据
1.2 CEEMDAN分解
1.3 数据集制作与预处理
2 麻雀优化算法
2.1 麻雀优化算法介绍
2.2 基于Python的麻雀优化算法实现
2.3 麻雀优化算法-超参数寻优过程
3 基于Pytorch的CEEMDAN + SSA-Transformer-BiLSTM 预测模型
3.1 定义CEEMDAN + SSA-Transformer-BiLSTM预测模型
3.2 设置参数,训练模型
4 模型评估与可视化
4.1 结果可视化
4.2 模型评估
代码、数据如下:

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
风速预测(六)基于Pytorch的EMD-CNN-GRU并行模型-CSDN博客
CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-LSTM + ARIMA)-CSDN博客
CEEMDAN +组合预测模型(Transformer - BiLSTM+ ARIMA)-CSDN博客
CEEMDAN +组合预测模型(CNN-Transformer + ARIMA)-CSDN博客
多特征变量序列预测(一)——CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(二)——CNN-LSTM-Attention风速预测模型-CSDN博客
多特征变量序列预测(三)——CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(四)Transformer-BiLSTM风速预测模型-CSDN博客
多特征变量序列预测(五) CEEMDAN+CNN-LSTM风速预测模型-CSDN博客
多特征变量序列预测(六) CEEMDAN+CNN-Transformer风速预测模型-CSDN博客
多特征变量序列预测(七) CEEMDAN+Transformer-BiLSTM预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-BiLSTM-Attention的预测模型-CSDN博客
基于麻雀优化算法SSA的CEEMDAN-Transformer-BiGRU预测模型-CSDN博客
多特征变量序列预测(八)基于麻雀优化算法的CEEMDAN-SSA-BiLSTM预测模型-CSDN博客
多特征变量序列预测(九)基于麻雀优化算法的CEEMDAN-SSA-BiGRU-Attention预测模型-CSDN博客
前言
本文基于前期介绍的风速数据(文末附数据集),介绍一种综合应用完备集合经验模态分解CEEMDAN与基于麻雀优化算法的SSA-Transformer-BiLSTM多特征变量序列预测模型,以提高时间序列数据的预测性能。
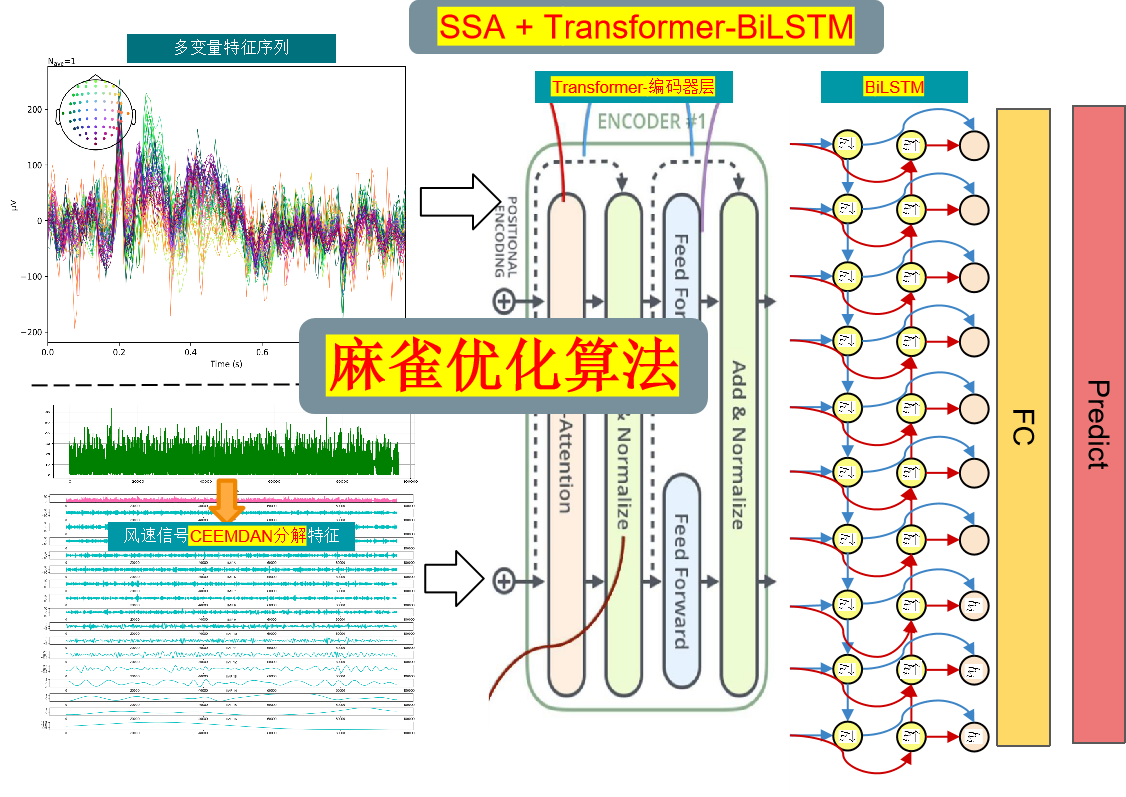
模型整体结构:数据集一共有天气、温度、湿度、气压、风速等九个变量,使用CEEMDAN算法对风速序列进行分解,然后合并所有的分量和原始数据集变量,形成一个加强的特征输入,通过滑动窗口制作数据集,利用多变量来预测风速。通过麻雀优化算法对SSA-Transformer-BiLSTM模型进行优化,提取加强后的特征,然后再送入全连接层,实现高精度的预测模型。
风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理_风速预测时序数据-CSDN博客
1 多特征变量数据集制作与预处理
1.1 导入数据
1.2 CEEMDAN分解

1.3 数据集制作与预处理
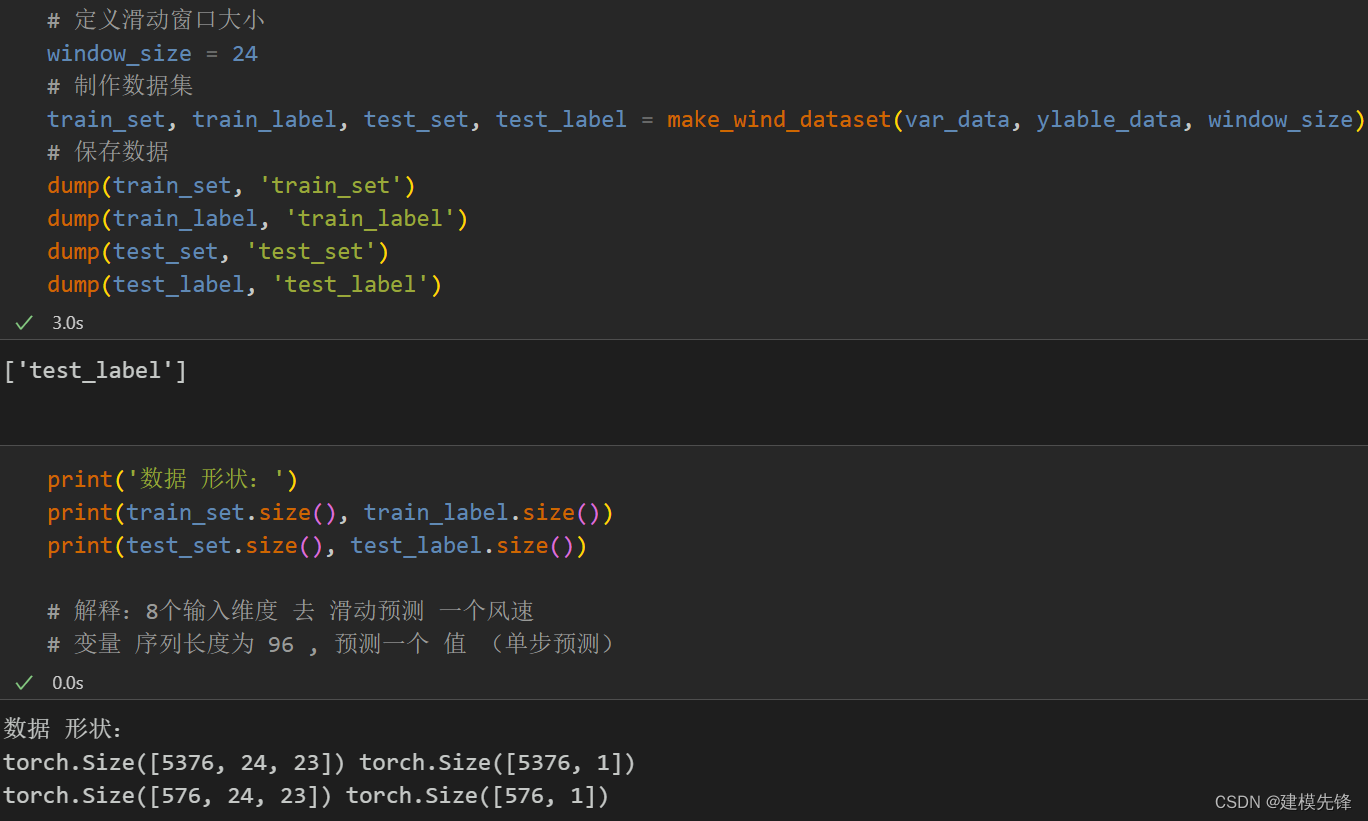
先合并原始数据变量和分解的分量,按照9:1划分训练集和测试集

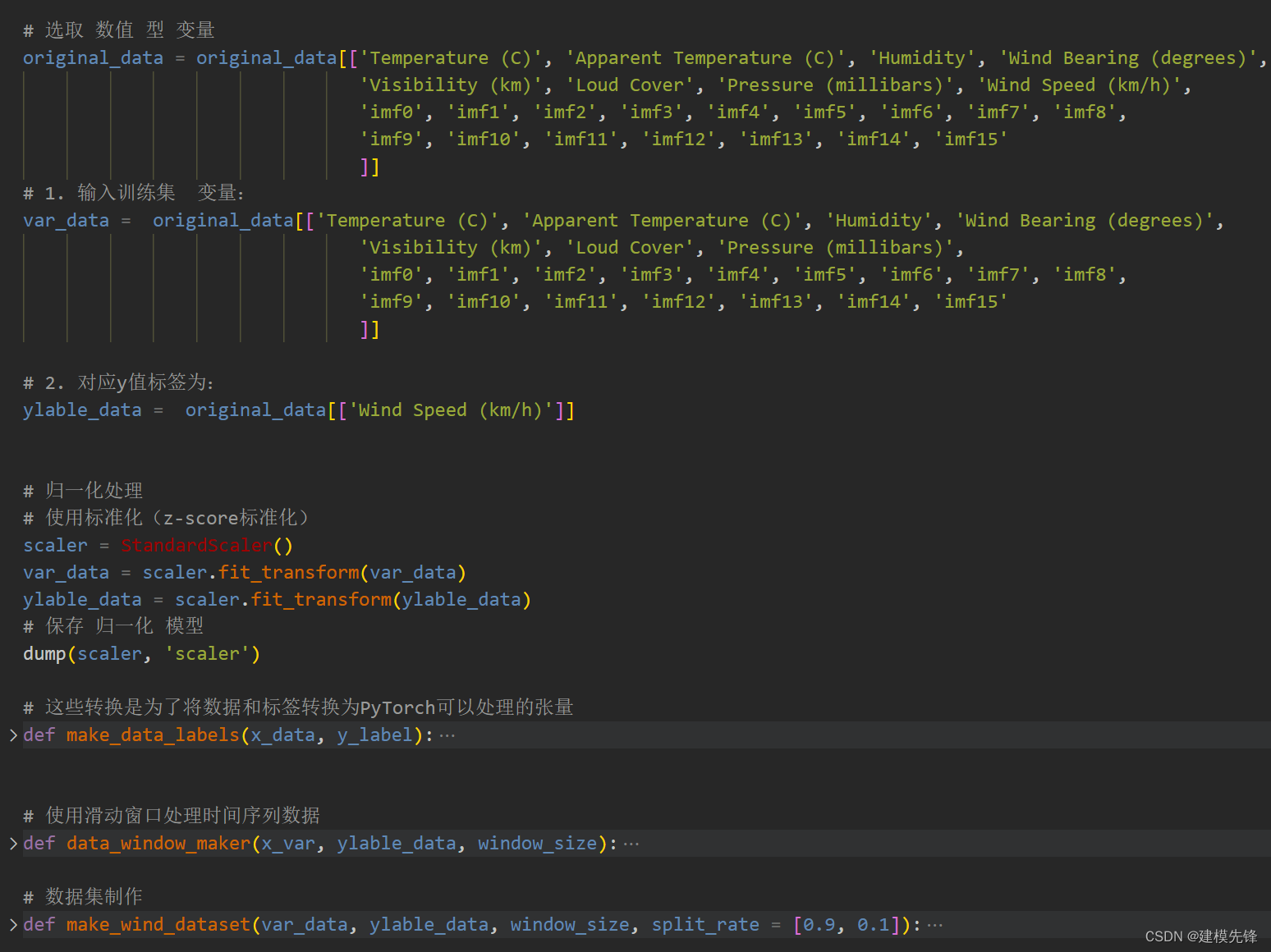
制作数据集
2 麻雀优化算法
2.1 麻雀优化算法介绍
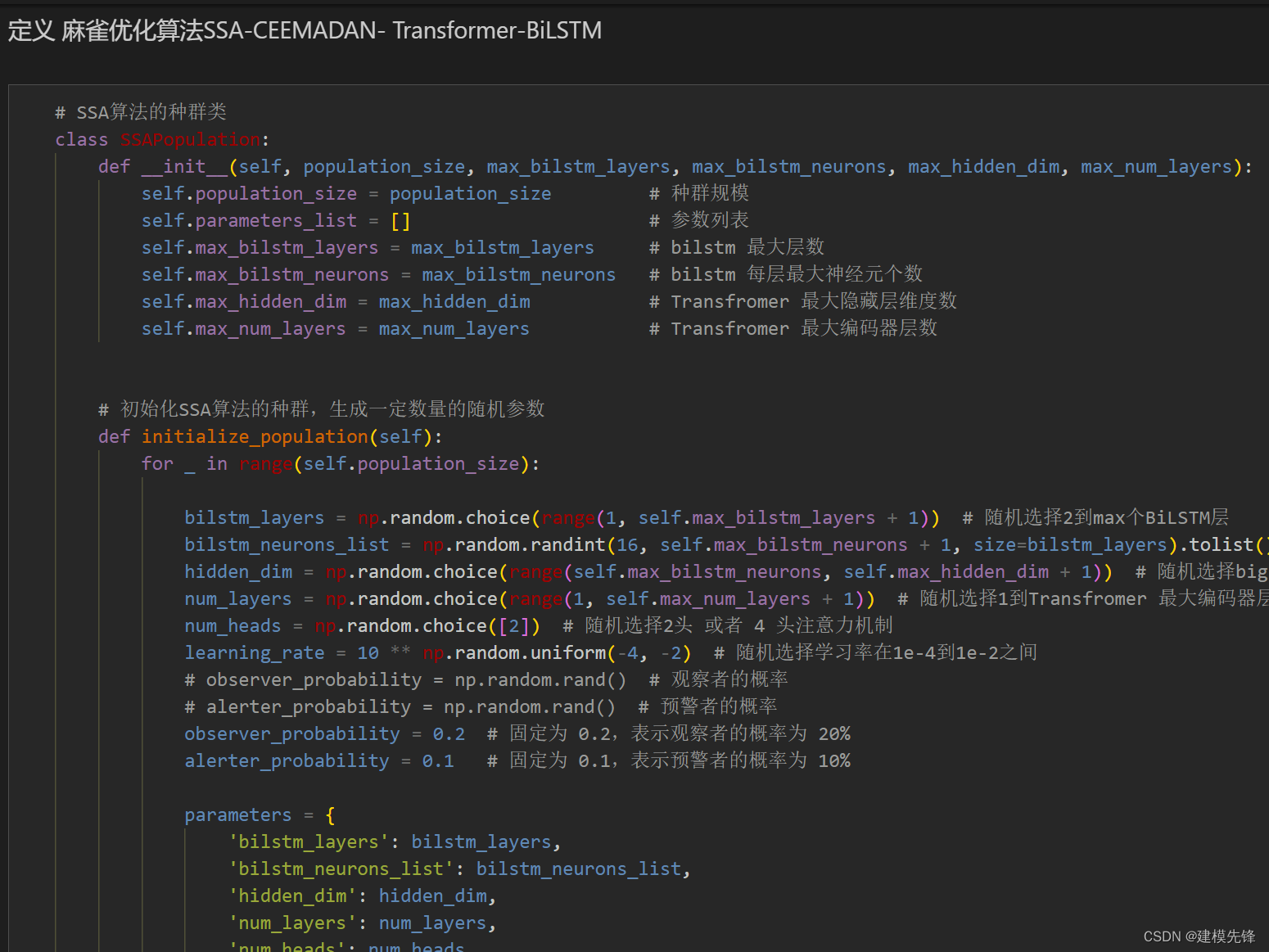
麻雀优化算法(Sparrow Optimization Algorithm,简称SOA)是一种基于自然界麻雀行为特点的优化算法,它模拟了麻雀在觅食、迁徙和社交等行为中的优化策略。该算法在解决多种优化问题方面展现出了良好的性能。
麻雀优化算法的基本思想是通过模拟麻雀的觅食行为,不断优化搜索空间中的解。算法的过程可以分为觅食行为、迁徙行为和社交行为三个阶段。
1. 觅食行为(Foraging Behavior):麻雀在觅食时会选择距离较近且具有较高适应度的食物源。在算法中,解空间中的每个个体被看作是一个食物源,具有适应度评价值。麻雀通过选择适应度较高的个体来寻找更优的解。
2. 迁徙行为(Migration Behavior):当麻雀在一个食物源周围搜索一段时间后,如果没有找到更优的解,它们会选择离开当前食物源,前往其他食物源继续寻找。在算法中,个体之间的位置信息会发生变化,以模拟麻雀的迁徙行为。
3. 社交行为(Social Behavior):麻雀在觅食时会通过与其他麻雀的交流来获取更多的信息,从而提高自己的觅食效率。在算法中,个体之间通过交换信息来改善自身的解,并且更新解空间中的最优解。
2.2 基于Python的麻雀优化算法实现
2.3 麻雀优化算法-超参数寻优过程
麻雀优化算法具有简单易实现、全局寻优能力和自适应性等特点,适用于解决组合优化问题。我们通过麻雀优化算法来进行SSA-Transformer-BiLSTM模型的超参数寻优。
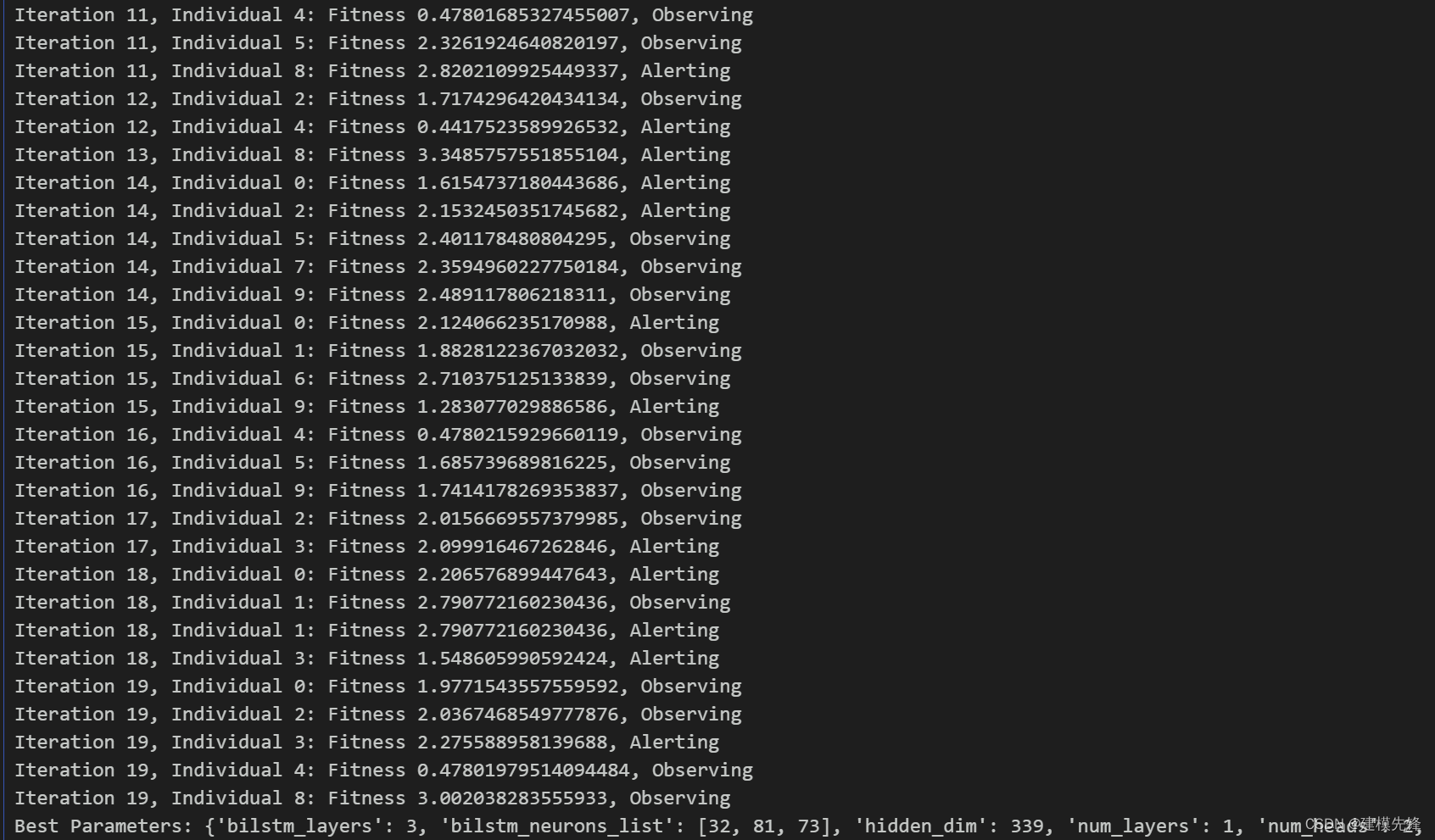
通过设置合适的种群规模和优化迭代次数,我们在给定的超参数范围内,搜索出最优的参数。
3 基于Pytorch的CEEMDAN + SSA-Transformer-BiLSTM 预测模型
3.1 定义CEEMDAN + SSA-Transformer-BiLSTM预测模型
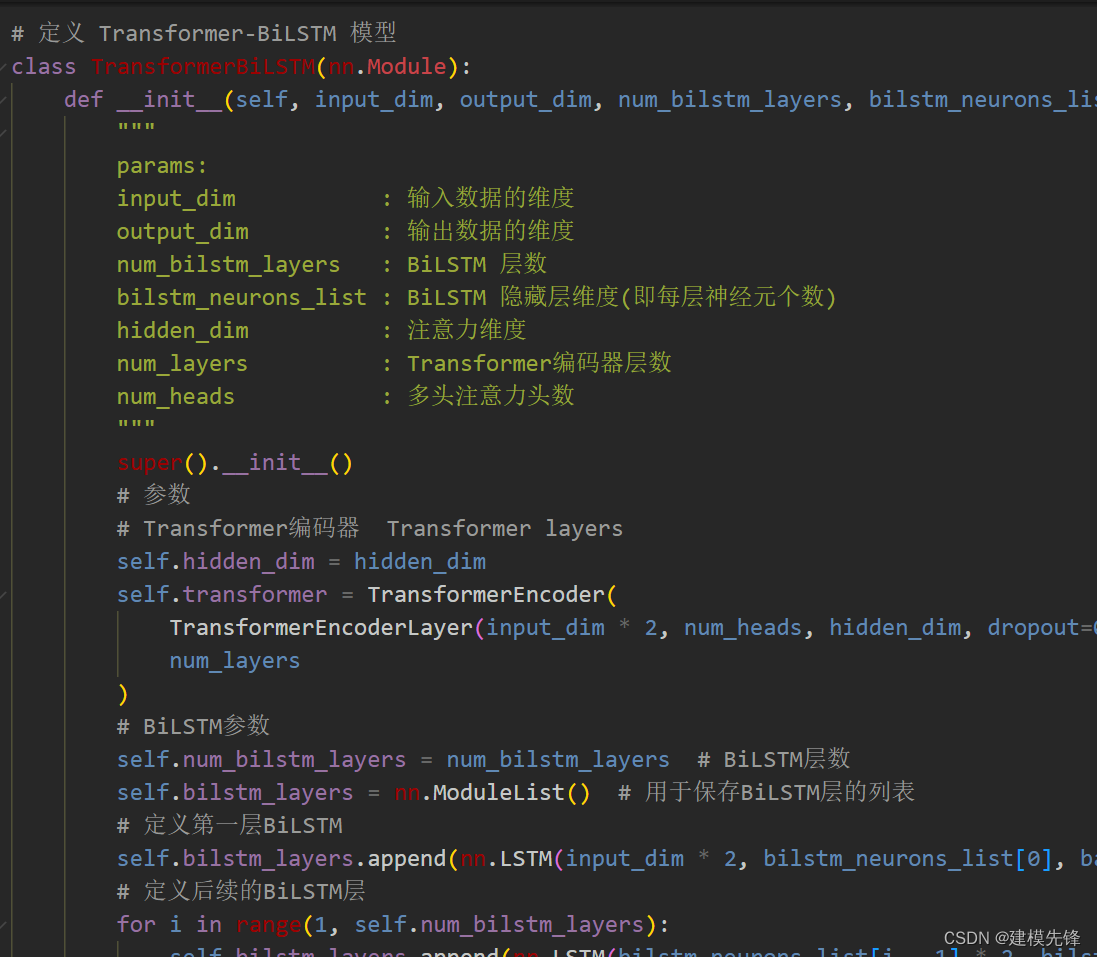
注意:输入风速数据形状为 [64, 24, 23], batch_size=64,24代表序列长度(滑动窗口取值), 维度23维代表挑选的8个变量和15个分量的维度。
在使用Transformer模型中的多头注意力时,输入维度必须能够被num_heads(注意力头的数量)整除。因为在多头注意力机制中,输入的嵌入向量会被分成多个头,每个头的维度是embed_dim / num_heads,因此embed_dim必须能够被num_heads整除,以确保能够均匀地分配给每个注意力头。
因为此时输入维度为23,本文采用对数据进行对半切分堆叠,使输入形状为[64, 12, 46]。
3.2 设置参数,训练模型
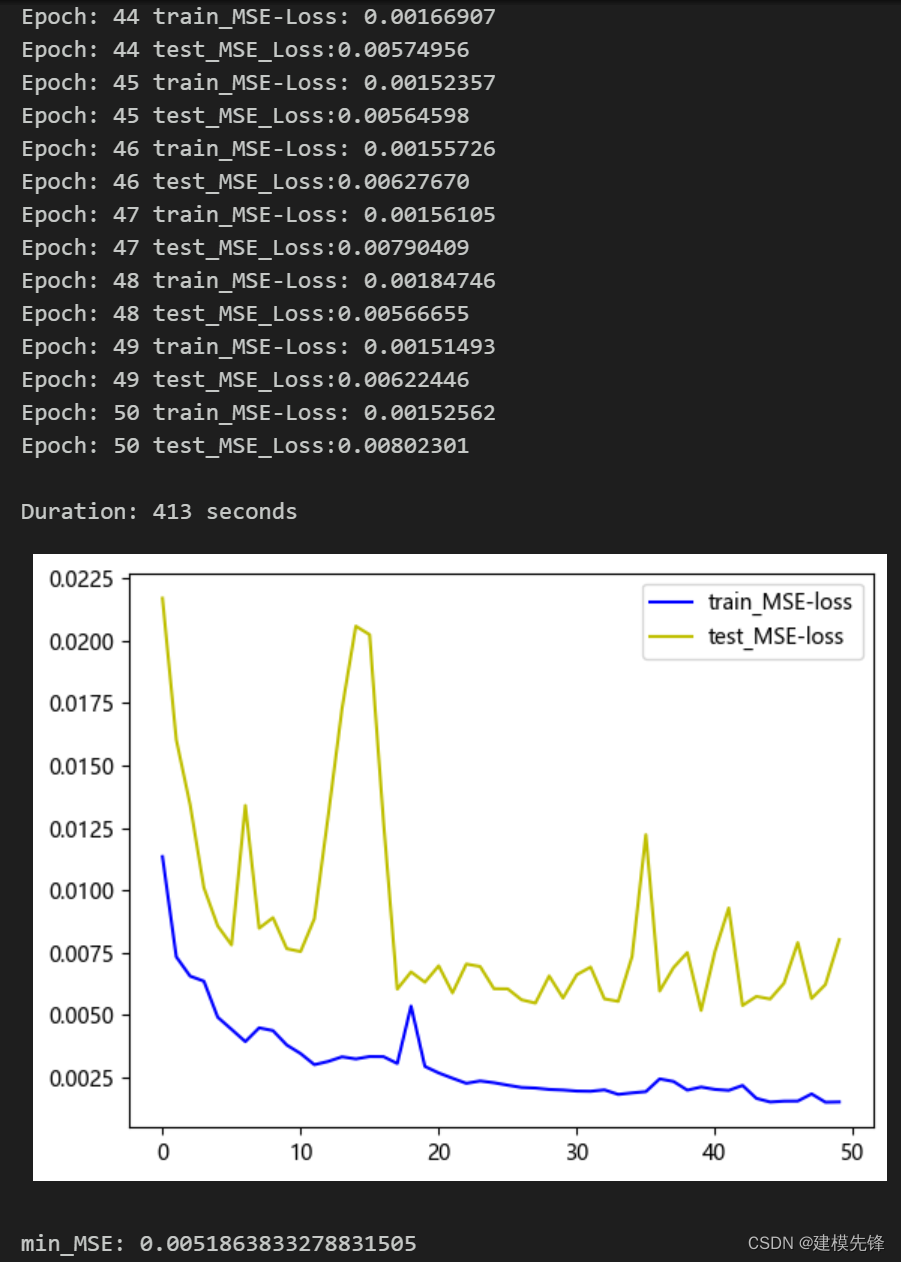
50个epoch,MSE 为0.005186,多变量特征CEEMDAN + SSA-Transformer-BiLSTM预测效果良好,加入CEEMDAN分解后,多变量预测效果提升明显,性能优越,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以修改麻雀优化算法的种群规模和优化迭代次数;
-
调整Transformer编码器层数、多头注意力头数和BiLSTM层数维度数的参数搜索范围,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
4 模型评估与可视化
4.1 结果可视化

4.2 模型评估

代码、数据如下:








![[计算机网络]--MAC/ARP/DNS协议](https://img-blog.csdnimg.cn/direct/35bef6573ffb4170930f59f268ef379c.png)