1. 连接
1.0 基础认知
多表(主表)和一表(从表的区别):
多表一般是主表,一般存储主要数据,每个字段都可能存在重复值,没有主键,无法根据某个字段定位到准确的记录;
一表一般是从表,一般存储辅助数据,通过主键与主表连接,存储的记录是不重复的,可通过主键定位到记录。
1.1 为什么要用连接(join)
因为大部分情况下,要符合数据库设计规范,数据不可能集中在同一张表里,那样的话会产生数据冗余,但是分成多张表会造成取数比较麻烦,join(连接)就是为解决上述问题的一种语法。
1.2 连接种类和语法
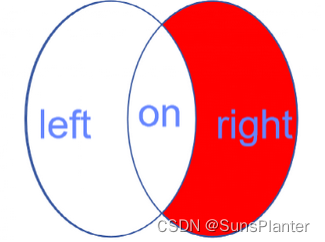
内连接:inner join,最常见的一种连接方式(最常用,查询效率最高)
左连接:也叫左外连接(left [outer] join)
右连接:也叫右外连接(right [outer] join)
全连接:full [outer] join ,MySQL不能直接支持。
默认情况不写outer关键字
以下述表为例子, 详细讲述连接
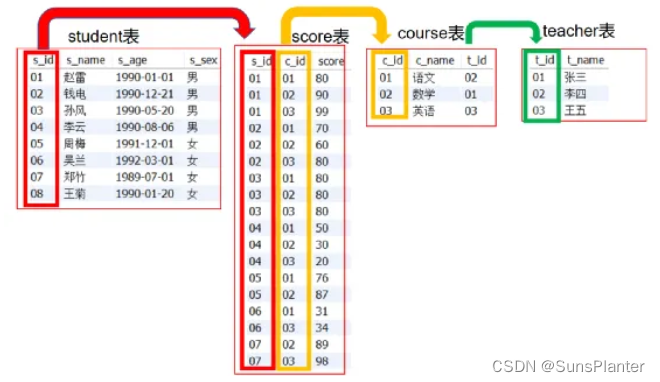
1.3 左连接
左连接:left join, 左连接从左表(t1)取出所有记录,与右表(t2)匹配。如果没有匹配,以null值代表右边表的列。
左表的所有行一定会全部出现在查询结果中至少一次
需求: 查询每个学生每科成绩和个人信息
分析: 两种方案
- 主表为student表, 每条记录后拼接学生信息即可
- 主表为score表.因为它存储每科每个学生成绩,每个学生对应多个成绩,这样就能查询出多条记录,
- 最终查出形如sid,name, course_id1, course_score1,course_id2,course_score2的记录, 即每个学生只占一条记录
但由于MySql不支持动态扩列 , 这一目标实现起来会比较复杂
1.3.1 左连接的第一种情况
左表中独有的数据行:对于左表中存在而右表中不存在(即没有匹配项)的行,它们也会被取出,但右表的列将为NULL。
即取出左表中所有项后排除与右表有匹配项的条目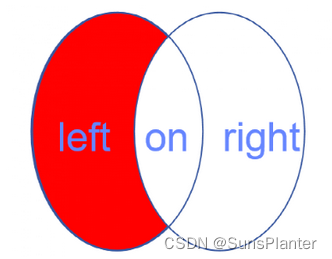
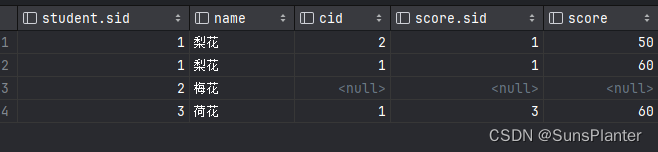
这里我们使用方案1进行左连接,student表为左表,score表为右表。
select *
from student
left join score
on student.sid = score.sid
由于id 为2的学生梅花 ,在score表中并没有分数记录, 而student表作为主表, 所有条目又必须出现至少一次, 因此结果如下
1.3.2 左连接的第二种情况
匹配的数据行:即左表和右表中基于连接条件相匹配的行。
即取出主表 + 与主表有交集的从表内容
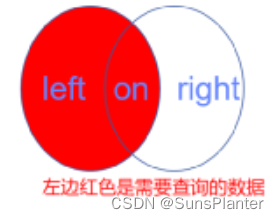
这里我们使用方案2进行左连接,score表为左表,student表为右表。
select *
from score
left join student
on student.sid = score.sid
由于score为主表, 因此没有任何成绩的梅花不必出现一次

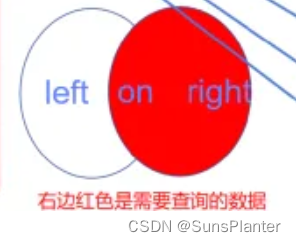
1.4 右外连接
右连接从右表(t2)取出所有记录,与左表(t1)匹配。如果没有匹配,以null值代表左边表的列。
右表的所有行一定会全部出现在查询结果中至少一次
实际上,右连接取出的结果和左连接取出的结果是一样的,唯一的不同时字段顺序不同,两者的字段顺序是相反的
对于每种连接来说,哪张表写在前面,哪张表的字段默认就会出现在结果集的左边(select后指定字段的情况除外)。
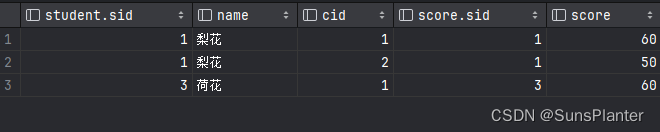
1.4.1 右连接的第一种情况
select *
from student
right join score
on student.sid = score.sid
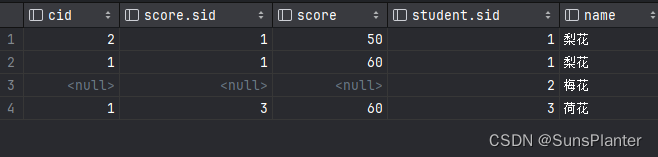
1.4.1 右连接的第二种情况
select *
from score
right join student
on student.sid = score.sid
1.5 内连接
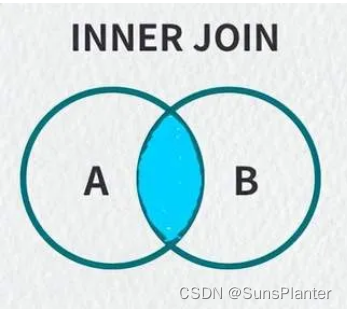
在左/右外连接中 , 至少有一张的表的全部条目会至少出现一次
内连接中不是, 仅会出现有交集的条目
1. 练习
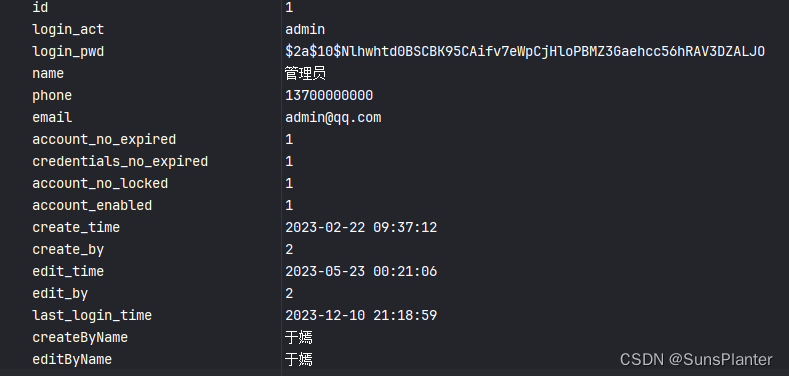
用户表结构如图 ,
需求: 用户表中的create_by创建人和edit_by编辑人角色是用id字段表示的, 这个id即用户id字段
当我们查询一条用户信息时, 我们希望直接看到创建人和编辑人的名字, 而非仅仅是id
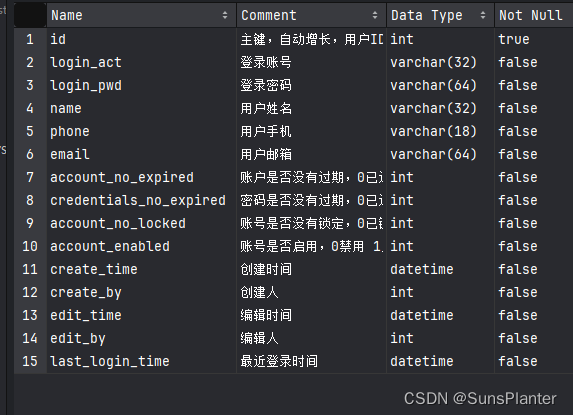
思路是是同一张表做左外连接, 这样可以在保留原本所有条目的基础上, 为每个条目增加姓名字段
select tu.*,
tu2.name createByName,
tu3.name editByName
from dlyk.t_user tu
left join dlyk.t_user tu2 on tu.create_by = tu2.id
left join dlyk.t_user tu3 on tu.edit_by = tu3.id
where tu.id = 1