用法1:map函数
with ThreadPoolExecutor() as pool:
results = pool.map(craw,utls)
for result in results:
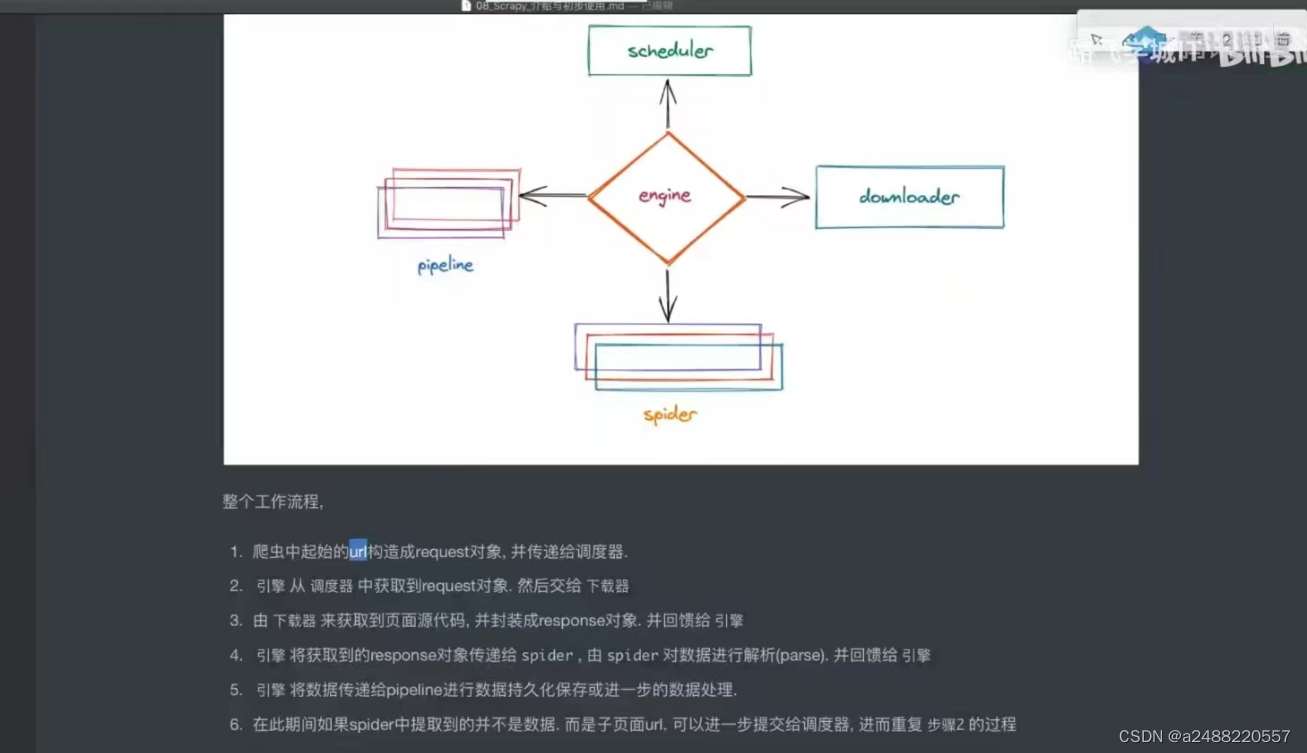
print(result)1.Scrapy框架:
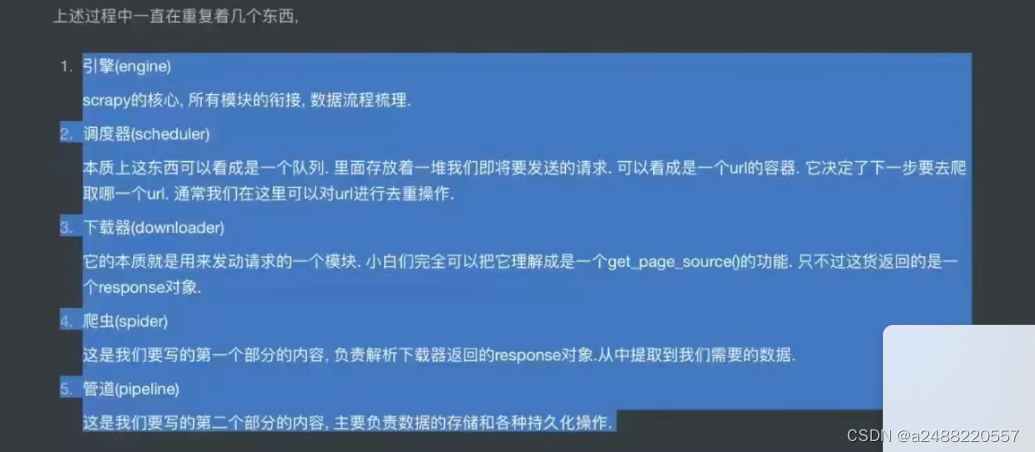
五大结构:引擎,下载器,爬虫,调度器,管道,爬虫
其中引擎,下载器,调度器。不用我们写。剩下的要我们写。
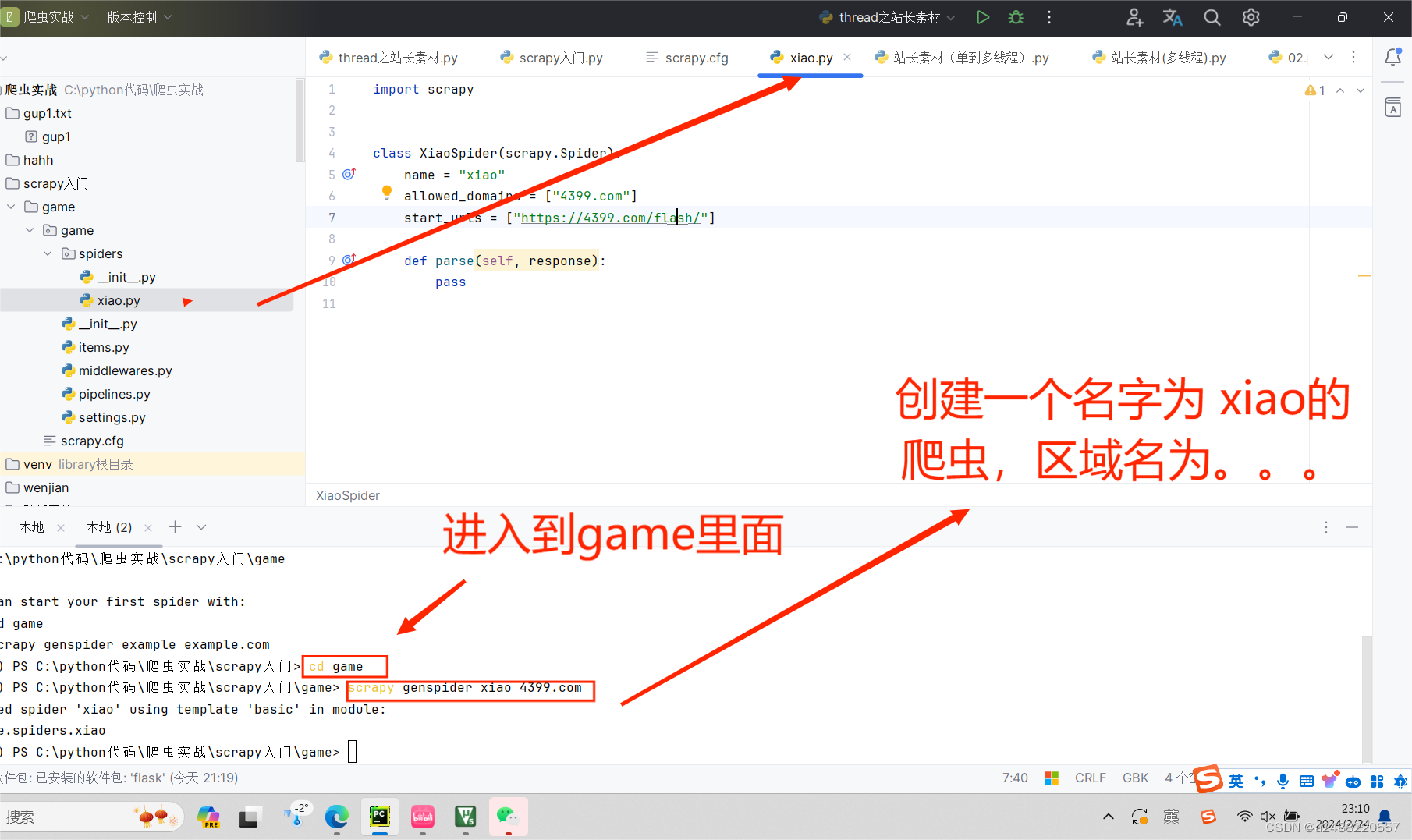
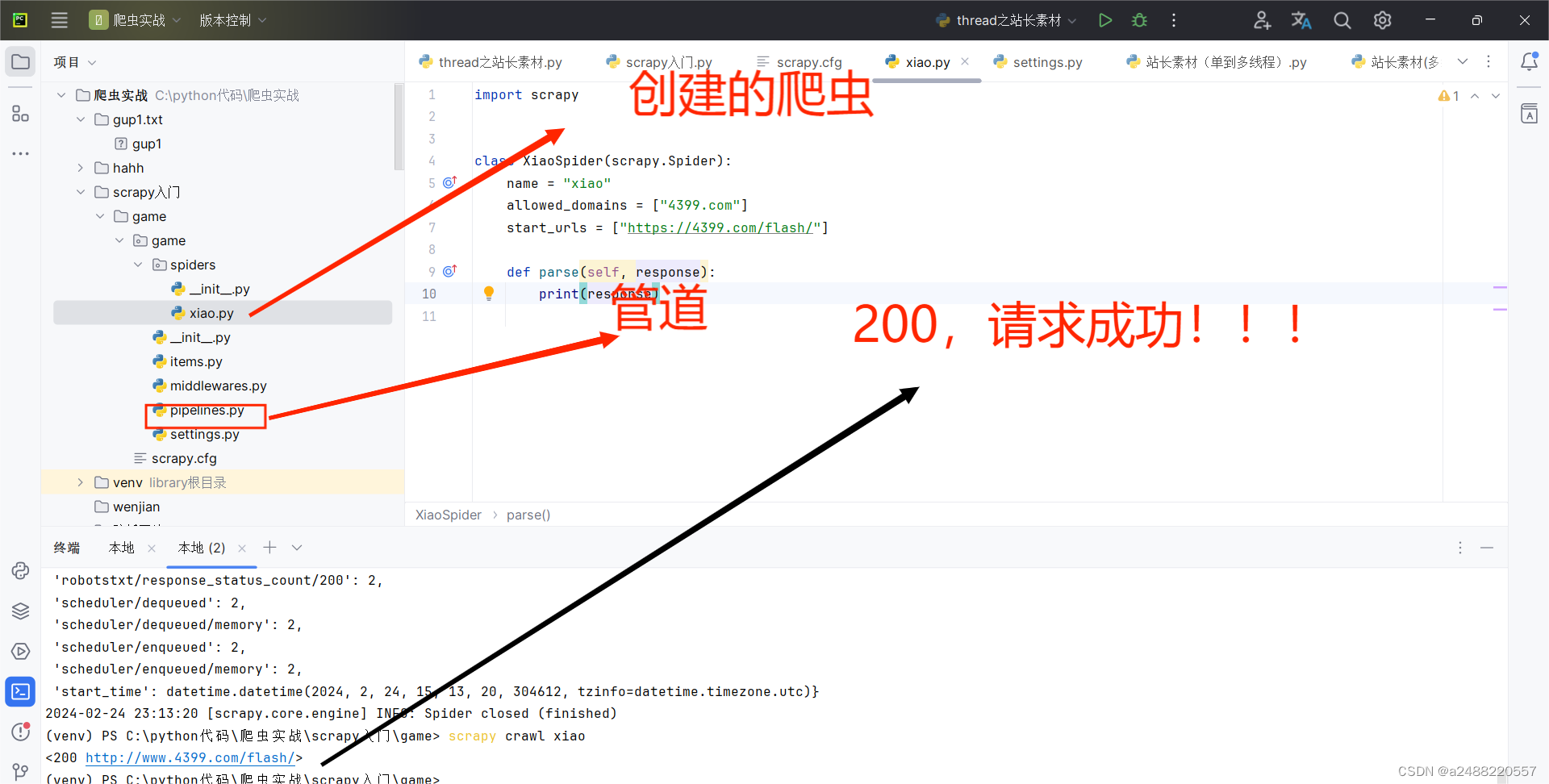
代码部分的了解:这个是自己创建一个爬虫(用scrapy)叫“xiao”
import scrapy
class XiaoSpider(scrapy.Spider):
name = "xiao"
allowed_domains = ["4399.com"]
start_urls = ["https://4399.com/flash/"]
def parse(self, response):
#print(response.text)
#获得游戏名
# txt = response.xpath("//ul[@class = 'n-game cf']/li/ a/b/text()")
# #提取信息内容
# txt = txt.extract()
# print(txt)
#分块提取
li_list = response.xpath("//ul[@class = 'n-game cf']/li")
for list in li_list:
#name = list.xpath("./a/b/text()").extract()#返回的一个列表,拿到字符串要加[0]
name = list.xpath("./a/b/text()").extract_first()#拿到第一个,如果没有返回None
leibie = list.xpath("./em/a/text()").extract_first()#拿到第一个,如果没有返回None
print(name,leibie)

这个scrapy是拿终端跑的。
步骤:
1.

2.
 3.
3.
4.
其中代码中,scrapy给我们了,寻找的方法
response.xpath(),respon,css()。
没有见过的是:
leibie = list.xpath("./em/a/text()").extract_first()
的extract(),这个就是
提取信息内容
学习笔记加油!!!
下来处理管道,数据给到管道:
 代码最后一行的yield dic 是将字典给管道。
代码最后一行的yield dic 是将字典给管道。
class GamePipeline:
def process_item(self, item, spider):#处理数据
print(item)
print(spider.name)
return item
class NewPipeline:
def process_item(self, item, spider): # 处理数据
item['love'] = "hahh"
return item在管道内部,为两个管道,平常管道是关闭的,我们需要打开。

打开管道。
1.创建项目
scrapy startproject+项目名称
2.进入项目
cd+项目名称
3.创建爬虫
scrapy genspider+名字+域名
4.可能要修改的url
5.对数据解析。在spider里面的parse(response)中解析
def parse(self,response):
response.text
response.xpath()/css()
解析数据时,xpath返回的是selector对象。
用extract()提取数据
extract()返回列表
extrac_first()返回一个数据
yield 返回数据->给管道来进行存储
6.在管道中完成数据的存储
class类名()
def 名字(self,item,spider)
item:数据
spider:爬虫
return item 必须要返回,否则下一个管道收不到数据
7.设置setting。py文件将管道生效设置
ITEM_PIPELINES = {
"管道路径":优先级,优先级越高数据越小
}
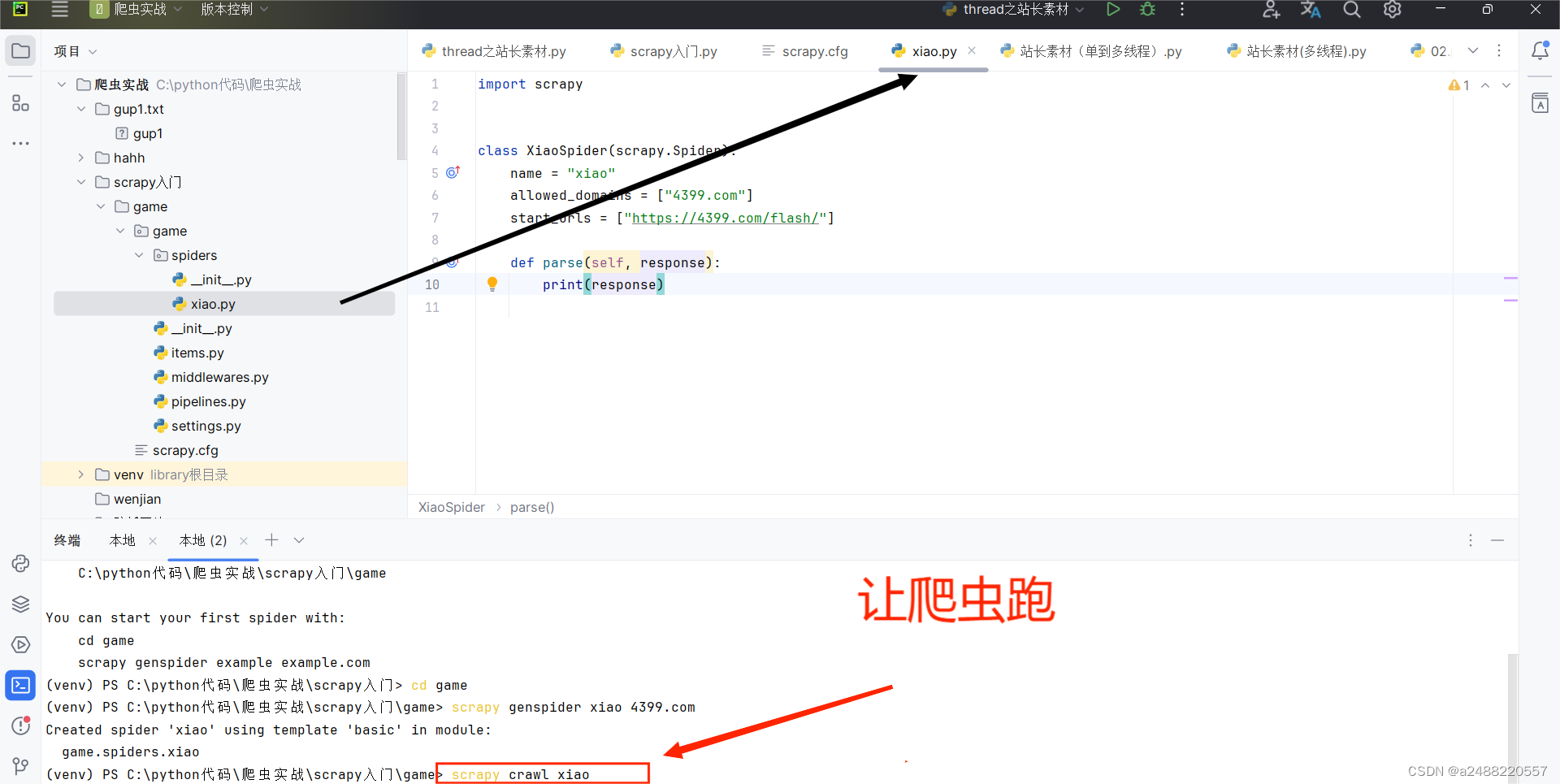
8.运行爬虫
scrapy crawl +爬虫名字