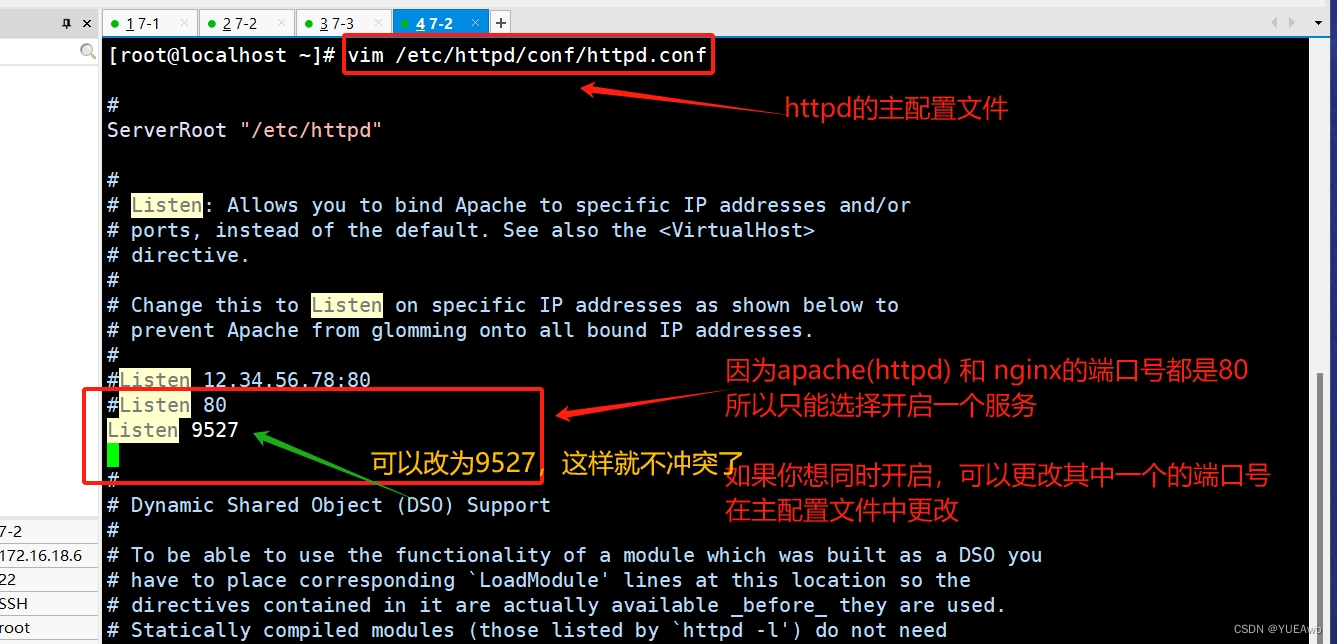
1 原理
1.1 静态分区裁剪与动态分区裁剪
静态分区裁剪的原理跟谓词下推是一致的,只是适用的是分区表,通过将where条件中的分区条件下推到数据源达到减少分区扫描的目的
动态分区裁剪应用于Join场景,这种场景下,分区条件在join的一侧,另一侧无法应用条件进行裁剪
静态分区裁剪是静态的规则优化下推,动态分区裁剪是运行时过滤,通过对有条件一侧的表进行过滤,提取结果中的分区数据,然后传递到另一侧的表中进行数据过滤
- 静态分区过滤
SELECT * FROM t1 WHERE parcl = 'A'
- 动态分区过滤
正常SQL优化,只能在t1表应用Filter进行提前过滤,而动态分区过滤先对t1进行扫描,将结果中的分区值进行收集,基于join的等值条件,传递到t2
SELECT * FROM t1 JOIN t2 on t1.parcl =t2.parcl WHERE t1.cl1 = 'A'
1.2 基础设计
Flink的FLIP-27设计当中,分片由SplitEnumerator产生,因此动态分区裁剪设计在SplitEnumerator当中
Flink的设计中引入了Coordinator协调器的角色,运行时由Coordinator将维度表的结果传送至事实表的SplitEnumerator进行分区过滤
由于之前的Source没有输入,此次为DPP引入一个新的TableScan的物理节点
设计上,首先是基于规则将事实表的TableScan转为BatchPhysicalDynamicFilteringTableSourceScan,然后真正的动态分区裁剪行为在BatchPhysicalDynamicFilteringTableSourceScan当中进行
2 框架设计
2.1 整体流程

首先是正常的SQL解析过程,这里会识别DPP模式并进行一定的转换设置
- 提交JobGraph
JobManager先调度维表和一个负责维表数据收集的DynamicFilteringDataCollector,维表的数据会向Join和DynamicFilteringDataCollector双向发送
DynamicFilteringDataCollector将收集过滤后的数据发送至SourceCoordinator
DynamicFileSplitEnumerator基于SourceCoordinator的维表分区数据对事实表进行切片
事实表基于切片产生任务,由JobManager调度
事实表的任务从DynamicFileSplitEnumerator获取切片,读取数据并发送到Join - Join计算
从整体上来看,DPP对事实表进行了提前的数据过滤,可以大量减少IO;但另一方面,两张表的并行扫描在DPP后变成了顺序扫描
2.2 计划转换

Flink基于DPP的执行计划转换如下,核心是加入了一个DynamicFilteringDataCollector的节点,用于维表数据的收集
前三幅图的转化是加入有输入边的TableScan以后优化器进行优化处理的转化流程
后两幅图的转化是因为DynamicFilteringDataCollector和事实表之间没有数据依赖关系,调度可能随机,在资源不足时产生死锁(这一块需要研究,线性的算子图为什么没有依赖关系)。为了解决这种死锁,加入了一个依赖运算符,以此来顺序调度DynamicFilteringDataCollector和事实表
3 相关接口
3.1 SupportsDynamicFiltering
Flink Source数据源支持的能力都是通过提供公共接口然后由数据源各自实现的,动态分区裁剪也是如此,SupportsDynamicFiltering就是提供由数据源实现的公共接口(Flink数据源能力集在flink-table\flink-table-common\src\main\java\org\apache\flink\table\connector\source\abilities和flink-table-planner\src\main\java\org\apache\flink\table\planner\plan\abilities\source,后者没看到实现类,不确定用法)
接口提供了两个方法抽象:listAcceptedFilterFields、applyDynamicFiltering
listAcceptedFilterFields接口返回数据源支持做动态分区过滤的字段(也就是可能有些数据源只有部分字段支持)
applyDynamicFiltering将用于动态分区的字段下推到数据源,具体的过滤数据在运行时提供,这里只是提供字段,用于数据源构建分片器时传入
目前看只有Hive表的两个实现类HiveTableSource和HiveLookupTableSource实现了该接口(官方设计文档说文件系统也支持,得具体研究)
3.2 DynamicFilteringEvent
传输DynamicFilteringData的Source数据源,由DynamicFilteringDataCollector发送,经由DynamicFilteringDataCollectorCoordinator和SourceCoordinator发送到数据源的enumerator
接口的核心就是封装了DynamicFilteringData,并提供获取方法
public class DynamicFilteringEvent implements SourceEvent {
private final DynamicFilteringData data;
3.3 DynamicFilteringData
就是上面DynamicFilteringEvent封装的内容,是动态过滤的数据,数据以RowData形式组建,数据的顺序以SupportsDynamicFiltering#applyDynamicFiltering接口传入的字段为顺序,没有单独再定义schema
接口有一个重点方法doPrepare,整体功能就是将接收到的序列化数据进行解析,然后重组成RowData队列数据
private void doPrepare() {
this.dataMap = new HashMap<>();
if (isFiltering) {
this.fieldGetters =
IntStream.range(0, rowType.getFieldCount())
.mapToObj(i -> RowData.createFieldGetter(rowType.getTypeAt(i), i))
.toArray(RowData.FieldGetter[]::new);
TypeSerializer<RowData> serializer = typeInfo.createSerializer(new ExecutionConfig());
for (byte[] bytes : serializedData) {
try (ByteArrayInputStream bais = new ByteArrayInputStream(bytes);
DataInputViewStreamWrapper inView = new DataInputViewStreamWrapper(bais)) {
RowData partition = serializer.deserialize(inView);
List<RowData> partitions =
dataMap.computeIfAbsent(hash(partition), k -> new ArrayList<>());
partitions.add(partition);
} catch (Exception e) {
throw new TableException("Unable to deserialize the value.", e);
}
}
}
}
3.4 DynamicFileEnumerator
FLIP-27设计中,数据源(目前是Hive和文件系统)切片是由FileEnumerator提供的,这个接口不支持动态分区裁剪,因此在此接口上又提供了子接口DynamicFileEnumerator来支持动态分区裁剪,目前看也是只有Hive实现HiveSourceDynamicFileEnumerator
DynamicFileEnumerator当中就是额外提供了一个创建自身的工厂类和一个setDynamicFilteringData方法,setDynamicFilteringData方法的作用就是传入上面的DynamicFilteringData
void setDynamicFilteringData(DynamicFilteringData data);
/** Factory for the {@link DynamicFileEnumerator}. */
@FunctionalInterface
interface Provider extends FileEnumerator.Provider {
DynamicFileEnumerator create();
}
3.5 HiveSourceDynamicFileEnumerator
DynamicFileEnumerator的实现类,setDynamicFilteringData当中完成了分区过滤,就是拿全量分区与DynamicFilteringData做比较
public void setDynamicFilteringData(DynamicFilteringData data) {
LOG.debug("Filtering partitions of table {} based on the data: {}", table, data);
if (!data.isFiltering()) {
finalPartitions = allPartitions;
return;
}
finalPartitions = new ArrayList<>();
RowType rowType = data.getRowType();
Preconditions.checkArgument(rowType.getFieldCount() == dynamicFilterPartitionKeys.size());
for (HiveTablePartition partition : allPartitions) {
RowData partitionRow = createRowData(rowType, partition.getPartitionSpec());
if (partitionRow != null && data.contains(partitionRow)) {
finalPartitions.add(partition);
}
}
LOG.info(
"Dynamic filtering table {}, original partition number is {}, remaining partition number {}",
table,
allPartitions.size(),
finalPartitions.size());
}
其中allPartitions是在HiveSourceBuilder当中确定的,后续通过接口传入到HiveSourceDynamicFileEnumerator,主要的获取方法如下,核心就是利用HiveClient的listPartitions方法获取分区
} else if (partitions == null) {
partitions =
HivePartitionUtils.getAllPartitions(
jobConf, hiveVersion, tablePath, partitionKeys, null);
}
enumerateSplits方法返回分片,本质就是调用HiveSourceFileEnumerator.createInputSplits,主要差异点就在与这里传入的分区是上面过滤过的分区
public Collection<FileSourceSplit> enumerateSplits(Path[] paths, int minDesiredSplits)
throws IOException {
return new ArrayList<>(
HiveSourceFileEnumerator.createInputSplits(
minDesiredSplits, finalPartitions, jobConf, false));
}
3.6 配置项
动态分区裁剪新增了配置项:table.optimizer.dynamic-filtering.enabled
public static final ConfigOption<Boolean> TABLE_OPTIMIZER_DYNAMIC_FILTERING_ENABLED =
key("table.optimizer.dynamic-filtering.enabled")
.booleanType()
.defaultValue(true)
.withDescription(
"When it is true, the optimizer will try to push dynamic filtering into scan table source,"
+ " the irrelevant partitions or input data will be filtered to reduce scan I/O in runtime.");
4 优化器
上面的接口是保证数据源上对动态分区裁剪的支持,完整的功能还需要优化器的参与,具体的优化器实现是FlinkDynamicPartitionPruningProgram,只支持Batch
注意这里的基类不是calcite的RelRule,而是Flink的FlinkOptimizeProgram,因为目前calcite的HepPlanner不支持部分确定场景和动态替换场景
4.1 转化事实表
优化器的核心就是对事实表做节点替换,变成BatchPhysicalDynamicFilteringTableSourceScan
Tuple2<Boolean, RelNode> relTuple =
DynamicPartitionPruningUtils
.canConvertAndConvertDppFactSide(
rightSide,
joinInfo.rightKeys,
leftSide,
joinInfo.leftKeys);
最终的实现逻辑在DynamicPartitionPruningUtils.convertDppFactSide,最终目标就是创建一个BatchPhysicalDynamicFilteringDataCollector,并基于此完成BatchPhysicalDynamicFilteringTableSourceScan创建
BatchPhysicalDynamicFilteringDataCollector dynamicFilteringDataCollector =
createDynamicFilteringConnector(dimSide, dynamicFilteringFieldIndices);
isChanged = true;
return new BatchPhysicalDynamicFilteringTableSourceScan(
scan.getCluster(),
scan.getTraitSet(),
scan.getHints(),
tableSourceTable,
dynamicFilteringDataCollector);
在最终达到创建BatchPhysicalDynamicFilteringTableSourceScan之前,有很多的分支路径和条件判断
分支路径是因为接口传入的RelNode可能不是TableScan(也就是join的左右字表并不是直接的TableScan,还有其他的如filter存在),分支路径的逻辑基本统一,就是继续解析RelNode并迭代调用convertDppFactSide方法,如下
} else if (rel instanceof Exchange || rel instanceof Filter) {
return rel.copy(
rel.getTraitSet(),
Collections.singletonList(
convertDppFactSide(
rel.getInput(0), joinKeys, dimSide, dimSideJoinKey)));
TableScan分支是最终创建BatchPhysicalDynamicFilteringTableSourceScan的分支,创建之前有很多的条件判断
如果已经是BatchPhysicalDynamicFilteringTableSourceScan,直接返回
if (scan instanceof BatchPhysicalDynamicFilteringTableSourceScan) {
// rule applied
return rel;
}
如果不是TableSourceTable,直接返回
TableSourceTable tableSourceTable = scan.getTable().unwrap(TableSourceTable.class);
if (tableSourceTable == null) {
return rel;
}
如果没有分区键,直接返回
List<String> partitionKeys = catalogTable.getPartitionKeys();
if (partitionKeys.isEmpty()) {
return rel;
}
如果数据源表不支持动态分区过滤,直接返回
DynamicTableSource tableSource = tableSourceTable.tableSource();
if (!(tableSource instanceof SupportsDynamicFiltering)
|| !(tableSource instanceof ScanTableSource)) {
return rel;
}
不支持数据源聚合的情况
// Dpp cannot success if source have aggregate push down spec.
if (Arrays.stream(tableSourceTable.abilitySpecs())
.anyMatch(spec -> spec instanceof AggregatePushDownSpec)) {
return rel;
}
只支持FLIP-27定义的新Source接口
if (!isNewSource((ScanTableSource) tableSource)) {
return rel;
}
join使用的字段不存在的不支持
List<String> candidateFields =
joinKeys.stream()
.map(i -> scan.getRowType().getFieldNames().get(i))
.collect(Collectors.toList());
if (candidateFields.isEmpty()) {
return rel;
}
接下来还是对分区字段的一个校验,前面SupportsDynamicFiltering有一个方法返回可做动态过滤的分区字段,这里就是基于这个做校验
List<String> acceptedFilterFields =
getSuitableDynamicFilteringFieldsInFactSide(tableSource, candidateFields);
if (acceptedFilterFields.size() == 0) {
return rel;
}
这里这个acceptedFilterFields接下来有多个使用,SupportsDynamicFiltering.applyDynamicFiltering的入参就是它
// Apply suitable accepted filter fields to source.
((SupportsDynamicFiltering) tableSource)
.applyDynamicFiltering(acceptedFilterFields);
BatchPhysicalDynamicFilteringDataCollector的构造参数也有基于它的数据
List<Integer> acceptedFieldIndices =
acceptedFilterFields.stream()
.map(f -> scan.getRowType().getFieldNames().indexOf(f))
.collect(Collectors.toList());
List<Integer> dynamicFilteringFieldIndices = new ArrayList<>();
for (int i = 0; i < joinKeys.size(); ++i) {
if (acceptedFieldIndices.contains(joinKeys.get(i))) {
dynamicFilteringFieldIndices.add(dimSideJoinKey.get(i));
}
}
BatchPhysicalDynamicFilteringDataCollector dynamicFilteringDataCollector =
createDynamicFilteringConnector(dimSide, dynamicFilteringFieldIndices);
4.2 维表判断
优化器在执行转化事实表之前还有很多的条件判断
基础的配置开关判断
if (!ShortcutUtils.unwrapContext(root)
.getTableConfig()
.get(OptimizerConfigOptions.TABLE_OPTIMIZER_DYNAMIC_FILTERING_ENABLED)) {
return root;
}
不是join或者join的类型不符
if (!(rel instanceof Join)
|| !DynamicPartitionPruningUtils.isSuitableJoin((Join) rel)) {
// Now dynamic partition pruning supports left/right join, inner and semi
// join. but now semi join can not join reorder.
if (join.getJoinType() != JoinRelType.INNER
&& join.getJoinType() != JoinRelType.SEMI
&& join.getJoinType() != JoinRelType.LEFT
&& join.getJoinType() != JoinRelType.RIGHT) {
return false;
}
然后最核心的有一个维表的判断,因为动态分区过滤是对事实表进行的转换,而事实表的过滤数据来自维表,所以需要识别;此外,动态分区过滤需要看效果,如果收集的维表数据过大是会取消执行动态分区过滤的
维表判断有一个专门的类DppDimSideChecker,判断逻辑是:如果joinKeys为空,则维表无需处理joinKeys,因为这些key已经被规则处理了;如果joinKeys发生了变化,则不是维表
public boolean isDppDimSide() {
visitDimSide(this.relNode);
return hasFilter && !hasPartitionedScan && tables.size() == 1;
}
核心是hasFilter和hasPartitionedScan两个成员的值,在DppDimSideChecker.visitDimSide当中赋值,visitDimSide有4.1中转化事实表一样的多分支,本质上最后都走进TableScan分支
TableScan分支当中,首先是对过滤条件的判断,部分过滤条件是不支持做动态分区过滤的,比如not null只过滤一个默认分区,效果几乎没有
if (!hasFilter
&& table.abilitySpecs() != null
&& table.abilitySpecs().length != 0) {
for (SourceAbilitySpec spec : table.abilitySpecs()) {
if (spec instanceof FilterPushDownSpec) {
List<RexNode> predicates = ((FilterPushDownSpec) spec).getPredicates();
for (RexNode predicate : predicates) {
if (isSuitableFilter(predicate)) {
hasFilter = true;
}
}
}
}
}
其次是分区判断,必须是分区表
CatalogTable catalogTable = table.contextResolvedTable().getResolvedTable();
if (catalogTable.isPartitioned()) {
hasPartitionedScan = true;
return;
}
最后就是数据源表必须只有一个,不能多数据源
// To ensure there is only one source on the dim side.
setTables(table.contextResolvedTable());
5 BatchExecTableSourceScan
Flink SQL的整体流程当中,有一步FlinkPhysicalRel向ExecNodeGraph转化(PlannerBase.translateToExecNodeGraph),在这一步当中,BatchPhysicalDynamicFilteringTableSourceScan最终转为BatchExecTableSourceScan,在BatchPhysicalDynamicFilteringTableSourceScan的translateToExecNode
override def translateToExecNode(): ExecNode[_] = {
val tableSourceSpec = new DynamicTableSourceSpec(
tableSourceTable.contextResolvedTable,
util.Arrays.asList(tableSourceTable.abilitySpecs: _*))
tableSourceSpec.setTableSource(tableSourceTable.tableSource)
new BatchExecTableSourceScan(
unwrapTableConfig(this),
tableSourceSpec,
InputProperty.DEFAULT,
FlinkTypeFactory.toLogicalRowType(getRowType),
getRelDetailedDescription)
}
BatchExecTableSourceScan有一个核心方法translateToPlanInternal,也是Flink SQL转化的一个核心步骤,完成向Transformation的转化,Transformation是Flink任务执行的基础,调用点就在PlannerBase.translate的最后一步translateToPlan
val relNodes = modifyOperations.map(translateToRel)
val optimizedRelNodes = optimize(relNodes)
val execGraph = translateToExecNodeGraph(optimizedRelNodes, isCompiled = false)
val transformations = translateToPlan(execGraph)
afterTranslation()
transformations
5.1 初步转化
首先是调用父类CommonExecTableSourceScan的translateToPlanInternal,这是一个通用转化,与动态分区过滤无关,主要就是根据provider的类型调用不同的接口方法创建Transformation
以Hive表HiveTableSource来说,provider获取如下
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
return new DataStreamScanProvider() {
@Override
public DataStream<RowData> produceDataStream(
ProviderContext providerContext, StreamExecutionEnvironment execEnv) {
return getDataStream(providerContext, execEnv);
}
@Override
public boolean isBounded() {
return !isStreamingSource();
}
};
}
这是一个DataStreamScanProvider,所以在CommonExecTableSourceScan走DataStreamScanProvider分支
} else if (provider instanceof DataStreamScanProvider) {
Transformation<RowData> transformation =
((DataStreamScanProvider) provider)
.produceDataStream(createProviderContext(config), env)
.getTransformation();
meta.fill(transformation);
transformation.setOutputType(outputTypeInfo);
return transformation;
因为provider已经校验过boundedness了,所以后一步直接设置boundedness
// the boundedness has been checked via the runtime provider already, so we can safely
// declare all legacy transformations as bounded to make the stream graph generator happy
ExecNodeUtil.makeLegacySourceTransformationsBounded(transformation);
后一步是动态分区裁剪的支持性判断,要么还有输入,要么是SourceTransformation才支持
// no dynamic filtering applied
if (getInputEdges().isEmpty() || !(transformation instanceof SourceTransformation)) {
return transformation;
}
5.2 dynamicFilteringDataCollector的监听设置
前面创建BatchPhysicalDynamicFilteringTableSourceScan时传入的input是BatchPhysicalDynamicFilteringDataCollector,转化后是BatchExecDynamicFilteringDataCollector,这里直接获取
// handle dynamic filtering
BatchExecDynamicFilteringDataCollector dynamicFilteringDataCollector =
getDynamicFilteringDataCollector(this);
之后设置监听,首先把dynamicFilteringDataCollector转化为Transformation
// Set the dynamic filtering data listener ids for both sides. Must use translateToPlan to
// avoid duplication.
Transformation<Object> dynamicFilteringTransform =
dynamicFilteringDataCollector.translateToPlan(planner);
然后记录id,这个id是对象创建时通过UUID产生的
((SourceTransformation<?, ?, ?>) transformation)
.setCoordinatorListeningID(dynamicFilteringDataListenerID);
((DynamicFilteringDataCollectorOperatorFactory)
((OneInputTransformation<?, ?>) dynamicFilteringTransform)
.getOperatorFactory())
.registerDynamicFilteringDataListenerID(dynamicFilteringDataListenerID);
5.3 最终transformation
之后生成最终的transformation,这里有两个分支,由needDynamicFilteringDependency区分,这是参数的设置在PlannerBase的translateToExecNodeGraph,最终设置在DynamicFilteringDependencyProcessor.process
判断条件应该是BatchExecTableSourceScan有输入,并且输入不是BatchExecMultipleInput
// The character of the dynamic filter scan is that it
// has an input.
if (input instanceof BatchExecTableSourceScan
&& input.getInputEdges().size() > 0) {
dynamicFilteringScanDescendants
.computeIfAbsent(
(BatchExecTableSourceScan) input,
ignored -> new ArrayList<>())
.add(node);
}
for (Map.Entry<BatchExecTableSourceScan, List<ExecNode<?>>> entry :
dynamicFilteringScanDescendants.entrySet()) {
if (entry.getValue().size() == 1) {
ExecNode<?> next = entry.getValue().get(0);
if (next instanceof BatchExecMultipleInput) {
// the source can be chained with BatchExecMultipleInput
continue;
}
}
// otherwise we need dependencies
entry.getKey().setNeedDynamicFilteringDependency(true);
}
在BatchExecTableSourceScan当中,不依赖的分支如下
if (!needDynamicFilteringDependency) {
planner.addExtraTransformation(dynamicFilteringInputTransform);
return transformation;
这个dynamicFilteringInputTransform最终被加进PlannerBase的extraTransformations,并最终在translateToPlan当中加在transformations的最后
transformations ++ planner.extraTransformations
另一个分支是构建MultipleInputTransformation,两个输入分别是TableSource和dynamicFilteringInputTransform
MultipleInputTransformation<RowData> multipleInputTransformation =
new MultipleInputTransformation<>(
"Order-Enforcer",
new ExecutionOrderEnforcerOperatorFactory<>(),
transformation.getOutputType(),
transformation.getParallelism(),
false);
multipleInputTransformation.addInput(dynamicFilteringInputTransform);
multipleInputTransformation.addInput(transformation);
return multipleInputTransformation;
6 DynamicFilteringDataCollectorOperator
BatchExecTableSourceScan当中很重要的一个点就是BatchExecDynamicFilteringDataCollector,这个对象最终也要转化成Flink的算子Operator,作用就是收集维表的数据,过滤后发送到Coordinator
BatchExecDynamicFilteringDataCollector.translateToPlanInternal当中创建了DynamicFilteringDataCollectorOperatorFactory并传给InputTransformation,DynamicFilteringDataCollectorOperatorFactory.createStreamOperator当中创建了DynamicFilteringDataCollectorOperator,这就是最后的算子
BatchExecDynamicFilteringDataCollector当中还有一个配置,配置了动态分区裁剪允许收集维表数据的最大值,以防止OOM的产生。这个配置最终传递到了DynamicFilteringDataCollectorOperator
private static final ConfigOption<MemorySize> TABLE_EXEC_DYNAMIC_FILTERING_THRESHOLD =
key("table.exec.dynamic-filtering.threshold")
.memoryType()
.defaultValue(MemorySize.parse("8 mb"))
.withDescription(
"If the collector collects more data than the threshold (default is 8M), "
+ "an empty DynamicFilterEvent with a flag only will be sent to Coordinator, "
+ "which could avoid exceeding the akka limit and out-of-memory (see "
+ AkkaOptions.FRAMESIZE.key()
+ "). Otherwise a DynamicFilterEvent with all deduplicated records will be sent to Coordinator.");
此外,DynamicFilteringDataCollectorOperatorFactory当中也提供了DynamicFilteringDataCollectorOperatorCoordinator的创建,在DefaultExecutionGraph.initializeJobVertex的流程中获取创建
public OperatorCoordinator.Provider getCoordinatorProvider(
String operatorName, OperatorID operatorID) {
return new DynamicFilteringDataCollectorOperatorCoordinator.Provider(
operatorID, new ArrayList<>(dynamicFilteringDataListenerIDs));
}
6.1 open
open里面最重要的就是FieldGetter数组的创建
this.fieldGetters =
IntStream.range(0, dynamicFilteringFieldIndices.size())
.mapToObj(
i ->
RowData.createFieldGetter(
dynamicFilteringFieldType.getTypeAt(i),
dynamicFilteringFieldIndices.get(i)))
.toArray(FieldGetter[]::new);
其本质就是根据字段类型用特定的方式读取数据
switch (fieldType.getTypeRoot()) {
case CHAR:
case VARCHAR:
fieldGetter = row -> row.getString(fieldPos);
break;
case BOOLEAN:
fieldGetter = row -> row.getBoolean(fieldPos);
break;
6.2 processElement
核心处理逻辑,接收维表的数据并做过滤,数据会缓存在buffer中并等待最后发送。因为数据全部缓存在buffer当中,所以过大的话会引起JobManager的OOM,需要前面将的配置做限制;此外数据需要一次发送给Coordinator,为防止akka消息超限,也需要做限制
方法的头和尾都有一个数据超限的判断,尾部判断超限时会清空buffer缓存
if (exceedThreshold()) {
// Clear the filtering data and disable self by leaving the currentSize unchanged
buffer.clear();
LOG.warn(
"Collected data size exceeds the threshold, {} > {}, dynamic filtering is disabled.",
currentSize,
threshold);
}
处理函数的基本逻辑就是取出维表数据当中用于动态分区过滤的字段数据,组建成一个新的数据并序列化缓存起来
这里先取维表的部分字段组成动态分区过滤的数据
RowData value = element.getValue();
GenericRowData rowData = new GenericRowData(dynamicFilteringFieldIndices.size());
for (int i = 0; i < dynamicFilteringFieldIndices.size(); ++i) {
rowData.setField(i, fieldGetters[i].getFieldOrNull(value));
}
对数据做序列化并缓存进buffer,缓存的同时会做去重,利用的buffer的特性
try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {
DataOutputViewStreamWrapper wrapper = new DataOutputViewStreamWrapper(baos);
serializer.serialize(rowData, wrapper);
boolean duplicated = !buffer.add(baos.toByteArray());
if (duplicated) {
return;
}
currentSize += baos.size();
}
6.3 finish/sendEvent
动态分区裁剪只适用批作业,数据处理完成,operator也会接受finish调用,一次性处理数据,处理逻辑就是调用sendEvent发送buffer中缓存的数据
finish当中只是做了一个简单的超限判断,然后就是直接调用的sendEvent
if (exceedThreshold()) {
LOG.info(
"Finish collecting. {} bytes are collected which exceeds the threshold {}. Sending empty data.",
currentSize,
threshold);
} else {
LOG.info(
"Finish collecting. {} bytes in {} rows are collected. Sending the data.",
currentSize,
buffer.size());
}
sendEvent();
sendEvent就是把buffer封装成DynamicFilteringData,然后再封装成DynamicFilteringEvent,最后发送到Coordinator
if (exceedThreshold()) {
dynamicFilteringData =
new DynamicFilteringData(
typeInfo, dynamicFilteringFieldType, Collections.emptyList(), false);
} else {
dynamicFilteringData =
new DynamicFilteringData(
typeInfo, dynamicFilteringFieldType, new ArrayList<>(buffer), true);
}
DynamicFilteringEvent event = new DynamicFilteringEvent(dynamicFilteringData);
operatorEventGateway.sendEventToCoordinator(new SourceEventWrapper(event));
7 DynamicFilteringDataCollectorOperatorCoordinator
核心就是一个handle处理handleEventFromOperator,负责接收处理operator发送的维表数据
先是从事件中还原DynamicFilteringData
DynamicFilteringData currentData =
((DynamicFilteringEvent) ((SourceEventWrapper) event).getSourceEvent()).getData();
接下来有一个数据有效性判断,因为在推测机制或者失败重试的场景下,消息可能发送两次,所以需要做一个数据是否已经接受的判断。因为只适用批处理,所以就一次赋值
if (receivedFilteringData == null) {
receivedFilteringData = currentData;
} else {
// Since there might be speculative execution or failover, we may receive multiple
// notifications, and we can't tell for sure which one is valid for further processing.
if (DynamicFilteringData.isEqual(receivedFilteringData, currentData)) {
// If the notifications contain exactly the same data, everything is alright, and
// we don't need to send the event again.
return;
} else {
// In case the mismatching of the source filtering result and the dim data, which
// may leads to incorrect result, trigger global failover for fully recomputing.
throw new IllegalStateException(
"DynamicFilteringData is recomputed but not equal. "
+ "Triggering global failover in case the result is incorrect. "
+ " It's recommended to re-run the job with dynamic filtering disabled.");
}
}
经过一系列的判断,最后把event发送到SourceCoordinator
// Subtask index and attempt number is not necessary for handling
// DynamicFilteringEvent.
((OperatorCoordinator) oldValue)
.handleEventFromOperator(0, 0, event);
8 SourceCoordinator
SourceCoordinator是FLP-27设计新增的一个内容,是一个独立的组件,不是ExecutionGraph的一部分,设计上可以运行在JobMaster上或者作为一个独立进程(具体实现应该是在JobMaster上)
与SourceCoordinator(Enumerator)的通信经过RPC,分片的分配通过RPC以pull方式进行。SourceCoordinator的地址信息在TaskDeploymentDescriptor当中,或者基于JobMaster更新。SourceReader需要向SourceCoordinator注册并发送分片请求
每个job至多有一个由JobMaster启动的SourceCoordinator。一个job可能有多个Enumerator,因为可能有多个不同的source,所有的Enumerator都运行在这个SourceCoordinator
Split分配需要满足checkpoint语义。Enumerator有自己的状态(split分配),是全局checkpoint的一部分。当一个新的checkpoing被触发,CheckpointCoordinator首先发送barrier到SourceCoordinator。SourceCoordinator保存所有Enumerator的快照状态,然后发送barrier到SourceReader
8.1 handleSourceEvent
handleEventFromOperator处理事件请求,判断是SourceEventWrapper类型,走handleSourceEvent分支
} else if (event instanceof SourceEventWrapper) {
handleSourceEvent(
subtask,
attemptNumber,
((SourceEventWrapper) event).getSourceEvent());
handleSourceEvent调用enumerator的处理函数,进行数据分片,动态分区过滤有一个专门的实现:DynamicFileSplitEnumerator(这个会调用DynamicFileEnumerator)
} else {
enumerator.handleSourceEvent(subtask, event);
}
9 Hive Connector变更
官网提供的Hive变更如下,中间两行绿色部分为新增的类

9.1 DynamicFileSplitEnumerator
就是8.1提到的DynamicFileSplitEnumerator,是SplitEnumerator的实现,所以有通用的handleSplitRequest等接口,DPP相关的核心点在handleSourceEvent接口
public void handleSourceEvent(int subtaskId, SourceEvent sourceEvent) {
if (sourceEvent instanceof DynamicFilteringEvent) {
LOG.warn("Received DynamicFilteringEvent: {}", subtaskId);
createSplitAssigner(((DynamicFilteringEvent) sourceEvent).getData());
} else {
LOG.error("Received unrecognized event: {}", sourceEvent);
}
}
createSplitAssigner本质就是调用下层的DynamicFileEnumerator完成分片
private void createSplitAssigner(@Nullable DynamicFilteringData dynamicFilteringData) {
DynamicFileEnumerator fileEnumerator = fileEnumeratorFactory.create();
if (dynamicFilteringData != null) {
fileEnumerator.setDynamicFilteringData(dynamicFilteringData);
}
Collection<FileSourceSplit> splits;
try {
splits = fileEnumerator.enumerateSplits(new Path[1], context.currentParallelism());
allEnumeratingSplits =
splits.stream().map(FileSourceSplit::splitId).collect(Collectors.toSet());
} catch (IOException e) {
throw new FlinkRuntimeException("Could not enumerate file splits", e);
}
splitAssigner = splitAssignerFactory.create(splits);
}
9.2 DynamicFileEnumerator
目前的实现只看到HiveSourceDynamicFileEnumerator,重点接口是setDynamicFilteringData,方法中完成了分区提取,如3.5中所述