Keras技术框架提供工具类库,用于对TensorFlow程序相关的超级参数进行调优,为机器学习选择正确的超级参数集合的过程被称之为超级参数调优。
超级参数是指用于治理一个机器学习模型的训练过程及其拓扑结构的变量,这些变量在整个训练过程中保持不变、并能直接影响机器学习程序的性能,超级参数包括以下两种类型:
| 1 模型超级参数,影响模型的选择,例如,隐藏层的层数、每层的单元数 2 算法超级参数,影响模型学习算法的速度以及质量,例如,随机梯度下降算法的学习速率(SGD)、KNN算法中的最近元素的数量 |
安装

如上所示,导入Keras以及TensorFlow的基础工具类、超级参数调优器。
加载数据集

如上所示,加载mnist样本数据集,该数据集是用于训练流行服饰。
定义模型

如上所示,定义一个专门用于超级参数调优的模型,该模型被称之为超级参数模型(hype model),hp_units是定义隐藏层的单元数在超级参数调优过程中的变化范围,其变化范围是32到512,hp_learning_rate是定义学习速率在超级参数调优过程中的变化值的列表,其值包括0.01、0.001、0.0001,该模型使用Adam优化器进行调优。
创建超级参数调优器

如上所示,实例化一个超级参数调优器,传入前面定义的超级参数模型定义函数、设置训练迭代的最大次数。

如上所示,定义一个正则化机制的类型。

如上所示,对前面定义的超级参数调优模型执行检索,输出,最优的隐藏层的单元数是288,最优的优化器的学习速率是0.001,对应的变量是best_hps。
训练超级参数调优模型
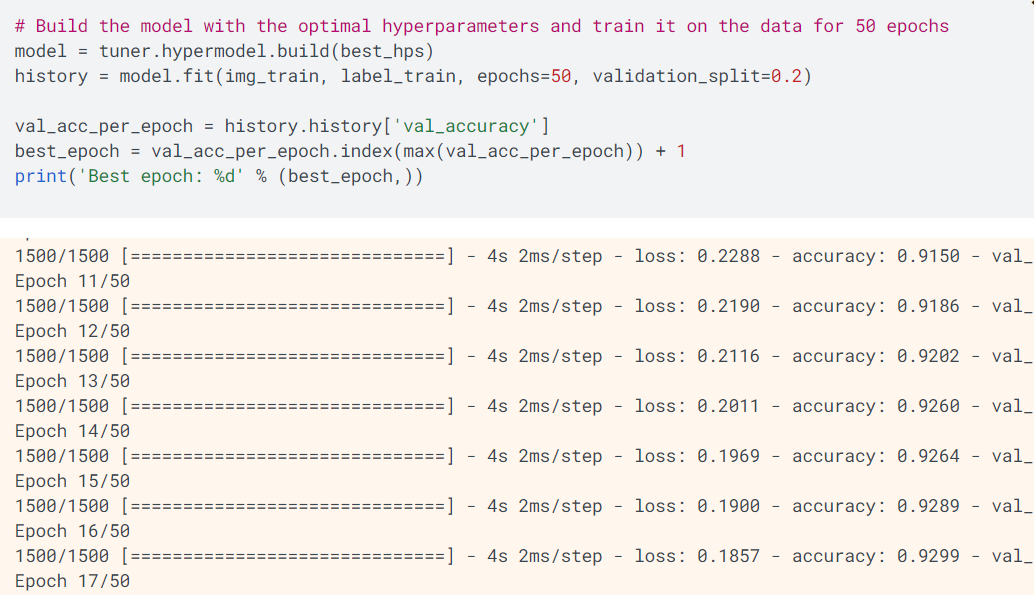
如上所示,使用检索的最优超级参数对模型执行训练,输出,最优的训练迭代次数,其对应的变量是best_epoch。
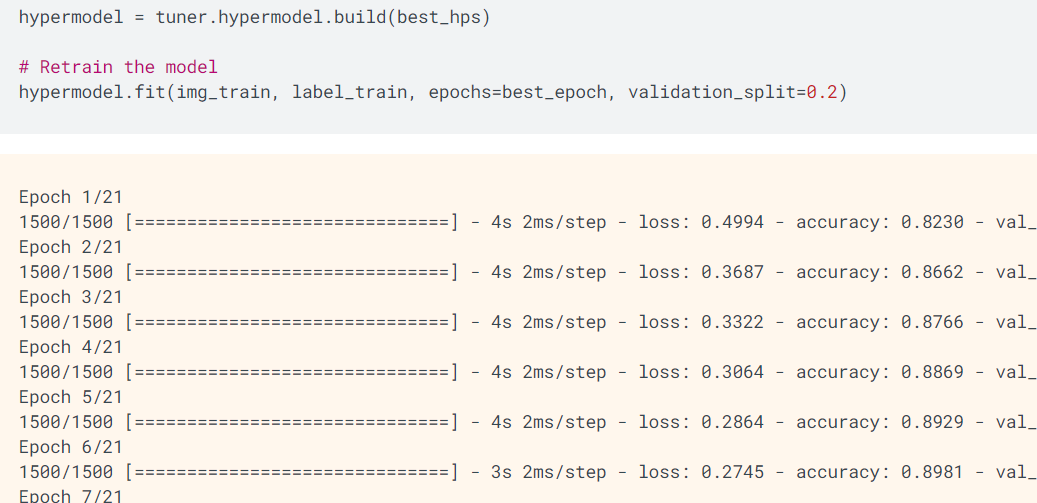
如上所示,使用最优的超级参数best_hps、最优的迭代次数best_epoch对模型执行训练。

如上所示,使用测试数据集对已经调优的模型执行测试评估。
(未完待续)