文章目录
- 什么是Thymeleaf
- 什么是模板引擎
- Thymeleaf的同行
- Thymeleaf优势
- 一个实例来认识大概过程
- 导入对应的jar包
- 配置对应的xml文件
- 对应的ViewBaseServlet编写——对应的模板引擎
- 写对应的Servlet类并且继承ViewBaseServlet
- 对应index.html资源——对应的模板
- Thymeleaf的基础语法
- th名称空间
- 表达式语法
- th:text作用
- 修改指定属性值
- 解析URL地址
- 给URL地址后面附加请求参数(查询字符串)
- 直接执行表达式
- 获取请求参数
- 内置对象
- 基本内置对象
- 公共内置对象
- ${}中的表达式本质是OGNL
- 分支与迭代
- 分支
- 迭代
- 包含其他模板文件
什么是Thymeleaf
官方文档
Thymeleaf is a modern server-side Java template engine for both web and standalone environments, capable of processing HTML, XML, JavaScript, CSS and even plain text. The main goal of Thymeleaf is to provide an elegant and highly-maintainable way of creating templates. To achieve this, it builds on the concept of Natural Templates to inject its logic into template files in a way that doesn’t affect the template from being used as a design prototype. This improves communication of design and bridges the gap between design and development teams. Thymeleaf has also been designed from the beginning with Web Standards in mind – especially HTML5 – allowing you to create fully validating templates if that is a need for you.
- 译过来就是:大概意思就是说Thymeleaf是适用于Web和独立环境的现代服务器端
Java模板引擎
什么是模板引擎
- 模板引擎(这里特指用于Web开发的模板引擎)
是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的html文档。从字面上理解模板引擎,最重要的就是模板二字,这个意思就是做好一个模板后套入对应位置的数据,最终以html的格式展示出来,这就是模板引擎的作用。 - 对于模板引擎的理解,可以这样形象的做一个类比:开会! 相信你在上学初高中时候每次开会都要提前布置场地、拿 小板凳、收拾场地。而你上了大学之后每次开会再也不去大操场了,每次开会都去学校的大会议室,桌子板凳音响主席台齐全,来个人即可,还可复用……。
- 我们的会议室就是我们的类似我们的模板
- 我们的学生和领导类似于我们的业务数据
- 不同的学生和领导到会议室开会,就是不同的会议(比如新生动员大会,毕业生动员大会),类比我们不同的业务数据嵌入到我们的模板中,就是不同的文档(张三登录后的页面,李四登录后的页面)
一些专用名称
-
数据
- 数据是信息的表现形式和载体,可以是符号、文字、数字、语音、图像、视频等。数据和信息是不可分离的,数据是信息的表达,信息是数据的内涵。数据本身没有意义,数据只有对实体行为产生影响时才成为信息。
-
模板
- 模板,是一个蓝图,即一个与类型无关的类。编译器在使用模板时,会根据模板实参对模板进行实例化,得到一个与类型相关的类。
-
模板引擎
- 模板引擎(这里特指用于Web开发的模板引擎)是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。
-
结果文档
- 一种特定格式的文档,比如用于网站的模板引擎就会生成一个标准的HTML文档。
Thymeleaf的同行
- JSP、Freemarker、Velocity等等,它们有一个共同的名字:服务器端模板技术
不仅如此,在Java中模板引擎还有很多,模板引擎是动态网页发展进步的产物,在最初并且流传度最广的jsp它就是一个模板引擎。jsp是官方标准的模板,但是由于jsp的缺点比较多也挺严重的,所以很多人弃用jsp选用第三方的模板引擎,市面上开源的第三方的模板引擎也比较多,有Thymeleaf、FreeMaker、Velocity等模板引擎受众较广。
听完了模板引擎的介绍,相信你也很容易明白了模板引擎在web领域的主要作用:让网站实现界面和数据分离,这样大大提高了开发效率,让代码重用更加容易。
Thymeleaf优势
- SpringBoot官方推荐使用的视图模板技术,和SpringBoot完美整合。
- 不经过服务器运算仍然可以直接查看原始值,对前端工程师更友好。
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p th:text="${hello}">Original Value</p>
</body>
</html>
一个实例来认识大概过程
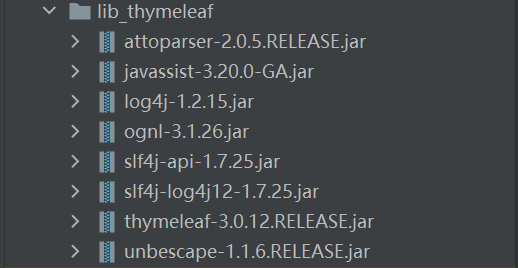
导入对应的jar包
- 这些功能也是Java代码实现的,所以也需要导入对应的jar包
配置对应的xml文件
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"
version="4.0">
<!-- 在上下文参数中配置视图前缀和视图后缀 -->
<context-param>
<param-name>view-prefix</param-name>
<param-value>/</param-value>
</context-param>
<context-param>
<param-name>view-suffix</param-name>
<param-value>.html</param-value>
</context-param>
</web-app>
为什么要放在WEB-INF目录下?
原因:WEB-INF目录不允许浏览器直接访问,所以我们的视图模板文件放在这个目录下,是一种保护。以免外界可以随意访问视图模板文件。
访问WEB-INF目录下的页面,都必须通过Servlet转发过来,简单说就是:不经过Servlet访问不了。
这样就方便我们在Servlet中检查当前用户是否有权限访问。
那放在WEB-INF目录下之后,重定向进不去怎么办?
重定向到Servlet,再通过Servlet转发到WEB-INF下
对应的ViewBaseServlet编写——对应的模板引擎
根据我们的jar包资源的基础上实现了对应的模板引擎的功能
这个类直接复制粘贴即可,将来使用框架后,这些代码都将被取代。
package com.lsc.myssm.myspringmvc;
import org.thymeleaf.TemplateEngine;
import org.thymeleaf.context.WebContext;
import org.thymeleaf.templatemode.TemplateMode;
import org.thymeleaf.templateresolver.ServletContextTemplateResolver;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
public class ViewBaseServlet extends HttpServlet {
private TemplateEngine templateEngine;
@Override
public void init() throws ServletException {
// 1.获取ServletContext对象
ServletContext servletContext = this.getServletContext();
// 2.创建Thymeleaf解析器对象
ServletContextTemplateResolver templateResolver = new ServletContextTemplateResolver(servletContext);
// 3.给解析器对象设置参数
// ①HTML是默认模式,明确设置是为了代码更容易理解
templateResolver.setTemplateMode(TemplateMode.HTML);
// ②设置前缀
String viewPrefix = servletContext.getInitParameter("view-prefix");
templateResolver.setPrefix(viewPrefix);
// ③设置后缀
String viewSuffix = servletContext.getInitParameter("view-suffix");
templateResolver.setSuffix(viewSuffix);
// ④设置缓存过期时间(毫秒)
templateResolver.setCacheTTLMs(60000L);
// ⑤设置是否缓存
templateResolver.setCacheable(true);
// ⑥设置服务器端编码方式
templateResolver.setCharacterEncoding("utf-8");
// 4.创建模板引擎对象
templateEngine = new TemplateEngine();
// 5.给模板引擎对象设置模板解析器
templateEngine.setTemplateResolver(templateResolver);
}
protected void processTemplate(String templateName, HttpServletRequest req, HttpServletResponse resp) throws IOException {
// 1.设置响应体内容类型和字符集
resp.setContentType("text/html;charset=UTF-8");
// 2.创建WebContext对象
WebContext webContext = new WebContext(req, resp, getServletContext());
// 3.处理模板数据
templateEngine.process(templateName, webContext, resp.getWriter());
}
}
- 继承这个类,可以实现模板引擎的功能
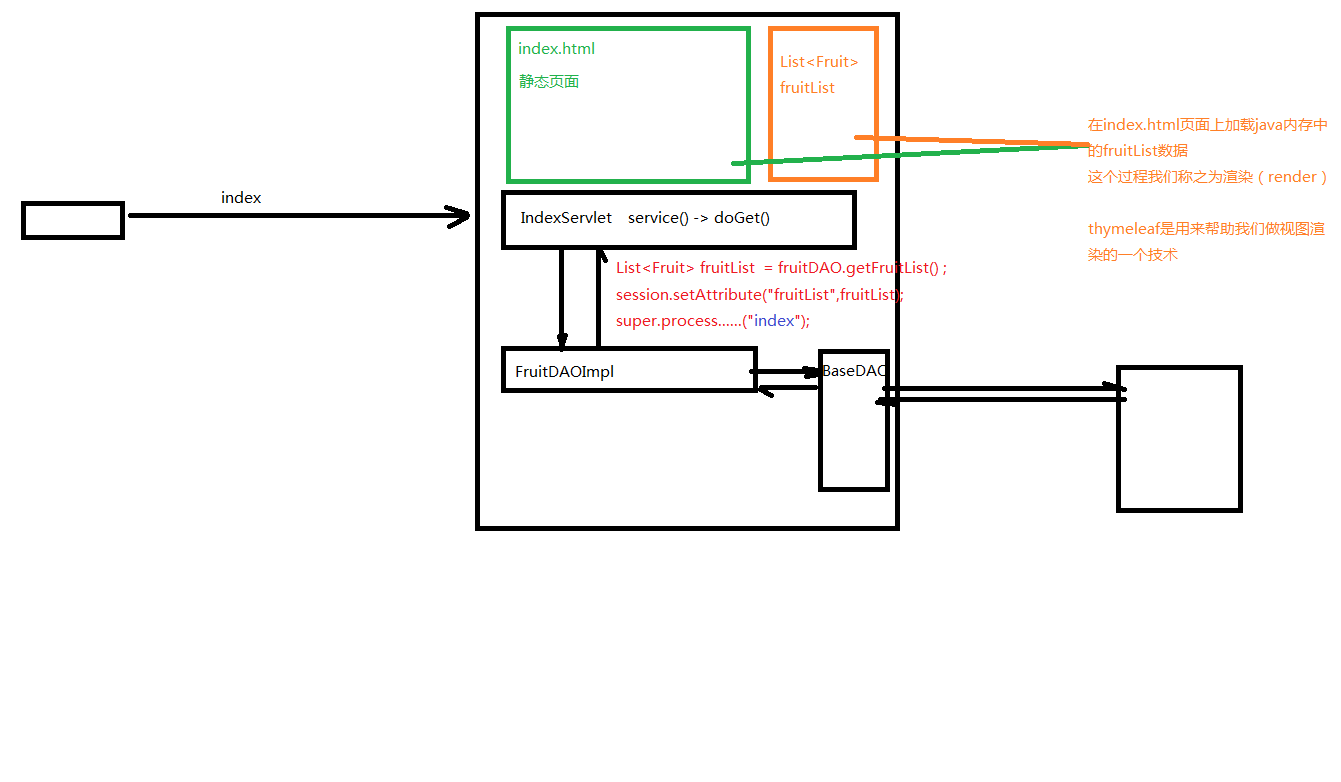
写对应的Servlet类并且继承ViewBaseServlet
//Servlet从3.0版本开始支持注解方式的注册
@WebServlet("/index")
public class IndexServlet extends ViewBaseServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
FruitDAO fruitDAO=new FruitDAOImpl();
List<Fruit> list=fruitDAO.getAllFruitList();//自己用JDBC封装的方法 可以获得当前数据库中的全部信息
//保存到Session作用域中
HttpSession session=request.getSession();
session.setAttribute("FruitList",list);
//此处的视图名称是 index
//那么thymeleaf会将这个 逻辑视图名称 对应到 物理视图 名称上去
//逻辑视图名称 : index
//物理视图名称 : view-prefix + 逻辑视图名称 + view-suffix
//所以真实的视图名称是: / index .html
super.processTemplate("index",request,response);
}
}
物理视图
在Servlet中,将请求转发到一个HTML页面文件时,使用的完整的转发路径就是物理视图。

/pages/user/login_success.html
如果我们把所有的HTML页面都放在某个统一的目录下,那么转发地址就会呈现出明显的规律:
/pages/user/login.html /pages/user/login_success.html
/pages/user/regist.html /pages/user/regist_success.html
……
路径的开头都是:/pages/user/
路径的结尾都是:.html
所以,路径开头的部分我们称之为视图前缀,路径结尾的部分我们称之为视图后缀
逻辑视图
- 物理视图=视图前缀+逻辑视图+视图后缀
| 视图前缀 | 逻辑视图 | 视图后缀 | 物理视图 |
|---|---|---|---|
| /pages/user/ | login | .html | /pages/user/login.html |
| /pages/user/ | login_success | .html | /pages/user/login_success.html |
对应index.html资源——对应的模板
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<link rel="stylesheet" href="css/index.css">
</head>
<body>
<div id="div_container">
<div id="div_fruit_list">
<table id="tbl_fruit">
<p class="center f30">欢迎使用水果库存后台管理系统</p>
<tr>
<th class="w20">名称</th>
<th class="w20">单价</th>
<th class="w20">库存</th>
<th>操作</th>
</tr>
<tr th:if="${#lists.isEmpty(session.FruitList)}">
<td colspan="4">对不起,库存为空!</td>
</tr>
<tr th:unless="${#lists.isEmpty(session.FruitList)}" th:each="fruit : ${session.FruitList}">
<td th:text="${fruit.fname}">无</td>
<td th:text="${fruit.price}">无</td>
<td th:text="${fruit.fcount}">无</td>
<td><img src="imgs/del.jpg" class="delImg"/></td>
</tr>
</table>
</div>
</div>
</body>
</html>
- FruitList就是对应的业务数据
- FruitList+index.html模块,就可以得到我们的结果文档
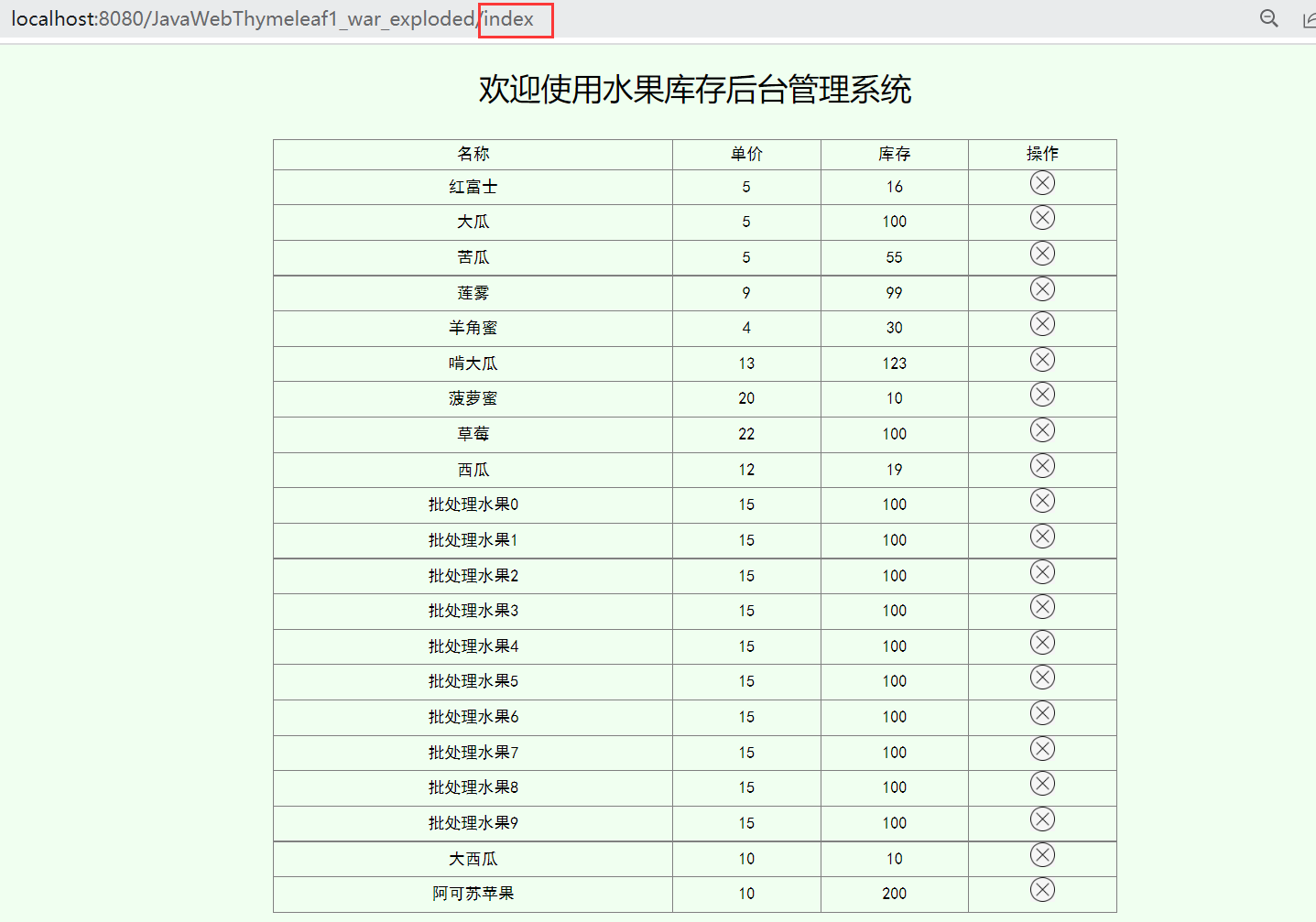
- 最后我们访问index,显示我们所有数据库中水果的信息
Thymeleaf的基础语法
th名称空间
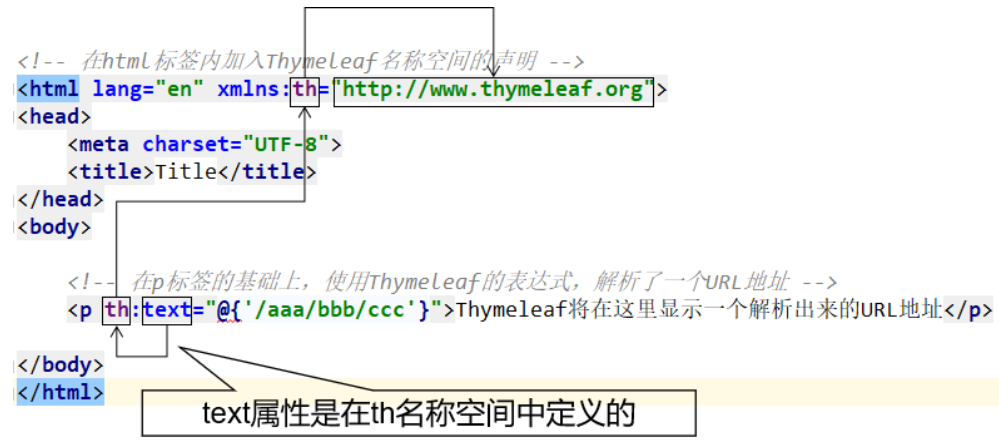
- 我们要在对应的HTML页面中的HTML标签配置对应的thymleaf名称空间的声明
- 然后在页面中写上th:,说明对应的内容会使用Thymeleaf的语法
表达式语法
<p th:text="标签体新值">标签体原始值</p>
th:text作用
- 不经过服务器解析,直接用浏览器打开HTML文件,看到的是『标签体原始值』
- 经过服务器解析,Thymeleaf引擎根据th:text属性指定的『标签体新值』去替换『标签体原始值』
修改指定属性值
<input type="text" name="username" th:value="文本框新值" value="文本框旧值" />
- 语法:任何HTML标签原有的属性,前面加上『th:』就都可以通过Thymeleaf来设定新值
解析URL地址
<p th:text="@{/aaa/bbb/ccc}">标签体原始值</p>
经过解析后得到:
/view/aaa/bbb/ccc
所以@{}的作用是**在字符串前附加『上下文路径』**上下文路径(context path)=/Web应用名称
这个语法的好处是:实际开发过程中,项目在不同环境部署时,Web应用的名字有可能发生变化。所以上下文路径不能写死。而通过@{}动态获取上下文路径后,不管怎么变都不怕啦!
首页使用URL地址解析
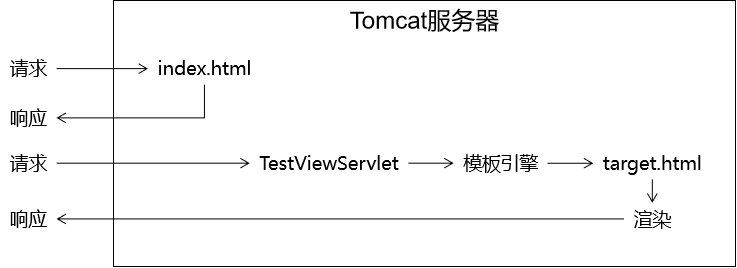
如果我们直接访问index.html本身,那么index.html是不需要通过Servlet,当然也不经过模板引擎,所以index.html上的Thymeleaf的任何表达式都不会被解析。
解决办法:通过Servlet访问index.html,这样就可以让模板引擎渲染页面了:
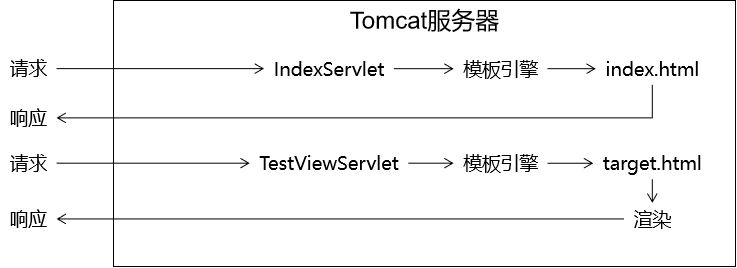
给URL地址后面附加请求参数(查询字符串)

<td ><a th:href="@{'/edit.do?fid='+${fruit.fid}}" th:text="${fruit.fname}">无</a></td>
<td><a th:text="${fruit.fname}" th:href="@{/edit.do(fid=${fruit.fid})}">无</a></td>
- 这两句想实现的功能就是在url中携带了查询字符串(query string)——fid=fruit.fid
- 因为/edit.do?fid=是字符串,但是
${fruit.fid}表示的是一个变量,所以需要使用字符串拼接 - 但是我们Thymeleaf为了方便,对于请求参数可以使用()括起来
直接执行表达式
Servlet代码:
request.setAttribute("reqAttrName", "<span>hello-value</span>");
页面代码:
<p>有转义效果:[[${reqAttrName}]]</p>
<p>无转义效果:[(${reqAttrName})]</p>
执行效果:
<p>有转义效果:<span>hello-value</span></p>
<p>无转义效果:<span>hello-value</span></p>
获取请求参数
具体来说,我们这里探讨的是在页面上(模板页面)获取请求参数。底层机制是:
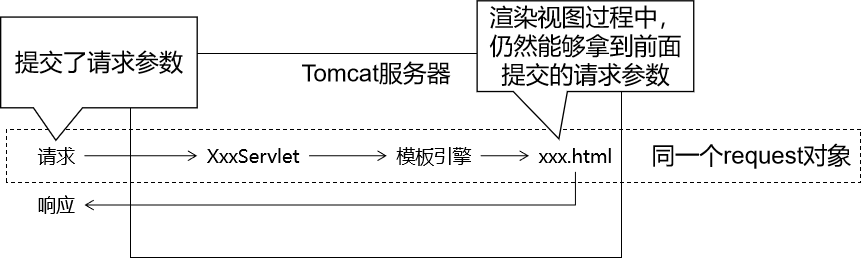
一个名字一个值
页面代码:
<p th:text="${param.username}">这里替换为请求参数的值</p>
页面显示效果:

一个名字多个值
页面代码:
<p th:text="${param.team}">这里替换为请求参数的值</p>
页面显示效果:

如果想要精确获取某一个值,可以使用数组下标。页面代码:
<p th:text="${param.team[0]}">这里替换为请求参数的值</p>
<p th:text="${param.team[1]}">这里替换为请求参数的值</p>

内置对象
基本内置对象
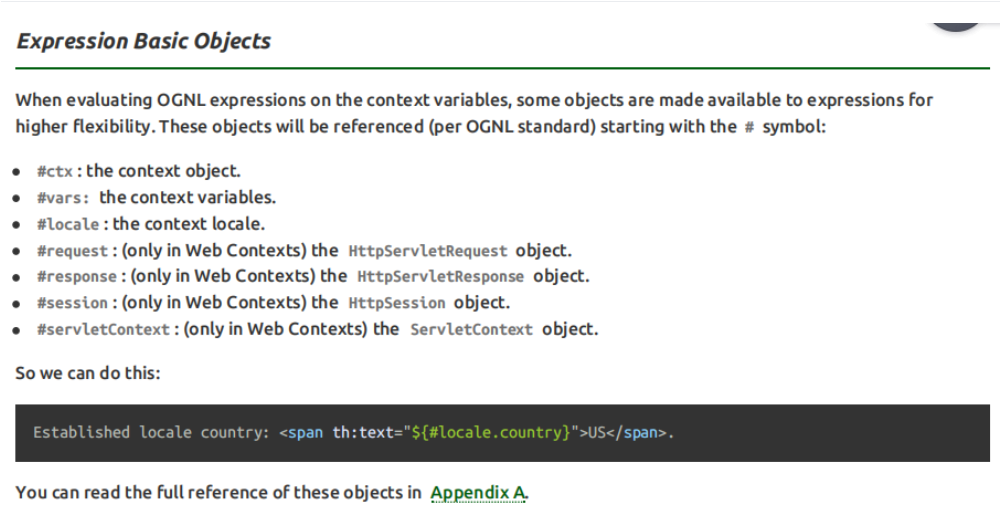
<h3>表达式的基本内置对象</h3>
<p th:text="${#request.getClass().getName()}">这里显示#request对象的全类名</p>
<p th:text="${#request.getContextPath()}">调用#request对象的getContextPath()方法</p>
<p th:text="${#request.getAttribute('helloRequestAttr')}">调用#request对象的getAttribute()方法,读取属性域</p>
基本思路:
- 如果不清楚这个对象有哪些方法可以使用,那么就通过getClass().getName()获取全类名,再回到Java环境查看这个对象有哪些方法
- 内置对象的方法可以直接调用
- 调用方法时需要传参的也可以直接传入参数
公共内置对象

Servlet中将List集合数据存入请求域:
request.setAttribute("aNotEmptyList", Arrays.asList("aaa","bbb","ccc"));
request.setAttribute("anEmptyList", new ArrayList<>());
页面代码:
<p>#list对象isEmpty方法判断集合整体是否为空aNotEmptyList:<span th:text="${#lists.isEmpty(aNotEmptyList)}">测试#lists</span></p>
<p>#list对象isEmpty方法判断集合整体是否为空anEmptyList:<span th:text="${#lists.isEmpty(anEmptyList)}">测试#lists</span></p>
公共内置对象对应的源码位置:
${}中的表达式本质是OGNL
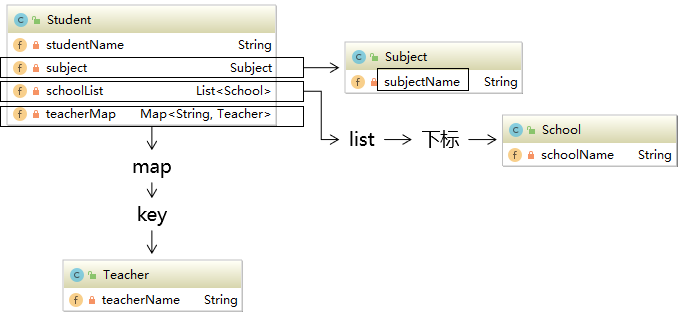
OGNL
- OGNL:Object-Graph Navigation Language对象-图 导航语言
对象图
从根对象触发,通过特定的语法,逐层访问对象的各种属性。
OGNL语法
①起点
在Thymeleaf环境下,${}中的表达式可以从下列元素开始:
- 访问属性域的起点
- 请求域属性名
- session
- application
- param
- 内置对象
- #request
- #session
- #lists
- #strings
②属性访问语法
- 访问对象属性:使用getXxx()、setXxx()方法定义的属性
- 对象.属性名
- 访问List集合或数组
- 集合或数组[下标]
- 访问Map集合
- Map集合.key
- Map集合[‘key’]
分支与迭代
分支
①if和unless
让标记了th:if、th:unless的标签根据条件决定是否显示。
示例的实体类:
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
}
示例的Servlet代码:
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 1.创建ArrayList对象并填充
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee(1, "tom", 500.00));
employeeList.add(new Employee(2, "jerry", 600.00));
employeeList.add(new Employee(3, "harry", 700.00));
// 2.将集合数据存入请求域
request.setAttribute("employeeList", employeeList);
// 3.调用父类方法渲染视图
super.processTemplate("list", request, response);
}
示例的HTML代码:
<table>
<tr>
<th>员工编号</th>
<th>员工姓名</th>
<th>员工工资</th>
</tr>
<tr th:if="${#lists.isEmpty(employeeList)}">
<td colspan="3">抱歉!没有查询到你搜索的数据!</td>
</tr>
<tr th:if="${not #lists.isEmpty(employeeList)}">
<td colspan="3">有数据!</td>
</tr>
<tr th:unless="${#lists.isEmpty(employeeList)}">
<td colspan="3">有数据!</td>
</tr>
这两个是一样的效果
</table>
if配合not关键词和unless配合原表达式效果是一样的,看自己的喜好。
switch
<h3>测试switch</h3>
<div th:switch="${user.memberLevel}">
<p th:case="level-1">银牌会员</p>
<p th:case="level-2">金牌会员</p>
<p th:case="level-3">白金会员</p>
<p th:case="level-4">钻石会员</p>
</div>
迭代
<h3>测试each</h3>
<table>
<thead>
<tr>
<th>员工编号</th>
<th>员工姓名</th>
<th>员工工资</th>
</tr>
</thead>
<tbody th:if="${#lists.isEmpty(employeeList)}">
<tr>
<td colspan="3">抱歉!没有查询到你搜索的数据!</td>
</tr>
</tbody>
<tbody th:if="${not #lists.isEmpty(employeeList)}">
<!-- 遍历出来的每一个元素的名字 : ${要遍历的集合} -->
<tr th:each="employee : ${employeeList}">
<td th:text="${employee.empId}">empId</td>
<td th:text="${employee.empName}">empName</td>
<td th:text="${employee.empSalary}">empSalary</td>
</tr>
</tbody>
</table>
在迭代过程中,可以参考下面的说明使用迭代状态:

<h3>测试each</h3>
<table>
<thead>
<tr>
<th>员工编号</th>
<th>员工姓名</th>
<th>员工工资</th>
<th>迭代状态</th>
</tr>
</thead>
<tbody th:if="${#lists.isEmpty(employeeList)}">
<tr>
<td colspan="3">抱歉!没有查询到你搜索的数据!</td>
</tr>
</tbody>
<tbody th:if="${not #lists.isEmpty(employeeList)}">
<!-- 遍历出来的每一个元素的名字 : ${要遍历的集合} -->
<tr th:each="employee,empStatus : ${employeeList}">
<td th:text="${employee.empId}">empId</td>
<td th:text="${employee.empName}">empName</td>
<td th:text="${employee.empSalary}">empSalary</td>
<td th:text="${empStatus.count}">count</td>
</tr>
</tbody>
</table>
包含其他模板文件
应用场景
抽取各个页面的公共部分:
创建页面的代码片创建页面的代码片段
使用th:fragment来给这个片段命名:
<div th:fragment="header">
<p>被抽取出来的头部内容</p>
</div>
包含到有需要的页面
| 语法 | 效果 |
|---|---|
| th:insert | 把目标的代码片段整个插入到当前标签内部 |
| th:replace | 用目标的代码替换当前标签 |
| th:include | 把目标的代码片段去除最外层标签,然后再插入到当前标签内部 |
页面代码举例:
<!-- 代码片段所在页面的逻辑视图 :: 代码片段的名称 -->
<div id="badBoy" th:insert="segment :: header">
div标签的原始内容
</div>
<div id="worseBoy" th:replace="segment :: header">
div标签的原始内容
</div>
<div id="worstBoy" th:include="segment :: header">
div标签的原始内容
</div>