“增删改查”都是查找问题,因为你都得先找到数据才能对数据做操作。那存储系统性能问题,其实就是查找快慢问题。
存储系统一次查询所耗时间取决两个因素:
- 查找的时间复杂度
- 数据总量
查找的时间复杂度取决于:
- 查找算法
- 存储数据的数据结构
大多业务系统用现成数据库,数据的存储结构和查找算法都由数据库实现,业务系统基本没法去改变。如MySQL InnoDB存储结构B+树,查找算法大多是树的查找,查找时间复杂度就是O(log n),唯一能改变的,就是数据总量。
所以,解决海量数据导致存储系统慢,就是“拆”,即分片。拆开之后,每个分片里的数据就没那么多了,然后让查找尽量落在某个分片提升查找性能。
存档历史订单数据提升查询性能
数据都具备时间属性,并随系统运行,累计增长越来越多,数据量达到一定程度就越来越慢,如订单数据,一般保存在MySQL订单表,当单表订单数据太多,影响性能,首选方案:归档历史订单。
归档是一种拆分数据策略,把大量历史订单移到另外一张历史订单表。像订单这类有时间属性的数据,都存在热尾效应。大多数访问最近数据,但订单表里大量数据都不怎么常用的老数据。
新数据只占数据总量中很少一部分,所以把新老数据分开,新数据的数据量就少,查询速度快很多。老数据和之前比起来没少,查询速度提升不明显,但老数据很少会被访问,所以慢点问题不大。
这样拆分好处,拆分订单时,要改动的代码少。大部分对订单表的操作都是在订单完成前,这些业务逻辑完全不用修改。即使退货退款这类订单完成后操作,也有时限,这些业务逻辑也不需要修改,原来该怎么操作订单表还怎么操作。
基本只有查询统计类功能,会查历史订单,要稍微调整,按时间,选择去订单表or历史订单表查询。查“三个月前订单”的选项,其实就是查订单历史表。
归档历史订单的流程:
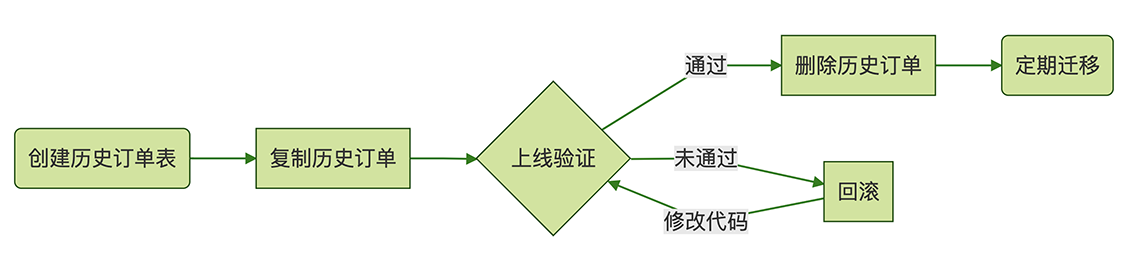
- 首先我们需要创建一个和订单表结构一模一样的历史订单表;
- 然后,把订单表中的历史订单数据分批查出来,插入到历史订单表中去。这个过程你怎么实现都可以,用存储过程、写个脚本或者写个导数据的小程序都行,用你最熟悉的方法就行。如果你的数据库已经做了主从分离,那最好是去从库查询订单,再写到主库的历史订单表中去,这样对主库的压力会小一点儿。
- 现在,订单表和历史订单表都有历史订单数据,先不要着急去删除订单表中的数据,你应该测试和上线支持历史订单表的新版本代码。因为两个表都有历史订单,所以现在这个数据库可以支持新旧两个版本的代码,如果新版本的代码有Bug,你还可以立刻回滚到旧版本,不至于影响线上业务。
- 等新版本代码上线并验证无误之后,就可以删除订单表中的历史订单数据了。
- 最后,还需要上线一个迁移数据的程序或者脚本,定期把过期的订单从订单表搬到历史订单表中去。
类似于订单商品表这类订单的相关的子表,也是需要按照同样的方式归档到各自的历史表中,由于它们都是用订单ID作为外键来关联到订单主表的,随着订单主表中的订单一起归档就可以了。
这个过程中,我们要注意的问题是,要做到对线上业务的影响尽量的小。迁移这么大量的数据,或多或少都会影响数据库的性能,你应该尽量放在闲时去迁移,迁移之前一定做好备份,这样如果不小心误操作了,也能用备份来恢复。
批量删除大量数据
如何从订单表删除已迁走的历史订单数据?直接执行一个删除历史订单的SQL:
delete from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);
大概提示删除失败,因为要删除的数据量太大,所以要分批删除。如每批删除1000条记录:
delete from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month)
order by id limit 1000;
执行删除语句的时候,最好在每次删除之间停顿一会儿,避免给数据库造成太大压力。反复执行这个SQL,直到全部历史订单都被删除。
SQL还能优化,它每执行一次,都要先去timestamp对应索引找出符合条件记录,再把这些记录按照订单ID排序,之后删除前1000条记录。
没必要每次按timestamp比较订单,可先通过一次查询,找到符合条件的历史订单中最大的订单ID,然后在删除语句中把删除的条件转换成按主键删除。
select max(id) from orders
where timestamp < SUBDATE(CURDATE(),INTERVAL 3 month);
delete from orders
where id <= ?
order by id limit 1000;
这样每次删除的时候,由于条件变成主键比较,B+树本身有序,所以查找快,也不需要再额外排序操作。这样做前提条件:订单ID必须和订单时间正相关,大多数订单ID的生成规则都满足这条件,问题不大。
为什么在删除语句中,非得加个排序?按ID排序后,每批删除的记录,基本都是ID连续一批记录,由于B+树有序性,这些ID相近记录,在磁盘物理文件也放在一起,删除效率较高,便于MySQL回收页。
大量的历史订单数据删除完成后,若检查MySQL占用磁盘空间,会发现它占用磁盘空间并没有变小,why?和InnoDB物理存储结构有关。
虽逻辑上每个表是颗B+树,但物理上每条记录都存放在磁盘文件,这些记录通过一些位置指针组织成一颗B+树。当MySQL删除一条记录,只能是找到记录所在的文件中位置,然后把文件的这块区域标记为空闲,然后再修改B+树中相关的一些指针,完成删除。其实那条被删除的记录还是躺在那个文件的那个位置,不会释放磁盘空间。
这么做也是没有办法的办法,因为文件就是一段连续二进制字节,类似数组,不支持从文件中间删除一部分数据。若非要这么删除,只是把这位置后的所有数据往前挪,这等于要移动大量数据,慢。所以,删除只能是标记一下,并不真正删除,后续写新数据时再重用这块空间。
不仅MySQL,很多其他的数据库都会有类似的问题。这个问题也没什么特别好的办法解决,磁盘空间足够的话,就这样吧,至少数据删了,查询速度也快,基本达到目的。
若DB的磁盘空间紧张,非要把这部分磁盘空间释放,可执行OPTIMIZE TABLE释放存储空间。对InnoDB执行OPTIMIZE TABLE就是把这个表重建,执行过程中会一直锁表,即这时下单都会被卡住。这么优化的前提条件:MySQL配置须是每个表独立一个表空间(innodb_file_per_table = ON),如果所有表都是放在一起的,执行OPTIMIZE TABLE也不会释放磁盘空间。
重建表的过程,索引也会重建,这样表数据和索引数据都更紧凑,不仅占用磁盘空间更小,查询效率也会有提升。对频繁插入删除大量数据的表,如能接受锁表,定期执行OPTIMIZE TABLE非常有必要。
如系统接受暂时停服,最快的:
- 直接新建一个临时订单表
- 把当前订单复制到临时订单表
- 再把旧的订单表改名
- 最后把临时订单表的表名改成正式订单表
这相当于手工把订单表重建,但不需要漫长删除历史订单过程。
-- 新建一个临时订单表
create table orders_temp like orders;
-- 把当前订单复制到临时订单表中
insert into orders_temp
select * from orders
where timestamp >= SUBDATE(CURDATE(),INTERVAL 3 month);
-- 修改替换表名
rename table orders to orders_to_be_droppd, orders_temp to orders;
-- 删除旧表
drop table orders_to_be_dropp
总结
对于订单这类具有时间属性的数据,会随时间累积,数据量越来越多,为了提升查询性能需要对数据进行拆分,首选的拆分方法是把旧数据归档到历史表中去。这种拆分方法能起到很好的效果,更重要的是对系统的改动小,升级成本低。
在迁移历史数据过程中,如果可以停服,最快的方式是重建一张新的订单表,然后把三个月内的订单数据复制到新订单表中,再通过修改表名让新的订单表生效。如果只能在线迁移,那需要分批迭代删除历史订单数据,删除的时候注意控制删除节奏,避免给线上数据库造成太大压力。线上数据操作非常危险,在操作之前一定要做好数据备份。
FAQ
这种“归档历史订单”的数据拆分方法,和直接进行分库分表相比,比如说按照订单创建时间,自动拆分成每个月一张表,两种方法各有什么优点和缺点?
复制状态机除了用于数据库的备份和复制以外,在计算机技术领域,还有哪些地方也用到了复制状态机?
复制状态机的应用是非常广泛的,比如说现在很火的区块链技术,也是借鉴了复制状态机理论,它的链,或者说是账本就是操作日志,每个人的钱包,就是状态。它只要保证账本一旦记录后就不会被篡改,那在任何人的电脑上,计算出来的钱包就都是一样的。
“归档历史订单”可以灵活控制,比如把不再会进行修改的订单,迁移到偏重查询快系统(各种NOSQL),不再需要online查询的数据,可以迁移到offline的库中。
直接进行分库分表,会遇到冷热不均的问题,如:电商大促或年节购物旺季订单量与谈季和平季订单可能会量级差别。用时间这个维度去分库分表,操作上相对简单,但是到达这种需要分库分表量级的系统,切分的灵活性更加重要,怎么分业务场景不同切分维度也会不同。
如果不进行OPTIMIZE,想通过历史表来提升性能的目的岂不是达不到了?
不执行OPTIMIZE也是可以提升性能的。数据和索引虽然在物理上没有删除,但逻辑上已经删除掉了,执行查询操作的时候,并不会去访问这些已经删除的数据。
比如,原来有100条数据,删除完成后剩了10条。虽然100条数据都在磁盘文件中,但这时候执行一次全表扫描,MySQL只会访问剩下的10条数据。
一下子和Java的GC算法产生了共鸣。
创建新表的方式,只复制少部分数据,效率更高,但你要能接受这段时间的STW。这是复制算法。
历史归档,删除数据的方式,会产生碎片,利用率低。只有到空间不足的情况下,才进行压缩整理(OPTIMIZE)。这是标记清理算法,关键时刻再整理(STW),CMS GC就是这个思路。
是的,磁盘碎片和内存碎片产生的原因是一样的,所以清理的思路很多都是相似的。
按时间分库分表一直有个疑惑, 按月进行分表, 有几个月数据很小,有几个月数据特别大,这种会怎么处理
这种情况可能就不适合按月来分片。
alter table A engine=InnoDB 命令来重建这样也能达到释放空间的效果吧?
是可以的。
定期归历史的方式其实oracle的使用频率是最高的。
不过删主键的方式确实不曾想到和尝试过,觉得短期不失为不错的选择。
自动分表总归会有坑:这也是为何自动化的极限还是要人去监控;自动化减少的人的机械操作而已,不是不需要人去操作和监控,尤其数据库数量众多时还是要人去自动化。
手工虽麻烦细节上的把控会比较好:细节会把控的比较好。
相对合理的方式应当是二者结合:1)拆分之前人为的做一次检查,2)拆分的动作自动化去执行,3)结果由人去复核。
毕竟当需要同时拆分的工作量很庞大时不可能全部都是手工操作,这其实就像运维:一个人去操作2-3台可能,20-50其实就很困难了,500以上要全部人为操作基本就只能自动化+人为操作了。
\1. 自动分表需要事先做好预估,把时间间隔设置好,如果表数据增长速度不均匀(例如淡季旺季,后期业务膨胀),可能需要重新设计分表规则,很麻烦。表名也变化了,代码侵入性比较大。
优点就是如果数据增长速度变化不大,不用持续做归档。
-
\2. 归档的好处是代码侵入性低,因为热表名字还是一样。表增长速度变成也能灵活改变归档数据大小跟速度。
缺点就是需要持续归档迁移,后期归档数据太大也会遇到瓶颈什么情况下需要归档,什么情况需要分库分表呢?有什么具体的指标吗?
如果归档能解决问题,就不要分库分表。
归档历史数据的优点是简单,对系统的改造少,缺点是不是长久之计
分库分表需要对数据访问层做架构变更,对系统的改造大,要考虑数据分布,对接口查询性能等业务需求的影响,另外我觉得按时间分表跟我们设计这个分库分表就不符,我们做业务数据分库分表就是想数据打散,按时间分达不到这个目的,按时间适用在做一体化系统,因为这些系统有很多报表统计需求可能用的上任何时间属性相关的数据基本都可以这样处理(比如聊天数据),这种处理办法和分库分表等并不冲突。这种办法相对简单大部分情况下效果也比较好,只是如果业务发展很好,那么订单表的数据依旧有可能很多,另外历史数据表依旧是需要查询的,时间越久数据量越多,查询历史数据太慢的话迟早也会是个问题。
分库分表这种方案需要选比较好的shard key,在数据统计上会麻烦一些,单表数据量上来之后依旧有归档的需求。
按月新建表会有数据热点问题,查询和统计还是会比较麻烦。比这个删除规律 是不是有问题啊?
1、创建temp表
2、把历史数据迁移老表
3、check历史数据条数
4、删除老数据?在rename 之前 插入之后 这时候有数据进来 数据会丢在老表里面了?
所以我们说,这个方案的前提是必须得停机操作。
1.前者操作所有数据都会有一个路由的前置操作,这是有开销的。其次,因为分表了,所以其区域查找这种就需要多表数据做聚合,这就会让查询变得很复杂低效(采用mycat这种中间件可以规避业务代码大量改动的问题,但聚合数据的开销依旧是跑不掉的,而且引入中间件还有多一条的问题)。
2.后者其实性能,操作成本,对业务代码的侵入程度都比前者有优势,唯一遗憾的就是其应用场景有限。只有在整体业务单量不大,且归档数据操作概率极低的情况下适用。因为如果业务单量很大,比如日单量一百万,那么这个热数据表能存多久的数据?十天?二十天?这样的时间区间是严重不符合归档条件的,往往归档数据都是半年,少说三四个月的完结订单。而且归档数据,数据量很大。意味着性能很差,频繁导入导出,查询修改,是支撑不住的。
最近的订单表往归档表挪数据的过程中可能一份数据在两张表都存在 这个时候用户查询全部订单的时候是否我们在应用利用是用去重去剔除重复数据
如果要同时查二个表,那合并和去重就在所难免。一般情况下,最好能设计好业务逻辑,尽量不要同时查当前和历史表。
归档历史数据一般可以根据日前时间分类新建表
删除历史数据要注意分批删除,还有就是删除数据但是磁盘空间并没有释放,可以执行optimism table 进行磁盘空间释放执行过程会锁表
还有一种方案就新建一张表迁移所需数据到新的表
注意别忘记和要删除的表的其他表的相关数据保证关系数据库数据最小化,在抗流量的过程中很有作用。历史数据异步同步到大数据环境,定期删除关系数据库里的归档数据。保证sql 执行效率
把历史订单数据归档方案实现相对简单,也很有效果,需要注意的就是归档时注意对线上服务的影响。
如果采用按照订单创建时间分库分表,优点是省去了后面归档历史数据的重复工作,在一定程序上可以提高写入和查询性能,但也有不足。
首先就是采用分库分表在技术复杂度上相比历史数据归档还是高一些的
其次就是如果刚好到新的一个月,前一个月的数据还是属于热数据,所以会涉及多表查询
最后就是这种方案会造成产生大量的表,如果订单数据不大,每个表中数据量也不会太大,有点浪费资源了