目录
1 ROC曲线
2.查看混淆矩阵
3.实战评估股票客户流失预警模型
4.阈值的取值方法
5.KS曲线与KS值
6.获取KS值对应的阈值
7.获取KS值
| 对于二分类模型来说,主流的评估方法有ROC曲线和KS曲线两种方法 | |||||||||||||||||||
1 ROC曲线 | 之前已经获得了模型的准确度为79.77%,但是这个准确度并不可靠 在商业实战中,更关心下面两个指标
TP、FP、TN、FN的含义如下表所示,这个表也叫作混淆矩阵:
| ||||||||||||||||||
| 7000客户中有2000个流失,5000个不流失客户,假设模型预测所有客户都不会流失,如下表所示,那么模型的假警报率(FPR)为0,即没有误伤一个未流失客户,但是此时模型的命中率(TPR)也为0,即没有揪出一个流失客户。 命中率计算的便是在所有实际流失的人中,预测为流失的比例,也称真正率或召回率; 而假警报率则是计算在所有实际没有流失的人当中,预测为流失的比例,也称假正率。
| |||||||||||||||||||
| 一个优秀的客户违约预测模型,我们希望命中率(TPR)尽可能的高,即能尽可能地揪出坏人,同时也希望假警报率(FPR)能尽可能的低,即不要误伤好人。 然而这两者往往成正相关性,因为一旦当调高阈值,比如认为违约率超过90%的才认定为流失,那么会导致假警报率很低,但是命中率也很低。 而如果降低阈值的话,比如认为违约率超过10%就认定为流失,那么命中率就会很高,但是假警报率也会很高。 | |||||||||||||||||||
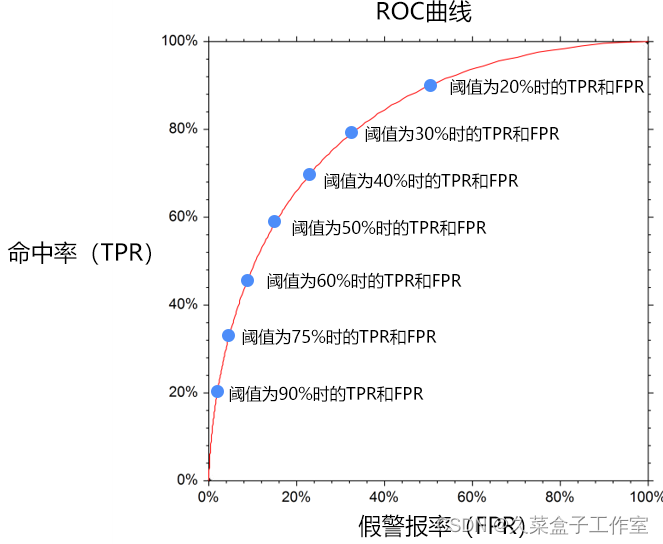
| 因此为了衡量一个模型的优劣,数据科学家根据不同阈值下的命中率和假警报率绘制了如下的曲线图,称之为ROC曲线: ROC曲线的横坐标为假警报率(FPR),其纵坐标为命中率(TPR),在某一个阈值条件下,我们希望命中率能尽可能的高,而假警报率尽可能的低。
举例来说,某一检测样本总量为100,其中流失客户为20人,当阈值为20%的时候,即流失概率超过20%的时候即认为客户会流失时,模型A和模型B预测出来的流失客户都是15人。 如果模型A预测流失的15人中有10人的确流失,有5人属于误判,那么命中率达10/20=50%,此时假警报率为5/80=6.25%。 如果模型B预测流失的15人中只有5人的确流失,有10人属于误判,那么其命中率为5/20=25%,假警报率为10/80=12.5%。 此时模型A的命中率是模型B的2倍,假警报率是模型B的一半,因此我们认为模型A是一个较优的模型。 如果把假警报率理解为代价的话,那么命中率就是收益,所以也可以说在相同阈值的情况下,我们希望假警报率(代价)尽量小的情况下,命中率(收益)尽量的高,该思想反映在图形上就是这个曲线尽可能的陡峭,曲线越靠近左上角说明在同样的阈值条件下,命中率越高,假警报率越小,模型越完善。换一个角度来理解,一个完美的模型是在不同的阈值下,假警报率(FPR)都接近于0,而命中率(TPR)接近于1,该特征反映在图形上,就是曲线非常接近(0,1)这个点,也即曲线非常陡峭。 | |||||||||||||||||||
2.查看混淆矩阵 | customer_warning_ROC.py # 查看混淆矩阵 from sklearn.metrics import confusion_matrix as cm m = cm(y_test, y_pred) # 代入实际值和预测值,前者为实际值,后者为预测值 print(m) 显示: [[940 101] [219 149]] 其中第一行为实际分类为0的数量,第二行为实际分类为1的数量;第一列为预测分类为0的数量,第二列为预测分类为1的数量。 # 增加表头 a = pd.DataFrame(m, index=['0(实际不流失)', '1(实际流失)'], columns=['0(预测不流失)', '1(预测流失)']) print(a) 显示: 0(预测不流失) 1(预测流失) 0(实际不流失) 940 101 1(实际流失) 219 149 由此可见
这里的TPR和FPR都是基于50%阈值情况下的 | ||||||||||||||||||
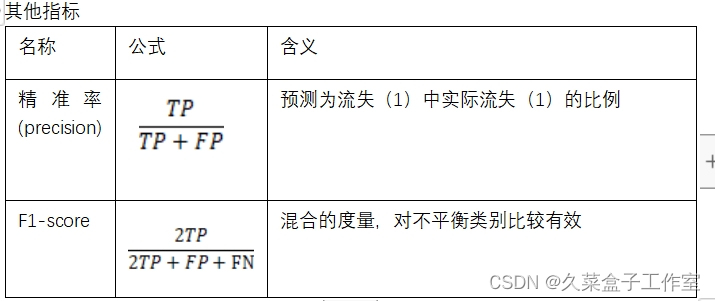
| 通过如下代码打印查看命中率情况,而无需手动计算 # 通过如下代码打印查看命中率情况 from sklearn.metrics import classification_report as cr print(cr(y_test, y_pred)) # 代入实际值和预测值,前者为实际值,后者为预测值 显示: precision recall f1-score support 0 0.81 0.90 0.85 1041 1 0.60 0.40 0.48 368 accuracy 0.77 1409 macro avg 0.70 0.65 0.67 1409 weighted avg 0.75 0.77 0.76 1409 recall表示召回率(相当于命中率) 0行的0.90,表示假警报预测准确度,可以理解为(1-假警报率),与手工计算的一致 1行的0.40,表示命中率,与手工计算的一致 support表示样本数 accuracy表示整体准确度,与以下代码计算的一致: from sklearn.metrics import accuracy_score as accs score = accs(y_pred, y_test) print('预测准确度:' + str(score))
这两个指标重要度不如命中率(TPR)和假警报率(FPR) | |||||||||||||||||||
3.实战评估股票客户流失预警模型 | 数值比较上可以使用AUC值来衡量模型的好坏,AUC值(Area Under Curver)指在曲线下面的面积,该面积的取值范围通常为0.5到1,0.5表示随机判断,1则代表完美的模型。 在商业实战中: AUC值能达到0.75以上就已经可以接受了 如果能达到0.85以上,则为非常不错的模型了 | ||||||||||||||||||
显示: 阈值 假警报率 命中率 0 1.932647 0.000000 0.000000 1 0.932647 0.000000 0.002717 2 0.917318 0.000000 0.010870 3 0.881889 0.000961 0.010870 4 0.858468 0.000961 0.021739 .. ... ... ... 443 0.033706 0.912584 0.994565 444 0.033667 0.912584 0.997283 445 0.033095 0.915466 0.997283 446 0.033000 0.915466 1.000000 447 0.022619 1.000000 1.000000 [448 rows x 3 columns] 注意:
显示前五个、后五个 随着阈值降低,命中率在上升、假警报率也在上升 | |||||||||||||||||||
| 注意点: 1、第一行的阈值表示只有当一个客户被预测流失的概率>=193%,才判定其会流失,但因为概率不会超过100%,所以此时不会有人被判定为流失,即所有人都不会被预测为流失,那么命中率和假警报率都为0,所以第一行的阈值其实没有什么意义。 那为什么还要设置它呢,这个是roc_curve函数的默认设置,下面是它的官方介绍:“thresholds[0] represents no instances being predicted and is arbitrarily set to max(y_score) + 1.” 其中文含义是第一个阈值没有含义,其往往设置为最大的阈值(本案例中为0.932647)+1,保证没有任何记录被选中。 2、表格第2行数据表示只有当一个客户被预测流失的概率大于等于93.26%,才判定其会流失。其他行类似。 | |||||||||||||||||||
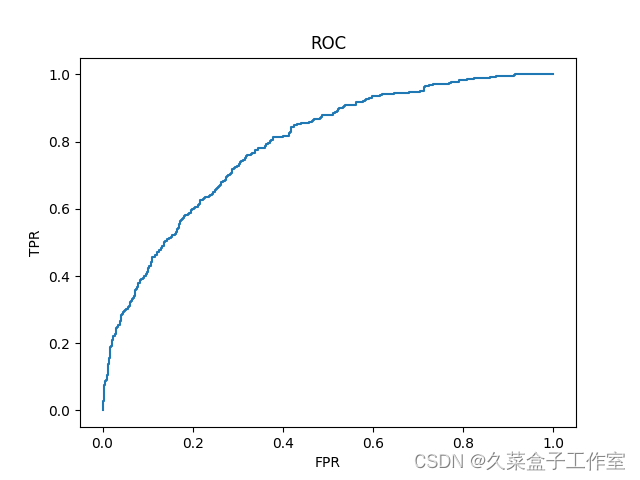
| # 用户绘图方式呈现不同阈值下的假警报率和命中率 import matplotlib.pyplot as plt plt.plot(fpr, tpr) # 用plot()函数绘制折线图 plt.title('ROC') # 添加标题 plt.xlabel('FPR') # 添加x轴标签 plt.ylabel('TPR') # 添加y轴标签 plt.show() 显示:
| |||||||||||||||||||
| # 快速求模型AUC值 from sklearn.metrics import roc_auc_score score = roc_auc_score(y_test,y_pred_proba[:, 1]) print(score) 显示: 0.789382596165894 AUC值打印出来为:0.789382596165894,可以说预测效果还是不错的 | |||||||||||||||||||
4.阈值的取值方法 | 本质就是分类为1 的概率 # 利用sort_values()函数,对'分类为1的概率'排序 # ascending参数为False表示降序 temp = pd.DataFrame(y_pred_proba, columns=['分类为0的概率', '分类为1的概率']) temp = temp.sort_values('分类为1的概率', ascending=False) print(temp) 显示: 分类为0的概率 分类为1的概率 651 0.067353 0.932647 768 0.075344 0.924656 1386 0.082178 0.917822 954 0.082682 0.917318 329 0.118111 0.881889 ... ... ... 204 0.976082 0.023918 665 0.976140 0.023860 1377 0.976499 0.023501 958 0.976726 0.023274 839 0.977381 0.022619 [1409 rows x 2 columns] 以651项,阈值为0.932647为例 表示概率大于等于0.932647,才归类为1 | ||||||||||||||||||
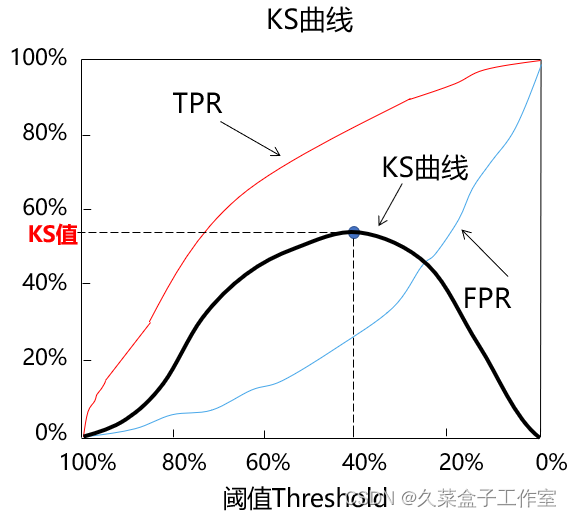
5.KS曲线与KS值 | KS曲线和ROC曲线的本质其实是相同的,同样关注命中率(TPR)和假警报率(FPR),希望命中率(TPR)尽可能的高,即能尽可能地揪出潜在流失客户,同时也希望假警报率(FPR)能尽可能的低,即不要把未流失客户误判断为流失客户。 | ||||||||||||||||||
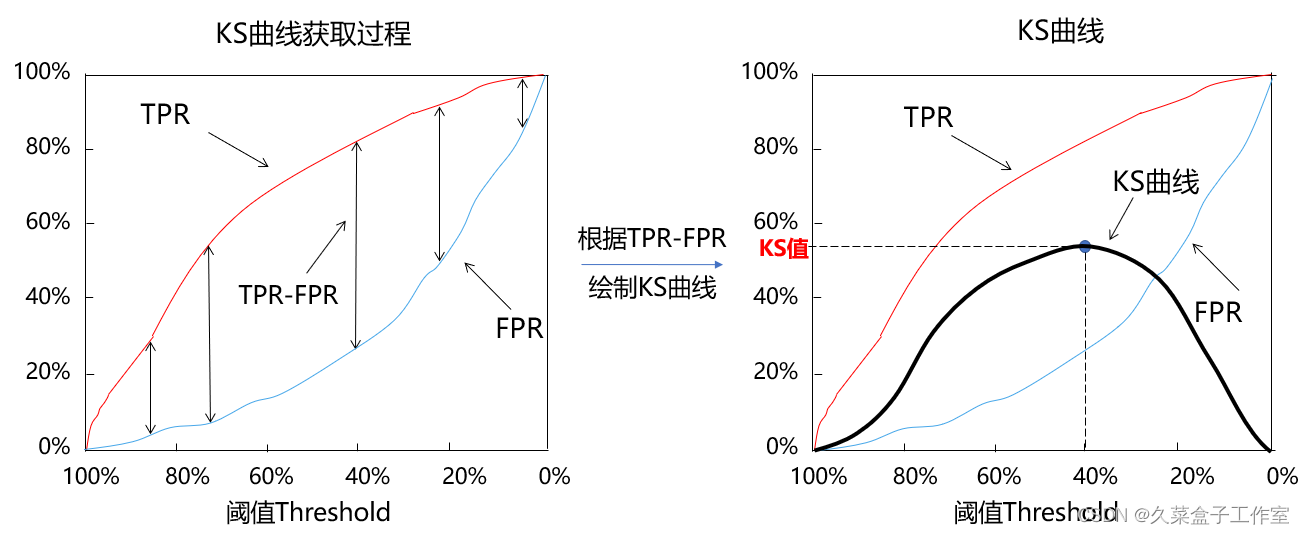
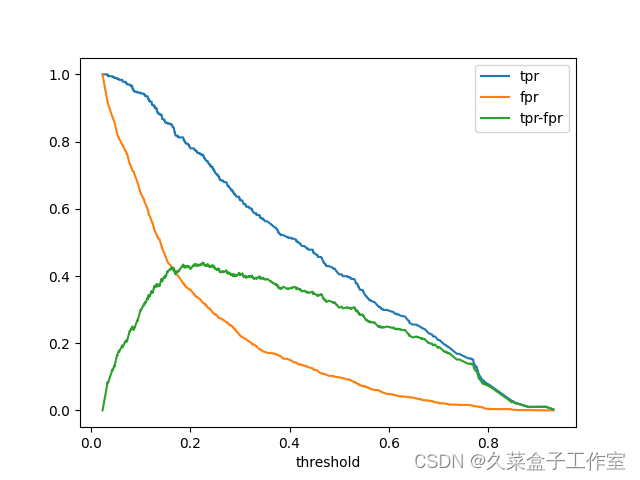
| 区别于ROC曲线将假警报率(FPR)作为横轴,命中率(TPR)作为纵轴,KS曲线的横坐标为阈值,其纵坐标为命中率(TPR)与假警报率(FPR)之差,如下图所示:
| |||||||||||||||||||
| 需要一个可以量化的指标来衡量模型预测效果,与ROC曲线对应的是AUC值,而与KS曲线相对应的就是KS值。KS值的定义如下所示:
例如上图中当阈值等于40%时,命中率(TPR)为80%,假警报率(FPR)为25%,所以(TPR-FPR)为55%,该值是所有不同阈值条件下(TPR-FPR)中最大的,因此此时这个模型的KS值就是55% | |||||||||||||||||||
| 通常来说,我们希望模型有较大的KS值,较大的KS值说明模型有较强的区分能力,其处在不同范围的模型的含义如下所示: KS值小于0.2,一般认为模型区分能力较弱。 KS值在[0.2,0.3]区间内,模型具有一定区分能力。 KS值在[0.3,0.5]区间内,模型具有较强的区分能力。 但KS值也不是越大越好,如果KS值大于0.75,往往表示模型有异常。其实在真正的生产实际中,KS值处于[0.2,0.3]区间类,就已经挺不错了。 | |||||||||||||||||||
| customer_warning_KS.py
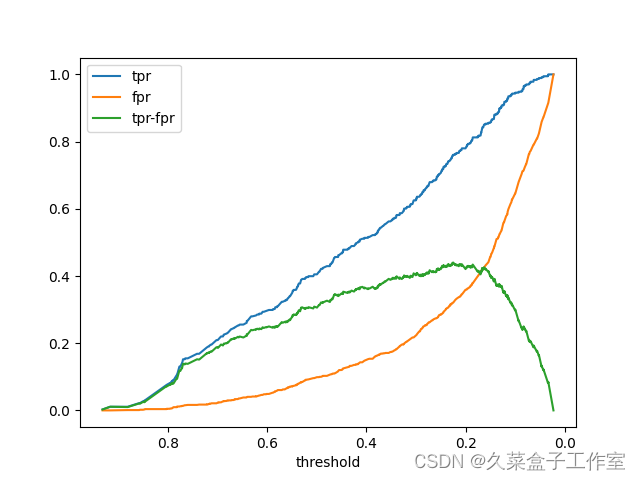
显示:
如果没有plt.gca().invert_xaxis(),显示:
阈值变成从小到大了 | |||||||||||||||||||
| # 求KS值
显示: 0.44002422419913967 阈值在[0.3, 0.5]区间,具有较强的区分能力 | |||||||||||||||||||
6.获取KS值对应的阈值 |
显示: 阈值 假警报率 命中率 TPR-FPR 0 1.932647 0.000000 0.000000 0.000000 1 0.932647 0.000000 0.002717 0.002717 2 0.917318 0.000000 0.010870 0.010870 3 0.881889 0.000961 0.010870 0.009909 4 0.858468 0.000961 0.021739 0.020779 .. ... ... ... ... 443 0.033706 0.912584 0.994565 0.081981 444 0.033667 0.912584 0.997283 0.084699 445 0.033095 0.915466 0.997283 0.081817 446 0.033000 0.915466 1.000000 0.084534 447 0.022619 1.000000 1.000000 0.000000 [448 rows x 4 columns] | ||||||||||||||||||
7.获取KS值 |
显示: 0.44002422419913967 和之前计算一致 | ||||||||||||||||||
显示: 阈值 假警报率 命中率 TPR-FPR 306 0.224835 0.320845 0.76087 0.440024 | |||||||||||||||||||
| 逻辑回归模型,在银行信贷场景中的信用评分卡模型中,经常使用 |
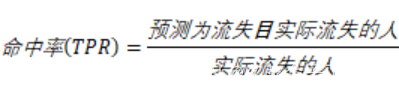
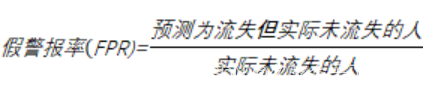
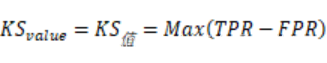
此系列为基础学习系列,请自行学习,课程资源免费获取地址:
https://download.csdn.net/download/weixin_68126662/88866689
久菜盒子工作室:大数据科学团队/全网可搜索的久菜盒子工作室 我们是:985硕博/美国全奖doctor/计算机7年产品负责人/医学大数据公司医学研究员/SCI一区2篇/Nature子刊一篇/中文二区核心一篇/都是我们 主要领域:医学大数据分析/经管数据分析/金融模型/统计数理基础/统计学/卫生经济学/流行与统计学/ 擅长软件:R/python/stata/spss/matlab/mySQL
团队理念:从零开始,让每一个人都得到优质的科研教育
点点关注,一起成长,会变更强哦