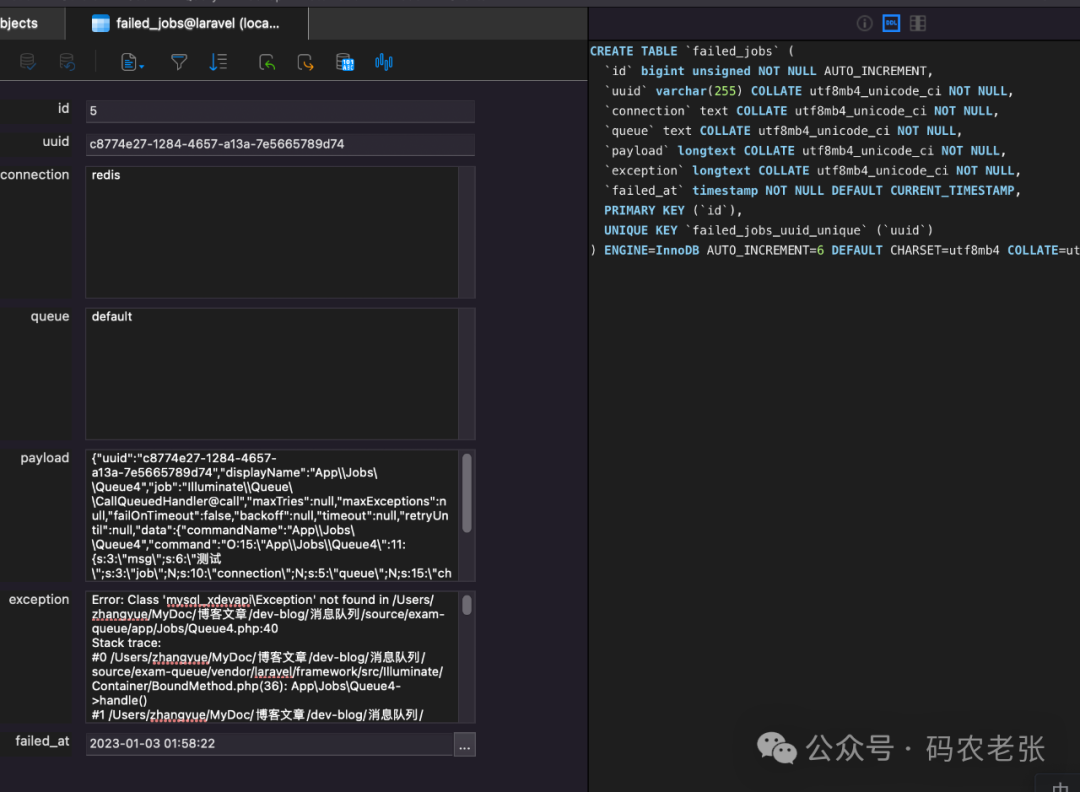
EMQX Enterprise 5.5.0 版本已正式发布!
在这个版本中,我们引入了一系列新的功能和改进,包括对 Elasticsearch 的集成、Apache IoTDB 和 OpenTSDB 数据集成优化、授权缓存支持排除主题等功能。此外,新版本还进行了多项改进以及 BUG 修复,进一步提升了整体性能和稳定性。
新增 Elasticsearch 数据集成
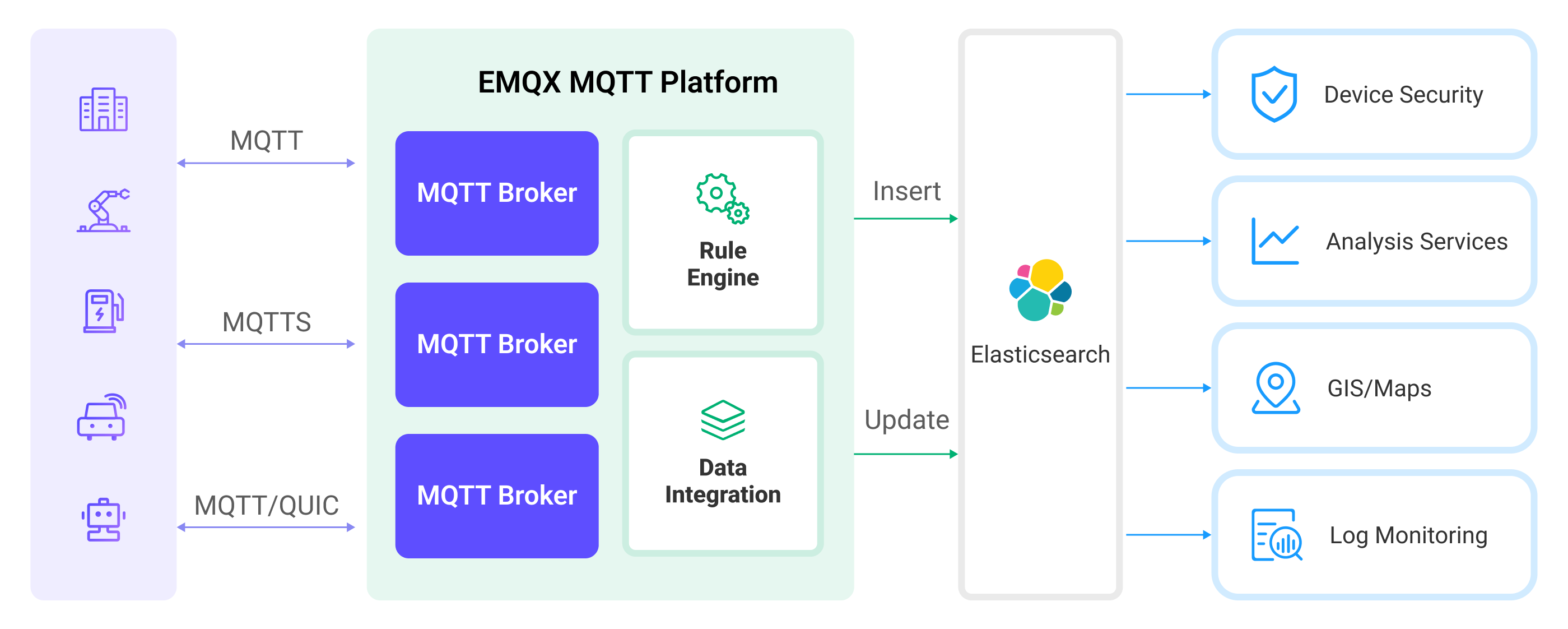
Elasticsearch 是一个分布式的搜索和数据分析引擎,能够提供多样化数据的全文搜索、结构化搜索以及分析等功能。在这个版本中,EMQX 新增了对 Elasticsearch 的数据集成,支持数据的插入、更新和删除操作,这意味着设备数据可以被写入到 Elasticsearch,用户可以灵活地使用 Elasticsearch 的搜索和分析能力对数据进行处理。
设备数据写入到 Elasticsearch 后,用户可以灵活的使用 Elasticsearch 的搜索和分析能力对数据进行处理。典型的使用场景包括物联网设备的事件和日志监测、地理位置数据(Maps)的处理以及终端安全监测。例如,物联网设备会生成大量的日志数据,这些数据可以被发送到 Elasticsearch 中进行存储和分析。通过连接到可视化工具,例如 Kibana,可以根据这些日志数据生成图表,实时展示设备状态、操作记录以及错误消息等信息。
Apache IoTDB 与 OpenTSDB 数据集成优化
Apache IoTDB 与 OpenTSDB 数据集成在这个版本中得到了优化,现在支持配置数据写入模板,通过指定每个字段的时间戳、字段名称、数据类型,实现灵活的数据写入,使得数据集成开发更加快速和灵活。
InfluxDB, IoTDB 与 TDengine 数据集成支持批量设置写入字段
在工业、车联网等应用中,时序类数据集成开发中,存在一条消息包含数百乃至更多数据点位的场景。要配置将它们从消息中提取,并一一对应存储到数据库中是一个重复且复杂的工作。
为了解决这个问题,EMQX 提供了批量设置功能,用户可以通过 CSV 文件编辑要写入的字段名称以及从 Payload 中的取值方式,将其通过 Dashboard 进行导入,实现对应数据集成的快速配置。目前支持的数据集成有 InfluxDB、Apache IoTDB, 以及 TDengine。
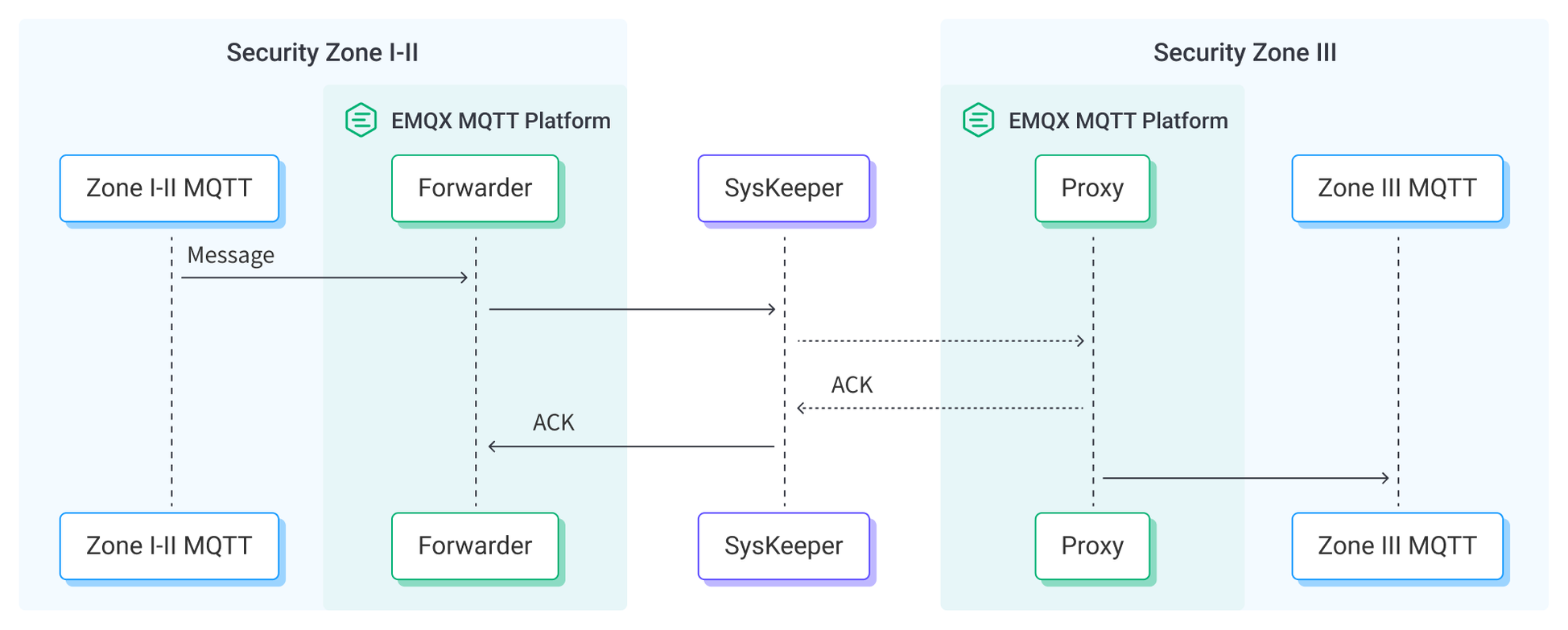
消息桥接 SysKeeper 穿透支持
在电力生产系统的网络安全要求下,生产控制区、生产非控制区和生产管理区之间的网络通讯需要通过单向网闸设备保障网络安全。
EMQX 在数据集成中新增了正向网闸 SysKeeper 2000 穿透功能,通过配置可以启用此功能,进行 EMQX 消息在不同生产区之间的桥接传输。这一功能确保符合规章制度的情况下,实现了两个生产区之间数据通信,为电力行业物联网应用落地提供了定制化的支持,助力电力系统的安全、高效运营。
授权缓存支持排除主题
EMQX 提供了开箱即用的客户端授权功能,为应用安全提供了强有力的保障。其中还支持授权缓存,能够大大减少后端压力,实现系统高性能稳定运行。
在启用缓存的基础上,对于一些安全敏感的业务,用户希望将其排除不生成缓存,以实现实时的权限更新保障通信安全。在这个版本中,EMQX 支持为授权缓存添加多个排除主题,客户可以灵活的定制不同安全级别要求,实现整个系统高效稳定运行。
可观测性提升
EMQX 为用户提供了丰富的指标和指标监控服务集成。此前用于指标集成的 Prometheus 只能获取集群运行和客户端、MQTT 相关的基础指标,对于认证授权、规则引擎和数据集成的运行指标没法实现监控管理。
在这个版本中,我们进一步增强了可观测性,暴露了更多的指标,包括:
- 认证与授权:每个认证与授权器的状态和允许/拒绝情况
- 规则:能够获取每个规则的执行情况,例如触发、通过与未通过、失败次数,以及执行的速度
- 数据集成:每个外部集成的连接状态,Sink 与 Source 的执行情况
- SSL/TLS 证书有效期,用以实现证书的轮换监控
- License 过期时间
通过这些更详细的指标,用户能够实现业务层面的监控,能够详细了解当前主要组件运行状态,更便捷地监测和排除系统问题。
性能提升
- 提高了 Kafka 生产者数据集成的性能,改善了 Kafka 服务侧的资源占用。这对于大量使用 Kafka 作为数据流通道的应用来说有非常大的帮助,因为它可以提高系统的整体性能和效率。
- 集群节点通信支持批量更新多个订阅操作,进一步提高了 Core - Replicant 架构在跨地域集群、高网络延迟场景下的订阅速度。实测在 220ms 的网络延迟中,能够提升 20% 的订阅速度。该设计还减轻了集群连接代理池的负载,从而最大限度地减少系统过载的风险。
- 提高了路由清理时的网络通信效率,在新的实现中,当一个节点宕机时,其余的存活节点只需要交换一个“匹配并删除”操作,这大大减少了所需的网络数据包数量,从而降低了集群间的网络负载。对于在网络延迟较高的跨地域环境中部署的 EMQX 集群,这种优化将会非常有益。
- GreptimeDB 数据集成支持异步写入操作,以提供更好的性能。
- 支持并发创建和更新数据集成,提高了例如导入备份文件时的操作速度。
其他功能更新
- JWT 认证中,Token 携带的 ACL 权限列表采用新的数据格式,使用上更加灵活。
- 保留消息支持搜索以及一键清除,此前已经支持了保留消息的列表查看和管理,现在我们对管理的用户体验进行了增强,支持在 Dashboard 上通过主题或者主题搜索管理保留消息列表,并实现保留消息的一键清除。
- 延迟消息支持指定主题进行批量删除,此项更新提高了操作效率并减少管理的复杂性。
- 调整 REST API 分页大小上限,将分页 REST API 的请求分页大小限制由 3000 调整为 10000,以支持更大数据量的 API 调用。
- 数据集成 MQTT 桥接重构,现在一组 MQTT 连接能够用于在多个消息订阅、消息发布配置中。这一改进将使得数据集成配置和管理更加灵活和高效。
BUG 修复
以下是主要 BUG 修复列表:
- #12243 修复了一系列可能导致全局路由状态不一致的细微竞争条件,确保全局路由状态的正确性和一致性,提高系统的稳定性。
- #12269 改进了
/clients接口的错误处理方式。现在,如果查询字符串验证失败,EMQX 将返回 400 状态和更详细的错误信息,而不是通用的 500。这样可以让用户更清楚地知道出错的原因,提高了错误处理的透明度。 - #12303 修复了保留消息索引的问题。此前如果客户端有通配符订阅,可能会收到与其订阅主题不匹配的无关保留消息。
- #12404 修复了消息流量较大的情况下,重启数据集成可能导致指标停止收集的问题。现在可以确保在任何情况下都能正确收集数据集成指标,提高了系统的可靠性。
- #12301 修复了 InfluxDB 中的行协议数值字面量被存储为字符串类型的问题。现在数值字面量将被正确地存储为数值类型,提高了数据的准确性。
更多功能变更和 BUG 修复请查看 EMQX Enterprise 5.5.0 更新日志。