where子句中经常使用的运算符


-- 查询总分大于200分的所有同学
select * from student2 where (chinese+english+math)>200;
-- 查询math大于60 并且(and)id大于4的学生成绩
select * from student2 where math>60 and id>4;
-- 查询英语成绩大于语文成绩的同学
select * from student2 where english > chinese;
--查询总分大于200分 并且 数学成绩小于语文成绩,的姓赵的学生.
-- 赵% 表示 名字以韩开头的就可以
select * from student2 where (chinese+english+math)>200 and math<chinese and name like '赵%';
查询英语分数在 80-90之间的同学。
-- between .. and .. 是 闭区间
select * from student2 where english between 80 and 90 ;
-- 查询数学分数为89,90,91的同学。
select * from student2 where math in (89,90,91);
order by 子句排序查询结果

对数学成绩排序后输出(升序)
select * from student2 order by math;
对总分按从高到低的顺序输出 [降序]-- 使用别名排序
select `name`,(math+chinese+english) as total from student2 order by total DESC;
合计 (count)
-- 统计数学成绩大于90的学生有多少个?
SELECT COUNT(*) FROM student2 WHERE math>90
-- 统计总分大于250的人数有多少?
SELECT COUNT(*) FROM student2 WHERE (math + english + chinese) > 250
-- count(*) 和 count(列) 的区别
-- 解释 :count(*) 返回满足条件的记录的行数
-- count(列): 统计满足条件的某列有多少个,但是会排除 为null的情况
统计函数(sum)
-- 统计一个班级数学总成绩?
SELECT SUM(math) FROM student2;
-- 统计一个班级语文、英语、数学各科的总成绩
SELECT SUM(math) AS math_total_score,SUM(english),SUM(chinese) FROM student2;
--统计一个班级语文、英语、数学的成绩总和
SELECT SUM(math+english+chinese) FROMs tudent2;
--统计一个班级语文成绩平均分
SELECT SUM(chinese)/COUNT(*) FROM student2;
求平均值函数(avg)
--求一个班级数学平均分?
SELECT AVG(math) FROM student2;
--求一个班级总分平均分
SELECT AVG(math+english+chinese) FROM student2;
最大值(max)和最小值(min)
--求班级最高分和最低分(数值范围在统计中特别有用)
SELECT MAX(math+english+chinese),MIN(math+english+chinese) FROM student2;
--求出班级数学最高分和最低分
SELECT MAX(math) AS math_high_socre,MIN(math) AS math_low_socre FROM student2;
groupby子句对列进行分组

创建部门表
/*部门表*/
CREATE TABLE dept(
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT "");
导入数据
INSERT INTO dept VALUES ( 10, 'ACCOUNTING', 'NEWYORK' ),( 20, 'RESEARCH', 'DALLAS' ),( 30, 'SALES', 'CHICAGO' ),
( 40, 'OPERATIONS', 'BOSTON' );
创建员工表
CREATE TABLE emp (
/*编号*/
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
/*名字*/
ename VARCHAR ( 20 ) NOT NULL DEFAULT "",
/*工作*/
job VARCHAR ( 9 ) NOT NULL DEFAULT "",
/*上级编号*/
mgr MEDIUMINT UNSIGNED,
/*入职时间*/
hiredate DATE NOT NULL,
/*薪水*/
sal DECIMAL ( 7, 2 ) NOT NULL,
/*红利 奖金*/
comm DECIMAL ( 7, 2 ),/*部门编号*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0
);
导入数据
INSERT INTO emp
VALUES
( 7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00, NULL, 20 ),
( 7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30 ),
( 7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30 ),
( 7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00, NULL, 20 ),
( 7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28', 1250.00, 1400.00, 30 ),
( 7698, 'BLAKE', 'MANAGER', 7839, '1991-5-1', 2850.00, NULL, 30 ),
( 7782, 'CLARK', 'MANAGER', 7839, '1991-6-9', 2450.00, NULL, 10 ),
( 7788, 'SCOTT', 'ANALYST', 7566, '1997-4-19', 3000.00, NULL, 20 ),
( 7839, 'KING', 'PRESIDENT', NULL, '1991-11-17', 5000.00, NULL, 10 ),
( 7844, 'TURNER', 'SALESMAN', 7698, '1991-9-8', 1500.00, NULL, 30 ),
( 7900, 'JAMES', 'CLERK', 7698, '1991-12-3', 950.00, NULL, 30 ),
( 7902, 'FORD', 'ANALYST', 7566, '1991-12-3', 3000.00, NULL, 20 ),
( 7934, 'MILLER', 'CLERK', 7782, '1992-1-23', 1300.00, NULL, 10 );
#工资级别表
CREATE TABLE salgrade (
/*工资级别*/
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
/* 该级别的最低工资 */
losal DECIMAL ( 17, 2 ) NOT NULL,
/* 该级别的最高工资*/
hisal DECIMAL ( 17, 2 ) NOT NULL
)
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
如何显示每个部门的平均工资和最高工
-- having 子句用于限制分组显示结果.
-- 分析:avg(sal) max(sal)
-- 按照部分来分组查询
SELECT AVG(sal), MAX(sal) , deptno FROM emp GROU PBY deptno;
-- 使用数学方法,对小数点进行处理
SELECT FORMAT(AVG(sal),2), MAX(sal) , deptno FROM emp GROUP BY deptno;
显示每个部门的每种岗位的平均工资和最低工资
SELECT AVG(sal), deptno FROM emp GROUP BY deptno HAVINGAVG(sal) < 2000;
字符串相关函数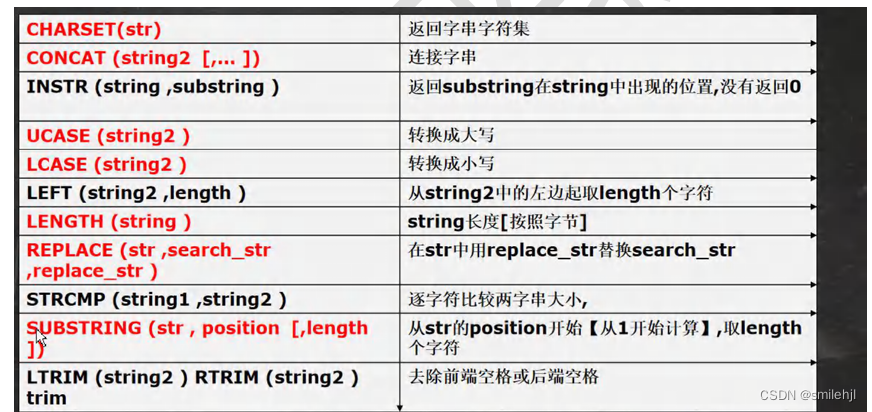
-- CHARSET(str) 返回字串字符集
SELECT CHARSET(ename) FROM emp;
-- CONCAT(string2 [,... ]) 连接字串, 将多个列拼接成一列
SELECT CONCAT(ename, ' 工作是 ', job) FROM emp;
......

数学相关函数
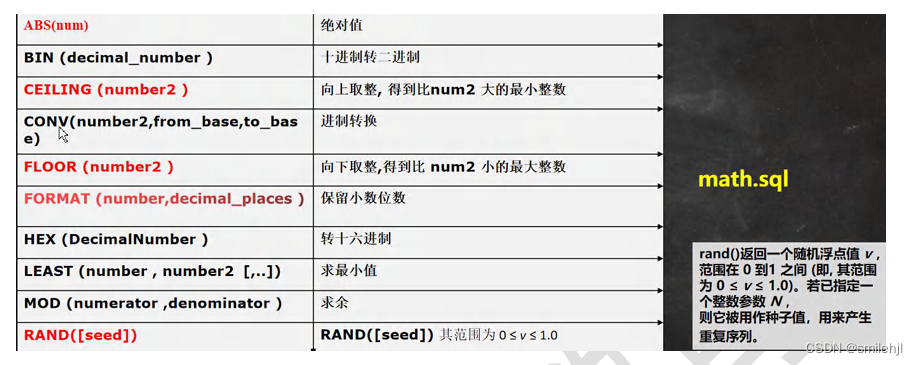
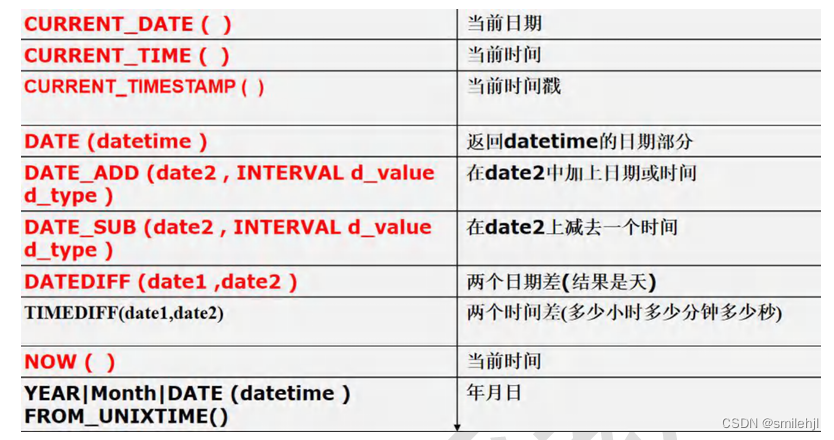
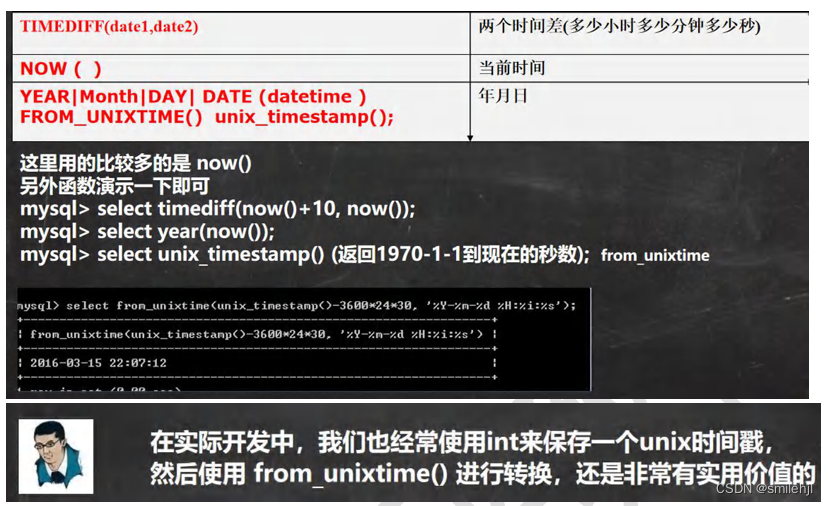
时间日期相关函数


加密和系统函数


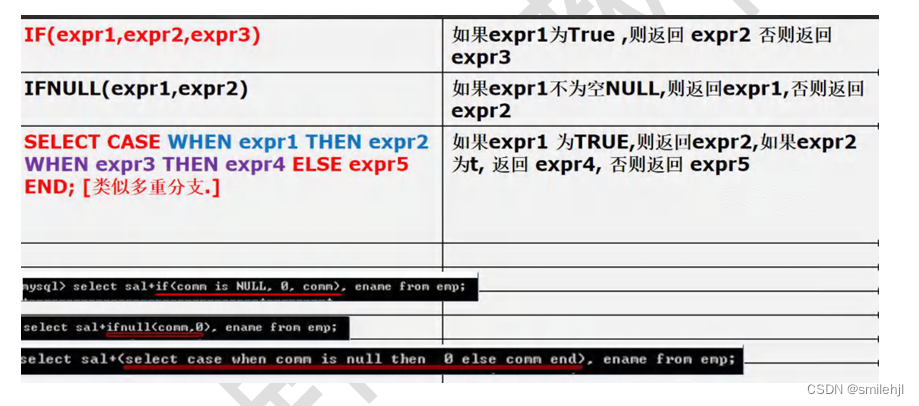
流程控制函数
自连接

合并查询

mysql 表外连接