前言
马上就要过年了,大家都在屯年货了网络上商品信息太多,不知道如何选择,今天,我们就用python爬取商品信息,并做可视化。
环境使用
- python 3.9
- pycharm
模块使用
- requests
- selenium
- time
- 谷歌驱动
说明
一、谷歌驱动安装
1.下载网址
CNPM Binaries Mirror
2.文件安装(放置)位置
可以把这个文件理解成一个脚本入口。说它是安装,其实就是把下载的
chromedriver.exe文件复制到相应的位置。将文件复制到两个位置:1.
..\python\Scripts复制一份到安装Python的文件夹中的Scripts文件夹中;2.如果用的是Pycharm,再复制一份到..\python\site-packages\selenium\webdriver\chrome文件中。这个地址可以将鼠标放在Pycharm里面安装库的地方的相应库上就能看到。
二、selenium模块
之前,我们爬虫是模拟浏览器,但始终不是用的浏览器,但今天我们要说的是另一种爬虫方式,这次不是模拟浏览器,而是用程序去控制浏览器进行一些列操作,也就是selenium。selenium是python的一个第三方库,对外提供的接口可以操控浏览器,比如说输入、点击,跳转,下拉等动作。
在使用selenium模块之前要做两件事,一是安装selenium模块,可以用终端用pip,也可以在pycharm里的setting安装;二是我们需要下载一款浏览器驱动程序,下载的驱动程序要和浏览器的版本一致。
代码实现
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
# r'C:\Users\YY\AppData\Local\Programs\Python\Python39\chromedriver.exe'
driver.get('https://www.jd.com/')
def GetInfo():
input_tag = driver.find_element(By.ID, "key")
input_tag.send_keys('笔记本')
time.sleep(5)
input_tag.send_keys(Keys.ENTER)
spider_jd()
def spider_jd():
goods = driver.find_elements(By.CLASS_NAME,"gl-item")
for good in goods:
name = good.find_element(By.CSS_SELECTOR,".p-name").text.replace('\n','')
price = good.find_element(By.CSS_SELECTOR,".p-price").text
link = good.find_element(By.TAG_NAME,"a").get_attribute('href')
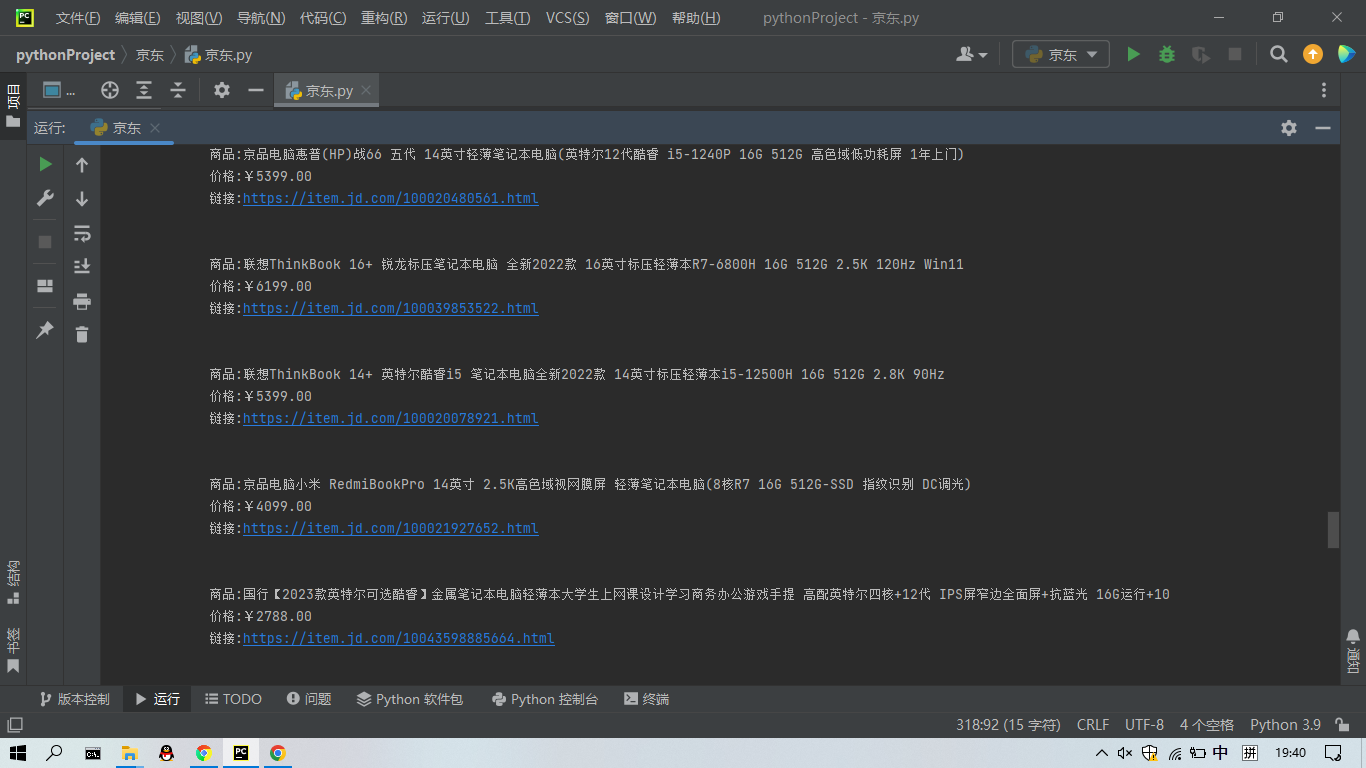
msg = '''
商品:%s
价格:%s
链接:%s
'''%(name,price,link)
print(msg)
# GetInfo()
for page in range(1,11):
print(f'爬取{page}页')
GetInfo()
driver.find_element(By.CSS_SELECTOR,'.pn-next').click()
time.sleep(2)
运行结果