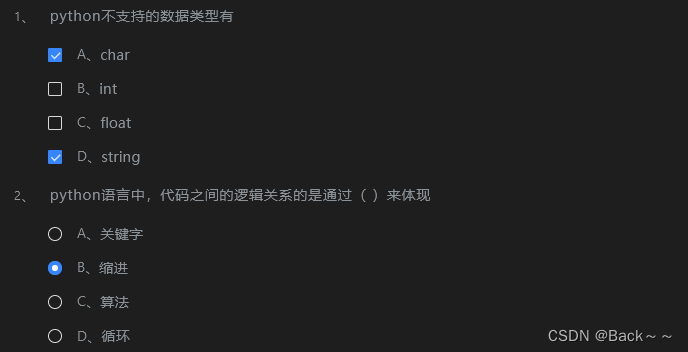
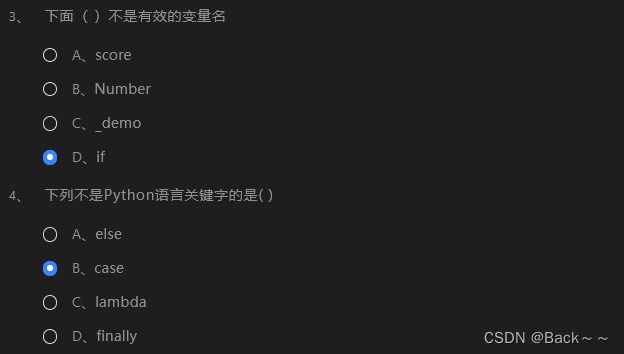

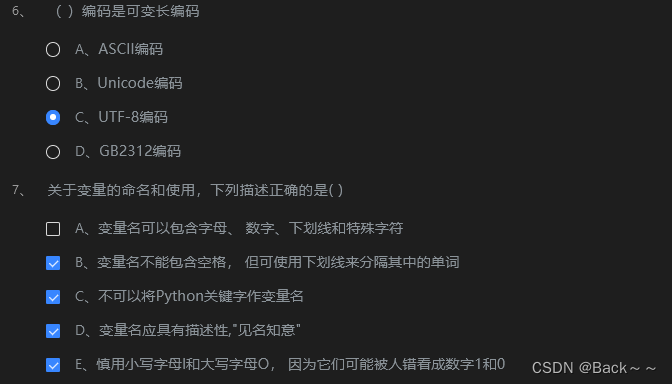

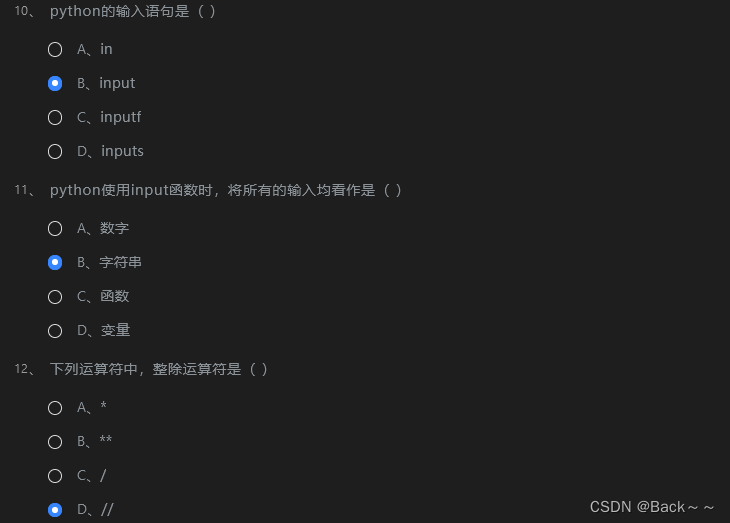
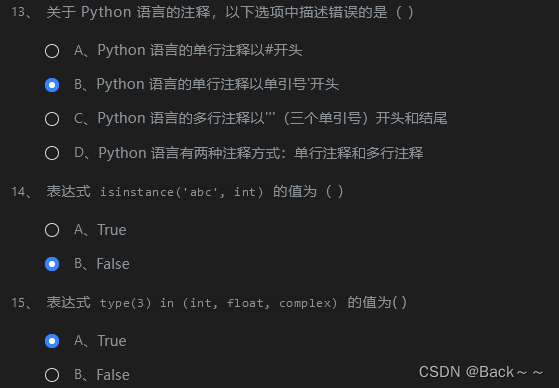
可变长编码和不可变长编码
可变长编码是指不同字符使用不同数量的字节进行编码。例如,UTF-8 编码中,ASCII 字符使用 1 个字节编码,而其他语言的字符使用 2 个或更多字节编码。
不可变长编码是指所有字符都使用相同数量的字节进行编码。例如,UCS-2 编码中,所有字符都使用 2 个字节编码。
可变长编码的优点
- 节省空间:对于使用大量 ASCII 字符的文本,可变长编码比不可变长编码节省空间
- 易于扩展:可变长编码可以轻松扩展以支持新的字符
可变长编码的缺点
- 处理复杂:由于字符长度不固定,处理可变长编码的文本比处理不可变长编码的文本更复杂
- 兼容性问题:并非所有系统都支持可变长编码
不可变长编码的优点
- 处理简单:由于字符长度固定,处理不可变长编码的文本比处理可变长编码的文本更简单
- 兼容性好:大多数系统都支持不可变长编码
不可变长编码的缺点
- 浪费空间:对于使用大量非 ASCII 字符的文本,不可变长编码会浪费空间
- 难以扩展:不可变长编码难以扩展以支持新的字符
总结
可变长编码和不可变长编码各有优缺点。选择哪种编码取决于具体应用场景。
以下是一些选择可变长编码的场景
- 需要节省空间
- 需要支持多种语言
以下是一些选择不可变长编码的场景
- 需要简单易用的编码
- 需要与其他系统兼容
一些常见的可变长编码
- UTF-8
- UTF-16
- UTF-32
一些常见的不可变长编码
-
ASCII
-
UCS-2
-
UCS-4
UTF-8 编码是可变长编码,因为不同字符使用不同数量的字节进行编码。 -
ASCII 字符使用 1 个字节编码
-
西欧语言的大多数字符使用 2 个字节编码
-
其他语言的字符使用 3 个或更多字节编码
可变长编码有以下优点:
- 节省空间:对于使用大量 ASCII 字符的文本,UTF-8 编码比固定长编码(如 UCS-2)节省空间
- 易于扩展:UTF-8 可以轻松扩展以支持新的字符
缺点:
- 处理复杂:由于字符长度不固定,处理 UTF-8 编码的文本比处理固定长编码的文本更复杂
- 兼容性问题:并非所有系统都支持 UTF-8 编码
UTF-8 编码规则
- 1 个字节:0xxxxxxx
- 2 个字节:110xxxxx 10xxxxxx
- 3 个字节:1110xxxx 10xxxxxx 10xxxxxx
- 4 个字节:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
示例
- 字符 “A” 的 Unicode 码点是 U+0041,使用 1 个字节编码为 01000001
- 字符 “中” 的 Unicode 码点是 U+4E2D,使用 3 个字节编码为 11100100 10100101 10010100
总结
UTF-8 编码是一种可变长编码,具有节省空间和易于扩展的优点,但也存在处理复杂和兼容性问题等缺点。
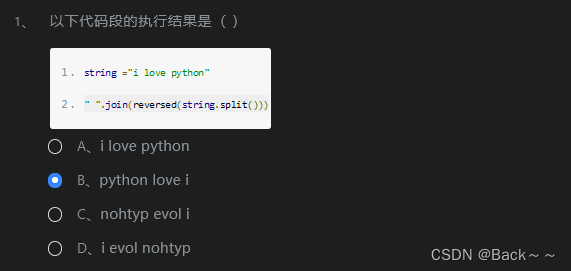 运行结果是 “python love i”。
运行结果是 “python love i”。
解释
string.split()将字符串string以空格 ( ) 为分隔符分割成一个列表reversed(string.split())将列表string.split()反转" ".join(reversed(string.split()))将列表reversed(string.split())中的元素以空格 ( ) 为连接符连接成一个字符串
示例
string = "i love python"
# 将字符串分割成列表
split_list = string.split()
# 反转列表
reversed_list = reversed(split_list)
# 将列表连接成字符串
joined_string = " ".join(reversed_list)
print(joined_string)
输出
python love i
注意
split()方法默认以空格 ( ) 为分隔符join()方法默认以空格 ( ) 为连接符- 可以指定分隔符和连接符

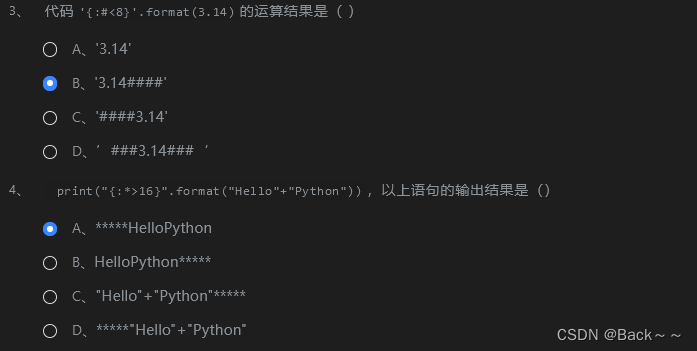
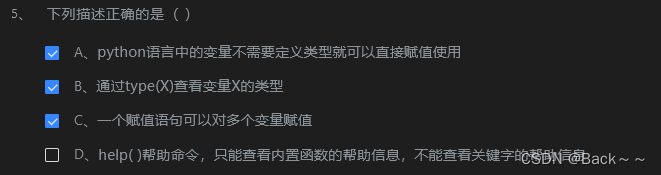

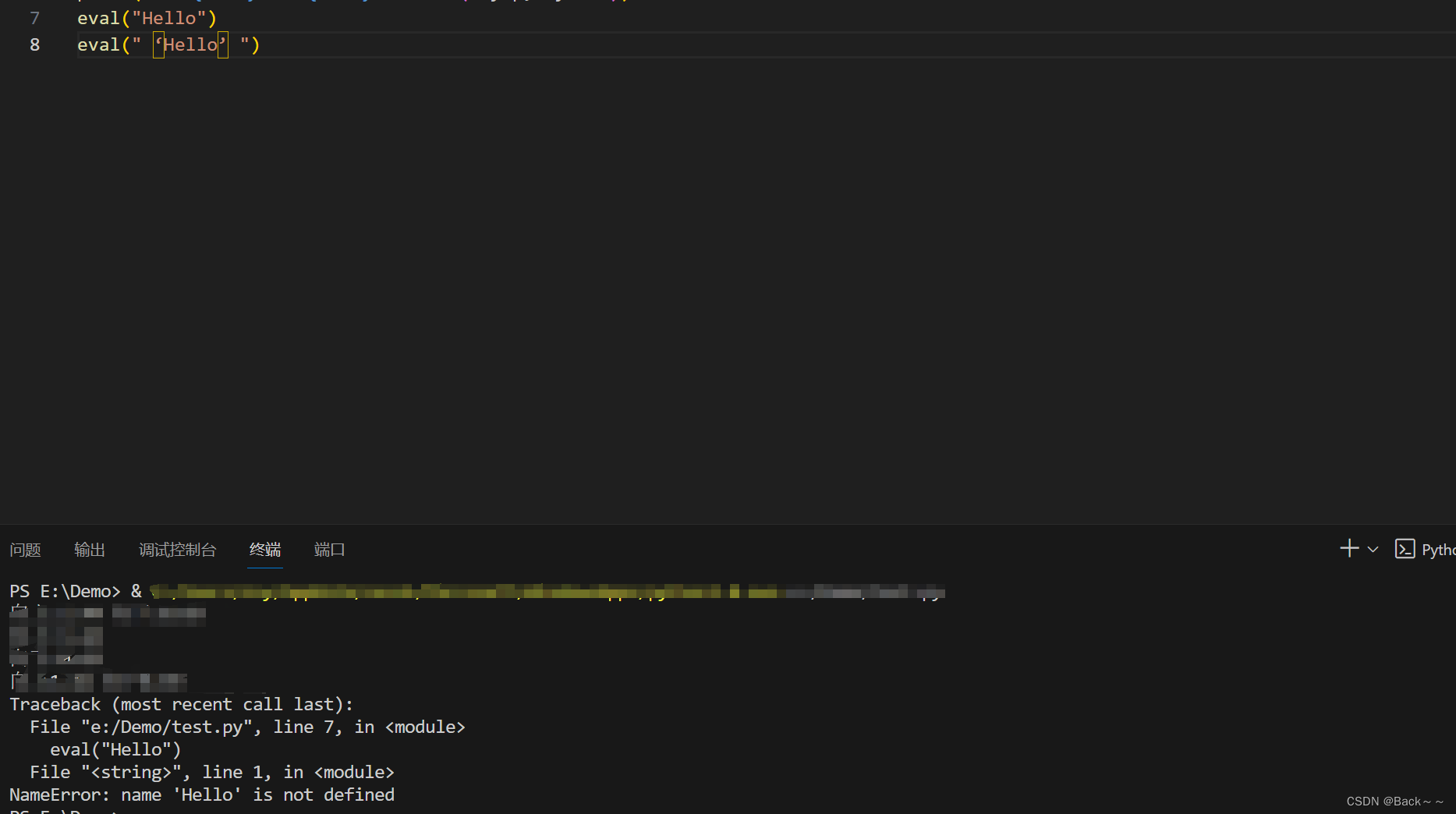
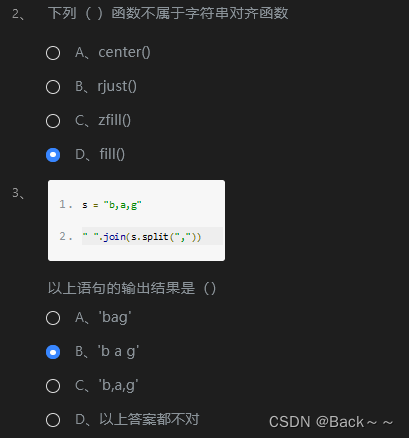 运行结果是 “b a g”。
运行结果是 “b a g”。
解释
s.split(",")将字符串s以逗号 (,) 为分隔符分割成一个列表" ".join(s.split(","))将列表s.split(",")中的元素以空格 ( ) 为连接符连接成一个字符串
示例
s = "b,a,g"
# 将字符串分割成列表
split_list = s.split(",")
# 将列表连接成字符串
joined_string = " ".join(split_list)
print(joined_string)
输出
b a g
注意
split()方法默认以空格 ( ) 为分隔符join()方法默认以空格 ( ) 为连接符- 可以指定分隔符和连接符




![壹[1],图像源](https://img-blog.csdnimg.cn/direct/d9f93428410447efac13bb4176026087.png)