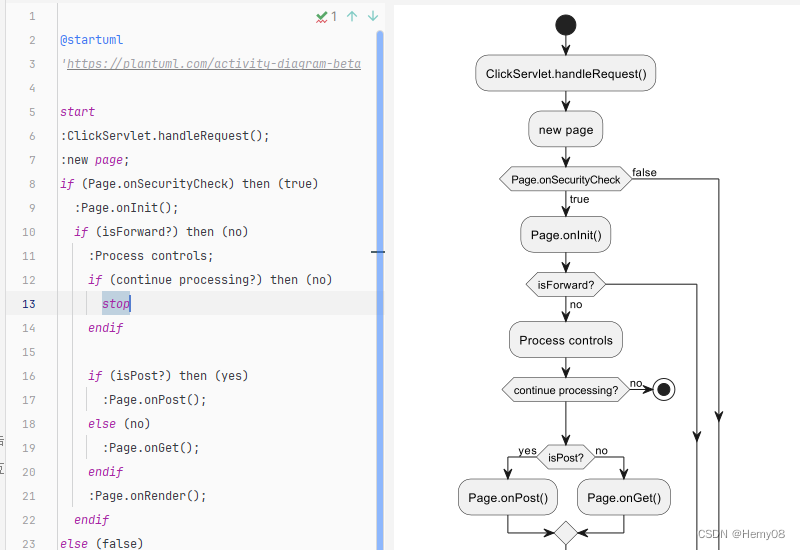
0 引言
国内外有关 VRPSPD的文献较多,求解目标多以最小化车辆行驶距离为主,但现实中可能存在由租赁费用产生的单次派出成本,需要综合考
虑单次派车成本和配送路径成本。虽然少数文献增加了车辆数目方面的分析,但缺乏对总配送成本、车辆数目、车辆行驶距离等多种目标的系统性分析。
历史成绩
- TASAN 等[4]以 最 小 化 车 辆 行 驶 距 离为 目 标,提出一种基于遗传算法的方法来求解VRPSPD,并利用 Augerat标 准 数 据 集 部 分 算 例进行 验 证,结 果 证 明 该 方 法 较 数 学 规 划 工 具
Cplex具有更好的稳定性。 - NAGY 等[5]提出采用插入式启发式方法求解单个/多个车场的带回程车辆路径问题,并设计了包含 VRPSPD问题在内的5类标准数据集。
- 柳毅等[6]提出采用改进人工鱼群算法求解相同目标问题,并利用 NAGY 标准数据集中的10组算例进行仿真分析,结果证明该算法虽然计算时间较长,但寻优性能较文献[5]的插入式启发式算法更加优越。
- 彭春林等[7]在求解VRPSPD问题时增加了派出车辆数目标,但对算法的性能分析只针对 NAGY 标准数据集中的两组算例,算法验证缺乏普适性。
- 龙 磊 等[8]针 对 相同目标问题提出采用一种粗粒度并行遗传算法进
行求解,并以 NAGY 标准数据集中的14组算例进行验证,证明该算法在大部分实例上超过了已知最优解。 - TANG 等[9]以最小化车辆数目、最小化车辆行驶距离为目标,提出采用一种基于局域迭代搜索的禁忌搜索算法进行求解,并以多个标
准测试集进行了算法准确性和 有效性的验证。 - WASSAN 等[10]提出一种能自动调节禁忌长度的自适应禁忌搜索算法,结果表明该算法性能在绝大部 分 算 例 上 优 于 文 献 [9]的 禁 忌 搜 索 算 法。
- WANG 等[11]以最 小 化 总 配 送 成 本、最 小 化 车 辆数目、最小化车辆行驶距离为目标,并考虑时间窗约束,提出采用联合进化遗传算法进行求解,结果表明该方法较基 本遗传算法和数学规划工具Cplex具有更好的寻优性能。
上述研究表明,VRPSPD 问题的优化目标多以配送距离为主,部分文献考虑了配送车辆数目,几乎没有文献将配送距离、车辆数目及配送成本进行系统性分析;求解算法大多集中在以经典 C-W 节约法为基础的启发式方法和以群体智能为基础 的 元 启 发 方 法。 遗 传 算 法 (geneticalgo-rithm,GA)作为一种 鲁 棒 性 较 强 的 元 启 发 方 法,在许多车辆路径与调度问题的求解应用中已被证明具有良好的优化性能[4,7-8,11]。
GA 在搜索处理后期容易出现两难窘境:要么收敛速度较慢耗时长,要么早熟收敛陷入局部最优,因此,必须在进化过程中改善种群的多样性和优良基因的遗传性,以提高 算 法 整 体 搜 索 性 能[7,11]。受 到 该 思 想的启发,本文将包含多样性种群和高质量种群的双种群并行策略引入基本遗传算法,提出一种自适 应 并 行 遗 传 算 法 求 解 包 含 多 种 目 标 的 VRP-SPD问题,并通过算例仿真和结果对比验证所提算法的可行性和有效性。
1. 问题描述
VRPSPD问题可以描述如下:物流中心拥有一定数量的相同车辆,车辆从配送中心出发,在一定时间内完成确定数量客户集的送货与取货后返回物流中心。每个客户的送货与取货由同一车辆同时完成。要求合理安排车辆配送路线,在派出车辆数目最小、车辆行驶距离最短的情况下,实现总配送成本最小。
采用符号体系描述如下:假设
物流中心共有 N 个客户,采用
i
,
j
i,j
i,j 表示客户编号
(
i,j=1,2,
…
,N
)
(i,j=1,2,…,N)
(i,j=1,2,…,N),0表示物流中心;
Z
Z
Z 为总配送成本;
客户的送货量和取货量分别为
d
i
,
p
i
d_i,p_i
di,pi;
客户之间的距 离 为
c
i
j
c_{ij}
cij,物 流 中 心 到 客 户
i
i
i 的 距 离 为
c
o
i
c_{oi}
coi;
车辆单位距离行驶成本为
g
g
g,单车指派成本为
f
f
f,最大装载量为
Q
Q
Q;
车辆总数为
K
K
K,车辆
k
(
k=1,2,
…
,K
)
k(k=1,2,…,K)
k(k=1,2,…,K)离开客户
i
i
i时车上载重量为
U
i
k
U_{ik}
Uik,车辆的最大行驶距离为
L
L
L。

2 自适应并行遗传算法
2.1 双种群并行策略
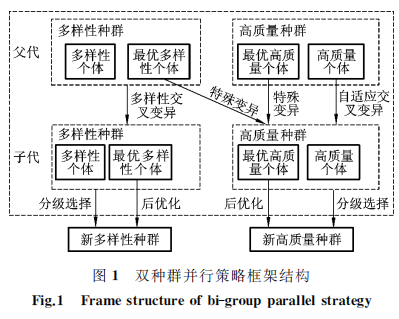
为解决 GA 在搜索过程中出现的两难窘境,本文提出一种包含多样性种群和高质量种群的双种群并行策略,其中多样性种群以改善种群多样性为主要目的,高质量种群以强化寻优能力为主要目的。双种群并行策略框架结构见图1。该策略通过对双种群同时执行不同的遗传操作(针对多样性种群执行多样性交叉变异操作、针对高质量种群执行自适应交叉变异操作),并针对双种群中最优个体执行特殊变异和后优化的局域搜索,使得算法在扩大搜索空间的同时能够进行深度搜索并保持优良基因的遗传性状,从而有效避免陷入局部最优。扩大搜索空间--避免陷入局部最优; 深度搜索优良基因---缓解耗时慢的特性
2.2 编码及解码
染色体结构为 N 个1~N 之间互不重复的自然数排列(N 为客户总数)以客户数而不包含车辆数进行编码,该排列是一条以自然数 序 列 表 示 客 户 服 务 顺 序 的 无 分 段 大 路径[12-13]。染色体解码 采用基于深度优先搜索的大路径分割 方 法[14],考 虑 车 辆 装 载 能 力、最 大 行驶里程等约束。
2.3 种群初始化
由于初始解质量对遗传算法求解的速度和质量影响 较 大,本 文 以 C-W 节 约 法 为 基 础,设 计3种基于双重需求的启发式种群初始化方法,并采用大部分个体随机生成、部分优良个体采用种群初始化方法生成的方式得到初始种群 。随机产生方法遵循两条原则:
1️⃣第一,不允许产生相同个体;
2️⃣第二,随机产生个体与已产生个体的目标值之差应不小于某一数值Δ[13]。
这里的部分个体随机生成一个是降低耗时量,另一个扩大搜索空间呢。
2.3.1 基于双重需求的最低成本插入法
C-W 节约法 根 据 待 插 入 位 置 所 能 带 来 的 成本(或距离)节约值中的最大值来决定最佳插入位置[15]。为降低车辆超载率并提 高车辆装载率,VRPSPD客户服 务 排 序 须 考 虑 集 货 量 与 送 货 量之间的关系,通常将具有较大配送需求、较小取货需求的客户提前安排,或将具有较大取货需求、较小送货需求的客户延后安排。本文设计了一种基于双重需求的最低成本插入法(简称 PDCW 法),新的节约值根据取货量与送货量之间的关系对客户在不同插入点产生的空间效益差异影响进行定义,其计算公式为
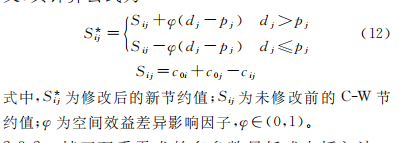
根据C-W节约法猜测 S i j S_{ij} Sij的形成。
- 第一种路线:仓库-节点i-仓库-节点j-仓库
c 0 i + c i 0 + c 0 j + c j 0 = 2 c 0 i + 2 c 0 j c_{0i}+c_{i0}+c_{0j}+c_{j0}=2c_{0i}+2c_{0j} c0i+ci0+c0j+cj0=2c0i+2c0j- 修改后的路线:仓库-节点i-节点j-仓库
c 0 i + c i j + c j 0 = c 0 i + c i j + c 0 j c_{0i}+c_{ij}+c_{j0}=c_{0i}+c_{ij}+c_{0j} c0i+cij+cj0=c0i+cij+c0j- 节约值为 S i j = c 0 i + c 0 j − c i j S_{ij}=c_{0i}+c_{0j}-c_{ij} Sij=c0i+c0j−cij
PDCW即在 S i j S_{ij} Sij的基础上考虑 送货量( d i d_i di)和取货量( q i q_i qi)的差值,其中 φ \varphi φ是影响因子,即决定这个差值所占的影响。
2.3.2 基于双重需求的多参数最低成本插入法
PDCW 法虽然考虑了客户需求量对改进节约值的不同影响,但未考虑不同节点之间运输费率或运 输 距 离 对 节 约 值 的 权 重 影 响。MESTER等[16]提出了一种改进 OSMAN 节约值[17]的多参数最低成本插入准则,插入点的成本节约值受到 插入点与其紧前、紧后节点之间成本(或距离)的权重影响。受此启发,本文设计了一种基于双重需求的多参数最低成本插入法(PDMPCW),通过同时考虑客户需求量及新弧对节约值的影响程度来改进成本节约值。改进后的成本节约值计算公式为

与上一节不同的事 S i j ′ S_{ij}' Sij′的事MESTER节约值而不是CW节约值了。计算方法不同了。整体思想没有变。
- MESTER节约值,如何计算呢?
MESTER启发式旨在通过计算插入一个节点(顾客点)到现有路径中的潜在成本节约来优化路径。MESTER节约值 的计算是基于路径上节点之间的距离。具体地,当你考虑将节点i插入到现有路径中的某个位置时,你需要计算由于这次插入而产生的总距离变化。这涉及到考虑从当前路径上的某个节点j到节点i的距离,以及从节点i到路径上下一个节点k的距离。
MESTER节约值的计算步骤如下:
- 对于每个现有路径中的节点j,计算从起点到j的总距离,记作( D j D_j Dj)。
- 对于每个现有路径中的节点j,计算从j到路径中下一个节点k的距离,记作( d j k d_{jk} djk)。
- 计算将节点i插入到j和k之间(或者作为路径的第一个或最后一个节点)时的额外距离,这将是( D j + d j k − d j i − d i k D_j + d_{jk} - d_{ji} - d_{ik} Dj+djk−dji−dik),其中( d j i d_{ji} dji)是从j到i的距离,( d i k d_{ik} dik)是从i到k的距离。
- 找到所有可能插入位置中额外距离最小的那个,这个最小的额外距离就是插入节点i时的MESTER节约值。
- 对所有待插入的节点重复上述步骤,并选择具有最大MESTER节约值的节点进行插入。
2.3.3 基于双重需求的多参数随机最低成本插入法
为了在搜索空间中产生多个较为分散且质量优良的初始染色体,本文提出基于双重需求的多参数随机最低成本插入法(PDMPRCW 法)。该方法以 PDMPCW 法 为 基 础,先 将 染 色 体 前 面k个客户固定,后 面 N -k 个 客 户 采 用 PDMPCW 法根据最大成本节约值准则插入。k 的取值根据客户总 数 N,按 一 定 百 分 比 可 以 取 不 同 的 整 数值,如 N =34时,k 按0.3N,0.4N,…,0.9N 进行向上 取 整,将 分 别 得 到 固 定 前 11、14、17、21、24、28、31个客户的7条染色体。
2.4 适应度值
总配送成本 同时受到车辆派出数量和配送路径距离的影响。相比具有较低车辆派出数量的父代,优良子代更容易从具有较短配送距离的父代染色体中遗传优良基因 。为有效避免早熟收敛并体现不同染色体的配送路径距离在整个种群中的影响,本文采用配送路径距离在整个种群中的评级,同时考虑种群大小的方式确定适应度值。适应度值的计算公式为
F
i
t
V
(
x
)
=
P
s
−
R
a
n
k
(
x
)
(14)
FitV(x)=P_s-Rank(x) \quad \text{(14)}
FitV(x)=Ps−Rank(x)(14)
其 中,
F
i
t
V
(
x
)
FitV(x)
FitV(x)表 示 染 色 体 x 的 适 应 度 值,
P
s
P_s
Ps表 示 种 群 大 小,
Rank(x)表 示 染 色 体 x 的 配 送路 径 距 离 在 整 个 种 群 中 的 评 级,即 配 送 路 径 距离 在 种 群 中 按 从 小 到 大 排 序 后 的 级 别。
如 染色 体x 的 配 送 路 径 距 离 在 种 群 中 的 排 序 为 5,则 Rank(x)=5。
2.5 交叉操作
交叉操作是产生新个体并将优良基因遗传给子代 的 主 要 方 法,是决定算法收敛性能的关键。针对多样性种群,本文采用传统的部分匹配交叉方式(partially mapped crossed,PMX),为大程度地提高种群多样性,直接以父代染色体作为交叉对象。针对高质量种群,本文采用边重组交叉算子和 PTL片段交叉算子。
《遗传算法中几种交叉算子小结》
- 选择父代染色体起止位置(位置相同),
>
- 交换这两组基因的位置
>
- 做冲突检测。因为proto-child 1中又两个1、2、9.获得最终结果:

边重 组 交 叉 算 子 是 由 STARKWEATHER等[18]提出的一种强化父代路径上边之间邻接关系遗传性状的个体交叉方式,具有较好的基因继承特性。文献[7]曾提出一种改进边重组交叉算子并将其用于求解 VRPSPD,该算子采用概率方式选择邻接节点,在强化子代遗传性状的同时保证了种群多样性。本文采用该改进边重组交叉算子[7],以染色体解码后的路径集合为父体产生对应邻接表,依次随机选择染色体中的客户节点,从邻接表中选择其前继节点及(或)后继节点,最终形成新的染色体。
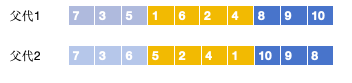
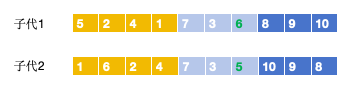
由于两个交叉父体可能相同,本文设 计 一 种PTL片段交叉,使相同序列交叉后得到不同的新序列。不同于直接以染色体交叉 的 PTL 两 点 交叉[19],PTL片段交叉以父体分割后的路径集合为交叉对象,随机地选择属于某一路径的客户作为交叉片段,交叉时将所选片段分别置于对方的前面,消去与交叉片段相同的客户节点,形成新的子代个体。具体交叉过程见图2。

随机选择某一路经作为交叉片段(例如,黄色片段)
交叉并将片段置于对方前面。(交叉后注意看到有重复的数字)
>
冲突检测,消去相同客户。
2.6 变异操作
为扩大个体搜索空间并在其附近进行深度探索,算法对染色体执行特殊变异。特殊变异包含两部分内容:去除重插入变异、两点互换变异。特殊变异本质上是对个体进行局域深度搜索,算法中主要用于高质量种群中的精英个体。
去除重插入变异是一种较大程度上的变异。变异时,先将父代染色体解码后的路径集合去除部分客户,然后 以Osman最 大 成 本 插 入 准 则 依次重新插入所去除客户后形成的子代染色体。
两点互换变异以染色体分割后的两条路径为父体,分别随机选择一定数量的节点形成多个节点对;针对各节点对,以 Osman最 大 成 本 插 入 准 则 为依据进行交换,最终选择具有最大成本节约值的节点对执行变异并形成子代个体。
Osman最大成本节约插入准则的基本思想是在构建车辆路径时,选择能够产生最大成本节约的插入点。具体来说,对于给定的一个路径和一个待插入的顾客点,该准则计算将该顾客点插入到路径中每个可能位置所带来的成本节约,并选择节约最大的位置进行插入。
这个准则的实现过程如下:
1. 对于每个待插入的顾客点,计算将其插入到路径中每个可能位置的成本节约。成本节约可以通过比较插入前后的路径总成本来计算。
2. 在所有可能的插入点中,选择节约最大的位置进行插入。
3. 重复步骤1和2,直到所有顾客点都被插入到路径中或达到其他终止条件(如最大迭代次数、时间限制等)。
2.7 选择操作
分级选择法是一种防止早熟收敛而设计的适应度值比例选择法。精英保留选择法将种群中最优个体保留直接进入下一代,可以有效保证算法寻优性能。算法在两个种群中同时采用精英保留选择法和分级选择法,确保在扩大搜索空间、加快搜索速度的同时提高全局搜索质量。
2.8 自适应策略
遗传算法搜 索 性 能 很 大 程 度 上 受 到 交 叉 概率和变异 概 率 的 影 响,取 值 过 大 容 易 破 坏 群 体中的优良 模 式;取 值 过 小 容 易 导 致 产 生 新 个 体的能力 变 差,导 致 过 早 收 敛。本 文 采 用 一 种 自适应策略调整高 质 量 种 群 的 交 叉 概 率 和 变 异 概率,以寻求 保 护 种 群 优 秀 性 状 得 以 遗 传 与 避 免早 熟 收 敛 两 者 之 间 的 平 衡,其 交 叉 概 率
P
c
P_c
Pc 和 变异概率
P
m
P_m
Pm分别为[20]

为有效避免陷入局部最优,通常
k
1
,
k
3
k_1,k_3
k1,k3 取 值 相 对 较 大,
k
2
,
k
4
k_2,k_4
k2,k4的取值根据实际情况确定。
2.9 算法整体流程
自适应并行遗传算法试图从搜索空间的广度及深度两个维度进行扩大搜索,通过引入多样性种群和高质量种群的双种群并行策略,并针对高质量种群中的个体进行自适应遗传操作,以进一步提高高质量种群的寻优性能。算法流程框图见图3,详细步骤如下。
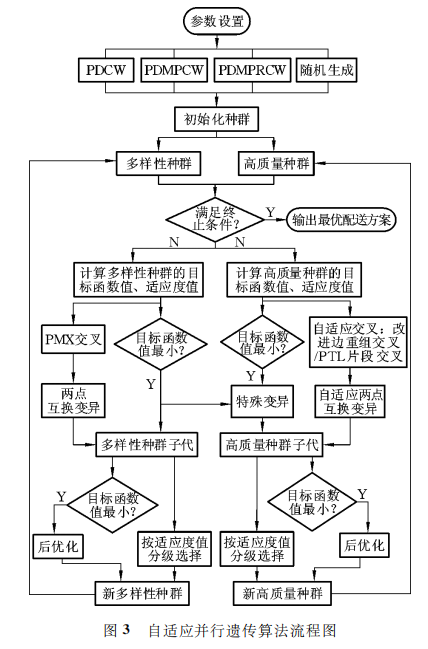
- PDCW, PDMPCW, PDMPRCW, 随机生成—》
插入的方法
(1)初始化 种 群 参 数 PS、交 叉 概 率 Pc、变 异
概率Pm 、最大迭 代 次 数tmax、全 局 极 值 连 续 未 更
新最大次数gsn;
(2)采用2.3节的种群初始化方法产生初始
种群,种群数目为PS;
(3)将上述初始种群复制两个,分别命名为多
样性种群ChromOne 和高质量种群ChromTwo;
令迭代次数t=0;
(4)如果 迭 代 次 数 不 超 过 最 大 迭 代 次 数tmax
或连续未更 新 次 数 不 超 过 最 大 次 数 gsn,执 行 以
下操作:
① 针对多样性种群:
a. 计算种群的目标函数值、适应度值;
b. 采用精英 保 留 策 略,将 种 群 中 目 标 函 数 值最小的个体bestChromOne 保存并复制给高质量种群ChromTwo;
c. 对种群执行多样性交叉变异操作:PMX 交叉和两点互换变异;
d. 更 新 多 样 性 种 群,即 将 原 精 英 个 体bestChromOne加入交叉操作后的种群,得到多样性种群子代,此时该种群大小为PS+ 1;
e. 计算多样 性 种 群 子 代 的 目 标 函 数 值、适 应度值;
f. 采用分级 选 择 法,从 新 种 群 中 选 择 PS -1个个体,加 上 原 精 英 个 体bestChromOne,形 成 新的多样性种群
②针对高质量种群:
a.计算种群的目标函数值、适应度值;
b.采用精英 保 留 策 略,将 种 群 中 目 标 函 数 值最小的个体bestChromTwo 保存;
c.对种群所 有 个 体 执 行 自 适 应 交 叉 操 作:改进边重组交叉或 PTL片段交叉;
d.对交叉后的种群所有个体执行自适应两点互换变异操作;
e.对两个种 群 的 原 精 英 个 体bestChromOne、bestChromTwo 执行特殊变异;
f.将经过步骤e后得到的两个新精英个体加入经过步骤d后得到的种群中,得到高质量种群子代,此时该种群大小为PS+ 1 + 1;
g.计算高质量种群子代的目标函数值及适应度值,找出目标函数值最小的精英 个 体,更 新bestChromTwo;
h.采用分级选择法,从高质量种群子代中选择PS-1个个体,加上精英个体bestChromTwo,最终形成新的高质量种群。
③对于两个种群中的精英个体bestChromOne、bestChromTwo,分别 执 行 特 殊 变 异 的 后 优 化 操作,如果后 优 化 操 作 使 得 该 精 英 个 体 的 目 标 函数值进一步降低,则 更 新 该 精 英 个 体;否 则 不 更新。选择目标函数 值 较 小 的 精 英 个 体 作 为 全 局最优个体。
④t←t+1,转步骤①。
(5)输出全局最优个体及其目标函数值,以及
最优路径集合。
3 算例测试与比较
为验证算法寻优性能,选取2个算例 进 行 寻优测试。算 法 采 用 MATLABR2009b编 程 语 言实现,微机运行环境为:CPU i5-2520,主 频2.5GHz,内存4GB。
3.1 算例选取及参数设置
3.1.1 算例选取
3.1.2 参数设置
3.2 结果分析
3.2.1 算例1分析
3.2.2 算例2分析
3.2.3 算法性能分析
为进一步分析双种群并行策略、种群 初 始 化方法及自适应交叉变异操作对算法性能的影响,选取算例2中 CMT8X 作为对 比 分 析 对 象,以 种
群大小为150、最大迭代次数为300、交叉概率为0.8、变异 概 率 为 0.03 的 组 合 参 数,独 立 运 算 20次,选取最优近似解进行分析。
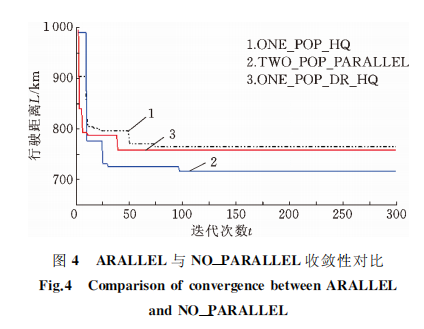
采用双种群并行策略与采用单一种群时的对比情况见图4。选取两种单一种群方式与双种群并行策略进行对比:一种为舍弃多样性种群、保留高质量种群的单一种群方式,另一种为包含小部分高质量个体、大部分多样性个体的单一种群方式,图4中分别采用 ONE_POP_HQ、ONE_POP_DR_HQ 表示,双种群并行策略采用 TWO_POP_PARALLEL表示。由 图4 可 见,单 纯 采 用 高 质量种群可以获取比较好的初始解,但在搜索过程中由于搜索空间变小很容易陷入局部最优;包含部分高质量个体、大部分多样性个体的单一种群方式虽然扩大了搜索空间,在一定程度上改善了种群多样性,但仍然无法跳出局部最优。而双种群并行策略却能以较少的迭代次数取得更小的行驶距离,说明本文提出的双种群并行策略在遗传算法求解 VRPSPD问题时,不仅能有效帮助算法在有限迭代次数内进行广度与深度的同步探索,而且能有效避免陷入局部最优,最终以较短时间快速寻找到近似最优解。
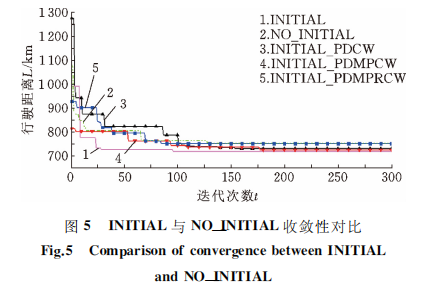
采用2.3节的种群初始化方法与不采用该方法时的 对 比 情 况 见 图5。图 例INITIAL_PDCW、INITIAL_PDMPCW、INITIAL_PDMPRCW 分别表示单独采用2.3.1节、2.3.2节和2.3.3节中的初始化方法,图例INITIAL表示同时采用上述三种初始化方法。图例 NO_INITIAL表示不采用上述初
始化种群方法,而以任意产生PS 条大路径序列方式对种群进行初始化。可见,在INITIAL情况下初始行 驶 距 离 较INITIAL_PDCW、NO_INITIAL要小 很 多,但 比 INITIAL_PDMPCW、INITIAL_PDMPRCW 要大一些,这说明,针对具有双重需求的 VRPSPD问题,其初始解质量在单纯考虑客户需求量对插入节点节约值的影响时最差,在增加考虑不同节点之间运输费率或运输距离对节约值权重影响、且不固定客户节点时最好,而同时考虑3种初始化方法仅处于中间状态。但是,同时考虑3种初始化方法在中后期收敛效果好,行驶 距 离 更
小,这说明初始化种群方法对本文算法求解 VRP-SPD问题的性能具有较大影响,良好的种群初始化方法能促使其收敛加快并保持良好寻优能力。
行驶距离通常指的是车辆从起始点出发,按照特定的路径为客户提供服务,并最终返回起始点所行驶的总距离。这个距离是优化目标之一,因为减少行驶距离可以降低运输成本、提高服务效率。
在迭代过程中,算法会根据某种策略(如局部搜索、遗传算法、模拟退火等)不断尝试寻找更好的路径。每次迭代后,算法会计算当前路径的行驶距离,并与之前的迭代结果进行比较。如果新的行驶距离比之前的更优(即更小),则接受这个新的路径作为当前最优解;否则,根据一定的概率或规则决定是否接受这个新的路径。
通过比较不同算法在迭代过程中行驶距离的变化,可以评估它们的收敛性。如果某个算法在较少的迭代次数内就能达到一个较低的行驶距离,并且这个距离在后续迭代中保持稳定或继续下降,那么可以认为这个算法具有较好的收敛性。相反,如果某个算法在迭代过程中行驶距离下降缓慢或波动较大,那么可能需要更多的迭代次数才能达到一个较好的解,这意味着该算法的收敛性可能较差。
通过比较不同算法在迭代过程中行驶距离的变化,可以评估它们的收敛性。如果某个算法在较少的迭代次数内就能达到一个较低的行驶距离,并且这个距离在后续迭代中保持稳定或继续下降,那么可以认为这个算法具有较好的收敛性。相反,如果某个算法在迭代过程中行驶距离下降缓慢或波动较大,那么可能需要更多的迭代次数才能达到一个较好的解,这意味着该算法的收敛性可能较差。
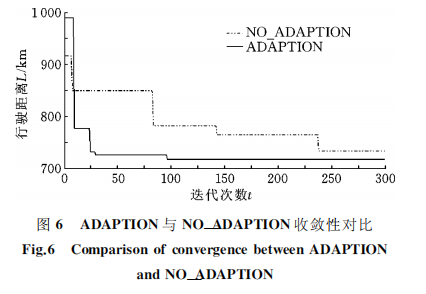
采用自适应交叉变异操作与交叉变异概率均恒定不变的对比情况见图6,图例分别为 ADAP-TION、NO_ADAPTION。由 图 可 见,当 交 叉 变异概率恒定不变时,算法收敛速度慢,容易在阶段性收敛后产生停滞从而陷入局部最优;而采用适应性变动的交叉变异操作能加快收敛速度,提升收敛效果,以较少的迭代次数搜索到更短的行驶距离。这说明本文提出的自适应交叉变异操作在遗传算法求解 VRPSPD问题时,能提高进化早期的全局搜索能力以及进化后期的局部搜索能力,
有效提高搜索质量。
4 结论
装卸一体化车辆路径问题是一类具有双重需求特征的复杂车辆路径问题,因其决策目标、决策因素和限制条件较多等特征需要高求解性能的启发式方法或元启发算法。针对装卸一体化车辆路径问题,本文建立了以总配送成本为优化目标的混合整数规划模型,提出了求解装卸一体化车辆路径问题的自适应并行遗传算法。该算法采用3种基于 C-W 的改进启发式算法产生初始种群,并引入多样 性 种 群 和 高 质 量 种 群 的 双 种 群 并 行 策略,同时采用保留精英及随着进化过程适应性改变交叉变异概率的自适应遗传操作,实现搜索空间在广度和深度上的同步拓展。针对不同规模、不同 总 目 标,分别基于两个算例进行仿真分析。仿真结果表明,无论是单纯以总行驶距离为目标
的算例1问题,还是以总配送成本为总目标、以车辆数最少和总行驶距离最短为子目标的算例2问题,本文提出的自适应并行遗传算法都能以较快的收敛速度找到近似最优解,且寻优性能强于已有的基于遗传算法的方法、插入式启发式算法、禁忌搜索 算 法 以 及 自 适 应 禁 忌 搜 索 算 法。由 此 可
见,本文所提算法对具有较大车辆指派成本的物流配送和取货优化问题具有重要的指导意义,同时对离散型组合优化问题的进一步研究也具有一
定的理论参考价值。