Paper name
MonoScene: Monocular 3D Semantic Scene Completion
Paper Reading Note
URL: https://arxiv.org/pdf/2112.00726.pdf
TL;DR
- 2022 cvpr 论文,提出一种能在室内与室外场景均可使用的单目 SSC 方案,与特斯拉的 Occupancy Network 非常相似
Introduction
背景
- 由图像估计出 3d 信息是个回到计算机视觉根源的问题,当前大部分方法都需要通过 2.5D 或者 3D 输入来进行 3d 估计,比如通过 Lidar 或深度相机,这些传感器相比于单目相机一般会更昂贵、占用空间更大、并对外部有干扰。如果能通过单目相机估计场景 3d 信息能为更多新应用铺平道路
- 3d 语义场景完成 (SSC)通过同时推理几何与语义信息来解决场景理解问题
- 当前方法的局限性是需要依赖深度数据输入,或者只能在室内或室外场景下使用
本文方案
- 本文提出一种能在室内与室外场景均可使用的单目 SSC 方案
- 提出一种将 2D 特征投影到 3D 的方法: FLoSP
- 提出一种 3D Context Relation Prior (3D CRP) 提升网络的上下文意识
- 新的 SSC loss 来优化场景类亲和力和局部截头体比例
Dataset/Algorithm/Model/Experiment Detail
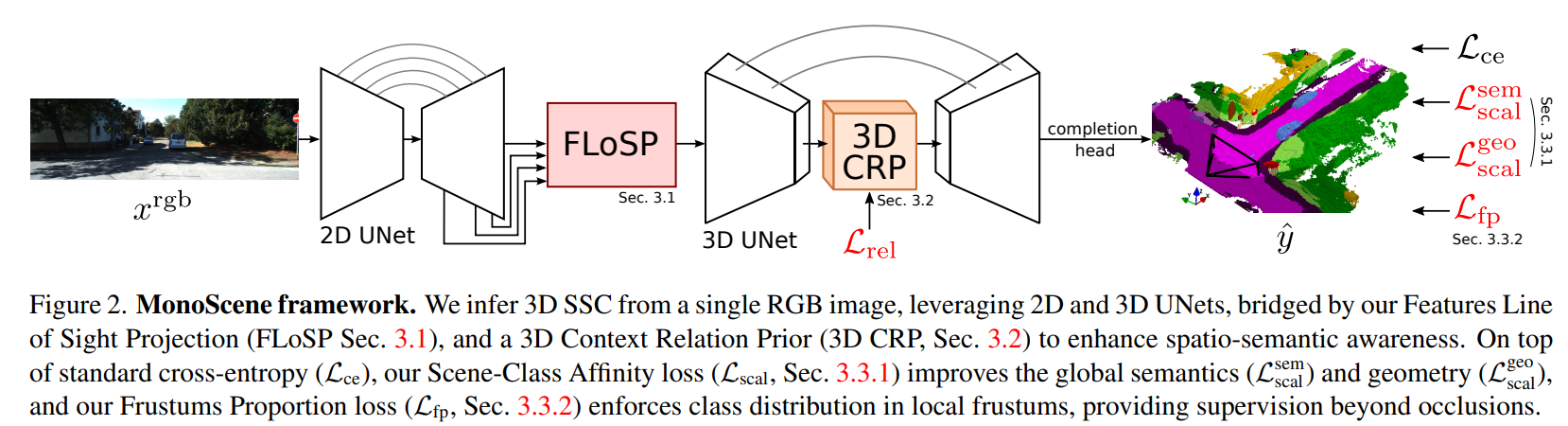
- Monoscene ppl 流程
- 输入 2d 图片,经过 2d unet 提取多层次的特征
- Features Line of Sight Projection module (FLoSP) 用于将 2d 特征提升到 3d 位置上,增强信息流并实现2D-3D分离
- 3D Context Relation Prior (3D CRP) 用于增强长距离的上下文信息提取
- loss 优化
- Scene-Class Affinity Loss:提升类内和类间的场景方面度量
- Frustum Proportion Loss:对齐局部截头体中的类分布,提供超越场景遮挡的监督信息
- 网络结构
- 2D unet:EfficientNetB7 用于提取图像特征
- 3D UNets:2层 encoder-decoder 结构,用于提取 3d 特征
- completion head:3D ASPP 结构和 softmax 层,用于处理 3D UNet 输出得到3d场景 completion 结果
实现方式
Features Line of Sight Projection (FLoSP)

- 对于 2d unet 的多尺度输出特征(1,2,4,8),分别过 1x1 conv,然后将多尺度的特征分别映射到 3d 空间中(映射方式是将 3d voxels 中心投影到 2d 特征上进行采样),最后对多尺度特征分别映射得到的 3d voxel 特征进行加和得到最终输出
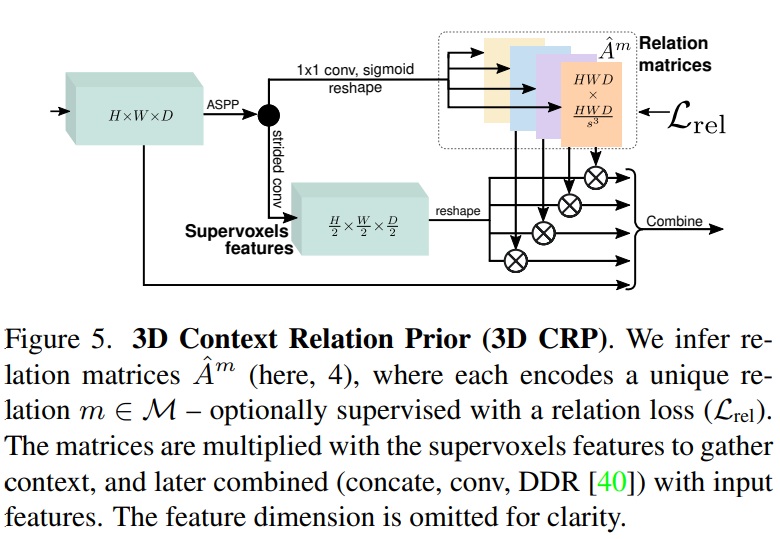
3D Context Relation Prior (3D CRP)
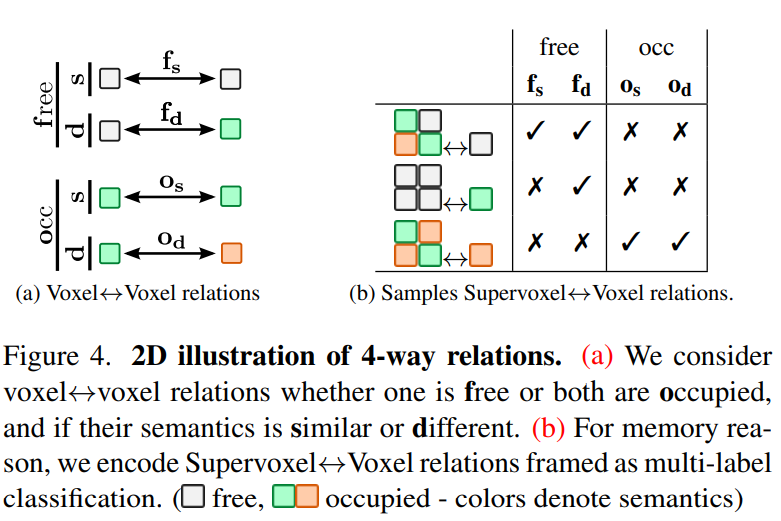
- 通过 2d 分隔中的 CPNet 启发,在 3d unet 增加 3D CRP 模块,学习 n 向体素↔体素语义场景关系图,本文 n 为 4,主要包含以下 voxel 类型
- free:至少有一个 voxel 是 free
- similar
- different
- occupied:所有 voxel 都是 occupied
- similar
- different
- free:至少有一个 voxel 是 free
- 上述的体素↔体素语义场景关系图构建是
n
2
n^2
n2 复杂度,本文使用 超体素↔体素 关系来降低存储和计算消耗
- 将超体素定义为非重叠组,每个组包含 s 3 s^3 s3 个相邻体素
- 超体素↔体素关系数量则降低为 N 2 s 3 \frac{N^2}{s^3} s3N2
- 对于某个超体素 V,以及体素 v,体素关系对的数量为 s 3 {s^3} s3 ,本文不是回归V↔ν中的M关系的复数计数,而是预测M个关系中的哪一个存在
- 3D Context Relation Prior Layer: 输入 3d map,经过 ASPP 卷积提升感受野,然后利用 1x1 conv 和 sigmoid 将 3d map 生成 M 组关系矩阵
A
^
m
\hat{A}^m
A^m,利用加权交叉熵损失进行训练;关系矩阵与重塑的超体素特征相乘,以收集全局上下文(或者,
A
m
A^m
Am 中的关系可以通过移除 Lrel 来自我发现(w/o M),即表现为注意力矩阵)
加权交叉熵
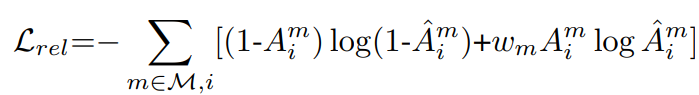
其中权重为
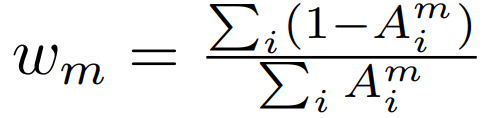
Losses
Scene-Class Affinity Loss
- 优化了类可导(P)recision、(R)ecall和(S)pecificity,其中Pc和Rc测量相似 c 类体素的性能,Sc 测量不相似体素(即不属于c类)的性能
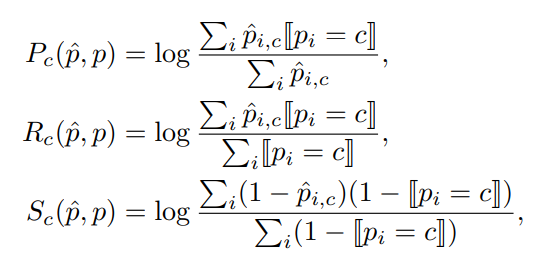
其中 p i p_i pi 是 voxel-i 的 gt class, p ^ i , c \hat{p}_{i,c} p^i,c 代表预测为 c 类的概率 - 使用以下 loss 提升上面的类别 metrics
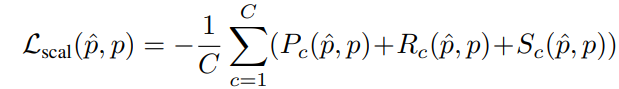
实际使用中会分别优化几何和语义
Frustum Proportion Loss
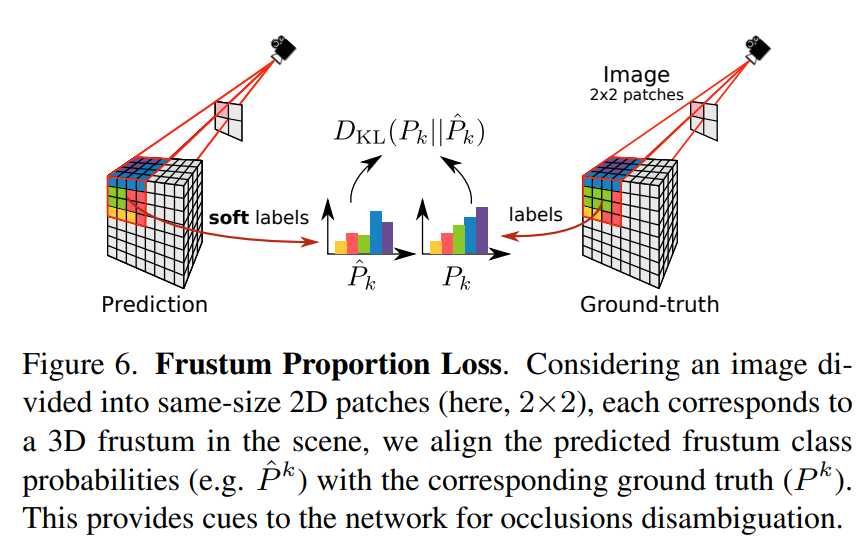
- 基于单目消除遮挡区域的歧义性是难以实现的,所以观察到遮挡区域的体素往往被预测为物体的一部分,提出了 Frustum Proportion Loss 来显式优化截头体中的类分布从而缓解上述问题
- 将输入图片分为 lxl 的 patches,对于每个 patch 投影到的 frustum 中对齐预测和 gt 的类别分布

其中 P k P_k Pk 是 k voxel 中的真实 gt 分布, P ^ k \hat{P}_k P^k 是 k voxel 中的预测分布
- 将输入图片分为 lxl 的 patches,对于每个 patch 投影到的 frustum 中对齐预测和 gt 的类别分布
Training strategy
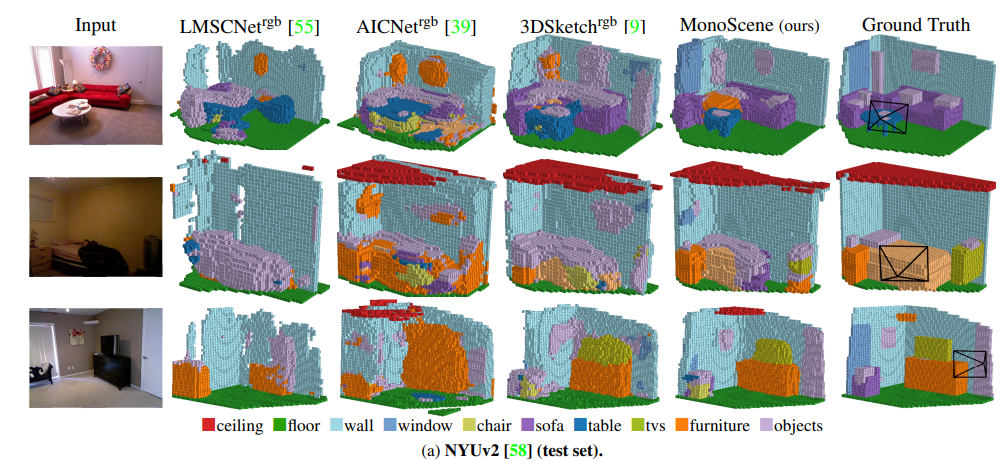
- 整体 loss 为上面的 4 个 loss 加上 ce loss
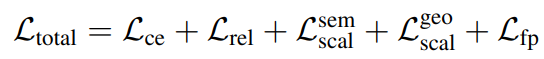
实验结果
数据集
- NYUv2
- 有 1449 Kinect 采集的室内场景图,体素标注为 240x144x240,13类 (11个语义,1 free,1 unknown)
- 640x480
- 795 train;654 test
- semantic kitti
- 室外雷达采集,体素标注为 256x256x32,voxel grid 尺寸为 0.2 m,21 类(19 语义,1 free,1 unknown)
- 使用 cam2 作为输入,1226x370,左裁剪到 1220x370
- 3834 train;815 val
训练超参

评价指标
- SC:occupied voxels 的 IoU,不细分语义类别
- SSC:每个类别的 mIoU
- 注意:之前文章对于室内仅对表面和 occluded voxels 进行评估,室外则是所有 voxel 都评估,本文因为对所有 voxels 进行评估,所以重新训练了所有的对比 baseline
NYUv2 与 SemanticKITTI 对比
- 因为本文是第一篇用纯视觉输入的工作,其他 baseline 基本是用深度估计网络 adabin 来提供深度或者伪 lidar 信息得到,monoscene 能取得 SOTA 效果
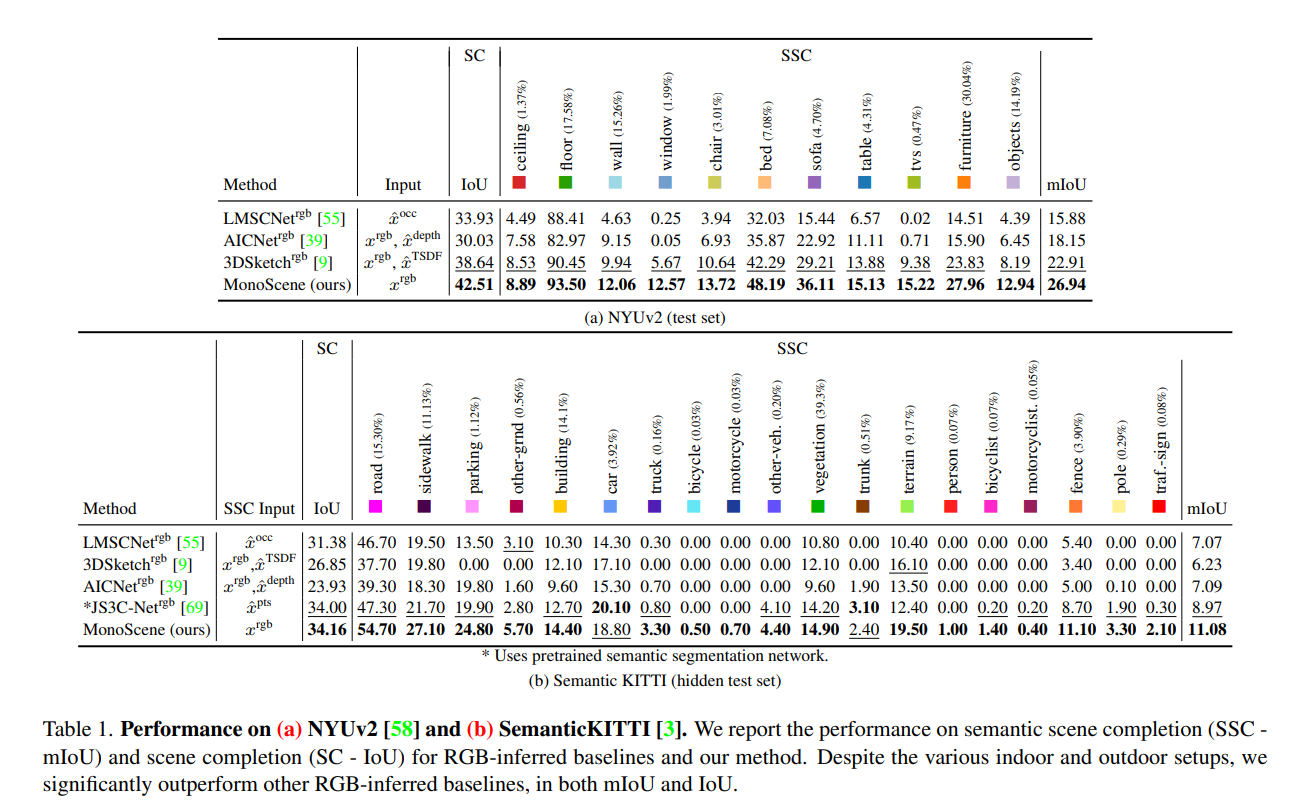
与 2.5D/3D 输入方法对比
- 因为信息量降低还是有一定差距,但某些 mIoU 之类的指标也有比其他方法更高的
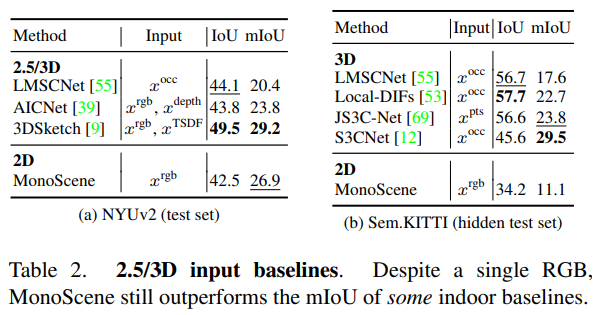
可视化对比
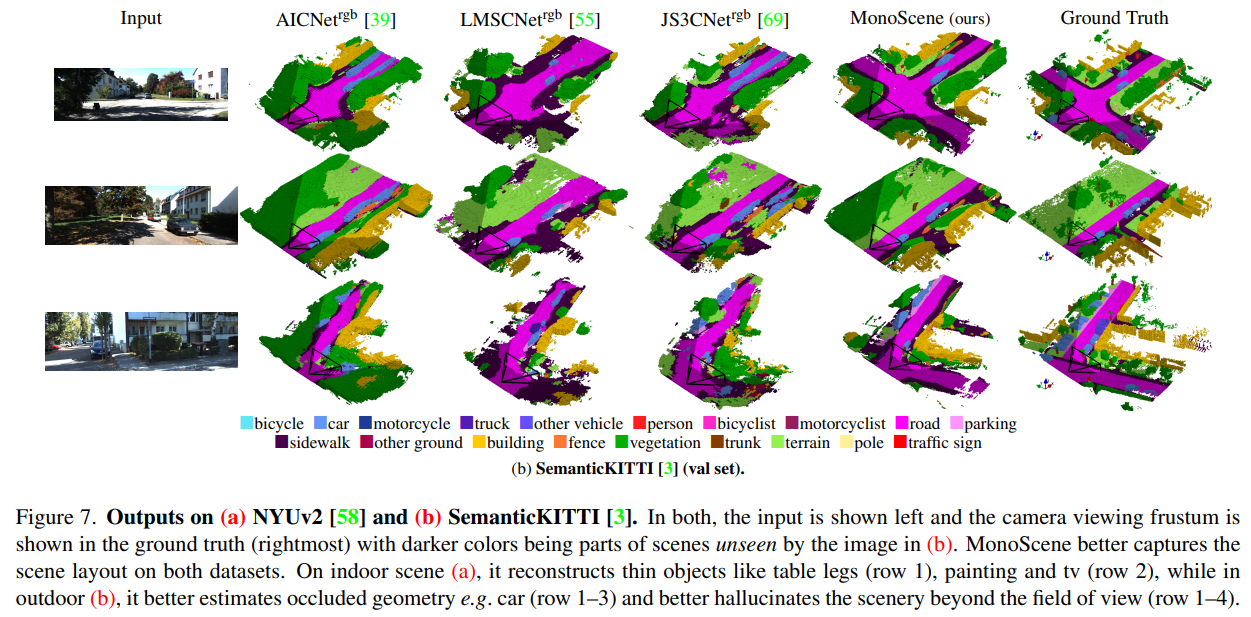
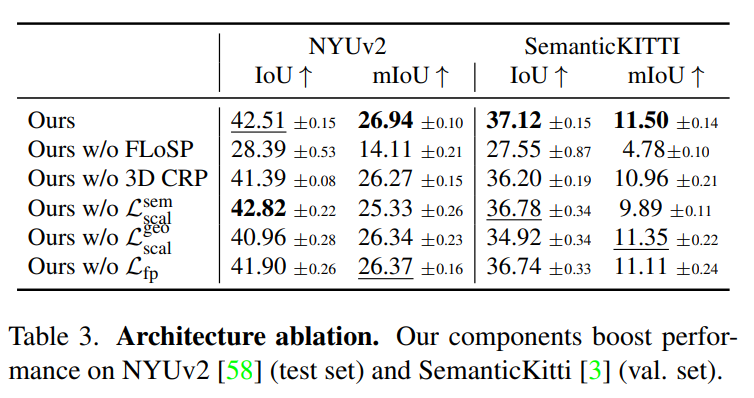
消融实验
- FLoSP 很重要,其他的均有贡献
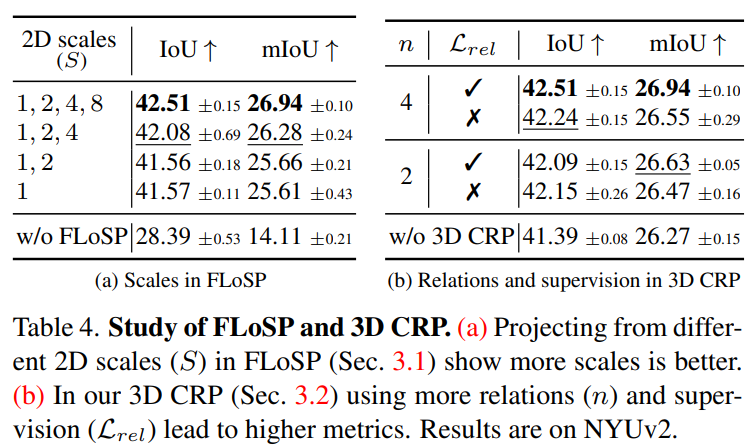
- FLoSP 中多尺度有涨点
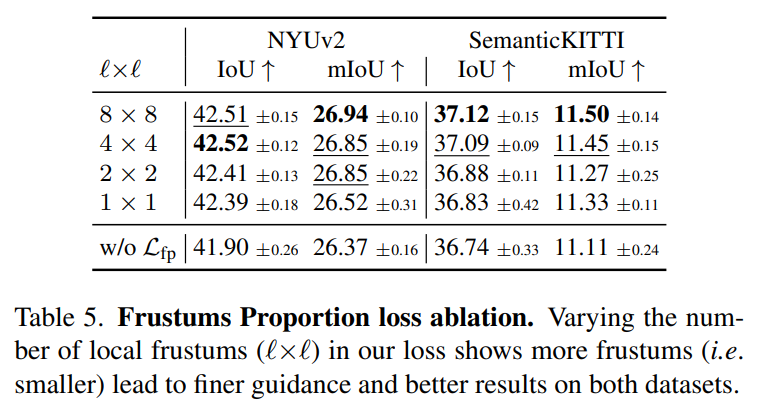
- Frustums Proportion loss 中 8x8 分块效果较好
- 2d-3d 投影变化对比
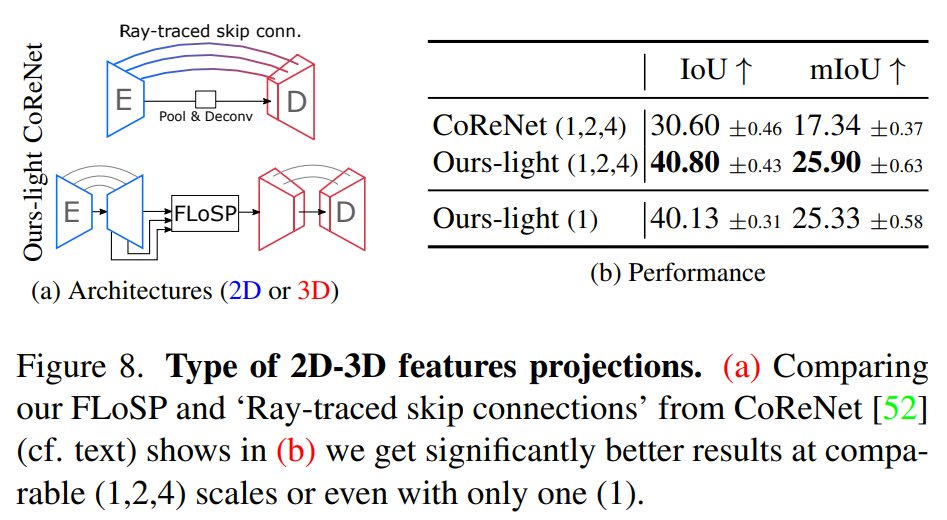
泛化性实验
- 在 SemanticKITTI 上训练,其他数据集上验证效果,大部分是合理的,不过 distortion 会变大

Limitation 分析
- 几何预测或语义预测的细粒度不行
- 小物体效果不行(SemKITTI 上小物体占比小于 0.3%)
- 其他数据集上泛化性一般
Thoughts
- 实验非常充分,复现效果也很好,不过用 v100 复现训练发现训练时长比论文中高
- 本文可以作为单目 SSC 的 baseline 进行一些实验迭代