一、Redis 的缓存穿透、缓存击穿、缓存雪崩是什么?

缓存穿透
请求不存在【 DB 和 Redis 中都不存在】的数据,导致请求直接打到持久层数据库中,导致数据库负载过高,甚至导致宕机。这样的请求几乎可以导致请求次次到达 DB ,会导致 DB 的压力过高,相当于 Redis 没有起到任何请求缓冲的功能。
【请求不存在的数据,数据既不在缓存,也不在数据库】
解决方法
- 缓存空结果:缓存和 DB 都没有请求结果的时候,将空值存入缓存层。之后再次发起请求的时候,就可以直接从缓存中返回空值了,避免 DB 短期内压力过高。需要注意空值的缓存生效时间不能过久,否则会产生数据一致性问题。
- 请求合法性校验:对用户的请求进行合法性校验,一旦发现用户的请求是不存在的数据,将该请求拦截禁止。
- 布隆过滤器:将所有存在的 Key 放入布隆过滤器中,在访问缓存层之前,先通过过滤器拦截,若请求的是不存在的 key ,则直接返回空值。
- 布隆过滤器的简单原理就是使用一个 Bit 数组,每个位置存储 0 或者 1 ,标识该位置是否被使用。而 Key 值则直接通过 Hash 映射到该数组中,判断一个 Key 是否存在可以直接看对应的 Hash 值位置上是否为 0 即可。事实上的布隆过滤器会存在一定的误判,但是对于大部分的判断还是准确的。
缓存击穿
缓存击穿指的是特定的热点数据被频繁访问,在失效的瞬间会将请求全部达到数据库上,造成 DB 瞬间压力过高宕机。可以理解为是对特定的热点数据的高频访问,一旦缓存失效请求会直接击穿 Redis 到达 DB 。
【特定的热点数据过期,导致 DB 瞬间压力过大】
解决办法
- 设置热点数据永不过期:两种方式,第一种不设置过期时间,达到物理上的“永不过期”。另一种本质上是对热点数据在过期前进行重新存储,刷新过期时间,达到一种”永不过期“的现象。
- 加互斥锁:让热点数据同时只能被一个线程访问,当一个线程访问该数据时,其他线程只能等待。访问完毕之后重建热点数据,届时其他线程可以直接从缓存取值。
缓存雪崩
由于某些原因,大量 key 在同一时间失效过期或不能用,导致缓存在瞬间几乎不可用,请求直接到达 DB ,最终导致宕机。
【缓存崩溃或大量缓存同时过期,没有数据可用】
解决办法
- 设置随机失效时间:在设置 key 的生效时间的时候,使用随机数。这样可以避免大量的 key 在同一时间都处于不能用的状态,避免了缓存雪崩出现。
- 数据永不过期:两种实现方式,目的就是延长 Redis 的生效时间。
- 构建多级缓存:可以在本地新建一级缓存,降低请求达到 DB 的概率。相当于在 Redis 之前再加了一层屏障。常用的一级缓存构建工具有 Caffeine 、 Guava Cache 、EhCache 等。相比于 Redis ,本地缓存在处理请求的时候效果更好,性能更高。
- 构建高可用的 Redis 集群:部署多个 Redis 实例,当某个实例不可用的时候,仍然可以保证服务的可用性。
- 启用限流和降级措施:对存储层增加限流措施,当请求超出限制的时候,对其提供降级服务。
参考文档:
三句话搞懂 Redis 缓存穿透、击穿、雪崩!JAVA技术全栈的博客-CSDN博客
redis缓存击穿
什么是缓存雪崩、击穿、穿透?_小林coding的博客-CSDN博客_缓存雪崩
二、Http 和 RPC 有什么区别?
RPC:Remote Produce Call 远程过程调用,类似的还有RMI(Remote Methods Invoke,远程方法调用,是 Java 十三大技术之一)。自定义数据格式,基于原生 TCP 通信,速度快,效率高。早期的 webservice ,现在热门的 dubbo、gRPC,都是RPC的典型。
Http:http其实是一种网络传输协议,基于TCP协议,规定了数据传输的格式。现在客户端浏览器与服务端通信基本都是采用 Http 协议,也可以用来进行远程服务调用。缺点是消息封装臃肿,有很多的请求头、请求行。
相同点:底层通讯都是基于 socket ,都可以实现远程调用和服务调用服务。
不同点:
- RPC:框架有:dubbo、cxf、(RMI远程方法调用)Hessian、gRPC。当使用 RPC 框架实现服务间调用的时候,要求服务提供方和服务消费方都必须使用统一的 RPC 框架,跨操作系统在同一编程语言内使用。优点是调用快、处理快。
- Http:框架有:httpClient。当使用 http 进行服务间调用的时候,无需关注服务提供方使用的编程语言,也无需关注服务消费方使用的编程语言。服务提供方只需要提供 RESTful 风格的接口,服务消费方按照 RESTful 的原则请求服务即可,是跨系统跨编程语言的远程调用框架,优点在于通用性强。
为什么使用 RPC 而不使用 HTTP ?
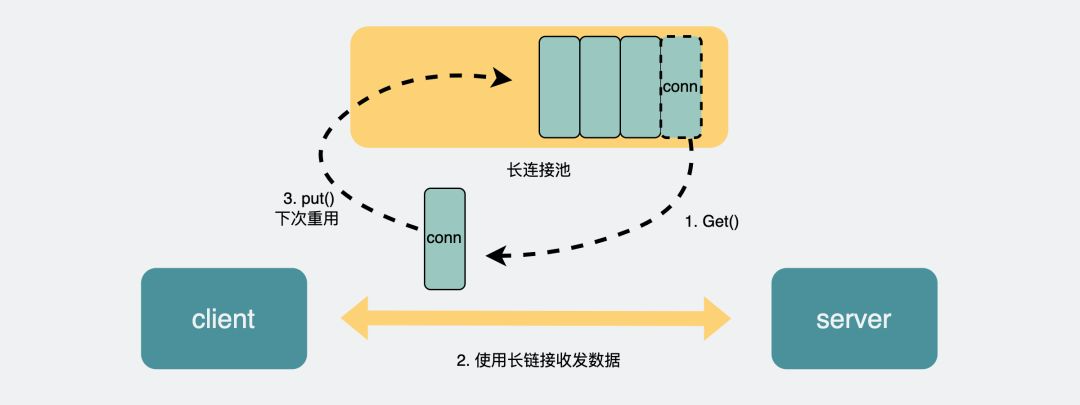
Http 调用效率较低:主要为了让分布式或者微服务系统中不同服务之间的调用像本地调用一样简单。RPC 是一种设计,为了解决不同服务之间的调用问题,他一般会包括传输协议和序列化协议。Http 协议使用 TCP 协议进行连接,三次握手会产生比较大的延迟,每发送一次请求,都会有一次建立连接的过程,加上 Http 报文和 JSON 序列比较,会造成 Http 调用效率比较低,并不能像实现本地调用一般完成远程调用。
RPC 框架功能更齐全:成熟的 RPC框架提供了有“服务自动注册与发现”、“智能负载均衡”、“可视化的服务治理和运维”、“运行期流量调度”等功能。
对于性能有高要求的场景,就需要使用 RPC 来进行一个远程调用。RPC 针对 Http 协议可以做出的性能优化主要包括:
减少传输量(RPC会有自己优化过的序列化方式)
简化协议(摒弃 Http 在调用时可能用不上的一些报文)
长连接(避免每次三次握手)
参考文档:
可以不要RPC吗?我都有 HTTP 协议了_不会敲代码的谌的博客-CSDN博客_不用rpc
三、如何规定多线程的执行顺序?
假设现在存在 A 、B 、C 三个线程,需要按照特定的前后顺序来执行,该如何规定呢?
① 在子线程内使用 join 方法:
通过 join() 方法使当前线程“阻塞”,等待指定线程执行完毕后继续执行。
public class ThreadJoinDemo {
public static void main(String[] args) throws InterruptedException {
final Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("打开冰箱!");
}
});
final Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
thread1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("拿出一瓶牛奶!");
}
});
final Thread thread3 = new Thread(new Runnable() {
@Override
public void run() {
try {
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("关上冰箱!");
}
});
//下面三行代码顺序可随意调整,程序运行结果不受影响,因为我们在子线程中通过“join()方法”已经指定了运行顺序。
thread3.start();
thread2.start();
thread1.start();
}
}
② 在主线程中使用 join() 方法:
public class ThreadJoinDemo {
public static void main(String[] args) throws InterruptedException {
final Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("打开冰箱!");
}
});
final Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
thread1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("拿出一瓶牛奶!");
}
});
final Thread thread3 = new Thread(new Runnable() {
@Override
public void run() {
try {
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("关上冰箱!");
}
});
// 在主线程中使用 join 方法,使得线程按照指定顺序运行
thread1.start();
thread1.join();
thread2.start();
thread2.join();
thread3.start();
}
}
③ 使用多个 CountdownLatch 对象:
只要检测到计数器为 0 当前线程就可以往下执行而不用管相应的 thread 是否执行完毕。
public class ThreadCountDownLatchDemo {
private static CountDownLatch countDownLatch1 = new CountDownLatch(1);
private static CountDownLatch countDownLatch2 = new CountDownLatch(1);
public static void main(String[] args) {
final Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("打开冰箱!");
countDownLatch1.countDown();
}
});
final Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
countDownLatch1.await();
System.out.println("拿出一瓶牛奶!");
countDownLatch2.countDown();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
final Thread thread3 = new Thread(new Runnable() {
@Override
public void run() {
try {
countDownLatch2.await();
System.out.println("关上冰箱!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//下面三行代码顺序可随意调整,程序运行结果不受影响
thread3.start();
thread1.start();
thread2.start();
}
}
④ 使用单一线程池 newSingleThreadExecutor() 来实现:
public class ThreadPoolDemo {
static ExecutorService executorService = Executors.newSingleThreadExecutor();
public static void main(String[] args) {
final Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("打开冰箱!");
}
});
final Thread thread2 =new Thread(new Runnable() {
@Override
public void run() {
System.out.println("拿出一瓶牛奶!");
}
});
final Thread thread3 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("关上冰箱!");
}
});
executorService.submit(thread1);
executorService.submit(thread2);
executorService.submit(thread3);
executorService.shutdown(); //使用完毕记得关闭线程池
}
}
四、解决 Hash 冲突的方法有哪些?
链地址法
对于相同的哈希值,使用链表进行连接。(HashMap使用此法)
- 优点:处理冲突简单,无堆积现象。即非同义词决不会发生冲突,因此平均查找长度较短;适合总数经常变化的情况(因为拉链法中各链表上的结点空间是动态申请的)。占空间小。装填因子可取 α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,删除结点的操作易于实现,只要简单地删去链表上相应的结点即可。
- 缺点:查询时效率较低。存储是动态的,查询时跳转需要更多的时间。在 key-value 可以预知,以及没有后续增改操作时候,开放定址法性能优于链地址法,不容易序列化。
再哈希法
对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
建立公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
开放定址法
- 线性探测:按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上往后加一个单位,直至不发生哈希冲突。
- 再平方探测:按顺序决定值时,如果某数据的值已经存在,则在原来值的基础上先加 1 的平方个单位,若仍然存在则减 1 的平方个单位。随之是2的平方,3的平方等等。直至不发生哈希冲突。
- 伪随机探测:按顺序决定值时,如果某数据已经存在,通过随机函数随机生成一个数,在原来值的基础上加上随机数,直至不发生哈希冲突。
五、常用的排序算法的实现?
冒泡排序:
private static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j + 1] < arr[j]) {
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
}
}
}
}
选择排序:
private static void choiceSort(int[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
int temp = arr[i];
for (int j = i + 1; j <= arr.length - 1; j++) {
if (arr[j] < temp) {
int swapTemp = arr[j];
arr[j] = arr[i];
arr[i] = swapTemp;
}
}
}
}
快速排序:
private void quickSort(int[] array, int left, int right) {
int pivot = array[left];
int low = left, high = right;
while (low < high) {
while (array[high] >= pivot && low < high)
high--;
// 找到右边第一个小于pivot的值
array[low] = array[high];
while (array[low] <= pivot && low < high)
low++;
// 找到左边第一个大于pivot的值
array[high] = array[low];
}
array[low] = pivot;
quickSort(array, left, low - 1);
quickSort(array, low + 1, right);
}