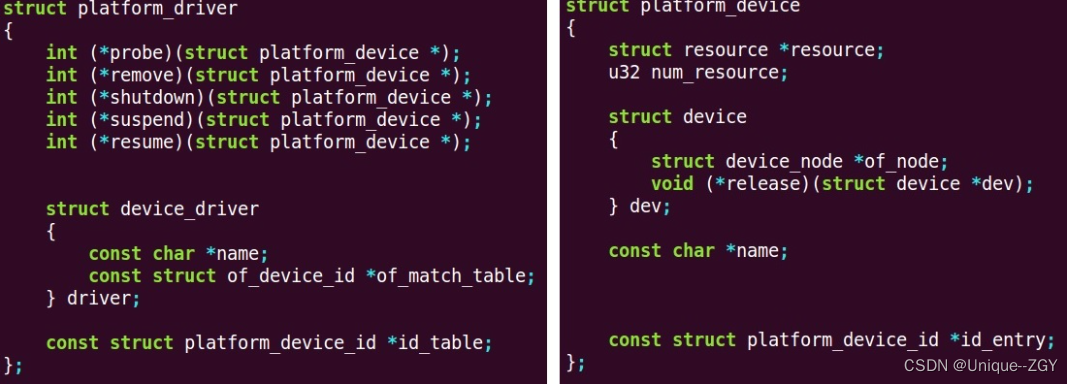
在ORBSLAM中,为了保证特征的均匀分布使用了均匀化的策略,最近在尝试扩展一下均匀化的内容,所以仔细看了一下ORBSLAM源码里面这部分的内容,之前看源码的时候没有展开仔细看这一部分的代码,这里补充记录一下,之前的阅读记录可参考链接
在展开看代码之前,首先对ORBSLAM的均匀化策略做一个小总结。均匀化本身是为了让特征在整张图像上分布得更加均匀,也就是保证图中每个位置基本都能有几个特征点,这样做的目的就是为了在位姿估计时能够更加准确。均匀化主要分为两个部分:分割和取点。分割指的是利用四叉树结构,对节点不断进行划分,从而达到满足特征点数目的节点个数。取点则是在划分好的节点中,选取落入节点中的一定数目的特征点,从而实现特征点的提取。
分割节点
均匀化的代码对应位置在ORBextractor.cc里面的DistributeOctTree函数中,该函数传入了待划分的特征点、图像的基本范围、特征点的目标数量以及一个层数,不过层数这个量好像在函数里面没有用到。下面简单看一下代码的实现,进入函数之后,首先会根据图像的宽高比,确定需要多少个初始节点,一般来说是一个,最多也不会超过两个,所以这里我们按照一个初始节点来计算。需要注意的是,由于使用的是树结构的分割方法,所以这里我们用节点这个词,一个节点表示的是图像中的一个范围,或者说一个格子,那么初始节点相当于是整张图像。

确定好初始节点的数目,就初始化这个初始节点ni,初始化过程中指定了节点的范围并为特征点预留了存储空间,之后就放入了lNodes的列表中,用于后续的分割流程。之后代码将特征点分配给了这个节点内部的vKeys的向量中,并根据初始节点的特征点数目,给初始节点的分割状态进行标记。

这里补充一下,均匀化的过程中,其实会根据内部特征点的数量,划定三种状态,如果节点内部一个特征点都没有,那就直接删掉,不向lNodes里面添加,如果节点内部只有一个特征点,就会将bNoMore标记为true,表示这个节点不能再进行分割了,最后一种状态就是特征点多于一个,表示这个节点还可以继续分割。
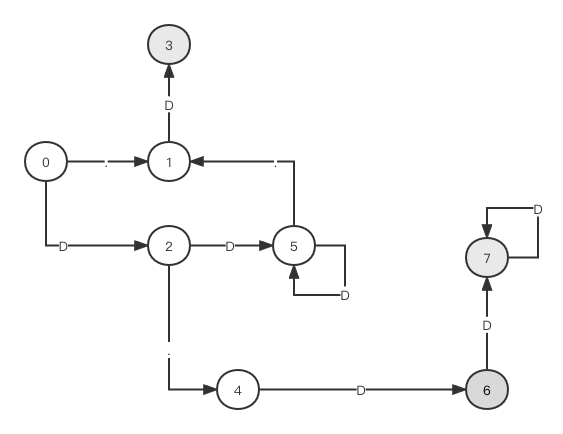
做好这一些准备工作之后,就可以开始分割了,分割的过程简单来说就是一分四,然后检查四个子节点是不是可以继续分割,如果可以,放入lNodes里面,否则就跳过。进入分割的循环后,会利用bFinish作为结束的标准,分割按照轮次进行,这里为了方便理解,一个轮次分割的节点我们就认为是开始分割时lNodes里面拥有的节点,之后每次从lNodes里面拿出一个节点作为要分割的节点。
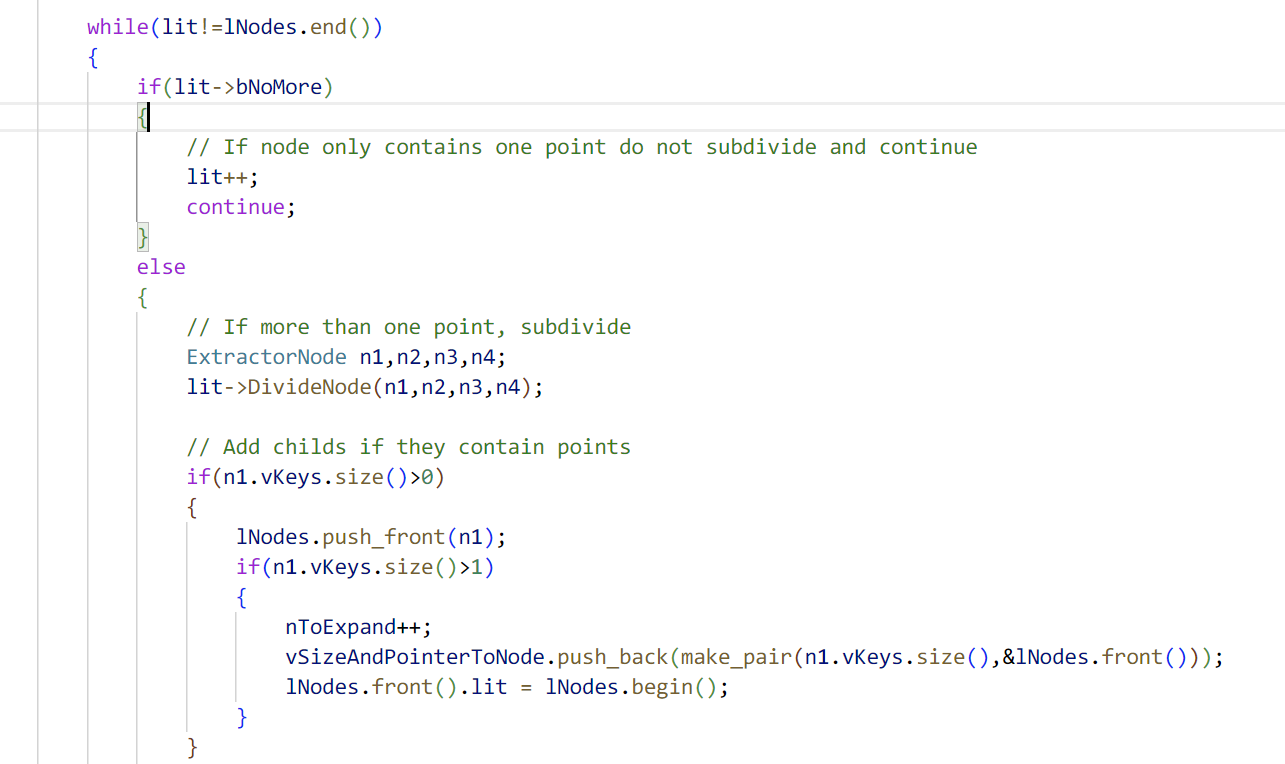
对于当前的这个节点,如果内部只有一个特征点,说明不能再分割但也不能直接扔掉,不对它做任何处理直接continue,如果能够进行分割,就调用DivideNode函数,将当前节点分割为四个子节点并将特征点放入其中,如果四个子节点中某个节点有特征点,那么首先将子节点放入lNodes中,之后检查这个节点的状态,确定是否可以进行分割。这里有一个细节,在将子节点放入lNodes时,调用的函数是push_front而非我们常用的push_back,调用这个函数会将节点插入到list的最前面,这样子相当于用一个普通的list实现了类似广搜的操作,这里我们按照代码流程理顺一遍,假设在一轮分割开始之前,lNodes里面有节点ABCD,现在我们取出节点A,这个节点分割出四个子节点abcd,这个时候我们假设这四个子节点都是可以分割的,那么根据代码的执行顺序,节点A通过erase函数去掉,指针移动到B的位置,四个子节点通过push_front插入到lNodes前面,所以对A的分割结束后,lNodes变为abcdBCD,下一次将开始B的分割,这样子在这一轮分割结束后,一共进行了四个节点的分割:ABCD,正好是这一轮分割开始前lNodes里面有的四个节点,同时内部特征点大于等于一的子节点将重新放入lNodes等待下一轮的继续分割。
这一层循环结束的标准是一轮分割结束,在一轮分割结束后,会有一个检验是否结束分割的步骤,如果lNodes里面的节点数目多于要提取的特征点数量,或者一轮分割前后节点数没有变化,则认为达到了分割结束的标准。这里稍微看一下这两个标准,这个if条件里面是两个或条件,根据节点数来判断是因为,我们在前面分割的时候,所有留在lNodes里面的节点,都是内部特征点大于等于1的节点,也就意味着,特征点数目一定是大于等于节点数的,当节点数都多于目标特征点数目的时候,说明没有再继续分割的必要了,直接提取点就够了,所以这个时候选择结束分割,另一个条件则是一轮分割前后节点数没有变化,这里其实对应的就是lNodes中所有节点都是不可再分割的节点,这时候不管重复多少次都是一样的,所以选择结束分割。

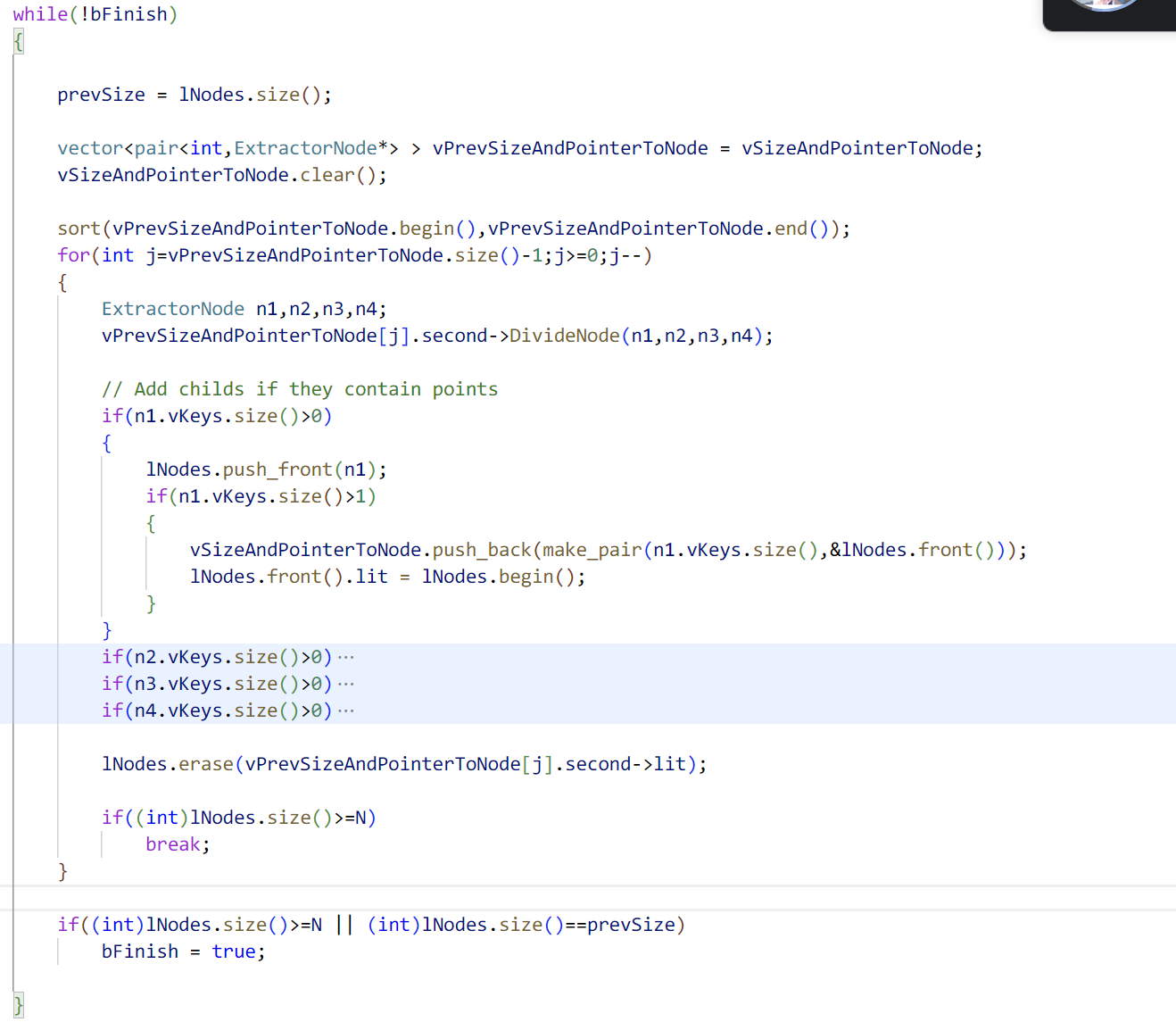
而另一个分支其实是想在停止分割的前一轮进行细微操作,这里可以看到依然是利用目标特征点数目做了一个约束,而约束的内容就是下次分割以后特征点的数目,一个可以分裂的节点分裂后最多产生四个新的子节点,从数目上看增加了三个,所以这里是乘三再做加法,表示下次分割之后最多的数目。如果进入这个分支,相当于在停止分割的前一轮进行下面的一大段操作。

在这个分支中,其实也是在重复进行分割操作,直到满足结束分割的条件,在这个分支中,需要对这一轮分割新加入的节点进行分割,相当于进行了下一次分割但是确实是在这一轮次中。对新加入的节点利用sort函数进行排序,根据节点内部的特征点数量进行升序排序,这里代码实现上是直接调用的sort,但是并没有指定排序函数,根据sort的默认排序规则,应该是升序,而且排序的是一个元素为pair的vector,所以按道理是根据pair的第一个元素进行排序,如果相同在根据第二个,由此推测是根据内部特征点数量进行的升序排序。

排序后根据内部特征点的数量,从大到小进行节点的遍历,对每个节点进行分割,操作与前面的分割一样。不同之处在于,如果对一个节点进行分割之后,如果满足了停止分割的条件,就直接结束分割,而不是完成这一轮之后再结束分割。
所以这里的分割策略就是先按照轮次进行分割,分割到倒数第二次,就换成以子节点为单位进行分割。那么问题在于,如果倒数第二次就更换了分割策略,那是不是就不需要最后一次的策略进行检验了。这里这种写法本意是让分割过程中进入倒数第二次时,更换分割策略从而防止过度分割,但是总感觉哪里有些问题却又说不上来。
提取
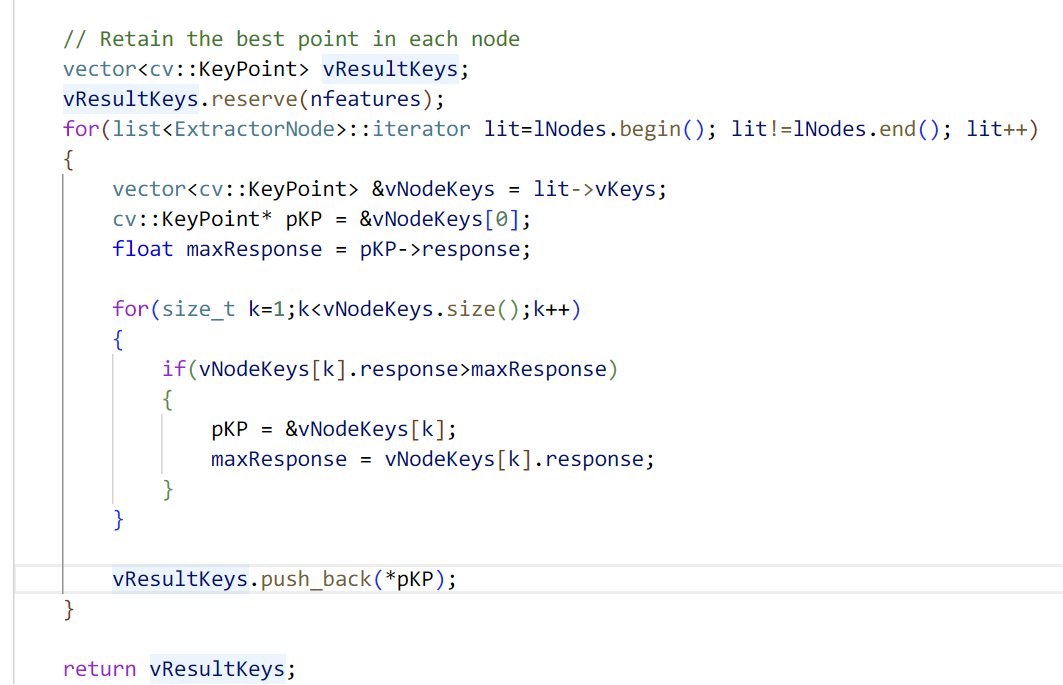
提取的过程就相对简单很多了,遍历lNodes中每一个节点,选择出这个节点中特征点响应值最高的点作为这个节点最终筛选出来的特征点,存入向量中返回即为最终结果。