文章目录
- elasticsearch(集群)中可以包含多个索引index(数据库) ,每个索引中可以包含多个类型types(表) ,每个类型下又包含多个文档Document(行) ,每个文档中又包含多个字段Field(列)
- 实战场景举例
- 映射类型的替代方案
- (1)每个文档类型的索引
elasticsearch(集群)中可以包含多个索引index(数据库) ,每个索引中可以包含多个类型types(表) ,每个类型下又包含多个文档Document(行) ,每个文档中又包含多个字段Field(列)
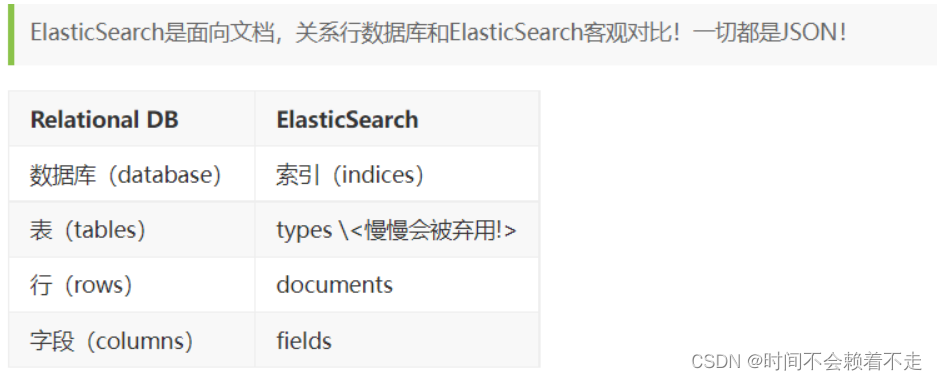
1.关系型数据库中的数据库(DataBase),等价于ES中的索引(Index)
2.一个数据库下面有N张表(Table),等价于1个索引 Index下面有N多类型(Type)
3.一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于1个Type由多个文档(Document)和多Field组成。
4.在一个关系型数据库里面,schema定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在ES中:Mapping定义索引下的Type的字段处理规则,即索引如何建立、索引类型、是否保存原始索引JSON文档、是否压缩原始JSON文档、是否需要分词处理、如何进行分词处理等。
5.在数据库中的增insert、删delete、改update、查search操作等价于ES中的增PUT、删Delete、改POST、查GET.
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站
点击跳转浏览。
最初,我们谈到“索引”类似于 SQL 数据库中的“数据库”,“类型”相当于“表”。
这是一个糟糕的类比,导致了错误的假设。在 SQL 数据库中,表是相互独立的。一个表中的列与另一个表中的同名列无关。对于映射类型中的字段,情况并非如此。
在 Elasticsearch 索引中,不同映射类型中具有相同名称的字段在内部由相同的 Lucene 字段支持。 换句话说,使用上面的示例,用户类型中的 user_name 字段与 tweet 类型中的 user_name 字段存储在完全相同的字段中,并且两个 user_name 字段在两种类型中必须具有相同的映射(定义)。
例如,当您希望 delete 成为同一索引中一种类型的日期字段和另一种类型的布尔字段时,这可能会导致挫败感.
最重要的是,在同一索引中存储具有很少或没有共同字段的不同实体会导致数据稀疏并干扰 Lucene 有效压缩文档的能力。
由于这些原因,我们决定从 Elasticsearch 中删除映射类型的概念。
实战场景举例
下面两种场景,大家都用过:
同一个index下,不同的type,命名名称一样的字段名。
同一个数据库下,不同的表,命名名称一样的字段名。
- 在关系型数据库中,不同的表中,包含相同的字段名是很常见的,而且它们可以做到互不干扰。
- 在ElasticSearch中,不同的type,如果包含相同的字段名,它们是一样的,es会认为是一个字段,模糊掉不同type的概念。
所以在es里边,type这个概念没必要存在,所以es7就废弃了。
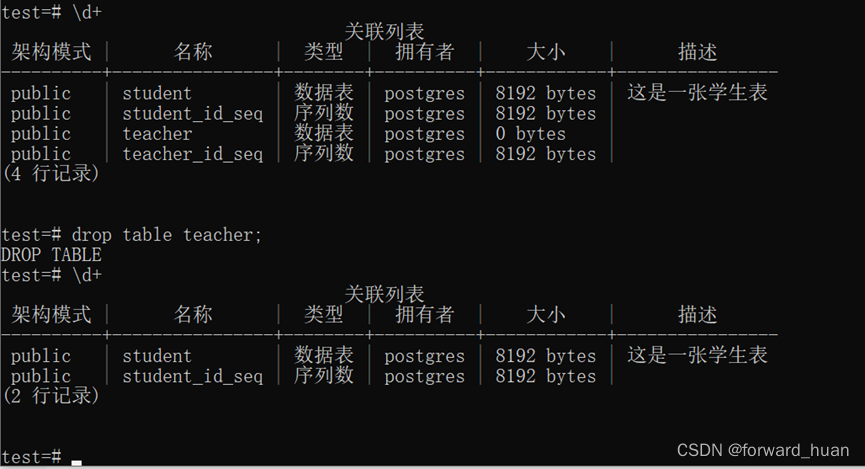
同志们,可以试一下,在同一个index中,不同的type,创建一个同名的字段,但是类型不要弄成一样的,看能否成功创建。
答案是不可以,它会提示你,不可以将这个字段的类型更改为这个类型。
illegla_argument_exception
mapper [create_time_] cannot be changed from type [date] to [keyword]
复制代码
所以,结论就是,es确实把不同type中的同名字段,当成了一个字段。
在设计索引库的时候,同名问题一定要注意:
- 最简单的方法就是一个index,一个type,想要其他类型,另外创建index,
- 当然你可以用别的字段名。
映射类型的替代方案
(1)每个文档类型的索引
**第一种选择是为每个文档类型设置一个索引。**您可以将推文和用户存储在推文索引中,将用户存储在用户索引中,而不是将推文和用户存储在单个推特索引中。索引彼此完全独立,因此索引之间不会存在字段类型冲突。
这种方法有两个好处:
- 数据更可能是密集的,因此受益于 Lucene 中使用的压缩技术。
- 在全文搜索中用于评分的术语统计信息更可能准确,因为同一索引中的所有文档都表示单个实体。
每个索引都可以根据它包含的文档数量适当调整大小:您可以为用户使用较少数量的主分片,为推文使用更多数量的主分片。