【Pytorch深度学习开发实践学习】B站刘二大人课程笔记整理lecture11 Advanced_CNN
代码:
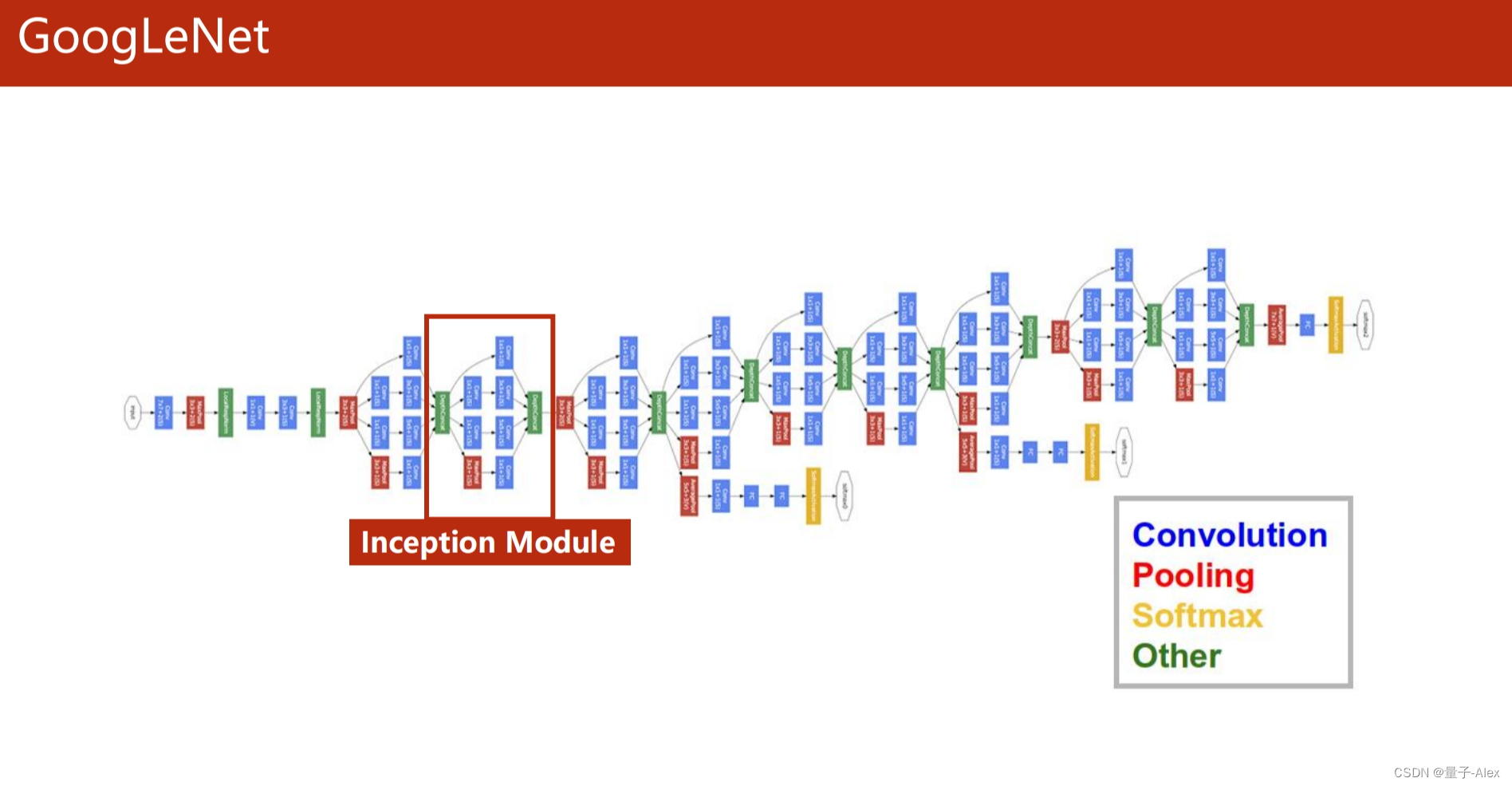
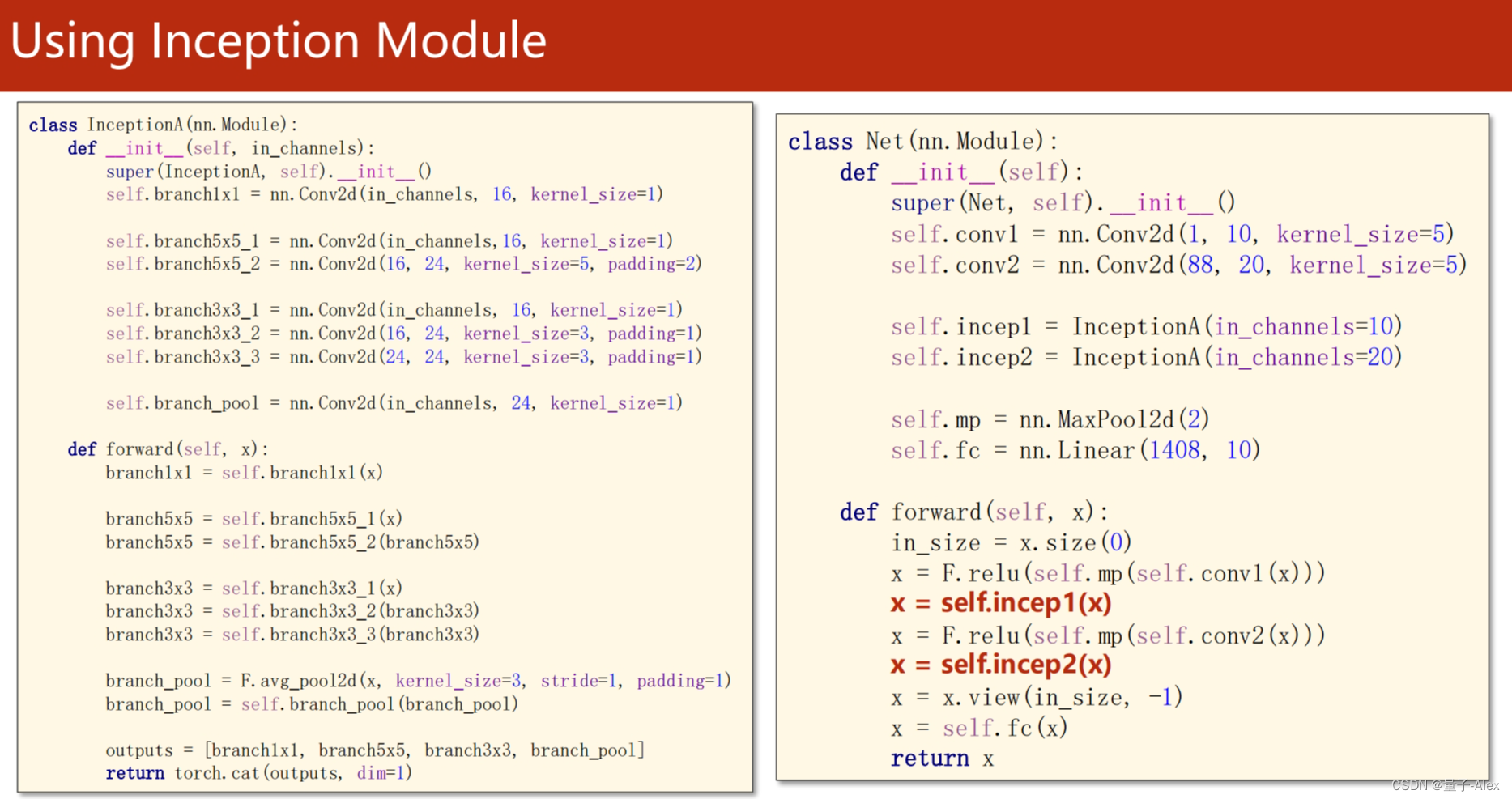
Pytorch实现GoogleNet
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) #把原始图像转为tensor 这是均值和方差
train_set = datasets.MNIST(root='./data/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_set = datasets.MNIST(root='./data/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=True)
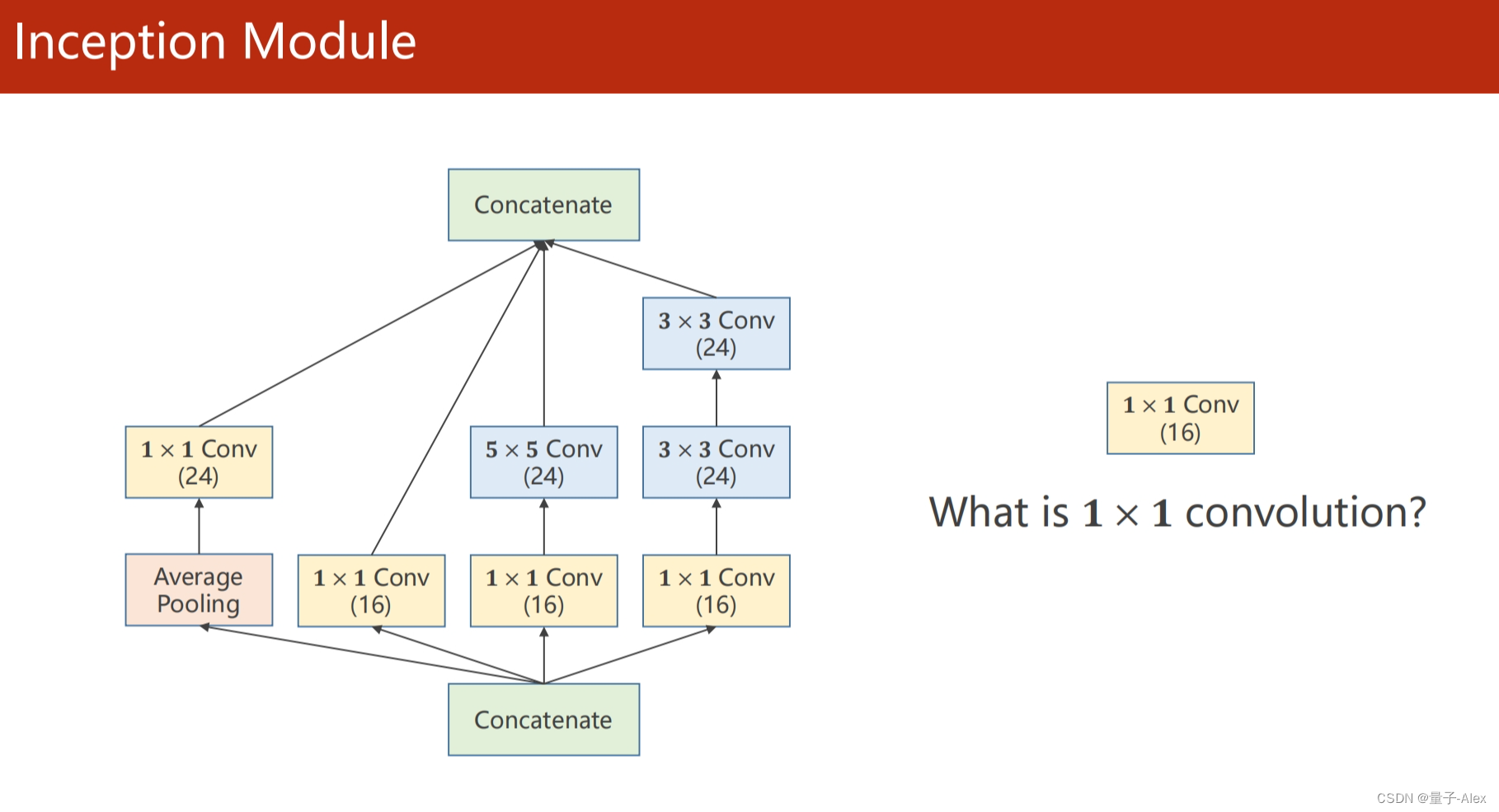
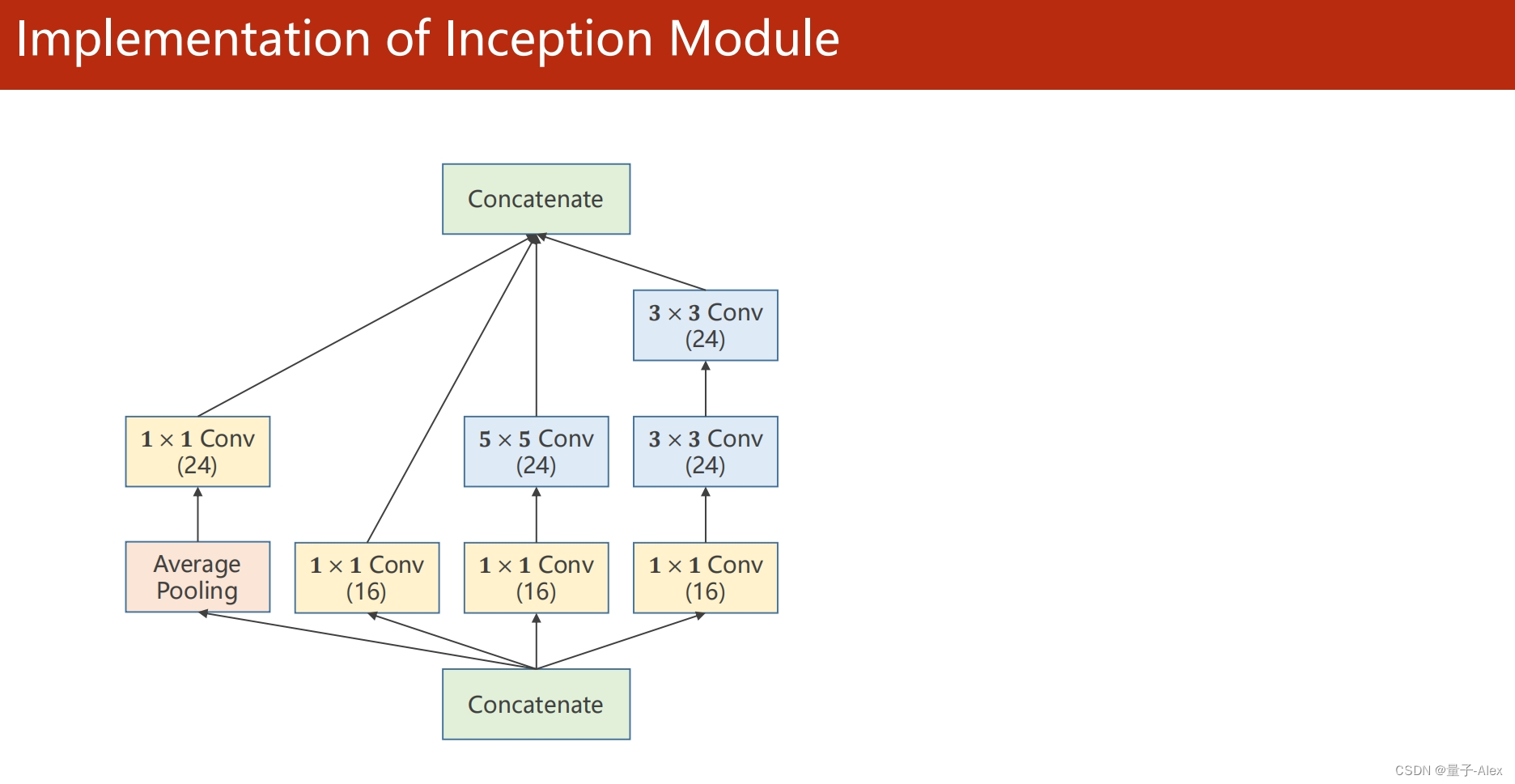
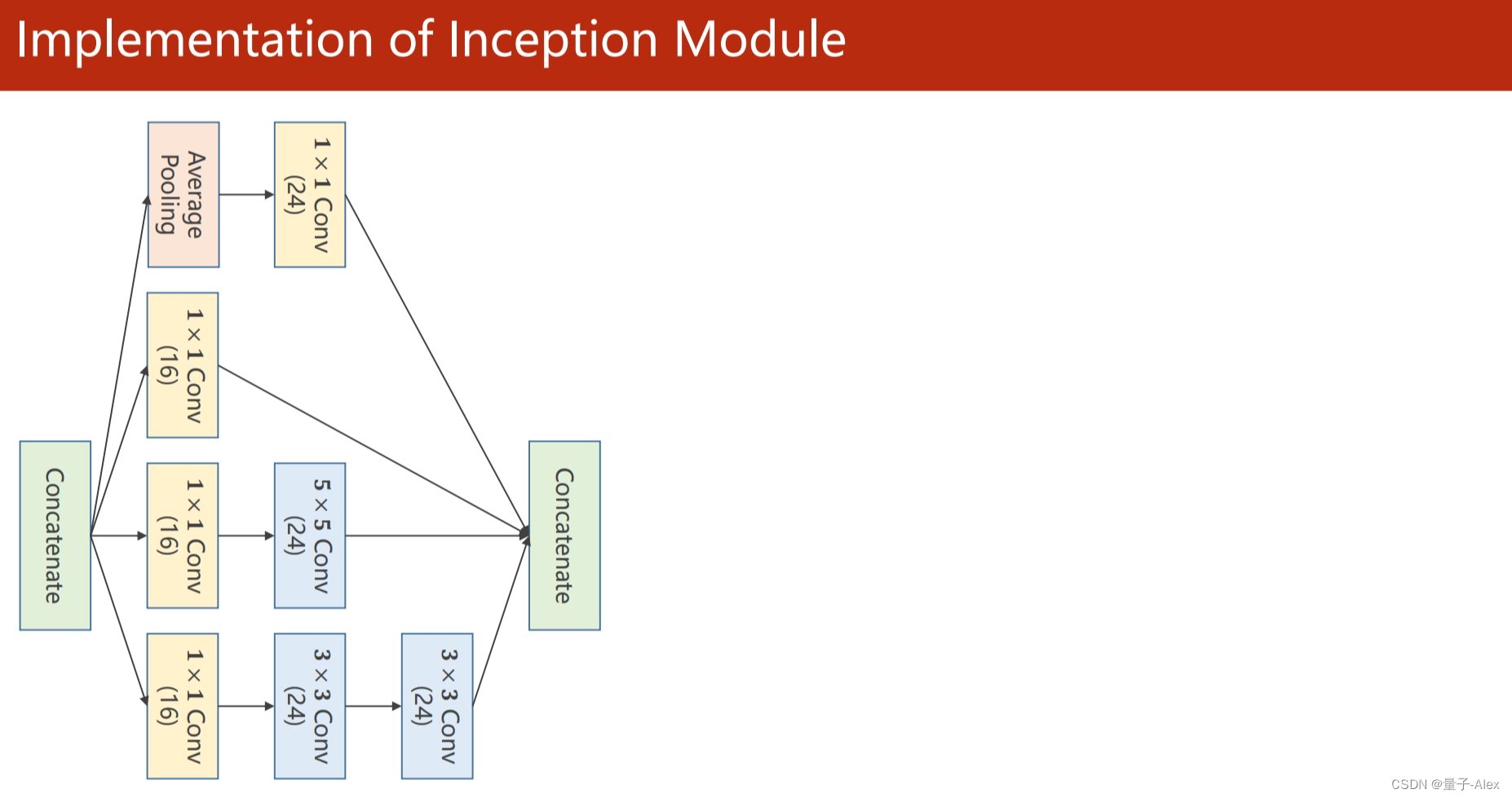
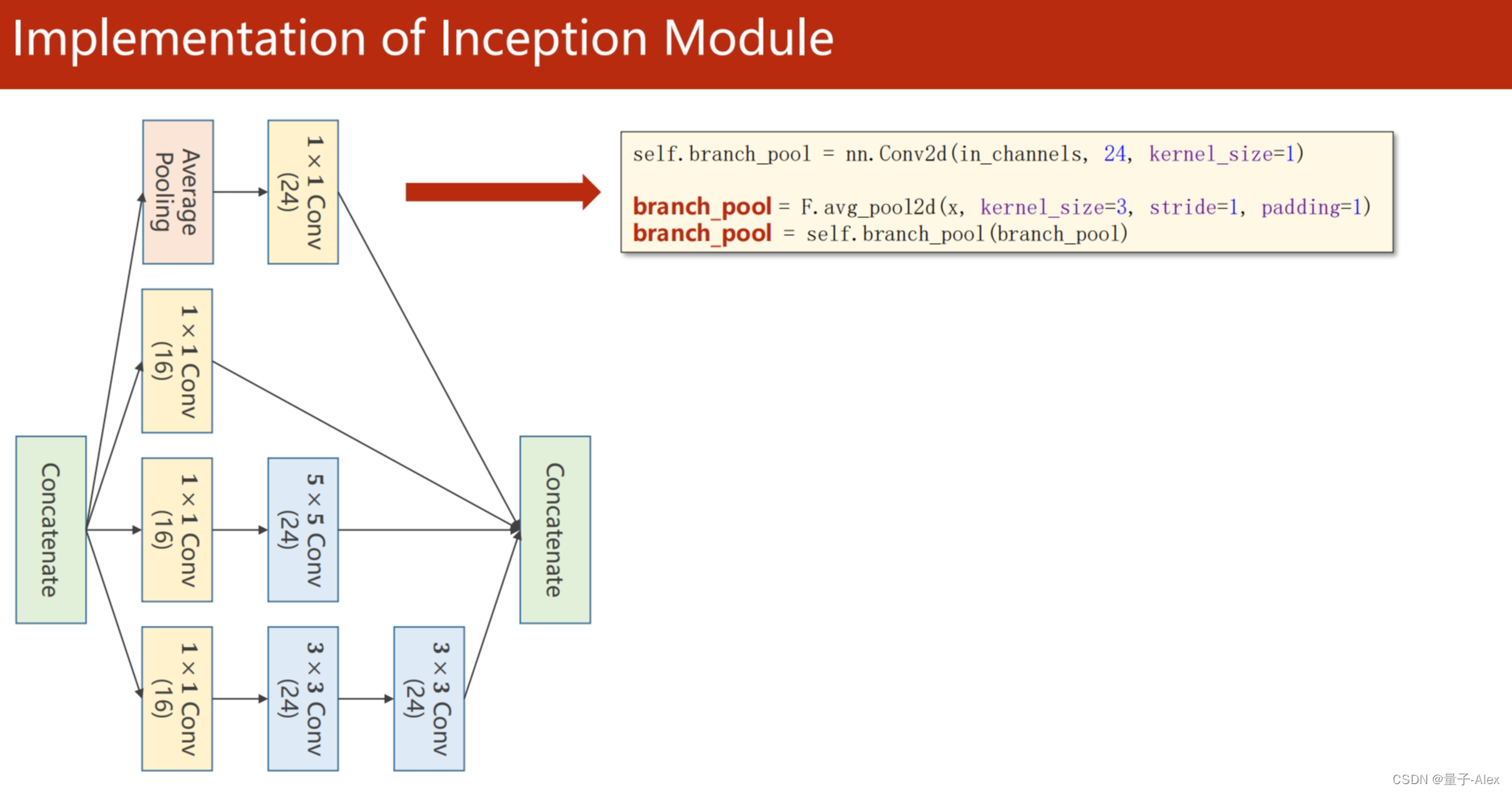
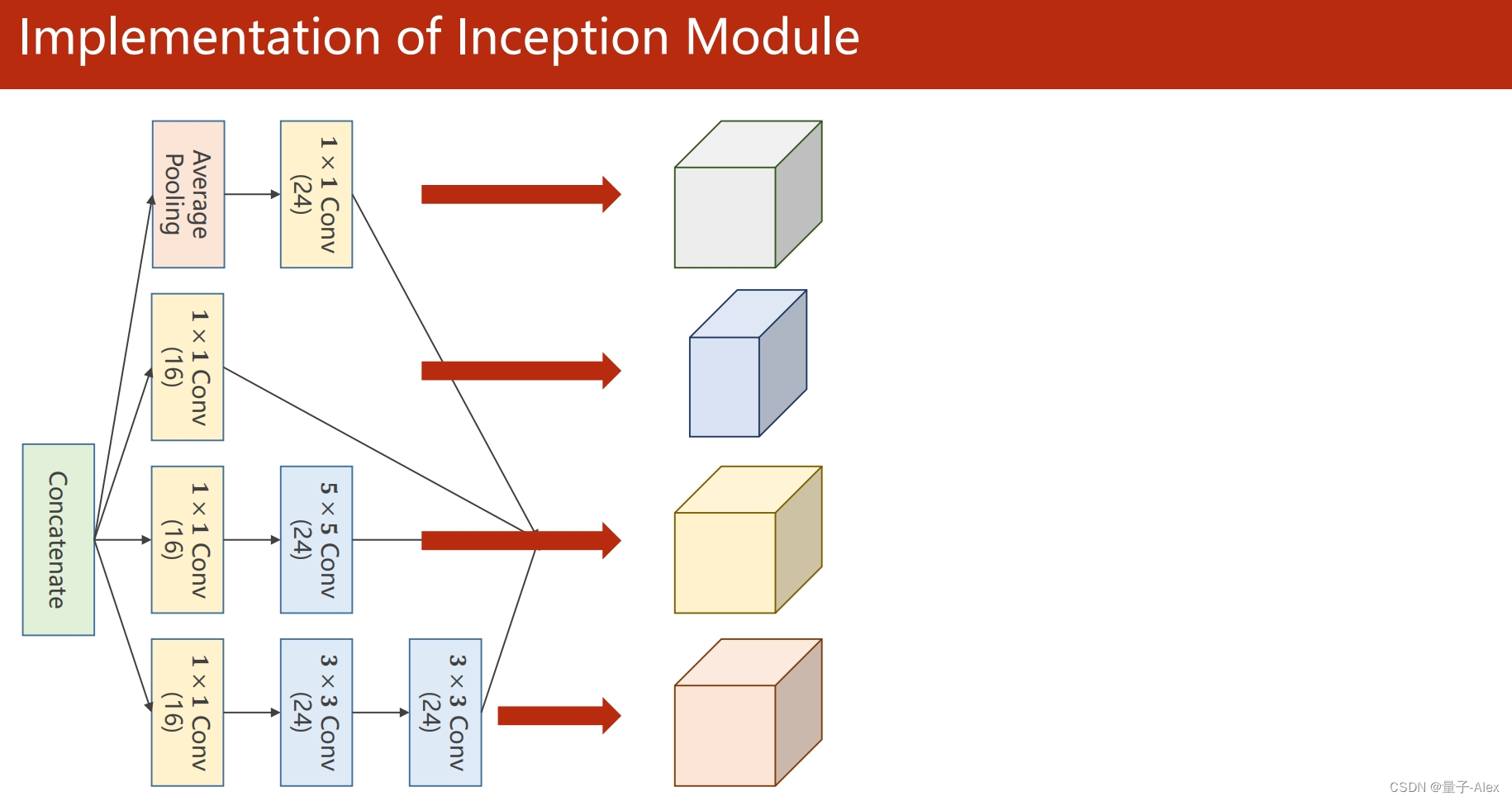
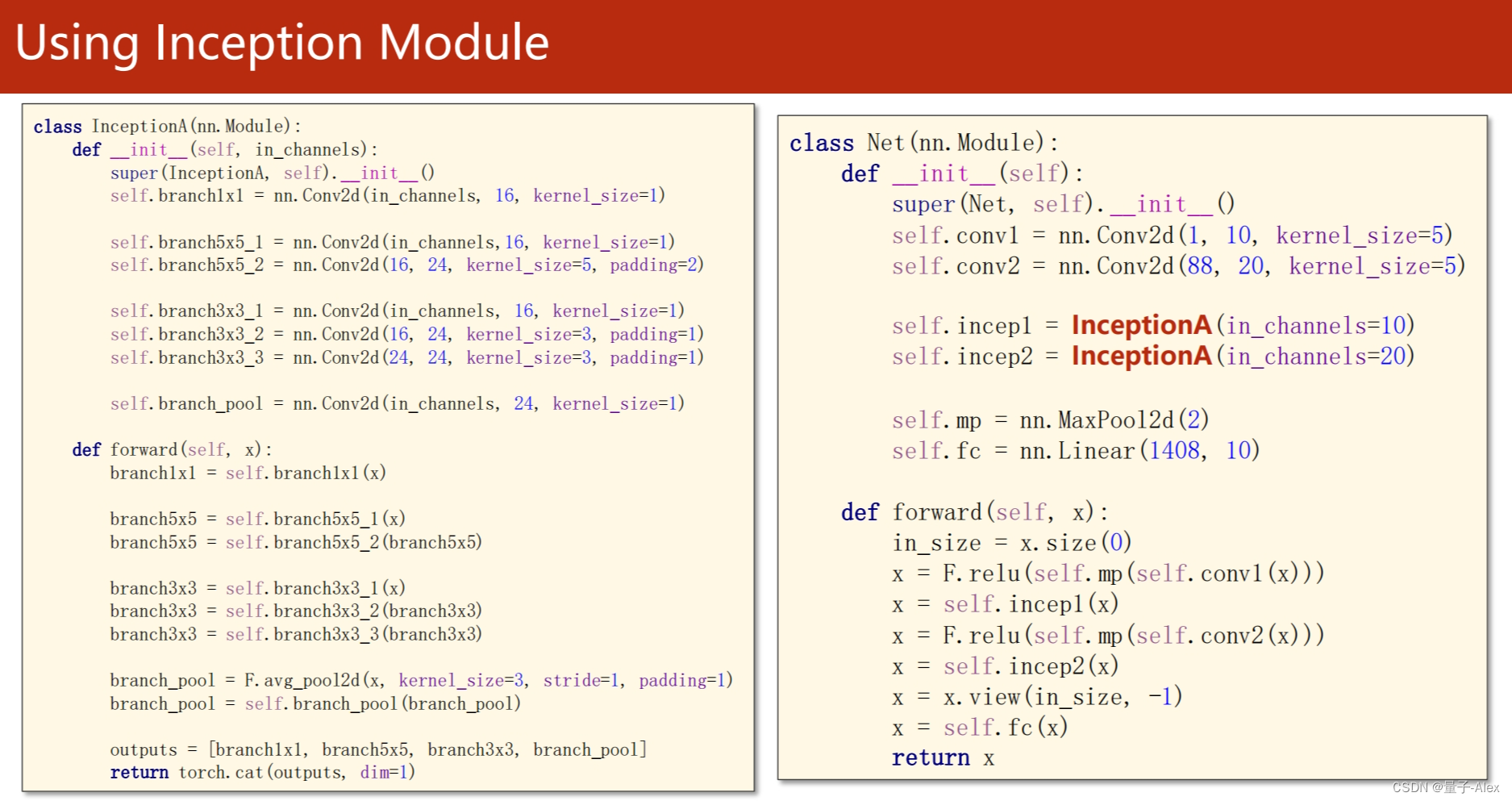
class Inception(torch.nn.Module):
def __init__(self,in_channels):
super(Inception, self).__init__()
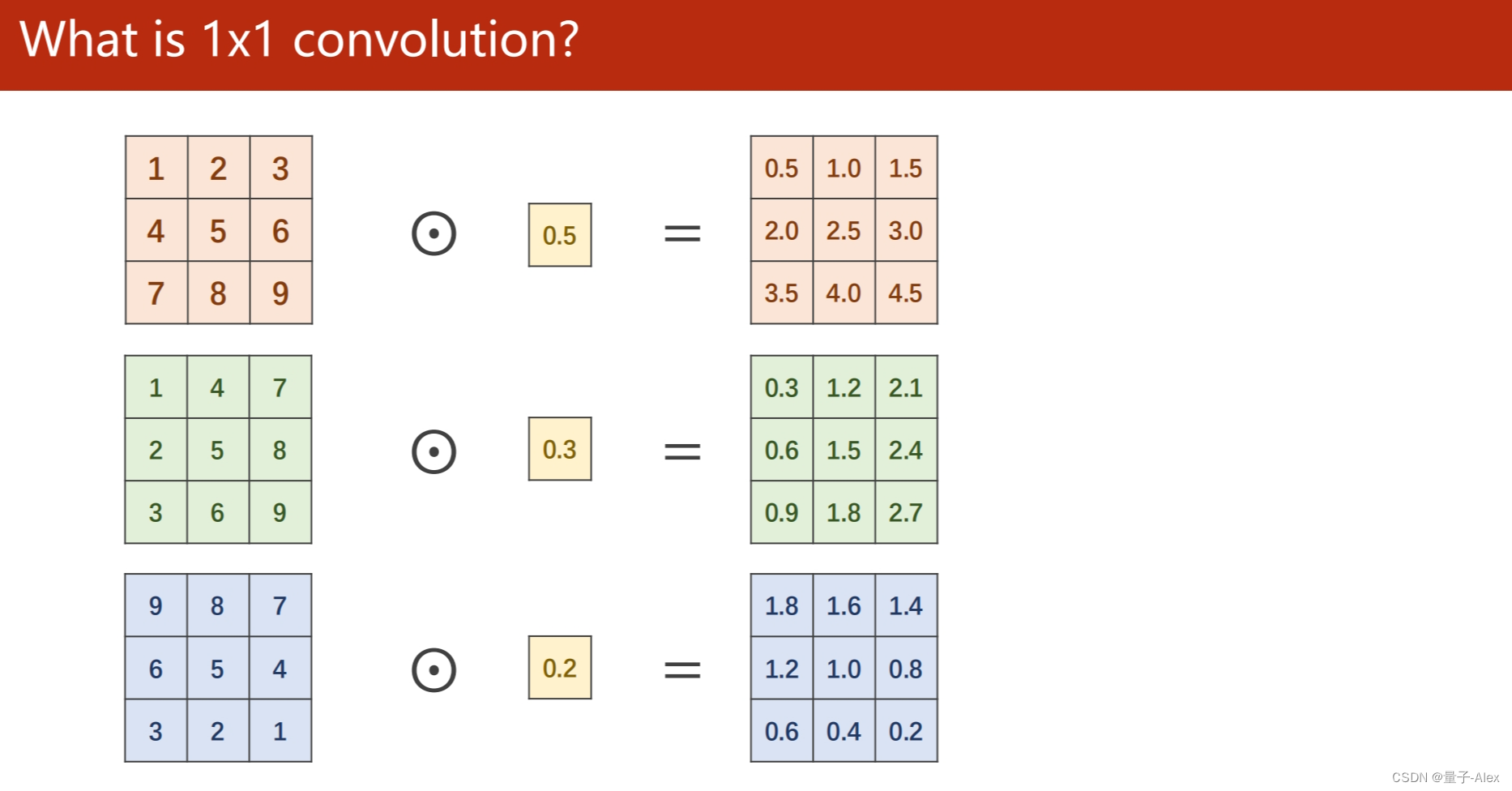
self.branchpool = nn.Conv2d(in_channels, 24, kernel_size=1)
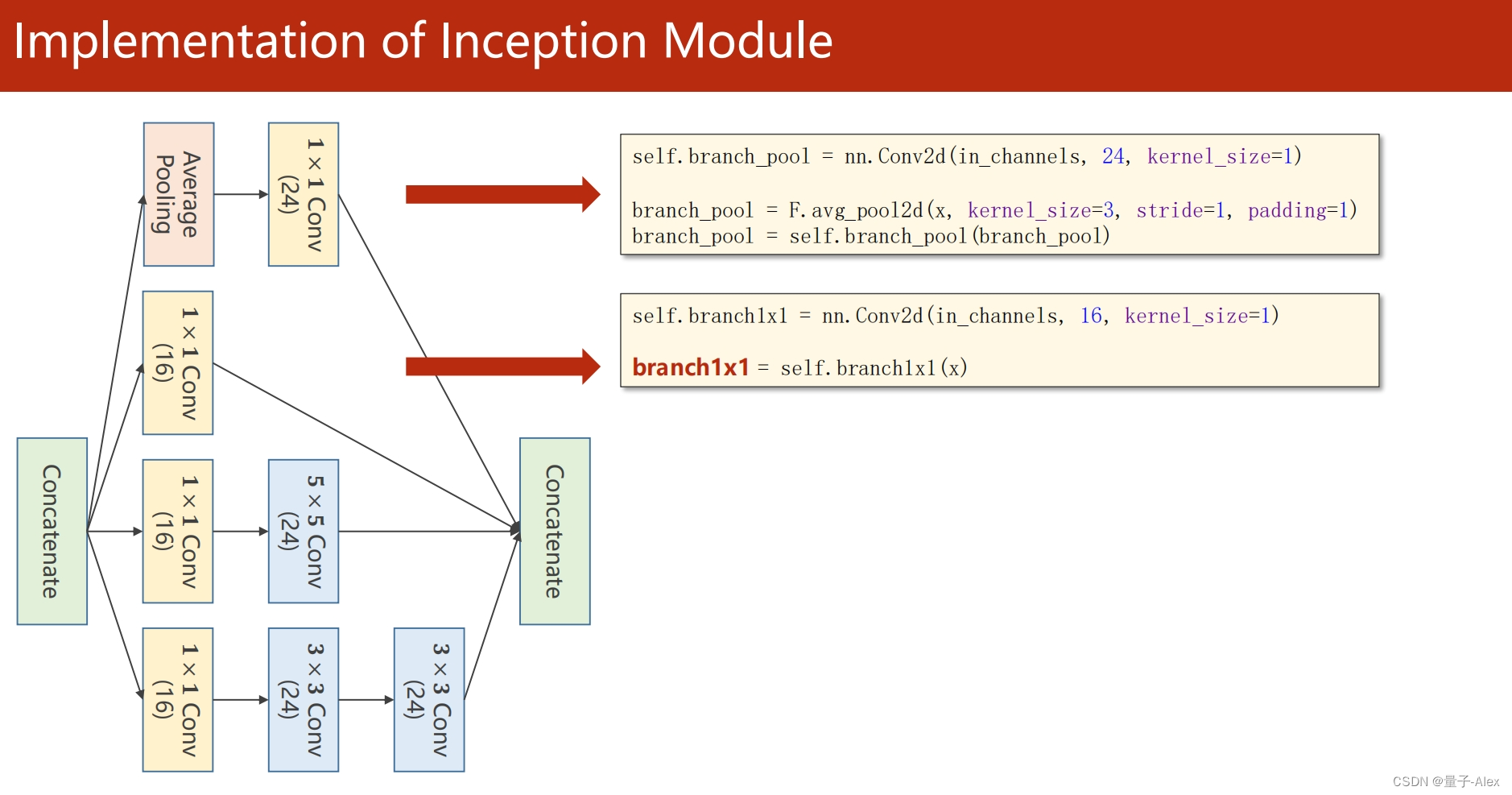
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
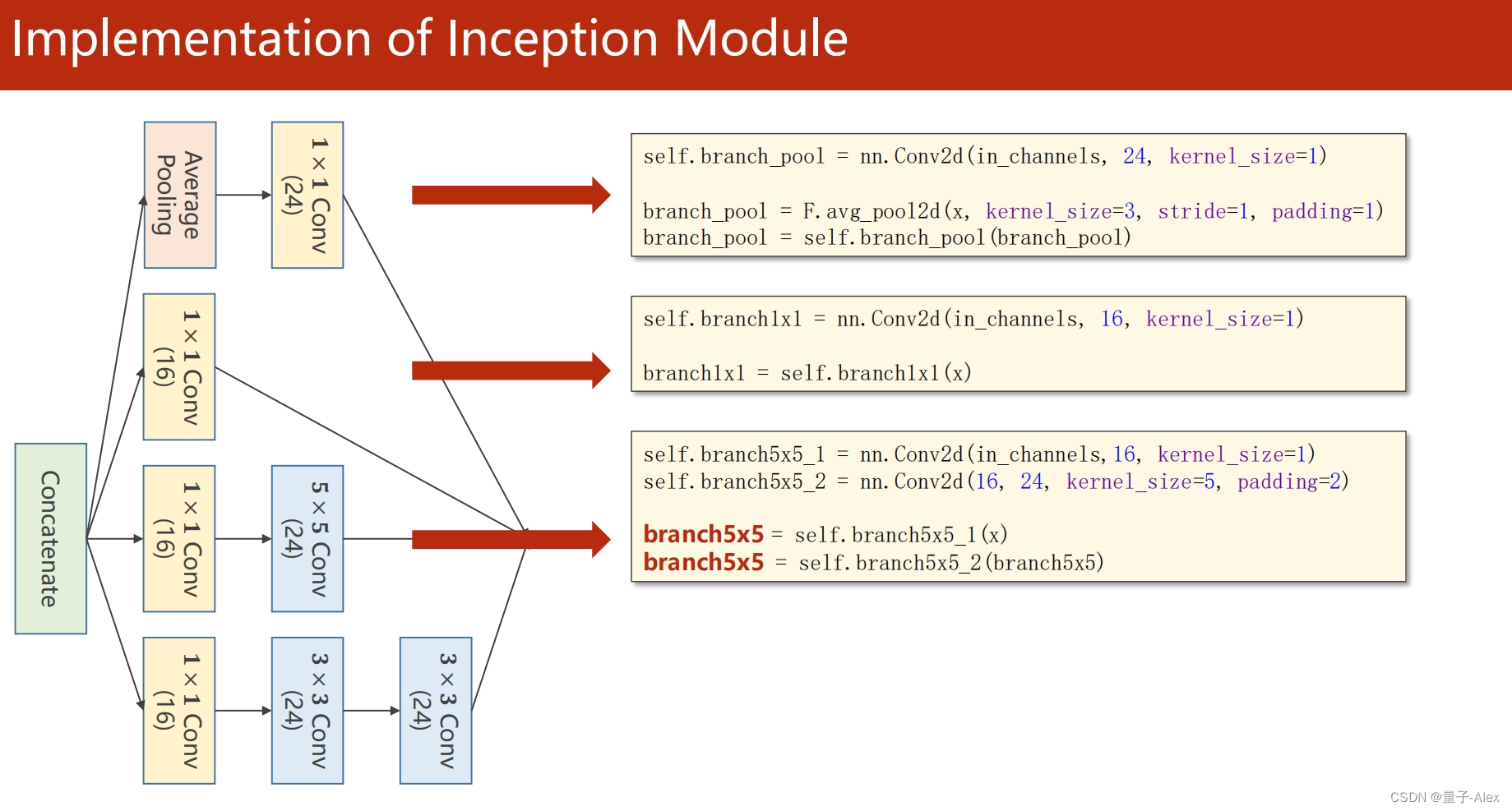
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5,padding=2)
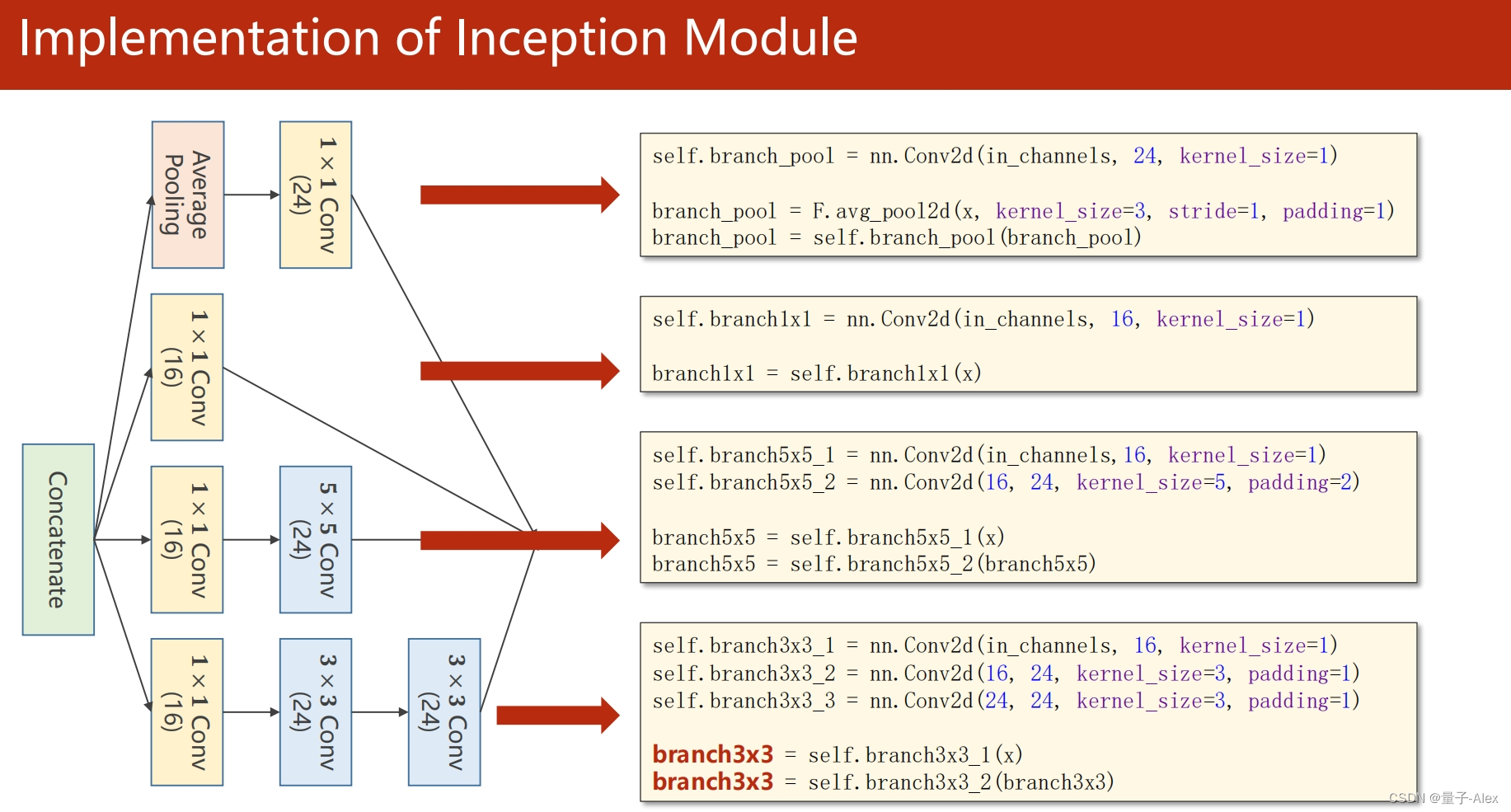
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24,kernel_size=3,padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3,padding=1)
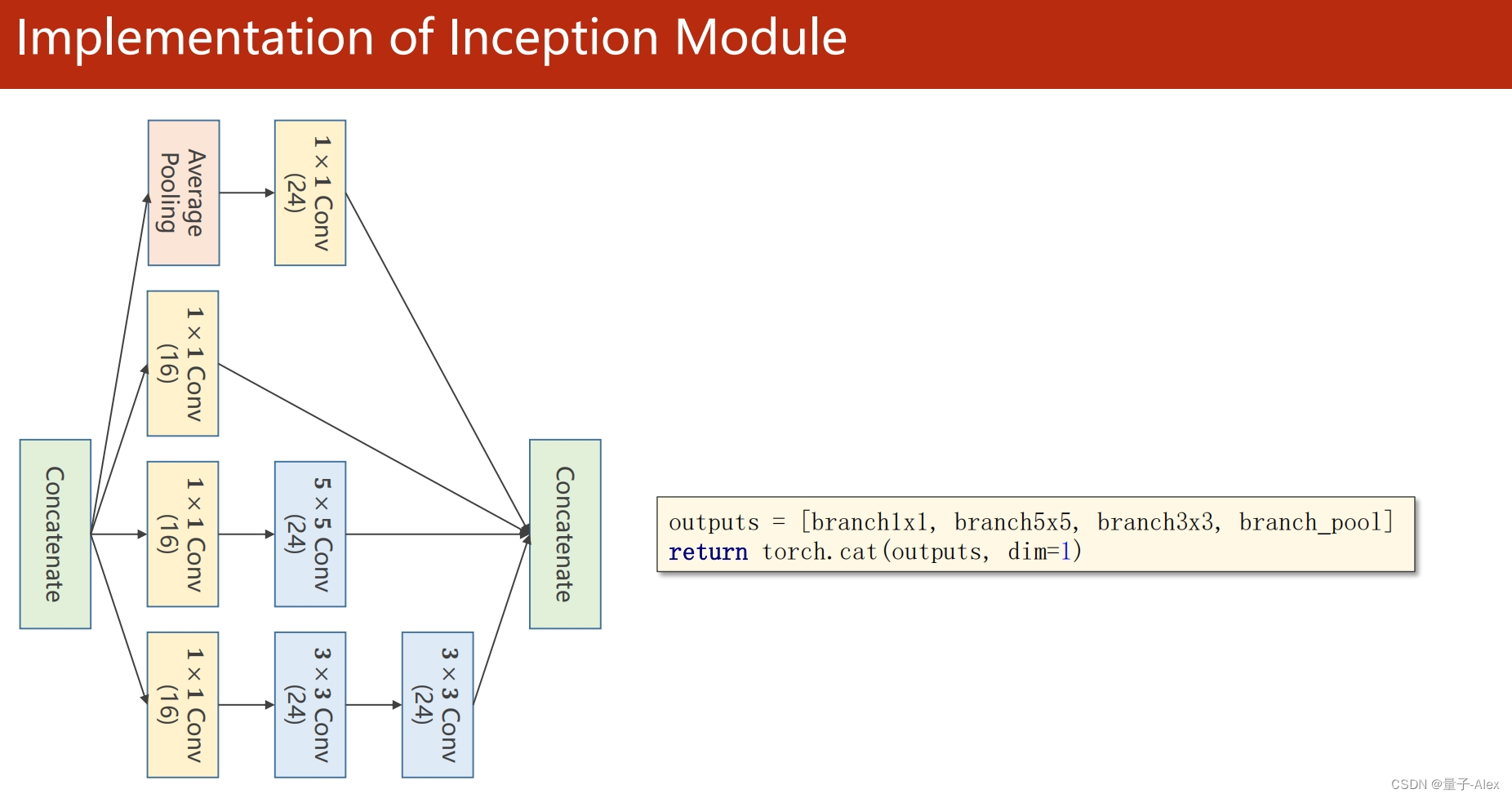
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branchpool = F.avg_pool2d(x, kernel_size=3,stride=1,padding=1)
branchpool = self.branchpool(branchpool)
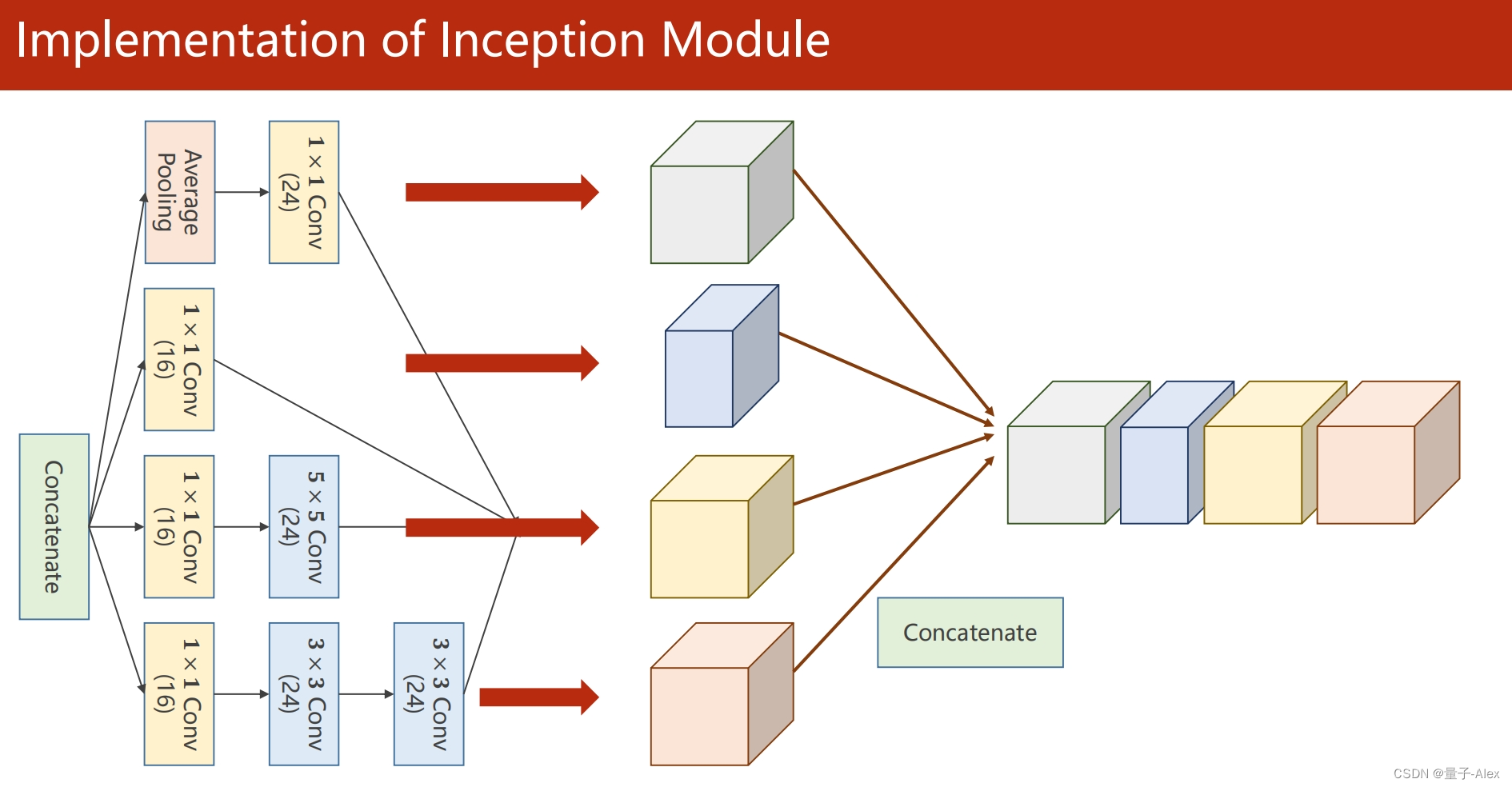
outputs = torch.cat((branch1x1,branch5x5,branch3x3,branchpool),dim=1)
return outputs
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = Inception(10)
self.incep2 = Inception(20)
self.fc = nn.Linear(1408, 10)
self.maxpool = nn.MaxPool2d(kernel_size=2)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.maxpool(self.conv1(x)))
x = self.incep1(x)
x =F.relu(self.maxpool(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #把模型迁移到GPU
model = model.to(device) #把模型迁移到GPU
def train(epoch):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs,labels = inputs.to(device), labels.to(device) #训练内容迁移到GPU上
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 300 == 299: # print every 300 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 300))
running_loss = 0.0
def test(epoch):
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images,labels = images.to(device), labels.to(device) #测试内容迁移到GPU上
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
if __name__ == '__main__':
for epoch in range(100):
train(epoch)
if epoch % 10 == 0:
test(epoch)
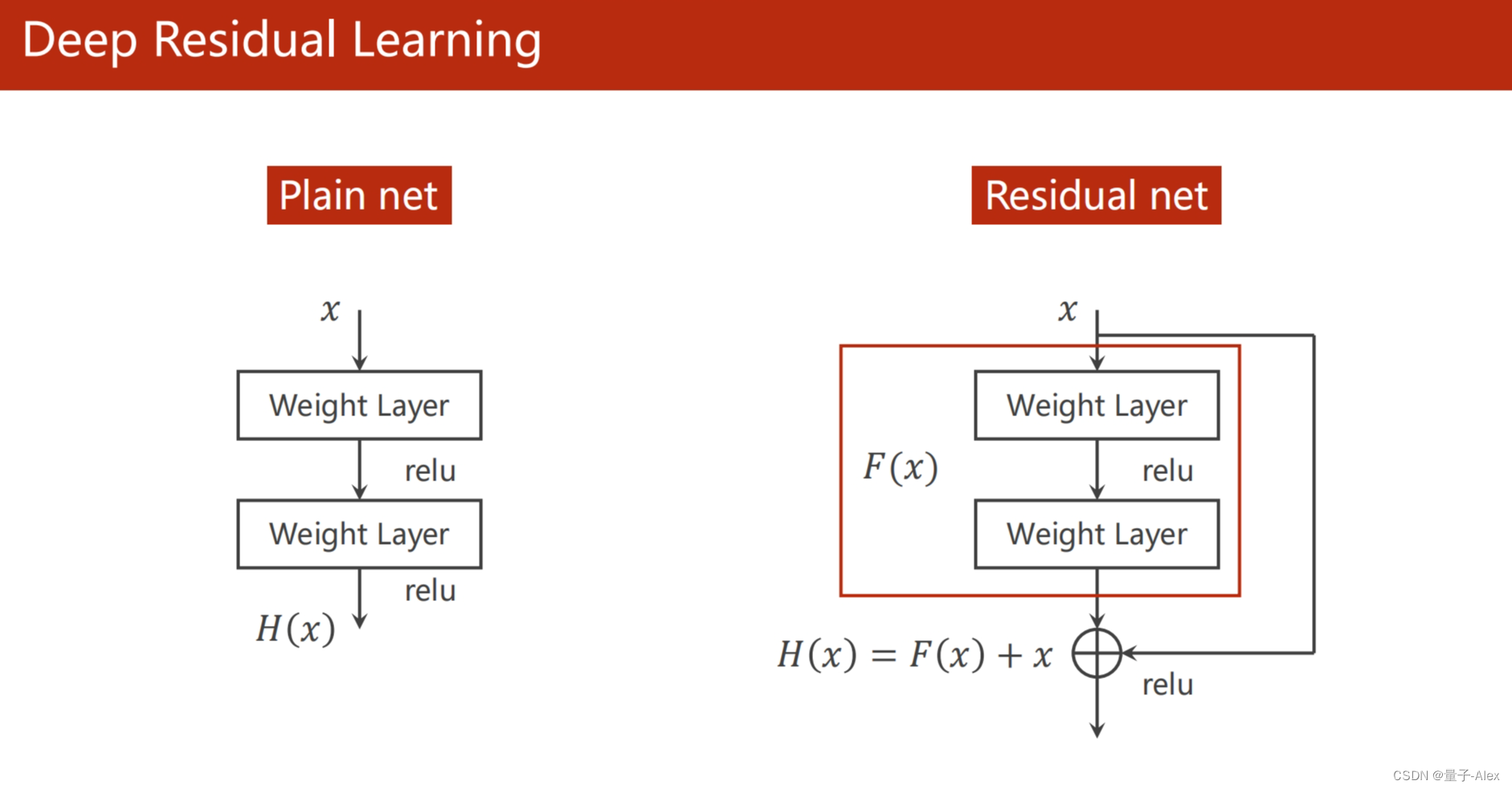
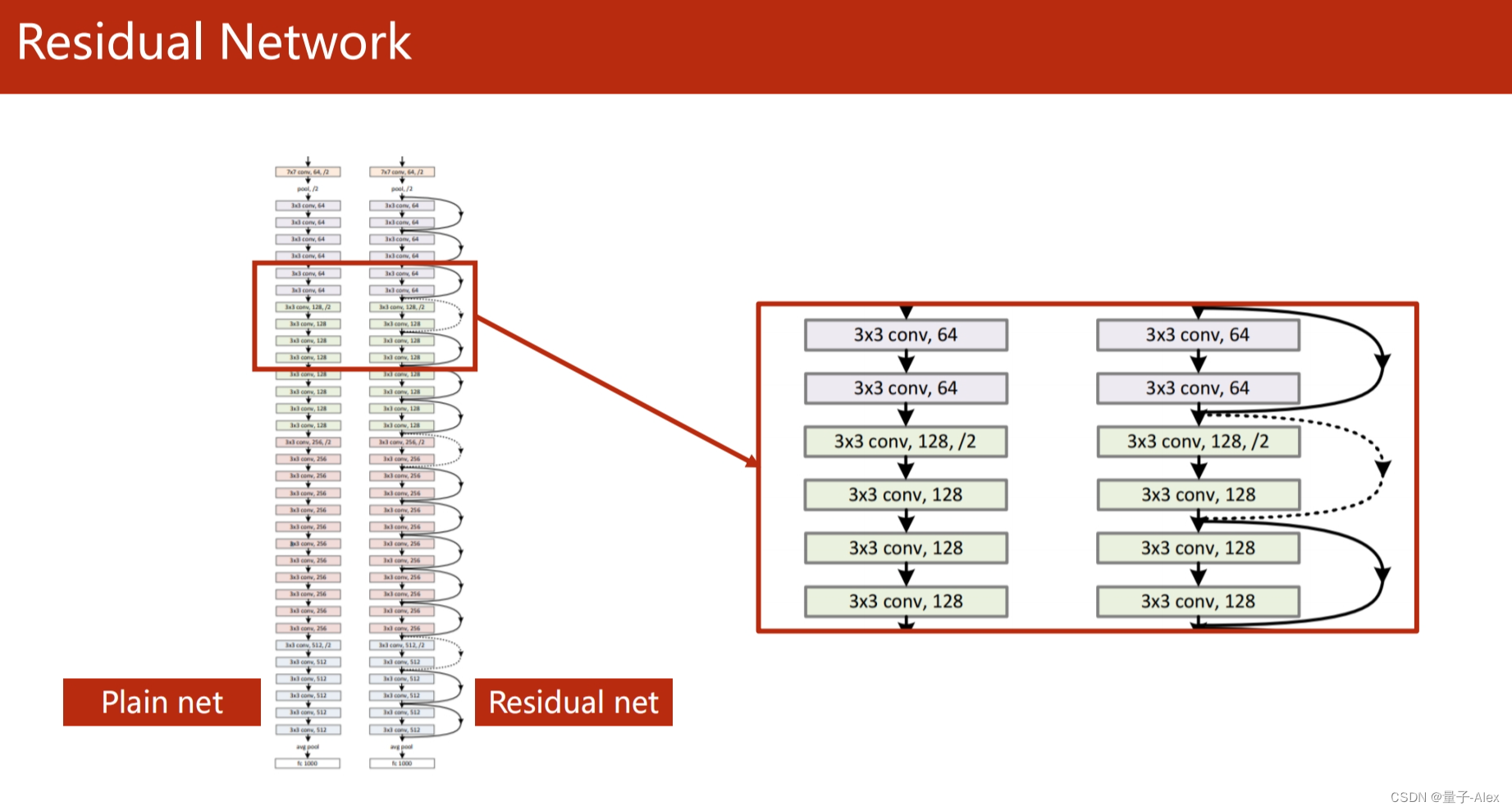
Pytorch实现ResNet
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) #把原始图像转为tensor 这是均值和方差
train_set = datasets.MNIST(root='./data/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_set = datasets.MNIST(root='./data/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=True)
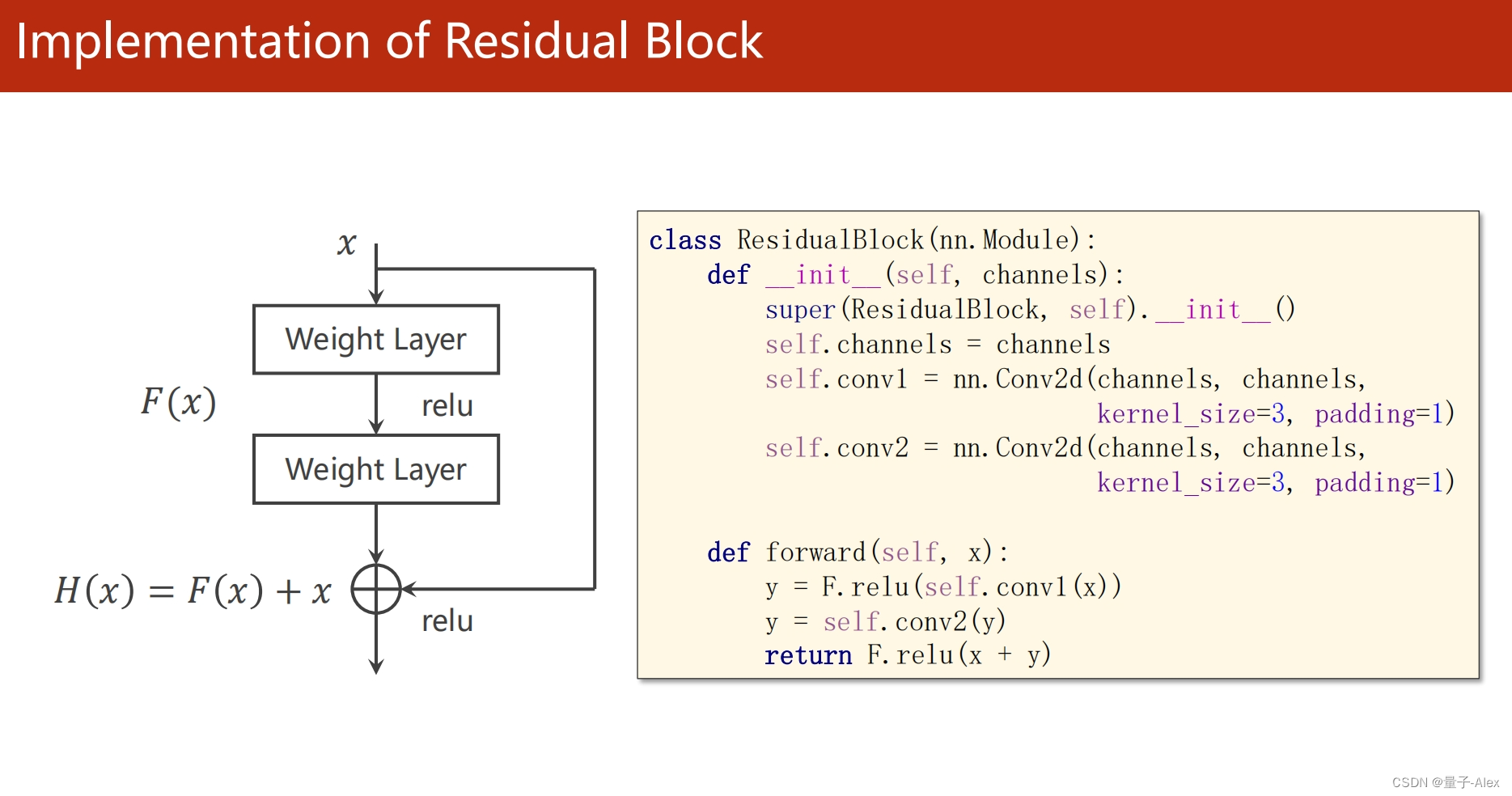
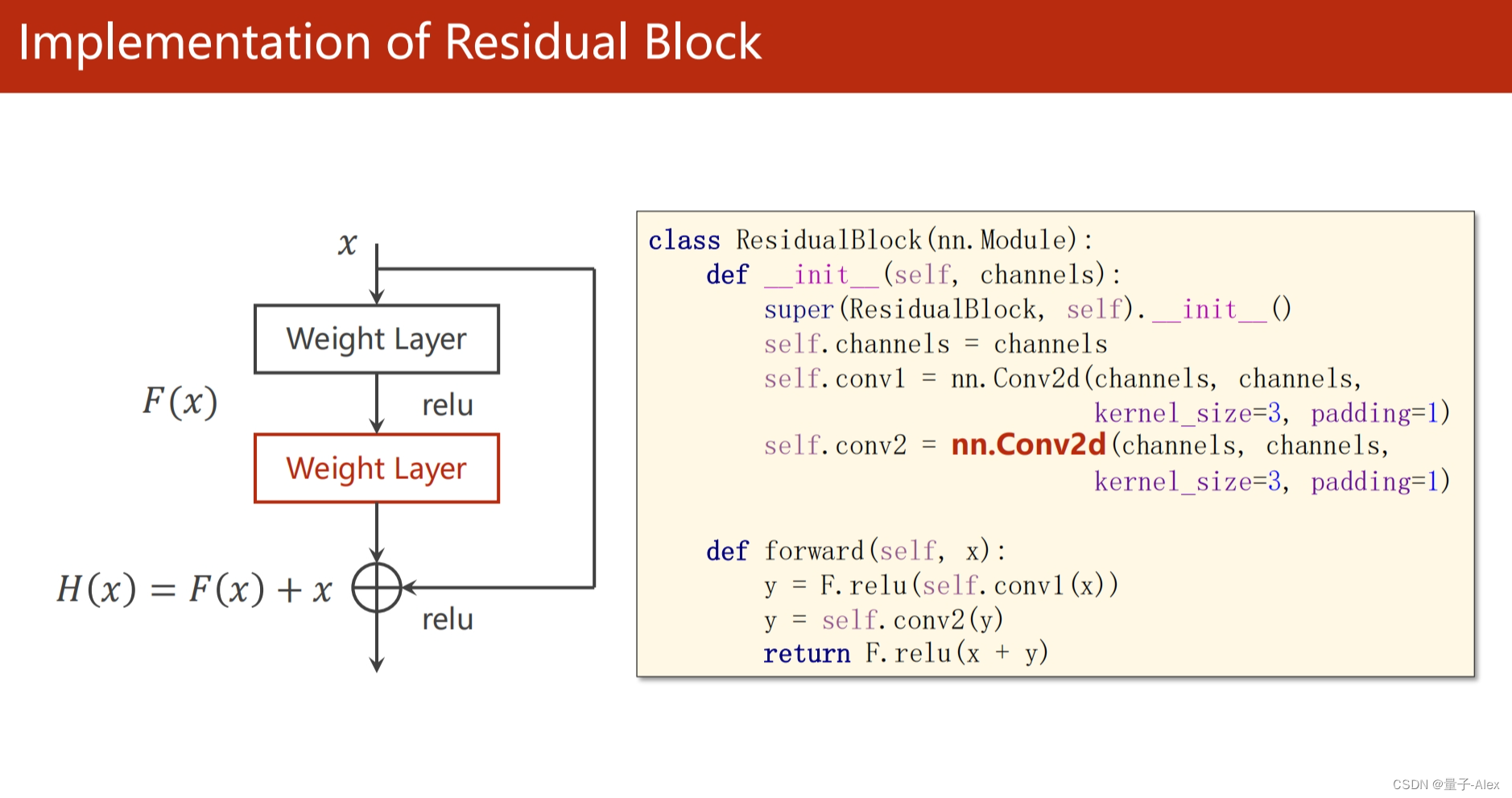
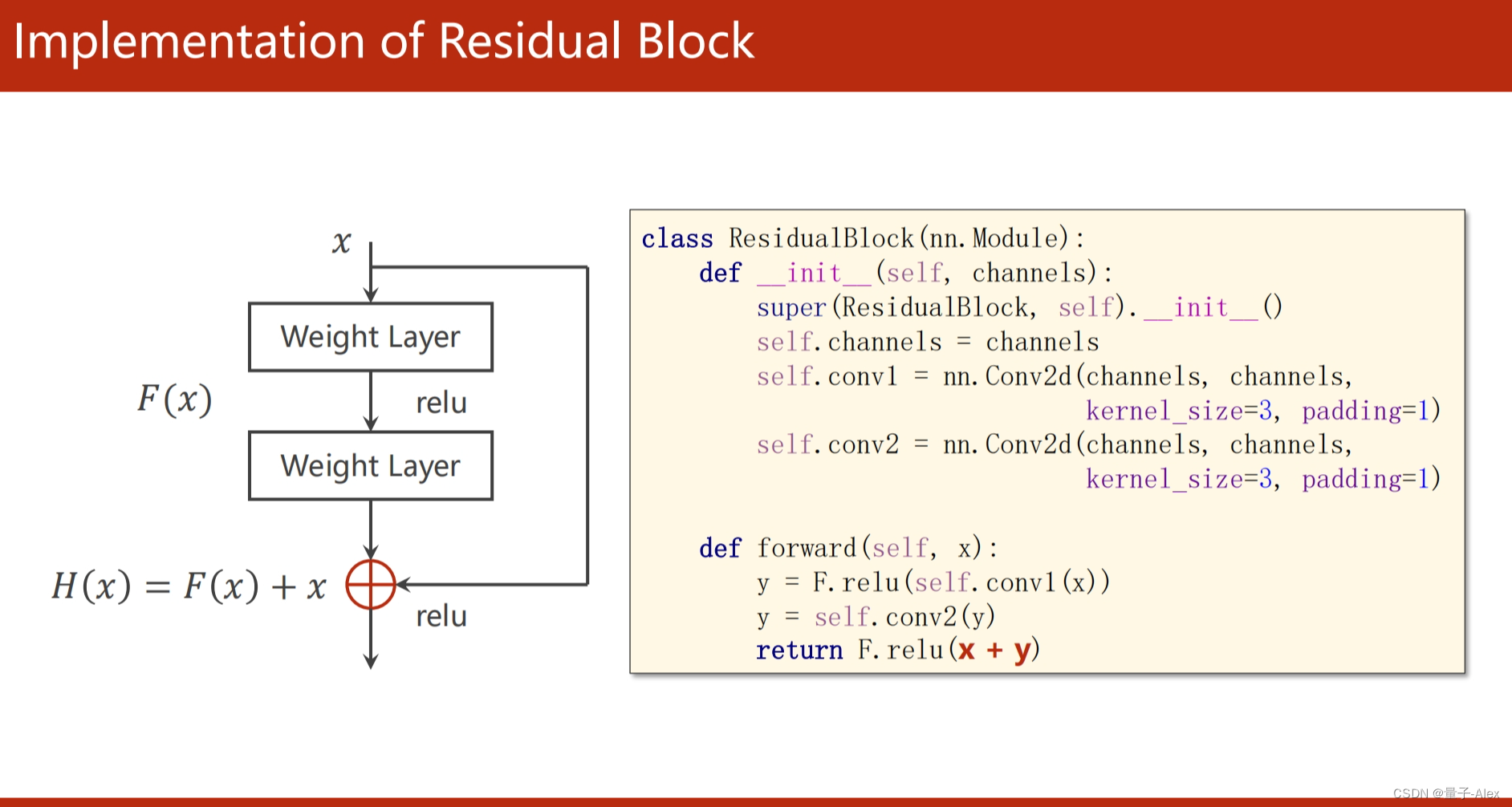
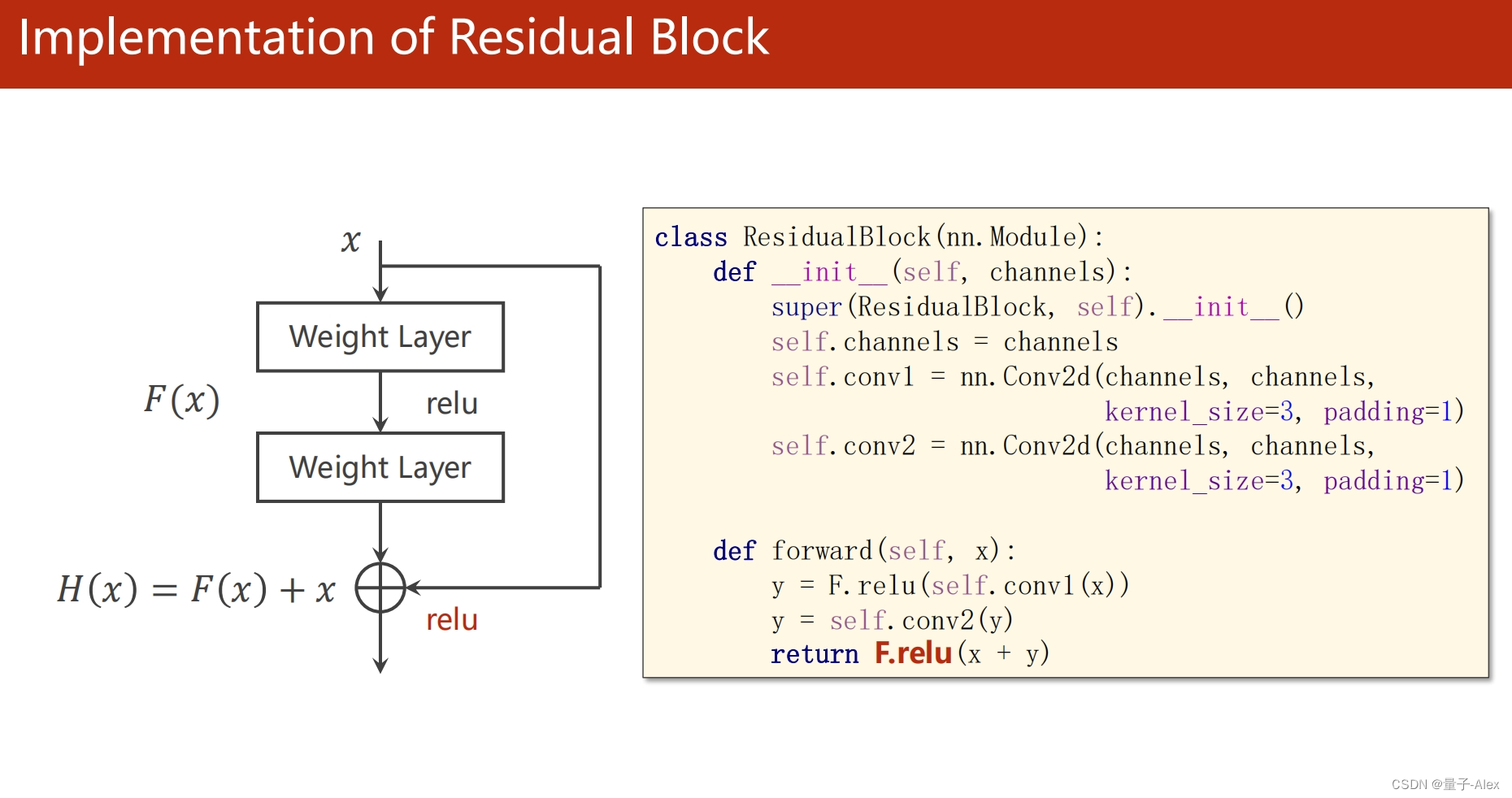
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
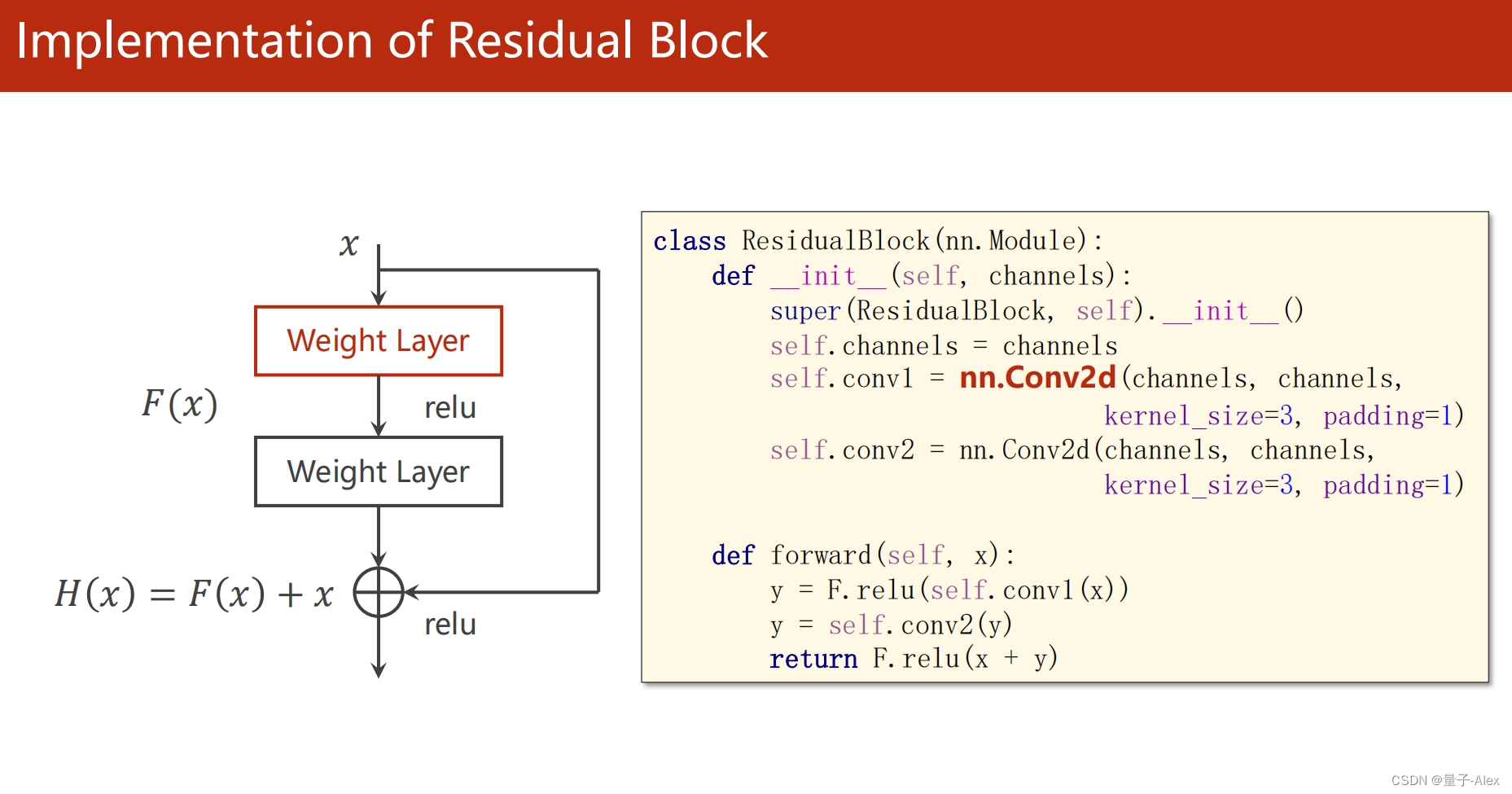
self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=3,padding=1)
def forward(self, x):
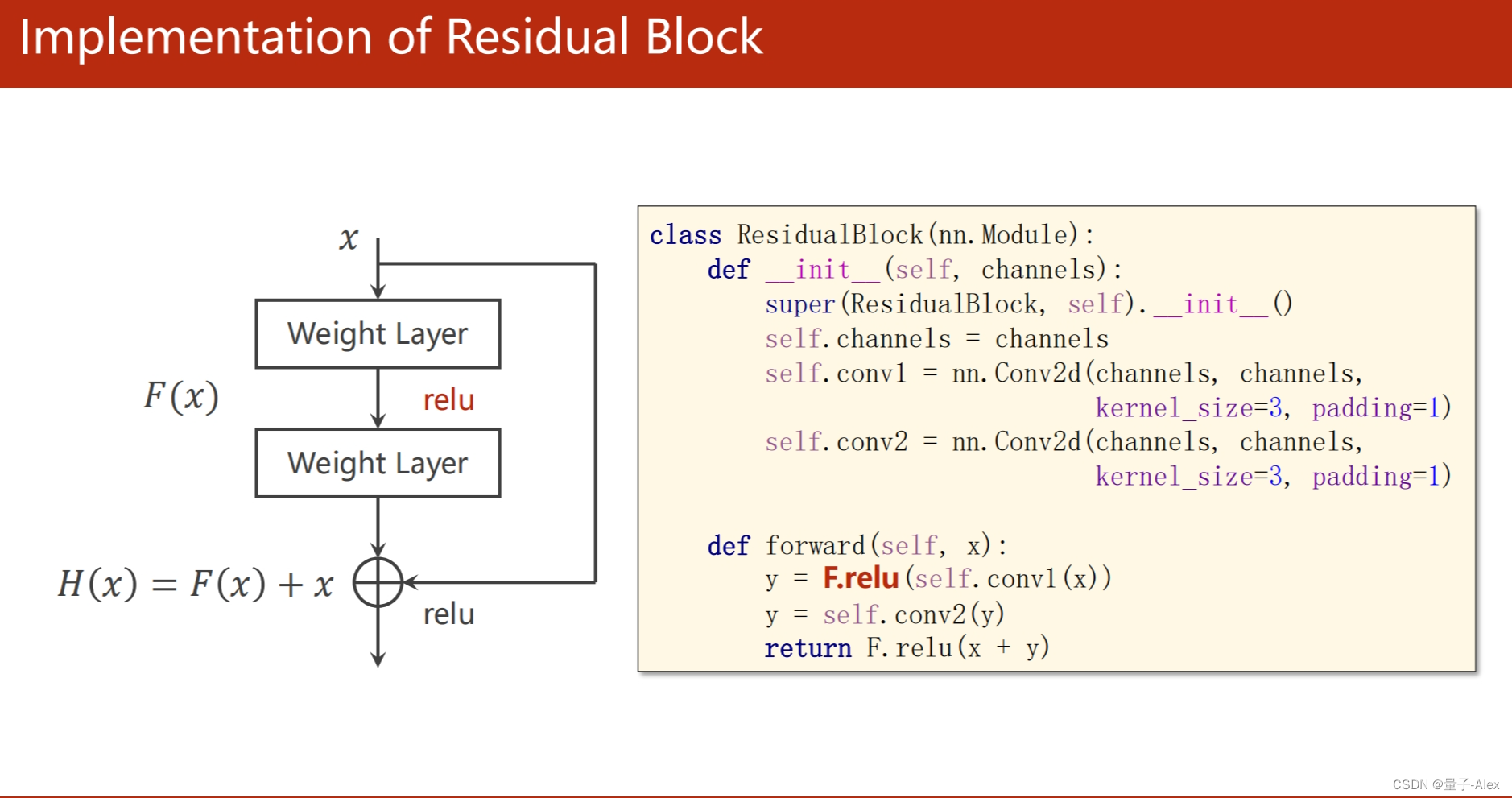
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.maxpool = nn.MaxPool2d(kernel_size=2)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.maxpool(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.maxpool(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') #把模型迁移到GPU
model = model.to(device) #把模型迁移到GPU
def train(epoch):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs,labels = inputs.to(device), labels.to(device) #训练内容迁移到GPU上
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 300 == 299: # print every 300 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 300))
running_loss = 0.0
def test(epoch):
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images,labels = images.to(device), labels.to(device) #测试内容迁移到GPU上
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
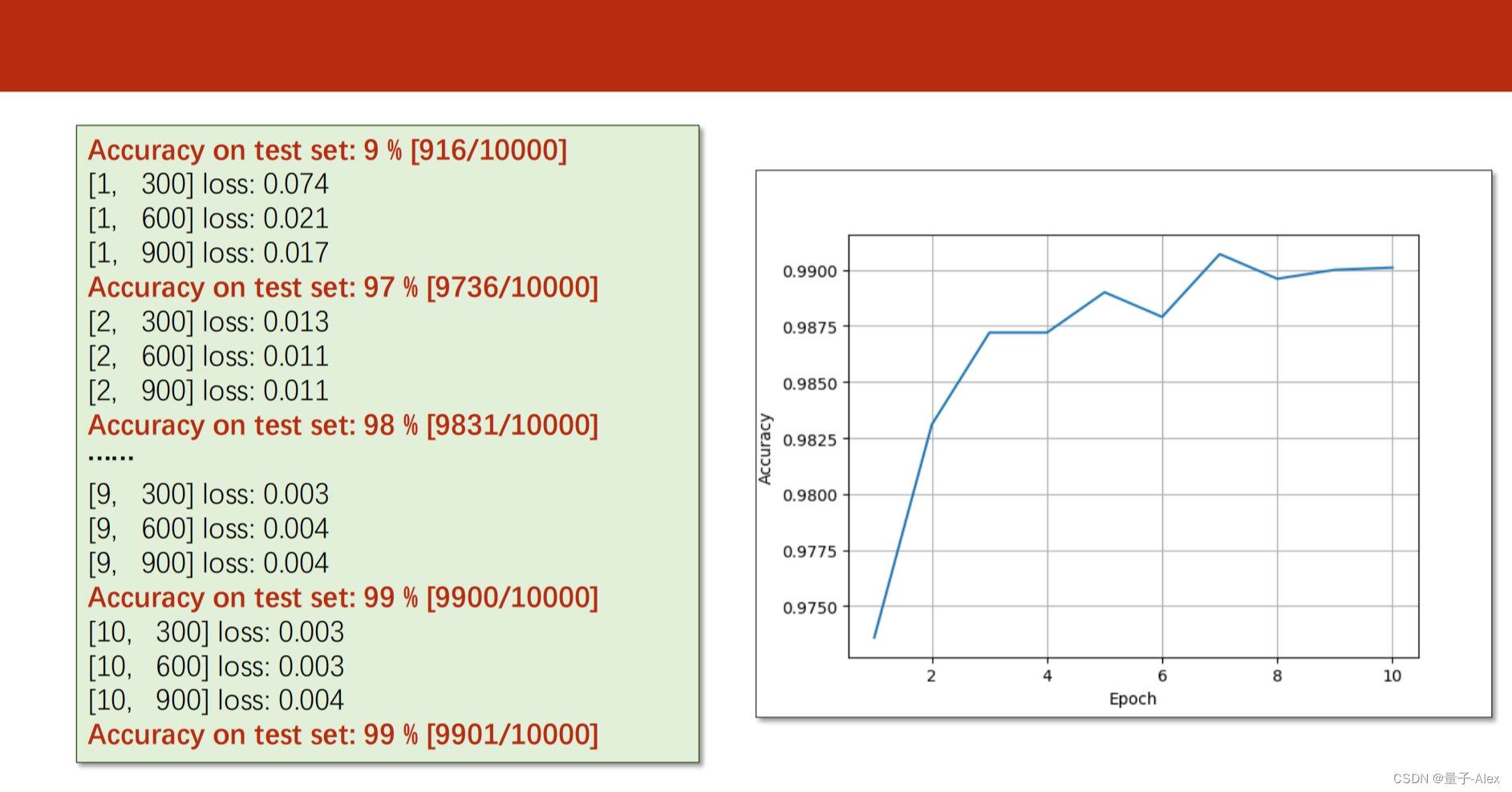
if __name__ == '__main__':
for epoch in range(100):
train(epoch)
if epoch % 10 == 0:
test(epoch)
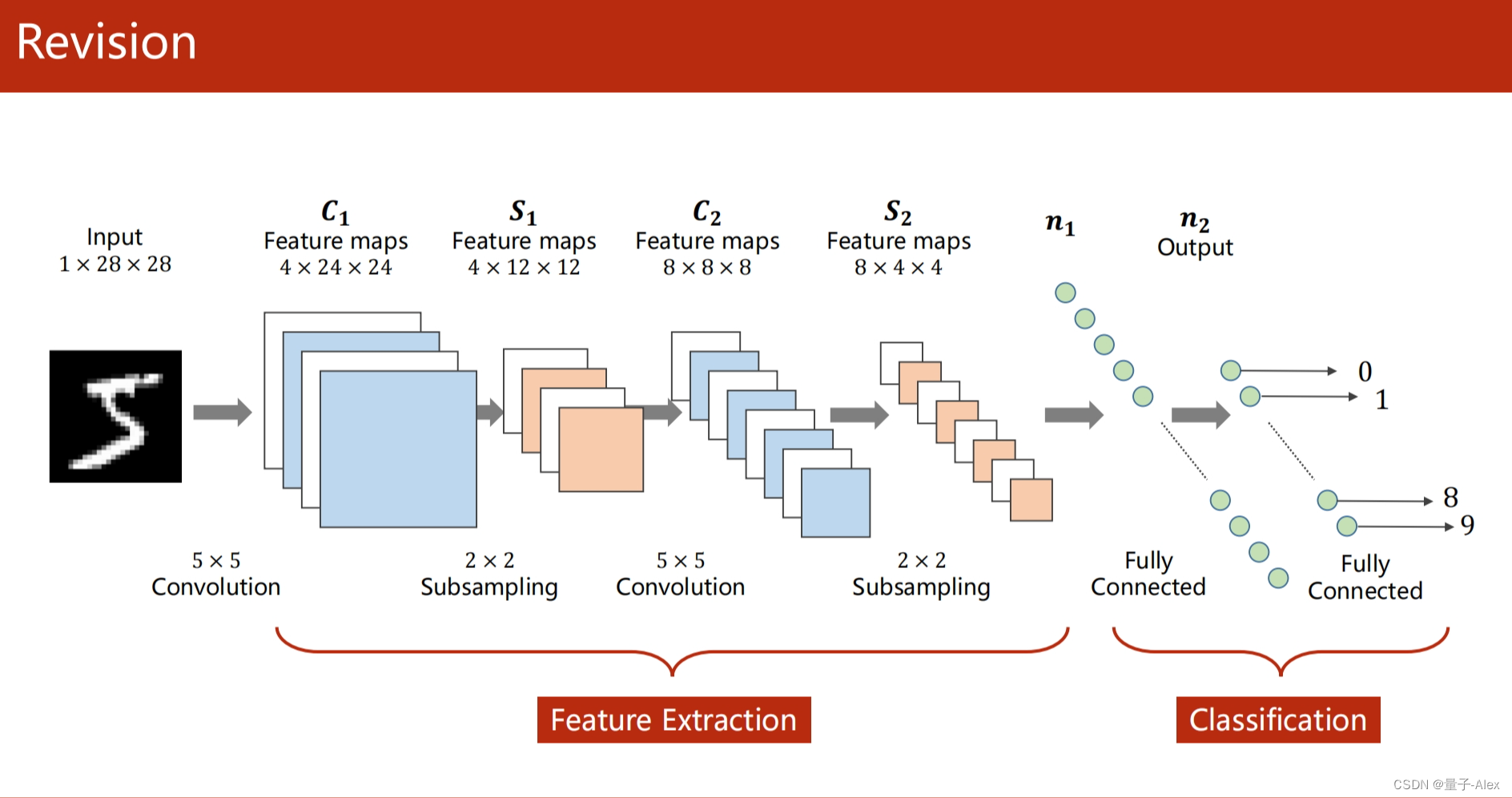
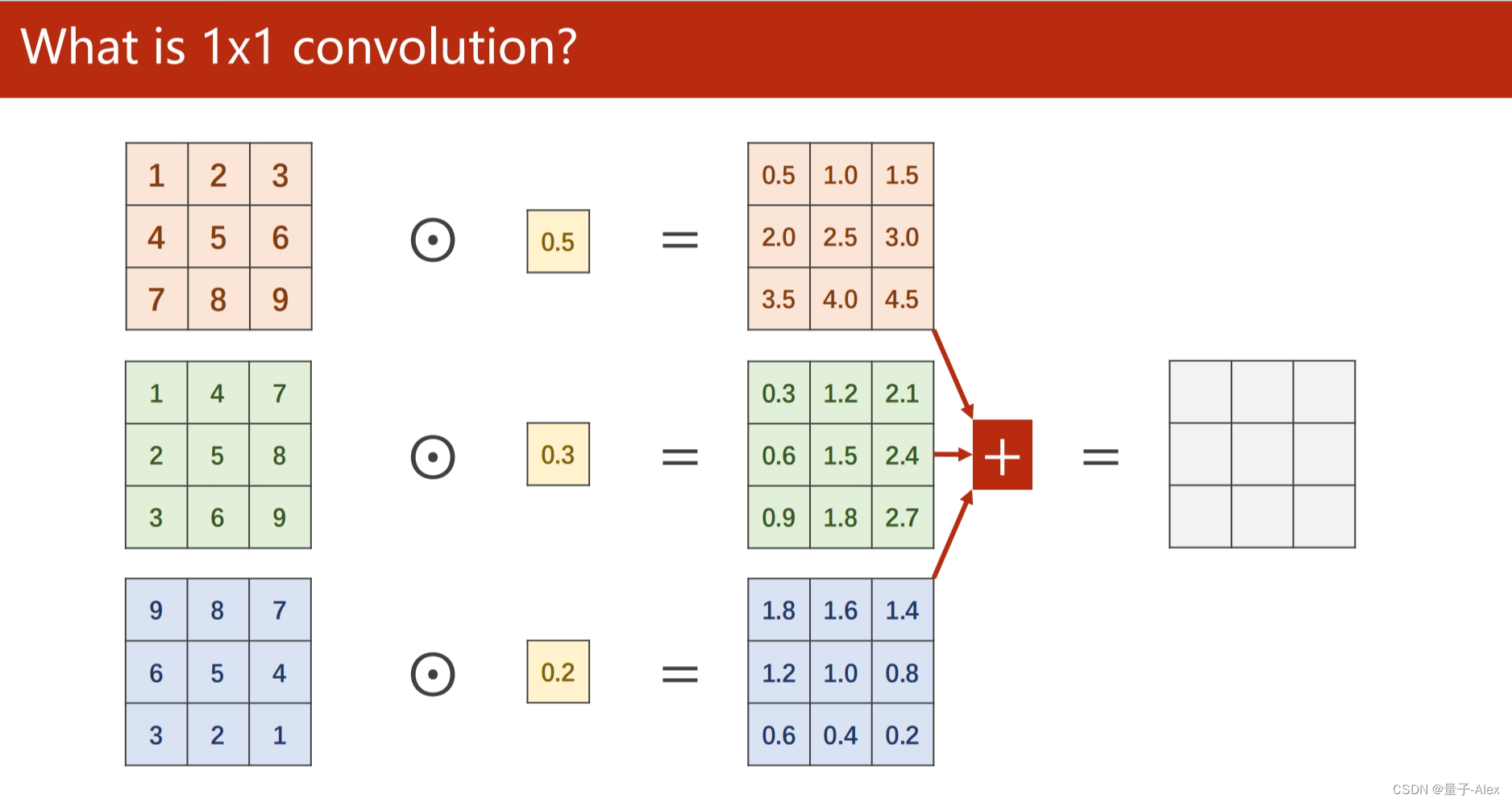
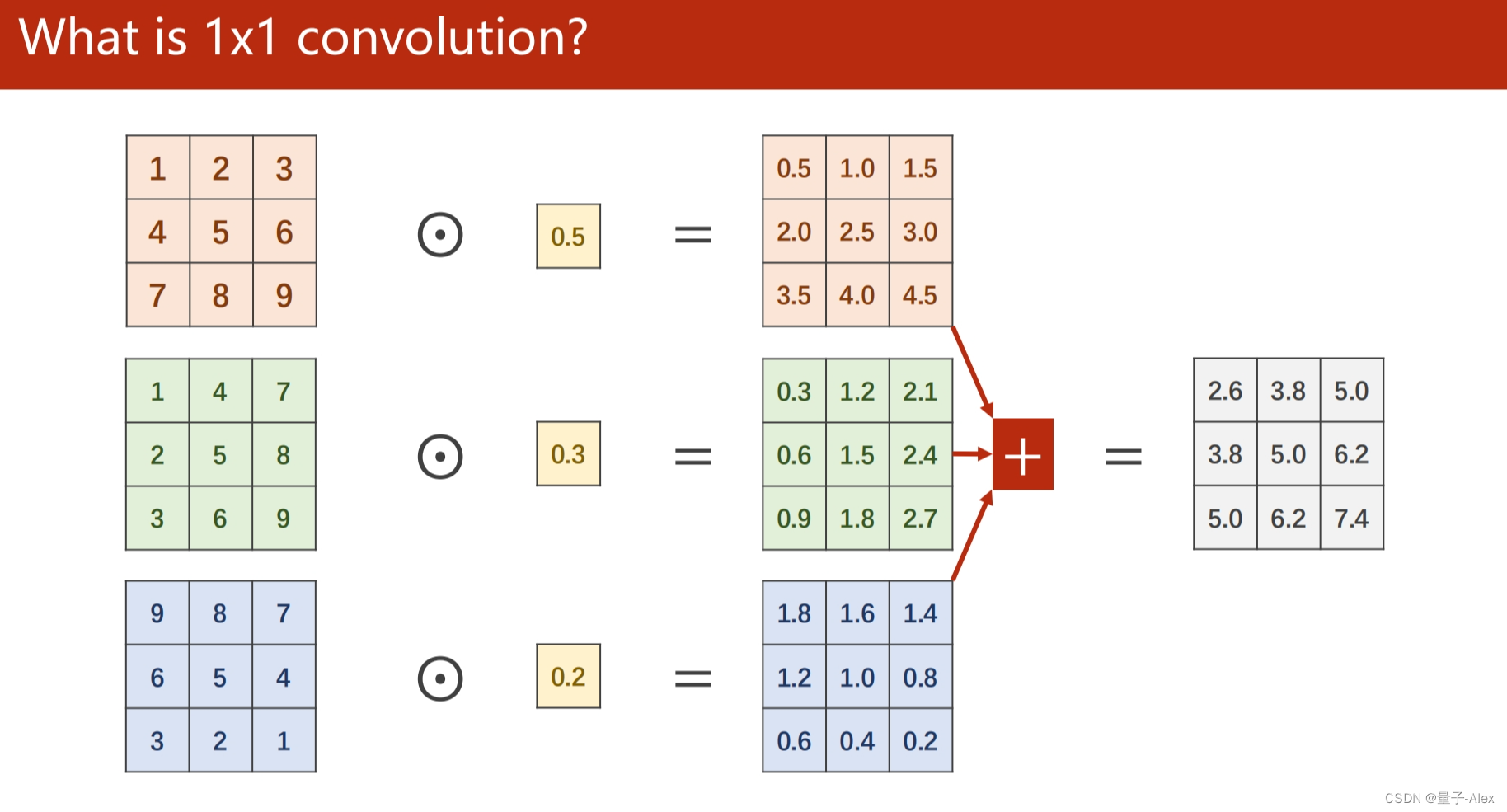
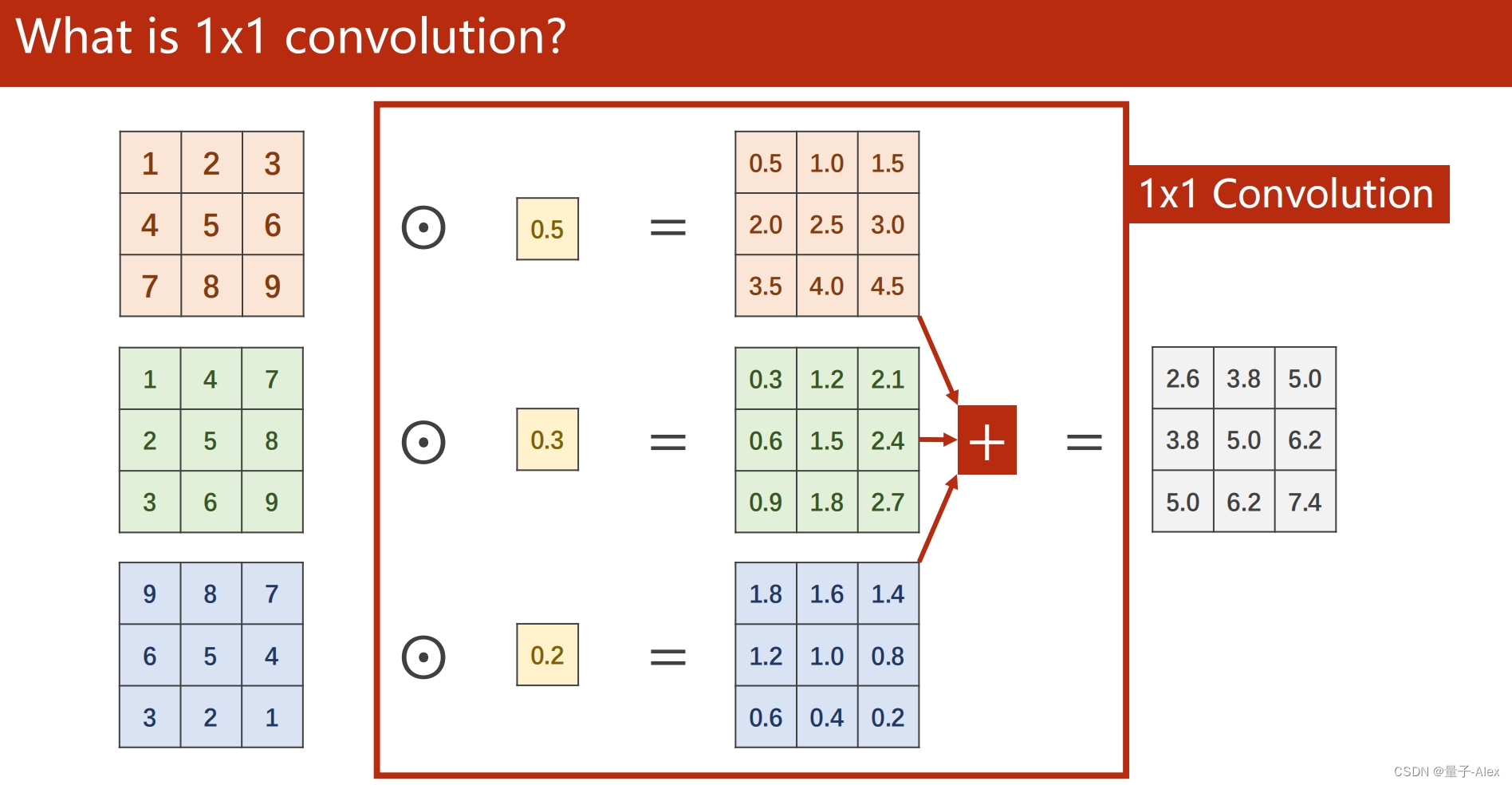
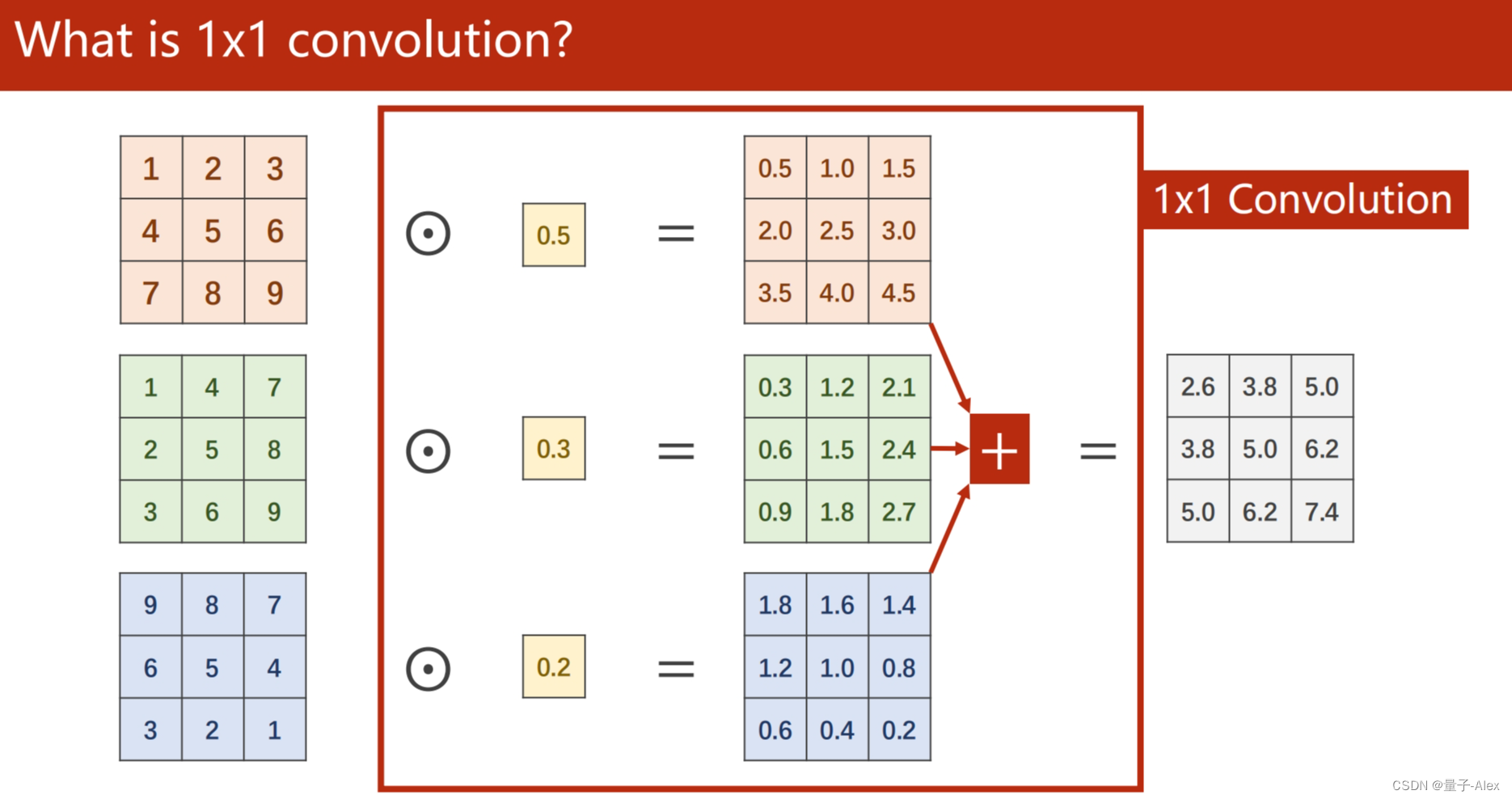
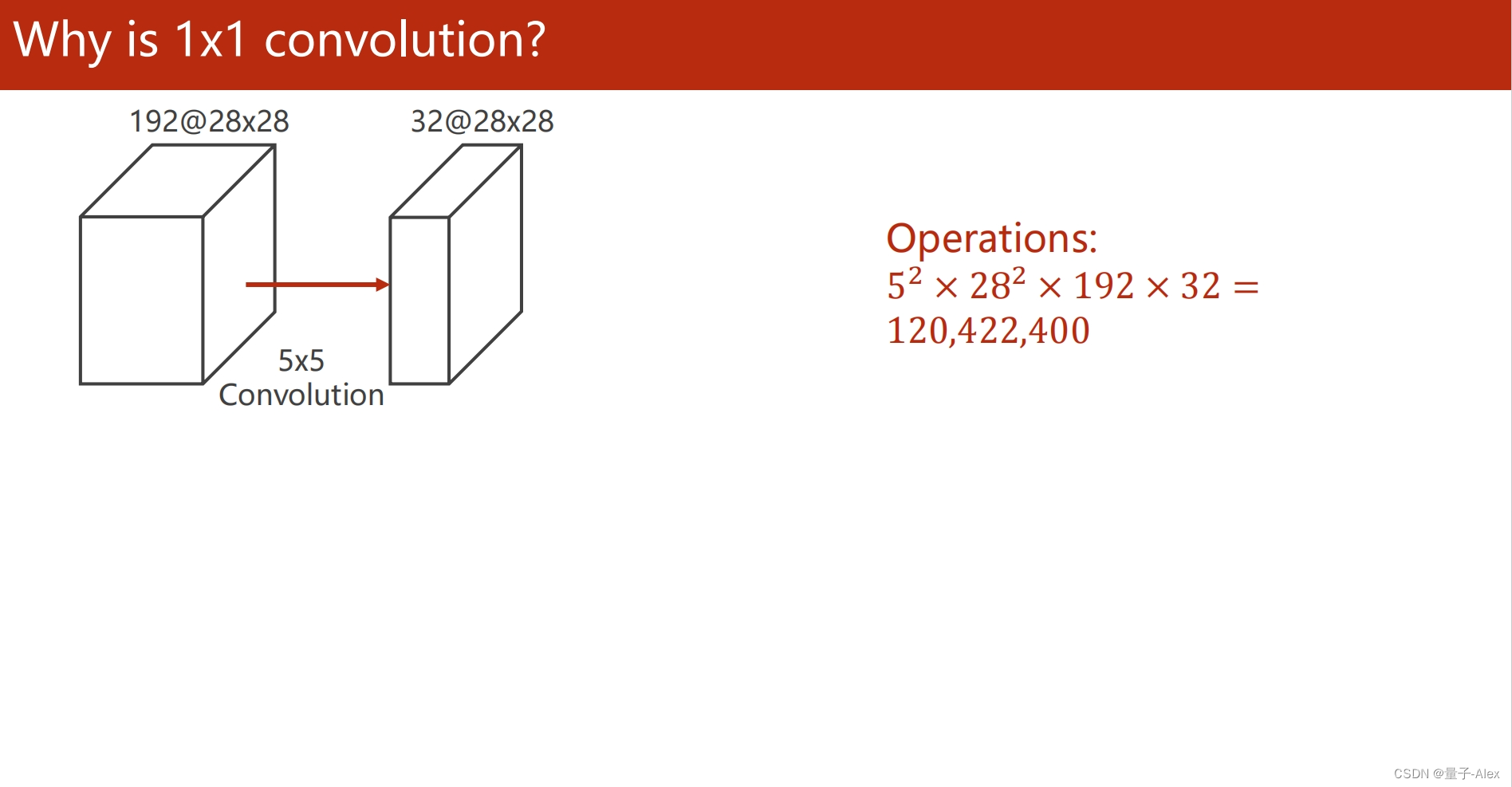
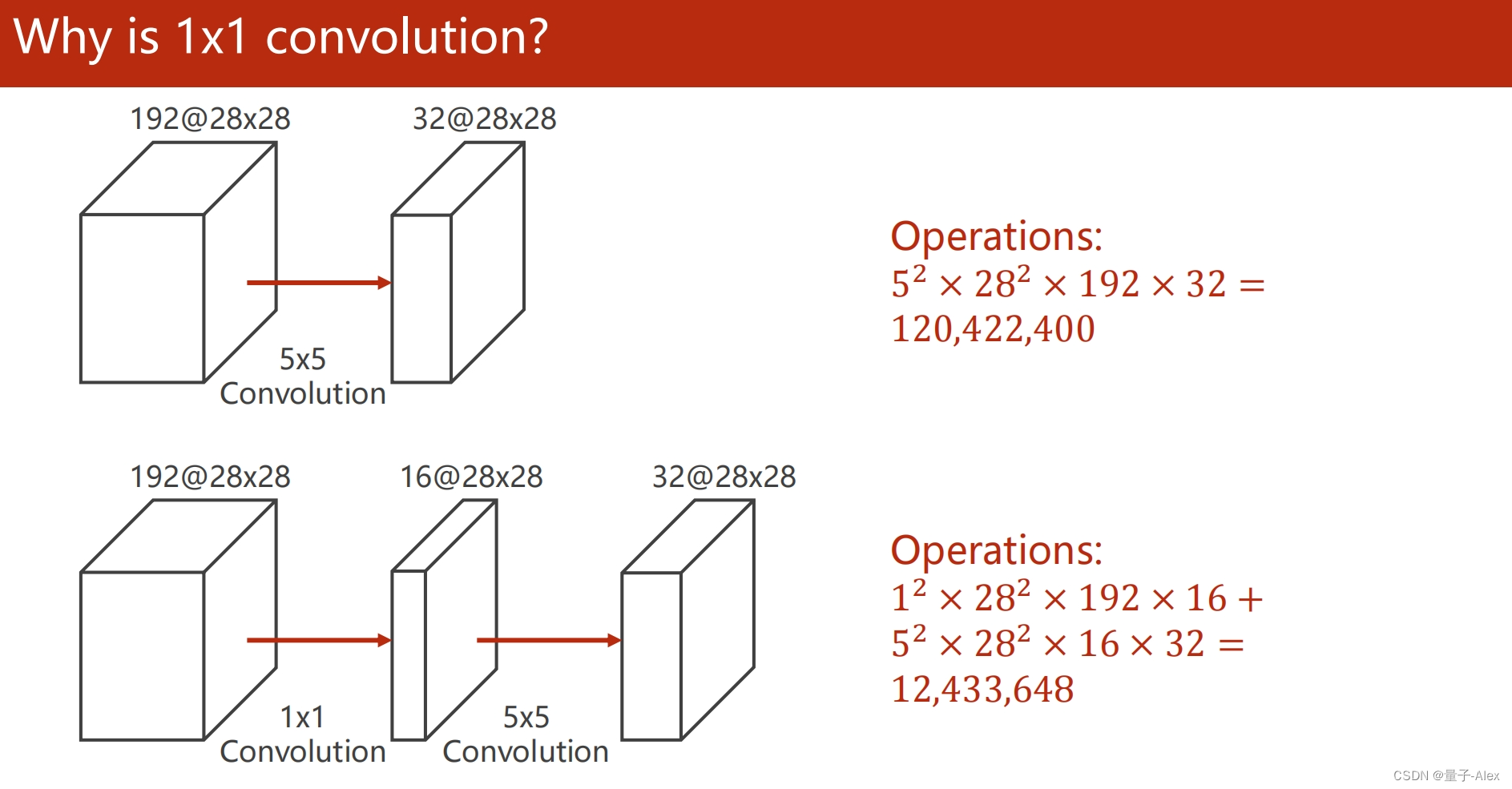
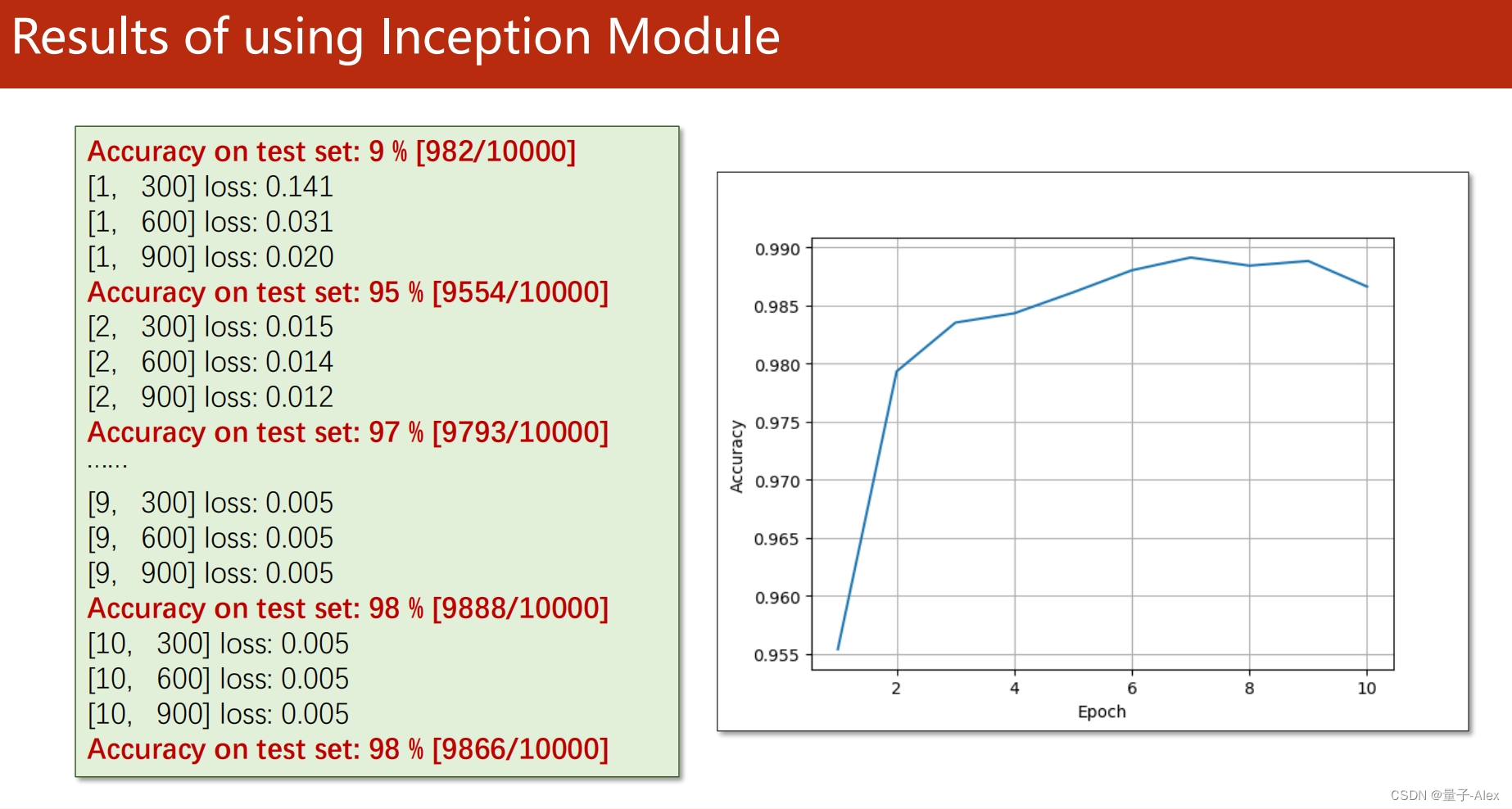
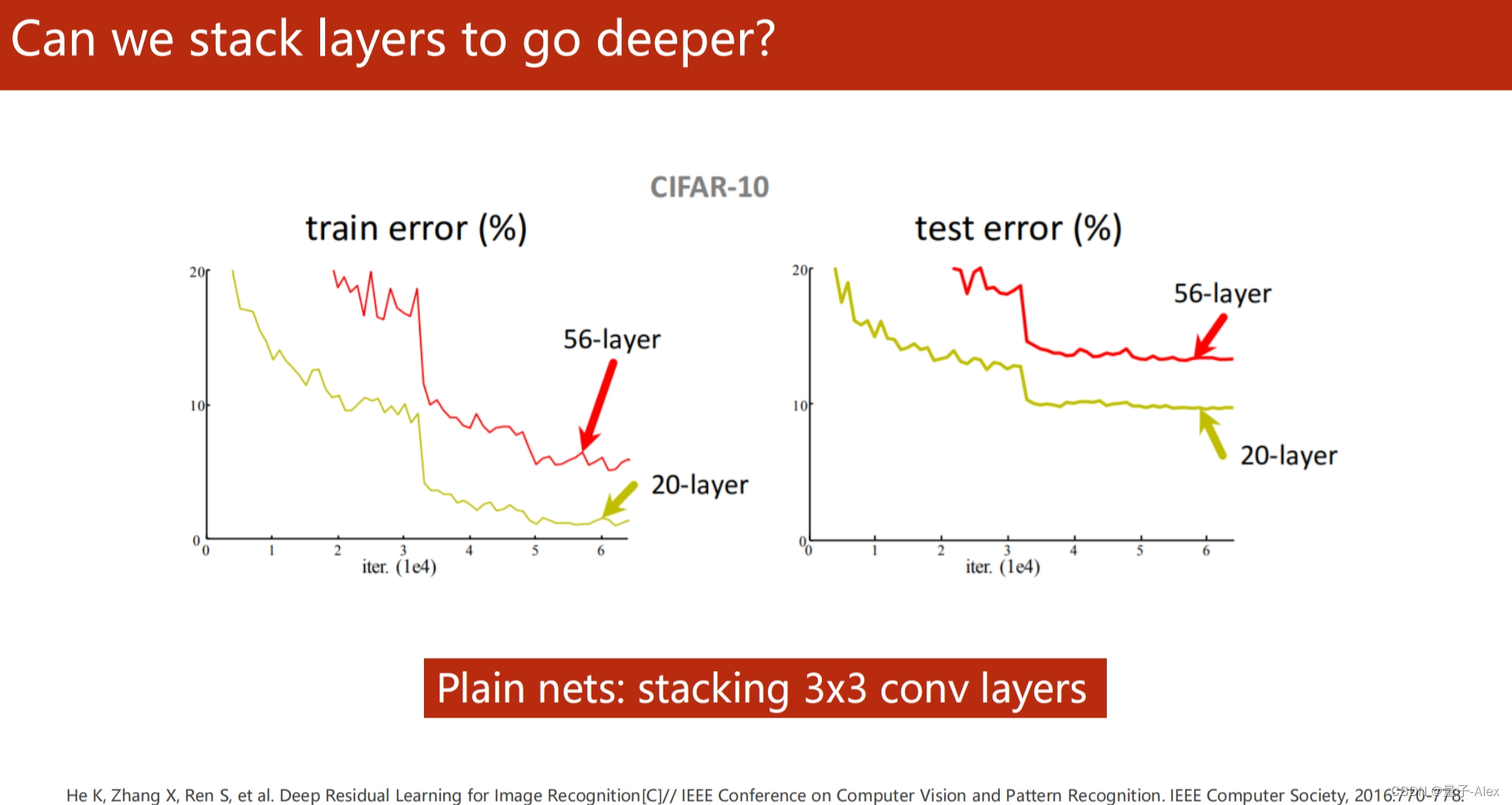
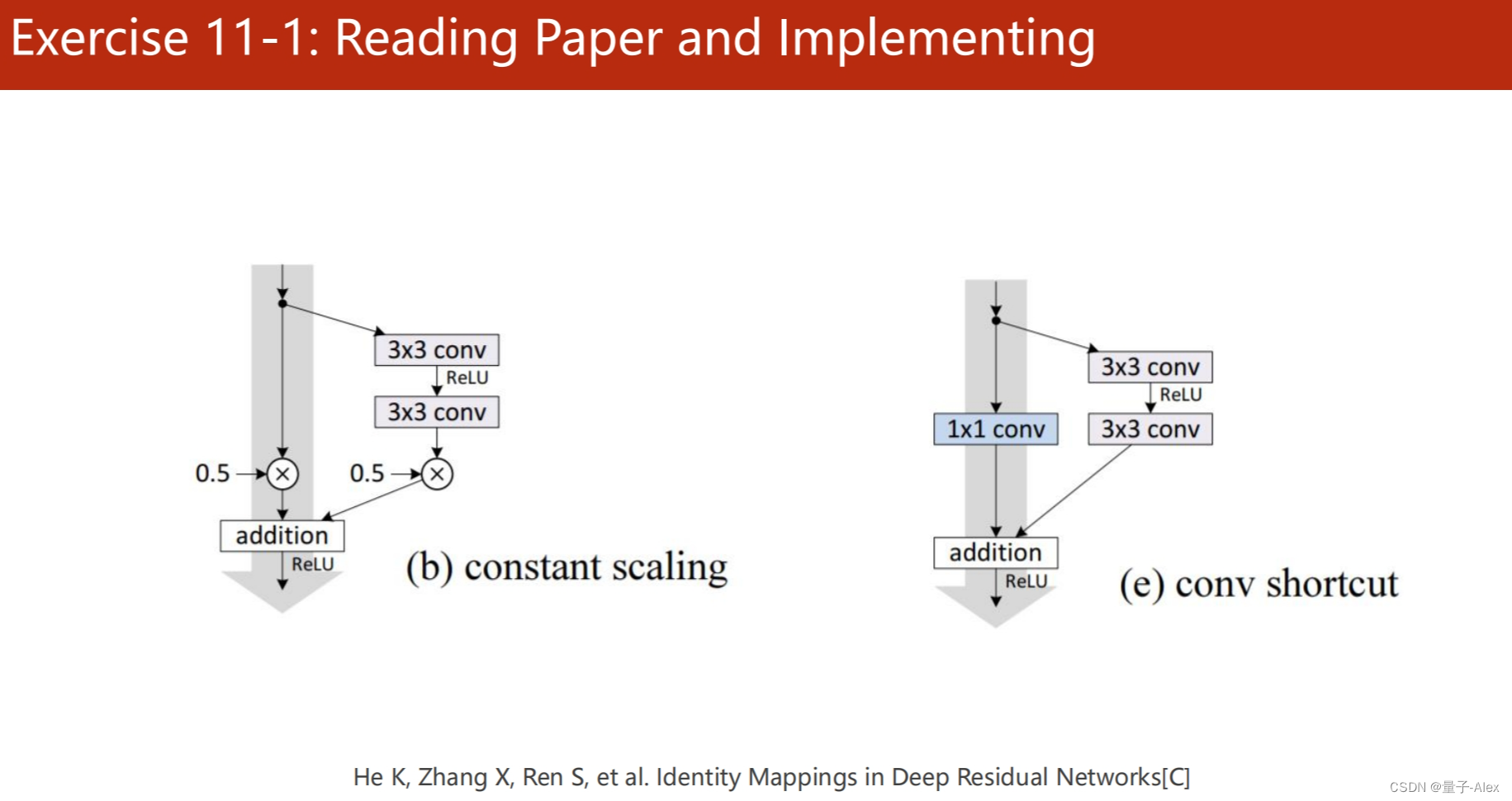
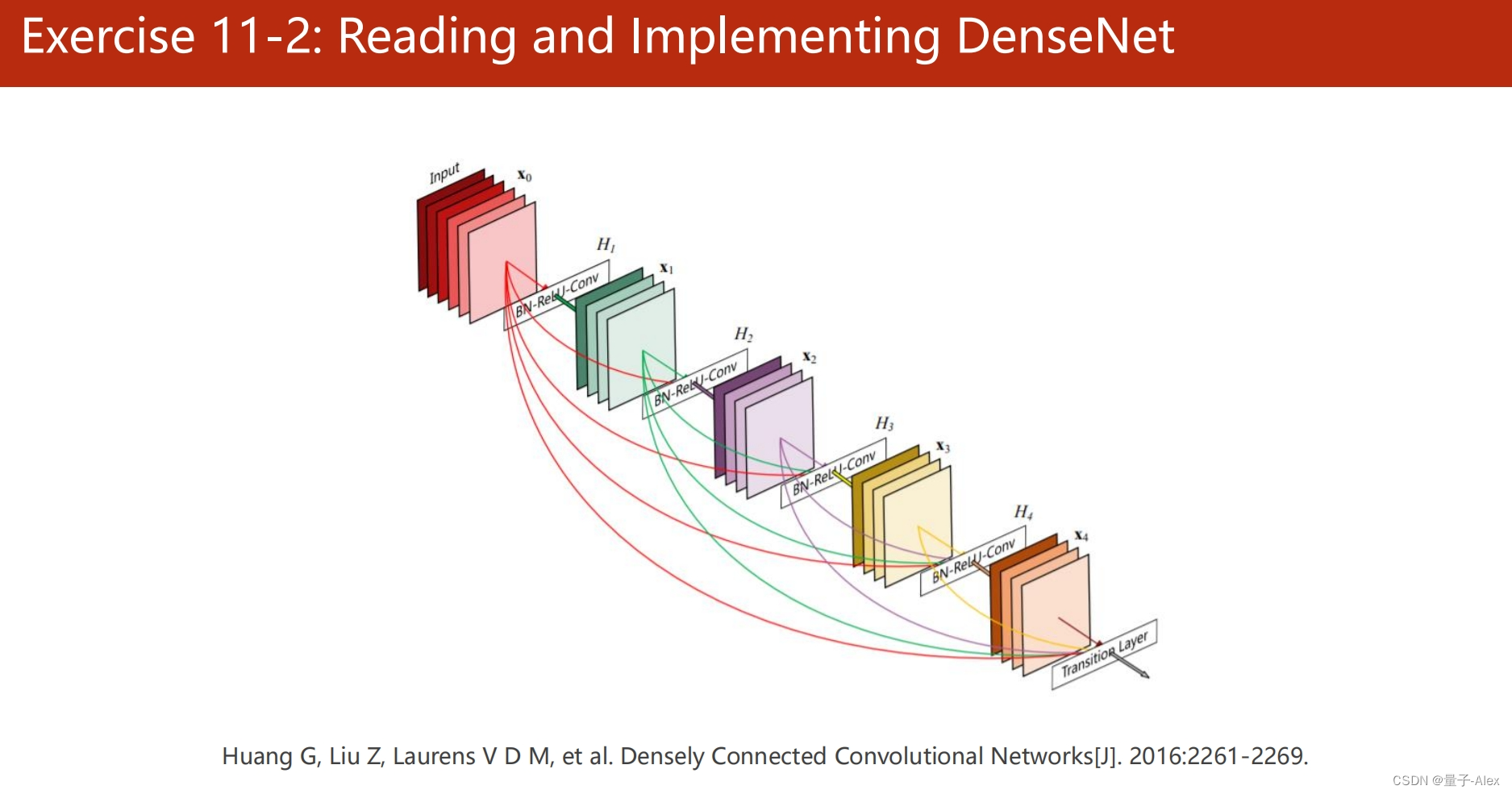
部分课件内容: