上一篇文章我们一起看了下TensorRT有哪些特性或者支持哪些功能,这一节我们来详细的从API出发研究一下具体的实现,难度要上升了哦,请系好安全带,准备发车!
文章目录
- 3. The C++ API
- 3.1 The Build Phase
- 3.1.1 Creating a Network Definition
- 3.1.2 Importing a Model Using the ONNX Parser
- 3.1.3 Building an Engine
- 3.2 Deserializing a Plan
- 3.3 Performing Inference
- 3.4 TensorRT tar安装及sample
3. The C++ API
这一节主要基于C++的API,我们基于ONNX模型,sampleOnnxMNIST这个例子更详细的说明了怎么使用这些API(我们会在后面单独研究这个例子,现在我们还是先熟悉一下API)。
C++的API可以从NvInfer.h头文件中找到,并且都是放在nvinfer1这个命名空间中的(阿达,为啥你的API命名总是这么随便),例如,几乎所有的程序在开头都是类似下面这样的:
#include “NvInfer.h”
using namespace nvinfer1;
TensorRT的接口类(Interface classes)C++ API通常用前缀I进行表示,比如ILogger, IBuilder,如果在此之前不存在一个 CUDA context,则TensorRT第一次调用CUDA时会自动创建CUDA context。在第一次调用TensorRT之前,最好自己创建和配置CUDA context。为了让你们能清楚的知道一些对象的生命周期,文档说故意没有使用智能指针,就是告诉你有些对象在某些时刻被我们手动释放了(但是文档推荐你使用智能指针,没错,就是怕你泄露)。
3.1 The Build Phase
要创建builder,首先必须实例化ILogger接口。这个例子捕获所有警告消息,但忽略信息性消息,就是让你对消息进行过滤:
class Logger : public ILogger
{
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
然后你可以创建一个builder的实例:
IBuilder* builder = createInferBuilder(logger);
3.1.1 Creating a Network Definition
创建完builder以后,优化网络的第一步就是创建一个网络的定义:
// 左移这么多位当作flag, 1U这种使用方式参考 https://stackoverflow.com/questions/2128442/what-does-1u-x-do
// 1U << 2 = 4
uint32_t flag = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
INetworkDefinition* network = builder->createNetworkV2(flag);
在使用ONNX parser导入模型的时候,我们需要指定kEXPLICIT_BATCH这个flag,可以参考 Explicit Versus Implicit Batch获取更多信息。
3.1.2 Importing a Model Using the ONNX Parser
现在,必须从ONNX表示中来填充(populate)网络。ONNX parser API位于文件NvOnnxParser.h中,且在nvonnxparser命名空间中。
#include “NvOnnxParser.h”
using namespace nvonnxparser;
你可以像如下代码所示来创建一个ONNX parser:
IParser* parser = createParser(*network, logger);
然后,读取模型文件顺带着打印一下错误信息:
parser->parseFromFile(modelFile, static_cast<int32_t>(ILogger::Severity::kWARNING));
for (int32_t i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
注意下,TensorRT网络定义的一个重要点是它包含了一个指向模型权重的指针,这些指针由builder复制到优化的engine中。由于网络是使用parser创建的,所以parser拥有权重占用的内存,因此在builder运行之前,不应该删除parser对象(就是说只有builder开始运行了,parser才能够被销毁,这个时候权重交由builder占用)。
3.1.3 Building an Engine
下一步就是创建一个build configuration来告诉TensorRT怎么优化模型:
IBuilderConfig* config = builder->createBuilderConfig();
这个接口有甚多你可以设置的属性。一个重要的属性就是最大空间( maximum workspace size)。Layer的实现通常需要一个临时空间,这个参数限制了网络中的任意layer可以使用的最大空间。如果你没有提供一个足够的空间,TensorRT就无法找到一个层的实现(就是放不下了)。默认情况下,workspace被设置为给定设备的所有全局内存大小(total global memory),当你需要的时候,你应该来进行限定,比如说你只有一个设备,但是有多个engine在build:
config->setMemoryPoolLimit(MemoryPoolType::kWORKSPACE, 1U << 20); // 2^20
当你的配置指定好以后,你就可以开始构建engine了:
IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
由于序列化的引擎包含必要的权重副本(serializedModel),所以parser,network definition,builder configuration和builder不再是必需的,可以安全地删除:
delete parser;
delete network;
delete config;
delete builder;
你可以把engine存到磁盘,然后记得删除这个serializedModel:
delete serializedModel
注意:Serialized engines不能跨平台或跨TensorRT版本进行移植。Engines是特定于它们所构建的确切GPU模型的(除了平台和TensorRT版本,也就是建议我们在哪用就在哪构建,除非你能保证版本都一致)。且由于构建engine我们把它当作一个离线的工作(offline process),需要花费比较多的时间,可以参考Optimizing Builder Performance章节来看看怎么让builder运行的更快。
3.2 Deserializing a Plan
假设你之前已经序列化了一个优化后的模型并且想进行推理,你必须创建一个Runtime接口的示例,和builder很类似,runtime也需要一个logger实例:
IRuntime* runtime = createInferRuntime(logger);
然后,你就可以把模型读取到buffer中了,你可以对模型进行反序列化(deserialize)并且放到一个engine中:
ICudaEngine* engine =
runtime->deserializeCudaEngine(modelData, modelSize); // 这里有点跳跃,我们一会看例程
3.3 Performing Inference
这个时候,所有的模型信息都给了engine变量,但是我们必须要管理中间激活( intermediate activations)的附加状态(真拗口,啥是中间激活,先有个印象)。我们通过ExecutionContext接口来进行:
IExecutionContext *context = engine->createExecutionContext();
一个engine可以有多个execution contexts,允许一组权重用于多个重叠的推理任务(除非使用了dynamic shapes,每个optimization profile只能有一个 execution context,除非指定了预览特性kPROFILE_SHARING_0806,后续有机会再补充)
为了运行推理,你必须要对输入输出传入相应的buffers,TensorRT会要求你调用setTensorAddress来进行设置,这个接口要求你输入tensor的name和buffer的地址。这个我们在之前提过,你可以通过查询engine来获得输入输出的名字和找到数组的正确位置:
context->setTensorAddress(INPUT_NAME, inputBuffer); // 我们后面对照例程再来看一下
context->setTensorAddress(OUTPUT_NAME, outputBuffer);
然后你可以调用enqueueV3()函数来使用CUDA stream进行推理:
context->enqueueV3(stream);
根据网络的结构和特点,网络可以异步执行,也可以同步执行。例如,可能导致同步行为的情况包括依赖数据的形状(data dependent shapes)、DLA的使用、循环和同步的插件(plugin)。通常在内核之前和之后使用cudaMemcpyAsync()排队数据传输,以便从GPU移动数据,这个很有必要,不要忘记,不然你的数据可能怎么都不对(要确定kernel(可能还有cudaMemcpyAsync())何时完成,请使用标准的CUDA同步机制,例如事件( events)或着等待这个流结束。)。
其实整个流程并不复杂,我们分成两部分:
- 构建的时候:logger->parser->network->config->builder->serializedModel
- 推理的时候:runtime->engine->context
熟悉了就好了,下面我们一起来看一下提供的例程,完整的看一下C++ API的调用流程。
3.4 TensorRT tar安装及sample
我使用的官方github里面的sample没有跑通,需要配置的地方还挺多。我通过tar包安装解压后的例程跑通了,最终输出结果如下:
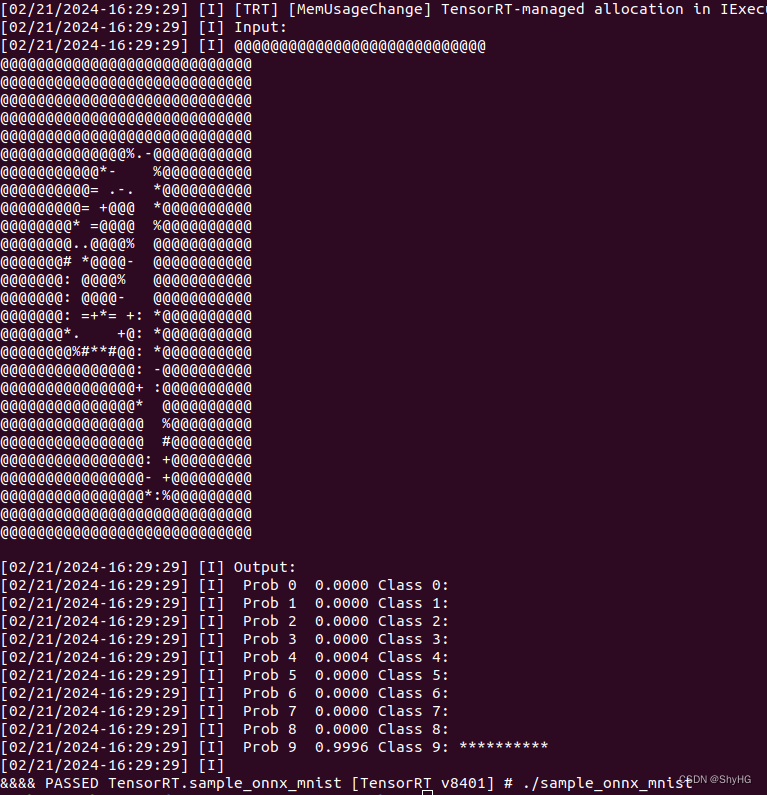
我这里附上我tar包安装TensorRT的流程吧(逃不掉):
-
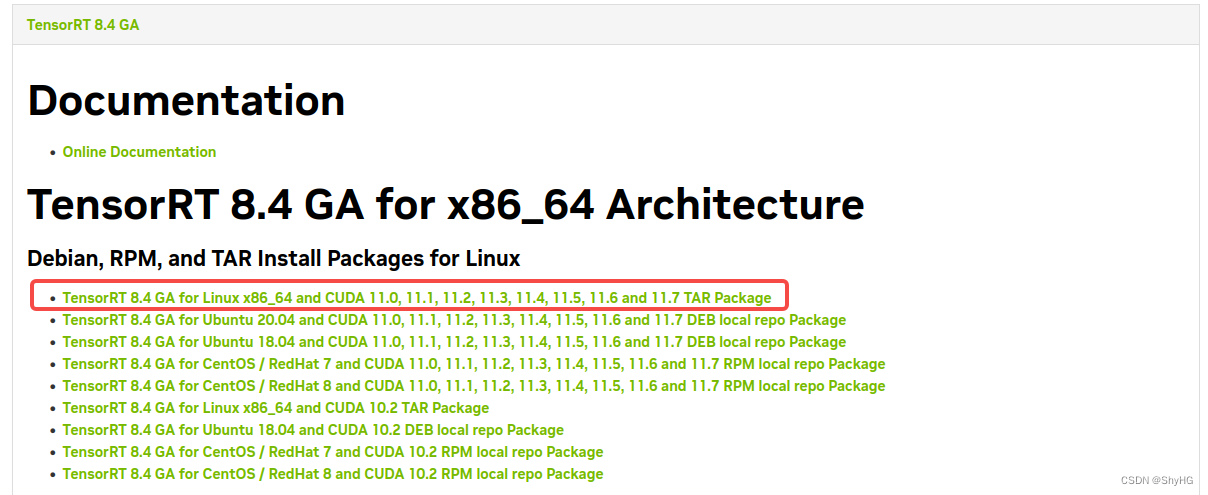
首先下载TensorRT的tar包,地址为:https://developer.nvidia.com/nvidia-tensorrt-download,版本可以选择你自己想要的(要和cudnn匹配)。
-
解压压缩包
tar -xzvf TensorRT-8.4.1.5.Linux.x86_64-gnu.cuda-11.6.cudnn8.4.tar.gz -
添加环境变量
# 打开环境变量文件 sudo vim ~/.bashrc # 将下面三个环境变量写入环境变量文件并保存 export LD_LIBRARY_PATH=/home/ubuntu/TensorRT-8.4.1.5/lib:$LD_LIBRARY_PATH export CUDA_INSTALL_DIR=/usr/local/cuda-11.4 export CUDNN_INSTALL_DIR=/usr/local/cuda-11.4 # 使刚刚修改的环境变量文件生效 source ~/.bashrc # 为了避免其它软件找不到TensorRT的库,建议把TensorRT的库和头文件添加到系统路径下 cd TensorRT-8.4.1.5 sudo cp -r ./lib/* /usr/lib sudo cp -r ./include/* /usr/include -
上面你解压的tar包里面有一个sample文件夹,首先进入
samples/sampleOnnxMNIST,然后参考这里:$ cd <samples_dir> # 就是进入sampleOnnxMNIST $ make -j4 $ cd ../bin # 其实是cd ../../bin $ ./<sample_bin> # ./sample_onnx_mnist
然后就可以获得结果了,下面我们对照着我们上面提到的流程来看一下源码:
-
创建builder,在sampleOnnxMNIST.cpp的111行
这里使用了一个智能指针,定义如下,然后创建一个builder,调用的接口是nvinfer1::createInferBuilder(),和上面讲解的一样吧。template <typename T> using SampleUniquePtr = std::unique_ptr<T, InferDeleter>; ... auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger())); -
创建网络,在117行
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch)); -
创建buildConfig
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig()); if (!config) { return false; } -
创建parser
auto parser = SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger())); if (!parser) { return false; } -
解析ONNX
auto parsed = parser->parseFromFile(locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(), static_cast<int>(sample::gLogger.getReportableSeverity())); if (!parsed) { return false; } if (mParams.fp16) { config->setFlag(BuilderFlag::kFP16); // 配置config } if (mParams.int8) { config->setFlag(BuilderFlag::kINT8); // 函数注释提到,如果没有使用校准数据集,那么你必须为每层都设置一个动态范围集(dynamic range set) samplesCommon::setAllDynamicRanges(network.get(), 127.0F, 127.0F); } // 最后打开DLA来进一步加速,这个概念我们之前有提过 samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);我们进入这个
setAllDynamicRanges()函数瞅瞅,其实就是逐层设置一下(但是在我们之前锁接触到的文档中,并没有提这个事,所以有点懵懵的)(如果一个tensor没有设置,如果它是一个pooling 节点layer的输入,那么动态范围是由inRange决定的,否则是由outRange决定的,也就是上面函数的第二第三参数):// 首先给每层的输入设置动态范围 for (int i = 0; i < network->getNbLayers(); i++) { auto layer = network->getLayer(i); for (int j = 0; j < layer->getNbInputs(); j++) { nvinfer1::ITensor* input{layer->getInput(j)}; // Optional inputs are nullptr here and are from RNN layers. if (input != nullptr && !input->dynamicRangeIsSet()) { ASSERT(input->setDynamicRange(-inRange, inRange)); } } } // 再给每层的输出设置动态范围 for (int i = 0; i < network->getNbLayers(); i++) { auto layer = network->getLayer(i); for (int j = 0; j < layer->getNbOutputs(); j++) { nvinfer1::ITensor* output{layer->getOutput(j)}; // Optional outputs are nullptr here and are from RNN layers. if (output != nullptr && !output->dynamicRangeIsSet()) { // Pooling must have the same input and output scales. if (layer->getType() == nvinfer1::LayerType::kPOOLING) { ASSERT(output->setDynamicRange(-inRange, inRange)); } else { ASSERT(output->setDynamicRange(-outRange, outRange)); } } } }然后我们再进入enableDLA()函数瞅瞅:
if (useDLACore >= 0) { if (builder->getNbDLACores() == 0) // 如果没有DLA,就拉倒了 { std::cerr << "Trying to use DLA core " << useDLACore << " on a platform that doesn't have any DLA cores" << std::endl; assert("Error: use DLA core on a platfrom that doesn't have any DLA cores" && false); } if (allowGPUFallback) { config->setFlag(nvinfer1::BuilderFlag::kGPU_FALLBACK); // 还是在配置config,配置是否允许Fallback到GPU计算 } if (!config->getFlag(nvinfer1::BuilderFlag::kINT8)) // 如果没有要求INT8,则使用FP16,禁止使用FP32 { // User has not requested INT8 Mode. // By default run in FP16 mode. FP32 mode is not permitted. config->setFlag(nvinfer1::BuilderFlag::kFP16); } // 设置默认设备DLA config->setDefaultDeviceType(nvinfer1::DeviceType::kDLA); // 设置core(其实这里是-1,全部使用的意思?) config->setDLACore(useDLACore); } -
配置config
auto profileStream = samplesCommon::makeCudaStream(); if (!profileStream) { return false; } config->setProfileStream(*profileStream);还有一些config需要单独配置,比如profileStream:
std::unique_ptr<cudaStream_t, decltype(StreamDeleter)> pStream(new cudaStream_t, StreamDeleter); if (cudaStreamCreateWithFlags(pStream.get(), cudaStreamNonBlocking) != cudaSuccess) { pStream.reset(nullptr); } -
序列化模型,创建plane
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)}; -
下面就是另一个环节了,开始推理。创建runtime
mRuntime = std::shared_ptr<nvinfer1::IRuntime>(createInferRuntime(sample::gLogger.getTRTLogger())); -
反序列化模型
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(mRuntime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter()); -
获取输入输出维度
// 输入输出必须为一个,输入维度为4,输出维度为2 ASSERT(network->getNbInputs() == 1); mInputDims = network->getInput(0)->getDimensions(); ASSERT(mInputDims.nbDims == 4); ASSERT(network->getNbOutputs() == 1); mOutputDims = network->getOutput(0)->getDimensions(); ASSERT(mOutputDims.nbDims == 2); -
所有准备工作做完以后,开始推理咯
这里面还有一个比较重要的工作就是设置输入,也就是将数据读取后进行预处理,放到host的buffer中,然后从host将buffer拷贝到device中。// 和我们之前说的一样,先申请buffer(注意这里的buffer是存储了engine中的所有tensor的) samplesCommon::BufferManager buffers(mEngine); // 然后获取ExecutionContext auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext()); // 拷贝数据到buffer if (!processInput(buffers)) { return false; } // 开始推理,getDeviceBindings()函数可以让你直接获取到device buffers,在enqueue和IExecutionContext时候使用 bool status = context->executeV2(buffers.getDeviceBindings().data());这个processInput()函数挺重要,我们单独拎出来研究一下:
bool SampleOnnxMNIST::processInput(const samplesCommon::BufferManager& buffers) { const int inputH = mInputDims.d[2]; // 由网络query来的 const int inputW = mInputDims.d[3]; // Read a random digit file srand(unsigned(time(nullptr))); std::vector<uint8_t> fileData(inputH * inputW); mNumber = rand() % 10; // ifstream读取本地pgm,放到buffer里面去,大小为h*w readPGMFile(locateFile(std::to_string(mNumber) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW); // Print an ascii representation sample::gLogInfo << "Input:" << std::endl; for (int i = 0; i < inputH * inputW; i++) { sample::gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n"); } sample::gLogInfo << std::endl; // 获取inputTensorNames的buffer,就是先拿出来 float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(mParams.inputTensorNames[0])); for (int i = 0; i < inputH * inputW; i++) // 逐个进行拷贝,同时归一化了一下,直接返回1-x/255,并不是减均值除以方差 { hostDataBuffer[i] = 1.0 - float(fileData[i] / 255.0); } return true; }然后需要将buffer拷贝到device中:
// 这样进行调用的:buffers.copyInputToDevice();->memcpyBuffers();memcpyBuffers()干了啥呢,一起看下 void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0) { for (int i = 0; i < mEngine->getNbBindings(); i++) { void* dstPtr = deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data(); const void* srcPtr = deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data(); const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes(); const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice; if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i))) { // 真正的核心,就是把我们上面的hostDataBuffer拷贝到deviceBuffer if (async) CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream)); else CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType)); } } } -
获取结果和后处理
// 调用流程是buffers.copyOutputToHost();->memcpyBuffers(); void memcpyBuffers(const bool copyInput, const bool deviceToHost, const bool async, const cudaStream_t& stream = 0) { for (int i = 0; i < mEngine->getNbBindings(); i++) { void* dstPtr = deviceToHost ? mManagedBuffers[i]->hostBuffer.data() : mManagedBuffers[i]->deviceBuffer.data(); const void* srcPtr = deviceToHost ? mManagedBuffers[i]->deviceBuffer.data() : mManagedBuffers[i]->hostBuffer.data(); const size_t byteSize = mManagedBuffers[i]->hostBuffer.nbBytes(); const cudaMemcpyKind memcpyType = deviceToHost ? cudaMemcpyDeviceToHost : cudaMemcpyHostToDevice; if ((copyInput && mEngine->bindingIsInput(i)) || (!copyInput && !mEngine->bindingIsInput(i))) { if (async) // 核心在这里,就是把deviceBuffer拷贝到hostBuffer中去 CHECK(cudaMemcpyAsync(dstPtr, srcPtr, byteSize, memcpyType, stream)); else CHECK(cudaMemcpy(dstPtr, srcPtr, byteSize, memcpyType)); } } }获取完结果后进行后处理:
verifyOutput(buffers); bool SampleOnnxMNIST::verifyOutput(const samplesCommon::BufferManager& buffers) { const int outputSize = mOutputDims.d[1]; // 和之前一样,通过名称取出output的buffer float* output = static_cast<float*>(buffers.getHostBuffer(mParams.outputTensorNames[0])); float val{0.0F}; int idx{0}; // Calculate Softmax float sum{0.0F}; for (int i = 0; i < outputSize; i++) { output[i] = exp(output[i]); sum += output[i]; } sample::gLogInfo << "Output:" << std::endl; for (int i = 0; i < outputSize; i++) { output[i] /= sum; val = std::max(val, output[i]); // 获得最大值,最后进行输出 if (val == output[i]) { idx = i; } sample::gLogInfo << " Prob " << i << " " << std::fixed << std::setw(5) << std::setprecision(4) << output[i] << " " << "Class " << i << ": " << std::string(int(std::floor(output[i] * 10 + 0.5F)), '*') << std::endl; } sample::gLogInfo << std::endl; return idx == mNumber && val > 0.9F; }
终于结束啦,这个sample麻雀虽小五脏俱全,里面有挺多对函数的进一步封装的操作,大家可以用函数跳转慢慢看,但是整个流程和我们前半部分讲的基本一致,希望大家通过这篇文章可以对整个TensorRT的模型优化及推理有个大概认知,先这样吧,写了几乎整整一天,一起加油呀!