1. 引言
就在 OpenAI 发布可以生成令人瞠目的视频的 Sora 和谷歌披露支持多达 150 万个Token上下文的 Gemini 1.5 的几天后,Stability AI 最近展示了 Stable Diffusion 3 的预览版。

闲话少说,我们快来看看吧!
2. 什么是Stable Diffusion 3?
Stable Diffusion 3 是 Stability AI 最新推出的功能最强大的文本到图像生成的模型。它在处理多文本提示、图像质量甚至文本渲染能力方面都有重大的改进。
目前,该模型套件的参数量从 800M 到 8B 不等。它结合了扩散transformer结构(类似于Sora中的结构)和Flow Matching。
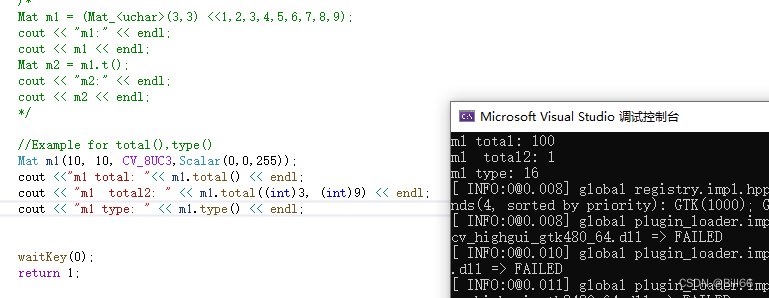
3. Diffusion Transformer Architecture
Diffusion Transformer(DiT)架构代表了一类融合了Transformer技术的新型扩散模型。与通常使用卷积 U-Net 主干网的传统扩散模型不同,DiT 采用Transformer结构对图像的潜在特征表示进行操作。DiT的网络结构如下:

事实证明,这种架构对于ImageNet等大型数据集上的基于类别条件图像生成任务特别有效,DiTs 在图像质量和生成模型性能方面树立了新的标杆。
4. Flow Matching
Flow Matching (FM)是 一种全新的、无需模拟的连续归一化流量(CNFs)的训练方法,它能以前所未有的规模训练 CNFs。FM 的工作原理是对与高斯概率路径(包括扩散路径)兼容的固定条件概率路径向量场进行回归。更多细节,可以读取官方论文。

这项技术不仅使扩散模型的训练更加稳健,还为使用非扩散概率路径的CNF 进行更快的训练、采样和更好的泛化铺平了道路。
5. SD3新功能
以下是Stable Diffusion 3带来的主要改进:
- 支持文本渲染
- 性能提升
- 多目标提示
- 更好的图像质量
上述这些改进中,最令人兴奋的功能是它能够渲染文本,类似于 openAI 的 Dall-E 3 和谷歌的Imagen 2。Emad Mostaque作为Stability AI的CEO一直在分享使用SD 3 生成的图像,以下是我最喜欢的一些:
Prompt: “Photo of a red sphere on top of a blue cube. Behind them is a green triangle, on the right is a dog, on the left is a cat”
提示:“一张红色球体放在蓝色立方体上面的照片。后面是一个绿色三角形,右边是一只狗,左边是一只猫”。

我觉得这张照片有趣的一点是,动物的白色皮毛上有微妙的绿色。不确认的是模型是否可以从训练数据中的绿幕电影场景照片中学到了这种效果。
Prompt: “cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk”
提示:"电影照片,教室的桌子上放着一个红苹果,黑板上用粉笔写着 "要么大干,要么回家 “的字样”

6. 效果对比
我快速比较了 SD3 和 OpenAI 的Dall-E 3生成的图像的效果,这里我使用了SD3官方博客中的提示词。
Prompt: “Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says “Stable Diffusion 3” made out of colorful energy”
提示:“史诗般的动漫作品,一个巫师在夜晚的山顶上向黑暗的天空施放宇宙咒语,咒语上写着 “稳定扩散 3”,由五彩缤纷的能量组成”


老实说,我很惊讶 Dall-E 3 在这个提示下一再拒绝呈现文本。自己去试试吧。
7. 总结
本文重点介绍了SD3带来的新的改进,在此说明下,目前SD3还为对公众开放,但是大家可以通过注册来获得Discord服务器的邀请。预览版的目的是提高其质量和安全性,就像其他稳定的扩散版本一样。


![[electron]官方示例解析](https://img-blog.csdnimg.cn/direct/fdd74d254f754b21964f63e454af6ebb.png)