原文地址:Using RAGAs + LlamaIndex for RAG evaluation
2024 年 2 月 5 日
如果您已经为实际的业务系统开发了检索增强生成(Retrieval Augmented Generation, RAG)应用程序,那么您可能会关心它的有效性。换句话说,您想要评估RAG的性能。
此外,如果您发现您现有的RAG不够有效,您可能需要验证先进的RAG改进方法的有效性。换句话说,您需要进行评估,看看这些改进方法是否有效。
在本文中,我们首先介绍了由RAGAs(检索增强生成评估)提出的RAG的评估指标,这是一个用于评估RAG管道的框架。然后,我们解释了如何使用RAGAs + LlamaIndex实现整个评估过程。
RAG评价指标
简单地说,RAG的过程包括三个主要部分:输入查询、检索上下文和LLM生成的响应。这三个要素构成了RAG过程中最重要的三位一体,并且是相互依存的。
因此,可以通过测量这些三元组之间的相关性来评估RAG的有效性,如图1所示。
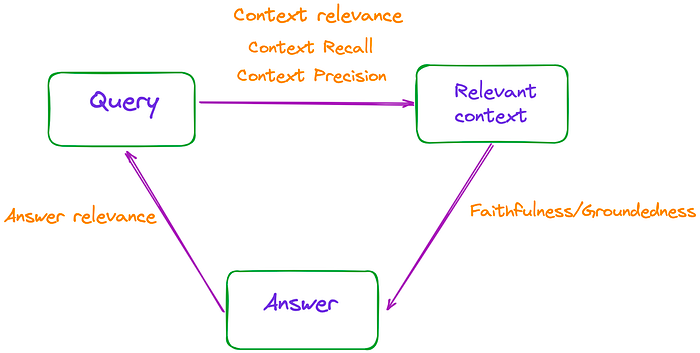
图1:RAG的有效性可以通过测量这些三元组之间的相关性来评估。
论文总共提到了3个指标:忠实度、答案相关性和上下文相关性,这些指标不需要访问人工注释的数据集或参考答案。
此外,RAGAs网站引入了另外两个指标:上下文精度和上下文召回。
Faithfulness/Groundedness
Faithfulness指的是确保答案是基于给定的上下文。这对于避免错觉和确保检索到的上下文可以用作生成答案的理由非常重要。
如果分数低,则表明LLM的回答不符合检索到的知识,提供幻觉答案的可能性增加。例如:

图2:高Faithfulness答案和低Faithfulness答案。来源:https://docs.ragas.io/en/latest/concepts/metrics/faithfulness.html。
为了估计信度,我们首先使用LLM提取一组语句,**S(a(q))**。方法是使用以下prompt:
1 2 3 | Given a question and answer, create one or more statements from each sentence in the given answer. question: [question] answer: [answer] |
在生成**S(a(q))之后,LLM确定是否可以从c(q)**中推断出每个语句si。此验证步骤使用以下prompt执行:
1 2 3 4 5 | Consider the given context and following statements, then determine whether they are supported by the information present in the context. Provide a brief explan ation for each statement before arriving at the verdict (Yes/No). Provide a final verdict for each statement in order at the end in the given format. Do not deviate from the specified format. statement: [statement 1] ... statement: [statement n] |
最终的忠实度得分**F计算为 F = |V|/|S|** ,其中**|V|表示根据LLM支持的语句数,|S|**表示语句总数。
回答的相关性
这个度量度量生成的答案和查询之间的相关性。分数越高,相关性越好。例如:

图3:高相关性答案和低相关性答案。来源:https://docs.ragas.io/en/latest/concepts/metrics/answer_relevance.html。
为了估计答案的相关性,我们promptLLM根据给定的答案 a(q) 生成n个潜在问题 qi ,如下所示:
1 2 3 | Generate a question for the given answer. answer: [answer] |
然后,我们利用文本Embedding模型获得所有问题的Embeddings。
对于每个 qi ,我们计算 sim(q, qi) 与原始问题 q 的相似性。这对应于Embeddings之间的余弦相似度。问题**q的答案相关性评分AR**计算方法如下:
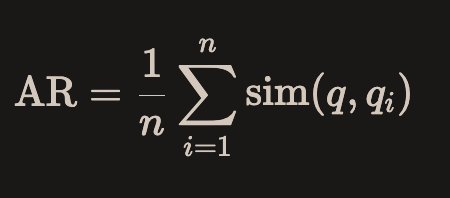
上下文相关性
这是一个度量检索质量的指标,主要评估检索上下文支持查询的程度。分数低表明检索到的不相关内容数量较多,这可能会影响LLM生成的最终答案。例如:

图4:高上下文相关性和低上下文相关性。来源:https://docs.ragas.io/en/latest/concepts/metrics/context_relevancy.html。
为了估计上下文的相关性,使用LLM从上下文**(c(q))**中提取一组关键句子 (Sext) 。这些句子对于回答这个问题至关重要。prompt符如下:
1 2 3 4 | Please extract relevant sentences from the provided context that can potentially help answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you’re not allowed to make any changes to sentences from given context. |
然后,在RAGAs中,使用以下公式在句子级别计算相关性:

上下文召回
该度量度量检索上下文与带注释的答案之间的一致性级别。它是使用地面真值和检索上下文计算的,值越高表示性能越好。例如:

图5:高上下文回忆和低上下文回忆。来源:Context Recall | Ragas
在实施时,要求提供地面真值数据。
计算公式如下:

上下文精准度
这个度量是相对复杂的,它被用来度量包含真实事实的所有相关上下文是否都排在最前面。分数越高表示精确度越高。
该指标的计算公式如下:

上下文精确的优势在于它能够感知排序效应。但是,它的缺点是,如果相关的召回很少,但是排名都很高,那么得分也会很高。因此,有必要结合其他几个指标来考虑总体效果。
采用RAGAs + LlamaIndex进行RAG评价
主要流程如图6所示:
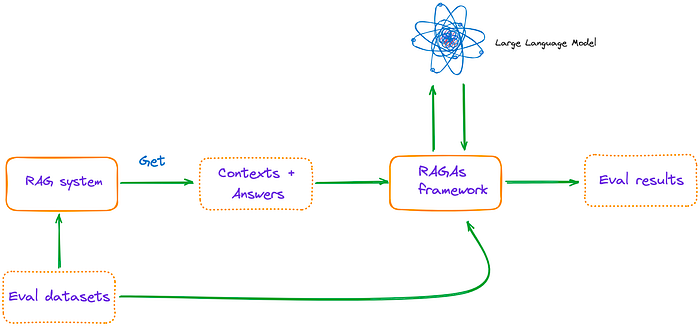
图6:主流程。
环境配置
安装ragas: pip install ragas。然后,检查当前版本。
1 2 | (py) Florian:~ Florian$ pip list | grep ragas ragas 0.0.22 |
值得一提的是,如果您使用pip install git+https://github.com/explodinggradients/ragas.git安装最新版本(v0.1.0rc1),则不支持LlamaIndex。
然后导入相关库,设置环境变量和全局变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
dir_path = "YOUR_DIR_PATH"
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision
)
from ragas.llama_index import evaluate
|
目录中只有一个PDF文件,使用的是论文“TinyLlama:一个开源的小型语言模型”。
1 2 | (py) Florian:~ Florian$ ls /Users/Florian/Downloads/pdf_test/ tinyllama.pdf |
使用LlamaIndex构建一个简单的RAG查询引擎
1 2 3 | documents = SimpleDirectoryReader(dir_path).load_data() index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() |
LlamaIndex默认使用OpenAI模型,LLM和Embedding模型可以通过ServiceContext轻松配置。
构建评估数据集
由于有些指标需要手动标注数据集,所以我自己编写了一些问题和相应的答案。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | eval_questions = [
"Can you provide a concise description of the TinyLlama model?",
"I would like to know the speed optimizations that TinyLlama has made.",
"Why TinyLlama uses Grouped-query Attention?",
"Is the TinyLlama model open source?",
"Tell me about starcoderdata dataset",
]
eval_answers = [
"TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.",
"During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.",
"To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance",
"Yes, TinyLlama is open-source",
"This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.",
]
eval_answers = [[a] for a in eval_answers]
|
指标选择和RAGAs评估
1 2 3 4 5 6 7 8 9 10 | metrics = [
faithfulness,
answer_relevancy,
context_relevancy,
context_precision,
context_recall,
]
result = evaluate(query_engine, metrics, eval_questions, eval_answers)
result.to_pandas().to_csv('YOUR_CSV_PATH', sep=',')
|
请注意,在缺省情况下,在RAGAs中使用OpenAI模型。
在RAGAs中,如果您想使用另一个LLM(如Gemini)使用LlamaIndex来评估,即使在调试了RAGAs的源代码之后,我也没有在RAGAs版本0.0.22中找到任何有用的方法。
最终代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"
dir_path = "YOUR_DIR_PATH"
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from ragas.metrics import (
faithfulness,
answer_relevancy,
context_relevancy,
context_recall,
context_precision
)
from ragas.llama_index import evaluate
documents = SimpleDirectoryReader(dir_path).load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
eval_questions = [
"Can you provide a concise description of the TinyLlama model?",
"I would like to know the speed optimizations that TinyLlama has made.",
"Why TinyLlama uses Grouped-query Attention?",
"Is the TinyLlama model open source?",
"Tell me about starcoderdata dataset",
]
eval_answers = [
"TinyLlama is a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes.",
"During training, our codebase has integrated FSDP to leverage multi-GPU and multi-node setups efficiently. Another critical improvement is the integration of Flash Attention, an optimized attention mechanism. We have replaced the fused SwiGLU module from the xFormers (Lefaudeux et al., 2022) repository with the original SwiGLU module, further enhancing the efficiency of our codebase. With these features, we can reduce the memory footprint, enabling the 1.1B model to fit within 40GB of GPU RAM.",
"To reduce memory bandwidth overhead and speed up inference, we use grouped-query attention in our model. We have 32 heads for query attention and use 4 groups of key-value heads. With this technique, the model can share key and value representations across multiple heads without sacrificing much performance",
"Yes, TinyLlama is open-source",
"This dataset was collected to train StarCoder (Li et al., 2023), a powerful opensource large code language model. It comprises approximately 250 billion tokens across 86 programming languages. In addition to code, it also includes GitHub issues and text-code pairs that involve natural languages.",
]
eval_answers = [[a] for a in eval_answers]
metrics = [
faithfulness,
answer_relevancy,
context_relevancy,
context_precision,
context_recall,
]
result = evaluate(query_engine, metrics, eval_questions, eval_answers)
result.to_pandas().to_csv('YOUR_CSV_PATH', sep=',')
|
请注意,在终端中运行程序时,可能不会完全显示Pandas数据框。为了查看它,您可以将其导出为CSV文件,如图6所示。

图6:最终结果。图片来自作者。
从图6中可以明显看出,第四个问题“Tell me about starcoderdata dataset”全部为0。这是因为LLM无法给出答案。第二个和第三个问题的上下文精度为0,表明检索上下文中的相关上下文没有排在最前面。第二个问题的上下文召回为0,表明检索到的上下文与带注释的答案不匹配。
现在,我们来检查问题0至问题3。这些问题的答案相关性得分很高,表明答案和问题之间存在很强的相关性。此外,信度得分不低,这表明答案主要是从上下文推导或总结出来的,可以得出结论,答案不是由于LLM的幻觉而产生的。
此外,我们发现尽管我们的上下文相关性得分很低,gpt-3.5-turbo-16k (RAGAs的默认模型)仍然能够从中推断出答案。
从结果来看,这个基本的RAG系统显然还有很大的改进空间。
结论
一般来说,RAGAs为评估RAG提供了全面的指标,并提供了方便的调用。目前,RAG评价框架缺乏,RAGAs提供了一个有效的工具。
在调试RAGAs的内部源代码后,很明显RAGAs仍处于早期开发阶段。我们对其未来的更新和改进持乐观态度。