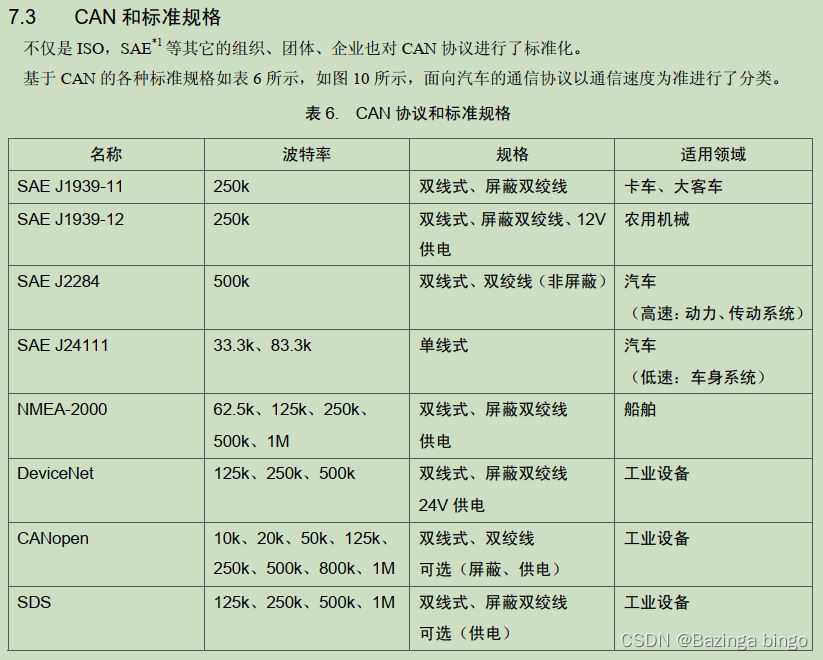
简介
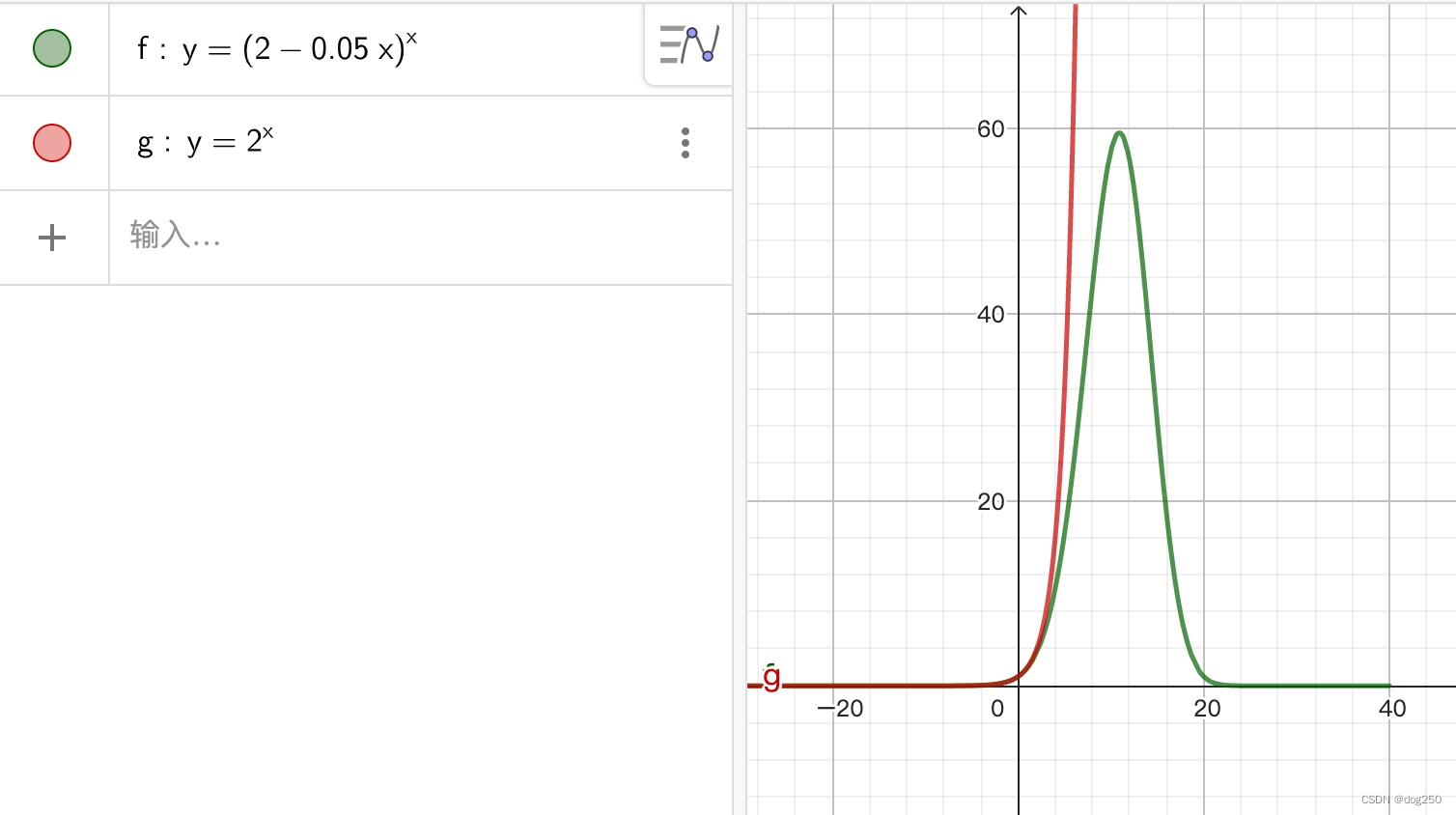
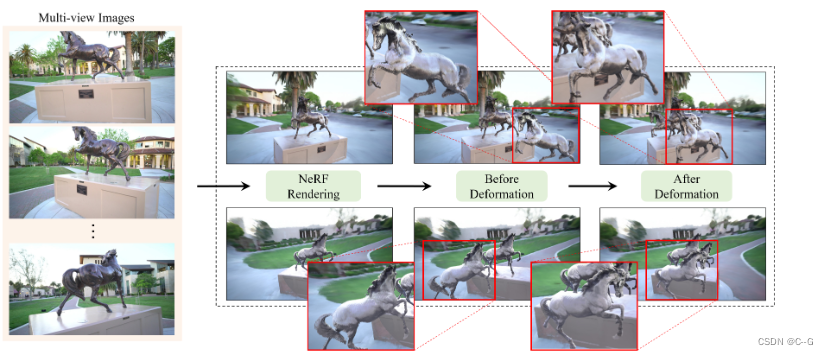
允许用户对场景的隐表示进行可控的形状变形,在不重新训练网络的情况下合成编辑过的场景的新视图图像。在提取的显式网格表示(Mesh)和目标场景的隐式神经表示之间建立了对应关系,利用基于网格的变形方法(ARAP)对场景的网格表示进行变形,通过引入一个四面体网格作为代理,利用用户编辑的网格表示来弯曲相机光线,借助NeRF新颖的视图合成能力,用户可以可视化来自任意视图的编辑结果。该方法适用于一般的真实场景,可以编辑场景对象,包括人体、动物、人造模型等。与以往NeRF编辑方法相比,该方法具有更高的自由度,能够支持细节编辑
基于网格的变形方法——ARAP

三维变形与编辑方法。
编辑三维模型意味着在用户给定的一些控制下对模型的形状进行变形。传统的网格变形方法是基于Laplacian坐标、泊松方程和对偶Laplacian坐标。其中代表性的ARAP (As- rigid -As- possible)变形是一种交互式网格编辑方法,通过保持局部变形的刚性来保持细节。另一种驱动网格变形的方法是通过代理,如骨架或笼子。这些方法需要计算代理和网格顶点之间的权重,并将代理的转换传播到网格。随着几何模型的普及,数据驱动变形成为可能,它分析数据集中现有形状的变形先验,并产生更真实的结果。同时,大量的数据也允许神经网络被引入到3D编辑中。除了显式的网格表示,隐式场也可以与神经网络结合进行编辑。Deng等人提出了变形隐场,它能够基于从物体类别学习到的信息建模密集的曲面对应和形状编辑。
实现流程
- 首先,从训练好的NeRF中提取一个显式的三角网格表示,用户可以直观地对显式网格表示进行变形
- 然后,基于三角网格表示构建四面体网格,利用三角网格的变形驱动四面体网格的变形,将场景几何表面的变形传播到空间离散变形场中
- 最后,利用四面体顶点插值完成离散变形场到连续变形场的传播,四面体网格的光线会随着连续的变形场发生相应的弯曲,从而使最终的绘制结果符合用户的编辑(通过插值直接将变形从三角网格转移到隐式体积会导致明显的伪影)
为了提升三角形网格重建质量,NeRF部分采用了NeuS进行SDF建模并通过Marching Cubes得到三角形网格。
三角形网格表示为 S, N ( i ) N(i) N(i)表示与顶点 i 相邻的顶点的索引集, V i ∈ R 3 V_i \in R^3 Vi∈R3表示为顶点 i 在网格 S 上的位置。用户编辑后,网格 S 被转换为具有相同连通性但顶点位置 v i v_i vi 不同的变形网格 S ′ S' S′。
总的ARAP变形能量是测量整个网格的刚性,是每个变形单元的变形能量的总和,包括顶点 i 及其1环邻居
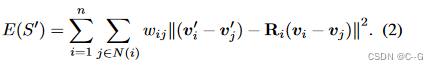
其中余切权值
W
i
j
=
1
2
(
c
o
t
a
i
j
+
c
o
t
β
i
j
)
W_{ij} = \frac{1}{2}(cot\ a_{ij} + cot \ \beta_{ij})
Wij=21(cot aij+cot βij),
a
i
j
,
β
i
j
a_{ij},\beta_{ij}
aij,βij是网格边 (i, j) 相对的角度,
R
i
R_i
Ri是顶点 i 的局部旋转,变形形状 S’ 是通过最小化ARAP能量得到的,该能量可以通过交替优化局部旋转
R
i
R_i
Ri 和变形位置
v
i
′
v'_i
vi′ 来有效求解。
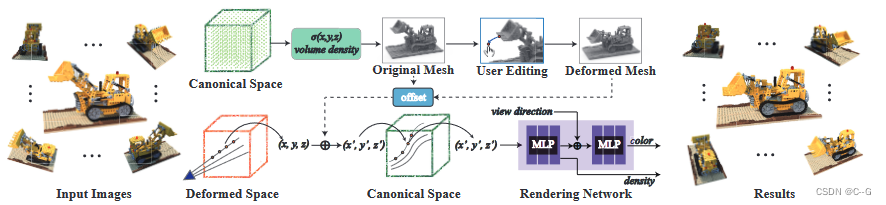
将变形转移到隐式体表示中
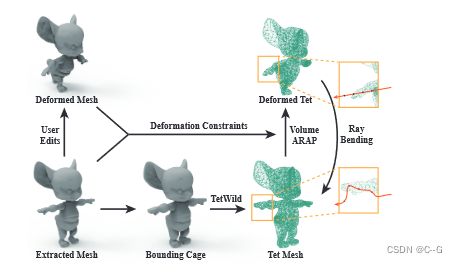
第一步建立一个四面体网格(一种离散体表示)来覆盖提取的三角网格 S
计算一个包裹三角形网格 S 的 cage 网格,通过在法线方向上与网格表面产生一定距离的偏移来实现,将默认值设置为从相机位置到对象中心平均距离的 5%。
cage 网格的内部空间可以看作是隐式体积的"有效空间",因为场景的近真实几何表面的面积被 cage 网格所包围。当编辑包含多个对象的大型场景时,这种设计还可以确保其他对象不受编辑的影响。
然后,采用TetWild四面体化方法对 cage 网格进行四面体化,得到一个四面体网格表示 T,提取的三角网格 S 也被包裹在四面体网格 T 中。
对提取的三角网格 S 和相应的四面体网格 T 进行可视化,利用三角网格顶点的位移 v i v_i vi 驱动四面体网格的变形 T,将三角变形转移到四面体网格,将变形后的四面体网格表示为 T ', t k t_k tk 和 t k ′ t'_k tk′ 分别表示变形前后四面体网格的顶点,其中 k 为顶点索引
使用ARAP变形方法对四面体网格 T 在曲面网格变形的约束下进行变形,公式2可以由三角形网格直接推广到四面体网格,唯一的区别是约束从用户指定的控制点更改为三角网格顶点。找到每个三角形网格顶点所在的四面体,并计算其相对于四面体四个顶点的重心坐标
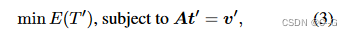
其中A为重心权重矩阵。利用拉格朗日乘子法将该优化问题转化为线性方程组
Ray Bending
曲面变形转换到四面体网格后,可以得到“有效空间”的离散变形场。利用这些离散的变换来弯曲投射光线。
为了生成变形辐射场的图像,将光线投射到包含变形四面体网格的空间中。对于光线上的每个采样点,找到它位于变形四面体网格的哪个四面体中。利用 T 和 T’ 之间的对应关系,可以得到变形后顶点与变形前顶点之间的位移。对采样点所在四面体的四个顶点的位移进行重心插值,可以得到采样点回到原始“有效空间”的位移 ∆p,将位移 ∆p 添加到采样点的输入坐标中,以预测密度和RGB值
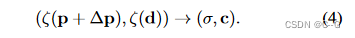
不在四面体网格 T′ 内的采样点不会被移动,即射线在四面体网格外的部分不会被弯曲
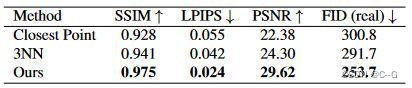
实验
与动态NeRF不同,在用户编辑后,很难获得新视图合成结果的真实情况,特别是在真实场景中,因为这种编辑后的场景实际上不存在,因此对mixamo中的特征进行定量和定性的评估
采用了以下几种评估指标
- Structural Similarity Index Measure (SSIM)
- Learned Perceptual Image Patch Similarity (LPIPS)
- Peak Signal-to-Noise Ratio (PSNR)
- Frechet Inception Distance [23] (FID)(衡量编辑前和编辑后结果之间的相似性)

局限
- 不能根据编辑结果来修改颜色和明暗
如果在捕捉过程中处于阴影中的物体部分变形面对光线,其颜色仍然是暗淡的,而不是明亮的 - 不能支持用户实时编辑
主要的时间瓶颈仍然存在于NeRF的渲染部分