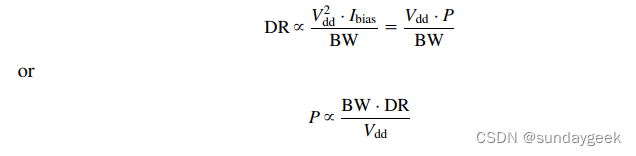0. 前言
最近公共祖先简称 LCA(Lowest Common Ancestor)。两个节点的最近公共祖先,就是这两个点的公共祖先里面,离根最远的那个。
这种算法应用很广泛,可以很容易解决树上最短路等问题。
为了方便,我们记某点集 S = { v 1 , v 2 , … , v n } S=\{v_1,v_2,\ldots,v_n\} S={v1,v2,…,vn} 的最近公共祖先为 LCA ( v 1 , v 2 , … , v n ) \text{LCA}(v_1,v_2,\ldots,v_n) LCA(v1,v2,…,vn) 或 LCA ( S ) \text{LCA}(S) LCA(S)。
部分内容参考 OI Wiki,文章中所有算法均使用C++实现。
例题:洛谷 P3379 【模板】最近公共祖先(LCA)
1. 性质
- LCA ( { u } ) = u \text{LCA}(\{u\})=u LCA({u})=u;
- u u u 是 v v v 的祖先,当且仅当 LCA ( u , v ) = u \text{LCA}(u,v)=u LCA(u,v)=u;
- 如果 u u u 不为 v v v 的祖先并且 v v v 不为 u u u 的祖先,那么 u , v u,v u,v 分别处于 LCA ( u , v ) \text{LCA}(u,v) LCA(u,v) 的两棵不同子树中;
- 前序遍历中, LCA ( S ) \text{LCA}(S) LCA(S) 出现在所有 S S S 中元素之前,后序遍历中 LCA ( S ) \text{LCA}(S) LCA(S) 则出现在所有 S S S 中元素之后;
- 两点集并的最近公共祖先为两点集分别的最近公共祖先的最近公共祖先,即 LCA ( A ∪ B ) = LCA ( LCA ( A ) , LCA ( B ) ) \text{LCA}(A\cup B)=\text{LCA}(\text{LCA}(A), \text{LCA}(B)) LCA(A∪B)=LCA(LCA(A),LCA(B));
- 两点的最近公共祖先必定处在树上两点间的最短路上;
- d ( u , v ) = h ( u ) + h ( v ) − 2 h ( LCA ( u , v ) ) d(u,v)=h(u)+h(v)-2h(\text{LCA}(u,v)) d(u,v)=h(u)+h(v)−2h(LCA(u,v)),其中 d d d 是树上两点间的距离, h h h 代表某点到树根的距离。
2. 求解算法
2.0 前置知识1:树的邻接表存储
简单来说,树的邻接表存储就是对于每个结点,存储其能通过一条有向或无向边,直接到达的所有结点。
传统的存储方式是使用链表(或模拟链表),这样实现比较麻烦,也容易写错。
此处为了更好的可读性我们使用STL中的可变长度顺序表vector。
#include <vector> // 需要使用STL中的vector
#define maxn 100005 // 最大结点个数
std::vector<int> G[maxn];
此时,若要添加一条无向边 u ↔ v u\leftrightarrow v u↔v,可使用:
G[u].push_back(v);
G[v].push_back(u);
若要添加 u → v u\to v u→v的有向边:
G[u].push_back(v);
遍历 v v v能直接到达的所有结点:
for(int u: G[v])
cout << u << endl;
2.1 前置知识2:DFS 遍历 & 结点的深度计算
对于两种算法,都需要预处理出每个结点的深度。
一个结点的深度定义为这个结点到树根的距离。
要预处理出所有结点的深度,很简单:
运用树形dp的方法,令
h
u
h_u
hu 表示结点
u
u
u 的深度,逐层向下推进:
#include <cstdio>
#include <vector>
#define maxn 100005
using namespace std;
vector<int> G[maxn]; // 邻接表存储
int depth[maxn]; // 每个结点的深度
void dfs(int v, int par) // dfs(当前结点,父亲结点)
{
int d = depth[v] + 1; // 子结点的深度=当前结点的深度+1
for(int u: G[v])
if(u != par) // 不加这条判断会无限递归
{
depth[u] = d; // dp更新子结点深度
dfs(u, v); // 往下dfs
}
}
int main()
{
// 构建一张图
// ...
// 假定图已存入邻接表G:
int root = 0; // 默认树根为0号结点,根据实际情况设置
dfs(root, -1); // 对于根结点,父亲结点为-1即为无父亲结点
return 0;
}
2.2 朴素算法
令 u , v u,v u,v 表示两个待求 LCA 的结点。需提前预处理出每个结点的父亲(记结点 v v v 的父亲为 f v f_v fv)。
算法步骤:
- 使 u , v u,v u,v 的深度相同:可以让深度大的结点往上走,直到与深度小的结点深度相同。
- 当 u ≠ v u\ne v u=v时: u ← f u , v ← f v u\gets f_u,v\gets f_v u←fu,v←fv。
- 循环直到 u = v u=v u=v,此条件成立后 u u u 和 v v v 的值即为我们要求的 LCA。
时间复杂度分析:
- 预处理:DFS 遍历整棵树, O ( N ) \mathcal O(N) O(N)
- 单次查询:最坏 O ( N ) \mathcal O(N) O(N),平均 O ( log N ) \mathcal O(\log N) O(logN)(随机树的高为 ⌈ log N ⌉ \lceil\log N\rceil ⌈logN⌉)
参考代码:
#include <cstdio>
#include <vector>
#include <algorithm>
#define maxn 500005
using namespace std;
vector<int> G[maxn];
int depth[maxn], par[maxn];
void dfs(int v)
{
int d = depth[v] + 1;
for(int u: G[v])
if(u != par[v])
{
par[u] = v, depth[u] = d;
dfs(u);
}
}
int lca(int u, int v)
{
if(depth[u] < depth[v])
swap(u, v);
while(depth[u] > depth[v])
u = par[u];
while(u != v)
u = par[u], v = par[v];
return u;
}
int main()
{
int n, q, root;
scanf("%d%d%d", &n, &q, &root);
for(int i=1; i<n; i++)
{
int u, v;
scanf("%d%d", &u, &v);
G[u].push_back(v);
G[v].push_back(u);
}
par[root] = -1, depth[root] = 0;
dfs(root);
while(q--)
{
int u, v;
scanf("%d%d", &u, &v);
printf("%d\n", lca(u, v));
}
return 0;
}
可以发现,程序在最后四个测试点上TLE了:

这是因为,这四个点是专门针对朴素算法设计的(正好是一个 Subtask),使算法的时间复杂度达到了最坏情况
O
(
N
Q
)
\mathcal O(NQ)
O(NQ),而
N
,
Q
≤
5
×
1
0
5
N,Q\le 5\times 10^5
N,Q≤5×105,所以无法通过测试点。当然,朴素算法在随机树上回答
Q
Q
Q 次询问的时间复杂度还是
O
(
N
+
Q
log
N
)
\mathcal O(N+Q\log N)
O(N+QlogN),被极端数据卡掉也没办法。
2.3 倍增
倍增算法是朴素算法的改进算法,也是最经典的 LCA 求法。
预处理:
- 令 fa x , i \text{fa}_{x,i} fax,i 表示点 x x x 的第 2 i 2^i 2i 个祖先。
- dfs 预处理深度信息时,也可以预处理出
fa
x
,
i
\text{fa}_{x,i}
fax,i:
- 首先考虑 i i i的范围: 2 i ≤ d x 2^i\le d_x 2i≤dx(前面说的, d x d_x dx 表示结点 x x x 的深度),所以有 0 ≤ i ≤ ⌊ log 2 d x ⌋ 0\le i\le \lfloor\log_2 d_x\rfloor 0≤i≤⌊log2dx⌋。
- 对于 i = 0 i=0 i=0, 2 i = 2 0 = 1 2^i=2^0=1 2i=20=1,所以直接令 fa x , 0 = ( x 的父亲 ) \text{fa}_{x,0}=(x\text{的父亲}) fax,0=(x的父亲) 即可。
- 对于
1
≤
i
≤
⌊
log
2
d
x
⌋
1\le i\le \lfloor\log_2 d_x\rfloor
1≤i≤⌊log2dx⌋,
x
x
x 的第
2
i
2^i
2i 个祖先可看作
x
x
x 的第
2
i
−
1
2^{i-1}
2i−1 个祖先的第
2
i
−
1
2^{i-1}
2i−1 个祖先(
2
i
−
1
+
2
i
−
1
=
2
i
2^{i-1}+2^{i-1}=2^i
2i−1+2i−1=2i),即:
fa x , i = fa fa x , i − 1 , i − 1 \text{fa}_{x,i}=\text{fa}_{\text{fa}_{x,i-1},i-1} fax,i=fafax,i−1,i−1
求解步骤:
- 使
u
,
v
u,v
u,v 的深度相同:计算出
u
,
v
u,v
u,v 两点的深度之差,设其为
y
y
y。通过将
y
y
y 进行二进制拆分,我们将
y
y
y 次游标跳转优化为「
y
y
y 的二进制表示所含
1的个数」次游标跳转(详见代码)。 - 特判:如果此时 u = v u=v u=v,直接返回 u u u 或 v v v 作为 LCA 结果。
- 同时上移 u u u和 v v v:从 i = ⌊ log 2 d u ⌋ i=\lfloor\log_2 d_u\rfloor i=⌊log2du⌋ 开始循环尝试,一直尝试到 0 0 0(包括 0 0 0),如果 fa u , i ≠ fa v , i \text{fa}_{u,i}\not=\text{fa}_{v,i} fau,i=fav,i,则 u ← fa u , i , v ← fa v , i u\gets\text{fa}_{u,i},v\gets\text{fa}_{v,i} u←fau,i,v←fav,i,那么最后的 LCA 为 fa u , 0 \text{fa}_{u,0} fau,0。
时间复杂度分析:
- 预处理: O ( N ) \mathcal O(N) O(N) DFS × O ( log N ) \times~\mathcal O(\log N) × O(logN) 预处理 = O ( N log N ) =\mathcal O(N\log N) =O(NlogN)
- 单次查询:平均 O ( log N ) O(\log N) O(logN),最坏 O ( log N ) O(\log N) O(logN)
- 预处理 + Q Q Q 次查询: O ( N + Q log N ) \mathcal O(N+Q\log N) O(N+QlogN)
另外倍增算法可以通过交换 fa 数组的两维使较小维放在前面。这样可以减少 cache miss 次数,提高程序效率。
参考代码:
#include <cstdio>
#include <vector>
#include <cmath>
#define maxn 500005
using namespace std;
vector<int> G[maxn];
int fa[maxn][19]; // 2^19=524288
int depth[maxn];
void dfs(int v, int par)
{
fa[v][0] = par;
int d = depth[v] + 1;
for(int i=1; (1<<i)<d; i++)
fa[v][i] = fa[fa[v][i - 1]][i - 1];
for(int u: G[v])
if(u != par)
depth[u] = d, dfs(u, v);
}
inline int lca(int u, int v)
{
if(depth[u] < depth[v])
u ^= v ^= u ^= v;
int m = depth[u] - depth[v];
for(int i=0; m; i++, m>>=1)
if(m & 1)
u = fa[u][i];
if(u == v) return u; // 这句不能丢
for(int i=log2(depth[u]); i>=0; i--)
if(fa[u][i] != fa[v][i])
u = fa[u][i], v = fa[v][i];
return fa[u][0];
}
int main()
{
int n, q, root;
scanf("%d%d%d", &n, &q, &root);
for(int i=1; i<n; i++)
{
int x, y;
scanf("%d%d", &x, &y);
G[--x].push_back(--y);
G[y].push_back(x);
}
depth[--root] = 0;
dfs(root, -1);
while(q--)
{
int u, v;
scanf("%d%d", &u, &v);
printf("%d\n", lca(--u, --v) + 1);
}
return 0;
}

3. 习题
- 题目链接:洛谷 P8805 [蓝桥杯 2022 国 B] 机房
- 题解:https://best-blogs.blog.luogu.org/solution-p8805
4. 总结
本文详细讲解了 LCA 问题以及求解 LCA 的两种算法。对比如下:
| 算法 | 预处理时间复杂度 | 单次查询时间复杂度1 | 空间复杂度 | 能否通过例题2? |
|---|---|---|---|---|
| 朴素算法 | O ( N ) \mathcal O(N) O(N) | O ( N ) \mathcal O(N) O(N) | O ( N ) \mathcal O(N) O(N) | ❌ |
| 倍增算法 | O ( N log N ) \mathcal O(N\log N) O(NlogN) | O ( log N ) \mathcal O(\log N) O(logN) | O ( N log N ) \mathcal O(N\log N) O(NlogN) | ✔️ |
创作不易,希望大家能给个三连,感谢支持!
此时间复杂度按照最坏情况计算。 ↩︎
例题:洛谷 P3379 【模板】最近公共祖先(LCA) ↩︎





![Isaac Sim 机器人仿真器介绍、安装与 Docker [1]](https://img-blog.csdnimg.cn/3ccf549e4387408f89b7b08d5acfb609.png)