flinkjob 提交流程
- 任务启动流程图
- 1客户端的工作内容
- 1.1解析命令
- 1.2 执行用户代码
- 2集群工作内容
- 2.2启动JobManager和 ResourceManager
- 2.3 申请资源 启动 taskmanager
- 3分配任务
- 3.1 资源计算
- 3.2 分发任务
- 4 Task 任务调度执行图
- 5 任务提交过程
- 总结

任务启动流程图
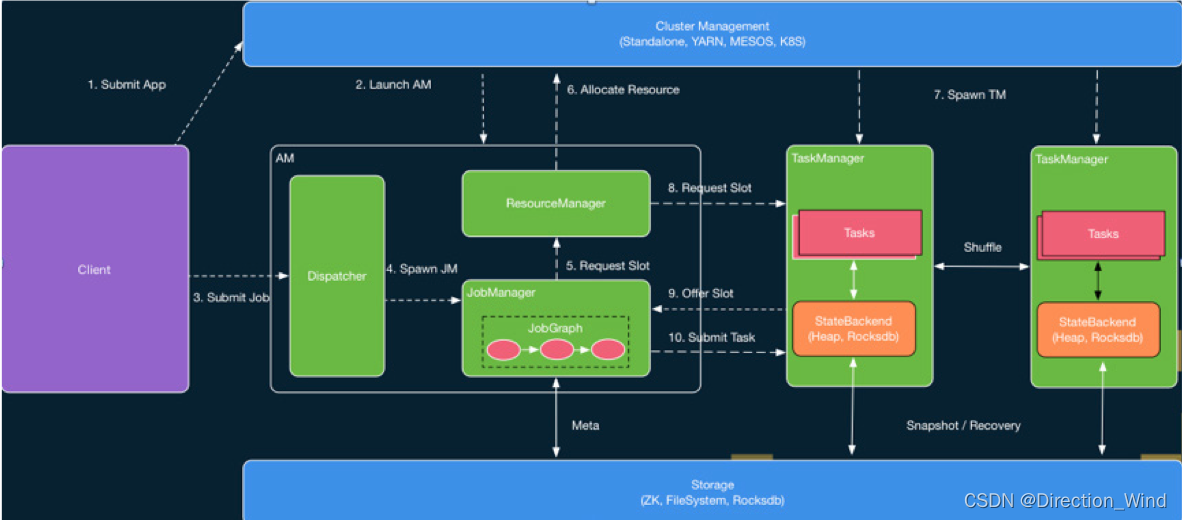
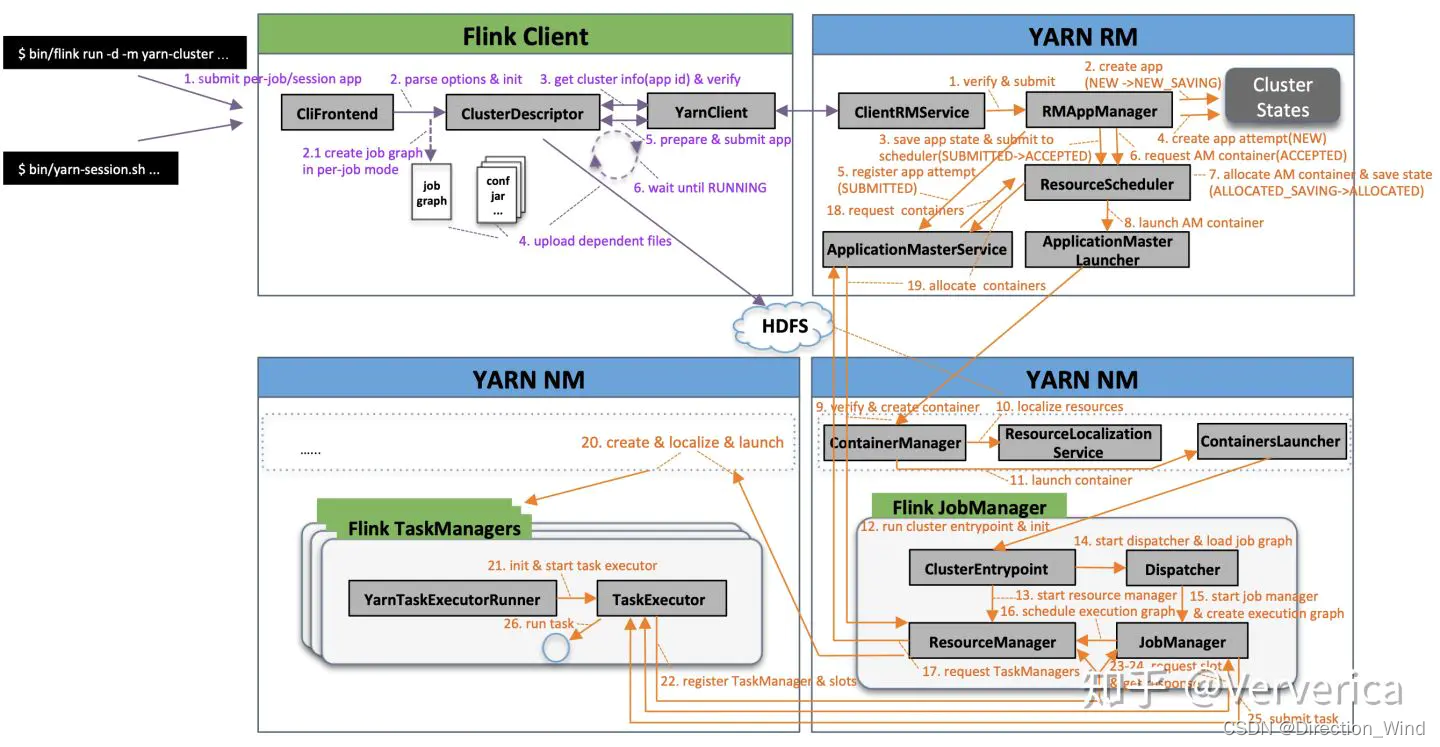
可以先简单看下流程图,对比下面详细说明,再回来看会更加清晰
1客户端的工作内容
1.1解析命令
- 第一步是命令行的解析,根据用户提交的 flink run 命令,在客户端类cliFronted中进行解析
- 通过空格与-c -m 等参数指令,提取出,用户提交的参数详情
- 获取flink的conf目录的路径
- 根据conf目录的路径,加载配置
- 加载命令行的输入 command line 封装命令行接口:按顺序 generic yarn default
- 获取run动作 默认的配置项
- 根据用户指定的配置项 进行解析
这个帖子是根据flink1.12来做的基础,所以对比以后的版本可能会有一点出入,但总的流程都是一致的,例如,flink1.12中 任务的启动模式 会根据提交命令中指定的是否是yarn,standalone等来封装一个 command line 提交给后面使用,如果用户没有指定,flink就会根据默认顺序generic yarn default 来封装这个flink任务的启动模式
1.2 执行用户代码
用户代码会从env.execute开始执行
- 从StreamExecutionEnvironment开始 execute
- 根据用户代码 ,调用的算子,生成streamgraph图
- streamgraph 转化 jobgraph
- yarnjobClusterExcutor 创建启动 yarnclient 包含了一些yarn flink的配置和环境信息,并构造了一个yarnClusterDescriptor
- yarnClusterDescriptor 获取集群特有配置 : jobmanager 内存 每个taskmanager 内存 每个 slot槽数
- 部署前检查: jar包路径 conf路径 yarn最大核数 检查置顶的yarn队列是否存在, 检查yarn有足够的资源
- yarn启动appmaster AM 通过startAppMaster
YarnClusterDescriptor.java
private ClusterClientProvider<ApplicationId> deployInternal(
ClusterSpecification clusterSpecification,
String applicationName,
String yarnClusterEntrypoint,
@Nullable JobGraph jobGraph,
boolean detached) throws Exception {
... ...
// 创建应用
final YarnClientApplication yarnApplication = yarnClient.createApplication();
... ...
ApplicationReport report = startAppMaster(
flinkConfiguration,
applicationName,
yarnClusterEntrypoint,
jobGraph,
yarnClient,
yarnApplication,
validClusterSpecification);
... ...
}
private ApplicationReport startAppMaster(
Configuration configuration,
String applicationName,
String yarnClusterEntrypoint,
JobGraph jobGraph,
YarnClient yarnClient,
YarnClientApplication yarnApplication,
ClusterSpecification clusterSpecification) throws Exception {
... ...
// 初始化文件系统(HDFS)
final FileSystem fs = FileSystem.get(yarnConfiguration);
... ...
ApplicationSubmissionContext appContext = yarnApplication.getApplicationSubmissionContext();
final List<Path> providedLibDirs = getRemoteSharedPaths(configuration);
// 上传文件的工具类
final YarnApplicationFileUploader fileUploader = YarnApplicationFileUploader.from(
fs,
fs.getHomeDirectory(),
providedLibDirs,
appContext.getApplicationId(),
getFileReplication());
... ...
final ApplicationId appId = appContext.getApplicationId();
... ...
if (HighAvailabilityMode.isHighAvailabilityModeActivated(configuration)) {
// yarn重试次数,默认2
appContext.setMaxAppAttempts(
configuration.getInteger(
YarnConfigOptions.APPLICATION_ATTEMPTS.key(),
YarnConfiguration.DEFAULT_RM_AM_MAX_ATTEMPTS));
activateHighAvailabilitySupport(appContext);
} else {
//不是高可用重试次数为1
appContext.setMaxAppAttempts(
configuration.getInteger(
YarnConfigOptions.APPLICATION_ATTEMPTS.key(),
1));
}
... ...
// 多次调用上传HDFS的方法,分别是:
// => systemShipFiles:日志的配置文件、lib/目录下除了dist的jar包
// => shipOnlyFiles:plugins/目录下的文件
// => userJarFiles:用户代码的jar包
fileUploader.registerMultipleLocalResources (... ...);
... ...
// 上传和配置ApplicationMaster的jar包:flink-dist*.jar
final YarnLocalResourceDescriptor localResourceDescFlinkJar = fileUploader.uploadFlinkDist(flinkJarPath);
... ...
//
fileUploader.registerSingleLocalResource(
jobGraphFilename,
new Path(tmpJobGraphFile.toURI()),
"",
true,
false);
... ...
// 上传flink配置文件
String flinkConfigKey = "flink-conf.yaml";
Path remotePathConf = setupSingleLocalResource(
flinkConfigKey,
fs,
appId,
new Path(tmpConfigurationFile.getAbsolutePath()),
localResources,
homeDir,
"");
... ...
// 将JobGraph写入tmp文件并添加到本地资源,并上传到HDFS
fileUploader.registerSingleLocalResource(
jobGraphFilename,
new Path(tmpJobGraphFile.toURI()),
"",
true,
false);
... ...
// 上传flink配置文件
String flinkConfigKey = "flink-conf.yaml";
fileUploader.registerSingleLocalResource(
flinkConfigKey,
new Path(tmpConfigurationFile.getAbsolutePath()),
"",
true,
true);
... ...
final JobManagerProcessSpec processSpec = JobManagerProcessUtils.processSpecFromConfigWithNewOptionToInterpretLegacyHeap(
flinkConfiguration,
JobManagerOptions.TOTAL_PROCESS_MEMORY);
//封装启动AM container的Java命令
final ContainerLaunchContext amContainer = setupApplicationMasterContainer(
yarnClusterEntrypoint,
hasKrb5,
processSpec);
... ...
appContext.setApplicationName(customApplicationName);
appContext.setApplicationType(applicationType != null ? applicationType : "Apache Flink");
appContext.setAMContainerSpec(amContainer);
appContext.setResource(capability);
... ...
yarnClient.submitApplication(appContext);
... ...
}
2集群工作内容
2.1 启动AM
- 初始化文件系统
- 封装appcontext 一些环境信息 appid
- yarn应用的文件上传器初始化: fs hdfs路径
- 配置appid zk的namespace,高可用重试次数 id
2.2启动JobManager和 ResourceManager
- ApplicationMaster启动dispatch和ResourceManager
- ResourceManager 中的 slotmanager 组件负责真正像yarn申请资源
- dispatch 启动 jobManager
- jobManage中的slotpool 负责真正发送请求
这么看来,在JobManager启动的过程中 主要发生了4个动作:
- 初始化各种服务initializeservices(…) 7个服务
- webMonitorEndpoint启动
- ResourceManager启动
- Dispatcher启动
以上四个动作全部完成,才算JobManager完成启动:下面是关键点的代码
其中 webMonitorEndpoint又启动了netty的服务端,一个leadership服务,这个服务里注册了几十个handler, 来接收客户端提交的命令,例如savepoint或停止指令等,他本身
其中ResourceManager 启动了两个心跳管理器,一个jobManagerHeartbeatManager,一个taskManagerHeartbeatManager
jobManagerHeartbeatManager -> jobmaster-ResourceManager
taskManagerHeartbeatManager -> taskManager-taskexecutor
每个job 都有一个jobmaster,jobmaster会被注册到ResourceManager,这些jobmaster会被维持与ResourceManager的心跳
ResourceManager还启动了两个定时服务,与taskmanager和slot相关,如果 taskmanager掉线或者slot分配超时,会参与一些处理。
//yarn启动入口 YarnApplicationClusterEntryPoint.java
public static void main(final String[] args) {
...
ClusterEntrypoint.runClusterEntrypoint(yarnApplicationClusterEntrypoint);
...
}
//ClusterEntrypoint.java
import org.apache.flink.runtime.webmonitor.retriever.impl.RpcMetricQueryServiceRetriever;
public static void runClusterEntrypoint(ClusterEntrypoint clusterEntrypoint) {
...
clusterEntrypoint.startCluster();
...
}
public void startCluster() throws ClusterEntrypointException {
...
runCluster(configuration, pluginManager);
...
}
private void runCluster(Configuration configuration, PluginManager pluginManager)
throws Exception {
synchronized (lock) {
initializeServices(configuration, pluginManager);
// write host information into configuration
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
关注!!!!!
final DispatcherResourceManagerComponentFactory
dispatcherResourceManagerComponentFactory =
createDispatcherResourceManagerComponentFactory(configuration);
clusterComponent =
dispatcherResourceManagerComponentFactory.create(
configuration,
resourceId.unwrap(),
ioExecutor,
commonRpcService,
haServices,
blobServer,
heartbeatServices,
metricRegistry,
executionGraphInfoStore,
关注!!!!!
new RpcMetricQueryServiceRetriever(
metricRegistry.getMetricQueryServiceRpcService()),
this);
clusterComponent
.getShutDownFuture()
.whenComplete(
(ApplicationStatus applicationStatus, Throwable throwable) -> {
if (throwable != null) {
shutDownAsync(
ApplicationStatus.UNKNOWN,
ShutdownBehaviour.GRACEFUL_SHUTDOWN,
ExceptionUtils.stringifyException(throwable),
false);
} else {
// This is the general shutdown path. If a separate more
// specific shutdown was
// already triggered, this will do nothing
shutDownAsync(
applicationStatus,
ShutdownBehaviour.GRACEFUL_SHUTDOWN,
null,
true);
}
});
}
}
各种初始化
protected void initializeServices(Configuration configuration, PluginManager pluginManager)
throws Exception {
LOG.info("Initializing cluster services.");
synchronized (lock) {
resourceId =
configuration
.getOptional(JobManagerOptions.JOB_MANAGER_RESOURCE_ID)
.map(
value ->
DeterminismEnvelope.deterministicValue(
new ResourceID(value)))
.orElseGet(
() ->
DeterminismEnvelope.nondeterministicValue(
ResourceID.generate()));
LOG.debug(
"Initialize cluster entrypoint {} with resource id {}.",
getClass().getSimpleName(),
resourceId);
workingDirectory =
ClusterEntrypointUtils.createJobManagerWorkingDirectory(
configuration, resourceId);
LOG.info("Using working directory: {}.", workingDirectory);
rpcSystem = RpcSystem.load(configuration);
commonRpcService =
RpcUtils.createRemoteRpcService(
rpcSystem,
configuration,
configuration.getString(JobManagerOptions.ADDRESS),
getRPCPortRange(configuration),
configuration.getString(JobManagerOptions.BIND_HOST),
configuration.getOptional(JobManagerOptions.RPC_BIND_PORT));
JMXService.startInstance(configuration.getString(JMXServerOptions.JMX_SERVER_PORT));
// update the configuration used to create the high availability services
configuration.setString(JobManagerOptions.ADDRESS, commonRpcService.getAddress());
configuration.setInteger(JobManagerOptions.PORT, commonRpcService.getPort());
ioExecutor =
Executors.newFixedThreadPool(
ClusterEntrypointUtils.getPoolSize(configuration),
new ExecutorThreadFactory("cluster-io"));
haServices = createHaServices(configuration, ioExecutor, rpcSystem);
blobServer =
BlobUtils.createBlobServer(
configuration,
Reference.borrowed(workingDirectory.unwrap().getBlobStorageDirectory()),
haServices.createBlobStore());
blobServer.start();
configuration.setString(BlobServerOptions.PORT, String.valueOf(blobServer.getPort()));
heartbeatServices = createHeartbeatServices(configuration);
metricRegistry = createMetricRegistry(configuration, pluginManager, rpcSystem);
final RpcService metricQueryServiceRpcService =
MetricUtils.startRemoteMetricsRpcService(
configuration,
commonRpcService.getAddress(),
configuration.getString(JobManagerOptions.BIND_HOST),
rpcSystem);
metricRegistry.startQueryService(metricQueryServiceRpcService, null);
final String hostname = RpcUtils.getHostname(commonRpcService);
processMetricGroup =
MetricUtils.instantiateProcessMetricGroup(
metricRegistry,
hostname,
ConfigurationUtils.getSystemResourceMetricsProbingInterval(
configuration));
executionGraphInfoStore =
createSerializableExecutionGraphStore(
configuration, commonRpcService.getScheduledExecutor());
}
}
2.3 申请资源 启动 taskmanager
- JobManager 将JobGraph 转换 ExcuetionGraph
- jobManager 中的slotpool 想 ResourceManager发出申请资源的请求
- jobManager 收到 ResourceManager中来自 yarn 的许可的请求回复后,会启动TaskManager
在整个TaskManager启动过程中,最重要的事情,就是在TaskManager初始化了一些基础服务和一些对外提供服务的核心服务之后就启动TaskExecutor,向ResourceManager 进行TaskManager的注册,并在注册成功之后,维持TaskManager和JobManager的心跳。
3分配任务
3.1 资源计算
其实这是2.3中的工作,在申请资源时,flink在生成StreamGraph时,会根据用户代码,来计算任务的并行度,并计算出所需多少个slot,根据系统配置的slot大小,来计算所需任务的内容大小
3.2 分发任务
- TaskManager启动后,TaskManager中 TaskExecutor 会像 resourceManager 注册slot
- TaskExecutor 收到 resourceManager回复的肯定分配指令后,会把resourceManager给过来的offset,给到JobMaster
- JobMaster 会提交具体的task到TaskExecutor
- 任务就启动了
4 Task 任务调度执行图

5 任务提交过程
在那么client的东西是如何提交到JobManager的呢?
- JobManager:
- WebMonitorEndpoint:维护了一个netty服务端,client通过RestClient 提交job(JobSubmitHandler)
- ResourceManager:资源集群的主节点
- Dispatcher:job的调度执行
- TaskManager:
- TaskExecutor:提供计算资源,注册给ResourceManager,维持心跳,执行JobMaster发送给他要执行的task
在JobSubmitHandler.java 是真正处理提交过来的东西的类。
JobSubmitHandler.java 集群入口
protected CompletableFuture<JobSubmitResponseBody> handleRequest(
@Nonnull HandlerRequest<JobSubmitRequestBody> request,
@Nonnull DispatcherGateway gateway){
//获取jobGraph requestBody 就是客户端通过RestClient 发来的。
CompletableFuture<JobGraph> jobGraphFuture = loadJobGraph(requestBody, nameToFile);
//通过dispatcher提交jobgraph
CompletableFuture<Acknowledge> jobSubmissionFuture =
finalizedJobGraphFuture.thenCompose(
jobGraph -> gateway.submitJob(jobGraph, timeout));
}
Dispatcher.java
//提交jobGraph 去执行
//重点1 创建Jobmaster jobGraph-> ExecutionGraph
private JobManagerRunner createJobMasterRunner(JobGraph jobGraph) throws Exception {
Preconditions.checkState(!jobManagerRunnerRegistry.isRegistered(jobGraph.getJobID()));
return jobManagerRunnerFactory.createJobManagerRunner(
jobGraph,
configuration,
getRpcService(),
highAvailabilityServices,
heartbeatServices,
jobManagerSharedServices,
new DefaultJobManagerJobMetricGroupFactory(jobManagerMetricGroup),
fatalErrorHandler,
System.currentTimeMillis());
}
//重点2 启动Jobmaster
private void runJob(JobManagerRunner jobManagerRunner, ExecutionType executionType)
throws Exception {
jobManagerRunner.start();
}
跑起来jobmaster相关服务,主要是注册和星跳
开始申请slot,并部署task
总结
- flink cliFronted类, 解析参数,封装commandLine, 执行用户代码生成streamGraph 并将streamGraph转化成JobGraph
- yarnjobClusterExcutor 初始化一个yarnclient对象,构造yarnClusterDescriptor
- yarnClusterDescriptor 将 依赖,jar,及其集群配置上传到Yarn Resource manager上
- yarn检查集群配置
- yarn的ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster。
- ApplicationMaster启动后加载Flink的Jar包和配置构建环境
- ApplicationMaster 启动 dispatch 和 ResourceManager(里面有slotmanager 真正管理资源向yarn申请资源的)
- dispatch 启动 JobMaster (里面有slotpool 真正发送请求的)
- JobMaster 将 JobGraph 转换 ExcuetionGraph
- JobMaster 向 Resourcemanager申请资源
- 启动JobManager之后ApplicationMaster向ResourceManager申请资源启动TaskManager。
- ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后 TaskExecutor 向 resourceManager 注册slot
- TaskExecutor 接收到分配的指令,提供offset给JobMaster
- JobMaster 提交具体的task 到 TaskExecutor
- JobManager 的 职 责 主 要 是 接 收 Flink 作 业 , 调 度 Task , 收 集 作 业 状 态 和 管 理TaskManager。
- TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请和管理。
具体Graph中如何转换的 可以参考 https://blog.csdn.net/Direction_Wind/article/details/121773408