📖 学习目标
- 自然语言处理(NLP)简介
- 探索自然语言处理的基本原理,理解其在ChatGPT中的应用。
- GPT模型概述
- 了解生成式预训练变换器(GPT)的工作原理。
✍️ 学习活动
学习资料
- 《走进AI(三) | 解构 NLP》—Process On
- 《一文看懂自然语言处理-NLP(4个典型应用+5个难点+6个实现步骤)》—微信公众号——AI科技在线
- 《AI产品经理必修课:NLP技术原理与应用》—人人都是产品经理——Alan
- 《基于深度学习的人机对话系统原理及应用》—客户世界——宁雪莉
- 《GPT》—GitHub——Paddlepaddle
学习笔记
自然语言处理(NLP)基础知识
-
NLP的定义
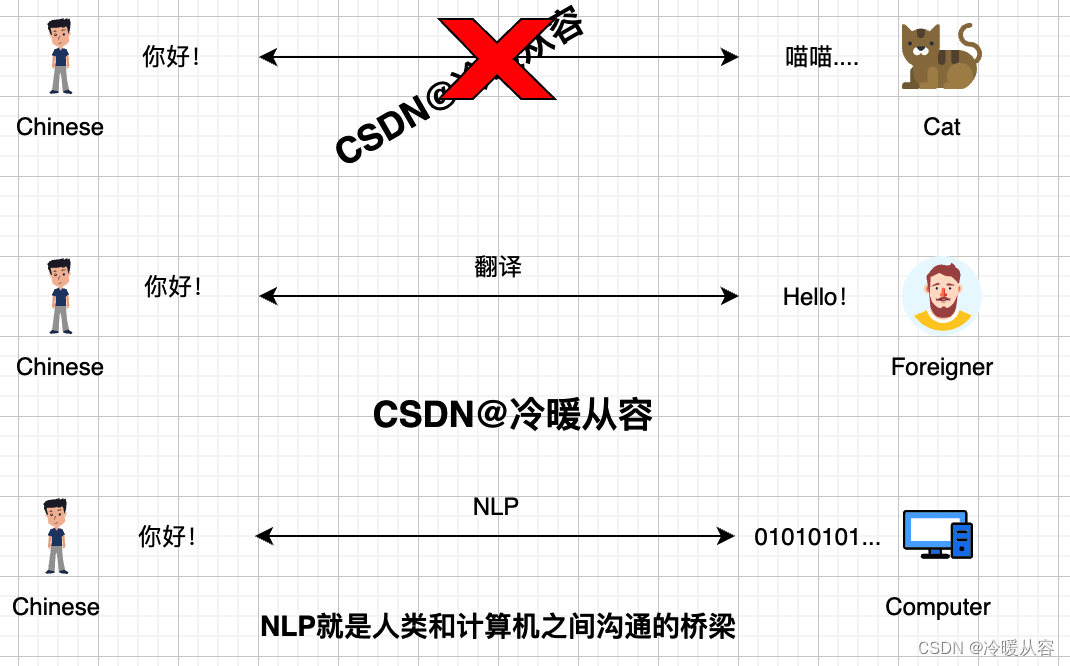
自然语言处理( Natural Language Processing, NLP)指的是能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言就是大家平时在生活中常用的表达方式,大家平时说的「讲人话」就是这个意思。
-
NLP的组成
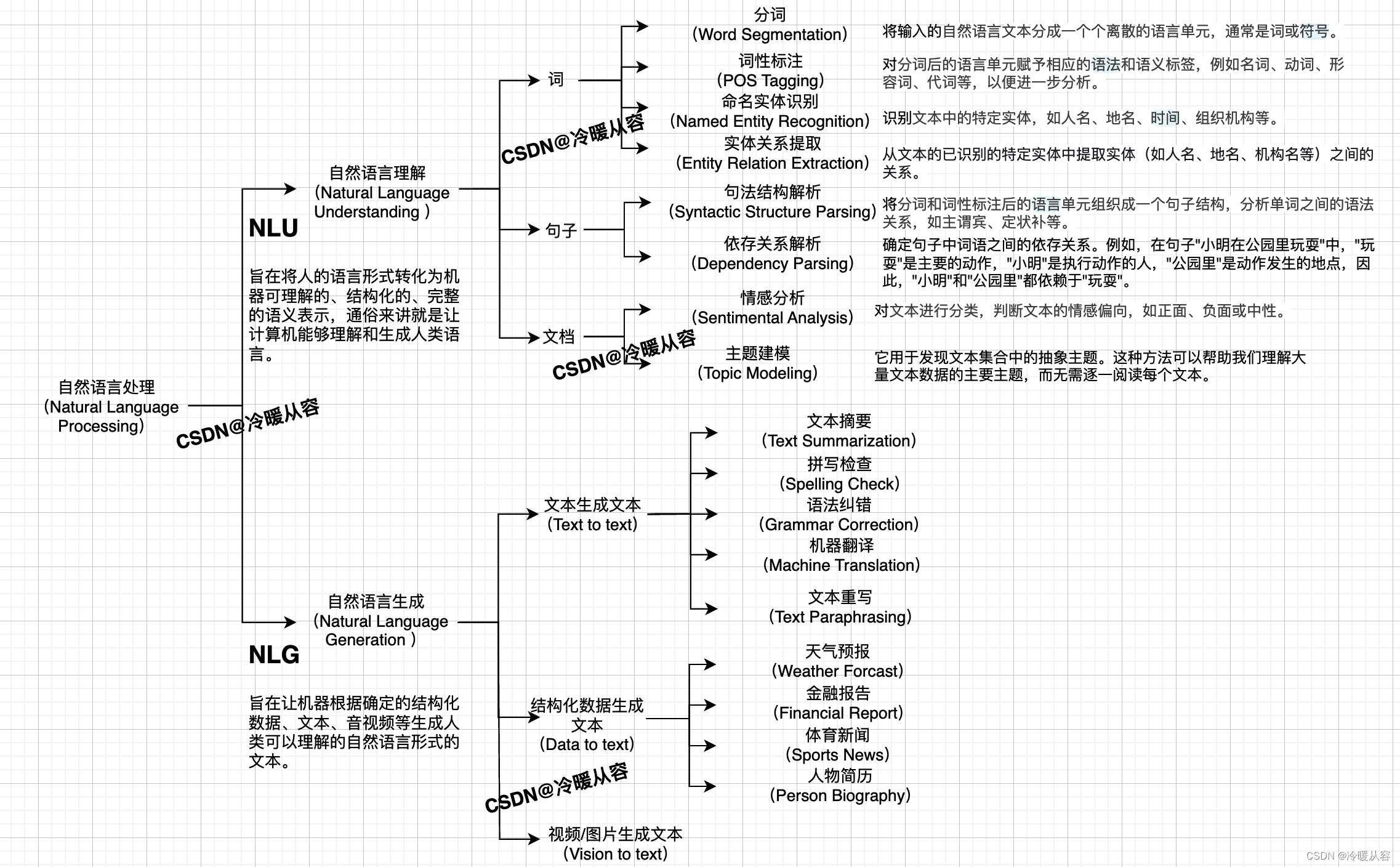
NLP 由两个主要的技术领域构成:自然语言理解(NLU)和自然语言生成(NLG)。主要包含的技术领域如下图所示。
-
NLP的工作原理
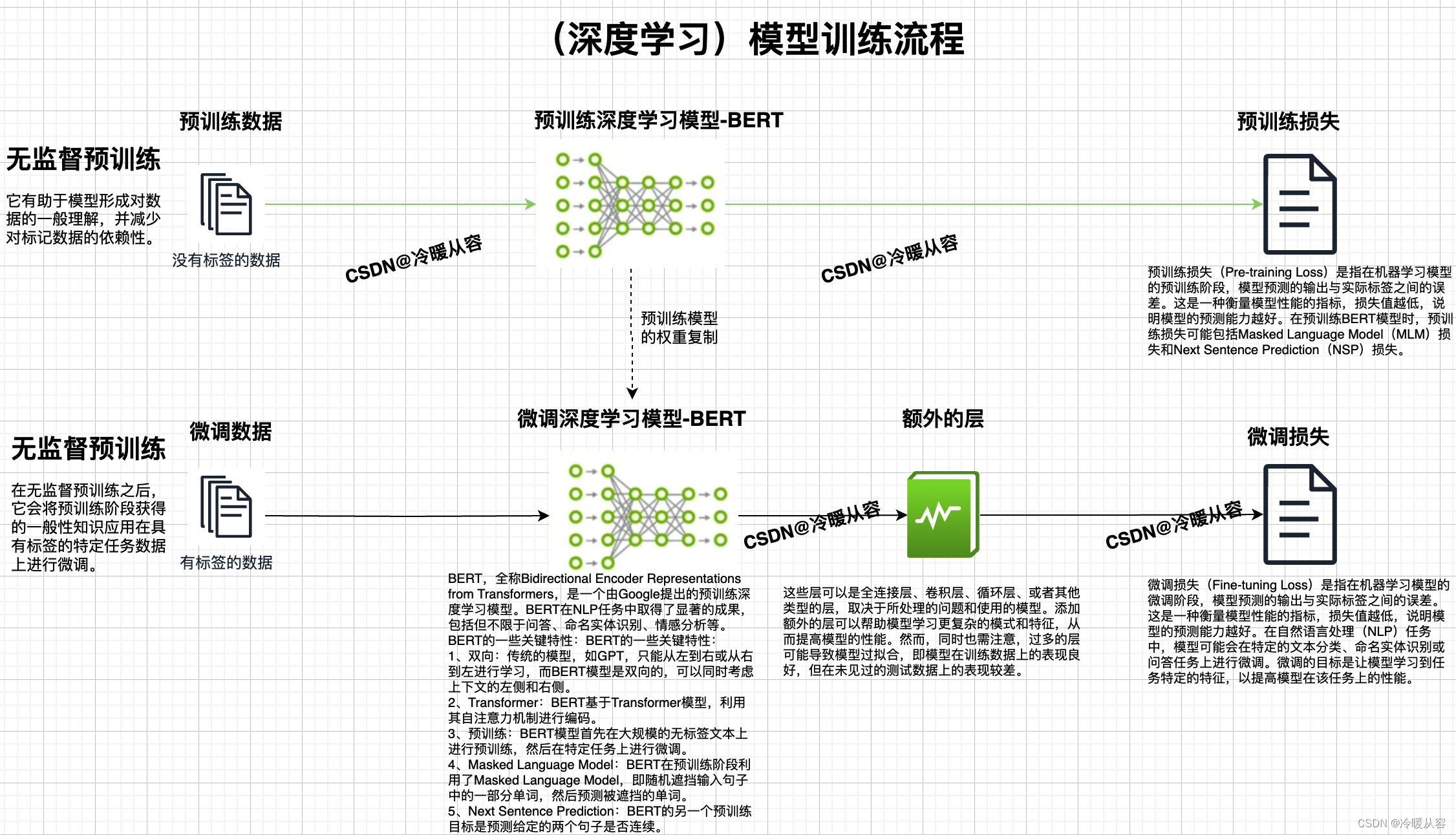
NLP工作原理分为这几步:首先,我们会对文本进行预处理,这个过程包括清理文本、切分词语、提取词干以及标注词性,以便将原始文本数据转化为更适合模型处理的形式。接着,我们会提取文本的特征,将文本转化为数值形式,使得模型可以处理。然后,我们会基于这些特征训练各种机器学习或深度学习模型。一旦模型训练完成,我们就可以用它对新的数据进行预测,并使用各种评估指标来评估模型的性能。最后,我们将训练好的模型应用于各种NLP任务,如文本分类、情感分析、命名实体识别、关键词提取、机器翻译、语音识别、聊天机器人等。下图是自然语言处理的核心技术和处理流程以及深度学习模型的训练流程。

-
NLP在ChatGPT中的应用
NLP是一系列使计算机能够理解、处理和生成人类语言的技术,而ChatGPT正是这些技术的一个应用实例。ChatGPT是一个聊天机器人,它使用了NLP中的深度学习模型——特别是Transformer模型——来理解和生成文本。这个模型在大量的文本数据上进行训练,学习如何用人类语言进行有效的交流。下图是NLP在ChatGPT对话实例中的作用。
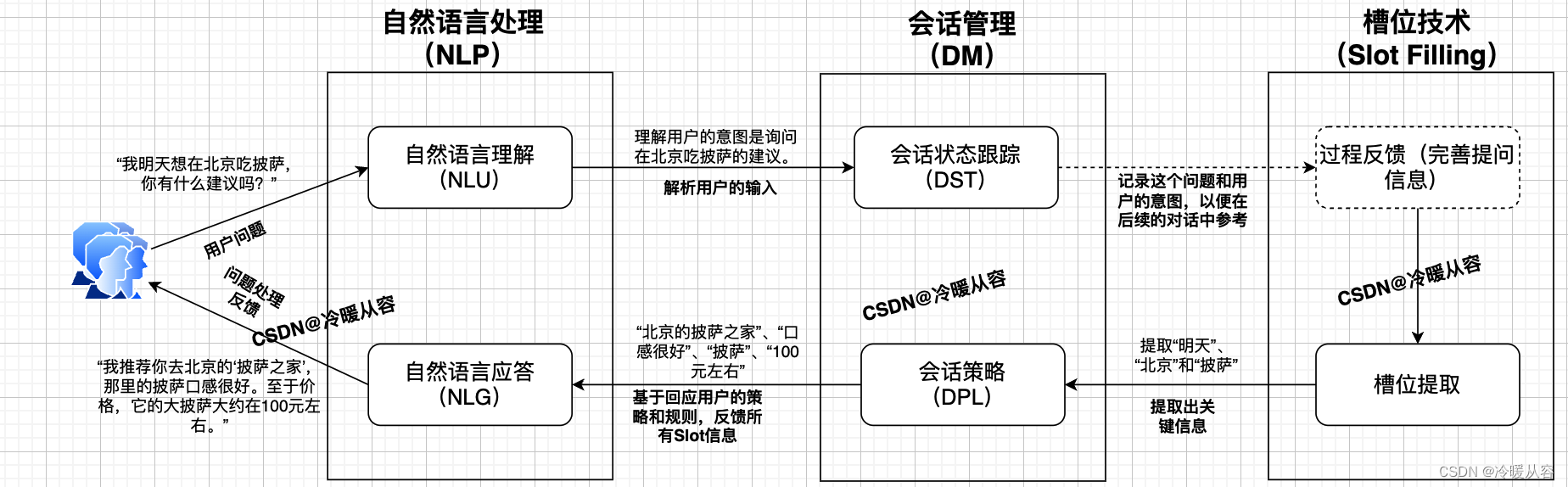
GPT模型概述
- GPT模型的定义
GPT(Generative Pre-training Transformer)是由OpenAI开发的一个自然语言处理模型。该模型使用了一种称为Transformer的深度学习模型,该模型最初是由Google的研究者在“Attention is All You Need”这篇论文中提出的。 GPT 模型是用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。 - Transformer模型与GPT模型之间的关系
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention(即每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward),如下图所示。
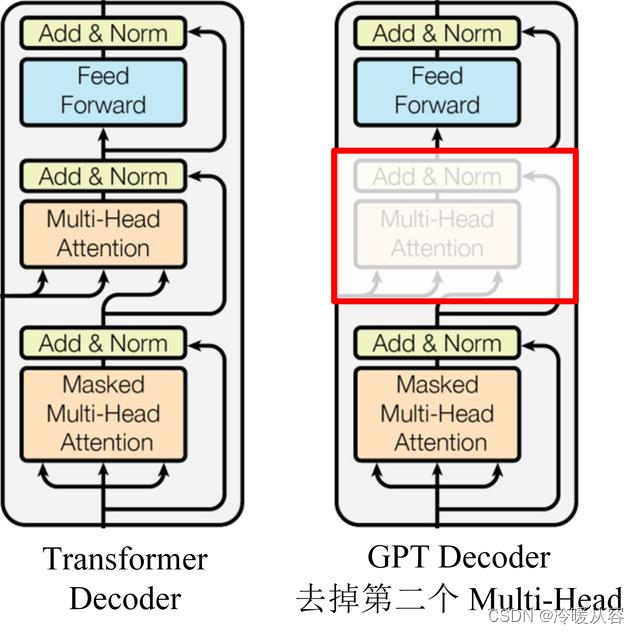
GPT模型仅仅使用了Transformer模型中的解码器部分,原因是语言模型的目标是利用已知的文本(上文)来预测下一个单词。在解码器中使用的是一种名为"Masked Multi Self-Attention"的技术,这种技术会屏蔽输入序列中未来的信息,也就是说在预测一个单词时,模型无法看到它后面的单词,从而模仿了语言模型的行为。然后,因为GPT模型只使用了解码器,没有使用编码器,所以它不需要使用到编码器和解码器之间的注意力机制,这种注意力机制在Transformer模型中是用来帮助解码器理解输入序列的。
- GPT模型结构图
下图是GPT模型的结构图。
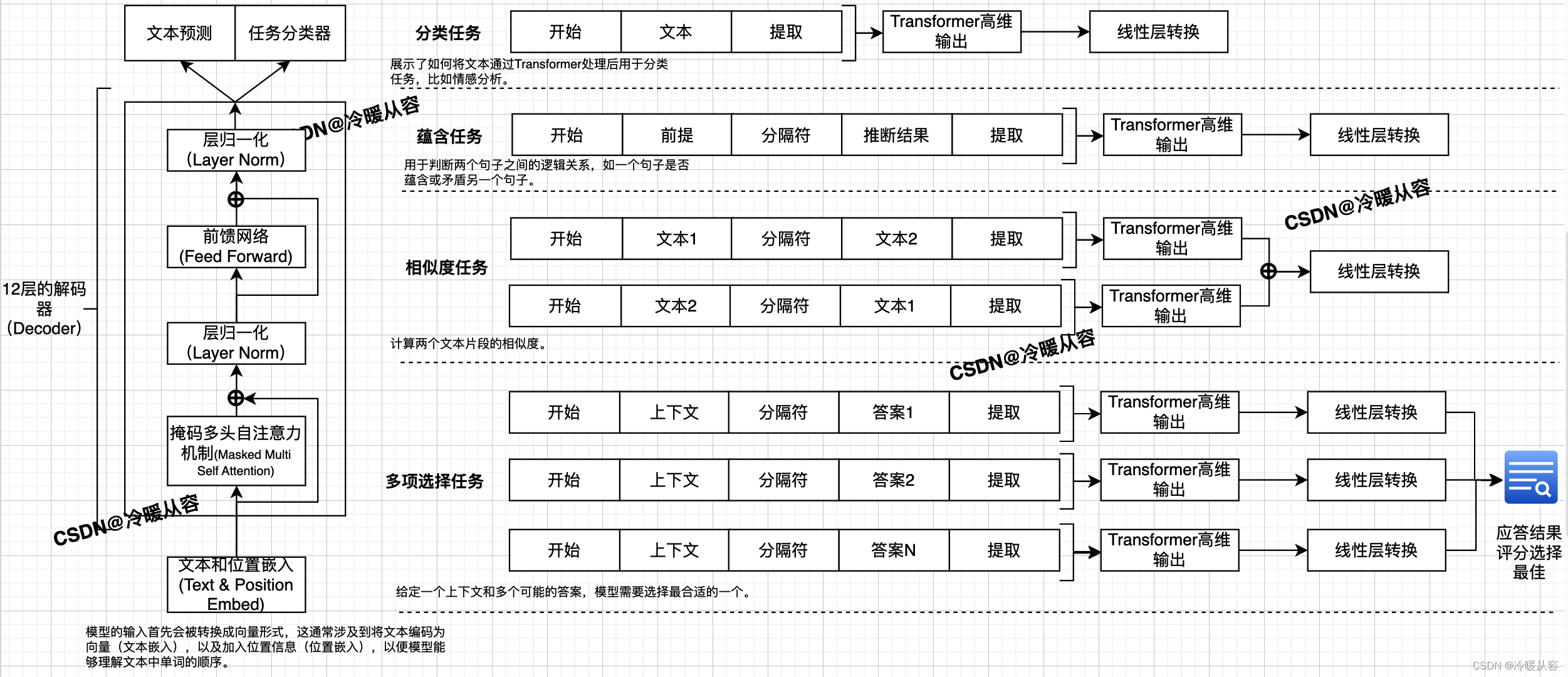






![[计算机网络]---TCP协议](https://img-blog.csdnimg.cn/direct/be3fa3072e824e848ecc1234837c4a1c.png)