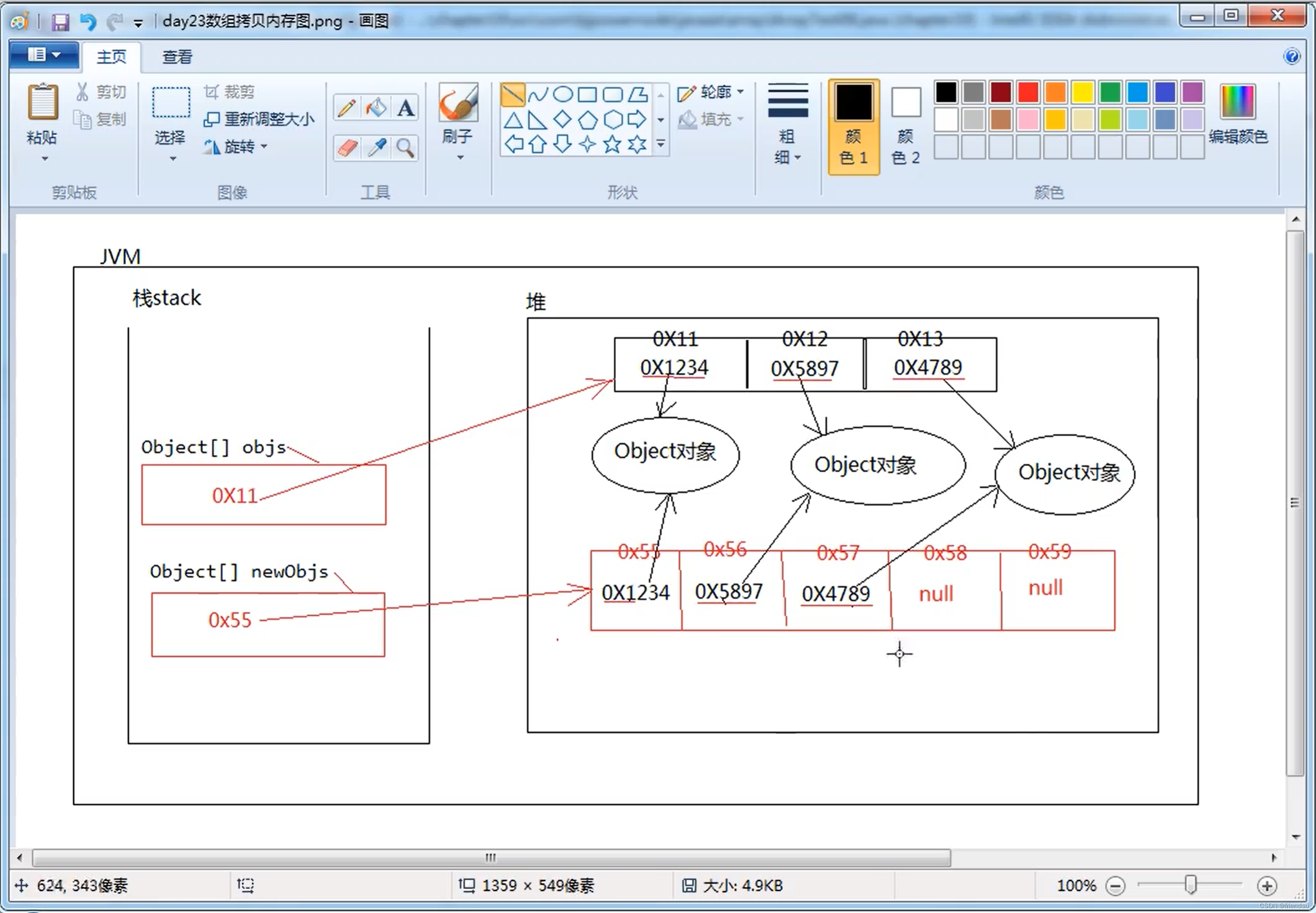
第一章、如何分析代码的执行效率和资源消耗
我们知道,数据结构和算法解决的是“快”和“省”的问题,也就是如何让代码运行得更快,一级如何让代码更节省计算机的存储空间。因此,执行效率是评价算法好坏的一个非常重要的指标。那么,如何衡量算法的执行效率尼?这里就要用到我们本节要讲的内容:时间复杂度分析和空间复杂度分析。
一、复杂度分析的意义
我们把代码运行一遍,通过监控和统计手段,就能得到算法执行的时间和占用的内存大小,为什么还要做时间复杂度分析,空间复杂度分析呢?这种“纸上谈兵”似的分析方法比实实在在地运行一遍代码得到的数据更准确吗?
实际上,这是两种不同的评估算法执行效率的方式。对于运行代码来统计复杂度的方法,很多有关数据结构和算法的图书还给它起了一个名字:事后统计法。这种统计方法看似可以给出非常精确的数值,但是却有非常大的局限性。
1、测试结果受测试环境的影响很大
在测试环境中,硬件的不同得到的测试结果会有很大的差异。例如,我们用同样一段代码分别在安装了Intel Core i9处理器(CPU)和Intel Core i3处理器的计算机上运行,显然,代码在安装了Intel Core i9处理器的计算机上要比在安装了Intel Core i3处理器的计算机上的执行速度快得多。又如,在某台机器上,a代码执行的速度比b代码快,当我们换到另外一台配置不同的机器上时,可能会得到截然相反的运行结果。
2、测试结果受测试数据的影响很大
我们会在后续章节详细讲解排序算法,这里用它进行举例说明。对同一种排序算法,待排序数据的有序度不一样,排序执行的时间会有很大的差别。在极端情况下,如果数据已经是有序的,那么有些排序算法不需要做任何操作,执行排序的时间就会非常短。除此之外,如果测试数据规模太小,那么测试结果可能无法真实地反应算法的性能。例如,对于小规模的数据排序,插入排序反而比快速排序快!
因此,我们需要一种不依赖具体的测试环境和测试数据就可以粗略地估计算法执行效率的方法。这就是本节要介绍的时间复杂度分析和空间复杂度分析。
二、大O复杂度表示法
如何在不运行代码的情况下,用“肉眼”分析代码后得到一段的执行时间尼?下面用一段非常简单的代码来举例,看一下如何估算代码的执行时间。求1~n的累加和的代码如下所示:
public static int cumulativeSum(int n){
int result = 0;
for (int i = 1; i <= n; i++){
result += i;
}
return result;
}从在CPU上运行的角度来看,这段代码的每一条语句执行类似的操作:读数据--运算--写数据。尽管每一条语句对应的执行时间不一样,但是,这里只是粗略估计,我们可以假设每条语句执行的时间一样,为unit_time。在这个假设的基础上,这段代码的总执行时间是多少尼?
执行第2,6行代码分别需要1个unit_time的执行时间;第3,4行代码循环运行了n遍,需要 2n x unit_time的执行时间。因此,这段代码的总执行时间为(2n + 2) x unit_time的执行时间。通过上面的举例分析,我们得到一个规律:一段代码的总的执行时间为T(n)(例子中的(2n + 2) x unit_time)与每一条语句的执行次数(累加数)(例子中的2n + 2)成正比。
按照这个分析思路,我们再来看另一段代码,如下所示:
public static int cal(int n){
int sum = 0;
int i = 1;
int j;
for (; i <= n; i++){
j = 1;
for (; j <= n; j++){
sum = sum + (i * j);
}
}
return sum;
}依旧假设每条语句的执行时间为unit_time,那么这段代码的总的执行时间是多少尼?
对于第2,3,4,11行代码,每行代码需要1个unit_time的执行时间。第5,6行代码循环执行了n遍,需要2n x unit_time的执行时间。第7,8行代码循环执行了n²遍,需要2n² x unit_time的执行时间。因此,整段代码总的执行时间为T(n) = (2n² + 2n + 4) x unit_time。尽管我们不知道unit_timede 具体值,而且,每一条语句执行时间unit_time可能都不尽相同,但是,通过这两段代码执行时间的推导过程,可以得到一个非常重要的规律:
一段代码的执行时间T(n)与每一条语句总的执行次数(累加数)成正比。
我们可以把这个规律总结成一个公式,如下所示:
T(n) = O(f(n))
下面具体解释一下公式。其中,T(n)表示代码执行的总时间;n表示数据规模;f(n)表示每条语句执行次数的累加和,这个值与n有关,因此用f(n)这样一个表达式来表示;公式中的O这个符号,表示代码的执行时间T(n) 与 f(n)成正比。
套用这个大O表示法,第一个例子中的T(n) = (2n + 2) x unit_time = O(2n + 2),第二个例子中的T(n) = (2n² + 2n + 4) x unit_time = O(2n² + 2n + 4)。实际上,大O时间复杂度并不具体表示代码真正的执行时间,而是表示代码执行时间随着数据规模增大的变化趋势,因此,也称为渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
当n很大时,读者可以把它想象成10000,100000,公式中的低阶,常量,系数3部分并不控制增长趋势,因此可以忽略。我们只需要记录一个最大量级。如果用大O表示法表示上面的两段代码的时间复杂度,就可以记为:T(n) = O(n) 和 T(n) = O(n²)。
补充知识:
在数学中,我们经常会听到关于“高阶”、“低阶”、“常量”和“系数”的术语。让我来解释一下:
高阶(High-order):在多项式或函数中,高阶项是指指数较高的项。例如,在多项式 axn+bxn−1+cxn−2+…axn+bxn−1+cxn−2+… 中,axnaxn 就是高阶项,nn 是高阶项的指数。通常来说,当 nn 越大,该项的影响就越显著,因此被称为“高阶”。
低阶(Low-order):与高阶相对应,低阶项是指指数较低的项。在上面的多项式中,bxn−1bxn−1 和 cxn−2cxn−2 就是低阶项。这些项的影响相对较小,因为它们的指数较低。
常量(Constant):常量是没有包含任何变量的项,它们是数学表达式中的固定值。在多项式 axn+bxn−1+cxn−2+…+daxn+bxn−1+cxn−2+…+d 中,dd 就是常量项。
系数(Coefficient):系数是与变量相乘的数字或参数。在多项式 axn+bxn−1+cxn−2+…axn+bxn−1+cxn−2+… 中,aa、bb 和 cc 都是各自项的系数。系数决定了每个变量项的影响程度,它们可以是实数、复数或其他数学结构的成员。
在一个多项式中,通常高阶项对函数的整体形状和行为有着更显著的影响,而低阶项和常量则在更小的尺度上调整函数的细节。系数则决定了每个项的具体贡献。系数决定了变量的比例关系和对整个公式的影响程度。它们可以改变公式的斜率、曲线形状和整体大小。
三、时间复杂度分析方法
前面介绍了时间复杂度的由来和表示方法。现在,我们介绍一下如何分析一段代码的时间复杂度。下面讲解两个比较实用的法则:加法法则和乘法法则。
1、加法法则:代码总的复杂度等于量级最大的那段代码的复杂度
大O复杂度表示方法只表示一种变化趋势。我们通常会忽略公式中的常量,低阶和系数,只记录最大量级。因此,在分析一段代码的时间复杂度的时候,我们也只需要关注循环执行次数最多的那段代码。
我们来看下面这样一段代码。读者可以先试着分析一下这段代码的时间复杂度,然后与作者分析的思路进行比较,看看思路是否一致。
public static int cal1(int n){
int sum_1 = 0;
int p = 1;
for (; p <= 100; ++p){
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q <= n; ++q){
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i){
j = 1;
for (; j <= n; ++j){
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}复杂度分析:
- 2 2 * 100
- 2 2 * n
- 3 2 * n 2 * n^2
- 1
2 * n^2 + 4 * n + 208
上述这段代码分为4部分,分别是求sum_1,sum_2,sum_3,以及对这3个数求和。我们分别分析每一部分代码的时间复杂度,然后把它们放到一起,再取一个量级最大的作为整段代码的时间复杂度。
求sum_1这部分代码的时间复杂度是多少尼?因为这部分代码循环执行了100次(p=100,一直不变,p是个常量),所以执行时间是常量。
这里要再强调一下,即便这段代码循环执行10000次或100000次,只要是一个已知的数,与数据规模n无关,这也是常量级的执行时间。回到大O时间复杂度的概念,时间复杂度表示的是代码执行时间随数据规模(n)的增长趋势,因此,无论常量级的执行时间多长,它本身对增长趋势没有任何影响,在大O复杂度表示法中,我们可以将它(常量)忽略。
求sum_2,sum_3,以及对这3个数求和这三部分代码的时间复杂度分别是多少尼?答案是O(n),O(n²),常量。读者应该很容易就分析出来,就不在赘述了。
综合这4部分代码的时间复杂度,我们取其中最大的量级,因此,整段代码的时间复杂度就为O(n²)。也就是说,总的时间复杂度等于量级最大的那部分代码的时间复杂度。这条法则就是加法法则,用公式表示出来,如下所示:
如果:
T1(n) = O(f(n)); T2(n) = O(g(n))
那么:
T(n) = T1(n) + T2(n) = max(O(f(n)), O(g(n))) = O(max(f(n), g(n)))
2、乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
我们刚讲了复杂度分析中的加法法则,再来看一下乘法法则,如下所示:
如果:
T1(n) = O(f(n)); T2(n) = O(g(n))
那么:
T(n) = T1(n) X T2(n) = O(f(n))X O(g(n)) = O(f(n) X g(n))
也就是说:假设T1(n) = O(n),T2(n) = O(n²),则T1(n) X T2(n) = O(n³)。落实到具体的代码上,我们可以把乘法法则看成嵌套循环。我们通过例子来解释一下,如下所示
public static void cal(int n){
int ret = 0;
int i = 1;
for (; i <= n; i++){
ret = ret + f(i);
}
}
private static int f(int n) {
int sum = 0;
int i = 1;
for (; i <= n; i++){
sum += i;
}
return sum;
} 
我们单独观察上述代码中的cal()函数,在cal()函数的时间复杂度为T1 = O(n),f()函数的时间复杂度为T2(n) = O(n),则总的时间复杂度为T(n) = T1(n) X T2(n) = O(n X n) = O(n²)。
四、几种常见的时间复杂度量级
虽然代码千差万别,但常见的时间复杂度量级并不多。简单总结一下,如图所示,这个涵盖了读者今后可以接触的绝大部分的时间复杂度量级。
计算数量级通常是对一个数的大小进行粗略估计,以确定它属于哪个数量级。这种估计可以通过以下步骤进行:
将数写成科学计数法:将数写成形如 a×10ba×10b 的形式,其中 1≤a<101≤a<10 是尾数,bb 是指数。例如,1234 可以写成 1.234×1031.234×103。
确定尾数 aa 的范围:确定尾数 aa 的范围。通常来说,aa 范围在 1 到 10 之间。
确定指数 bb 的值:指数 bb 表示了数值在数量级上的大小。例如,103103 表示数值在数量级上是千级别的。
确定数量级:根据指数 bb 的值来确定数量级。例如,bb 为 3 表示数值在数量级上是千级别的。
举例来说,假设有一个数值是 6.78×1056.78×105。尾数 aa 是 6.78,指数 bb 是 5。因为 bb 是 5,所以这个数值在数量级上是百万级别的。
注意,计算数量级是一个近似值的过程,因此结果可能不是精确的,但通常足够用于粗略估计
一、时间复杂度
时间复杂度是指执行算法所需要的计算工作量
时间复杂度是用来衡量算法执行时间随着输入大小增加而增加的程度的一个度量。它表示算法的运行时间与输入数据的大小之间的关系。
在计算时间复杂度时,通常考虑最坏情况下的运行时间,因为这能够给出算法的最差执行时间保证。时间复杂度用大O符号表示,通常写作O(f(n)),其中n表示输入大小,f(n)是一个函数,它描述了算法执行所需的时间与n的关系。
例如,一个具有时间复杂度O(n)的算法表示,当输入大小增加n倍时,它的运行时间也将增加n倍。而一个具有时间复杂度O(n^2)的算法表示,当输入大小增加n倍时,它的运行时间将增加n的平方倍。
时间复杂度的计算可以帮助我们选择合适的算法来解决特定问题,并预测算法在实际应用中的性能表现。通常来说,我们会选择具有较低时间复杂度的算法,尤其是当处理大量数据时。
二、空间复杂度
而空间复杂度是指执行这个算法所需要的内存空间。
空间复杂度是衡量算法空间利用率的度量标准,也就是算法在执行过程中所需要的存储空间大小。
在计算空间复杂度时,通常会考虑以下几个因素:
算法本身所需要的空间:例如程序中定义的变量、数组、对象等。
输入数据所占用的空间:例如在排序算法中,需要占用额外的数组空间来存储输入数据。 算法执行过程中所占用的空间:例如在递归算法中,每个递归调用都需要分配额外的栈空间。
空间复杂度通常用大O符号(O)表示,与时间复杂度类似。例如,如果一个算法的空间复杂度为O(n),则它所需要的存储空间与输入数据的大小n成正比。
在实际应用中,除了考虑算法的时间复杂度之外,也需要考虑空间复杂度。对于内存有限的嵌入式系统或移动设备等场景,空间复杂度的控制非常重要,因为过高的空间复杂度会导致程序崩溃或无法运行。


![[计算机网络]---TCP协议](https://img-blog.csdnimg.cn/direct/be3fa3072e824e848ecc1234837c4a1c.png)