paper:An Intriguing Failing of Convolutional Neural Networks and the CoordConv Solution
official implementation:https://github.com/uber-research/coordconv
存在的问题
本文揭示并分析了CNN在两种不同类型空间表示之间转换能力的欠缺:从密集笛卡尔表示到稀疏基于像素的表示。虽然这种转换似乎对网络来说很容易学习,但实验结果表明比预计要困难,至少当网络由如若干卷积层组成时是这样的。虽然直接堆叠卷积层擅长于图像分类等任务,但对于坐标转换来说它们不是正确的模型。
作者首先设计了一个数据集Not-so-Clever dataset并在这个数据集上进行模型坐标转换能力的实验。这个数据集是Sort-of-CLEVER数据集的单一目标、灰度版本,具体是在一个64x64的画布上放置9x9的方块,方块完整的落在画布内因此方块中心点可能落入的区域大小为56x56,遍历中心点所有可能的位置得到一个包含3136样本的数据集,对于每个样本 \(i\),数据集包含三个字段:
- \(C_{i}\in\mathbb{R}^2\),其中心位置的笛卡尔坐标 \((x,y)\)
- \(P_{i}\in\mathbb{R}^{64\times 64}\),中心点像素的one-hot表示
- \(I_{i}\in\mathbb{R}^{64\times 64}\),64x64的图像,其中9x9的方块在上面
这3136张图片按两种方式划分为训练集和测试集:uniform,所有可能的位置随机按80/20分成训练集和测试集;quadrant,按象限划分,三个象限作为训练集,另一个象限作为测试集。样本以及划分示例如图2

The CoordConv Layer
本文提出的CoordConv是对标准卷积层的一个简单延伸,这里只考虑二维的情况。卷积在很多任务中都表现良好可能是由于下面三个因素:学习参数较少、在GPU上计算快、具有平移不变性。CoordConv保留了前两个特性,但是允许网络根据任务需要学习保留或丢弃第三点即平移不变性。丢弃平移不变性似乎会阻碍网络学习可泛化函数的能力,但在后续实验中可以看到,分配少量的网络容量来建模问题的non-translation invariant非平移不变性可以得到一个更容易训练的模型并且泛化能力更强。
CoordConv的具体实现很简单:增加额外的通道,其中填充的是对应位置的坐标(常数,不参与训练),然后与输入沿通道维度concatenate,然后接一个普通卷积层。图3展示了二维坐标 \(i,j\) 的情况。
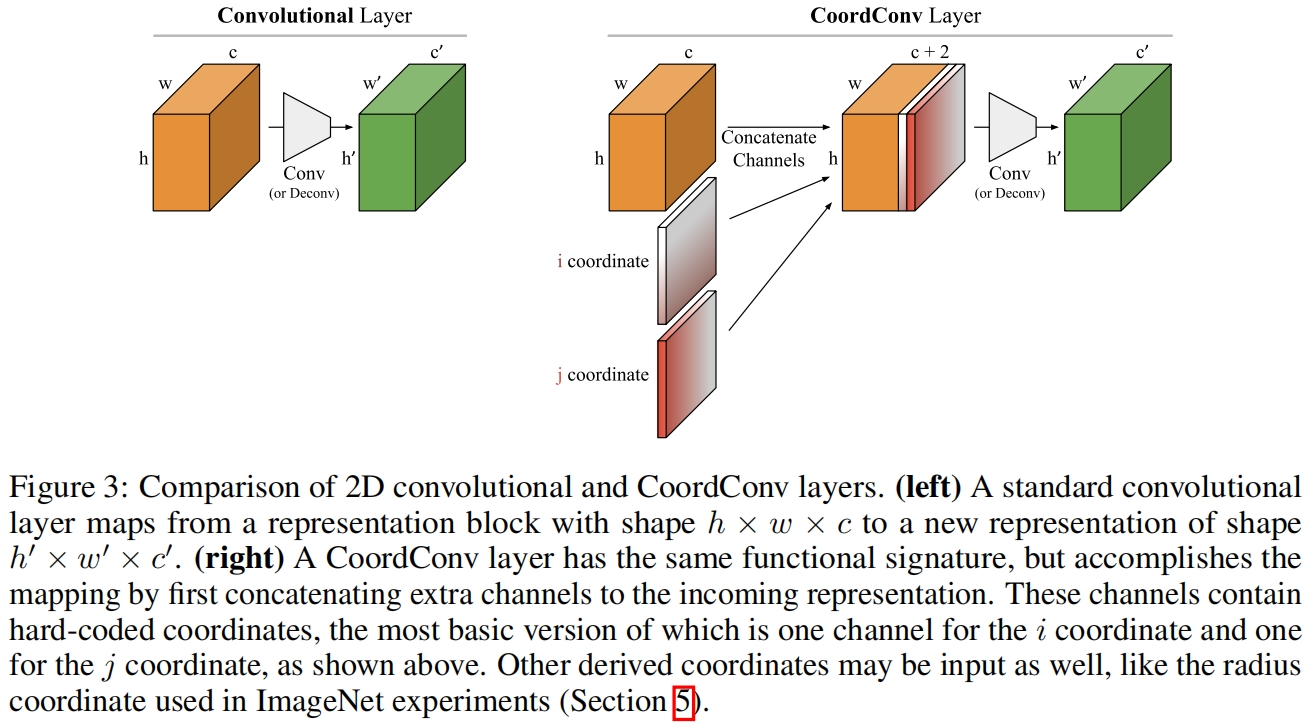
后续实验中,坐标 \(i,j\) 都进行了归一化使它们落入[-1, 1]范围内。
Supervised Coordinate tasks
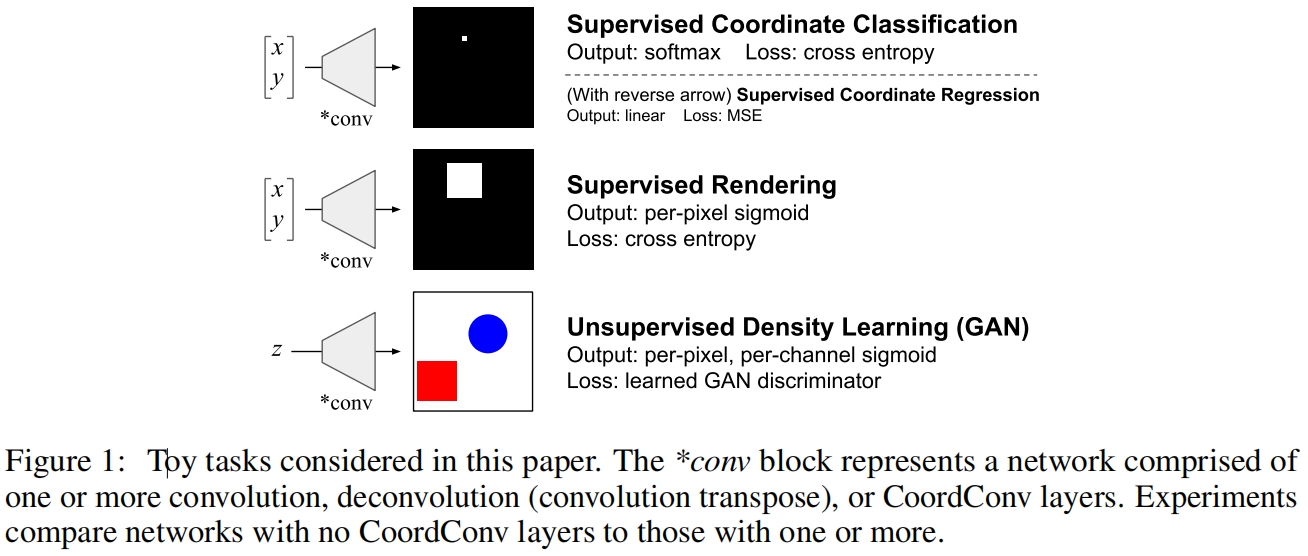
Supervised Coordinate Classification
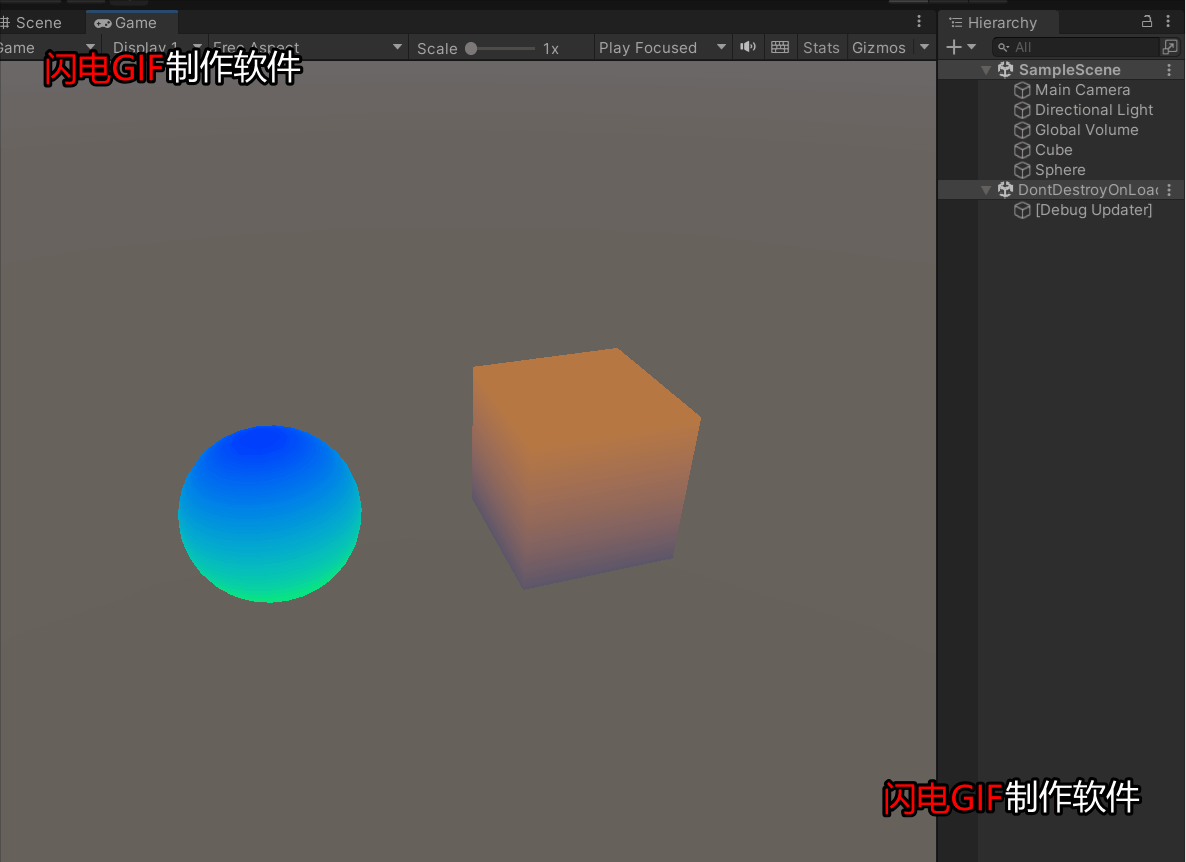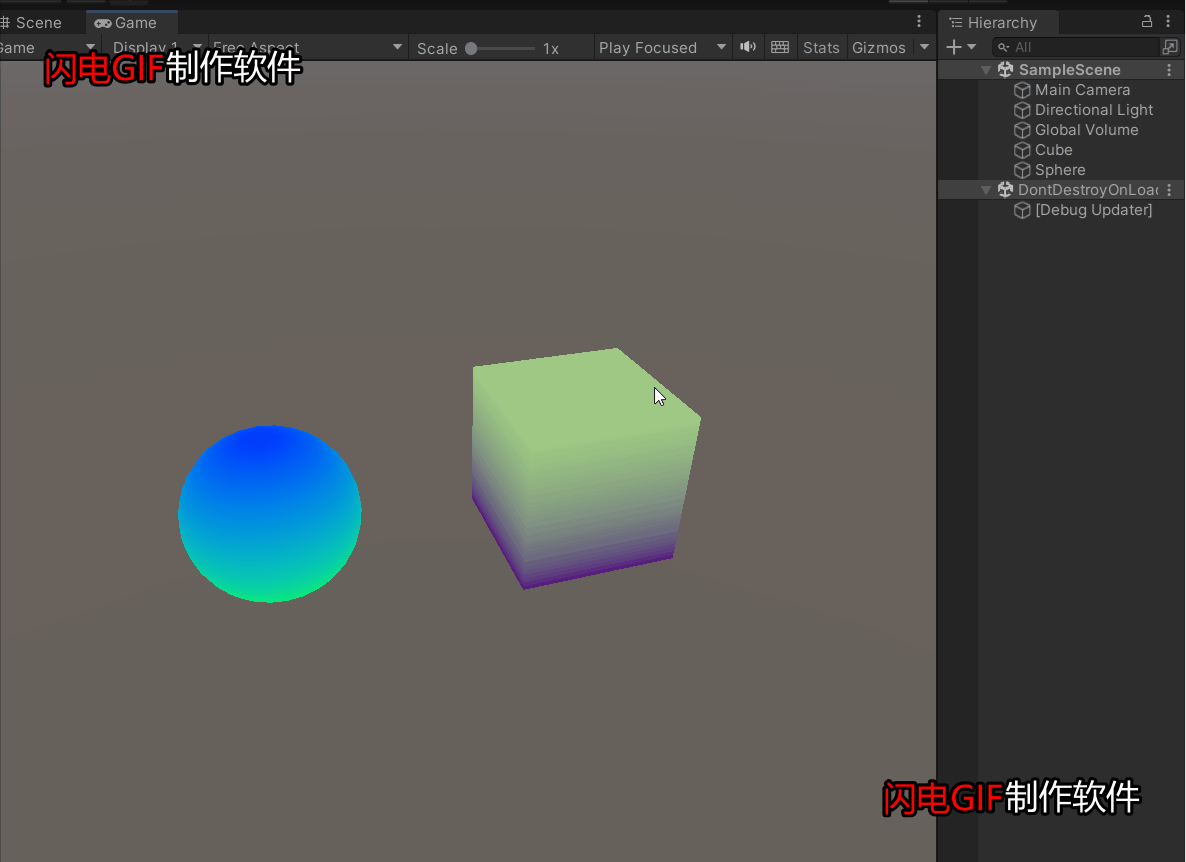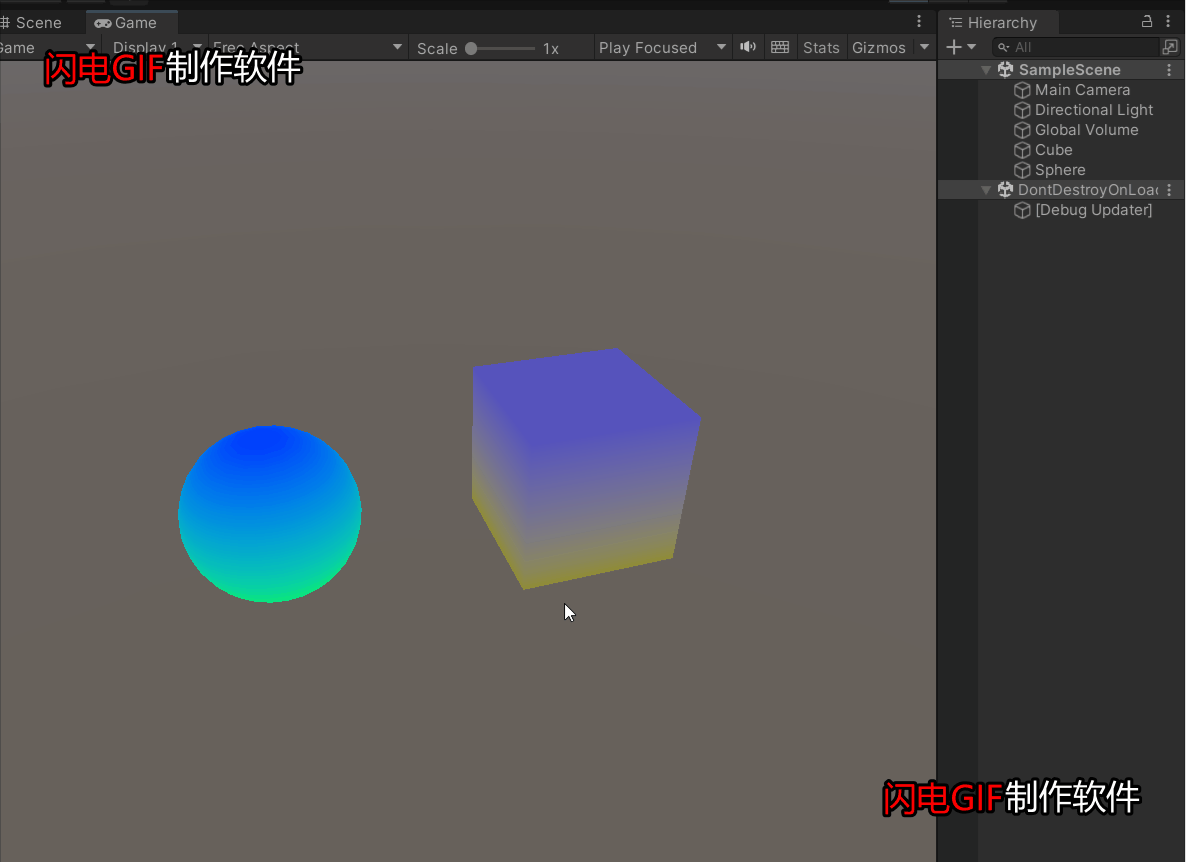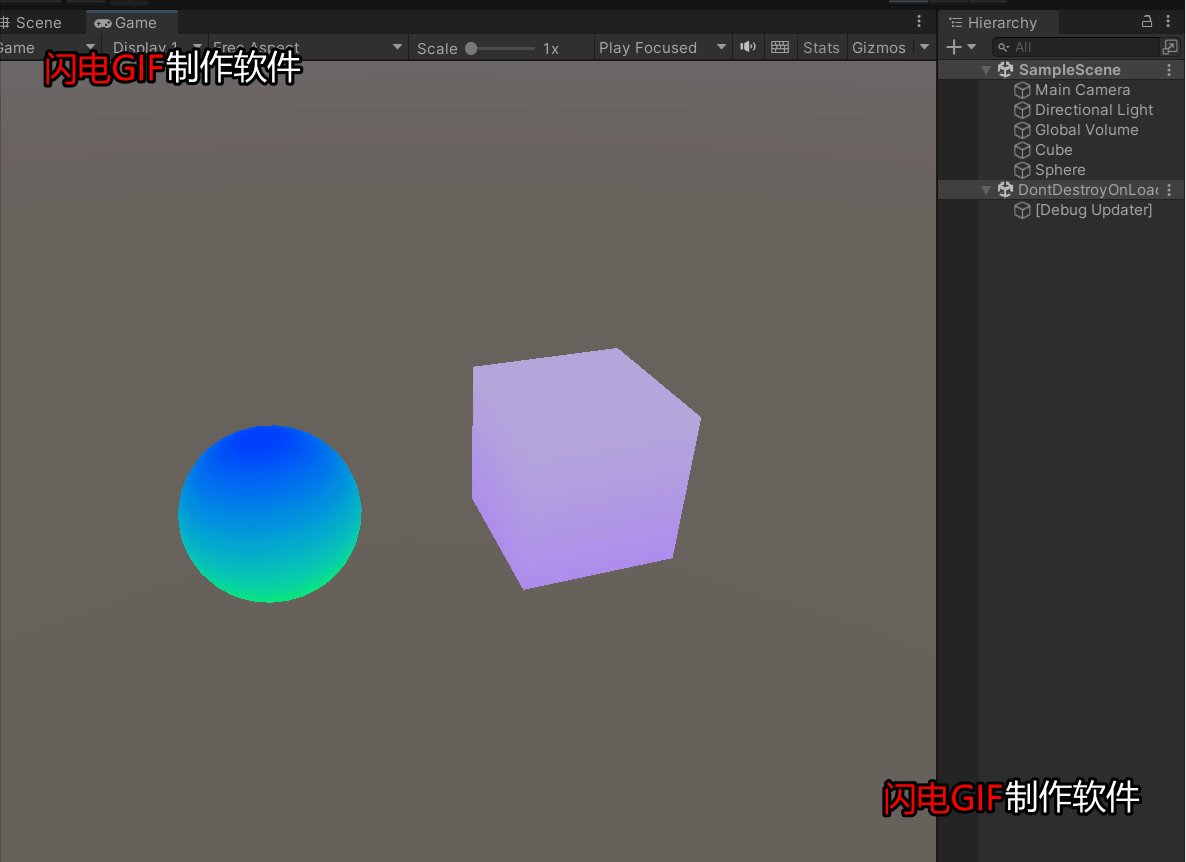
第一个也是最简单的任务是监督坐标分类,如图1上所示,输入为坐标 \((x,y)\),网络需要学习绘制正确的输出坐标。这是一个简单的多分类问题,每个像素位置为一个类别。

图4展示的是两种划分方式下训练集精度 vs.测试集精度。网络结构如下所示,包含6个stride=2的转置卷积。

在uniform划分数据集上,模型有一定的泛化能力,但最高的测试精度为86%,远没有达到100%。由此作者得到了第一个惊人的结论:即使在监督训练下,对卷积网络来说,学习一个从 \((x,y)\) 到one-hot像素的平滑函数是困难的。此外,训练卷积网络达到86%的精度需要一个小时,200k的参数。在quadrant划分数据集上,卷积网络根本无法泛化,图5展示了训练集和测试集预测结果的总和,可以直观地看出卷积模型的记忆能力和泛化能力的欠缺。

相反CoordConv在两个划分数据集上都获得了完美的性能,只需要7.5k的参数和10-20s的训练时间。参数的简约进一步验证了它是更适合坐标转换任务的模型。
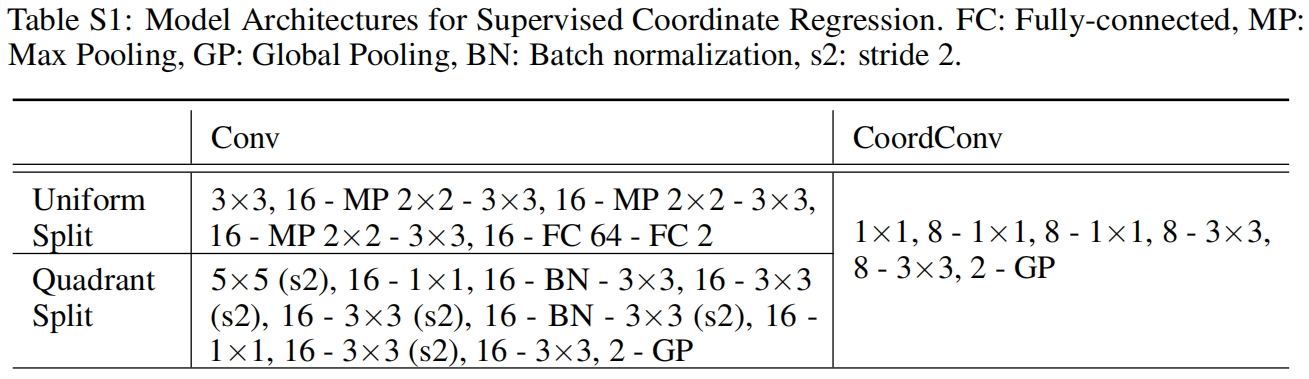
Supervised Coordinate Regression
由于学习由笛卡尔坐标转换为基于像素的坐标非常困难,作者又研究了相反的转换是否同样困难。作者尝试了不同的卷积网络结构一个4层的卷积层加全连接层(85k参数,具体结构表S1所示)在uniform划分数据集上表现很好(平均误差不到半个像素),但同样的结构在quadrant划分数据上完全失败了。一个小的全卷积结构(12k参数)在quadrant划分数据集上可以实现有限的泛化(误差平均约5个像素)但在uniform划分数据集上表现很差。如图5右所示。
许多因素都可能导致性能的变化,包含max-pooling、BN、全连接层的使用,作者并没有充分研究每个因素在这些任务上导致表现不佳的程度,相反只报告了在两种划分数据集上寻找可行架构的努力并没有产生任何赢家。相比之下,一个900参数的CoordConv模型,具体一个CoordConv层后接几层普通卷积就可以在两种划分数据集上快速训练和泛化。
Applicability to Classification, Object Detection
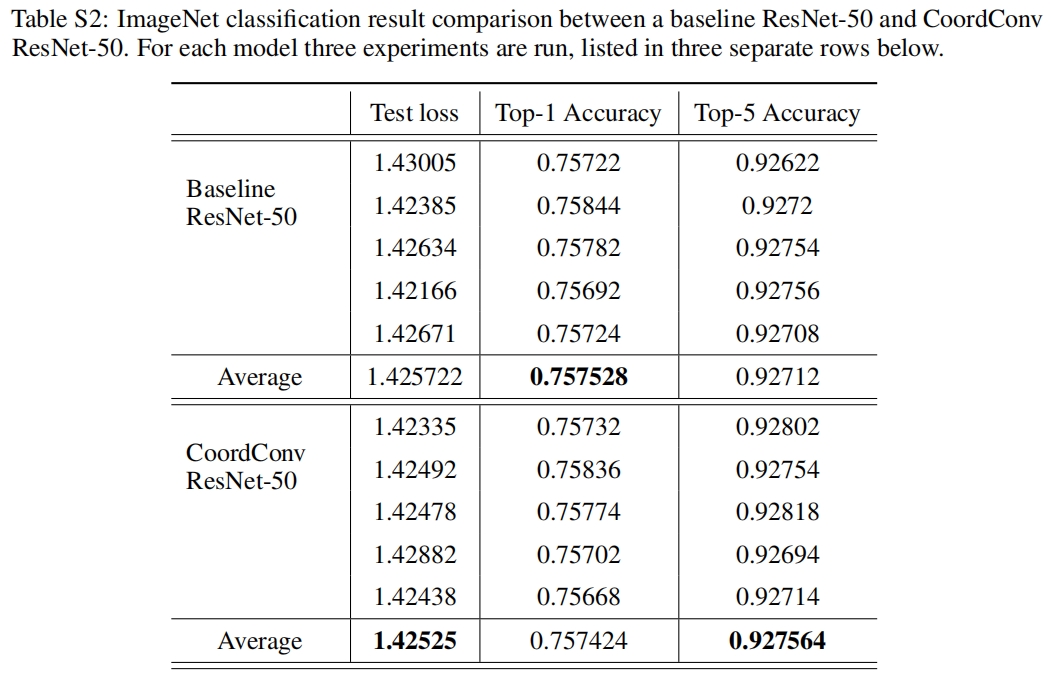
正如预期的那样,对于需要平移不变性的分类任务,CoordConv对分类任务并没有显著的帮助。添加一个额外的8输出通道的1x1 CoordConv,ResNet-50的Top-5精度运行5次平均只提升了0.04%。但至少CoordConv不会影响性能,因为它总是可以学会忽略坐标。
目标检测的实验是在包含随机缩放并在64x64的背景上随机放置的MNIST数字组成的数据集上进行的,训练集有9000张,测试集有1000张。模型采用Faster R-CNN,结构如下所示
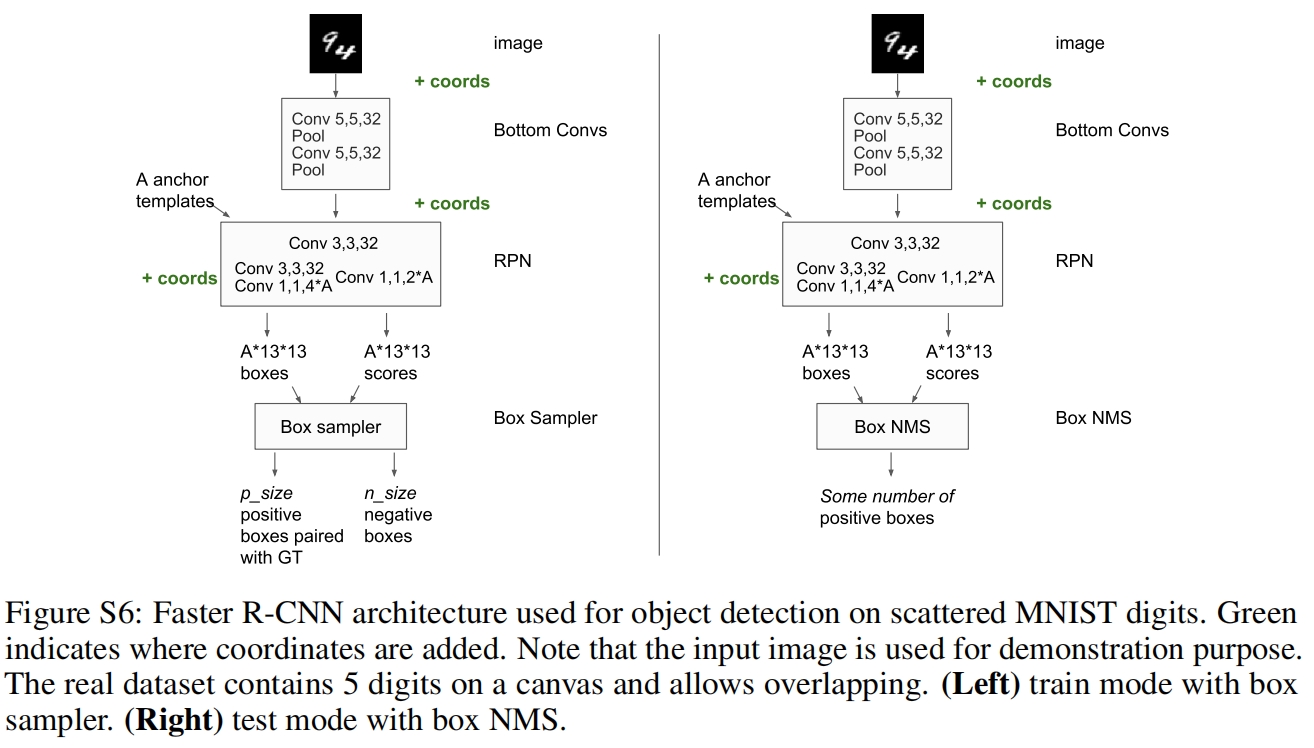
结果如下,可以看到当使用CoordConv,测试集的IOU提升了24%。