k-means聚类、GMM高斯聚类、canopy聚类、DBSCAN聚类、FCM聚类、ISODATA聚类、k-medoid聚类、层次聚类、谱聚类 对比

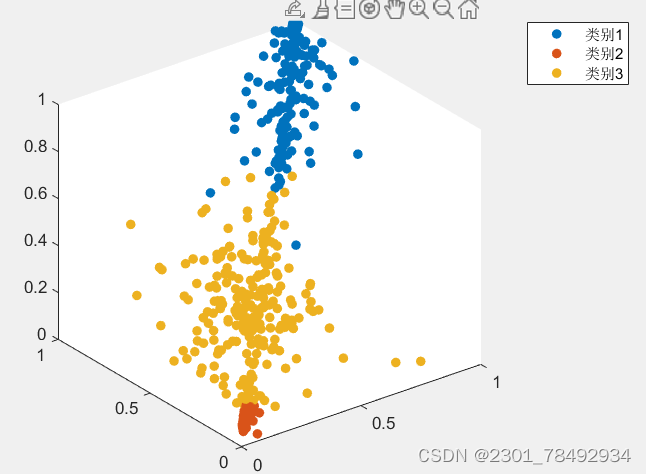
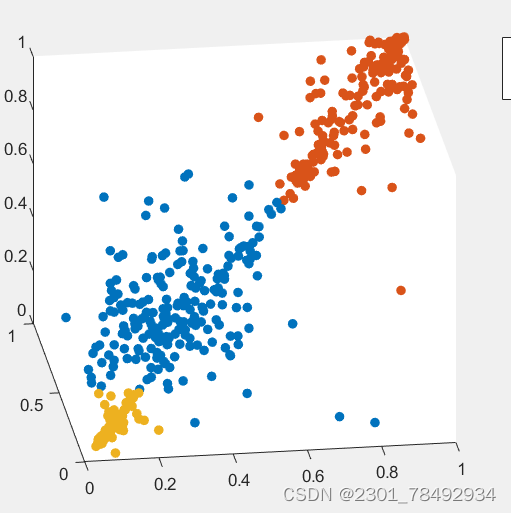
GMM(高斯混合模型)是一种聚类算法,其基本原理是通过多个高斯分布函数去近似任意形状的概率分布。每个高斯分布被称为一个“Component”,这些Component线性加和即为GMM的概率密度函数。GMM将数据点看作是这些高斯分布的采样点,通过极大似然估计的方法估计高斯分布的参数,包括每个Component的概率、均值和协方差等。
GMM的优点主要有以下几点:
-
可解释性好:GMM使用高斯分布来描述数据,高斯分布是一种常见的概率分布,具有很好的数学性质和可解释性。因此,GMM的聚类结果可以很容易地解释和理解。
-
适应性强:GMM可以适应各种形状的数据分布,包括圆形、椭圆形、不规则形状等。这是因为GMM使用多个高斯分布的组合来近似任意形状的概率分布,因此具有很强的适应能力。
-
聚类效果好:GMM在聚类时考虑了数据的概率分布,因此可以更好地处理噪声数据和异常值。同时,GMM的聚类结果具有软聚类的特性,即数据点可以属于多个聚类中心,这可以更好地反映数据的真实情况。
-
应用广泛:GMM在数值逼近、语音识别、图像分类、图像去噪、图像重构、故障诊断、视频分析、邮件过滤、密度估计、目标识别与跟踪等领域都有广泛的应用。
需要注意的是,GMM的计算复杂度较高,需要较多的计算资源。同时,GMM的聚类结果可能会受到初始参数设置的影响,需要进行参数调优以获得更好的聚类效果。
以三维数据为例聚类效果如下
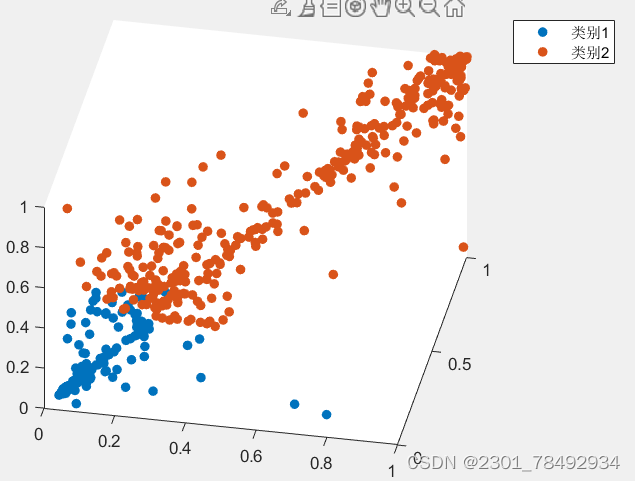
Canopy聚类算法是一种基于密度的聚类方法,其原理是通过快速近似距离度量和两个距离阈值T1和T2来处理数据。其基本步骤是:从一个点集合开始,随机删除一个点作为Canopy的中心,然后在剩余的点集合上迭代。对于每个点,如果它到中心点的距离小于T1,则将该点加入这个Canopy中;如果距离小于T2,则将该点从集合中删除,以避免后续处理。这个过程一直迭代到初始集合为空,最终得到一系列的Canopies,每个Canopy可以包含一个或多个点。
Canopy聚类的优点主要包括以下几点:
-
速度快:Canopy聚类算法使用快速近似距离度量,可以快速地处理大规模数据集,提高了聚类的效率。
-
抗干扰能力强:Canopy聚类算法对噪声的抗干扰能力较强,可以通过设置合适的T1和T2阈值来过滤掉噪声点,从而得到更加准确的聚类结果。
-
可作为其他聚类算法的预处理步骤:Canopy聚类算法可以作为其他聚类算法的预处理步骤,如K-means等。通过先使用Canopy聚类算法进行粗聚类,可以减少后续聚类算法的计算量,并提高聚类的准确性。
-
可发现任意形状的聚类:Canopy聚类算法基于密度进行聚类,可以发现任意形状的聚类,而不仅仅是球形或凸形聚类。
需要注意的是,Canopy聚类算法也存在一些缺点,如需要设置T1和T2两个阈值,阈值的选择对聚类结果影响较大;同时,Canopy聚类算法只能得到粗粒度的聚类结果,如果需要更精细的聚类结果,还需要结合其他聚类算法进行进一步处理。
以三维数据为例聚类效果如下
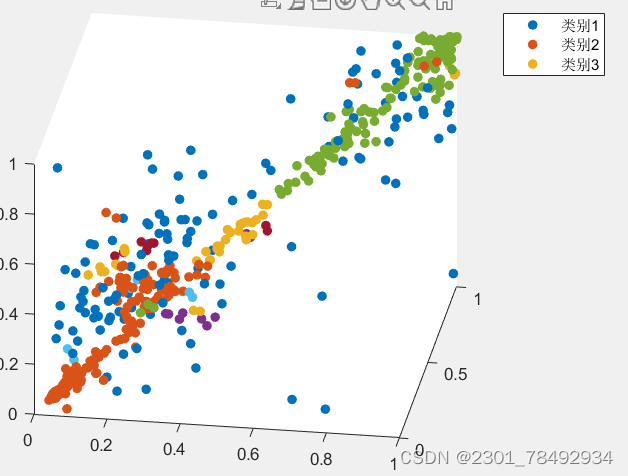
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,其原理是通过识别数据空间中的“拥挤”区域,即许多数据点靠近在一起的区域,来形成聚类。这些拥挤区域被称为密集区域,并由相对较空的区域分隔开。在DBSCAN中,如果一个点的邻域内包含足够多的点(根据给定的密度阈值),则该点被视为核心点,而密集区域是由核心点及其邻域内的点构成的。通过不断扩展核心点的邻域,DBSCAN能够发现任意形状的聚类,并可以识别和处理噪声点。
DBSCAN聚类算法的优点主要包括以下几点:
-
发现任意形状的聚类:与许多其他聚类算法(如K-means)只能发现凸形或球形的聚类不同,DBSCAN可以发现任意形状的聚类。这使得DBSCAN在处理具有复杂形状的数据集时具有很大的优势。
-
处理噪声数据:DBSCAN能够自动识别和处理数据集中的噪声点。在聚类过程中,不属于任何密集区域的点被视为噪声点,并被单独标记。这使得DBSCAN在处理包含噪声的数据集时更加鲁棒。
-
无需事先设定簇的数量:DBSCAN不需要用户事先设定要形成的簇的数量。算法会根据数据点的密度和距离关系自动确定簇的数量和形状。这为用户提供了更大的灵活性,特别是在处理未知内容的数据集时。
-
对初始参数设置相对不敏感:虽然DBSCAN需要设置两个参数(邻域半径和最小点数),但相对于其他聚类算法(如K-means),DBSCAN对初始参数的设置相对不敏感。这意味着在不同的参数设置下,DBSCAN的聚类结果通常具有较好的稳定性。
需要注意的是,DBSCAN也存在一些局限性,例如当数据集的密度不均匀或聚类间距差异较大时,聚类质量可能会受到影响;同时,对于高维数据,存在“维数灾难”的问题,因为随着维数的增加,数据点之间的距离计算变得困难且不准确。此外,在处理大规模数据集时,DBSCAN可能需要较高的计算资源和内存支持。
以三维数据为例聚类效果如下
FCM(Fuzzy C-Means)聚类,即模糊C均值聚类,是一种基于目标函数的模糊聚类算法,它用模糊理论对数据集进行分析和建模。与传统的硬聚类方法(如K-means)不同,FCM聚类允许数据点以一定的隶属度属于多个聚类中心,从而提供了更为灵活的聚类结果。
FCM聚类算法的核心原理是将n个向量xj(j=1,2,...,n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。FCM与硬聚类的主要区别在于FCM用模糊划分,使得每个给定数据点用值在0,1间的隶属度来确定其属于各个组的程度。与引入模糊划分相适应,隶属矩阵U允许有取值在0,1间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1。
FCM聚类的优点主要包括以下几点:
- 能够处理不确定性和噪声数据:由于FCM采用模糊隶属度表示数据点属于各个簇的程度,因此能够更好地处理不确定性和噪声数据。在实际情况中,数据点往往存在一定的模糊性,因此FCM算法能够更准确地反映数据的真实分布情况。
- 对初始值和参数选择不敏感:相对于一些硬聚类算法,如K-means算法,FCM算法对初始值和参数选择的敏感性较低。在FCM算法中,可以通过设定不同的模糊参数来调整聚类结果,使得算法更加灵活和稳健。
- 能够处理任意形状的簇:由于FCM算法采用模糊隶属度表示数据点与各个簇之间的关系,因此能够更好地处理任意形状的簇。在实际情况中,数据簇的形状往往是不规则的,因此FCM算法能够更好地适应数据的复杂分布情况。
- 可解释性强:相对于一些复杂的机器学习算法,FCM算法相对简单,易于理解和实现。同时,通过计算模糊隶属度,可以更好地解释聚类的结果和意义。
需要注意的是,FCM算法也存在一些局限性,例如在处理大规模数据集时可能需要较高的计算资源和内存支持;对于高维数据,也可能存在“维数灾难”的问题。此外,FCM算法需要设定合适的模糊参数以获得理想的聚类结果,参数的选择可能需要一定的经验和尝试。
以三维数据为例聚类效果如下
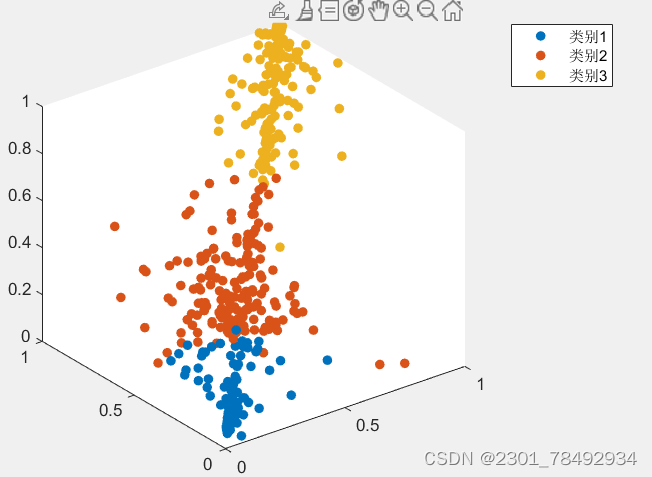
ISODATA(Iterative Self-Organizing Data Analysis Technique Algorithm)聚类,即迭代自组织数据分析技术算法,是一种基于K-means算法的改进型聚类方法。ISODATA在K-means的基础上增加了对聚类结果的“合并”和“分裂”两个操作,并引入了人机对话环节,使得算法在聚类过程中能够动态调整聚类中心的位置和数目。
ISODATA聚类算法的原理如下:
- 初始化:选择初始聚类中心,设定迭代次数、合并和分裂的阈值等参数。
- 迭代过程:根据最近邻规则将每个样本分配到最近的聚类中心,形成初始聚类结果。
- 合并操作:当某个聚类中的样本数过少,或者两个聚类之间的距离过近时,根据合并阈值进行合并操作,即将两个聚类合并为一个新的聚类。
- 分裂操作:当某个聚类中的样本在某个特征上的类内方差过大,即样本在该特征上的分布过于分散时,根据分裂阈值进行分裂操作,即将该聚类分裂为两个新的聚类。
- 更新聚类中心:根据新的聚类结果,重新计算每个聚类的中心。
- 迭代终止条件:当满足迭代次数或者聚类中心的变化小于某个阈值时,算法终止。
ISODATA聚类的优点主要包括以下几点:
- 能够动态调整聚类中心和数目:ISODATA聚类算法在聚类过程中能够动态调整聚类中心的位置和数目,这使得算法能够适应不同形状和大小的聚类,并且对于噪声数据和异常值具有一定的鲁棒性。
- 无需事先设定聚类数目:相对于一些需要事先设定聚类数目的算法(如K-means),ISODATA算法无需事先确定聚类的数量,而是通过合并和分裂操作自动确定最佳的聚类数目。
- 人机交互环节:ISODATA聚类算法引入了人机对话环节,使得用户可以通过设定合并和分裂的阈值等参数来干预聚类过程,从而得到更符合实际需求的聚类结果。
需要注意的是,ISODATA算法也存在一些局限性,例如对于初始聚类中心的选择较为敏感,可能需要多次尝试以获得理想的聚类结果;同时,算法的计算复杂度较高,在处理大规模数据集时可能需要较长的运行时间。
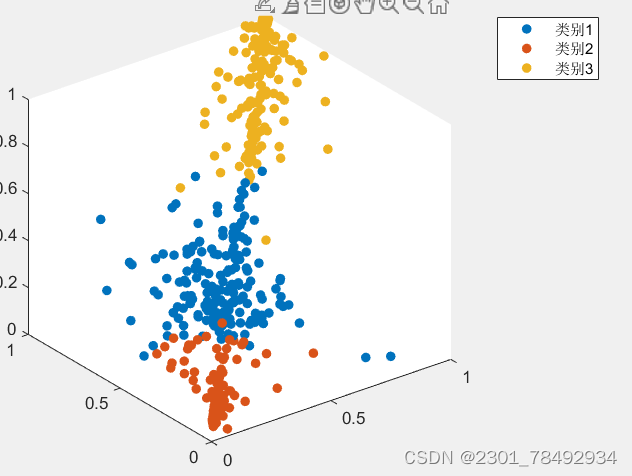
K-medoids聚类算法是一种基于划分的聚类方法,与K-means算法相似,但有所不同。在K-medoids中,每个簇的中心是一个实际的数据点,即medoid(中心点),而不是通过计算得到的均值点。K-medoids算法的目标是选择K个数据点作为簇的中心,使得每个数据点与其所属簇的中心点的距离之和最小化。
K-medoids聚类算法的原理如下:
- 初始化:随机选择K个数据点作为初始的簇中心。
- 分配数据点到簇:根据每个数据点与簇中心点的距离,将数据点分配到最近的簇中。
- 更新簇中心:在每个簇中,选择一个数据点作为新的中心点,使得该数据点到簇内其他数据点的距离之和最小。
- 迭代:重复步骤2和3,直到簇中心不再发生变化或达到预设的迭代次数。
K-medoids聚类算法的优点主要包括以下几点:
- 对噪声和离群点鲁棒性:与K-means算法相比,K-medoids算法使用实际的数据点作为簇的中心,因此更能抵抗噪声和离群点的影响。当数据集中存在噪声或离群点时,K-medoids算法通常能够提供更稳定、更准确的聚类结果。
- 簇中心更具代表性:由于K-medoids算法选择实际的数据点作为簇的中心,这些中心点通常更具代表性,能够更好地反映簇内数据点的特征。
- 可解释性强:K-medoids算法的结果更容易解释和理解。每个簇的中心点是一个实际的数据点,可以直接观察和分析,从而更容易洞察数据的结构和模式。
需要注意的是,K-medoids算法也存在一些局限性,例如计算复杂度较高,因为每次迭代都需要在每个簇中选择一个新的中心点;同时,K-medoids算法也需要事先确定簇的数量K,这对于某些应用场景可能是一个挑战。另外,与K-means算法一样,K-medoids算法也仅适用于球形或凸形簇的情况,对于非球形簇可能无法得到理想的聚类结果。
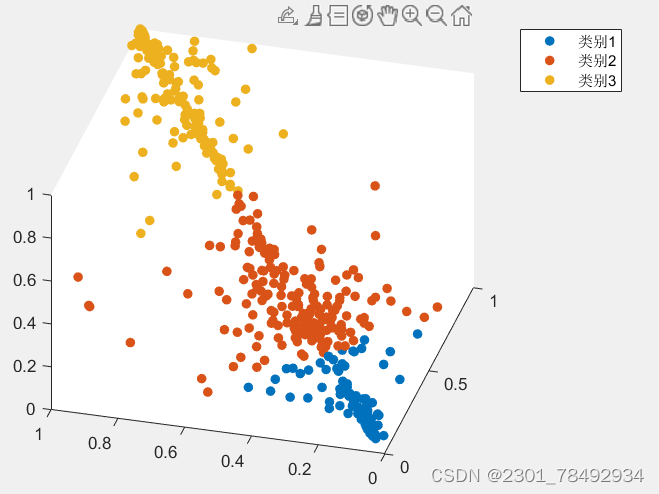
层次聚类(Hierarchical Clustering)是一种聚类方法,它的原理是通过计算不同类别数据点间的相似度来创建一个有层次的嵌套聚类结构。层次聚类可以采用自底向上的聚合策略(Agglomerative)或自顶向下的分拆策略(Divisive)。
自底向上的聚合策略(Agglomerative):
- 首先将每个数据点视为一个单独的簇。
- 计算所有簇之间的距离或相似度。
- 将最相似的两个簇合并成一个新的簇。
- 重复步骤2和3,直到所有的数据点都合并到一个簇中,或者达到预设的簇的数量。
自顶向下的分拆策略(Divisive):
- 开始时将所有数据点视为一个簇。
- 将簇拆分为两个最不相似的子簇。
- 重复步骤2,直到每个数据点都是一个单独的簇,或者达到预设的簇的数量。
层次聚类的优点包括:
- 能够发现层次结构:层次聚类可以生成一个嵌套的簇结构,这有助于理解数据点之间的层次关系。
- 对初始设置不敏感:与一些其他聚类方法(如K-means)相比,层次聚类对初始簇中心或参数设置不太敏感。
- 能够处理不同形状和大小的簇:层次聚类不依赖于簇的形状或大小,因此能够处理不同形状和大小的簇。
- 能够识别噪声和离群点:在层次聚类过程中,噪声和离群点通常会被单独分到一个小簇中。
然而,层次聚类也有一些缺点,如计算复杂度较高,尤其是当数据集较大时。此外,层次聚类通常不能很好地处理高维数据,并且一旦合并或拆分操作完成,通常很难进行回溯或调整。
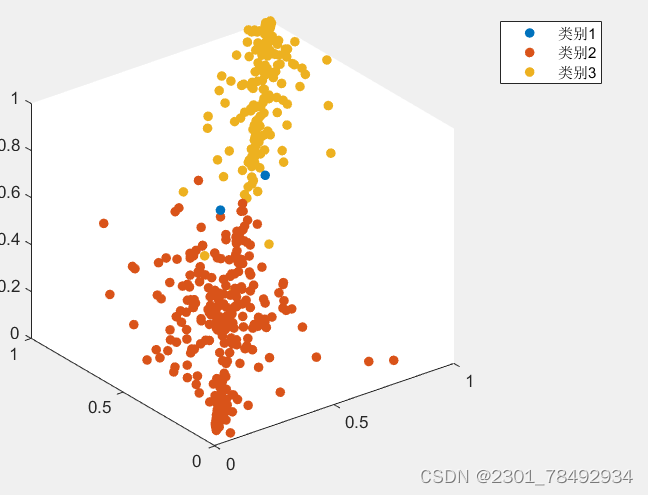
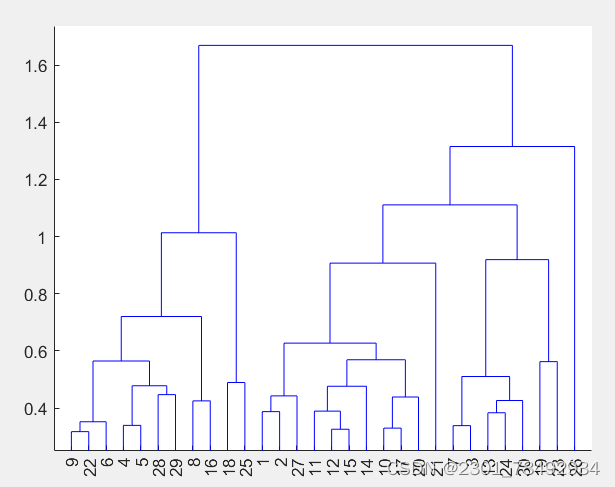
谱聚类(Spectral Clustering)是一种基于图论的聚类方法,它通过对数据点的相似度矩阵进行特征分解,将数据点映射到低维空间,并在该空间中进行聚类。谱聚类的原理可以分为以下几个步骤:
- 构建相似度矩阵:首先,根据数据点之间的相似度(如欧氏距离、高斯核函数等)构建一个相似度矩阵W。这个矩阵的元素W_ij表示数据点i和j之间的相似度。
- 计算拉普拉斯矩阵:拉普拉斯矩阵L定义为L = D - W,其中D是一个对角矩阵,其对角线上的元素D_ii是数据点i的度,即W_ii之和。拉普拉斯矩阵反映了数据点的局部结构信息。
- 特征分解:对拉普拉斯矩阵L进行特征分解,得到其特征向量和对应的特征值。选择前k个最小的特征值对应的特征向量,构成一个低维空间的表示。
- 低维空间聚类:将数据点映射到由这k个特征向量构成的低维空间中,并在该空间中使用传统的聚类方法(如K-means)进行聚类。
谱聚类的优点主要包括:
- 适应性强:谱聚类只需要数据之间的相似度矩阵,因此对数据分布的适应性更强。它能够处理任意形状的簇,并且对于噪声和离群点也具有一定的鲁棒性。
- 降维效果:通过特征分解,谱聚类将数据点映射到低维空间,这有助于简化聚类问题并减少计算复杂度。在处理高维数据时,谱聚类的性能通常优于传统聚类方法。
- 能够发现非线性结构:谱聚类基于图论的思想,能够发现数据中的非线性结构,这是许多传统聚类方法所无法做到的。
然而,谱聚类也存在一些缺点,如计算复杂度较高,尤其是当数据集较大时。此外,谱聚类的效果依赖于相似度矩阵的选择和构建,不同的相似度矩阵可能导致完全不同的聚类结果。因此,在实际应用中,需要根据具体的数据特点选择合适的相似度度量方法。