低秩适应(LoRA)
低秩适应(LoRA)是一种创新技术,它使得在保持预训练神经网络的基础上进行高效定制成为可能,比如在扩散模型或语言模型中的应用。这种方法的核心优势在于其能够通过仅训练相对较少的参数来实现,既保留了完全微调过程中的性能,又显著加快了训练速度。此外,LoRA还大幅度减少了模型检查点的大小,这对于存储和计算资源有限的环境尤其重要。由于这些显著的优势,LoRA已经成为定制人工智能模型的首选方法之一。
全面微调(Full Fine-tuning)
全面微调(Full Fine-tuning)是一种在深度学习领域常用的技术,特别是在处理预训练神经网络模型时。这种方法涉及对一个已经在大规模数据集上预训练好的模型进行进一步的训练,以使其更好地适应特定的任务或数据集。
但是
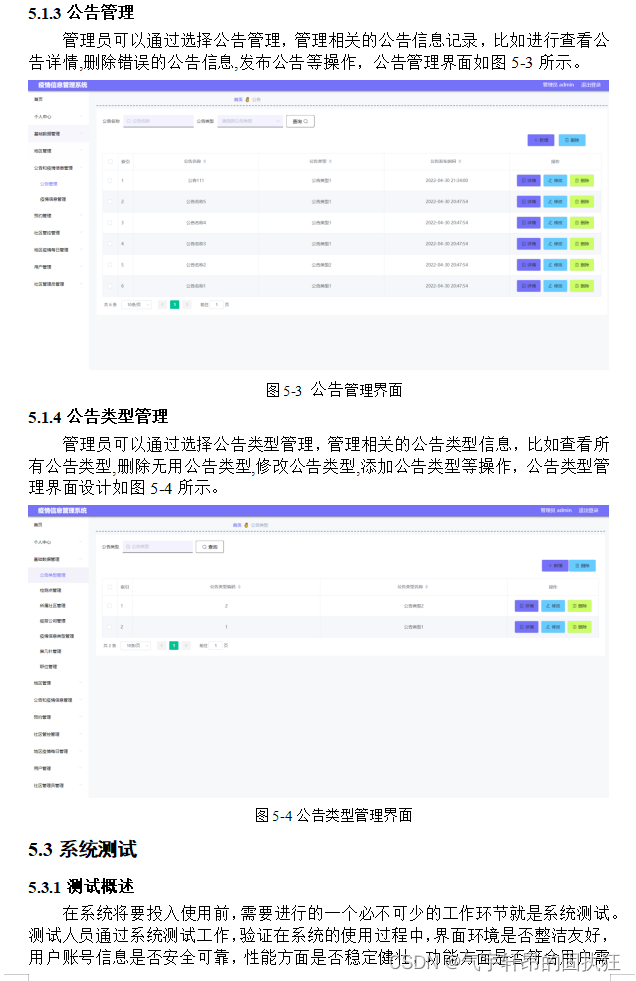
1750 亿个参数变体的单个模型检查点大小为 1 TB, 难以存储,部署时需要几分钟才能加载。
为什么需要LoRA
问题一:我们需要 找到并调整所有参数吗?
问题二:对于 我们微调的权重矩阵,更新在矩阵秩方面应该具有多大的表现力 ?

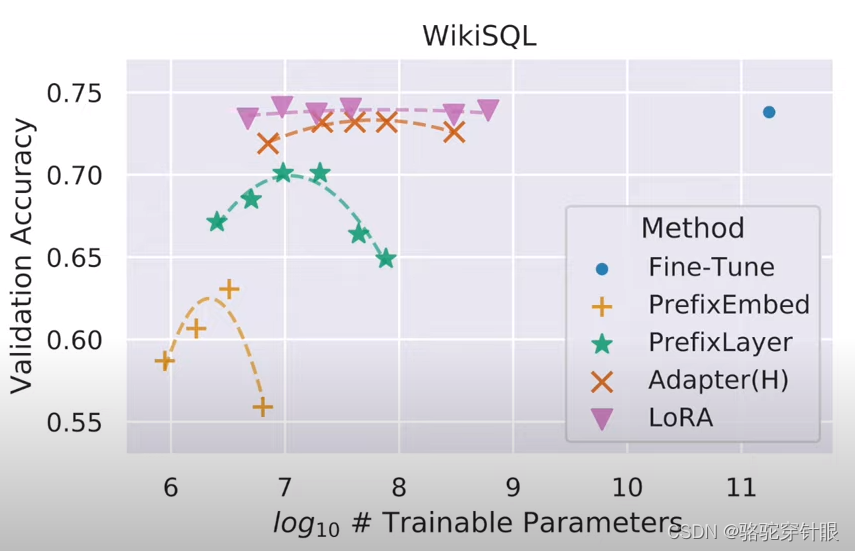
我们可以将这两个问题转化 为二维平面的两个轴。完全微调一直 在右上角,并且轴(包括原点)与 原始模型相对应。此框中的任何点都是 有效的 LoRA 配置。
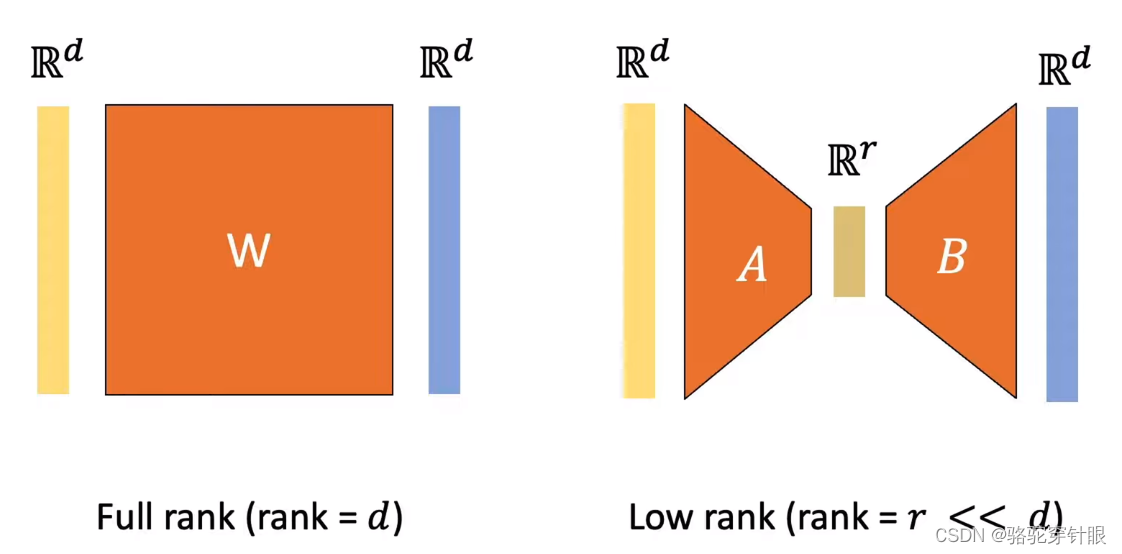
| Full rank (rank =d) | Low rank (rank =r << d) |
|---|---|
| dxd 参数 | 2xdxr 参数 |
choosing LoRA config
Start near the origin and working our way back to the fine-tuning corner.
r 可以在源点附近进行微调

对于扩散模型有显著的效果

if it underperforms: we adapt more parameters and increase the rank.
我们调整更多 参数并提高排名。
Most efficient tuning methods don’t recover full fine-tuning as a specical casel
大多数有效的调整方法都不能恢复完全微调,因为这只是一种特殊情况。
For approaches like prefix tuning, BitFit, or adapters, 对于前缀 调整、BitFit 或适配器等方法
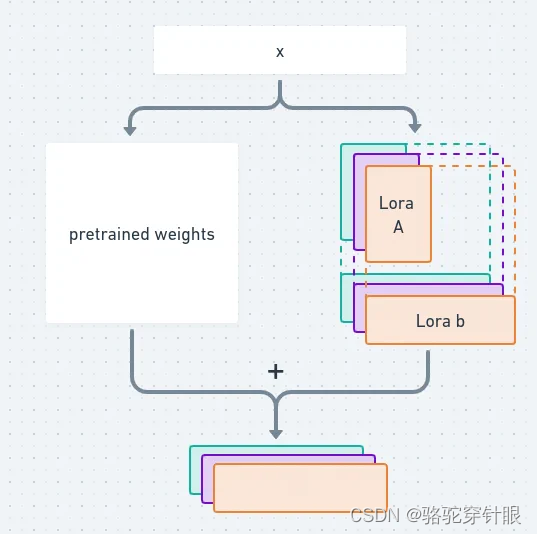
更加小的 checkpoint, 且不会引起任何的推理上面的延迟

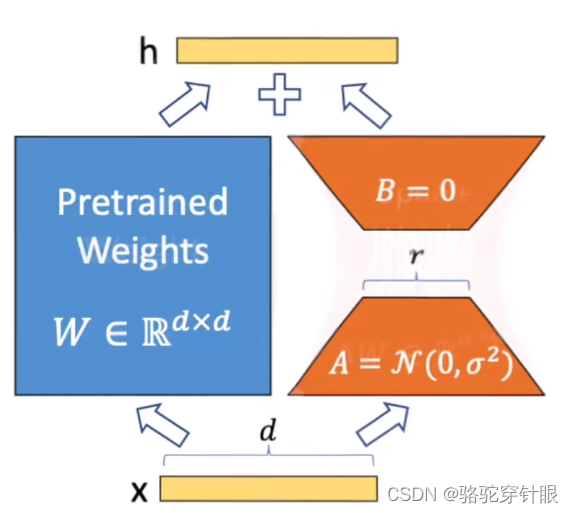
推理过程
- 简单的推理

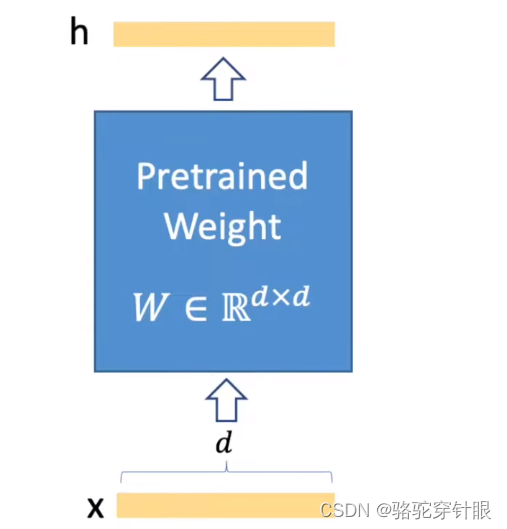
2,前面的知识变成了预训练
3.加上一个LoRA模型
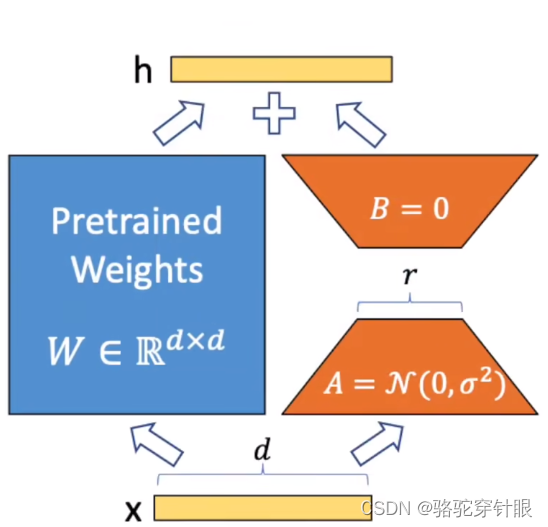
4.再通过乘以LoRA来扩展低秩矩阵
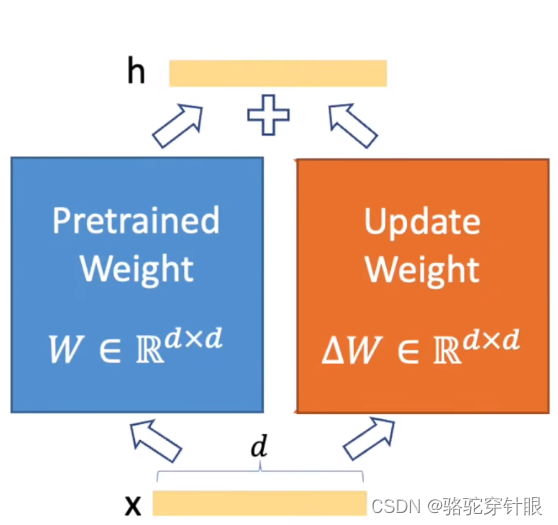
所以不会增加任何的推理的延迟
Caching LoRA modules in RAM
在 RAM 中缓存 LoRA 模块
RAM 比 VRAM 大得很多 可以放很多 LoRA模型
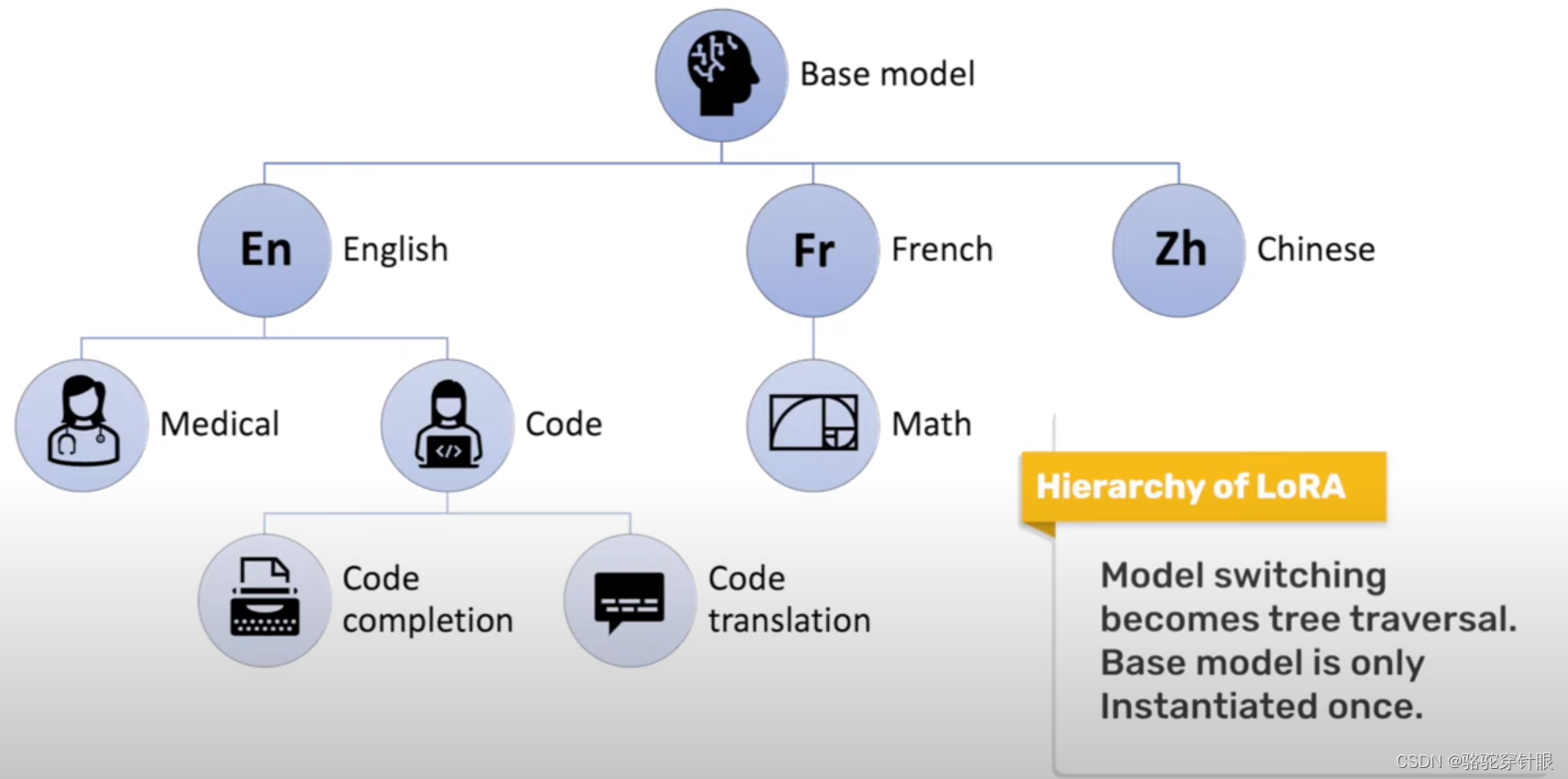
使用共享基础模型的多个LoRA子模型并行训练
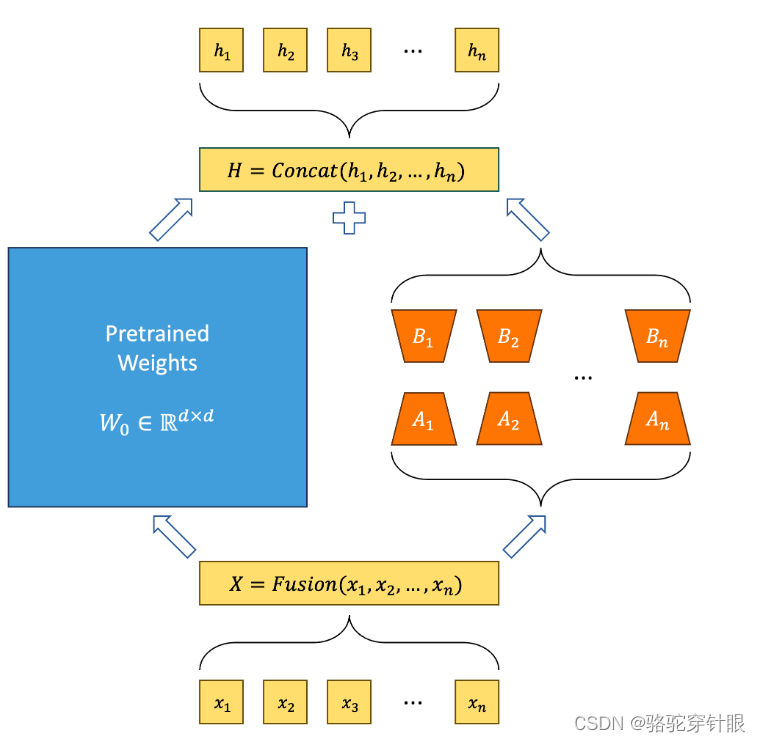
ASPEN: ASPEN:Efficient LLM Model Fine-tune and Inference via Multi-Lora Optimization是一个开源框架,用于使用高效的多重 LoRA/QLoRA 方法对大型语言模型(LLM)进行微调。Multi-lora 如何改进基于 LoRA 的方法:
- 节省 GPU 内存: 使用一个基础模型进行多个微调过程,大大节省资源。
- 自动参数学习: 在模型微调过程中引入超参数的自动学习过程,可以加快微调过程并确保获得最佳模型结果。
- 早期停止机制:采用这种方法可确保不会出现过度拟合,并有效利用资源。一旦模型的改进变得可以忽略不计,它就会停止训练。
使用逐渐适应不同任务的自适应模型树形结构