Go语言调度器使用与CPU数量相等的线程来减少线程频繁切换带来的内存开销,同时在每一个线程上执行额外开销更低的Goroutine来降低操作系统和硬件的负载。
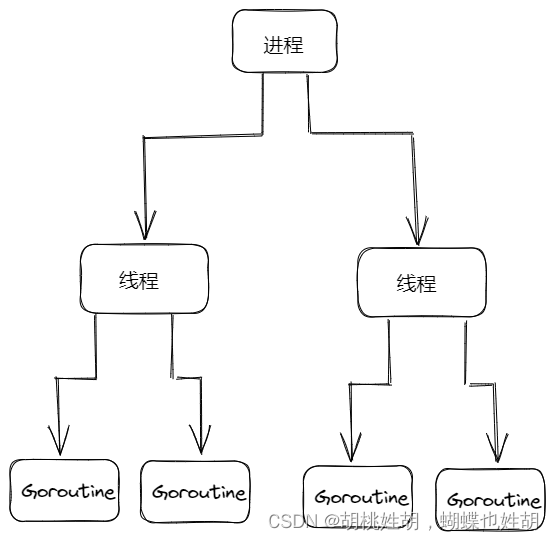
每一次线程上下文切换都需要消耗约1us的时间,而Go调度器对Goroutine的上下文的切换约为0.2us,减少了80%的额外开销!
演变过程
我们先来了解一下Goroutine的演变过程。
-
单线程调度器 – Go 0.X
程序中只能存在一个活跃线程。由G - M模型组成
-
多线程调度器 – Go 1.0
全局锁导致竞争严重
-
任务窃取调度器 – Go 1.1
改进点:
- 引入了处理器P,构成了目前的G-M-P模型
- 在处理器P的基础上实现了基于工作窃取的调度器
缺陷点:
- 在某些情况下
Goroutine不会让出线程,进而导致饥饿问题 - 垃圾收集机制时间过长
-
抢占式调度 – Go 1.2至今
-
基于协作的抢占式调度器 – Go 1.2 ~ Go 1.13
改进:
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前
Goroutine是否发起了抢占请求,实现基于协作的抢占式调度
缺陷:
Goroutine可能会因为垃圾收集和循环长时间占用资源导致程序暂停
- 通过编译器在函数调用时插入抢占检查指令,在函数调用时检查当前
-
基于信号的抢占式调度器 – Go 1.14 ~ 至今
改进:
- 实现了基于信号的真抢占式调度
缺陷:
- 垃圾收集在扫描线程时会触发抢占式调度
- 抢占的时间点不够多,不能覆盖所有边缘情况
-
布局
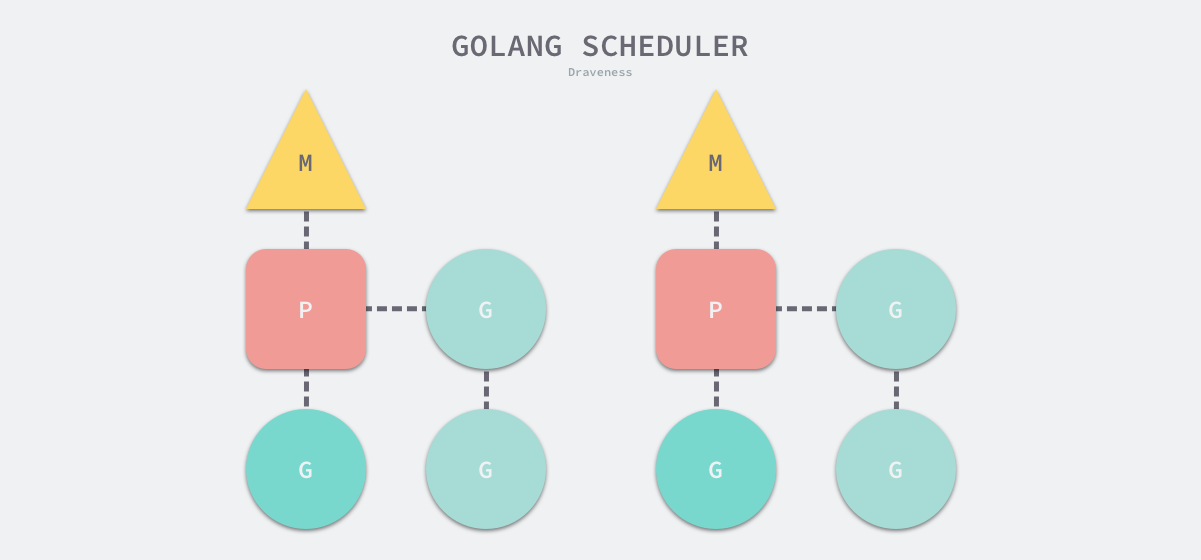
该图来自面向信仰编程
- G表示
Goroutine,它是待执行的任务 - M表示操作系统的线程,它由操作系统的调度器调度和管理
- P表示处理器,可以把它看作在线程上运行的本地调度器
我们必须有一个整体的认识才能开始学习:
G
数据结构
Goroutine只存在于Go的运行时,它是Go在用户态提供的线程。G的结构体有40多个字段,很难全部弄清楚,所以我们来挑选几个经典的来进行讲解:
type g struct {
goid int64 // 唯一的goroutine的ID
sched gobuf // goroutine切换时,用于保存g的上下文
stack stack // 栈
gopc // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
...
}
type gobuf struct {
sp uintptr // 栈指针位置
pc uintptr // 运行到的程序位置
g guintptr // 指向 goroutine
ret uintptr // 保存系统调用的返回值
...
}
//[stack.lo, stack.hi)
type stack struct {
lo uintptr // 栈的下界内存地址
hi uintptr // 栈的上界内存地址
}
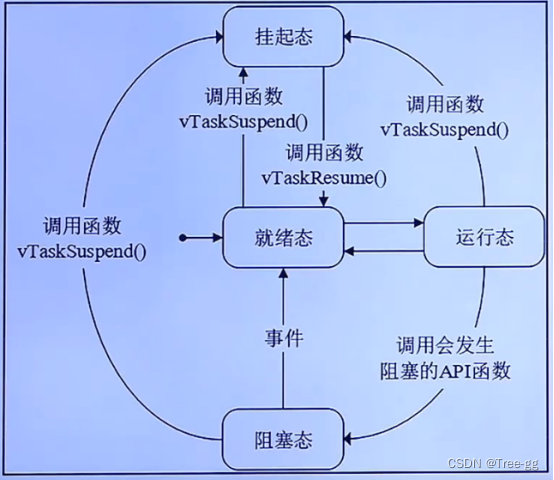
Goroutine的状态
| 状态 | 含义 |
|---|---|
| 空闲中_Gidle | G刚刚新建,没有初始化 |
| 待运行_Grunnable | 就绪状态,G在运行队列中,等待M取出并运行 |
| 运行中_Grunning | M正在运行这个G,这时候M会拥有一个P |
| 系统调用中_Gsyscall | M正在运行这个G发起的系统调用,这时候M并不拥有P |
| 等待中_Gwaiting | G在等待某些条件完成,这时候G不在运行也不在运行队列中(可能在channel的等待队列中) |
| 已中止_Gdead | G未被使用,可能已经执行完毕 |
| 栈复制中_Gcopystack | G正在获取一个新的栈空间并把原来的内容复制过去(用于防止GC扫描) |

M
M是操作系统线程,调度器最多可以创建10 000个线程,但是绝大多数线程不会执行用户的代码,最多只会有GOMAXPROCS个活跃线程能够运行。默认情况下GOMAXPROCS会设置成当前机器的核数。
type m struct {
g0 *g
// 每个M都有一个自己的G0,不指向任何可执行的函数,在调度或系统调用时,M会切换到G0,使用G0的栈空间来调度
curg *g
// 当前正在执行的G
...
}
- g0是持有调度栈的
Goroutine,它会深度参与运行时的调度过程,包括Goroutine的创建,大内存分配核cgo函数的执行 - curg是在当前线程上运行的用户的
Goroutine
P
调度器中的处理器P是线程核Goroutine的中间层,它能提供线程需要的上下文,也会负责调度线程上的等待队列。通过处理器P的调度,每一个内核线程都能执行多个Goroutine,它能在Goroutine进行一些I/O操作时及时让出计算资源,提供线程利用率。
有多少个活跃线程就有多少个P。
数据结构
P中有非常多字段,例如性能追踪,垃圾收集,计时器相关等,但是这里暂时先讲解线程和运行队列。
type p struct {
lock mutex
id int32
status uint32 // one of pidle/prunning/...
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32 // 本地队列队头
runqtail uint32 // 本地队列队尾
runq [256]guintptr // 本地队列,大小256的数组,数组往往会被都读入到缓存中,对缓存友好,效率较高
runnext guintptr // 下一个优先执行的goroutine(一定是最后生产出来的),为了实现局部性原理,runnext中的G永远会被最先调度执行
...
}
处理器状态
| 状态 | 描述 |
|---|---|
| _Pidle | 处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空 |
| _Prunning | 被线程M持有,并且正在执行用户代码或者调度器 |
| _Psyscall | 没有执行用户代码,当前线程陷入系统调用(例如去执行I/O操作了) |
| _Pgcstop | 被线程M持有,当前处理器由于垃圾收集而被停止 |
| _Pdead | 当前处理器已经被停用了 |
Go调度器实现原理
调度器启动
我们先宏观的启动整个调度器,之后会等待用户创建,运行新的Goroutine并为Goroutine调度处理器资源。
创建Goroutine
调用runtime.newproc获取新的Goroutine结构体将其加入处理器的运行队列,并在满足条件时调用runtime.wakep唤醒新的处理器执行Goroutine。下面来详细的展开讲解这一句话:
初始化结构体
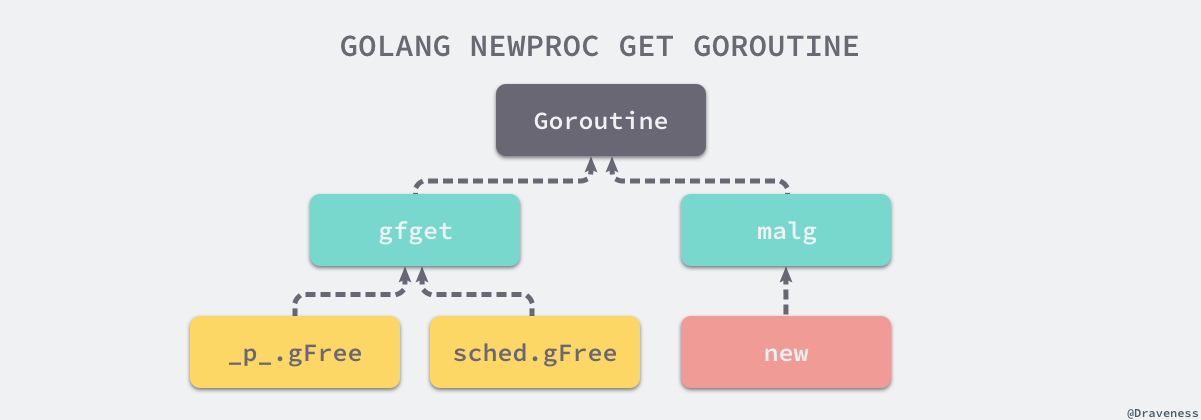
先总结一下:runtime.newproc1会从处理器或者调度器的缓存中获取新的结构体,也可以调用runtime.malg函数创建。
这个逻辑由runtime.gfget这个函数来实现:
- 从
Goroutine所在处理器的gFree列表或者调度器的sched.gFree列表中获取runtime.g - 调用
runtime.malg生成一个新的runtime.g并将结构体追加到全局的Goroutine列表allgs中
如果调度器和处理器的gFree列表都不存在结构体时,才会新创建,否则会根据处理器中gFree列表中的Goroutine数量做出不同的决策:
- 处理器的
Goroutine列表对象为空时,会将调度器持有的空闲Goroutine转移到当前处理器上,知道gFree列表中的Goroutine数量达到32 - 处理器的
Goroutine数量充足时,会从列表头部返回一个新的Goroutine
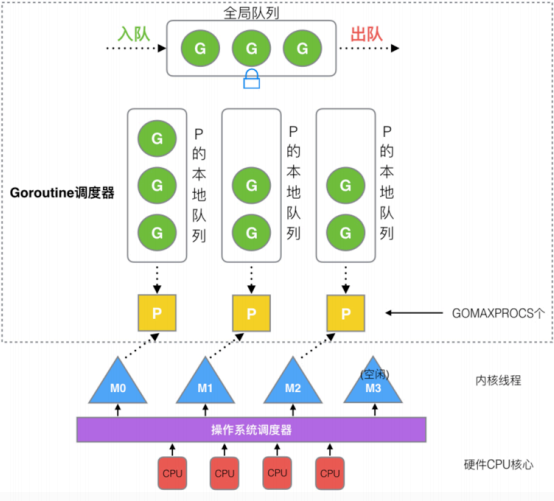
运行队列
runtime.runqput会将Goroutine放到运行队列上,这既可能是全局的运行队列,也可能是处理器的本地队列。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pchCgpgq-1672989679776)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20230106001757467.png)]
这张图我们会随着讲解逐渐展开。
调度信息
我们前面有讲过一个结构体:
type gobuf struct {
sp uintptr // 栈指针位置
pc uintptr // 运行到的程序位置
g guintptr // 指向 goroutine
ret uintptr // 保存系统调用的返回值
...
}
这个结构体保存Goroutine的上下文信息,也就是调度信息,其中sp存储了runtime.goexit函数的程序计数器,pc中存储了传入函数的程序计数器,pc寄存器的作用是存储程序接下来要运行的位置,所以pc的使用比较好理解,但是sp中存储的goexit不好理解,需要结合下面的调度循环来进行理解。
调度循环
我们先来看一张图宏观的理解一下什么叫做调度循环。
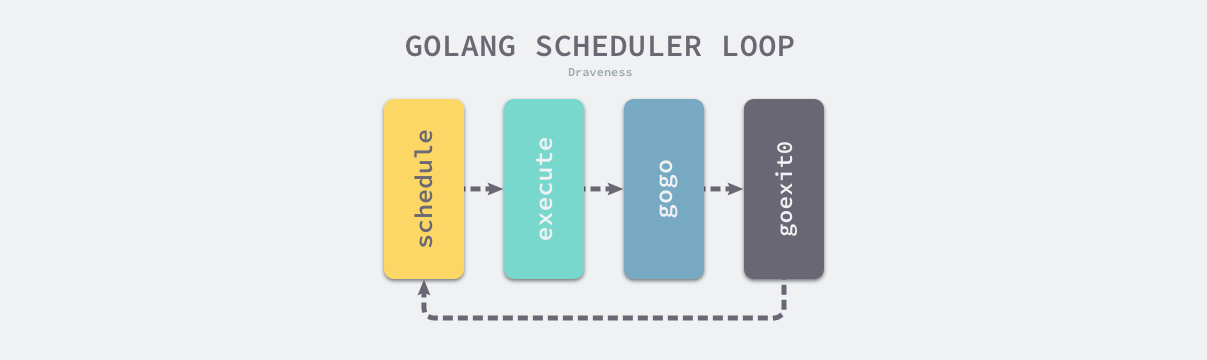
使用什么策略来挑选下一个Goroutine执行。由于P中的G分布在runnext,本地队列,全局队列,网络轮询器中,则需要挨个判断是否有可执行的G,大体逻辑如下:
- 每执行61次调度循环,从全局队列获取G,若有则直接返回
- 从P的runnext看一下是否有G,若有则直接返回
- 从P上的本地队列看一下是否有G,若有则直接返回
- 上面都没有查到时,则取全局队列,网络轮询器查找或者从其他P中窃取,一直阻塞直到获取到一个可用的G为止
首先是调用schedule函数。
func schedule() {
_g_ := getg()
var gp *g
var inheritTime bool
...
if gp == nil {
// 每执行61次调度循环会看一下全局队列。为了保证公平,避免全局队列一直无法得到执行的情况,当全局运行队列中有待执行的G时,通过schedtick保证有一定几率会从全局的运行队列中查找对应的Goroutine;
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 先尝试从P的runnext和本地队列查找G
gp, inheritTime = runqget(_g_.m.p.ptr())
}
if gp == nil {
// 仍找不到,去全局队列中查找。还找不到,要去网络轮询器中查找是否有G等待运行;仍找不到,则尝试从其他P中窃取G来执行。
gp, inheritTime = findrunnable() // blocks until work is available
// 这个函数是阻塞的,执行到这里一定会获取到一个可执行的G
}
...
// 调用execute,继续调度循环
execute(gp, inheritTime)
}
然后就的调度循环的execute函数,执行获取的Goroutine,做好工作后使用gogo把Goroutine调度到当前线程上。在gogo函数中,经过一系列复杂的函数调用,最终会调用goexit0函数,将Goroutine转换为_Gdead状态,清除其中的字段,移除Goroutine和线程的关联,并调用gfput重新加入处理器的Goroutine的空闲列表gFree。最后goexit0函数重新调用schedule开始新一轮的循环,不出现意外的话循环是永不终止的。
触发调度
下面简单介绍所有触发调度的时间点:
- 主动挂起 —
runtime.gopark->runtime.park_m - 系统调用 —
runtime.exitsyscall->runtime.exitsyscall0 - 协作式调度 —
runtime.Gosched->runtime.gosched_m->runtime.goschedImpl - 系统监控 —
runtime.sysmon->runtime.retake->runtime.preemptone
线程管理
Go运行时会通过调度器改变线程的所有权,绑定Goroutine和当前线程。