Golang集合源码-Map
22届211本科,在字节实习了一年多,正式工作了半年,工作主要是golang业务研发,go语言使用和生态比java简洁很多,也存在部分容易遇见的问题,常用结构需要对其底层实现略有了解才不容易写出有问题的代码。
本文学习主要参考《Go 语言设计与实现》一书,其对go语言部分底层实现解释较为清晰,但书上的都是别人的,故写一篇记录。
一、Map简介
哈希表是编程语言中必备的常见数据结构,也叫做映射、map、散列表。map实际上是一个非常简单的数据结构,其核心为hash函数、数组、拉链(或类似拉链)。
map使用数组存储元素,但是不像列表一样顺序存储,而是使用hash函数获得存储key的hash值,通常经过取模运算获得最终数组index然后存储数据,这样从map中查询元素时即可通过key计算数组index,快速定位已经存储的元素。hash冲突是不同的key通过hash函数可能得到的hash值去模后时一样的,例如数学中的抛物线函数,一定存在两个x对应的y值一样,此时数组存储在原位上就不够用了,通常使用开放寻址法或者拉链法处理,此处不展开。
map数据结构相比数组提高了集合元素的查询效率,最快有O(1)的时间复杂度,但是如果hash冲突严重,可能退化成O(n)。
不同语言中map实现主题一样,细节可能有些差别。Java中Map的实现主要是通过拉链法,如果拉链过长则会将链表转化成红黑树,在Java中数组的每个元素就是一个桶,即一个桶只有一个头元素,冲突后立即拉链。Golang中的数组每个元素是一个bmap,其中能够存储8个key-value对,并且bmap支持拉链,以bmap作为链表元素,链表元素的value是8个key-value对。Java中链表转化红黑树的条件为数组长度大于等于64且链表长度大于8,为什么都是8呢?据说按照正态分布,hash冲突为8的概率已经非常小,故Java设置8可以减少维持红黑树的性能成本,golang设置为8可以减少拉链的空间成本。
golang中bmap里可以存储8个key-value对,其实顺序存储就行了,类似java的拉链存储。而当bmap中存储的元素需要多余8个,即hash冲突过多时,bmap会有一个指向溢出桶bmap结构的指针。

二、 Map的数据结构
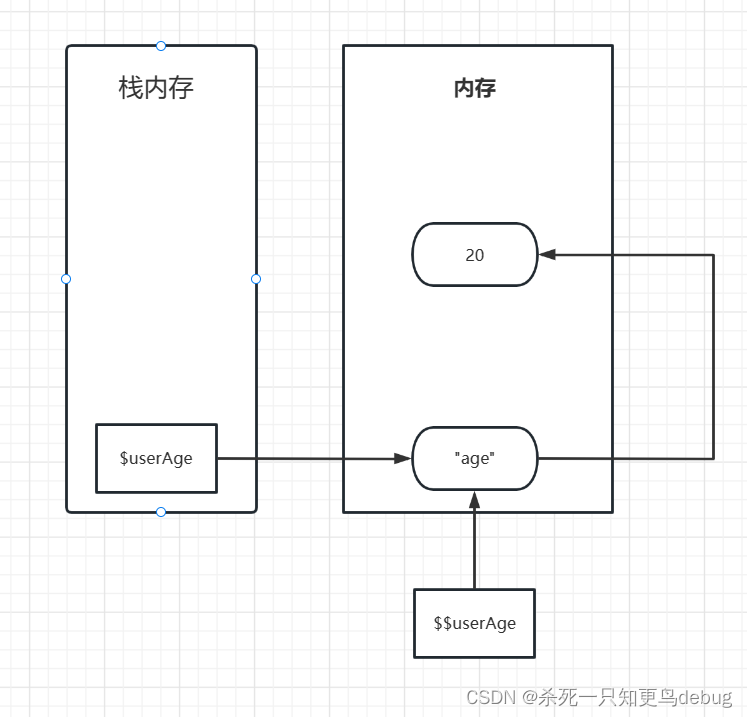
golang中map的数据结构使用的是hmap,其中含义明显的字段有count代表map中包含key-value的数量,即len(map)。其中B为map的底层数组长度的对数,即B=log_2(len(buckets))。其中oldbuckets是扩容时用于同时维持老数组的字段。
// A header for a Go map.
type hmap struct {
count int // map的长度
flags uint8
B uint8 // log_2(桶数量)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // 长度为2^B的桶数组. 如果map是空的可能是空.
oldbuckets unsafe.Pointer // 长度只有一半的老桶数组, 只有扩容时不为空
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
数组中的每个元素都是bmap,bmap结构中包含tophash为一个长度为8的uint8数组,用于存储该桶对应hash值的高8位,用hash值的高8位定位桶,低8为定位桶中元素。看注释“接着是 bucketCnt 键,然后是 bucketCnt 元素。”,为什么没有显示声明字段在结构体中呢?个人理解为golang中存在指针计算偏移量的功能,后续插入、查询、扩容都是基于指针计算偏移量来进行的,只需创建的桶数组(本质是一段连续的内存)中包含8个bmap对象,每个bmap对象后面跟着8*(key_size+value_size)的大小即可。这样实现还有一个好处是没有额外的内存消耗,例如维护对象或者padding等。
注释原话是,“注意:将所有键打包在一起,然后将所有元素打包在一起,使代码比交替 keyelemkeyelem 更复杂一些…但它允许我们消除需要的填充,例如 map[int64]int8。后跟一个溢出指针。”
// Maximumnumber of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
三、Make一个Map
golang创建一个map对象实例通常使用make(map[k]v, hint),其中math.MulUintptr的含义为两个int指针的数据相乘的结果。
- 参数的输入,其中 t *maptype含义为key和value的类型及类型所占内存大小,以及以该类型为数据桶占的大小,h *hmap初始化时一半时nil,暂时无需关心
- 首先通过初始化输入的map数组长度hint和桶的大小相乘,获取最终占据的内存大小,以及内存大小是否溢出int值。
- 初始化map结构hmap,计算一个随机数
- 通过overLoadFactor计算map最终长度,为输入值hint的上一个2的B次方,即满足
2^B>hint式子的最小B值。 - 如果不是懒加载,则通过makeBucketArray函数初始化map的底层数组h.buckets,这个函数会返回nextOverflow即为溢出桶
// makemap implements Go map creation for make(map[k]v, hint).
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
- 可以轻易看出,如果b>=4即map的底层桶数组长度大于等于16时,此时会有
2^(b-4)个溢出桶即原数据长度的1/16个溢出桶,和桶数组一起被分配。 - 假设当前b为4,即底层数组长度理论上为16,那么溢出桶为1个,实际底层数组长度为17。nextOverflow = (bmap)(add(buckets, baseuintptr(t.bucketsize))),其中add是加法函数将地址和偏移量加起来,其中base为数组基础长度16,故nextOverflow的含义就是底层数组第17个元素的地址。同理可得last为桶中第16个元素的地址,
- last.setoverflow(t, (*bmap)(buckets))的含义为不包含溢出桶的数组前半段最后一个元素的下一个是第一个元素,即16后面是1。
// makeBucketArray initializes a backing array for map buckets.
// 1<<b is the minimum number of buckets to allocate.
// dirtyalloc should either be nil or a bucket array previously
// allocated by makeBucketArray with the same t and b parameters.
// If dirtyalloc is nil a new backing array will be alloced and
// otherwise dirtyalloc will be cleared and reused as backing array.
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
// For small b, overflow buckets are unlikely.
// Avoid the overhead of the calculation.
if b >= 4 {
// Add on the estimated number of overflow buckets
// required to insert the median number of elements
// used with this value of b.
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
if dirtyalloc == nil {
buckets = newarray(t.bucket, int(nbuckets))
} else {
。。。
}
if base != nbuckets {
// We preallocated some overflow buckets.
// To keep the overhead of tracking these overflow buckets to a minimum,
// we use the convention that if a preallocated overflow bucket's overflow
// pointer is nil, then there are more available by bumping the pointer.
// We need a safe non-nil pointer for the last overflow bucket; just use buckets.
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
四、Map的访问
有多个mapaccess方法,其中mapaccess1表示只返回value,mapaccess2表示返回value,exist,其他的暂不用了解
- 其中部分逻辑和注释可以忽略阅读
- hash := t.hasher(key, uintptr(h.hash0)) 首先计算hash值
- 通过hash值取模hash&m获得数组索引,然后获得对应桶的bmap结构:b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
- 如果正在扩容,则先从oldbuckets中查询,扩容分为sameSiz扩容和2倍扩容,如果是2倍扩容,老表长度为新表一半,故m >>= 1
- oldb为计算的老表的桶,evacuated函数的含义为疏散,即是否已经迁移到新桶
- 进入bucketloop,此时b代表的要么是非扩容状态下桶中的bmap,要么是扩容时的新数组中的桶或者老数据中的桶(取决于该桶是否已经迁移新数组)
- for ; b != nil; b = b.overflow(t) 即为遍历桶及其链接的溢出桶,即遍历桶链表,实际上否底层数组分配在同一片连续空间,只是用指针串成链表
- for i := uintptr(0); i < bucketCnt; i++ 遍历桶中8个元素的高位hash值
- t.indirectkey() 如果map的key类型是指针,则会使用指针指向的对象作为比较依据
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
// it will return a reference to the zero object for the elem type if
// the key is not in the map.
// NOTE: The returned pointer may keep the whole map live, so don't
// hold onto it for very long.
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
。。。
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
return unsafe.Pointer(&zeroVal[0])
}
五、Map的插入
如果阅读过Java的HashMap源码,实际上插入方法&扩容方法已经可以完全说明Map的实现原理,其他方法都可以依次类推,上述讲解了map的访问,实际上是方便理解
- 老规矩先计算插入元素的hash值:hash := t.hasher(key, uintptr(h.hash0))
- hash值取模获得最终bmap桶index对应的b对象:bucket := hash & bucketMask(h.B)
- 此处有个for循环,目的是遍历桶元素及其拉链的溢出桶,
- 内层for循环用于便利桶中8个kv对(其中部分有可能为空,用枚举的hash值标记),for i := uintptr(0); i < bucketCnt; i++
- 如果遍历桶中8个kv位置的当前位置有空位,则插入其中,记录要插入的index和key位置和value位置
- 如果遍历桶中8个kv位置的当前位置已经被占用了,说明要插入的地方已经有key-value对了,接下来就判断key是否相等,相等说明是一样的key,已经插入过旧value了,需要覆盖,如果不想等,则和tohash高位不想等是一样的,继续往后判断,如果后续有空位则插入其中
- 上述结束后,我们发现当桶满了之后,我们就没有插入了,所以桶拉链指向溢出桶的逻辑在更后面的逻辑中
- 插入溢出桶的逻辑不着急,先判断负载因子看需不需要扩容,需要的话则进行扩容
- 然后检查是否已经插入,没有插入说明map中没有位置可以插入了,需要创建溢出桶插入,这句代码就是给桶b插入溢出桶,让后将插入数据在在溢出桶首位。newb := h.newoverflow(t, b)
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
continue
}
// already have a mapping for key. Update it.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// Did not find mapping for key. Allocate new cell & add entry.
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// The current bucket and all the overflow buckets connected to it are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// store new key/elem at insert position
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
return elem
}
六、Map的扩容
1. 创建新数组,维护新老指针
根据map插入中的逻辑,会调用hashGrow函数进行扩容,可以容易看出函数中只涉及新数组的创建,以及维护新老数组、新老溢出桶的指针,并没有实际桶数据迁移操作
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
2. 迁移数据
在hashGrow函数的结尾注释中,迁移数据存在于函数growWork和evacuate里。属实有点复杂,下次再写,,,,等xmd催更
func growWork(t *maptype, h *hmap, bucket uintptr) {
// make sure we evacuate the oldbucket corresponding
// to the bucket we're about to use
evacuate(t, h, bucket&h.oldbucketmask())
// evacuate one more oldbucket to make progress on growing
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}