目录
引言
约定存储方式
消息序列化
重点理解
针对 MessageFileManager 单元测试
小结
引言
问题:
- 关于 Message(消息)为啥在硬盘上存储?
回答:
- 消息操作并不涉及到复杂的增删查改
- 消息数量可能会非常多,使用数据库的访问效率是并不高
- 因此我们不使用数据库进行存储,而是直接将消息存储到文件中
约定存储方式
- 此处设定了消息具体如何在文件中存储
约定一
- 消息依附于队列,因此在存储时,我们可以将消息按照 队列 纬度展开
- 之前我们因为引入 SQLite 已经设置了一个 data 目录(meta.db 就在该目录中)
- 所以我们可以在现有的 data 目录中存储一些子目录
- 每个子目录对应一个队列, 即 子目录名 就是 队列名
- 约定目录结构如上图所示
- 文件 queue_data.txt 保存消息的内容
- 文件 queue_stat.txt 保存消息的统计信息
// 约定消息文件所在的目录和文件名 // 这个方法,用来获取到指定队列对应的消息文件所在路径 private String getQueueDir(String queueName) { return "./data/" + queueName; } // 这个方法用来获取该队列的消息数据文件路径 // 二进制文件使用 txt 作为后缀,不太合适,txt 一般表示文本,此处我们也就不改了 // .bin / .dat private String getQueueDataPath(String queueName) { return getQueueDir(queueName) + "/queue_data.txt"; } // 这个方法用来获取该队列的消息统计文件路径 private String getQueueStatPath(String queueName) { return getQueueDir(queueName) + "/queue_stat.txt"; } // 创建队列对应的文件和目录 public void createQueueFiles(String queueName) throws IOException{ // 1、先创建队列对应的消息目录 File baseDir = new File(getQueueDir(queueName)); if(!baseDir.exists()) { // 不存在,就创建这个目录 boolean ok = baseDir.mkdirs(); if(!ok) { throw new IOException("创建目录失败!baseDir = " + baseDir.getAbsolutePath()); } } // 2、创建队列数据文件 File queueDataFile = new File(getQueueDataPath(queueName)); if(!queueDataFile.exists()){ boolean ok = queueDataFile.createNewFile(); if(!ok) { throw new IOException("创建文件失败!queueDataFile = " + queueDataFile.getAbsolutePath()); } } // 3、创建消息统计文件 File queueStatFile = new File(getQueueStatPath(queueName)); if(!queueStatFile.exists()){ boolean ok = queueStatFile.createNewFile(); if(!ok) { throw new IOException("创建文件失败!queueStatFile = " + queueStatFile.getAbsolutePath()); } } // 4、给消息统计文件,设定初始值 0\t0 Stat stat = new Stat(); stat.totalCont = 0; stat.validCount = 0; writeStat(queueName,stat); } // 删除队列的目录和文件 // 队列也是可以被删除的,当队列删除之后,对应的消息文件啥的,自然也要随之删除 public void destroyQueueFiles(String queueName) throws IOException{ // 先删除里面的文件,在删除目录 File queueDataFile = new File(getQueueDataPath(queueName)); boolean ok1 = queueDataFile.delete(); File queueStatFile = new File(getQueueStatPath(queueName)); boolean ok2 = queueStatFile.delete(); File baseDir = new File(getQueueDir(queueName)); boolean ok3 = baseDir.delete(); if(!ok1 || !ok2 || !ok3) { // 有任意一个删除失败,都算整体删除 throw new IOException("删除队列目录和文件失败! baseDir = " + baseDir.getAbsolutePath()); } } // 检查队列的目录和文件是否存在 // 比如后续有生产者给 broker server 生产消息了,这个消息就可能需要记录到文件上(取决于消息是否要持久化) public boolean checkFilesExits(String queueName) { // 判定队列的数据文件 和统计文件是否都存在!! File queueDataFile = new File(getQueueDataPath(queueName)); if(!queueDataFile.exists()) { return false; } File queueStatFile = new File(getQueueStatPath(queueName)); if(!queueStatFile.exists()) { return false; } return true; }
约定二
- queue_data 是一个二进制格式的文件
- 该文件中包含若干个消息,每个消息均以二进制的方式存储
- 约定每个消息的组成部分如上图所示
消息序列化
- 序列化就是将一个对象(结构化的数据)转成一个 字符串 或 字节数组
注意点一:
- 序列化完成之后,对象的信息不丢失
- 因此在后面进行反序列化操作时,才能将序列化的 字符串 或 字节数组 重新转化成对象
注意点二:
- 将对象序列化后,更方便存储和传输
- 存储:一般存储在文件中,文件只能存 字符串/二进制数据,不能直接存对象
- 传输:通过网络传输
JSON 格式
- 在 Java 中,Jackson 是一个流行的 JSON 处理库,它提供了 ObjectMapper 类来处理 JSON 数据的序列化和反序列化
问题:
- Message 中存储的 body 部分为二进制数据,可以用 JSON 进行序列化吗?
回答:
- JSON 格式通常用于标识文本数据,而无法直接存储二进制数据
- JSON 格式中包含一些特殊符号( : " { } ),如果直接存储二进制数据,可能会受到这些特殊符号的影响,导致 JSON 解析错误
具体理解:
- 如果存 文本数据,你的键值对中不会包含上述特殊符号
- 如果存 二进制数据,且万一某一二进制的字节正好就与上述特殊符号的 ASCII 一样,此时便可能会引起 JSON 解析格式错误
解决方案A
- 针对二进制数据进行 Base64 编码,将其转化为文本数据,然后再存储在 JSON 格式中
注意点一:
- Base64 将每 3 个字节的二进制数据转换为 4 个文本字符,从而确保所有字符都是文本字符,避免了特殊符号的问题(相当于是把二进制数据转成文本了)
- 比如在 HTML 中嵌入一个图片,图片其本身为二进制数据,此时便可以将图片的二进制 数据进行 Base64 编码,然后便可以把图片直接以文本的形式嵌入到 HTML 中
注意点二:
- Base64 这种方案,效率低,且伴随有额外转码开销,同时,还会使数据变得更大
解决方案B
- 放弃使用 JSON 格式,直接使用二进制的序列化方式,针对 Message 对象进行序列化
注意点一:
- 针对二进制序列化,有很多种解决方案
- Java 标准库提供了序列化的方案 ObjectInputStream 和 ObjectOutputStream
- Hessian
- protobuffer
- thrift
注意点二:
- 我们将直接使用 标准库自带的序列化方案
- 该方案最大的好处就是 不必引入额外的依赖
import java.io.*; //下列的逻辑,不仅仅是 Message,其他的 Java 中的对象,也是可以通过这样的逻辑进行序列化和反序列化的 //如果要想让这个对象能够序列化或者反序列化,需要让这个类能够实现 Serializable 接口 public class BinaryTool { // 把一个对象序列化成一个字节数组 public static byte[] toBytes(Object object) throws IOException { // 这个流对象相当于一个边长的字节数组 // 就可以把 object 序列化的数据给逐渐写入到 byteArrayOutputStream 中,再同一转成 byte[] try (ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){ try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)){ // 此处的 writerObject 就会把对象进行序列化,生成的二进制字节数据,就会写入到 // ObjectOutputStream 中 // 由于 ObjectOutputStream 有关联到了 ByteArrayOutputStream,最终结果就写入到 ByteArrayOutputStream 里了 objectOutputStream.writeObject(object); } // 这个操作就是把 byteArrayOutputStream 中持有的二进制数据取出来,转成 byte[] return byteArrayOutputStream.toByteArray(); } } // 把一个数组反序列化成一个对象 public static Object fromBytes(byte[] data) throws IOException,ClassNotFoundException{ Object object = null; try (ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(data)){ try (ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)){ // 此处的 readObject 就是从 data 这个 byte[] 中读取数据并进行反序列化 object = objectInputStream.readObject(); } } return object; } }
约定三
- 对于 Broker Server 来说,消息既需要新增,也需要删除
具体理解:
- 生产者生产一个消息过来,就得新增这个消息
- 消费者把这个消息消费掉,这个消息就得删除
注意:
- 新增和删除,对于内存来说,好办~(直接使用一些集合类即可)
- 但是在文件上就麻烦了!
- 新增消息,可以直接将新消息追加到文件末尾
- 删除消息,不好搞
具体理解:
- 文件可以视为是一个 "顺序表" 这样的结构
- 如果直接删除中间元素,就需要涉及到类似于 顺序表搬运 这样的操作,效率是非常低的
- 因此使用这种搬运的方式删除 是不合适的,所以我们采取逻辑删除
- 约定一个 isValid 成员变量给 Message 如上图所示
- isValid 为 1 表示该条 Message 为有效消息
- isValid 为 0 表示该条 Message 为无效消息(即已经被删除)
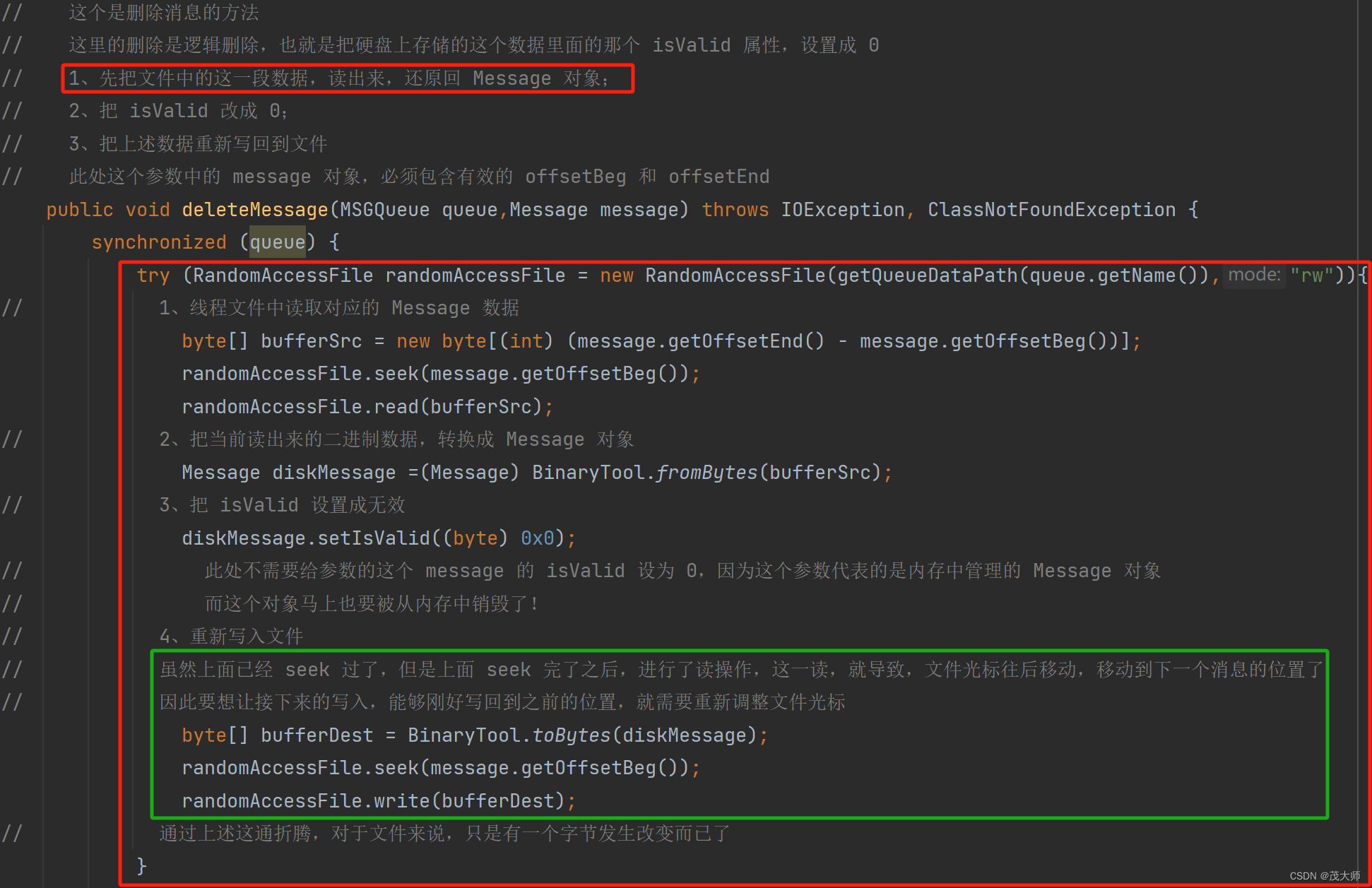
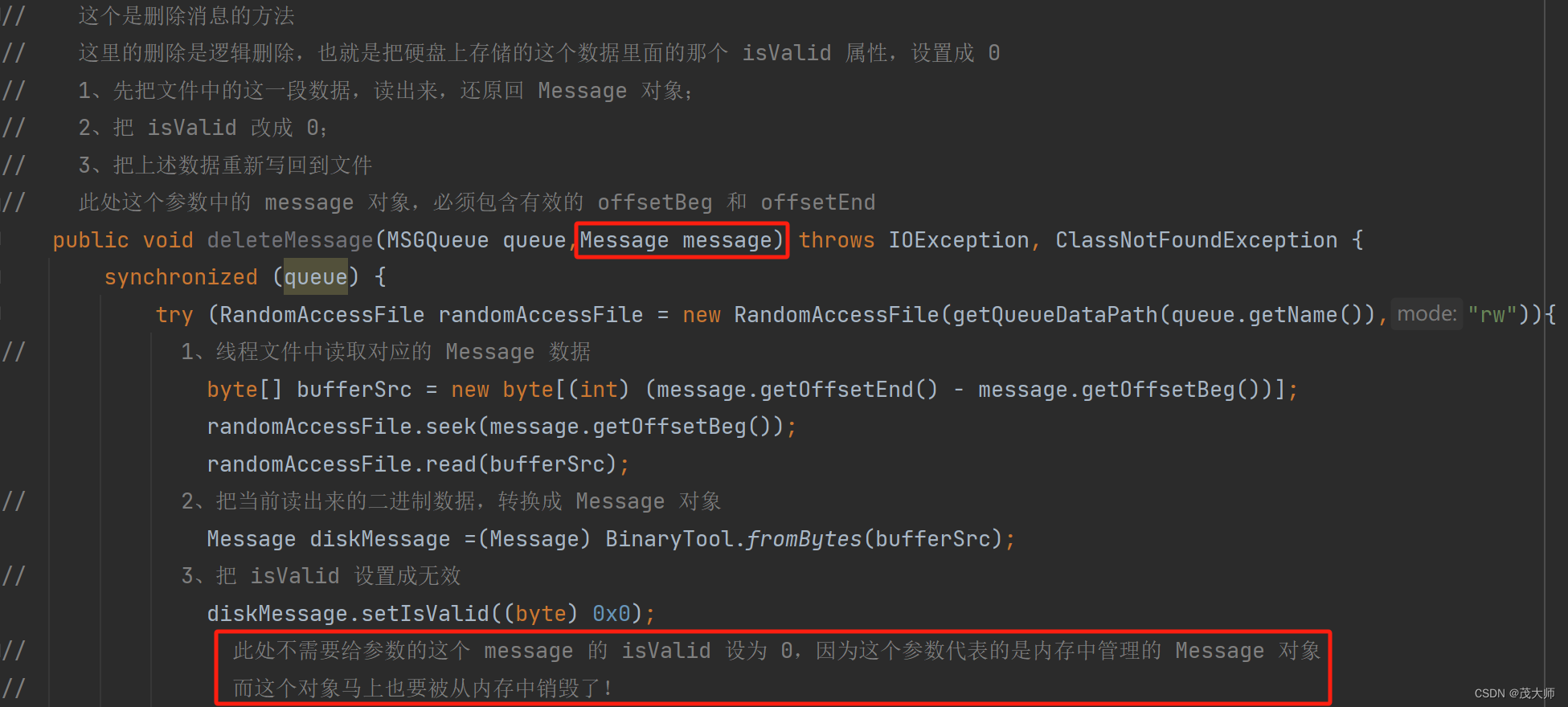
// 这个方法用来把一个新的消息,当到队列对应的文件中 // queue 表示要把消息写入的队列 message 则是要写的消息 public void sendMessage(MSGQueue queue, Message message) throws MqException, IOException { // 1、检查一下当前要写入的队列对应的文件是否存在 if(!checkFilesExits(queue.getName())) { throw new MqException("[MessageFileManager] 队列对应的文件不存在! queueName = " + queue.getName()); } // 2、把 Message 对象进行序列化,转成二进制的字节数组 byte[] messageBinary = BinaryTool.toBytes(message); synchronized (queue) { // 3、先获取到当前的队列数据文件的长度,用这个来计算出 Message 对象的 offsetBeg 和 offsetEnd // 把新的 Message 数据,写入到队列数据文件的末尾,此时 Message 对象的 offsetBeg,就是当前文件长度 + 4 // offsetEnd 就是当前文件长度 + 4 + message 自身长度 File queueDataFile = new File(getQueueDataPath(queue.getName())); // 通过这个方法 queueDataFile.length() 就能获取到文件到长度,单位字节 message.setOffsetBeg(queueDataFile.length() + 4); message.setOffsetEnd(queueDataFile.length() + 4 + messageBinary.length); // 4、写入消息到数据文件,注意,是追加写入到数据文件末尾 try (OutputStream outputStream = new FileOutputStream(queueDataFile,true)){ // 接下来要先写当前消息的长度,占据 4 个字节的 // outputStream.write(messageBinary.length); 实际只写入 1 字节 try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){ dataOutputStream.writeInt(messageBinary.length); // 写入消息本体 dataOutputStream.write(messageBinary); } } // 5、更新消息统计文件 Stat stat = readStat(queue.getName()); stat.totalCont +=1; stat.validCount +=1; writeStat(queue.getName(),stat); } } // 这个是删除消息的方法 // 这里的删除是逻辑删除,也就是把硬盘上存储的这个数据里面的那个 isValid 属性,设置成 0 // 1、先把文件中的这一段数据,读出来,还原回 Message 对象; // 2、把 isValid 改成 0; // 3、把上述数据重新写回到文件 // 此处这个参数中的 message 对象,必须包含有效的 offsetBeg 和 offsetEnd public void deleteMessage(MSGQueue queue,Message message) throws IOException, ClassNotFoundException { synchronized (queue) { try (RandomAccessFile randomAccessFile = new RandomAccessFile(getQueueDataPath(queue.getName()),"rw")){ // 1、线程文件中读取对应的 Message 数据 byte[] bufferSrc = new byte[(int) (message.getOffsetEnd() - message.getOffsetBeg())]; randomAccessFile.seek(message.getOffsetBeg()); randomAccessFile.read(bufferSrc); // 2、把当前读出来的二进制数据,转换成 Message 对象 Message diskMessage =(Message) BinaryTool.fromBytes(bufferSrc); // 3、把 isValid 设置成无效 diskMessage.setIsValid((byte) 0x0); // 此处不需要给参数的这个 message 的 isValid 设为 0,因为这个参数代表的是内存中管理的 Message 对象 // 而这个对象马上也要被从内存中销毁了! // 4、重新写入文件 // 虽然上面已经 seek 过了,但是上面 seek 完了之后,进行了读操作,这一读,就导致,文件光标往后移动,移动到下一个消息的位置了 // 因此要想让接下来的写入,能够刚好写回到之前的位置,就需要重新调整文件光标 byte[] bufferDest = BinaryTool.toBytes(diskMessage); randomAccessFile.seek(message.getOffsetBeg()); randomAccessFile.write(bufferDest); // 通过上述这通折腾,对于文件来说,只是有一个字节发生改变而已了 } // 不要忘了更新统计文件!把一个消息设为无效了,此时有效消息个数就需要 -1 Stat stat = readStat(queue.getName()); if(stat.validCount > 0) { stat.validCount -=1; } writeStat(queue.getName(),stat); } } // 使用这个方法,从文件中,读取出所有的消息内容,加载到内存中(具体来说是放到一个链表里) // 这个方法,准备在程序启动的时候,进行调用 // 这里使用一个 LinkedList,主要目的是为了后续进行头删操作 // 这个方法的参数,只是一个 queueName 而不是 MSGQueue 对象 因为这个方法无需加锁,只使用 queueName 就够了 // 由于该方法是在程序启动时调用,此时服务器还不能处理请求,即不涉及多线程操作文件 public LinkedList<Message> loadAllMessageFromQueue(String queueName) throws IOException, MqException, ClassNotFoundException { LinkedList<Message> messages = new LinkedList<>(); try (InputStream inputStream = new FileInputStream(getQueueDataPath(queueName))){ try (DataInputStream dataInputStream = new DataInputStream(inputStream)){ // 这个变量记录当前文件光标 long currentOffset = 0; // 一个文件包含了很多消息,此处势必要循环读取 while (true) { // 1、读取当前消息的长度,这里的 readInt() 可能会读到文件的末尾(EOF) // readInt() 方法,读到文件末尾,会抛出一个 EOFException 异常,这一点和之前的很多流对象不太一样 int messageSize = dataInputStream.readInt(); // 2、按照这个长度,读取消息内容 byte[] buffer = new byte[messageSize]; int actualSize = dataInputStream.read(buffer); if (messageSize != actualSize){ // 如果不匹配,说明文件有问题,格式错误了,即文件剩余的空间不够 throw new MqException("[MessageFileManager] 格式文件错误! queueName = " + queueName); } // 3、把读到的二进制数据,反序列化回 Message 对象 Message message = (Message) BinaryTool.fromBytes(buffer); // 4、判定一下看看这个消息对象,是不是无效对象 if(message.getIsValid() != 0x1) { // 无效数据,直接跳过 continue; } // 5、有效数据,则需要把这个 Message 对象加入到链表中,加入之前还需要填写 offsetBeg 和 offsetEnd // 进行计算 offset 的时候,需要知道当前文件光标的位置的 由于当下使用的 DataInputStream 并不方便直接获取到文件光标 // 因此就需要手动计算下文件光标 message.setOffsetBeg(currentOffset + 4); message.setOffsetEnd(currentOffset + 4 + messageSize); currentOffset += (4 + messageSize); messages.add(message); } }catch (EOFException e) { // 这个 catch 并非真是处理 "异常",而是处理 "正常" 的业务逻辑,文件读到末尾,会被 readInt 抛出该异常 // 这个 catch 语句中也不需要做啥特殊的事情 System.out.println("[MessageFileManager] 恢复 Message 数据完成!"); } } return messages; }
约定四
- 使用 逻辑删除 会衍生出一个问题
- 随着时间的推移,queue_data 消息文件可能会越来越大,并且其中的无效消息也会随之增加
- 针对这种情况,就需考虑对当前队列对应的 queue_data 消息数据文件,进行垃圾回收
注意:
- 此处我们使用 复制算法,针对 queue_data 消息数据文件中的无效消息进行回收
- 直接遍历原有的消息数据文件,将所有的有效消息拷贝到一个新文件中,再把之前整个旧文件都删除
- 复制算法 比较适用的前提是,当前空间里,有效消息不多,且大部分都是无效数据
问题:
- 究竟什么时候触发一次 GC? 什么时候才知道当前有效消息不多,无效消息很多呢?
回答:
- 约定当总消息数目超过 2000,且有效消息数目低于总消息数目的 50%,就触发一次 GC
约定五
- 约定四中的数字 2000 是为了避免 GC 的太频繁
- 比如一共 4 个消息,其中 2 个消息无效了,就触发 GC,属实没必要
- 当然,2000 和 50% 这两个数字均可根据实际场景进行灵活调整
注意:
- 约定 queue_stat 这个文件来保存消息的统计信息,该文件仅存一行数据
文本格式:
- 这一行里有两列
- 第一列是 queue_data.txt 中总的消息的数目(totalCont)
- 第二列是 queue_data.txt 中有效消息的数目(validCount)
- 两者使用 \t 分割
- 形如 2000\t500 那么此时就需要触发 GC
// 此处定义一个内部类,来表示该队列的统计信息 // 有限考虑使用 static,静态内部类 static public class Stat { // 此处直接定义成 public, 就不再搞 get set 方法了 // 对于这样的简单的类,就直接使用成员,类似于 C 的结构体了 public int totalCont; public int validCount; } private Stat readStat(String queueName) { // 由于当前的消息统计文件是文本文件,可以直接使用 Scanner 来读取文件内容 Stat stat = new Stat(); try (InputStream inputStream = new FileInputStream(getQueueStatPath(queueName))){ Scanner scanner = new Scanner(inputStream); stat.totalCont = scanner.nextInt(); stat.validCount = scanner.nextInt(); return stat; }catch (IOException e) { e.printStackTrace(); } return null; } private void writeStat(String queueName,Stat stat) { // 使用 PrintWrite 来写文件 // OutputStream 打开文件,默认情况下,会直接把原文件清空 此时相当于新的数据覆盖了旧的! try (OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName))){ PrintWriter printWriter = new PrintWriter(outputStream); printWriter.write(stat.totalCont + "\t" + stat.validCount); printWriter.flush(); }catch (IOException e) { e.printStackTrace(); } } // 检查当前是否要针对该队列的消息数据文件进行 GC public boolean checkGC(String queueName) { // 判定是否要 GC,是根据总消息数和有效消息数,这两个值都是在 消息统计文件 中的 Stat stat = readStat(queueName); if(stat.totalCont > 2000 && (double)stat.validCount / (double) stat.totalCont < 0.5){ return true; } return false; } private String getQueueDataNewPath(String queueName) { return getQueueDir(queueName) + "/queue_data_new.txt"; } // 通过这个方法,真正执行消息数据文件的垃圾回收操作 // 使用复制算法来完成 // 创建一个新的文件,名字就是 queue_data_new.txt // 把之前消息数据文件中的有效消息都读取出来,写到新的文件中 // 删除旧的文件,再把新的文件改名回 queue_data.txt public void gc(MSGQueue queue) throws MqException, IOException, ClassNotFoundException { // 进行 GC 的时候,是针对消息数据文件进行大洗牌,在这个过程中,其他线程不能针对该队列的消息文件做任何修改 synchronized (queue) { // 由于 GC 操作可能比较耗时,此时统计一下执行消耗的时间 long gcBeg = System.currentTimeMillis(); // 1、创建一个新的文件 File queueDataNewFile = new File(getQueueDataNewPath(queue.getName())); if(queueDataNewFile.exists()) { // 正常情况下,这个文件不应该存在,如果存在,就是意外,即上次 gc 了一半,程序意外崩溃了 throw new MqException("[MessageFileManager] gc 时发现该队列的 queue_data_new 已经存在! queueName=" + queue.getName()); } boolean ok = queueDataNewFile.createNewFile(); if(!ok) { throw new MqException("[MessageFileManager] 创建文件失败! queueDataNewFile=" + queueDataNewFile.getAbsolutePath()); } // 2、从旧文件中,读取出所有的有效消息对象了 (这个逻辑直接调用上述方法即可,不必重新写了) LinkedList<Message> messages = loadAllMessageFromQueue(queue.getName()); // 3、把有效消息,写入到新的文件中 try (OutputStream outputStream = new FileOutputStream(queueDataNewFile)){ try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)){ for (Message message : messages) { byte[] buffer = BinaryTool.toBytes(message); // 先写四个字节消息的长度 dataOutputStream.writeInt(buffer.length); dataOutputStream.write(buffer); } } } // 4、删除旧的数据文件,并且把新的文件进行重命名 File queueDataOldFile = new File(getQueueDataPath(queue.getName())); ok = queueDataOldFile.delete(); if(!ok) { throw new MqException("[MessageFileManager] 删除旧的数据文件失败! queueDataOldFile=" + queueDataOldFile.getAbsolutePath()); } // 把 queue_data_new.txt => queue_data.txt ok = queueDataNewFile.renameTo(queueDataOldFile); if(!ok) { throw new MqException("[MessageFileManager] 文件重命名失败! queueDataNewFile=" + queueDataNewFile.getAbsolutePath() + ",queueDataOldFile=" + queueDataOldFile.getAbsolutePath()); } // 5、更新统计文件 Stat stat = readStat(queue.getName()); stat.totalCont = messages.size(); stat.validCount = messages.size(); writeStat(queue.getName(), stat); long gcEnd = System.currentTimeMillis(); System.out.println("[MessageFileManager] gc 执行完毕! queueName=" + queue.getName() + ",time=" + (gcEnd - gcBeg) + "ms"); } }
引入问题
- 如果某个队列中,消息特别多,而且这些都是有效消息
- 此时便会导致整个 queue_data 消息数据文件变得特别大,后续针对这个文件的各种操作,其成本就会上升很多
- 假设某文件的大小为 10G,此时如果触发一次 GC,其整体的耗时就会非常高了!
解决方案:
- 对于 RabbitMQ 来说,其解决方案是把一个大文件,拆分成若干个小文件
- 文件拆分:当单个文件长度达到一定阈值后,便会拆分成两个文件(拆着拆着,就成了很多文件)
- 文件合并:每个单独的文件都会进行 GC,如果 GC 之后,发现文件变小了很多,就可能会和相邻的其他文件合并
- 通过上述方式,便可在消息特别多时,同时保证性能上的及时响应
注意:
- 这一块的逻辑还比较复杂~ 此处我们仅考虑单个文件的情况
实现该机制的大致思路:
- 需要专门的数据结构,来存储当前队列中有多少个数据文件(每个文件大小是多少,消息数目是多少,无效消息是多少)
- 设计策略,什么时候触发文件的拆分,什么时候触发文件的合并



重点理解
理解一
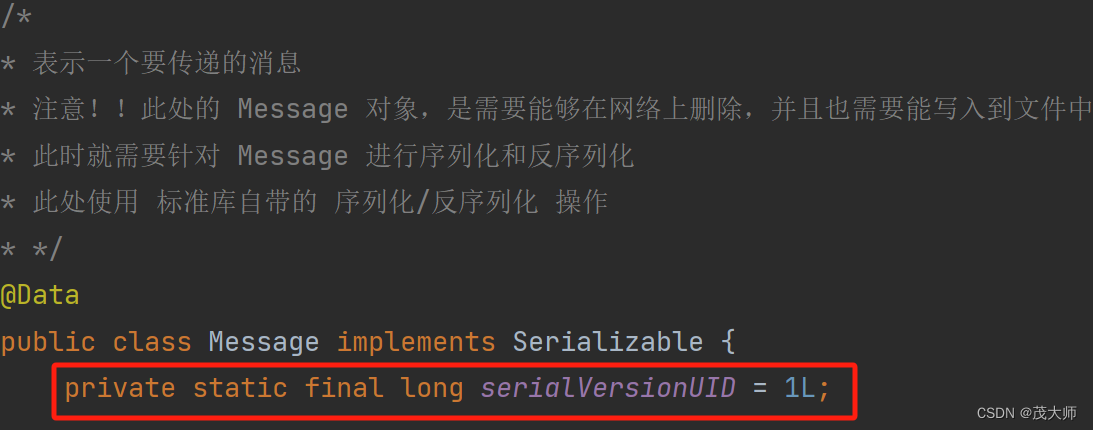
- 此处的 serialVersionUID 用于验证版本
注意:
- 在实际开发中,代码是不断修改更新的
具体理解:
- 有一个 Message ,且对该 Message 进行序列化,并将序列化的结果存储到对对应的 queue_data.txt 文件中
- 如果在这期间该 Message 里的东西更新了!但还未重新序列化更新
- 如果此时想要进行反序列化操作时,那么拿到的将是一个旧版本的 Message
- 所以我们通过设置一个 serialVersionUID 来验证代码是否与序列化的数据相互匹配,如果不匹配就不允许反序列化,直接报错,提醒从程序员数据有问题
理解二
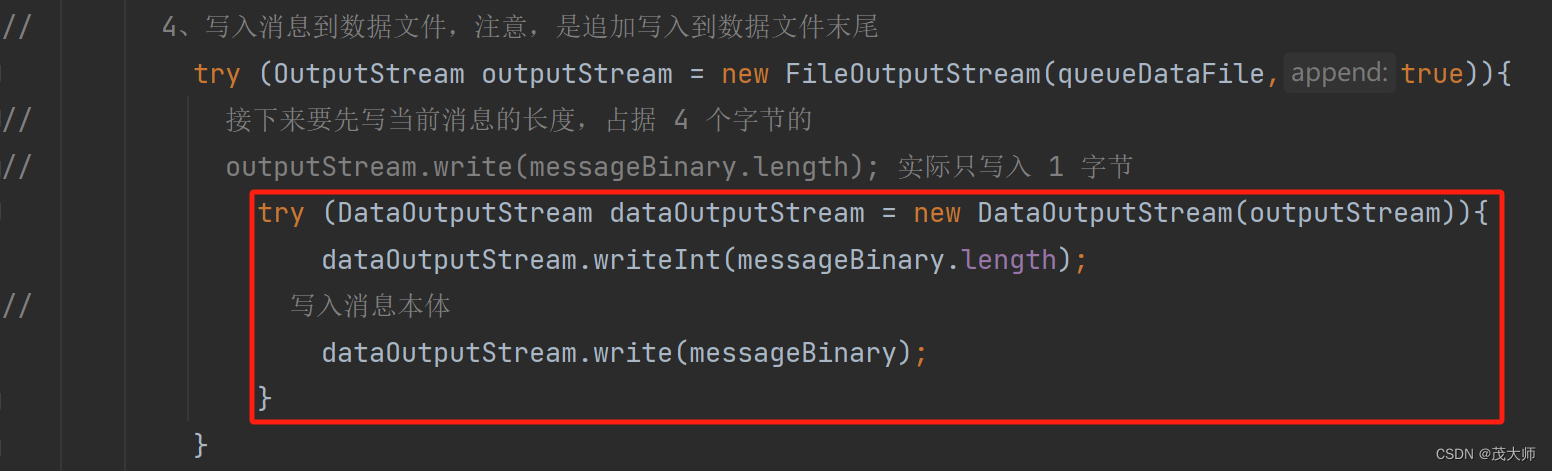
- 此处我们需要往对应的 queue_data.txt 文件中,先写入 Message 消息的长度
- 上文我们已经约定好 Message 消息的长度为 4个字节,所以此处需写 4个字节的数据
注意:
- 如上图所示,虽然这个 write 方法的参数为 int 类型,但是实际上只能写 1个字节
- 在流对象中,经常会涉及到使用 int 表示 byte 的情况
问题:
- 是否可以将 int 的 4个字节分别取出来,然后一个一个字节的写入文件呢?
回答:
- 通过位运算即可!
- 将每个字节按照位运算的方式取出来,再按照字节写入到文件中~
小总结:
- 上述这种方式固然可以,但是还是比较繁琐的
- Java 标准库已经提供了现成的类,即已经帮我们封装好了上述操作
- DataOutputStream / DataInputStream
理解三
- 当两个线程同时写 同一个队列对应的 queue_data.txt 文件时,可能存在线程安全问题
- 当两个线程同时写 同一个队列对应的 queue_stat.txt 文件时,也可能存在线程安全问题
- 与经典线程安全问题的 count++ 相类似
- 所以我们需要对上述代码操作加锁
问题:
- 此处的锁对象是什么?即需要写到 synchronized () 里的对象是什么?
回答:
- 当前以 队列对象 进行加锁即可
- 如果两个线程,是往同一个队列中写消息,此时需要阻塞等待
- 如果两个线程,往不同队列中写消息,此时不需要阻塞等待(不同队列,对应不同的文件,各写各的,不会产生冲突)
注意:
- 这个代码在编写时,IDEA 会给一个警告,当前的加锁是针对方法的参数加锁的
- IDEA 分析不出来这个方法的实参究竟会传啥,IDEA 不确认你这个加锁是否能真的达到预期效果
- 后续调用这个方法,传入的 queue 对象,是后续通过内存管理的 queue 对象
- 总而言之,上述写法必须是 两个线程针对同一个 queue 对象进行加锁才能有效
理解四
- 之前用过的 FileInputStream 和 FileOutputStream 都是从文件头进行读写的
- 而此处我们想要删除 queue_data.txt 中的某条消息
- 所以需要能够在 queue_data.txt 文件中的指定位置进行读写操作,即针对文件进行随机访问
解决方案:
- 此处我们用到的类为 RandomAccessFile
- read 方法用来读,write 方法用来写
- seek 方法用来调整当前文件光标,即当前要读写文件的位置
注意点一:
- seek 方法虽然可以使使文件光标移动, 但是使用 read 和 write 方法也会引起光标移动
注意点二:
- 内存就支持随机访问
- 内存的随机访问,访问内存的任意一个地址,其开销成本都差不多
- 典型的例子为 数组取下标操作的时间复杂度为 O(1)
- 硬盘也能支持随机访问,即上述文件光标的移动
- 但是硬盘的随机访问,其成本/开销,比内存是要高很多的!(尤其机器硬盘)
理解五
- 此处红框中的 Message 对象,是在内存中管理的 消息对象
- 刚才从硬盘上读出来的 diskMessage,这是硬盘上管理的消息对象
问题:
- 什么时候调用我们刚刚写的这个删除硬盘上的消息对象的操作方法呢?
回答:
- 显然是确实要删除这个消息,即消费者已经将该消息正确处理完便可删除
- 这个删除,就是把内存的 Message 对象 和 硬盘的 Message 对象都删除
- 而我们此处的 deleteMessage 方法仅用来逻辑删除 硬盘中的 Message 对象
- isValid 属性只是用来在文件中标识这个消息有效这样的作用的
- 相较于删除内存中的 Message 对象,删除内存中的 Message 对象要容易很多!





针对 MessageFileManager 单元测试
- 编写测试用例代码是十分重要的!
package com.example.demo; import com.example.demo.common.MqException; import com.example.demo.mqserver.core.MSGQueue; import com.example.demo.mqserver.core.Message; import com.example.demo.mqserver.datacenter.MessageFileManager; import org.junit.jupiter.api.AfterEach; import org.junit.jupiter.api.Assertions; import org.junit.jupiter.api.BeforeEach; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; import org.springframework.test.util.ReflectionTestUtils; import java.io.File; import java.io.IOException; import java.util.LinkedList; import java.util.List; @SpringBootTest public class MessageFileManagerTest { private MessageFileManager messageFileManager = new MessageFileManager(); private static final String queueName1 = "testQueue1"; private static final String queueName2 = "testQueue2"; // 这个方法是每个用例执行之前的准备工作 @BeforeEach public void setUp() throws IOException { // 准备阶段,创建出两个队列,以后备用 messageFileManager.createQueueFiles(queueName1); messageFileManager.createQueueFiles(queueName2); } // 这个方法就是每个用例执行完毕之后的收尾工作 @AfterEach public void tearDown() throws IOException { // 收尾阶段,就把刚才的队列给干掉 messageFileManager.destroyQueueFiles(queueName1); messageFileManager.destroyQueueFiles(queueName2); } @Test public void testCreateFiles() { // 创建队列文件已经在上面 setUp 阶段执行过了,此处主要是验证看看文件是否存在 File queueDataFile1 = new File("./data/" + queueName1 + "/queue_data.txt"); Assertions.assertEquals(true,queueDataFile1.isFile()); File queueStatFile1 = new File("./data/" + queueName1 + "/queue_stat.txt"); Assertions.assertEquals(true,queueStatFile1.isFile()); File queueDataFile2 = new File("./data/" + queueName2 + "/queue_data.txt"); Assertions.assertEquals(true,queueDataFile2.isFile()); File queueStatFile2 = new File("./data/" + queueName2 + "/queue_stat.txt"); Assertions.assertEquals(true,queueStatFile2.isFile()); } @Test public void testReadWriteStat() { MessageFileManager.Stat stat = new MessageFileManager.Stat(); stat.totalCont = 100; stat.validCount = 50; // 此处就需要使用反射的方式,来调用 writeStat 和 readStat 了 // Java 原生的反射 API 其实非常难用 // 此处使用 Spring 帮我们封装好的 反射 的工具类 ReflectionTestUtils.invokeMethod(messageFileManager,"writeStat",queueName1,stat); // 写入完毕之后,再调用一下读取,验证读取的结果和写入的数据是一致的 MessageFileManager.Stat newStat = ReflectionTestUtils.invokeMethod(messageFileManager,"readStat",queueName1); Assertions.assertEquals(100,newStat.totalCont); Assertions.assertEquals(50,newStat.validCount); } private MSGQueue createTestQueue(String queueName) { MSGQueue queue = new MSGQueue(); queue.setName(queueName); queue.setDurable(true); queue.setAutoDelete(false); queue.setExclusive(false); return queue; } private Message createTestMessage(String content) { Message message = Message.createMessageWithId("testRoutingKey",null,content.getBytes()); return message; } @Test public void testSendMessage() throws IOException, MqException, ClassNotFoundException { // 构造出消息,并且构造出队列 Message message = createTestMessage("testMessage"); // 此处创建的 queue 对象的 name,不能随便写,只能用 queueName1 和 queueName2,需要保证这个队列对象对应的目录和文件啥的都存在才行 MSGQueue queue = createTestQueue(queueName1); // 调用发送消息方法 messageFileManager.sendMessage(queue,message); // 检查 stat 文件 MessageFileManager.Stat stat = ReflectionTestUtils.invokeMethod(messageFileManager,"readStat",queueName1); Assertions.assertEquals(1,stat.totalCont); Assertions.assertEquals(1,stat.validCount); // 检查 data 文件 LinkedList<Message> messages = messageFileManager.loadAllMessageFromQueue(queueName1); Assertions.assertEquals(1,messages.size()); Message curMessage = messages.get(0); Assertions.assertEquals(message.getMessageId(),curMessage.getMessageId()); Assertions.assertEquals(message.getRoutingKey(),curMessage.getRoutingKey()); Assertions.assertEquals(message.getDeliverMode(),curMessage.getDeliverMode()); // 比较两个字节数组的内容是否相同,不能直接使用 assertEquals 了 Assertions.assertArrayEquals(message.getBody(),curMessage.getBody()); System.out.println("message : " + curMessage); } @Test public void testLoadAllMessageFromQueue() throws IOException, MqException, ClassNotFoundException { // 往队列中插入 100 条消息,然后验证看看这 100 条消息从文件中读取之后,是否和最初是一致的 MSGQueue queue = createTestQueue(queueName1); List<Message> expectedMessages = new LinkedList<>(); for (int i = 0; i < 100; i++) { Message message = createTestMessage("testMessage" + i); messageFileManager.sendMessage(queue,message); expectedMessages.add(message); } // 读取所有消息 LinkedList<Message> actualMessages = messageFileManager.loadAllMessageFromQueue(queueName1); Assertions.assertEquals(expectedMessages.size(),actualMessages.size()); for (int i = 0; i < expectedMessages.size(); i++) { Message expectedMessage = expectedMessages.get(i); Message actualMessage = actualMessages.get(i); System.out.println("["+ i +"] actualMessage=" + actualMessage); Assertions.assertEquals(expectedMessage.getMessageId(),actualMessage.getMessageId()); Assertions.assertEquals(expectedMessage.getRoutingKey(),actualMessage.getRoutingKey()); Assertions.assertEquals(expectedMessage.getDeliverMode(),actualMessage.getDeliverMode()); Assertions.assertArrayEquals(expectedMessage.getBody(),actualMessage.getBody()); Assertions.assertEquals(0x1,actualMessage.getIsValid()); } } @Test public void testDeleteMessage() throws IOException, MqException, ClassNotFoundException { // 创建队列,写入 10 个消息,删除其中的几个消息,再把所有消息读取出来,判定是否符合预期 MSGQueue queue = createTestQueue(queueName1); List<Message> expectedMessages = new LinkedList<>(); for (int i = 0; i < 10; i++) { Message message = createTestMessage("testMessage" + i); messageFileManager.sendMessage(queue,message); expectedMessages.add(message); } // 删除其中的三个消息 messageFileManager.deleteMessage(queue,expectedMessages.get(7)); messageFileManager.deleteMessage(queue,expectedMessages.get(8)); messageFileManager.deleteMessage(queue,expectedMessages.get(9)); // 对比这里的内容是否正确 LinkedList<Message> actualMessages = messageFileManager.loadAllMessageFromQueue(queueName1); Assertions.assertEquals(7,actualMessages.size()); for (int i = 0; i < actualMessages.size(); i++) { Message expectedMessage = expectedMessages.get(i); Message actualMessage = actualMessages.get(i); System.out.println("["+ i +"] actualMessage=" + actualMessage); Assertions.assertEquals(expectedMessage.getMessageId(),actualMessage.getMessageId()); Assertions.assertEquals(expectedMessage.getRoutingKey(),actualMessage.getRoutingKey()); Assertions.assertEquals(expectedMessage.getDeliverMode(),actualMessage.getDeliverMode()); Assertions.assertArrayEquals(expectedMessage.getBody(),actualMessage.getBody()); Assertions.assertEquals(0x1,actualMessage.getIsValid()); } } @Test public void testGC() throws IOException, MqException, ClassNotFoundException { // 先往队列中写 100 个消息 // 再把 100 个消息中的一半,都给删除掉(比如把下标为偶数的消息都删除) // 再手动调用 gc 方法,检测得到的新的文件的大小是否比之前缩小了 MSGQueue queue = createTestQueue(queueName1); LinkedList<Message> expectedMessages = new LinkedList<>(); for (int i = 0; i < 100; i++) { Message message = createTestMessage("testMessage" + i); messageFileManager.sendMessage(queue,message); expectedMessages.add(message); } // 获取 gc 前的文件大小 File beforeGCFile = new File("./data/" + queueName1 + "./queue_data.txt"); long beforeGCLength = beforeGCFile.length(); // 删除偶数下标的消息 for (int i = 0; i < 100; i+=2) { messageFileManager.deleteMessage(queue,expectedMessages.get(i)); } // 手动调用 gc messageFileManager.gc(queue); // 重新读取文件,验证新的文件的内容是不是和之前的内容匹配 LinkedList<Message> actualMessages = messageFileManager.loadAllMessageFromQueue(queueName1); Assertions.assertEquals(50,actualMessages.size()); for (int i = 0; i < actualMessages.size(); i++) { // 把之前消息偶数下标的删了,剩下的就是奇数下标的元素了 // actual 中的 0 对应 expected 的 1 // actual 中的 1 对应 expected 的 3 // actual 中的 2 对应 expected 的 5 // actual 中的 i 对应 expected 的 2 * i + 1 Message expectedMessage = expectedMessages.get(2 * i +1); Message actualMessage = actualMessages.get(i); Assertions.assertEquals(expectedMessage.getMessageId(),actualMessage.getMessageId()); Assertions.assertEquals(expectedMessage.getRoutingKey(),actualMessage.getRoutingKey()); Assertions.assertEquals(expectedMessage.getDeliverMode(),actualMessage.getDeliverMode()); Assertions.assertArrayEquals(expectedMessage.getBody(),actualMessage.getBody()); Assertions.assertEquals(0x1,actualMessage.getIsValid()); } // 获取新的文件的大小 File afterGCFile = new File("./data/" + queueName1 + "/queue_data.txt"); long afterGCLength = afterGCFile.length(); System.out.println("before: " + beforeGCLength); System.out.println("after: " + afterGCLength); Assertions.assertTrue(beforeGCLength > afterGCLength); } }
小结
- MessageFileManager 类主要是负责管理消息在文件中的存储
- 设计了目录结构和文件格式
- 实现了目录创建和删除
- 实现了统计文件的读写
- 实现了消息的写入
- 实现了消息的删除 => 随机访问文件
- 实现了加载所有消息
- 垃圾回收