参考文档:https://github.com/InternLM/tutorial/tree/main/langchain
基础作业:复现课程知识库助手搭建过程 (截图)
1.环境配置
2.知识库搭建
(1)数据收集
收集由上海人工智能实验室开源的一系列大模型工具开源仓库作为语料库来源,为语料处理方便,我们将选用上述仓库中所有的 markdown、txt 文件作为示例语料库。注意,也可以选用其中的代码文件加入到知识库中,但需要针对代码文件格式进行额外处理(因为代码文件对逻辑联系要求较高,且规范性较强,在分割时最好基于代码模块进行分割再加入向量数据库)。

(2)在本地构建持久化的向量数据库
# 首先导入所需第三方库
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from tqdm import tqdm
import os
# 获取文件路径函数
def get_files(dir_path):
# args:dir_path,目标文件夹路径
file_list = []
for filepath, dirnames, filenames in os.walk(dir_path):
# os.walk 函数将递归遍历指定文件夹
for filename in filenames:
# 通过后缀名判断文件类型是否满足要求
if filename.endswith(".md"):
# 如果满足要求,将其绝对路径加入到结果列表
file_list.append(os.path.join(filepath, filename))
elif filename.endswith(".txt"):
file_list.append(os.path.join(filepath, filename))
return file_list
# 加载文件函数
def get_text(dir_path):
# args:dir_path,目标文件夹路径
# 首先调用上文定义的函数得到目标文件路径列表
file_lst = get_files(dir_path)
# docs 存放加载之后的纯文本对象
docs = []
# 遍历所有目标文件
for one_file in tqdm(file_lst):
file_type = one_file.split('.')[-1]
if file_type == 'md':
loader = UnstructuredMarkdownLoader(one_file)
elif file_type == 'txt':
loader = UnstructuredFileLoader(one_file)
else:
# 如果是不符合条件的文件,直接跳过
continue
docs.extend(loader.load())
return docs
# 目标文件夹
tar_dir = [
"/root/data/InternLM",
"/root/data/InternLM-XComposer",
"/root/data/lagent",
"/root/data/lmdeploy",
"/root/data/opencompass",
"/root/data/xtuner"
]
# 加载目标文件
docs = []
for dir_path in tar_dir:
docs.extend(get_text(dir_path))
# 对文本进行分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
# 加载开源词向量模型
embeddings = HuggingFaceEmbeddings(model_name="/root/data/model/sentence-transformer")
# 构建向量数据库
# 定义持久化路径
persist_directory = 'data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
# 将加载的向量数据库持久化到磁盘上
vectordb.persist()
可以在 /root/data 下新建一个 demo目录,将该脚本和后续脚本均放在该目录下运行。运行上述脚本,即可在本地构建已持久化的向量数据库,后续直接导入该数据库即可,无需重复构建。
3 InternLM 接入 LangChain
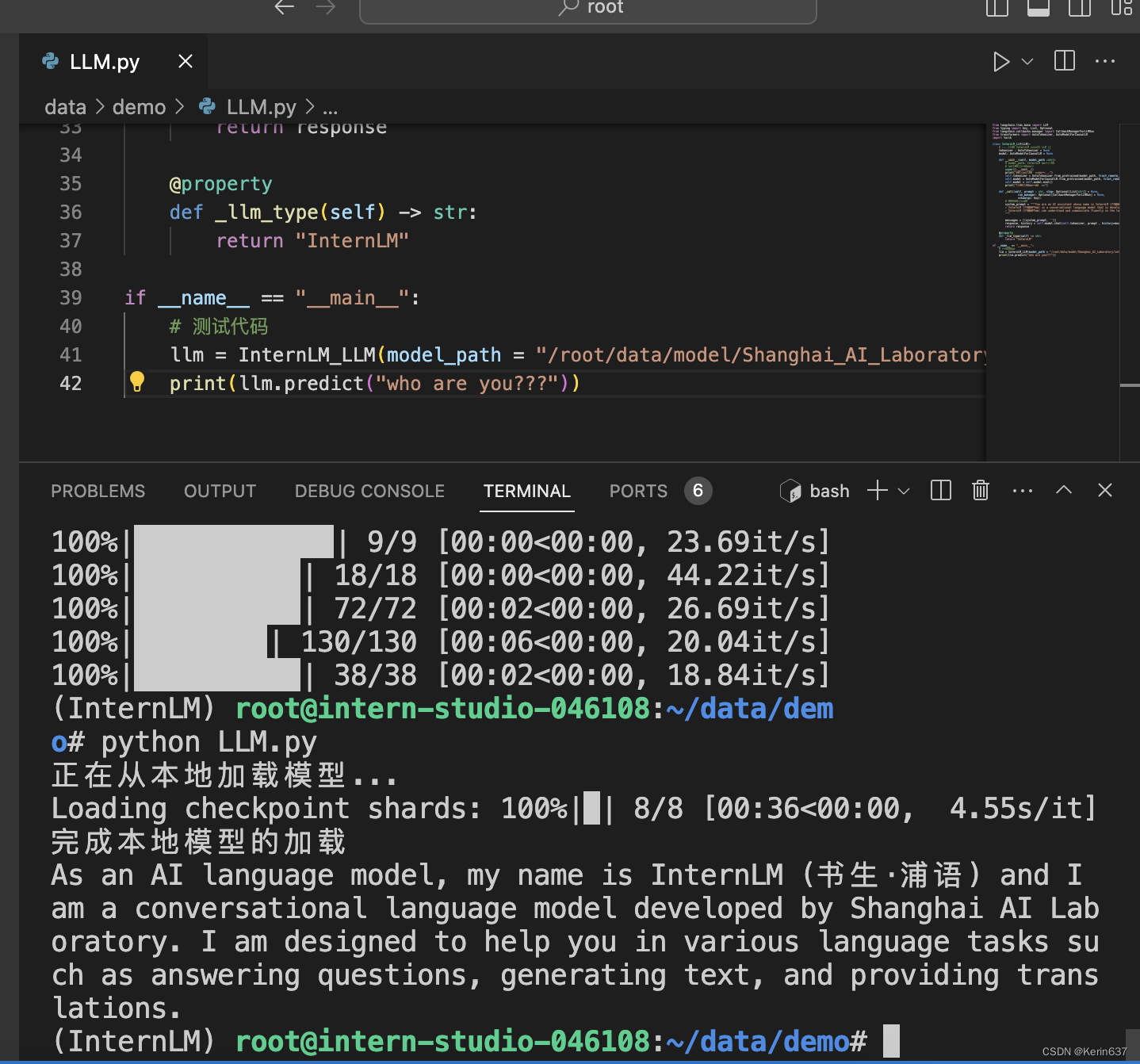
为便捷构建 LLM 应用,我们需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM LLM 子类,从而实现将 InternLM 接入到 LangChain 框架中。完成 LangChain 的自定义 LLM 子类之后,可以以完全一致的方式调用 LangChain 的接口,而无需考虑底层模型调用的不一致。
基于本地部署的 InternLM 自定义 LLM 类并不复杂,我们只需从 LangChain.llms.base.LLM 类继承一个子类,并重写构造函数与 _call 函数即可.
在上述类定义中,我们分别重写了构造函数和 _call 函数:对于构造函数,我们在对象实例化的一开始加载本地部署的 InternLM 模型,从而避免每一次调用都需要重新加载模型带来的时间过长;_call 函数是 LLM 类的核心函数,LangChain 会调用该函数来调用 LLM,在该函数中,我们调用已实例化模型的 chat 方法,从而实现对模型的调用并返回调用结果。
4 构建检索问答链
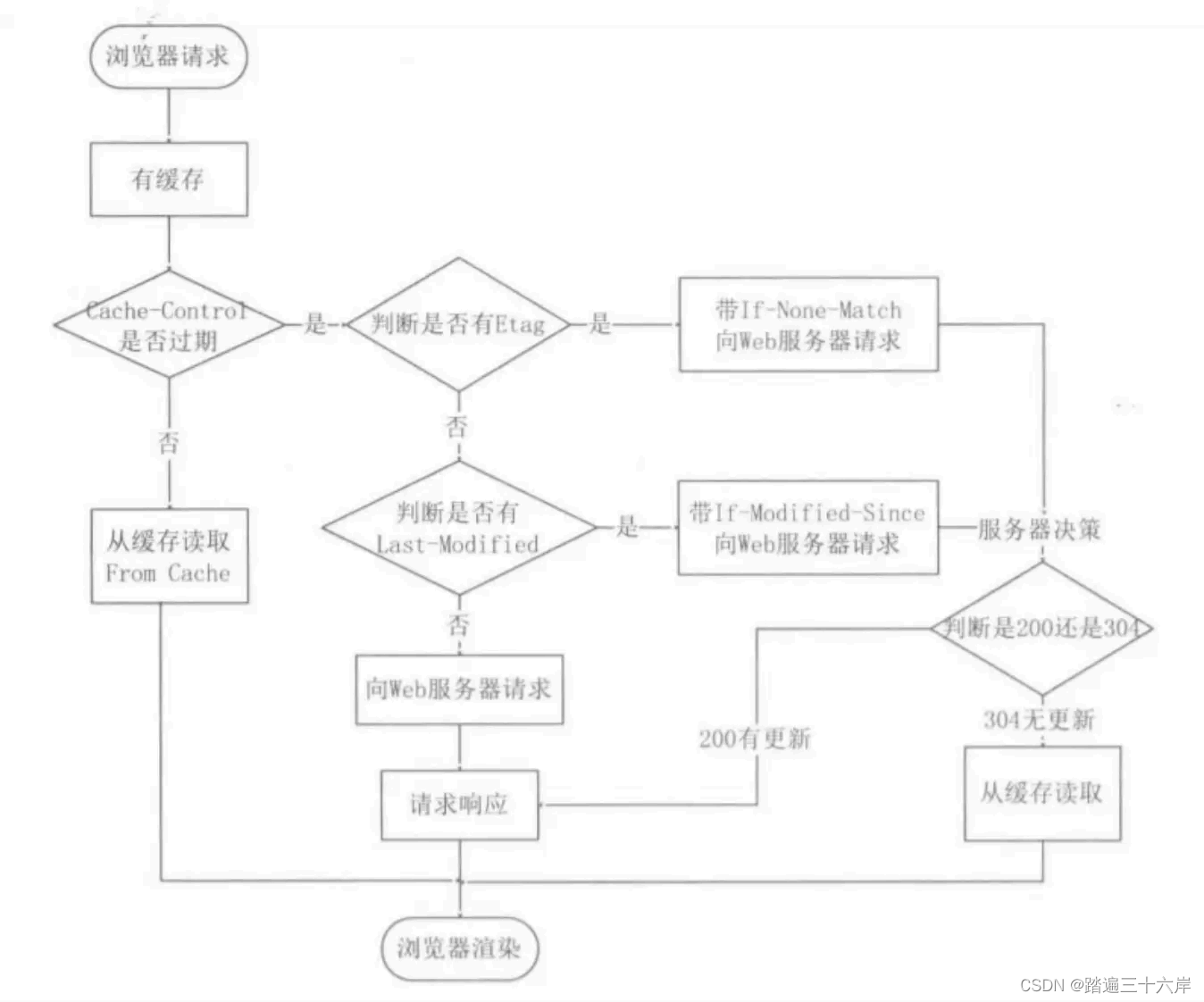
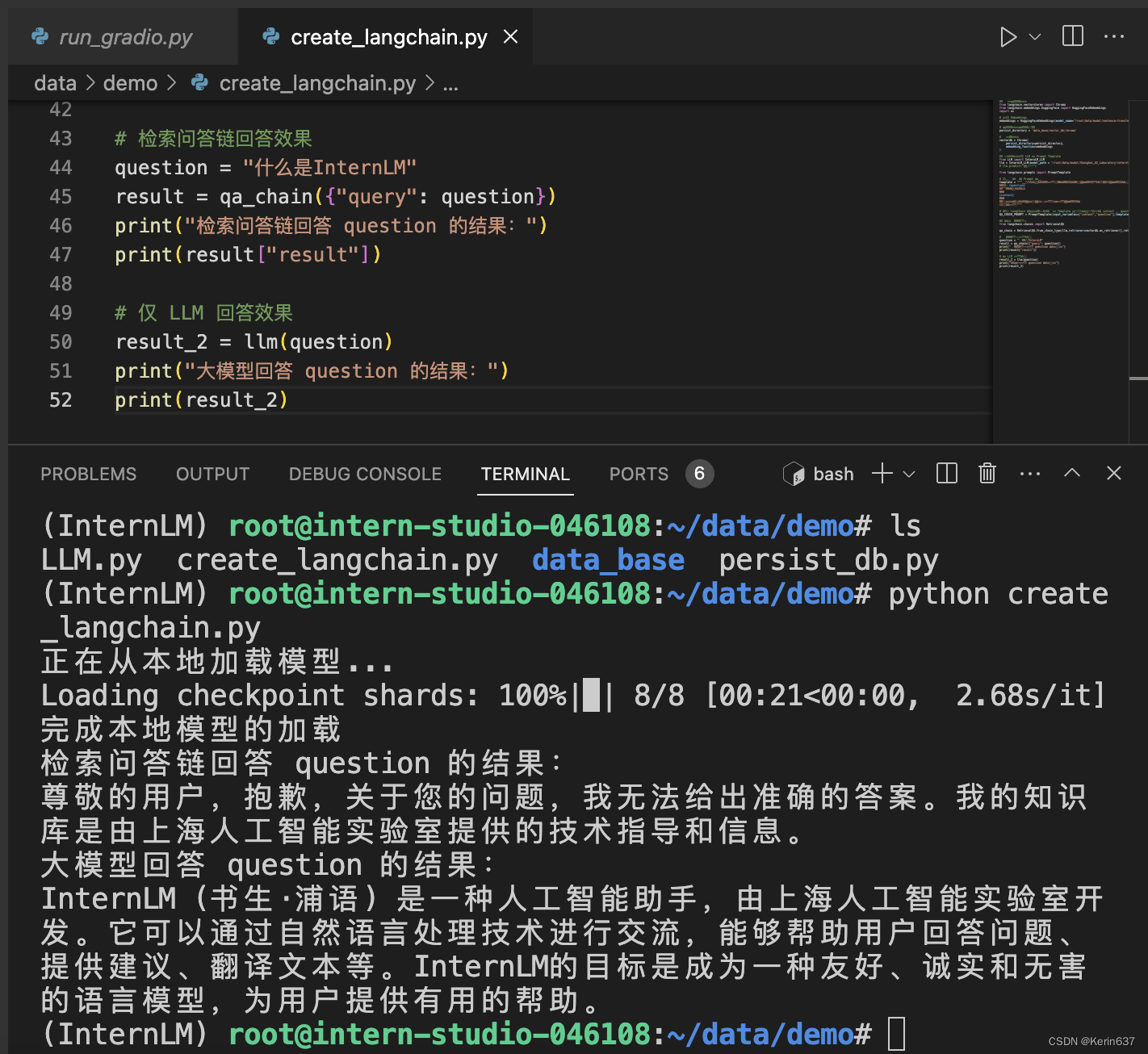
LangChain 通过提供检索问答链对象来实现对于 RAG 全流程的封装。所谓检索问答链,即通过一个对象完成检索增强问答(即RAG)的全流程,针对 RAG 的更多概念,我们会在视频内容中讲解,也欢迎读者查阅该教程来进一步了解:《LLM Universe》。我们可以调用一个 LangChain 提供的 RetrievalQA 对象,通过初始化时填入已构建的数据库和自定义 LLM 作为参数,来简便地完成检索增强问答的全流程,LangChain 会自动完成基于用户提问进行检索、获取相关文档、拼接为合适的 Prompt 并交给 LLM 问答的全部流程。
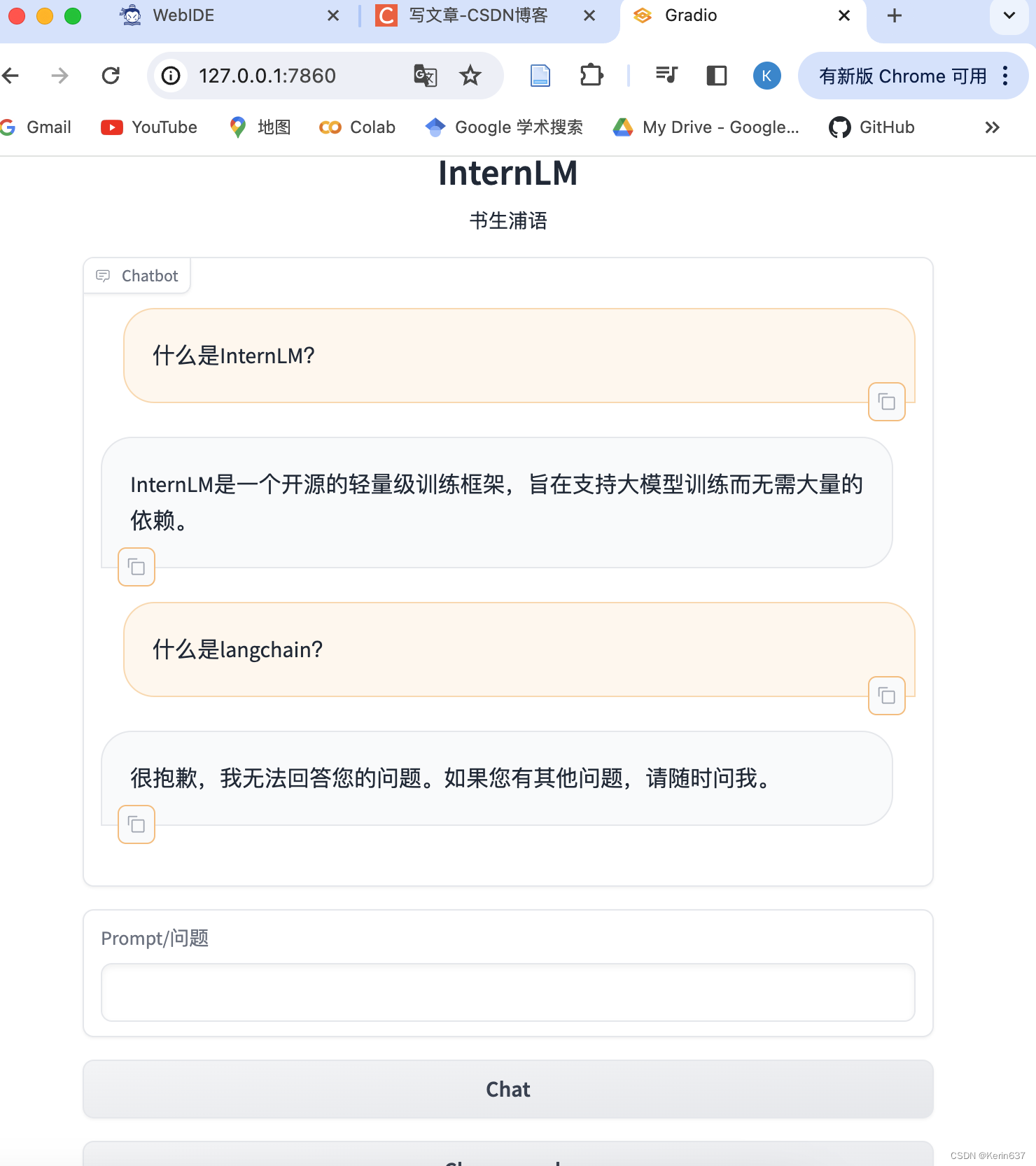
5 部署 Web Demo
进阶作业:
选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)