目录
一、逆向基础
1.1 语法基础
1.2 作用域
1.3 窗口对象属性
1.4 事件
二、浏览器控制台
2.1 Network
Network-Headers
Network-Header-General
Network-Header-Response Headers
Network-Header-Request Headers
2.2 Sources
2.3 Application
2.4 Console
三、加密参数的定位方法
3.1 巧用搜索
3.2 堆栈调试
3.3 控制台调试
3.4 监听XHR
3.5 事件监听
3.6 添加代码片
3.7 Hook
四、常见的压缩和混淆
4.1 JavaScript压缩
4.2 JavaScript混淆
4.3 javascript-obfuscator示例
4.3.1 代码压缩
4.3.2 变量名混淆
4.3.3 字符串混淆
4.3.4 代码自我保护
4.3.5 控制流平坦化
4.3.6 无用代码注入
4.3.7 对象键名替换
4.3.8 禁用控制台输出
4.3.9 调试保护
4.3.10 域名锁定
4.3.11特殊编码
五、常见的编码和加密
5.1 base64
5.2 MD5
5.3 SHA1
5.4 HMAC
5.5 DES
5.5 AES
5.6 RSA
一、逆向基础
1.1 语法基础
Js调试相对方便,通常只需要chrome或者一些抓包工具、扩展插件,就能顺利的完成逆向分析。但是Js的弱类型和语法多样,各种闭包,逗号表达式等语法让代码可读性变得不如其他语言顺畅。所以需要学习一下基础语法。
-
基本数据类型
| 字符串 | String |
|---|---|
| 数字 | Number |
| 布尔 | Boolean |
| 空值 | Null |
| 未定义 | Undefined |
| 独一无二的值 | Symbol |
-
引用数据类型
| 对象 | Object |
|---|---|
| 数组 | Array |
| 函数 | Function |
-
语句标识符
| 在条件为true时重复执行 | do……while |
|---|---|
| 在条件为true时执行 | while |
| 循环遍历 | for |
| 条件判断 | if……else |
| 根据情况执行代码块 | switch |
| 退出循环 | break |
| 异常捕获 | try……catch……finally |
| 抛出异常 | Throw |
| 声明固定值的变量 | const |
| 声明类 | class |
| 停止函数并返回 | return |
| 声明块作用域的变量 | let |
| 声明变量 | var |
| 断点调试 | debugger |
| 当前所属对象 | this |
-
算数运算符
| 加 | + |
|---|---|
| 减 | - |
| 乘 | * |
| 除 | / |
| 取余 | % |
| 累加 | ++ |
| 递减 | -- |
-
比较运算符
| 等于 | == |
|---|---|
| 相等值或者相等类型 | === |
| 不等于 | != |
| 不相等值或者不相等类型 | !== |
| 大于 | > |
| 小于 | < |
| 大于等于 | >= |
| 小于等于 | <= |
在JavaScript中将数字存储为64位浮点数,但所有按位运算都以32位二进制数执行。在执行位运算之前,JavaScript将数字转换位32位有符号整数。执行按位操作后,结果将转换回64位JavaScript数。
Javascript 函数
JavaScript 中的函数是头等公民,不仅可以像变量一样使用它,同时它还具有十分强大的抽象能力
定义函数的 2 种方式
在JavaScript 中,定义函数的方式如下:
function abs(x) {
if (x >= 0) {
return x;
} else {
return -x;
}
}上述 abs() 函数的定义如下:
-
function 指出这是一个函数定义;
-
abs 是函数的名称;
-
(x) 括号内列出函数的参数,多个参数以,分隔;
-
{……} 之间的代码是函数体,可以包含若干语句,甚至可以没有任何语句。
请注意,函数体内部的语句在执行时,一旦执行到 return 时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。
如果没有 return 语句,函数执行完毕后也会返回结果,只是结果为 undefined。
由于JavaScript的函数也是一个对象,上述定义的 abs()函数实际上是一个函数对象,而函数名 abs可以视为指向该函数的变量。
因此,第二种定义函数的方式如下:
var abs = function (x) {
if (x >= 0) {
return x;
} else {
return -x;
}
};在这种方式下,function(x){……} 是一个匿名函数,它没有函数名。但是,这个匿名函数赋值给了变量 abs,所以,通过变量 abs 就可以调用该函数。
注意:上述两种定义 完全等价 ,第二种方式按照完整语法需要在函数体末尾加一个 ;,表示赋值语句结束。( 加不加都一样,如果按照语法完整性要求,需要加上)
调用函数时,按顺序传入参数即可:
abs(10); // 返回10
abs(-9); // 返回9由于JavaScript 允许传入任意个参数而不影响调用,因此传入的参数比定义的参数多也没有问题,虽然函数内部并不需要这些参数:
abs(10, 'blablabla'); // 返回10
abs(-9, 'haha', 'hehe', null); // 返回9传入的参数比定义的少也没有问题:
abs(); // 返回NaN此时 abs(s) 函数的参数 x 将收到 undefined,计算结果为NaN。要避免收到undefined,可以对参数进行检查:
function abs(x) {
if (typeof x !== 'number') {
throw 'Not a number'; // 停止并抛出错误信息
}
if (x >= 0) {
return x;
} else {
return -x;
}
}1.2 作用域
Js中有一个被称为作用域的特性。作用域是在运行时代码中的某些特定部分中变量、函数和对象的可访问性。换句话说,作用域决定了代码区块中变量和其他资源的可见性。作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
Js的作用域分为三种:全局作用域、函数作用域、块级作用域。全局作用域可以让用户在任何位置进行调用,需要注意的是最外层函数和在最外层函数外面定义的变量拥有全局作用域,所有未定义直接赋值的变量会自动声明为拥有全局作用域,所有window对象的属性也拥有全局作用域。函数作用域也就是说只有在函数内部可以被访问,当然函数内部是可以访问全局作用域的。块级作用域则是在if和switch的条件语句或for和while的循环语句中,块级作用域可通过新增命令let和const声明,所声明的变量在指定的作用域外无法被访问。
1.3 窗口对象属性
我们总结了浏览器window的常见属性和方法。因为很多环境监测都是基于这些属性和方法的,在补环境前,需要了解window对象的常用属性和方法。
-
Window
-
Window对象表示浏览器当前打开的窗口。
-
| Document对象 | document |
|---|---|
| History对象 | history |
| Location对象 | location |
| Navigator对象 | navigator |
| Screen对象 | screen |
| 按照指定的像素值来滚动内容 | scrollBy() |
| 把内容滚动到指定的坐标 | scrollTo() |
| 定时器 | setInterval() |
| 延时器 | setTimeout() |
| 弹出警告框 | alert() |
| 弹出对话框 | prompt() |
| 打开新页面 | open() |
| 关闭页面 | close() |
-
Document
-
载入浏览器的HTML文档。
-
| <body>元素 | body |
|---|---|
| 当前cookie | cookie |
| 文档域名 | domain |
| 文档最后修改日期和时间 | lastModified |
| 访问来源 | referrer |
| 文档标题 | title |
| 当前URL | URL |
| 返回指定id的引用对象 | getElementById() |
| 返回指定名称的对象集合 | getElementByName() |
| 返回指定标签名的对象集合 | getElementByTagName() |
| 打开流接收输入输出 | open() |
| 向文档输入 | write() |
-
Navigator
-
Navigator对象包含的属性描述了当前使用的浏览器,可以使用这些属性进行平台专用的配置。
-
| 用户代理 | userAgent |
|---|---|
| 浏览器代码名 | AppCodeName |
| 浏览器名称 | AppName |
| 浏览器版本 | AppVersion |
| 浏览器语言 | browserLanguage |
| 指明是否启用cookie的布尔值 | cookieEnabled |
| 浏览器系统的cpu等级 | cpuClass |
| 是否处于脱机模式 | onLine |
| 浏览器的操作系统平台 | platform |
| 插件,所有嵌入式对象的引用 | plugins |
| 是否启用驱动 | webdriver |
| 引擎名 | product |
| 硬件支持并发数 | hardwareConcurrency |
| 网络信息 | connection |
| 是否启用java | javaEnabled() |
| 是否启用数据污点 | taintEnabled() |
-
Location
-
Location对象包含有关当前URL的信息
-
| URL锚 | hash |
|---|---|
| 当前主机名和端口号 | host |
| 当前主机名 | hostname |
| 当前URL | href |
| 当前URL的路径 | pathname |
| 当前URL的端口号 | port |
| 当前URL的协议 | protocol |
| 设置URL查询部分 | search |
| 加载新文件 | assign() |
| 重新加载文件 | reload() |
| 替换当前文档 | replace() |
-
Screen
-
每个window对象的screen属性都引用一个Screen对象。Screen对象中存放着有关显示浏览器屏幕的信息。
-
| 屏幕高度 | avaiHeight |
|---|---|
| 屏幕宽度 | availWidth |
| 调色版比特深度 | bufferDepth |
| 显示屏每英寸水平点数 | deviceXDPI |
| 显示屏每英寸垂直点数 | deviceYDPI |
| 是否启用字体平滑 | fontSmoothingEnabled |
| 显示屏高度 | height |
| 显示屏分辨率 | pixeIDepth |
| 屏幕刷新率 | updateInterval |
| 显示屏宽度 | width |
-
History
-
History对象包含用户在浏览器窗口中访问过的URL。
-
| 浏览器历史列表中的URL数量 | length |
|---|---|
| 加载前一个URL | back() |
| 加载下一个URL | forward() |
| 加载某个具体页面 | go() |
window中还有很多属性和方法,这里就不再过多的描述,大家可以自行查看。
1.4 事件
HTML 事件是发生在 HTML 元素上的事情。
当在 HTML 页面中使用 JavaScript 时, JavaScript 可以触发这些事件。
HTML 事件可以是浏览器行为,也可以是用户行为。
以下是 HTML 事件的实例:
-
HTML 页面完成加载
-
HTML input 字段改变时
-
HTML 按钮被点击
通常,当事件发生时,你可以做些事情。
在事件触发时 JavaScript 可以执行一些代码。
HTML 元素中可以添加事件属性,使用 JavaScript 代码来添加 HTML 元素。
事件可以用于处理表单验证,用户输入,用户行为及浏览器动作:
-
页面加载时触发事件
-
页面关闭时触发事件
-
用户点击按钮执行动作
-
验证用户输入内容的合法性
-
等等 ...
可以使用多种方法来执行 JavaScript 事件代码:
-
HTML 事件属性可以直接执行 JavaScript 代码
-
HTML 事件属性可以调用 JavaScript 函数
-
你可以为 HTML 元素指定自己的事件处理程序
-
你可以阻止事件的发生。
-
等等 ..
HTML事件
| 事件 | 描述 |
|---|---|
| onclick | 当用户单击HTML元素时触发 |
| ondblclick | 当用户双击对象时触发 |
| onmove | 当对象移动时触发 |
| onmoveend | 当对象停止移动时触发 |
| onmovestart | 当对象开始移动时触发 |
| onkeydown | 当用户按下键盘按键时触发 |
| onkeyup | 当用户释放键盘按键时触发 |
| onload | 当某个页面或图像被完成加载 |
| onselect | 当文本被选定 |
| onblur | 当元素失去焦点 |
| onchange | 当HTML元素改变时触发 |
| onfocusin | 当元素将要被设置为焦点之前触发 |
| onhelp | 当用户在按F1键时触发 |
| onkeypress | 当用户按下字面键时触发 |
| onmousedown | 当用户用任何鼠标按钮单击对象时触发 |
| onmousemove | 当用户将鼠标划过对象时触发 |
| onmouseover | 当用户从一个HTML元素上移动鼠标时触发 |
| onmouseout | 当用户从一个HTML元素上移开鼠标时触发 |
| onmouseup | 当用户在对象之上释放鼠标按钮时触发 |
| onmousewheel | 当鼠标滚轮按钮旋转时触发 |
| onstop | 当用户单击停止按钮或者离开页面时触发 |
| onactivate | 当对象设置为活动元素时触发 |
| onreadystatechange | 当在对象上发生对象属性更改时触发 |
| ondragend | 当用户拖拽操作结束后释放鼠标时触发 |
接下来说一下HTMl中绑定事件的几种方法,分别是行内绑定、动态绑定、事件监听、bind和on绑定。
-
行内绑定是指把触发事件直接写到元素的标签中
<li>
<div onclick="xxx()">点击</div>
</li>-
动态绑定是指先获取到dom元素,然后在元素上绑定事件
<script>
var xx = document.getElementById("lx");
xx.onclick = function(){}
</script>-
事件监听主要通过addEventListener()方法来实现
<script>
var xx = document.getElementById("lx");
xx.addEventListener("click", function(){})
</script>-
bind()和on()绑定都是属于JQuery的事件绑定方法,bind()的事件函数只能针对已经存在的元素进行事件的设置
$("button").bind("click",function(){
$("p").slideToggle();
});-
on()支持对将要添加的新元素设置事件
$(document).ready(function(){
$("p").on("click", function(){});
});还有live()和delegate()等事件绑定方法,目前并不常用。
二、浏览器控制台
首先介绍一下浏览器控制台的使用,以开发者使用最多的chrome为例。Windows操作系统下的F12键可以打开控制台,mac操作系统下用Fn+F12键打开。我们选择平时使用较多的模块进行介绍
2.1 Network
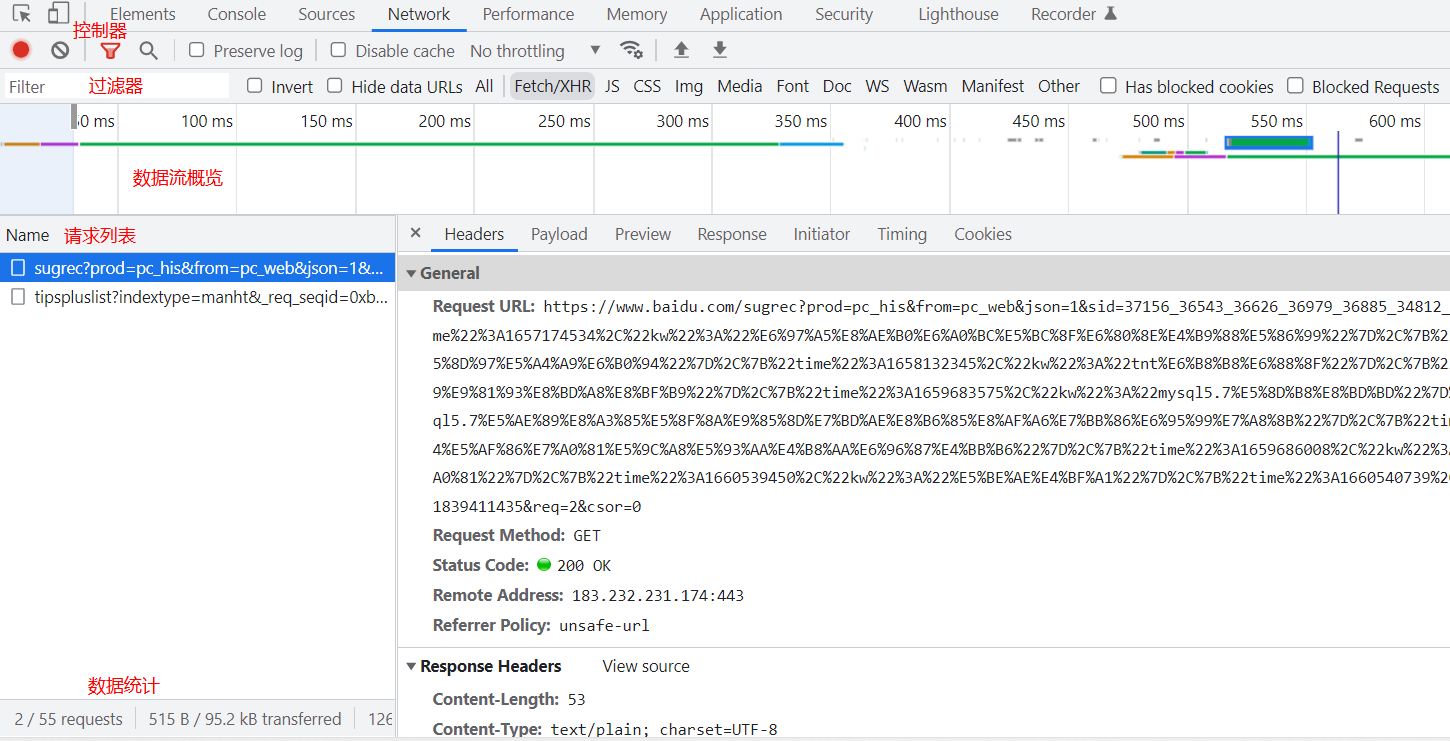
Network是Js调试的重点,面板上由控制器、过滤器、数据流概览、请求列表、数据统计这五部分组成。
-
控制器:Presserve Log是保留请求日志的作用,在跳转页面的时候勾选上可以看到跳转前的请求。Disable cache是禁止缓存的作用,Offline是离线模拟。
-
过滤器:根据规则过滤器请求列表的内容,可以选择XHR,JS,CSS,WS等。
-
数据流概览:显示HTTP请求、响应的时间轴。
-
请求列表:默认是按时间排序,可以看到浏览器所有的请求,主要用于网络请求的查看和分析,可以查看请求头、响应状态和内容、Form表单等。
-
数据统计:请求总数、总数据量、总花费时间等。
浏览器控制台Network下各项属性的含义
作用:
-
可以查看调取接口是否正确,后台返回的数据;
-
查看请求状态、请求类型、请求地址
Network-Headers
首先打开控制台,找到Network. 刷新页面可以看到Name
Name对应的是资源的名称及路径, Status Code 是请求服务器返回的状态码,一般情况下当状态码为200时,则表示接口匹配成功。点击任一文件名,右侧会出现Header选项。
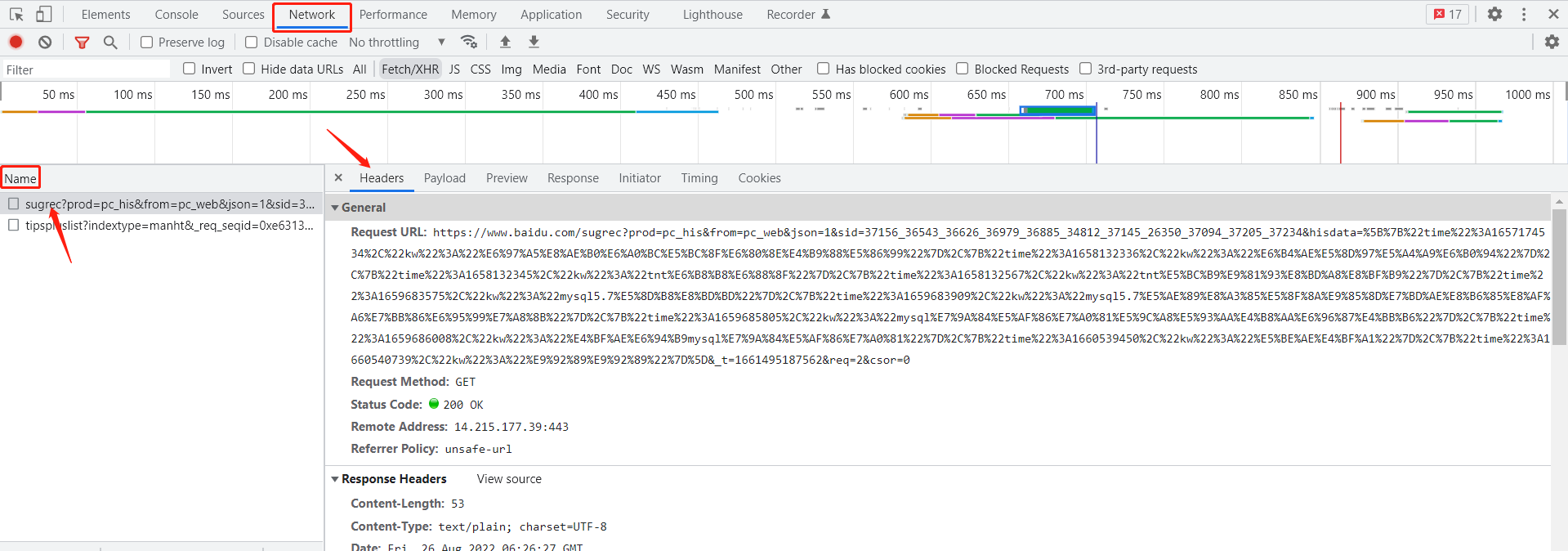
Network-Header-General
-
Request URL: 资源请求的url
-
Request Method: 请求方法(HTTP方法)
-
Status Code: 状态码
-
200(状态码) OK
-
301 - 资源(网页等)被永久转移到其它URL
-
404 - 请求的资源(网页等)不存在
-
500 - 内部服务器错误(后台问题)
-
-
Remote Address: 远程地址;
-
Referrer Policy: 控制请求头中 refrrer 的内容 包含值的情况:
-
"", 空串默认按照浏览器的机制设置referrer的内容,默认情况下是和no-referrer-when-downgrade设置得一样
-
"no-referrer", 不显示 referrer的任何信息在请求头中
-
"no-referrer-when-downgrade", 默认值。当从https网站跳转到http网站或者请求其资源时(安全降级HTTPS→HTTP),不显示 referrer的信息,其他情况(安全同级HTTPS→HTTPS,或者HTTP→HTTP)则在 referrer中显示完整的源网站的URL信息
-
"same-origin", 表示浏览器只会显示 referrer信息给同源网站,并且是完整的URL信息。所谓同源网站,是协议、域名、端口都相同的网站
-
"origin", 表示浏览器在 referrer字段中只显示源网站的源地址(即协议、域名、端口),而不包括完整的路径
-
"strict-origin", 该策略更为安全些,和 origin策略相似,只是不允许 referrer信息显示在从https网站到http网站的请求中(安全降级)
-
"origin-when-cross-origin", 当发请求给同源网站时,浏览器会在 referrer中显示完整的URL信息,发个非同源网站时,则只显示源地址(协议、域名、端口)
-
"strict-origin-when-cross-origin", 和 origin-when-cross-origin相似,只是不允许 referrer信息显示在从https网站到http网站的请求中(安全降级)
-
"unsafe-url" 浏览器总是会将完整的URL信息显示在 referrer字段中,无论请求发给任何网站
-
补充: 什么是referrer?
-
当一个用户点击页面中的一个链接,然后跳转到目标页面时,本变页面会收到一个信息,即用户是从哪个源链接跳转过来的。
-
也就是说当你发起一个HTTP请求,请求头中的 referrer 字段就说明了你是从哪个页面发起该请求的;
-
-
Network-Header-Response Headers
-
Access-Control-Allow-Origin: 请求头中允许设置的请求方法
-
Connection: 连接方式
-
content-length: 响应数据的数据长度,单位是byte
-
content-type: 客户端发送的类型及采用的编码方式
-
Date: 客户端请求服务端的时间
-
Vary: 用来指示缓存代理(例如squid)根据什么条件去缓存一个请求
-
Last-Modified: 服务端对该资源最后修改的时间
-
Server: 服务端的web服务端名
-
Content-Encoding: gzip 压缩编码类型
-
Transfer-Encoding:chunked: 分块传递数据到客户端
Network-Header-Request Headers
-
Accept: 客户端能接收的资源类型
-
Accept-Encoding: 客户端能接收的压缩数据的类型
-
Accept-Language: 客户端接收的语言类型
-
Cache-Control: no-cache 服务端禁止客户端缓存页面数据
-
Connection: keep-alive 维护客户端和服务端的连接关系
-
Cookie:客户端暂存服务端的信息
-
Host: 连接的目标主机和端口号
-
Pragma: no-cache 服务端禁止客户端缓存页面数据
-
Referer: 来于哪里(即从哪个页面跳转过来的)
-
User-Agent: 客户端版本号的名字
2.2 Sources
Sources按列分为三列,从左至右分别是文件列表区、当前文件区、断点调试区。
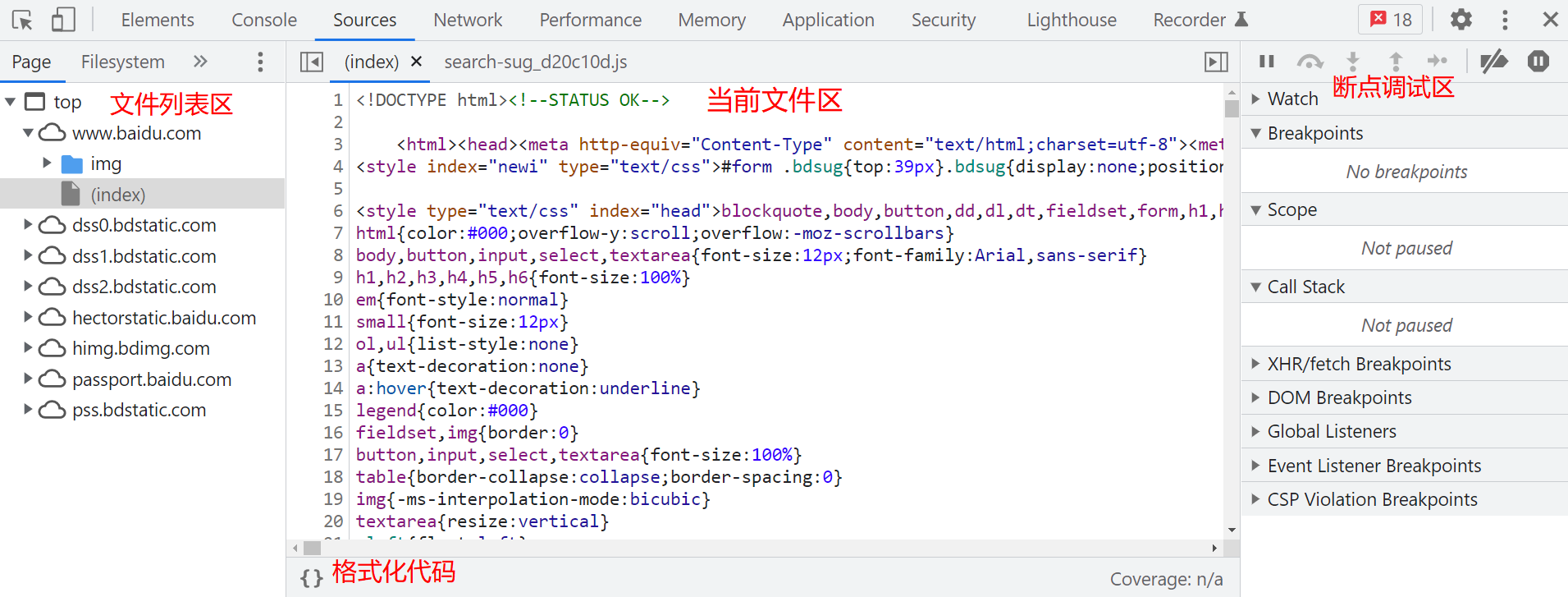
文件列表区中有Page、Snippets、FileSytem等。Page可以看到当前所在的文件位置,在Snippets中单击New Snippets可以添加自定义的Js代码,FileSytem可以把本地的文件系统导入到chrome中。
当前文件区是需要重点操作的区域,单击下方的{}来格式化代码,就能看到美观的Js代码,然后可以根据指定行数进行断点调试。
断点调试区也非常重要,每个操作点都需要了解是什么作用。最上方的功能区分别是暂停、跳过、进入、跳出、步骤进入、禁用断点、异常断点。
Watch:变量监听,对加入监听列表的变量进行监听。
Call Stack:断点的调用堆栈列表,完整地显示了导致代码被暂停的执行路径。
Scope:当前断点所在函数执行的作用域内容。
Breakpoints:断点列表,将每个断点所在文件/行数/改成简略内容进行展示。
DOM Breakpoints:DOM断点列表。
XHR/fetch Breakpoints:对达到满足过滤条件的请求进行断点拦截。
Event Listener Breakpoints:打开可监听的事件监听列表,可以在监听事件并且触发该事件时进入断点,调试器会停留在触发事件代码行。
2.3 Application
Application是应用管理部分,主要记录网站加载的所有资源信息。包括存储数据(Local Storage、Session Storage、InDexedDB、Web SQL、Cookies)、缓存数据、字体、图片、脚本、样式表等。Local Storage(本地存储)和 Session Storage中可以查看和管理其存储的键值对。这里使用最多的是对Cookies的管理了,有时候调试需要清除Cookies,可以在Application的Cookies位置单击鼠标右键,选择Clear进行清除,或者根据Cookies中指定的Name和Value来进行清除,便于进一步调试。
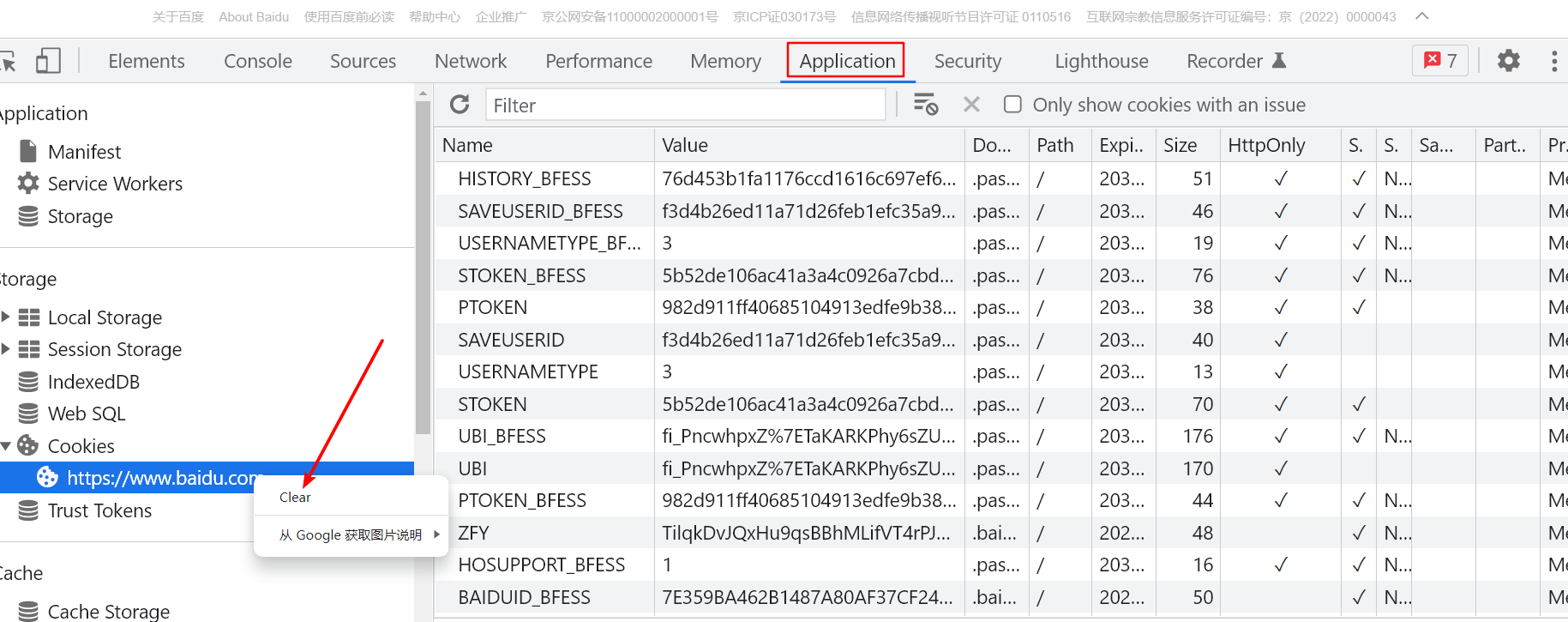
注意:我们辨别Cookie来源时,可以看httpOnly这一栏,有√的是来自于服务端,没有√的则是本地生成的。
2.4 Console
谷歌控制台中的Console区域用于审查DOM元素、调试JavaScript代码、查看HTML解析,一般是通过Console.log()来输出调试信息。在Console中也可以输出window、document、location等关键字查看浏览器环境,如果对某函数使用了断点,也可以在Console中调用该函数。
如果你平时只是用console.log()来输出一些变量的值,那你肯定还没有用过console的强大的功能。下面带你用console玩玩花式调试。
来看下主要的调试函数及用法:
console.log(), console.error(), console.warn(), console.info()
最基本也是最常用的用法了,分别表示输出普通信息、错误信息、警示信息和提示性信息,且error和warn方法有特定的图标和颜色标识。
-
console.assert(expression, message)
-
参数:
-
expression: 条件语句,语句会被解析成 Boolean,且为 false 的时候会触发message语句输出
-
message: 输出语句,可以是任意类型
-
该函数会在 expression 为 false 的时候,在控制台输出一段语句,输出的内容就是传入的第二个参数 message 的内容。当我们在只需要在特定的情况下才输出语句的时候,可以使用 console.assert
-
function greaterThan(a,b) { console.assert(a > b, {"message":"a is not greater than b","a":a,"b":b}); } greaterThan(5,6);
-
-
console.count(label)
-
参数:
-
label: 计算数量的标识符
-
该函数用于计算并输出特定标识符为参数的console.count函数被调用的次数。下面的例子更能直观的了解:
-
function login(name) { console.count(name + ' logged in'); }
-
-
console.dir(object)
-
参数:
-
object:被输出扎实的对象
-
该函数用于打印出对象的详细的属性、函数及表达式等信息。如果该对象已经被记录为一个HTML元素,则该HTML元素的DOM表达式的属性会被像下面这样打印出来:
-
console.dir(document.body);
-
-
console.dirxml(object)
-
该函数将打印输出XML元素及其子孙后代元素,且对HTML和XML元素调用 console.dirxml() 和 调用 console.log() 是等价的
-
-
console.group([label]), console.groupEnd([label])
-
参数:
-
label: group分组的标识符
-
在控制台创建一个新的分组,随后输出到控制台上的内容都会自动添加一个缩进,表示该内容属于当前分组,知道调用 console.groupEnd() 之后,当前分组结束。
-
举个例子:
-
console.log("This is the outer level"); console.group(); console.log("Level 2"); console.group(); console.log("Level 3"); console.warn("More of level 3"); console.groupEnd(); console.log("Back to level 2"); console.groupEnd(); console.log("Back to the outer level");
-
-
console.groupCollapsed(label)
-
该函数同console.group(),唯一的区别是该函数的输出默认不展开分组,而console.group()是默认展开分组。
-
-
console.time([label]), console.timeEnd([label])
-
label: 用于标记计时器的名称,不填的话,默认为 default
-
console.time() 会开始一个计时器,并当执行到 console.timeEnd() 函数时(需要两个函数的lable参数相同),结束计时器,并将计时器的总时间输出到控制台上。
-
再举几个例子:
-
console.time(); var arr = new Array(10000); for (var i = 0; i < arr.length; i++) { arr[i] = new Object(); } console.timeEnd(); // default: 3.696044921875ms -
对 console.time(label) 设置一个自定义的 label 字段,并使用console.timeEnd(label) 设置相同的 label 字段来结束计时器。
-
console.time('total'); var arr = new Array(10000); for (var i = 0; i < arr.length; i++) { arr[i] = new Object(); } console.timeEnd('total'); // total: 3.696044921875ms -
设置多个 label 属性,开启多个计时器同步计时。
-
console.time('total'); console.time('init arr'); var arr = new Array(10000); console.timeEnd('init arr'); for (var i = 0; i < arr.length; i++) { arr[i] = new Object(); } console.timeEnd('total'); // init arr: 0.0546875ms // total: 2.5419921875ms
-
-
console.trace(object)
-
该函数将在控制台打印出从 console.trace() 被调用的位置开始的堆栈信息。
-
三、加密参数的定位方法
想要找到Js加密参数的生成过程,就必须要找到参数的位置,然后通过debug来进行观察调试。我们总结了目前通用的调试方式。每种方法都有其独特的运用之道,大家只有灵活运用这些参数定位方法,才能更好地提高逆向效率。
3.1 巧用搜索
搜索操作比较简单,打开控制台,通过快捷键Ctrl + F打开搜索框。在Network中的不同位置使用Ctrl + F会打开不同的搜索区域,有全局搜索、页面搜索。
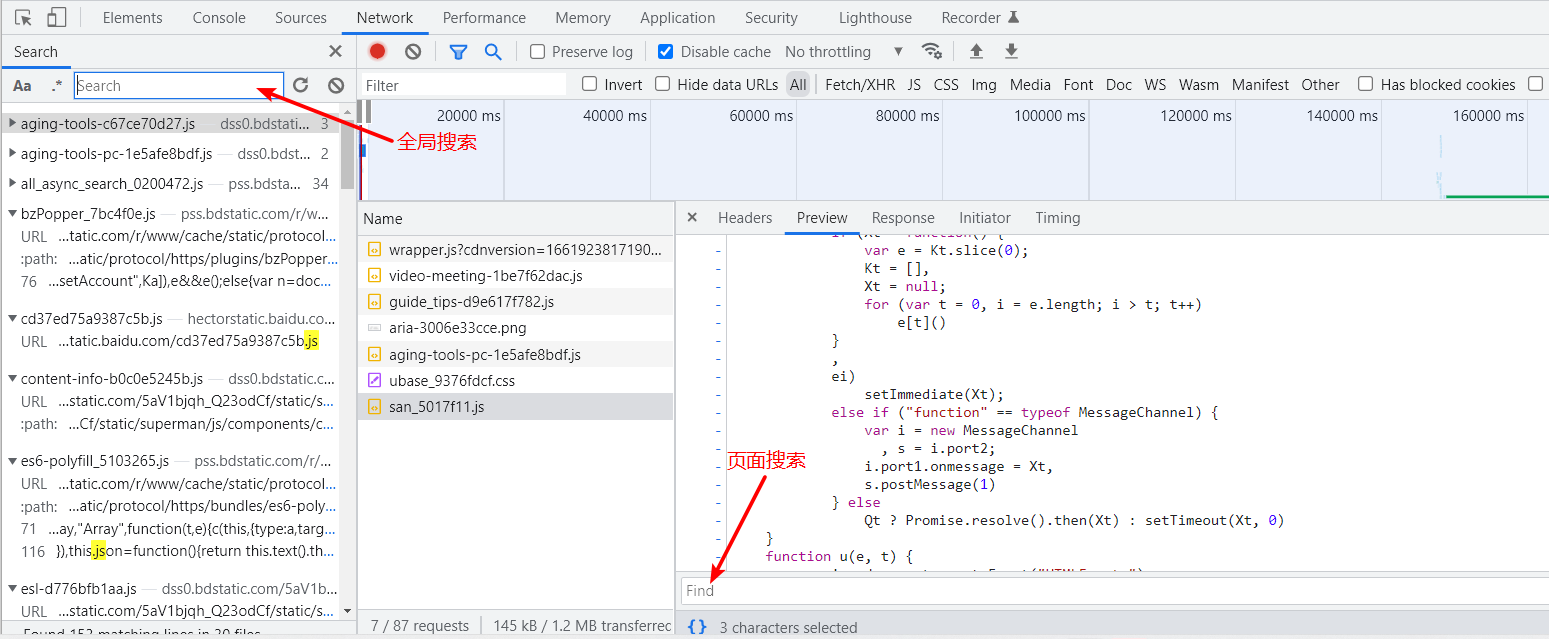
另外关于搜索也有一定的技巧,如果加密参数的关键词是signature,可以直接全局搜索signature,搜索不到可以尝试搜索sign或者搜索接口名。如果还没有找到位置,则可以使用下面几种方法。
3.2 堆栈调试
控制台的 Initiator 堆栈调试是我们比较喜欢的调试方式之一,不过新版本的谷歌浏览器才有,如果没有 Initiator 需要更新Chrome版本。Initiator主要是为了监听请求是怎样发起的,通过它可以快速定位到调用栈中。
具体使用方法是先确定请求的接口,然后进入Initiator,单击第一个Request call stack参数,进入Js文件后,在跳转行上打上断点,然后刷新页面等待调试。
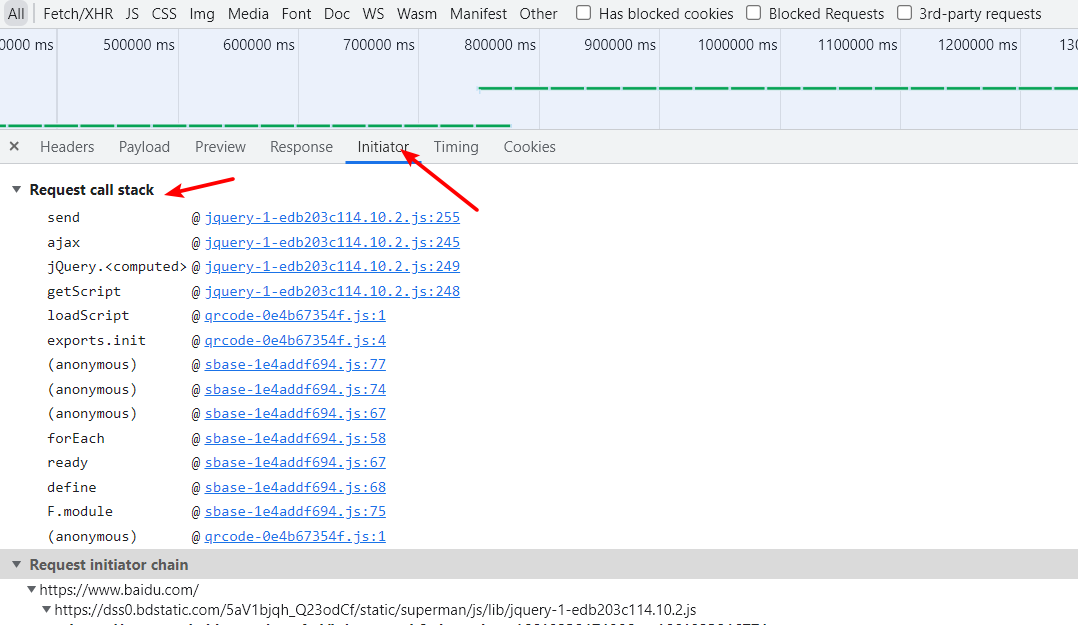
3.3 控制台调试
控制台的Console中可以由console.log()方法来执行某些函数,该方法对于开发调试很有帮助,有时通过输出会比找起来更便捷。在断点到某一处时,可以通过console.log()输出此时的参数来查看状态和属性,console.log()方法在后面的参数还原中也很重要。
3.4 监听XHR
XHR是XMLHttpRequest的简称,通过监听XHR的断点,可以匹配URl中params参数的触发点和调用堆栈,另外post请求中From Data的参数也可以用XHR来拦截。
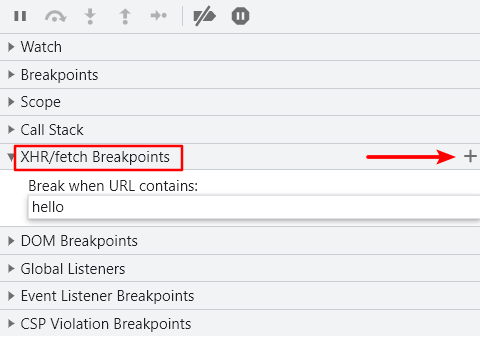
使用方法:打开控制台,单击Sources,右侧有一个XHR/fetch Breakpoints,单击+号即可添加监听事件。像一些URL中的_signature参数就很适合使用XHR断点。
3.5 事件监听
这里其实和监听XHR有些相似,为了方便记忆,我们将其单独放在一个小节中。
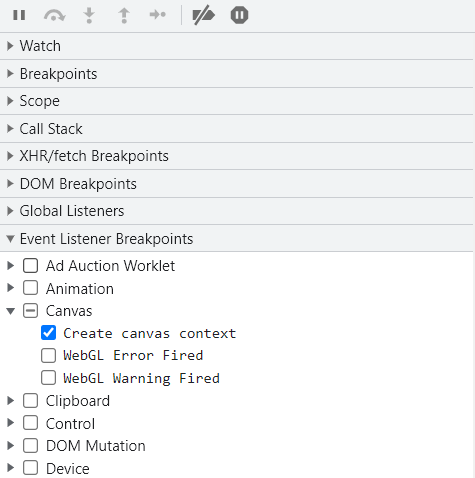
有的时候找不到参数位置,但是知道它的触发条件,此时可以使用事件监听器进行断点,在Sources中有
DOM Breakpoints、Global Listeners、Event Listener Breakpoints都可以进行DOM事件监听。
比如需要对Canvas进行断点,就在Event Listener Breakpoints中选择Canvas,勾选Create canvas context时就是对创建canvas时的事件进行了断点。
3.6 添加代码片
在控制台中添加代码片来完成Js代码注入,也是一种不错的方式。
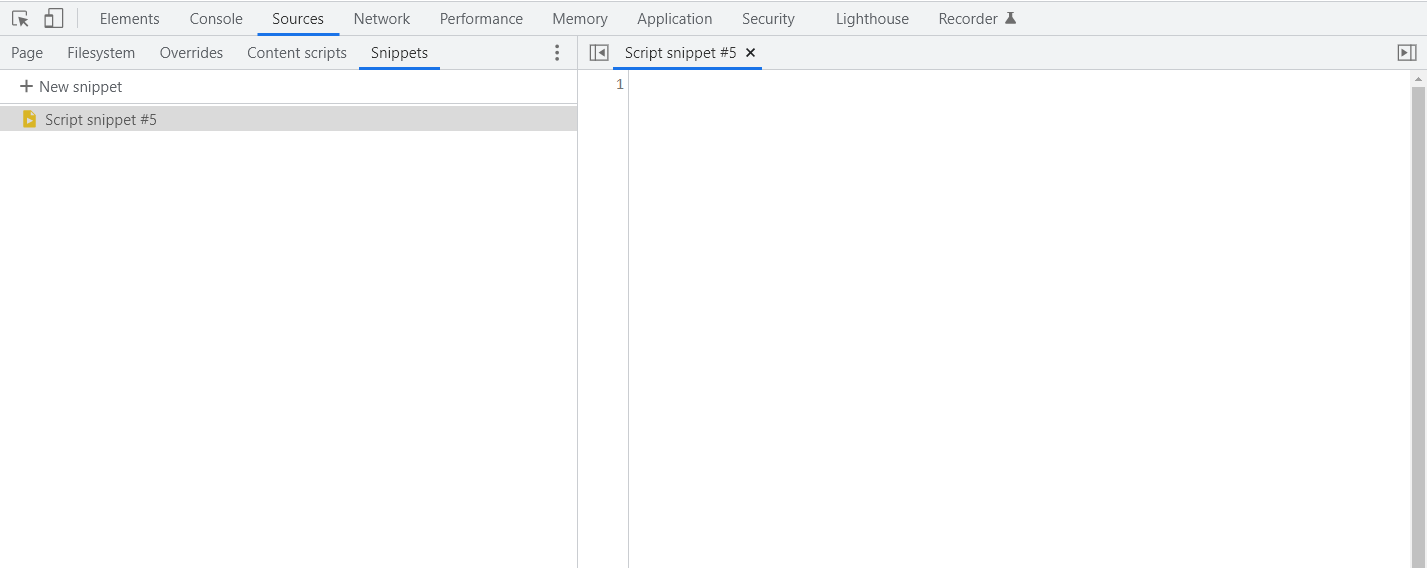
使用方法:打开控制台,单击Sources,然后单击左侧的snippets,新建一个Script Snippet,就可以在空白区域编辑Js代码了。
3.7 Hook
在Js中也需要用到Hook技术,例如当想分析某个cookie是如何生成时,如果想通过直接从代码里搜索该cookie的名称来找到生成逻辑,可能会需要审核非常多的代码。这个时候,如果能够用hook document.cookie的set方法,那么就可以通过打印当时的调用方法堆栈或者直接下断点来定位到该cookie的生成代码位置。
什么是hook?
在 JS 逆向中,我们通常把替换原函数的过程都称为 Hook。一般使用 Object.defineProperty() 来进行hook。
以下先用一段简单的代码理解Hook的过程:
function a() {
console.log("I'm a.");
}
a = function b() {
console.log("I'm b.");
};
a() // I'm b.直接覆盖原函数是以最简单的做法,以上代码将a函数进行了重写,再次调用a函数将会输出I'm b.
如果还想执行原来a函数的内容,可以使用中间变量进行存储:
function a() {
console.log("I'm a.");
}
var c = a;
a = function b() {
console.log("I'm b.");
};
a() // I'm b.
c() // I'm a.
此时,调用 a 函数会输出 I’m b.,调用 c 函数会输出 I’m a.
这种原函数直接覆盖的方法通常只用来进行临时调试,实用性不大,但是它能够帮助我们理解 Hook 的过程,在实际 JS 逆向过程中,我们会用到更加高级一点的方法,比如 Object.defineProperty()。
Object.defineProperty()
Object.defineProperty(obj, prop, descriptor)-
obj:需要定义属性的当前对象;
-
prop:当前需要定义的属性名;
-
descriptor:属性描述符,可以取以下值;
属性描述符的取值通常为以下:
| 属性名 | 默认值 | 含义 |
|---|---|---|
| get | undefined | 存取描述符,目标属性获取值的方法 |
| set | undefined | 存取描述符,目标属性设置值的方法 |
| value | undefined | 数据描述符,设置属性的值 |
| writable | false | 数据描述符,目标属性的值是否可以被重写 |
| enumerable | false | 目标属性是否可以被枚举 |
| configurable | false | 目标属性是否可以被删除或是否可以再次修改特性 |
通常情况下,对象的定义与赋值是这样的:
var people = {}
people.name = "Bob"
people["age"] = "18"
console.log(people)
// { name: 'Bob', age: '18' }使用 defineProperty() 方法:
var people = {}
Object.defineProperty(people, 'name', {
value: 'Bob',
writable: true // 是否可以被重写
})
console.log(people.name) // 'Bob'
people.name = "Tom"
console.log(people.name) // 'Tom'
我们一般hook使用的是get和set方法:
var people = {
name: 'Bob',
};
var count = 18;
// 定义一个 age 获取值时返回定义好的变量 count
Object.defineProperty(people, 'age', {
get: function () {
console.log('获取值!');
return count;
},
set: function (val) {
console.log('设置值!');
count = val + 1;
},
});
console.log(people.age);
people.age = 20;
console.log(people.age);输出:
获取值!
18
设置值!
获取值!
21通过这样的方法,我们就可以在设置某个值的时候,添加一些代码,比如 debugger;
让其断下,然后利用调用栈进行调试,找到参数加密、或者参数生成的地方,需要注意的是,网站加载时首先要运行我们的Hook代码,再运行网站自己的代码,才能够成功断下,这个过程我们可以称之为Hook代码的注入。
TamperMonkey 注入
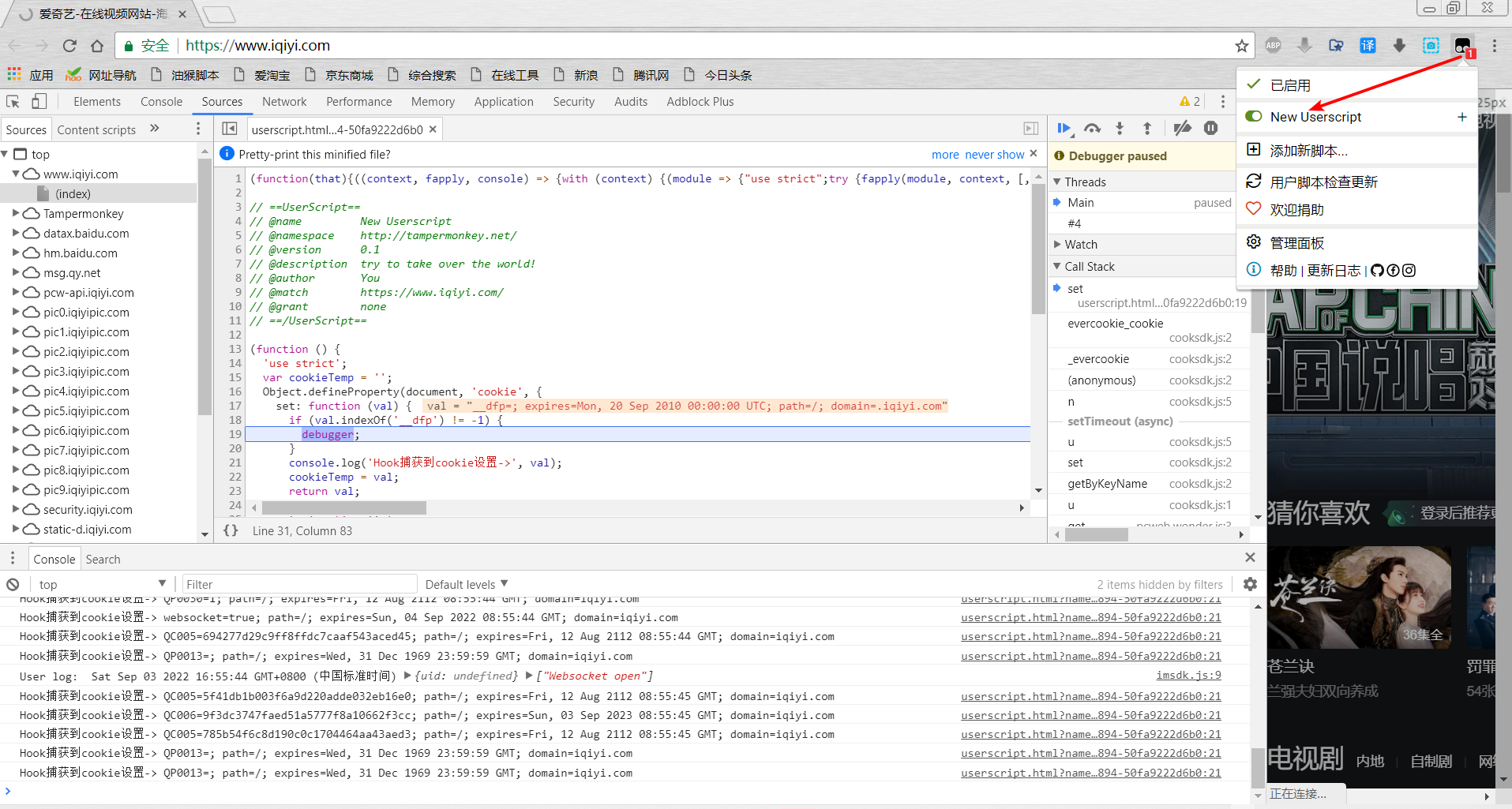
TamperMonkey 俗称油猴插件,是一款免费的浏览器扩展和最为流行的用户脚本管理器,支持很多主流的浏览器, 包括 Chrome、Microsoft Edge、Safari、Opera、Firefox、UC 浏览器、360 浏览器、QQ 浏览器等等,基本上实现了脚本的一次编写,所有平台都能运行,可以说是基于浏览器的应用算是真正的跨平台了。用户可以在 GreasyFork、OpenUserJS 等平台直接获取别人发布的脚本,功能众多且强大,比如视频解析、去广告等。
来到某奇艺首页,可以看到cookie里面有个__dfp值:
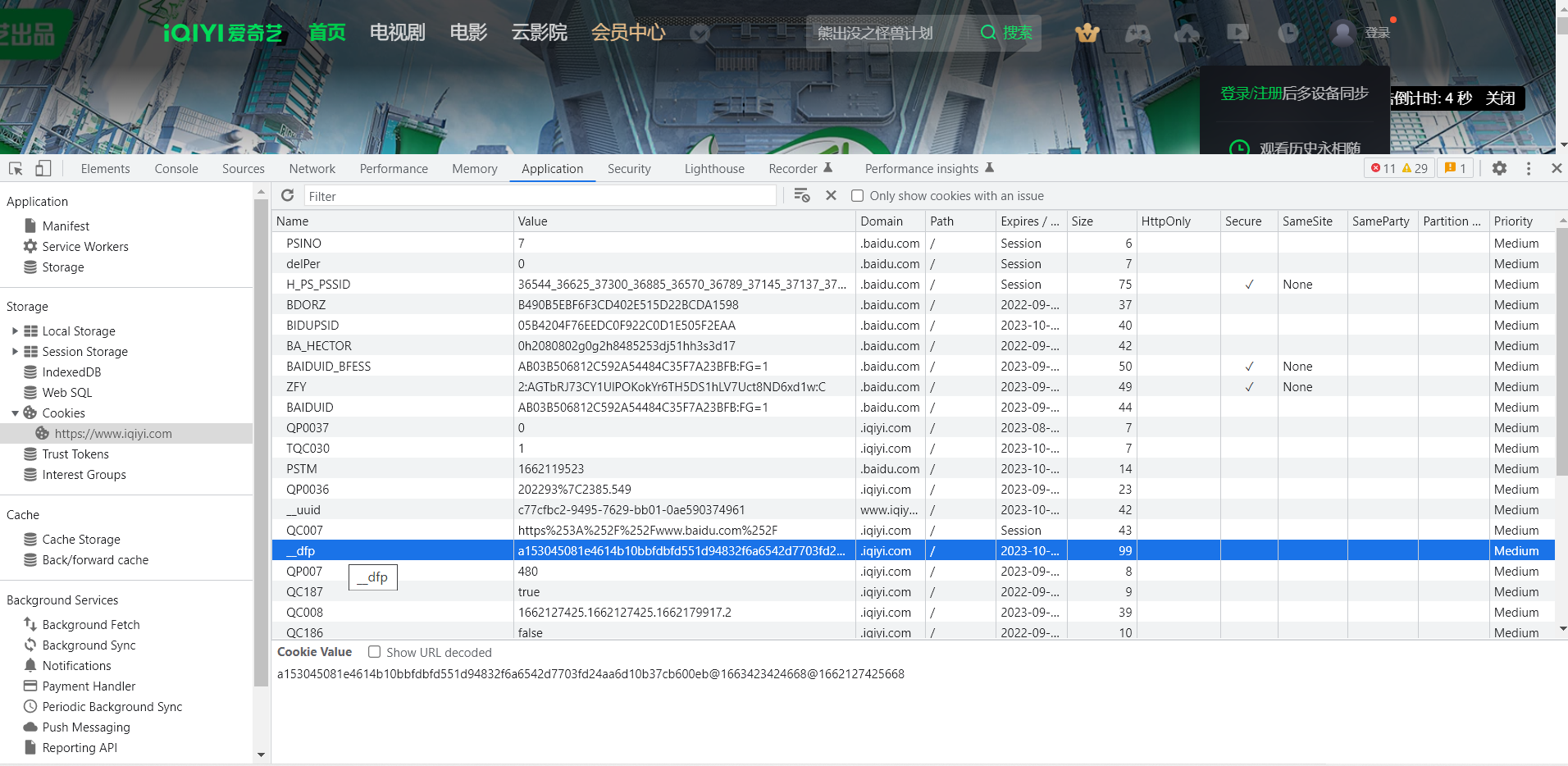
我们想通过Hook的方式,让在生成__dfp的地方断下,就可以编写如下函数:
我们以某奇艺的 cookie 为例来演示如何编写 TamperMonkey 脚本,首先去应用商店安装 TamperMonkey,安装过程不再赘述,然后点击图标,添加新脚本,或者点击管理面板,再点击加号新建脚本,写入以下代码:
(function () {
'use strict';
var cookieTemp = '';
Object.defineProperty(document, 'cookie', {
set: function (val) {
if (val.indexOf('__dfp') != -1) {
debugger;
}
console.log('Hook捕获到cookie设置->', val);
cookieTemp = val;
return val;
},
get: function () {
return cookieTemp;
},
});
})();if (val.indexOf('__dfp') != -1) {debugger;} 的意思是检索 __dfp 在字符串中首次出现的位置,等于 -1 表示这个字符串值没有出现,反之则出现。如果出现了,那么就 debugger 断下,这里要注意的是不能写成 if (val == '__dfp') {debugger},因为 val 传过来的值类似于 __dfp=xxxxxxxxxx,这样写是无法断下的。
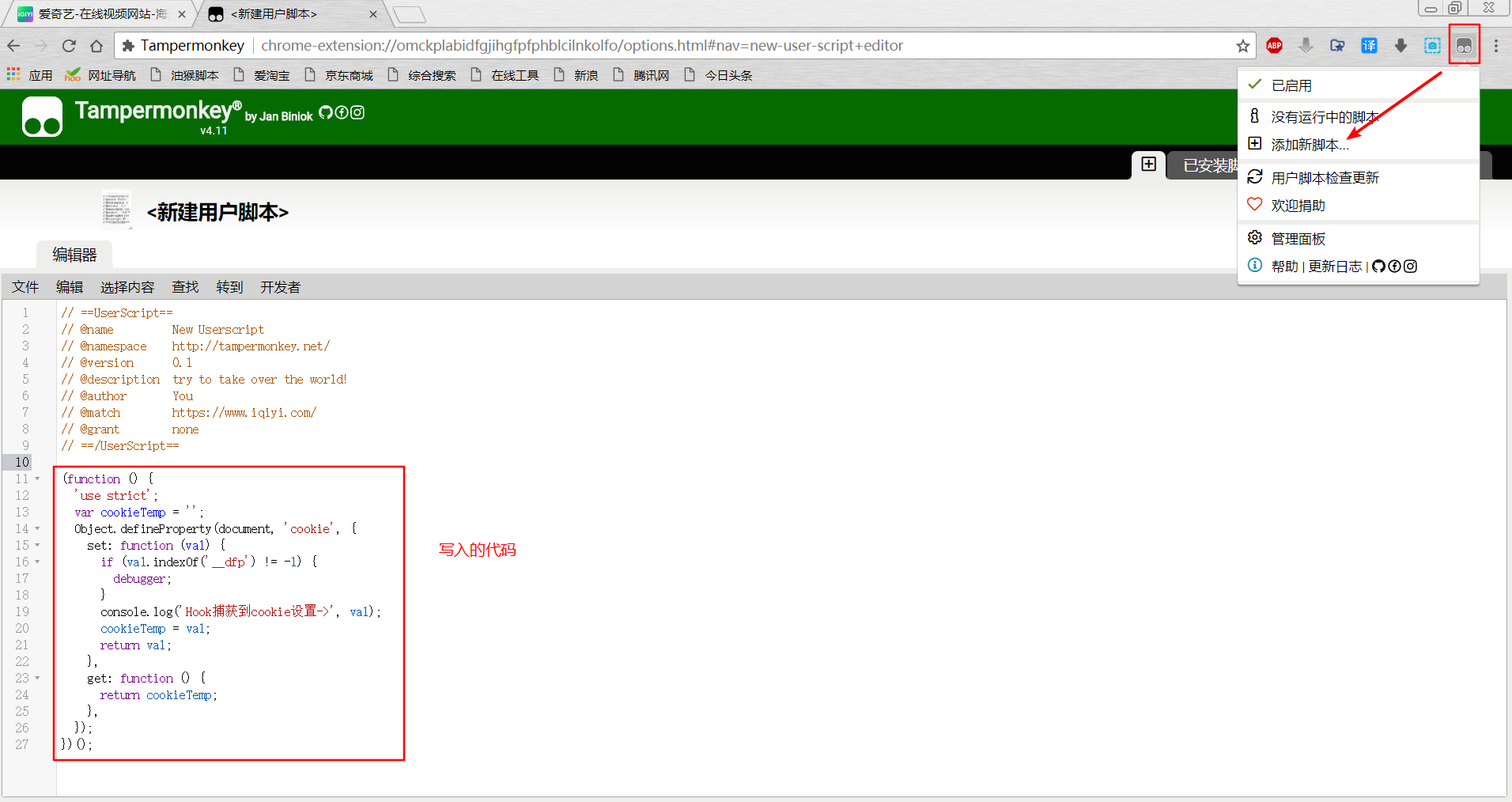
写入后进行保存
主体的JavaScript自执行函数和前面的都是一样的,这里需要注意的是最前面的注释,每个选项都是有意义的,所有的选项参考 TamperMonkey 官方文档,以下列出了比较常用、比较重要的部分选项(其中需要特别注意 @match、@include、@run-at)
| 选项 | 含义 |
|---|---|
| @name | 脚本的名称 |
| @namespace | 命名空间,用来区分相同名称的脚本,一般写作者名字或者网址就可以 |
| @version | 脚本版本,油猴脚本的更新会读取这个版本号 |
| @description | 描述这个脚本是干什么用的 |
| @author | 编写这个脚本的作者的名字 |
| @match | 从字符串的起始位置匹配正则表达式,只有匹配的网址才会执行对应的脚本,例如 * 匹配所有,https://www.baidu.com/* 匹配百度等,可以参考 Python re 模块里面的 re.match() 方法,允许多个实例 |
| @include | 和 @match 类似,只有匹配的网址才会执行对应的脚本,但是 @include 不会从字符串起始位置匹配,例如 *://*baidu.com/* 匹配百度,具体区别可以参考 TamperMonkey 官方文档 |
| @icon | 脚本的 icon 图标 |
| @grant | 指定脚本运行所需权限,如果脚本拥有相应的权限,就可以调用油猴扩展提供的 API 与浏览器进行交互。如果设置为 none 的话,则不使用沙箱环境,脚本会直接运行在网页的环境中,这时候无法使用大部分油猴扩展的 API。如果不指定的话,油猴会默认添加几个最常用的 API |
| @require | 如果脚本依赖其他 JS 库的话,可以使用 require 指令导入,在运行脚本之前先加载其它 |
| @run-at | 脚本注入时机,该选项是能不能 hook 到的关键,有五个值可选:document-start:网页开始时;document-body:body出现时;document-end:载入时或者之后执行;document-idle:载入完成后执行,默认选项;context-menu:在浏览器上下文菜单中单击该脚本时,一般将其设置为 document-start |
清除 cookie,开启 TamperMonkey 插件,再次来到某奇艺首页,可以成功被断下,也可以跟进调用栈来进一步分析 __dfp 值的来源。
四、常见的压缩和混淆
在Web系统发展早期,Js在Web系统中承担的职责并不多,Js文件比较简单,也不需要任何的保护。随着Js文件体积的增大和前后端交互增多,为了加快http传输速度并提高接口的安全性,出现了很多的压缩工具和混淆加密工具。
代码混淆的本质是对于代码标识和结构的调整,从而达到不可读不可调用的目的,常用的混淆有字符串、变量名混淆,比如把字符串转换成_0x,把变量重命名等,从结构的混淆包括控制流平坦化,虚假控制流和指令替换,代码加密主要有通过veal方法去执行字符串函数,通过escape()等方法编码字符串、通过转义字符加密代码、自定义加解密方法(RSA、Base64、AES、MD5等),或者通过一些开源的工具进行加密。
另外目前市面上比较常见的混淆还有ob混淆(obfuscator),特征是定义数组,数组位移。不仅Js中的变量名混淆,运行逻辑等也高度混淆,应对这种混淆可以使用已有的工具ob-decrypt或者AST解混淆或者使用第三方提供的反混淆接口。大家平时可以多准备一些工具,在遇到无法识别的Js时,可以直接使用工具来反混淆和解密,当然逆向工作本身就很看运气。
-
例如翻看网站的Javascript源代码,可以发现很多压缩或者看不太懂的字符,如javascript文件名被编码,文件的内容被压缩成几行,变量被修改成单个字符或者一些十六进制的字符——这些导致我们无法轻易根据Javascript源代码找出某些接口的加密逻辑。
4.1 JavaScript压缩
这个非常简单,Javascript压缩即去除JavaScript代码中不必要的空格、换行等内容或者把一些可能公用的代码进行处理实现共享,最后输出的结果都压缩为几行内容,代码的可读性变得很差,同时也能提高网站的加载速度。
如果仅仅是去除空格、换行这样的压缩方式,其实几乎是没有任何防护作用的,因为这种压缩方式仅仅是降低了代码的直接可读性。因为我们有一些格式化工具可以轻松将JavaScirpt代码变得易读,比如利用IDE、在线工具或Chrome浏览器都能还原格式化的代码。
这里举一个最简单的JavaScript压缩示例。原来的JavaScript代码是这样的:
function echo(stringA, stringB){
const name = "Germey";
alert("hello " + name);
}压缩之后就变成这样子:
function echo(d,c){const e="Germey";alert("hello "+e)};可以看到,这里参数的名称都被简化了,代码中的空格也被去掉了,整个代码也被压缩成了一行,代码的整体可读性降低了。
目前主流的前端开发技术大多都会利用webpack、Rollup等工具进行打包。webpack、Rollup会对源代码进行编译和压缩,输出几个打包好的JavaScript文件,其中我们可以看到输出的JavaScript文件名带有一些不规则的字符串,同时文件内容可能只有几行,变量名都用一些简单字母表示。这其中就包含JavaScript压缩技术,比如一些公共的库输出成bundle文件,一些调用逻辑压缩和转义成冗长的几行代码,这些都属于JavaScript压缩,另外,其中也包含了一些很基础的JavaScript混淆技术,比如把变量名、方法名替换成一些简单的字符,降低代码的可读性。
但整体来说,JavaScript压缩技术只能在很小的程度上起到防护作用,想要真正的提高防护效果,还得依靠JavaScript混淆和加密技术。
4.2 JavaScript混淆
JavaScript混淆完全是在JavaScript上面进行的处理,它的目的就是使得JavaScript变得难以阅读和分析,大大降低代码的可读性,是一种很实用的JavaScript保护方案。
JavaScript混淆技术主要有一下几种。
-
变量名混淆:将带有含义的变量名、方法名、常量名随机变为无意义的类乱码字符串,降低代码的可读性,如转换成单个字符或十六进制字符串。
-
字符串混淆:将字符串阵列化集中并可进行MD5或Base64加密存储,使代码中不出现明文字符串,这样可以避免使用全局搜索字符串的方式定位到入口。
-
对象键名替换:针对JavaScript对象的属性进行加密转化,隐藏代码之间的调用关系。
-
控制流平坦化:打乱函数原有代码的执行流程及函数调用关系,使代码逻辑变得混乱无序。
-
无用代码注入:随机在代码中插入不会被执行到的无用代码,进一步使代码看起来更加混乱。
-
调试保护:基于调试器特征,对当前运行环境进行检查,加入一些debugger语句,使其在调试模式下难以顺利执行JavaScript代码。
-
多态变异:使JavaScript代码每次被调用时,将代码自身立刻自动发生变异,变为与之前完全不同的代码,即功能完全不变,只是代码形式变异,以此杜绝代码被动态分析和调试。
-
域名锁定:使JavaScript代码只能在指定域名下执行。
-
代码自我保护:如果对JavaScript代码进行格式化,则无法执行,导致浏览器假死。
-
特殊编码:将JavaScript完全编码为人不可读的代码,如表情符号、特殊表示内容、等等。
总之,以上方案都是JavaScript混淆的实现方式,可以在不同程度上保护JavaScript代码。
在前端开发中,现在JavaScript混淆的主流实现使javascript-obfuscator和terser这两个库。它们都能提供一些代码混淆功能,也都有对应的webpack和Rollup打包工具的插件。利用它们,我们可以非常方便地实现页面的混淆,最终输出压缩和混淆后的JavaScript代码,使得JavaScript代码的可读性大大降低。
下面我们以javascript-obfuscator为例来介绍一些代码混淆的实现,了解了实现,那么我们自然就对混淆的机制有了更加深刻的认识。
javascript-obfuscator的官方介绍内容如下:
链接:Javascript Obfuscator - Protects JavaScript code from stealing and shrinks size - 100% Free
它是支持ES8的免费、高效的JavaScript混淆库,可以使得JavaScript代码经过混淆后难以被复制、盗用、混淆后的代码具有和原来的代码一模一样的功能。
首先我们需要安装好Node.js 12.x及以上版本,确保可以正常使用npm命令。
具体的安装方式如下:
简单的说 Node.js 就是运行在服务端的 JavaScript。
Node.js 是一个基于 Chrome JavaScript 运行时建立的一个平台。
Node.js 是一个事件驱动 I/O 服务端 JavaScript 环境,基于 Google 的 V8 引擎,V8 引擎执行 Javascript 的速度非常快,性能非常好。
-
官网:Node.js
-
文档:Index | Node.js v21.6.2 Documentation
-
中文网:Node.js 中文网
-
基础教程:Node.js 教程 | 菜鸟教程
接着新建一个文件夹,比如js-ob然后进入该文件夹,初始化工作空间:
npm init这里会提示我们输入一些信息,然后创建package.json文件,这就完成了项目的初始化了。
接下来,我们来安装javascript-obfuscator这个库:
npm i -D javascript-obfuscator稍等片刻,即可看到本地js-ob文件下生成了一个node_modules文件夹,里面就包含了javascript-obfuscator这个库,这就说明安装成功了。
接下来,我们就可以编写代码来实现一个混淆样例了。比如,新建main.js文件,其内容如下:
const code = `
let x = '1' + 1
console.log('x', x)
`
const options = {
compact: false,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))这里我们定义了两个变量:一个是code,即需要被混淆的代码;另一个是混淆选项options,是一个Object。接下来,我们引入了javascript-obfuscator这个库,然后定义了一个方法,给其传入code和options来获取混淆之后的代码,最后控制台输出混淆后的代码。
代码逻辑比较简单,我们来执行一下代码:
node main.js输出结果如下:
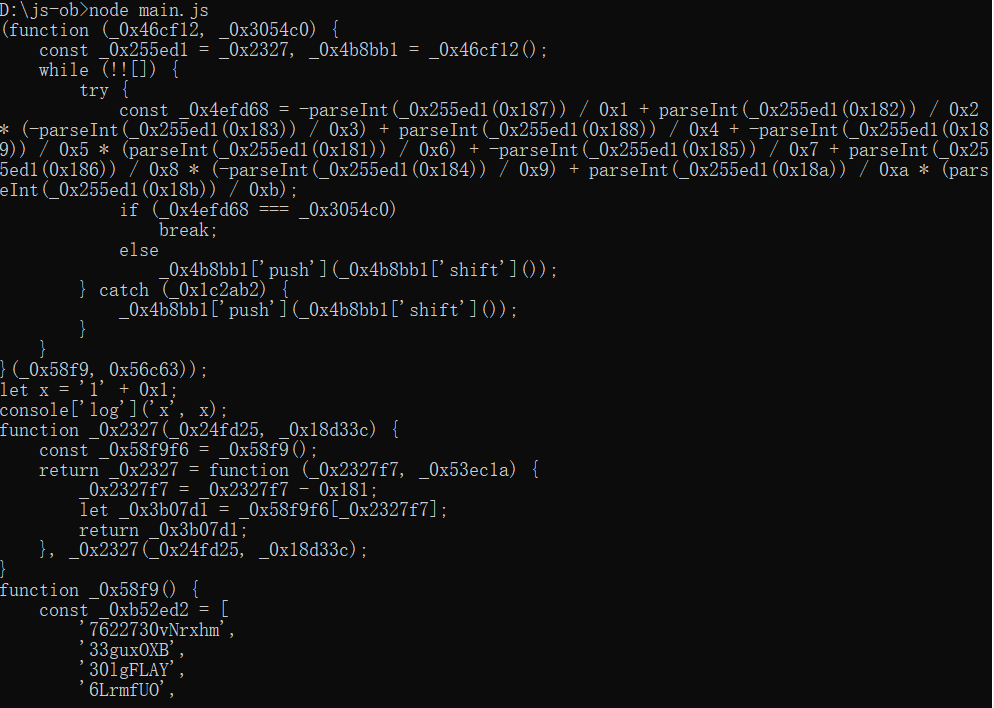
看到了吧,那么简单的代码,被我们混淆成了这个样子,其实这里我们就是设定了“控制流平坦化”选项。整体看来,代码的可读性大大降低了,JavaScript调试的难度也大大加强了。
4.3 javascript-obfuscator示例
下面的例子代码同上
4.3.1 代码压缩
这里javascript-obfuscator也提供了代码压缩的功能,使用其参数compact即可完成JavaScript代码的压缩,输出为一行内容。参数compact的默认值是true,如果定义为false,则混淆后的代码会分行显示。
如果不设置或者把compact设置为true,结果如下:
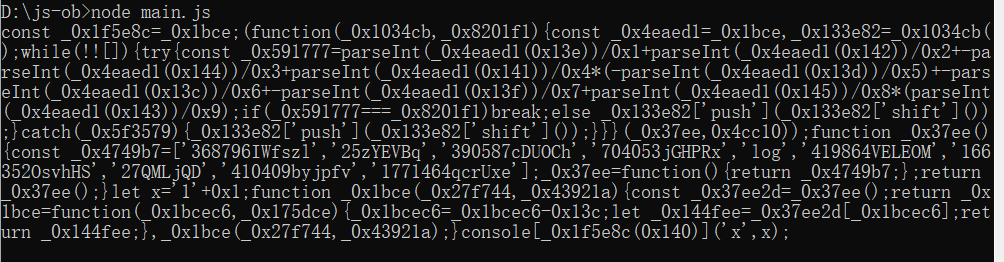
可以看到,单行显示的时候,对变量名进行了进一步的混淆,这里变量的命名都变成了十六进制形式的字符串,这是因为启用了一些默认压缩和混淆的方式。总之我们可以看到代码的可读性相比之前大大降低。
4.3.2 变量名混淆
变量名混淆可以通过在javascript-obfuscator中配置identifierNamesGenerator参数来实现。我们通过这个参数可以控制变量名混淆的方式,如将其设置为hexadecimal,则会将变量名替换为十六进制形式的字符串。该参数的取值如下。
-
hexadecimal:将变量名替换为十六进制形式的字符串,如0xabc123。
-
mangled:将变量名替换为普通的简写字符,如a,b,c等。
该参数的默认值为:hexadecimal
我们将该参数改为:mangled 来试一下:
const code = `
let x = '1' + 1
console.log('x', x)
`
const options = {
compact: true,
identifierNamesGenerator: 'mangled'
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果如下:
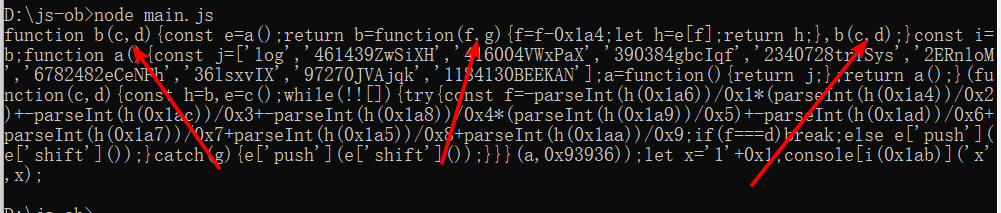
另外,我们还可以通过设置identifiersPrefix参数来控制混淆后的变量前缀,示例如下:
const code = `
let x = '1' + 1
console.log('x', x)
`
const options = {
identifiersPrefix: 'kk',
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果如下:
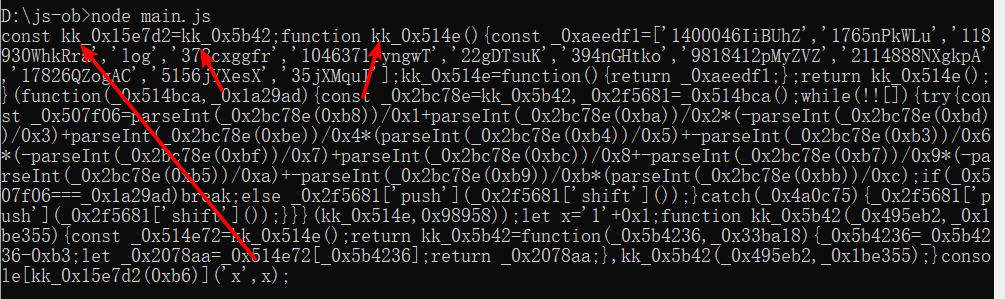
可以看到,混淆后的变量前缀加上了我们自定义的字符串kk。
另外,renameGlobals这个参数还可以指定是否混淆全局变量和函数名称,默认值为false。示例如下:
const code = `
var $ = function(id){
return document.getElementById(id);
};
`
const options = {
renameGlobals: true,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果如下:
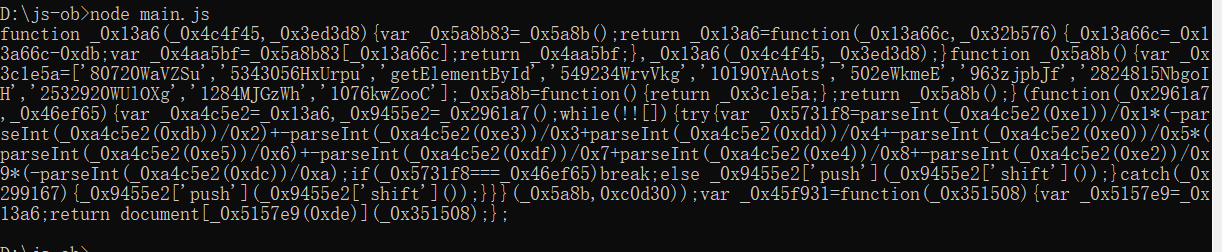
可以看到,这里我们声明了一个全局变量$,在renameGlobals设置为true之后,这个变量也被替换了。如果后文用到了这个变量,可能就会有找不到定义的错误,因此这个参数可能导致代码执行不通。
如果我们不设置 renameGlobals 或者将其设置为false,结果如下:
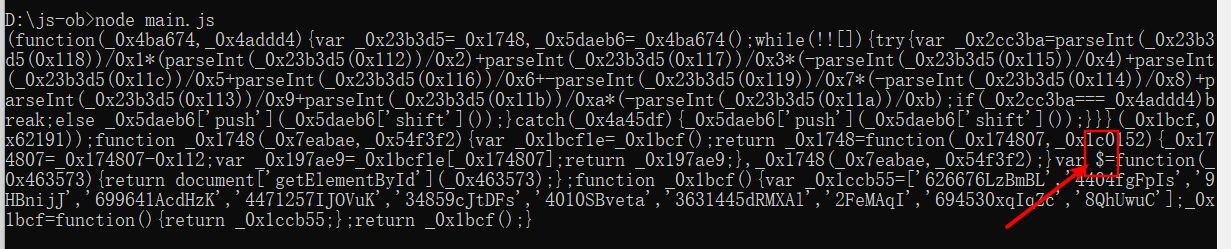
可以看到,最后还是有$的声明,其全局名称没有被改变。
4.3.3 字符串混淆
字符串混淆,就是将一个字符串声明放到一个数组里面,使之无法被直接搜索到。这可以通过stringArray参数来控制,默认为true。
此外,我们还可以通过rotateStringArray参数来控制数组化后结果的元素顺序,默认为true。
示例如下:
const code = `
var a = 'helloworld'
`
const options = {
stringArray: true,
rotateStringArray: true,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))运行结果如下:

另外,我们还可以使用unicodeEscapeSequence这个参数对字符串进行Unicode转码,使之更加难以辨认,示例如下:
const code = `
var a = 'hello world'
`
const options = {
compact: false,
unicodeEscapeSequence: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options)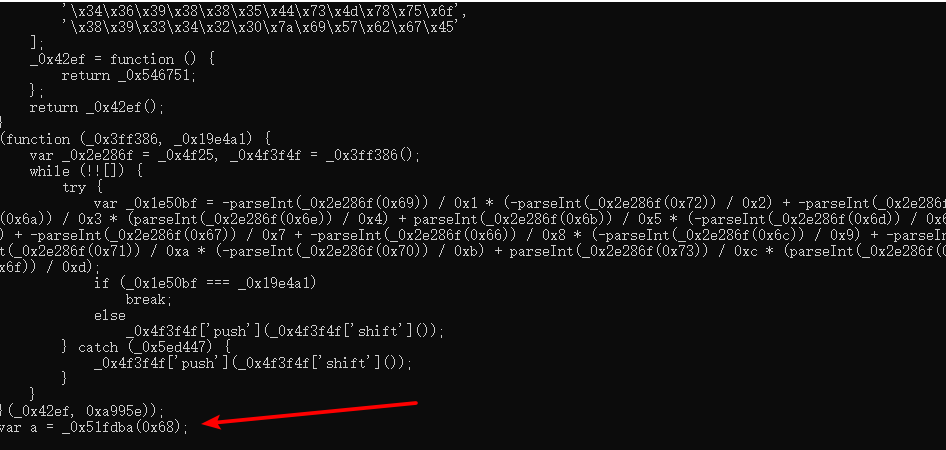
可以看到,这里字符串被数字化和Unicode化,非常难以辨认。
在很多JavaScript逆向过程中,一些关键的字符串可能会作为切入点来查找加密入口,用了这种混淆之后,如果有人想通过全局搜索的方式搜索hello这样的字符串找加密入口,也就没法搜到了。
4.3.4 代码自我保护
我们可以通过设置selfDefending参数来开启代码自我保护功能。开启之后混淆后的JavaScript会强制以一行显示。如果我们将混淆后的代码进行格式化或者重命名,该段代码将无法执行。
示例如下:
const code = `
console.log('hello world')
`
const options = {
selfDefending: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))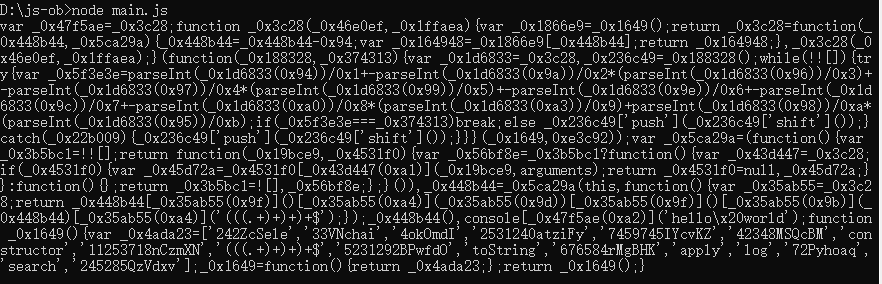
如果我们将上述代码放到控制台,它的执行结果和之前是一模一样的,没有任何问题。
如果我们将其进行格式化,然后粘贴到浏览器控制台里面,浏览器会直接卡死无法运行。这样如果有人对代码进行了格式化,就无法正常对代码进行运行和调试,从而起到了保护作用。
4.3.5 控制流平坦化
控制流平坦化其实就是将代码的执行逻辑混淆,使其变得复杂、难度。其基本的思想是将一些逻辑处理块都统一加上一个前驱逻辑块,每个逻辑块都由前驱逻辑块进行条件判断个分发,构成一个个闭环逻辑,这导致整个执行逻辑十分复杂、难度。
比如说这里有一段示例代码:
console.log(c);
console.log(a);
console.log(b);代码逻辑一目了然,一次在控制台输出了c, a, b三个变量的值。但是如果把这段代码进行控制流平坦化处理,代码就会变成这样:
const code = `
console.log(c);
console.log(a);
console.log(b);
`
const options = {
compact: false,
controlFlowFlattening: true,
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))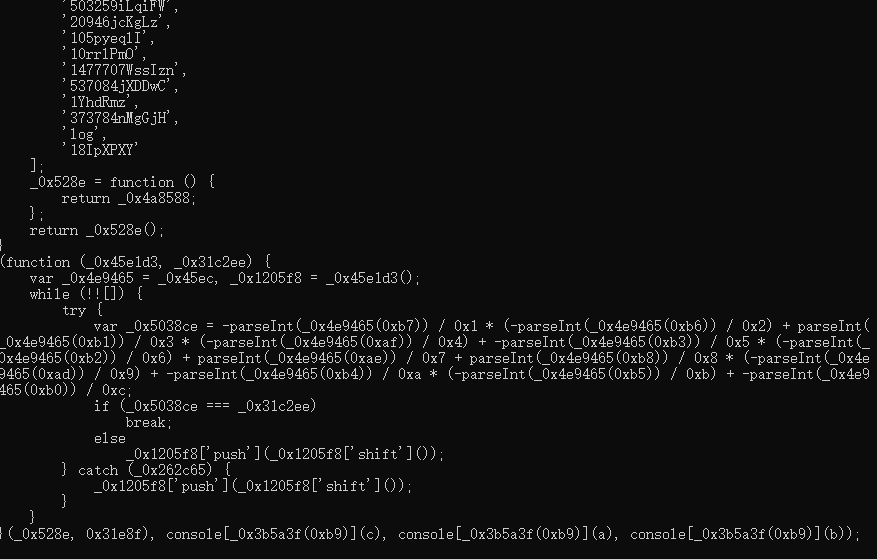
使用控制流平坦化可以使得执行逻辑更加复杂、难读,目前非常多的前端混淆都会加上这个选项。但启用控制流平坦化之后,代码的执行时间会变长。
4.3.6 无用代码注入
无用代码即不会被执行的代码或对上下文没有任何影响的代码,注入之后可以对现有的JavaScript代码的阅读形成干扰。我们可以使用deadCodeInjection参数开启这个选项,其默认值为false。
示例:
const code = `
console.log(c);
console.log(a);
console.log(b);
`
const options = {
compact: false,
deadCodeInjection: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))这种混淆方式通过混入一些特殊的判断条件并加入一些不会被执行的代码,可以对代码起到一定的干扰作用。
4.3.7 对象键名替换
如果是一个对象,可以使用transformObjectKeys来对对象的键值进行替换,示例如下:
const code = `
(function(){
var object = {
foo: 'test1',
bar: {
baz: 'test2'
}
};
})();
`
const options = {
compact: false,
transformObjectKeys: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}可以看到,Object的变量名被替换为了特殊的变量,代码的可读性变差,这样我们就不好直接通过变量名进行搜寻了,这也可以起到一定的防护作用。
4.3.8 禁用控制台输出
我们可以使用disableConsoleOutput来禁用掉console.log输出功能,加大调试难度,示例如下:
const code = `
console.log('hello world')
`
const options = {
disableConsoleOutput: true
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))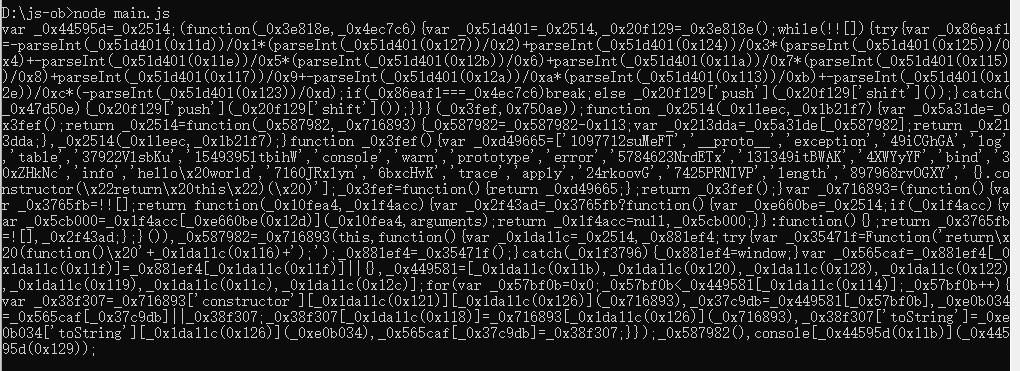
此时,我们如果执行这段代码,发现是没有任何输出的,这里实际上就是将console的一些功能禁用了。
4.3.9 调试保护
我们知道,如果Javascript代码中加入关键字debugger关键字,那么执行到该位置的时候,就会进入断点调试模式。如果在代码多个位置都加入debugger关键字,或者定义某个逻辑来反复执行debugger,就会不断进入断点调试模式,原本的代码就无法顺畅执行了。这个过程可以称为调试保护,即通过反复执行debugger来使得原来的代码无法顺畅执行。
其效果类似于执行了如下代码:
setInterval(() => {debugger;}, 3000)如果我们把这段代码粘贴到控制台,它就会反复执行debugger语句,进入断点调试模式,从而干扰正常的调试流程。
在javascript-obfuscator中,我们可以使用debugProtection来启用调试保护机制,还可以使用debugProtectionInterval来启用无限调试(debug),使得代码在调试过程中不断进入断点模式,无法顺畅执行。配置如下:
const options = {
debugProtection: true,
}混淆后的代码会跳到debugger代码的位置,使得整个代码无法顺畅执行,对JavaScript代码的调试形成干扰。
4.3.10 域名锁定
我们还可以通过控制domainLock来控制JavaScript代码只能在特定域名下运行,这样就可以降低代码被模拟或者盗用的风险。
示例如下:
const code = `
console.log('hello world')
`
const options = {
domainLock: ['kk.com']
}
const obfuscator = require('javascript-obfuscator')
function obfuscate(code, options) {
return obfuscator.obfuscate(code, options).getObfuscatedCode()
}
console.log(obfuscate(code, options))这里我们使用domainLock指定了一个域名kk.com,也就是设置了一个域名白名单,混淆后的代码结果如下:
这段代码就只能在指定的域名kk.com下运行,不能在其他网站运行。这样的话,如果一些相关JavaScript代码被单独剥离出来,想在其他网站运行或者使用程序模拟运行的话,运行结果只有失败,这样就可以有效降低代码被模拟或盗用的风险。
4.3.11特殊编码
另外,还有一些特殊的工具包(jjencode,aaencode等)他们可以对代码进行混淆和编码。
链接:JSON在线 | JSON解析格式化—SO JSON在线工具
示例如下:
var kk = 100使用jjencode工具的结果:

使用aaencode工具的结果:
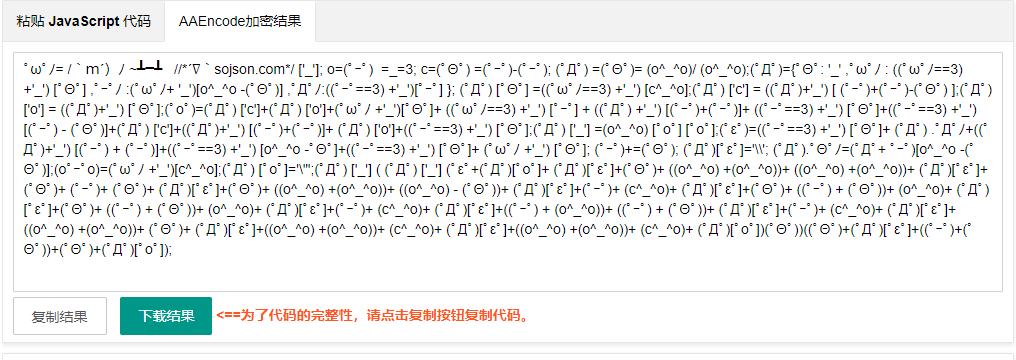
可以看到,通过这些工具,原本非常简单的代码被转化为一些几乎完全不可读的代码,但实际上运行效果还是相同的。这些混淆方式比较另类,看起来虽然没有什么头绪,但实际上找到规律是非常好还原的,并没有真正达到强力混淆的效果。
关于这种混淆代码的解码方法,一般直接复制到控制台运行或者用解码工具进行转换,如果运行失败,就需要按分号分割语句,逐行调试分析源码。
以上便是对JavaScript混淆方式的介绍和总结。总的来说经过混淆的JavaScript代码的可读性大大降低,同时其防护效果也大大增强。
五、常见的编码和加密
我们在爬取网站的时候,会遇到一些需要分析接口或URL信息的情况,这时会有各种各样的类似加密的情形。
-
某个网站的URL带有一些看不太懂的长串加密参数,要抓取就得必须懂得这些参数是怎么构造的,否则我们连完整的URL都构造不出来,更不用说爬取了。
-
在分析某个网站的Ajax接口时,可以看到接口的一些参数也是加密的,Request Headers 里面也可能带有一些加密参数,如果不知道这些参数的具体构造逻辑,就没法直接用程序来模拟这些Ajax请求。
常见的编码有base64、unicode、urlencode编码,加密有MD5、SHA1、HMAC、DES、RSA等。
简单介绍一下常见的编码加密,同时附上Python实现加密的方法。
5.1 base64
base64是一种基于64个可打印ASCLL字符对任意字节数据进行编码的算法,其在编码后具有一定意义的加密作用。在逆向过程中经常会碰到base64编码(不论是Js逆向还是安卓逆向)。
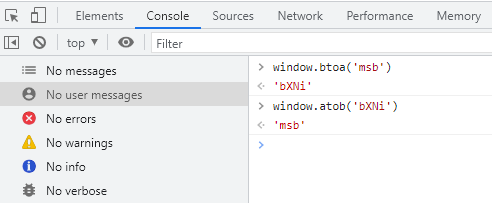
浏览器提供了原生的base64编码、解码方法,方法名就是btoa和atob如下图所示:
在python中使用base64:
import base64
print(base64.b64encode('msb'.encode()))
print(base64.b64decode('bXNi'.encode()))var str1 = "msb";unicode和urlencode比较简单,unicode是计算机中字符集、编码的一项业界标准,被称为统一码、万国码,表现形式一般以“\u" 或者 "&#"开头。urlencode是URL编码,也称作百分号编码用于把URL中的符号进行转换。
5.2 MD5
MD5消息摘要算法(英文:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。MD5加密算法是不可逆的,所以解密一般都是通过暴力穷举方法,以及网站的接口实现解密。
python代码实现加密:
import hashlib
pwd = "123"
# 生成MD5对象
m = hashlib.md5()
# 对数据进行加密
m.update(pwd.encode('utf-8'))
# 获取密文
pwd = m.hexdigest()
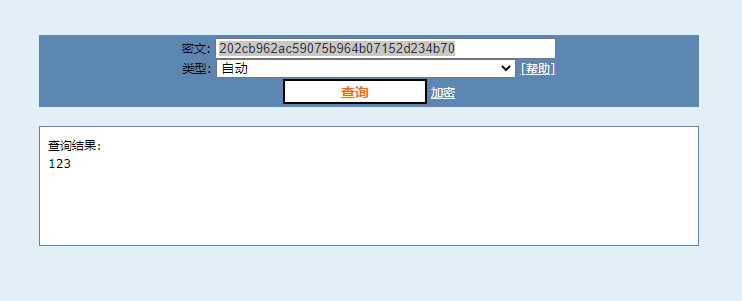
print(pwd)解密工具:md5在线解密破解,md5解密加密
5.3 SHA1
SHA1(Secure Hash Algorithm)安全哈希算法主要适用于数字签名标准里面定义的数字签名算法,SHA1比MD5的安全性更强。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。
一般在没有高度混淆的Js代码中,SHA1加密的关键词就是sha1。
Python实现代码:
import hashlib
sha1 = hashlib.sha1()
data1 = "msb"
data2 = "kkk"
sha1.update(data1.encode("utf-8"))
sha1_data1 = sha1.hexdigest()
print(sha1_data1)
sha1.update(data2.encode("utf-8"))
sha1_data2 = sha1.hexdigest()
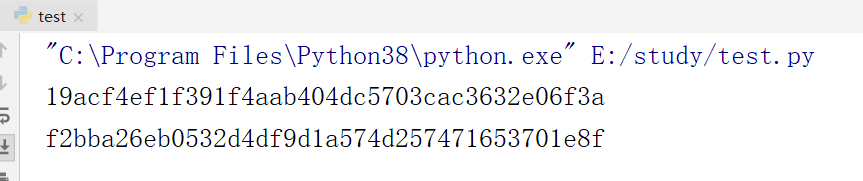
print(sha1_data2)运行结果:
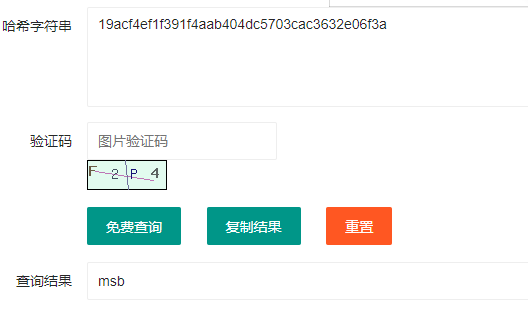
解密工具:哈希在线加密|MD5在线解密加密|SHA1在线解密加密|SHA256在线解密加密|SHA512在线加密|GEEKAPP开发者在线工具
5.4 HMAC
HMAC全称:散列消息鉴别码。HMAC加密算法是一种安全的基于加密hash函数和共享密钥的消息认证协议。实现原理是用公开函数和密钥产生一个固定长度的值作为认证标识,用这个标识鉴别消息的完整性。
python实现代码:
new(key,msg=None,digestmod)方法
-
创建哈希对象
-
key和digestmod参数必须指定,key和msg(需要加密的内容)均为bytes类型,digestmod指定加密算法,比如‘md5’,'sha1'等
对象digest()方法:返回bytes类型哈希值
对象hexdigest()方法:返回十六进制哈希值
import hmac
import hashlib
key = "key".encode()
text = "msb".encode()
m = hmac.new(key, text, hashlib.sha256)
print(m.digest())
print(m.hexdigest())5.5 DES
DES全称:数据加密标准(Data Encryption Standard),属于对称加密算法。DES是一个分组加密算法,典型的DES以64位为分组对数据加密,加密和解密用的是同一个算法。它的密钥长度是56位(因为每个第8位都用作奇偶校验),密钥可以是任意的56位数,而且可以任意时候改变。
Js逆向时,DES加密的搜索关键词有DES、mode、padding等。
python实现代码:
# pyDes需要安装
from pyDes import des, CBC, PAD_PKCS5
import binascii
# 秘钥
KEY = 'dsj2020q'
def des_encrypt(s):
"""
DES 加密
:param s: 原始字符串
:return: 加密后字符串,16进制
"""
secret_key = KEY
iv = secret_key
k = des(secret_key, CBC, iv, pad=None, padmode=PAD_PKCS5)
en = k.encrypt(s, padmode=PAD_PKCS5)
return binascii.b2a_hex(en).decode()
def des_decrypt(s):
"""
DES 解密
:param s: 加密后的字符串,16进制
:return: 解密后的字符串
"""
secret_key = KEY
iv = secret_key
k = des(secret_key, CBC, iv, pad=None, padmode=PAD_PKCS5)
de = k.decrypt(binascii.a2b_hex(s), padmode=PAD_PKCS5)
return de.decode()
text = 'msb'
secret_str = des_encrypt(text)
print(secret_str)
clear_str = des_decrypt(secret_str)
print(clear_str)5.5 AES
AES全程:高级加密标准,在密码学中又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。
AES也是对称加密算法,如果能够获取到密钥,那么就能对密文解密。
Js逆向时,AES加密的搜索关键词有AES、mode、padding等。
python代码实现之前
pip install pycryptodomepython实现代码:
import base64
from Crypto.Cipher import AES
# AES
# 需要补位,str不是16的倍数那就补足为16的倍数
def add_to_16(value):
while len(value) % 16 != 0:
value += '\0'
return str.encode(value) # 返回bytes
# 加密方法
def encrypt(key, text):
aes = AES.new(add_to_16(key), AES.MODE_ECB) # 初始化加密器
encrypt_aes = aes.encrypt(add_to_16(text)) # 先进行aes加密
encrypted_text = str(base64.encodebytes(encrypt_aes), encoding='utf-8')
return encrypted_text
# 解密方法
def decrypt(key, text):
aes = AES.new(add_to_16(key), AES.MODE_ECB) # 初始化加密器
base64_decrypted = base64.decodebytes(text.encode(encoding='utf-8'))
decrypted_text = str(aes.decrypt(base64_decrypted), encoding='utf-8').replace('\0', '') # 执行解密密并转码返回str
return decrypted_text5.6 RSA
RSA全称:Rivest-Shamir-Adleman, RSA加密算法是一种非对称加密算法,在公开密钥加密和电子商业中RSA被广泛使用,它被普遍认为是目前最优秀的公钥方案之一。RSA是第一个能同时用于加密和数字签名的算法,它能够抵抗目前为止已知的所有密码攻击。
注意Js代码中的RSA常见标志setPublickey。
算法原理参考:https://www.yht7.com/news/184380
实现代码之前先安装 :
pip install pycryptodome python代码实现:
import base64
from Crypto.Cipher import PKCS1_v1_5
from Crypto import Random
from Crypto.PublicKey import RSA
# ------------------------生成密钥对------------------------
def create_rsa_pair(is_save=False):
"""
创建rsa公钥私钥对
:param is_save: default:False
:return: public_key, private_key
"""
f = RSA.generate(2048)
private_key = f.exportKey("PEM") # 生成私钥
public_key = f.publickey().exportKey() # 生成公钥
if is_save:
with open("crypto_private_key.pem", "wb") as f:
f.write(private_key)
with open("crypto_public_key.pem", "wb") as f:
f.write(public_key)
return public_key, private_key
def read_public_key(file_path="crypto_public_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
def read_private_key(file_path="crypto_private_key.pem") -> bytes:
with open(file_path, "rb") as x:
b = x.read()
return b
# ------------------------加密------------------------
def encryption(text: str, public_key: bytes):
# 字符串指定编码(转为bytes)
text = text.encode("utf-8")
# 构建公钥对象
cipher_public = PKCS1_v1_5.new(RSA.importKey(public_key))
# 加密(bytes)
text_encrypted = cipher_public.encrypt(text)
# base64编码,并转为字符串
text_encrypted_base64 = base64.b64encode(text_encrypted).decode()
return text_encrypted_base64
# ------------------------解密------------------------
def decryption(text_encrypted_base64: str, private_key: bytes):
# 字符串指定编码(转为bytes)
text_encrypted_base64 = text_encrypted_base64.encode("utf-8")
# base64解码
text_encrypted = base64.b64decode(text_encrypted_base64)
# 构建私钥对象
cipher_private = PKCS1_v1_5.new(RSA.importKey(private_key))
# 解密(bytes)
text_decrypted = cipher_private.decrypt(text_encrypted, Random.new().read)
# 解码为字符串
text_decrypted = text_decrypted.decode()
return text_decrypted
if __name__ == "__main__":
# 生成密钥对
# create_rsa_pair(is_save=True)
# public_key = read_public_key()
# private_key = read_private_key()
public_key, private_key = create_rsa_pair(is_save=False)
# 加密
text = "msb"
text_encrypted_base64 = encryption(text, public_key)
print("密文:", text_encrypted_base64)
# 解密
text_decrypted = decryption(text_encrypted_base64, private_key)
print("明文:", text_decrypted)