目录
- 综述
- export-camera.py
- 加载模型
- 加载数据
- 生成需要导出成 onnx 的模块
- Backbone 模块
- VTransform 模块
- 生成 onnx
- 使用 pytorch 原生的伪量化计算方法
- 导出 camera.backbone.onnx
- 导出 camera.vtransform.onnx
综述
bevfusion的各个部分的实现有着鲜明的特点,并且相互独立,特别是考虑到后续部署的需要,这里将整个网络,分成多个部分,分别导出onnx,方便后续部署。

export-camera.py
相机部分导出思路如下:
1)骨干网络的选择
对于骨干网络来说,选择了Resnet50作为骨干网络。精度会掉一点,但是收益非常大,益于部署。
2)网络拆分
bev_pool有着高性能计算的需求,是使用cuda核函数实现的。
bev_pool的输入,依赖于bev_pool之前的网络的输出,bev_pool的输出,需要有个池化,使得360360大小的bev池化成180180。
所以bev_pool把整个网络,从中间分隔。
目前思路如下:
- bev_pool前的网络,导出onnx,最终用TRT推理。
- bev_pool部分使用cuda核函数实现。
- bev_pool后的网络,导出onnx,最终用TRT推理。

加载模型

这里选择经过 ptq 量化后的 bevfusion 模型。
- Args
Namespace(ckpt='qat/ckpt/bevfusion_ptq.pth', fp16=False)
加载数据

- Data数据中有什么
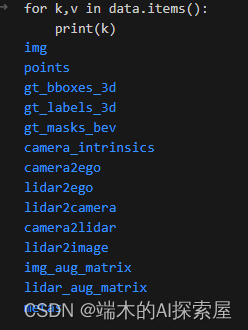
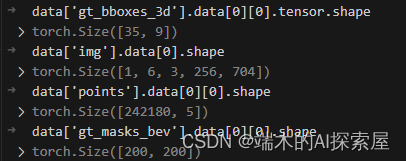

加载后续生成计算图时需要的数据。其实就是提供了一个全是0的样本数据。
生成需要导出成 onnx 的模块
Backbone 模块
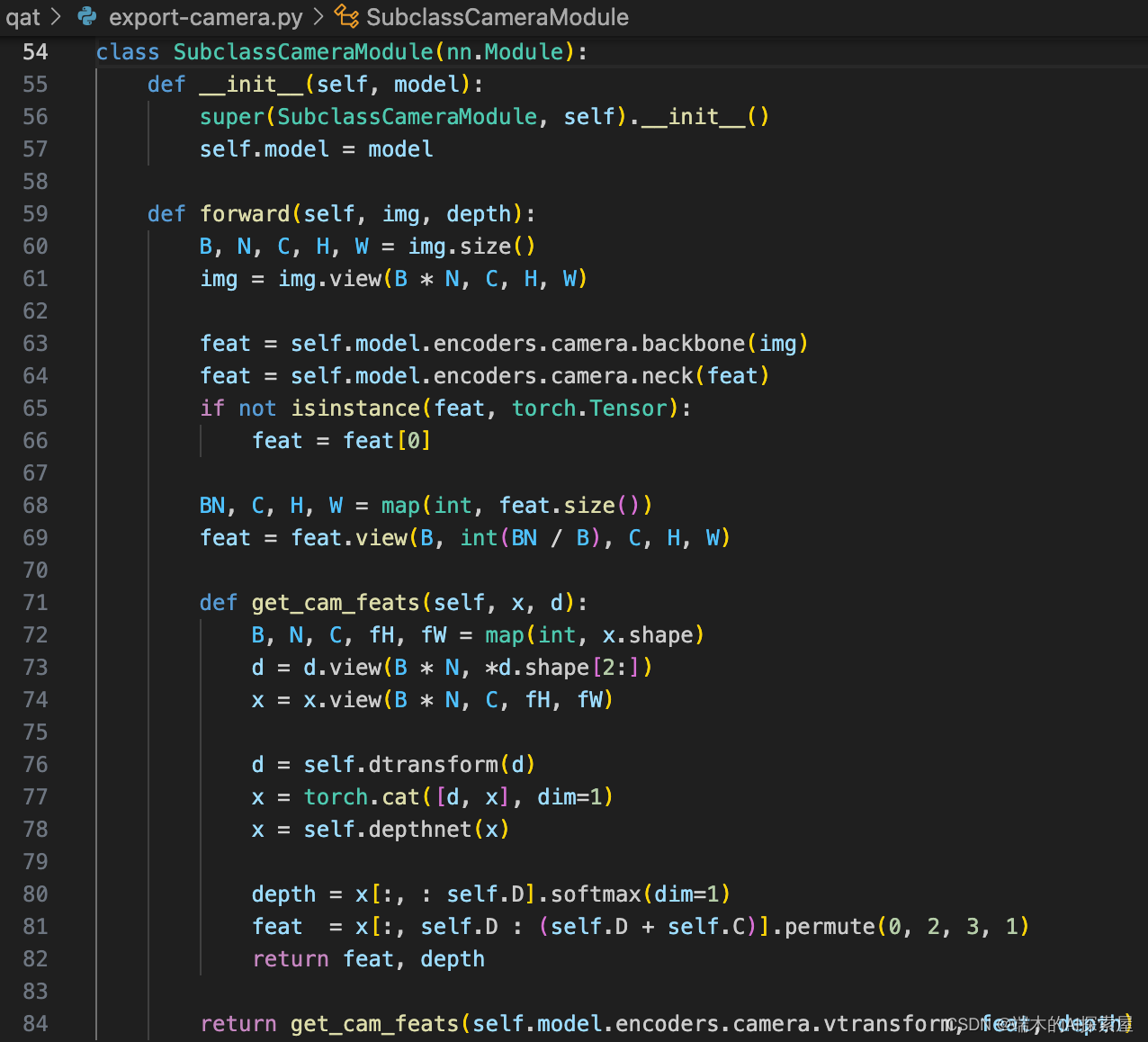
CUDA-BEVFusion选择使用子类化的方式,从model也就是整个模型中,摘出自己想要的相机部分,构建成camera_model

下图是具体子类化实现方式,子类化要对mit-bevfusion的代码、网络十分熟悉,有着充分的理解。
下图是mit-bevfusion的代码,会发现二者很像。子类化要忠实于原本的python算法,在这个基础上进行修改,实现自己想要的功能。
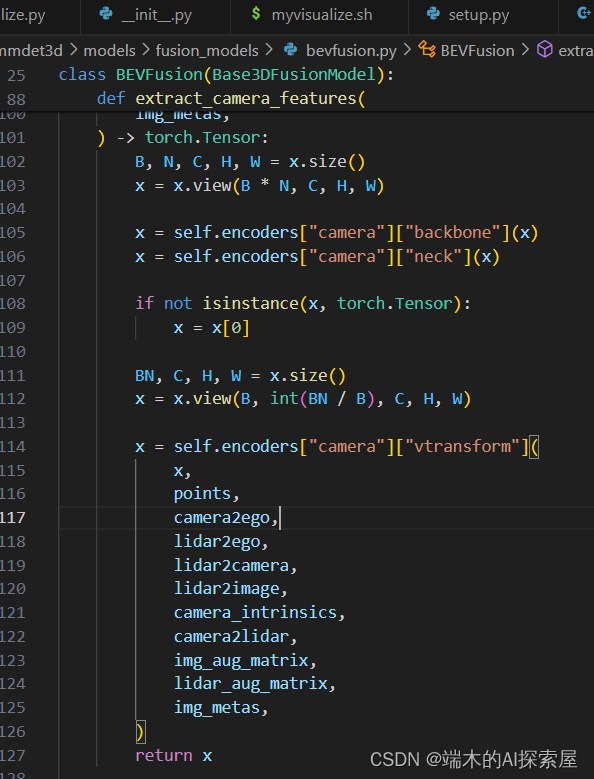
下方也是原mit-bevfusion的代码,可以看到原本的输出只有1个,而SubclassCameraModule里的get_cam_feats有两个输出。这个
这里创建了一个SubclassCameraModule类,用于在 BEVFusion 模型中提取部分模型用于导出 onnx。
-
init 函数就是通常的初始化函数。
-
forward 函数是基于 bevfusion 中的
extract_camera_features函数的修改,对self.encoders["camera"][vtransforms]进行了较多修改。-
取消了
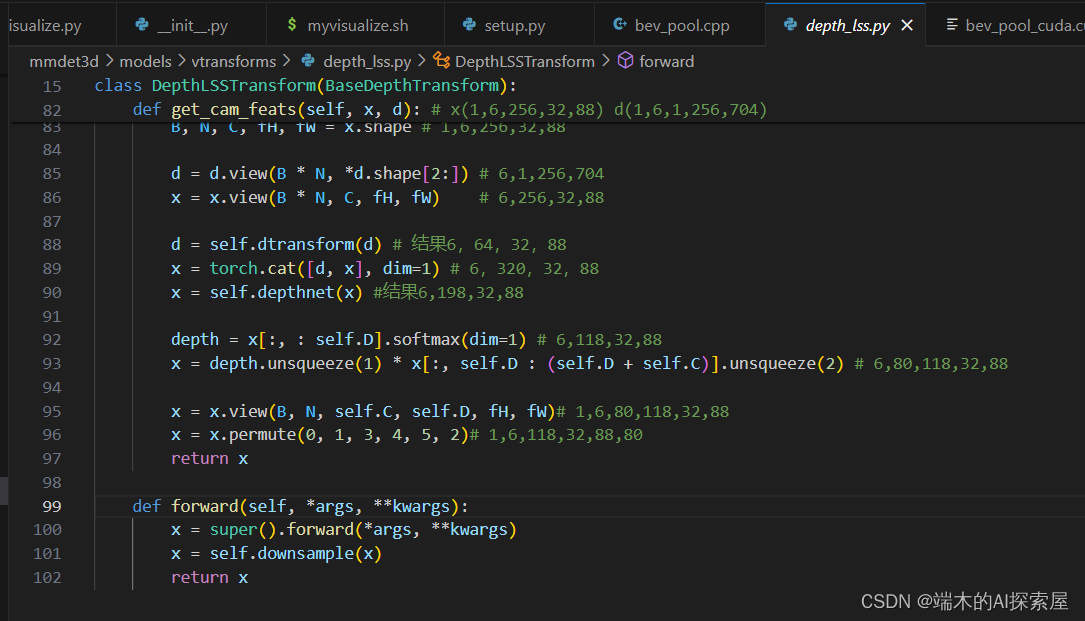
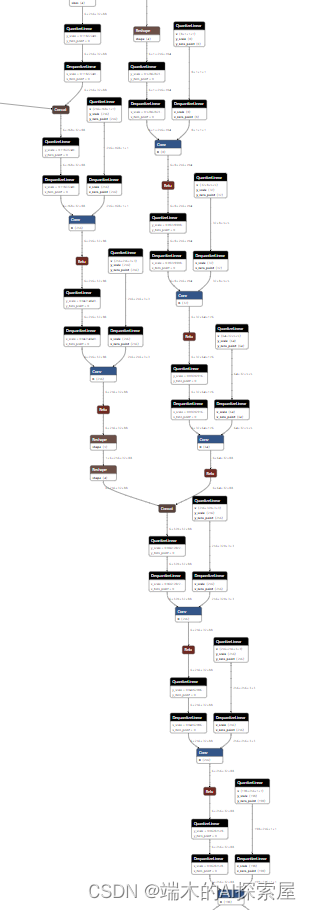
get_geometry和bev_pool的计算,并且省去了深度和图像特征的外积操作。之后生成的计算图包含了 Resnet50、GeneralizedLSSFPN、dtransform、depthnet 和两个切片操作。 -
输出从原本的一个输出,
-
Resnet50




-
GeneralizedLSSFPN(Neck)、dtransform、depthnet
-
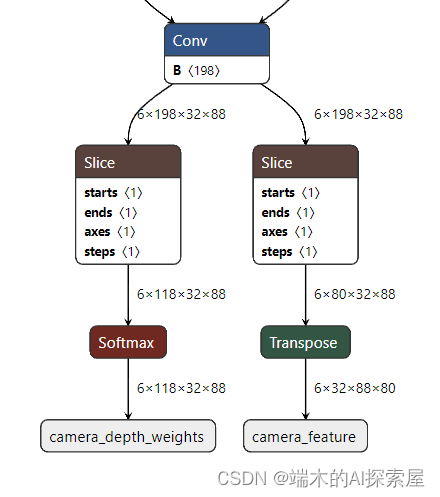
切片
-
-
从onnx中可以明显的看出,
SubclassCameraModule类的输出修改为两个。- 取消外积,这样输入bev_pool的数据规模大大减少。从161183288*80拆成了两个如图形状的数据。
VTransform 模块

BaseDepthTransform 中的下采样操作,将 bev pool 的输出作为输入,这里仅导出 downsampling 的计算图。
生成 onnx
使用 pytorch 原生的伪量化计算方法

导出 camera.backbone.onnx
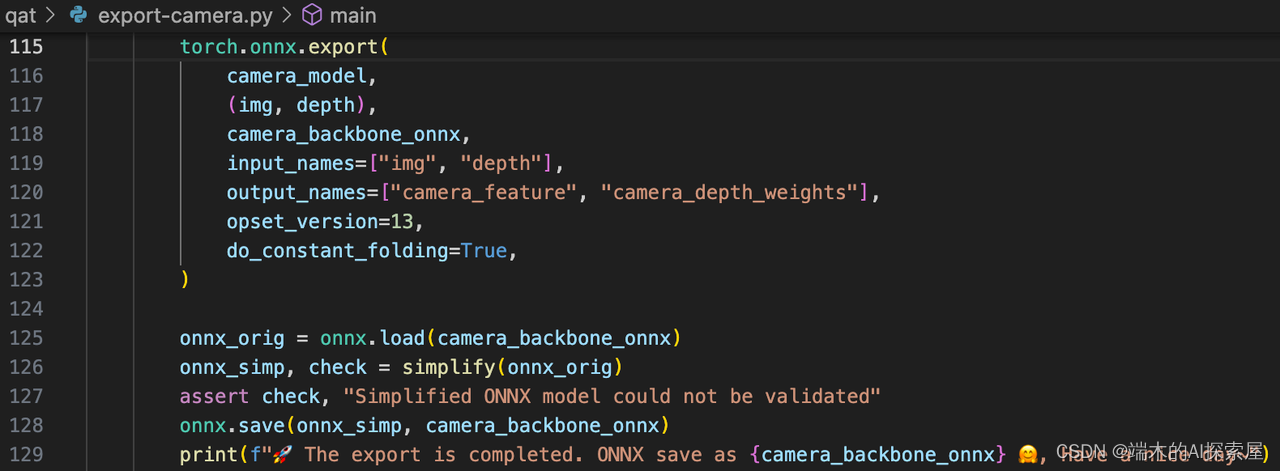
根据 SubclassCameraModule.forward 中的流程生成计算图,再经过简化(126行)生成最终的 camera.backbone.onnx。
导出 camera.vtransform.onnx
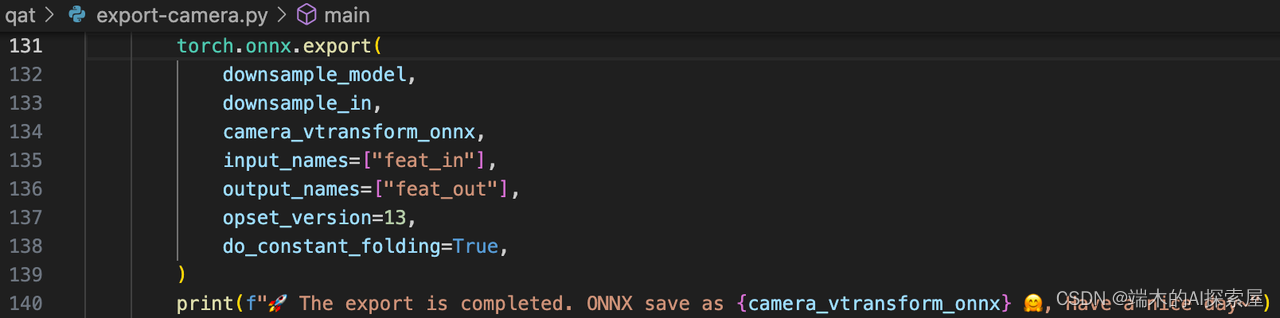
根据 DepthLSSTransform.downsample 模块生成计算图,保存为 camera.vtransform.onnx。