概述
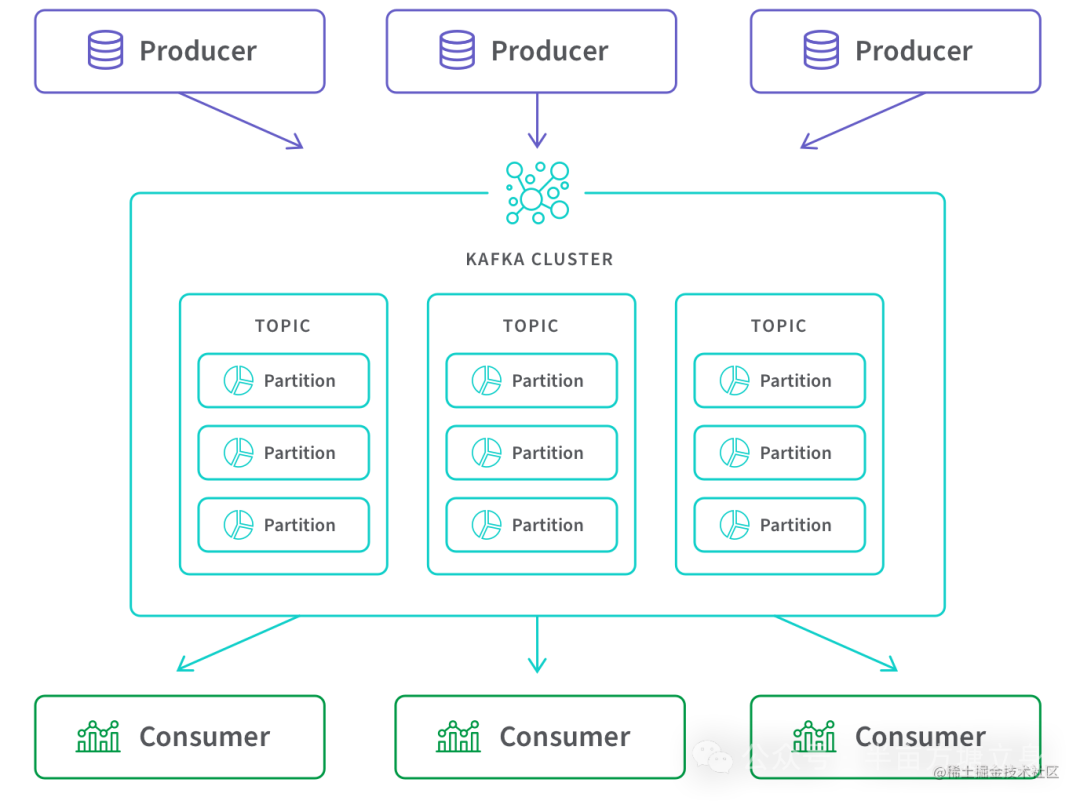
我们知道Kafka架构如下,主要由 Producer、Broker、Consumer 三部分组成。一条消息从生产到消费完成这个过程,可以划分三个阶段,生产阶段、存储阶段、消费阶段。
-
产阶段: 在这个阶段,从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
-
存储阶段: 在这个阶段,消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。
-
消费阶段: 在这个阶段,Consumer 从 Broker 上拉取消息,经过网络传输发送到Consumer上。
那么如何保证消息不丢我们可以从这三部分来分析。
消息传递语义
在深度剖析消息丢失场景之前,我们先来聊聊「消息传递语义」到底是个什么玩意?
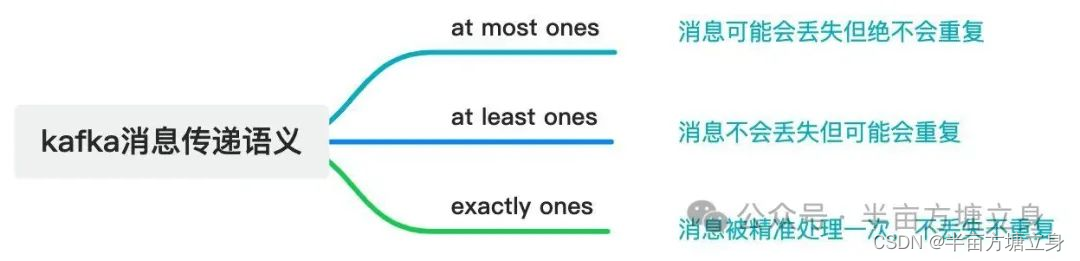
所谓的消息传递语义是 Kafka 提供的 Producer 和 Consumer 之间的消息传递过程中消息传递的保证性。主要分为三种, 如下图所示:
-
1. 首先当 Producer 向 Broker 发送数据后,会进行
commit,如果commit成功,由于Replica副本机制的存在,则意味着消息不会丢失,但是Producer发送数据给Broker后,遇到网络问题而造成通信中断,那么Producer就无法准确判断该消息是否已经被提交(commit),这就可能造成at least once语义。 -
2. 在
Kafka 0.11.0.0之前, 如果Producer没有收到消息commit的响应结果,它只能重新发送消息,确保消息已经被正确的传输到 Broker,重新发送的时候会将消息再次写入日志中;而在0.11.0.0版本之后,Producer支持幂等传递选项,保证重新发送不会导致消息在日志出现重复。为了实现这个,Broker为Producer分配了一个ID,并通过每条消息的序列号进行去重。也支持了类似事务语义来保证将消息发送到多个 Topic 分区中,保证所有消息要么都写入成功,要么都失败,这个主要用在 Topic 之间的exactly once语义。 其中启用幂等传递的方法配置:enable.idempotence = true。 启用事务支持的方法配置:设置属性transcational.id = "指定值"。 -
3. 从
Consumer角度来剖析, 我们知道Offset是由Consumer自己来维护的, 如果Consumer收到消息后更新Offset, 这时Consumer异常crash掉, 那么新的Consumer接管后再次重启消费,就会造成at most once语义(消息会丢,但不重复)。 -
4. 如果
Consumer消费消息完成后, 再更新Offset,如果这时Consumer crash掉,那么新的Consumer接管后重新用这个Offset拉取消息, 这时就会造成at least once语义(消息不丢,但被多次重复处理)。
总结: 默认 Kafka 提供「at least once」语义的消息传递,允许用户通过在处理消息之前保存 Offset的方式提供 「at mostonce」 语义。如果我们可以自己实现消费幂等,理想情况下这个系统的消息传递就是严格的「exactly once」, 也就是保证不丢失、且只会被精确的处理一次,但是这样是很难做到的。
接下来我们从生产阶段、存储阶段、消费阶段这几方面看下kafka如何保证消息不丢失。
生产阶段
通过深入解析Kafka消息发送过程我们知道Kafka生产者异步发送消息并返回一个Future,代表发送结果。首先需要我们获取返回结果判断是否发送成功。
// 异步发送消息,并设置回调函数
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("消息发送失败: " + exception.getMessage());
} else {
System.out.println("消息发送成功到主题: " + metadata.topic() + ", 分区: " + metadata.partition() + ", 偏移量: " + metadata.offset());
}
}
});消息队列通过最常用的请求确认机制,来保证消息的可靠传递:当你的代码调用发消息方法时,消息队列的客户端会把消息发送到 Broker,Broker 收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到响应后,完成了一次正常消息的发送。
Producer(生产者)保证消息不丢失的方法:
-
1. 发送确认机制:Producer可以使用Kafka的acks参数来配置发送确认机制。通过设置合适的acks参数值,Producer可以在消息发送后等待Broker的确认。确认机制提供了不同级别的可靠性保证,包括:
-
• acks=0:Producer在发送消息后不会等待Broker的确认,这可能导致消息丢失风险。
-
• acks=1:Producer在发送消息后等待Broker的确认,确保至少将消息写入到Leader副本中。
-
• acks=all或acks=-1:Producer在发送消息后等待Broker的确认,确保将消息写入到所有ISR(In-Sync Replicas)副本中。这提供了最高的可靠性保证。
-
-
2. 消息重试机制:Producer可以实现消息的重试机制来应对发送失败或异常情况。如果发送失败,Producer可以重新发送消息,直到成功或达到最大重试次数。重试机制可以保证消息不会因为临时的网络问题或Broker故障而丢失。
Broker存储阶段
正常情况下,只要 Broker 在正常运行,就不会出现丢失消息的问题,但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
在kafka高性能设计原理中我们了解到kafka为了提高性能用到了 Page Cache 技术.在读写磁盘日志文件时,其实操作的都是内存,然后由操作系统决定什么时候将 Page Cache 里的数据真正刷入磁盘。如果内存中数据还未刷入磁盘服务宕机了,这个时候还是会丢消息的。
为了最大程度地降低数据丢失的可能性,我们可以考虑以下方法:
-
持久化配置优化:可以通过调整 Kafka 的持久化配置参数来控制数据刷盘的频率,从而减少数据丢失的可能性。例如,可以降低
flush.messages和flush.ms参数的值,以更频繁地刷写数据到磁盘。 -
副本因子增加:在 Kafka 中,可以为每个分区设置多个副本,以提高数据的可靠性。当某个 broker 发生故障时,其他副本仍然可用,可以避免数据丢失。
-
使用acks=all:在生产者配置中,设置
acks=all可以确保消息在所有ISR(In-Sync Replicas)中都得到确认后才被视为发送成功。这样可以确保消息被复制到多个副本中,降低数据丢失的风险。 -
备份数据:定期备份 Kafka 的数据,以便在发生灾难性故障时可以进行数据恢复。
消费阶段
消费阶段采用和生产阶段类似的确认机制来保证消息的可靠传递,客户端从 Broker 拉取消息后,执行用户的消费业务逻辑,成功后,才会给 Broker 发送消费确认响应。如果 Broker 没有收到消费确认响应,下次拉消息的时候还会返回同一条消息,确保消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。
-
自动提交位移:Consumer可以选择启用自动提交位移的功能。当Consumer成功处理一批消息后,它会自动提交当前位移,标记为已消费。这样即使Consumer发生故障,它可以使用已提交的位移来恢复并继续消费之前未处理的消息。
-
手动提交位移:Consumer还可以选择手动提交位移的方式。在消费一批消息后,Consumer可以显式地提交位移,以确保处理的消息被正确记录。这样可以避免重复消费和位移丢失的问题。
下面是手动提交位移的例子:
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList(topic));
try {
while (true) {
// 消费消息
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
// 处理消息逻辑
System.out.println("消费消息:Topic = " + record.topic() +
", Partition = " + record.partition() +
", Offset = " + record.offset() +
", Key = " + record.key() +
", Value = " + record.value());
// 手动提交位移
TopicPartition topicPartition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offsetMetadata = new OffsetAndMetadata(record.offset() + 1);
consumer.commitSync(Collections.singletonMap(topicPartition, offsetMetadata));
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}